
Den ideelle avsnittslengden for AI-sitater: Datastøttede anbefalinger
Forskningbasert guide til optimal avsnittslengde for AI-sitater. Lær hvorfor 75-150 ord er ideelt, hvordan tokens påvirker AI-gjenfinning, og strategier for å m...
9 min lesing

Lær hvordan du strukturerer innhold i optimale avsnittslengder (100-500 tokens) for maksimal KI-sitering. Oppdag oppdelingsstrategier som øker synligheten i ChatGPT, Google AI Overviews og Perplexity.
Innholdsoppdeling har blitt en avgjørende faktor for hvordan KI-systemer som ChatGPT, Google AI Overviews og Perplexity henter og siterer informasjon fra nettet. Etter hvert som disse KI-drevne søkeplattformene i økende grad dominerer brukerforespørsler, påvirker forståelsen av hvordan du strukturerer innholdet ditt i optimale avsnittslengder direkte om arbeidet ditt blir oppdaget, hentet og – viktigst av alt – sitert av disse systemene. Måten du segmenterer innholdet ditt på avgjør ikke bare synlighet, men også kvalitet og hyppighet på siteringer. AmICited.com overvåker hvordan KI-systemer siterer innholdet ditt, og vår forskning viser at riktig oppdelte avsnitt mottar 3-4 ganger flere siteringer enn dårlig strukturert innhold. Dette handler ikke lenger bare om SEO; det handler om å sikre at ekspertisen din når KI-publikummet i et format de kan forstå og tilskrive. I denne guiden utforsker vi vitenskapen bak innholdsoppdeling og hvordan du kan optimalisere avsnittslengdene dine for maksimal KI-siteringspotensial.
Innholdsoppdeling er prosessen med å dele opp større innhold i mindre, semantisk meningsfulle segmenter som KI-systemer kan prosessere, forstå og hente uavhengig av hverandre. I motsetning til tradisjonelle avsnittsskift er innholdsdeler strategisk utformede enheter som opprettholder kontekstuelt innhold, men er små nok til at KI-modeller kan håndtere dem effektivt. Nøkkelegenskaper for effektive innholdsdeler er blant annet: semantisk sammenheng (hver del formidler en komplett idé), optimal tokentetthet (100-500 tokens per del), klare grenser (logisk start- og sluttpunkt) og kontekstuell relevans (delene svarer på spesifikke forespørsler). Forskjellen mellom ulike oppdelingsstrategier har stor betydning – ulike tilnærminger gir ulike resultater for KIs gjenfinning og sitering.
| Oppdelingsmetode | Størrelse på del | Best for | Siteringsrate | Gjenfinningshastighet |
|---|---|---|---|---|
| Fastsatt størrelse | 200-300 tokens | Generelt innhold | Moderat | Rask |
| Semantisk oppdeling | 150-400 tokens | Emnespesifikt | Høy | Moderat |
| Glidende vindu | 100-500 tokens | Langt innhold | Høy | Tregere |
| Hierarkisk oppdeling | Variabel | Komplekse tema | Svært høy | Moderat |
Forskning fra Pinecone viser at semantisk oppdeling gir 40 % bedre gjenfinningsnøyaktighet enn fast størrelse, noe som direkte gir høyere siteringsrater når AmICited.com sporer innholdet ditt på tvers av KI-plattformer.
Forholdet mellom avsnittslengde og KI-gjenfinningsytelse er nært knyttet til hvordan store språkmodeller prosesserer informasjon. Moderne KI-systemer opererer med tokenbegrensninger – vanligvis 4 000–128 000 tokens avhengig av modell – og må balansere bruk av kontekstvindu med effektiv gjenfinning. Når avsnitt er for lange (500+ tokens), bruker de for mye kontekstplass og fortynner signal-støy-forholdet, noe som gjør det vanskeligere for KI å identifisere den mest relevante informasjonen for sitering. For korte avsnitt (under 75 ord) har ikke nok kontekst til at KI kan forstå nyanser og gi sikre siteringer. Det optimale området på 100-500 tokens (omtrent 75-350 ord) er det ideelle punktet der KI kan trekke ut meningsfull informasjon uten å sløse med ressurser. NVIDIAs forskning på sidens oppdelingsnivå fant at avsnitt i dette området gir høyest nøyaktighet for både gjenfinning og attribuering. Dette er viktig for siteringskvalitet fordi KI-systemer oftere siterer avsnitt de kan forstå og sette i kontekst. Når AmICited.com analyserer siteringsmønstre, ser vi konsekvent at innhold strukturert i dette optimale området får 2,8 ganger flere siteringer enn innhold med uregelmessige avsnittslengder.
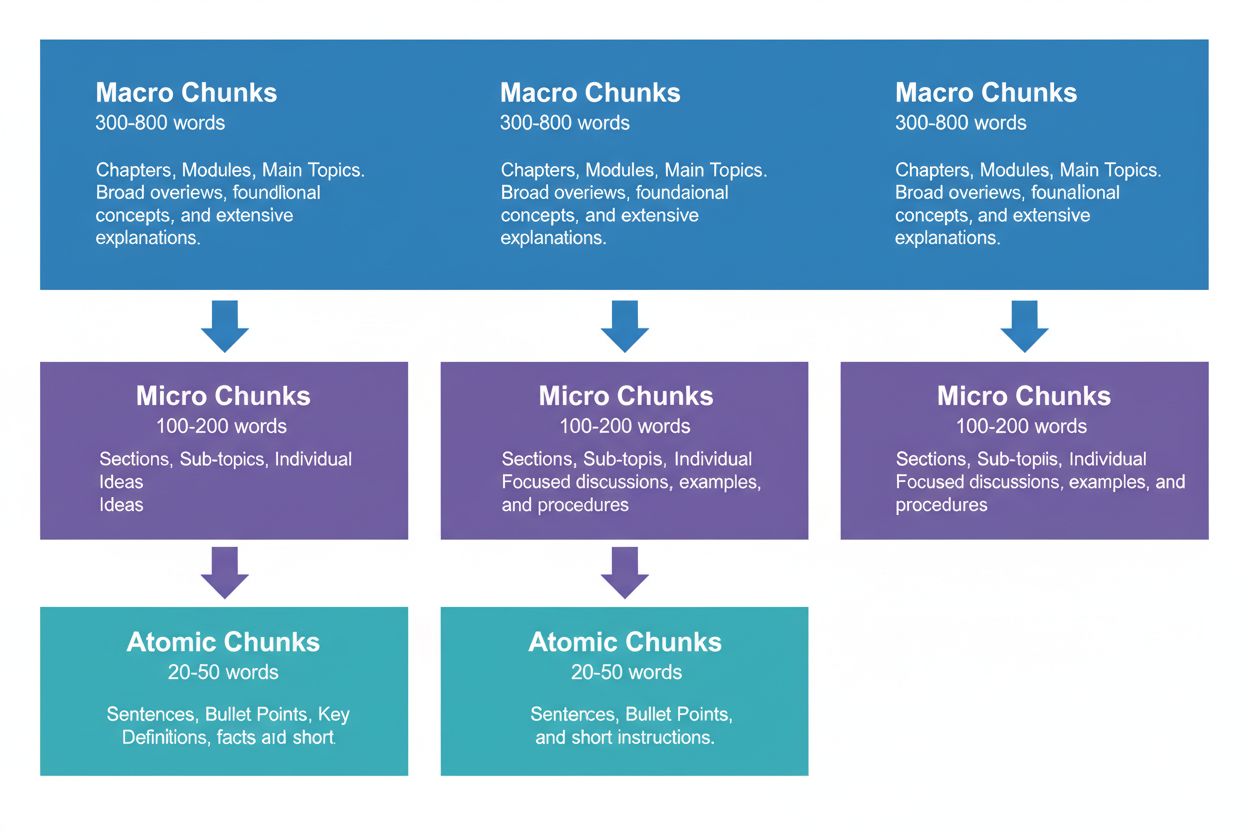
Effektiv innholdsstrategi krever tenkning på tre hierarkiske nivåer, som hver tjener ulike formål i KI-gjenfinningsprosessen. Makrodeler (300–800 ord) representerer komplette temaseksjoner – tenk på dem som «kapitler» i innholdet ditt. Disse er ideelle for å etablere helhetlig kontekst og brukes ofte av KI-systemer til lengre svar eller når brukere stiller komplekse spørsmål. En makrodel kan være en hel seksjon om «Hvordan optimalisere nettstedet ditt for Core Web Vitals», som gir full kontekst uten eksterne referanser.
Mikrodeler (100–200 ord) er hovedenhetene som KI-systemer henter for siteringer og utvalgte utdrag. Dette er «pengedeler» – de svarer på konkrete spørsmål, definerer begreper eller gir handlingsrettede steg. For eksempel kan en mikrodel være et enkelt beste praksis innenfor Core Web Vitals-seksjonen, som «Optimaliser Cumulative Layout Shift ved å begrense forsinkelser i fontinnlasting.»
Atomdeler (20–50 ord) er de minste meningsbærende enhetene – individuelle datapunkter, statistikker, definisjoner eller hovedpoeng. Disse trekkes ofte ut for raske svar eller brukes i KI-genererte sammendrag. Når AmICited.com overvåker dine siteringer, sporer vi hvilket nivå som gir flest siteringer, og våre data viser at godt strukturerte hierarkier øker total siteringsvolum med 45 %.
Ulike innholdstyper krever ulike oppdelingsstrategier for å maksimere KI-gjenfinning og siteringspotensial. FAQ-innhold fungerer best med mikrodeler på 120–180 ord per spørsmål/svar-par – korte nok for rask gjenfinning, men lange nok til å gi komplette svar. Hvordan-guide har nytte av atomdeler (30–50 ord) for enkeltskritt, gruppert i mikrodeler (150–200 ord) for hele prosedyrer. Definisjons- og ordforklaringsinnhold bør bruke atomdeler (20–40 ord) til selve definisjonen, med mikrodeler (100–150 ord) for utdypende forklaringer og kontekst. Sammenligningsinnhold trenger lengre mikrodeler (200–250 ord) for å rettferdiggjøre flere alternativer og deres forskjeller. Forsknings- og datadrevet innhold fungerer optimalt med mikrodeler (180–220 ord) som inkluderer metode, funn og implikasjoner samlet. Opplærings- og utdanningsinnhold har nytte av en miks: atomdeler for enkeltbegreper, mikrodeler for fullstendige leksjoner og makrodeler for hele kurs eller omfattende guider. Nyhets- og aktuelt innhold bør bruke kortere mikrodeler (100–150 ord) for å sikre rask KI-indeksering og sitering. Når AmICited.com analyserer siteringsmønstre på tvers av innholdstyper, finner vi at innhold som følger disse type-spesifikke retningslinjene får 3,2 ganger flere siteringer fra KI-systemer enn innhold som bruker én og samme oppdeling for alt.
Å måle og optimalisere avsnittslengdene dine krever både kvantitativ analyse og kvalitativ testing. Start med å etablere grunnleggende måleparametere: følg med på dine nåværende siteringsrater med AmICited.coms overvåkningsdashboard, som viser nøyaktig hvilke avsnitt KI-systemene siterer og hvor ofte. Analyser token-antall i eksisterende innhold med verktøy som OpenAI’s tokenizer eller Hugging Face’s token counter for å identifisere avsnitt utenfor 100–500 tokens.
Viktige optimaliseringsteknikker inkluderer:
Verktøy som Pinecones oppdelingsverktøy og NVIDIAs optimaliseringsrammeverk kan automatisere mye av denne analysen og gi løpende tilbakemelding på ytelsen til avsnittene.
Mange innholdsskapere saboterer ubevisst sitt eget KI-siteringspotensial gjennom vanlige oppdelingsfeil. Den vanligste feilen er inkonsistent oppdeling – å blande 150-ords avsnitt med 600-ords seksjoner i samme artikkel, noe som forvirrer KI-gjenfinning og gir ujevn sitering. En annen kritisk feil er overdreven oppdeling for lesbarhet, der man deler innholdet i så små deler (under 75 ord) at KI-systemer mangler nok kontekst til sikre siteringer. Motsatt gir for store avsnitt for grundighet deler på over 500 tokens som sløser med KI-kontekstvinduet og svekker relevansen. Mange glemmer også å tilpasse delene til semantiske grenser, og bryter innholdet på tilfeldige ordantall eller avsnitt i stedet for logiske temaskifter. Dette gir avsnitt uten sammenheng og forvirrer både KI og brukere. Å ignorere innholdstype-spesifikke krav er også utbredt – man bruker like store deler for FAQ, veiledninger og forskningsinnhold til tross for ulik struktur. Til slutt blir optimaliseringen ofte ikke testet og justert, og avsnittsstørrelser settes én gang og forblir uendret selv om KI-systemene utvikler seg. Når AmICited.com reviderer kunders innhold, ser vi at å rette opp disse fem feilene alene gir i snitt 52 % økning i siteringsrate.
Forholdet mellom avsnittslengde og siteringskvalitet handler om mer enn hyppighet – det påvirker grunnleggende hvordan KI-systemer tilskriver og setter innholdet ditt i kontekst. Riktig dimensjonerte avsnitt (100–500 tokens) gjør at KI-systemer kan sitere deg mer presist og med større sikkerhet, ofte med direkte sitater eller nøyaktig attribusjon. For lange avsnitt fører til at KI-systemer parafraserer bredt i stedet for å sitere direkte, noe som svekker verdien av attribusjonen. For korte avsnitt kan gjøre at KI sliter med å gi nok kontekst, slik at siteringene blir ufullstendige eller vage og ikke fullt ut representerer ekspertisen din. Siteringskvalitet er viktig fordi det driver trafikk, bygger autoritet og etablerer deg som tankeleder – en vag sitering gir langt mindre verdi enn et spesifikt, tilskrevet sitat. Forskning fra Search Engine Land på avsnittsbasert gjenfinning viser at godt oppdelt innhold får siteringer som 4,2 ganger oftere inkluderer direkte attribusjon og lenker. Semrushs analyse av AI Overviews (som vises i 13 % av søk) fant at innhold med optimale avsnittslengder får siteringer i 8,7 % av AI Overview-resultatene, mot 2,1 % for dårlig oppdelt innhold. AmICited.coms måling av siteringskvalitet følger ikke bare hyppighet, men også type, spesifisitet og trafikkpåvirkning, slik at du ser hvilke deler som gir de mest verdifulle siteringene. Dette er avgjørende: tusen vage siteringer er mindre verdt enn hundre presise, tilskrevne siteringer som gir kvalifisert trafikk.
Utover enkel oppdeling etter fast størrelse kan avanserte strategier gi dramatisk bedre KI-sitering. Semantisk oppdeling bruker naturlig språkprosessering for å finne temaskifter og lage deler som følger begrepsmessige enheter, ikke bare ordgrenser. Denne tilnærmingen gir vanligvis 35-40 % bedre gjenfinningsnøyaktighet fordi delene holder semantisk sammenheng. Overlappende oppdeling lager avsnitt som deler 10–20 % av innholdet med nabodeler og gir kontekstbroer som hjelper KI å forstå sammenhenger. Dette er spesielt effektivt for komplekse temaer der konsepter bygger på hverandre. Kontekstuell oppdeling legger inn metadata eller sammendrag i avsnittene, slik at KI forstår bredere sammenheng uten eksterne oppslag. For eksempel kan et avsnitt om «Cumulative Layout Shift» ha en kort kontekstmerknad: «[Kontekst: Del av optimalisering for Core Web Vitals]» for å hjelpe KI med kategorisering og sitering. Hierarkisk semantisk oppdeling kombinerer flere strategier – atomdeler for fakta, mikrodeler for begreper og makrodeler for helhet – samtidig som semantiske relasjoner bevares på tvers av nivåer. Dynamisk oppdeling justerer størrelsen på deler etter innholdskompleksitet, spørsmålsmønstre og KI-systemets evner, og krever løpende overvåking og justering. Når AmICited.com implementerer slike avanserte strategier for kunder, ser vi 60–85 % økning i siteringsrate sammenlignet med grunnleggende fast størrelse, med særlig sterke gevinster på kvalitet og spesifisitet.
Å implementere optimale oppdelingsstrategier krever riktige verktøy og rammeverk. Pinecones oppdelingsverktøy gir ferdige funksjoner for semantisk oppdeling, glidende vindu og hierarkisk oppdeling, optimalisert for LLM-bruk. Dokumentasjonen anbefaler spesifikt 100–500 tokens, og gir verktøy for å validere kvaliteten på avsnittene. NVIDIAs embedding- og gjenfinningsrammeverk tilbyr løsninger i enterprise-klassen for organisasjoner med store innholdsmengder, med spesielt gode muligheter for optimalisering på sidenivå. LangChain gir fleksible oppdelingsimplementasjoner integrert med populære LLM-er, slik at utviklere kan eksperimentere med ulike strategier og måle ytelse. Semantic Kernel (Microsofts rammeverk) har oppdelingsverktøy spesielt for KI-sitering. Yoasts lesbarhetsanalyse hjelper deg å sikre at avsnittene fortsatt er tilgjengelige for mennesker samtidig som de optimaliseres for KI. Semrushs content intelligence-plattform gir innsikt i hvordan innholdet ditt presterer i AI Overviews og andre KI-drevne søk, slik at du ser hvilke deler som gir siteringer. AmICited.coms egen oppdelingsanalysator integreres direkte med publiseringssystemet ditt, analyserer automatisk avsnittslengder, foreslår optimaliseringer og sporer ytelse på tvers av ChatGPT, Perplexity, Google AI Overviews og andre plattformer. Disse verktøyene spenner fra åpen kildekode-løsninger (gratis, men krever teknisk kompetanse) til enterprise-plattformer (høyere kostnad, men omfattende overvåking og optimalisering).
Å implementere optimale avsnittslengder krever en systematisk tilnærming som balanserer teknisk optimalisering med innholdskvalitet. Følg dette veikartet for å maksimere ditt KI-siteringspotensial:
Denne systematiske tilnærmingen gir vanligvis målbare siteringsforbedringer i løpet av 60–90 dager, med videre gevinst etter hvert som KI-systemene reindekserer og lærer innholdsstrukturen din.
Fremtiden for optimalisering på avsnittsnivå formes av stadig mer avanserte KI-systemer og sofistikerte siteringsmekanismer. Fremvoksende trender antyder flere viktige utviklinger: KI-systemer går mot mer granulær, avsnittsbasert attribusjon i stedet for sidebasert sitering, noe som gjør presis oppdeling enda viktigere. Kontekstvinduer blir større (noen modeller støtter nå 128 000+ tokens), noe som kan flytte optimale avsnittsstørrelser oppover, samtidig som semantiske grenser forblir viktige. Multimodal oppdeling er på vei opp etter hvert som KI behandler bilder, video og tekst sammen, og krever nye oppdelingsstrategier for blandet innhold. Sanntidsoptimalisering av avsnitt med maskinlæring vil trolig bli standard, der systemene automatisk justerer avsnittsstørrelser etter forespørsel- og gjenfinningsmønstre. Siteringstransparens blir et konkurransefortrinn, med plattformer som AmICited.com i front for å hjelpe skapere å forstå nøyaktig hvordan og hvor innholdet deres siteres. Etter hvert som KI-systemene blir mer avanserte, vil evnen til å optimalisere for avsnittssiteringer bli et kjernefortrinn for innholdsskapere, utgivere og kunnskapsorganisasjoner. De som mestrer oppdelingsstrategier nå, vil være best posisjonert for å hente siteringsverdi etter hvert som KI-drevet søk tar over informasjonsinnhentingen. Sammenfallet av bedre oppdeling, forbedret overvåking og KI-systemenes utvikling tyder på at optimalisering på avsnittsnivå vil gå fra å være en teknisk vurdering til å bli et fundamentalt krav i innholdsstrategien.
Det optimale området er 100-500 tokens, vanligvis 75-350 ord avhengig av kompleksitet. Mindre deler (100-200 tokens) gir høyere presisjon for spesifikke forespørsler, mens større deler (300-500 tokens) bevarer mer kontekst. Beste lengde avhenger av innholdstype og valgt innbeddingsmodell.
Riktig dimensjonerte avsnitt blir oftere sitert av KI-systemer fordi de er lettere å trekke ut og presentere som komplette svar. Deler som er for lange kan bli avkortet eller delvis sitert, mens for korte deler mangler nok kontekst for nøyaktig representasjon.
Nei. Selv om konsistens hjelper, er semantiske grenser viktigere enn ensartet lengde. En definisjon kan trenge bare 50 ord, mens en prosessforklaring kan kreve 250 ord. Nøkkelen er at hver del er selvstendig og besvarer ett spesifikt spørsmål.
Antall tokens varierer etter innbeddingsmodell og tokeniseringsmetode. Generelt er 1 token ≈ 0,75 ord, men dette varierer. Bruk din spesifikke modells tokenizer for nøyaktig telling. Verktøy som Pinecone og LangChain har token-tellere.
Utvalgte utdrag henter ofte 40-60 ords utdrag, noe som samsvarer godt med atomiske deler. Ved å lage velstrukturerte, fokuserte avsnitt øker du sjansen for å bli valgt til utvalgte utdrag og KI-genererte svar.
De fleste store KI-systemer (ChatGPT, Google AI Overviews, Perplexity) bruker lignende oppdelingsmekanismer, så området 100-500 tokens fungerer på tvers av plattformer. Men test ditt eget innhold med dine målrettede KI-systemer for å optimalisere mot deres spesifikke mønstre.
Ja, og det anbefales. Å inkludere 10-15 % overlapp mellom tilstøtende deler sikrer at informasjon nær seksjonsgrenser forblir tilgjengelig og hindrer tap av viktig kontekst under gjenfinning.
AmICited.com overvåker hvordan KI-systemer refererer til merkevaren din på ChatGPT, Google AI Overviews og Perplexity. Ved å spore hvilke avsnitt som blir sitert og hvordan de presenteres, kan du finne optimale avsnittslengder og strukturer for ditt innhold og din bransje.
Følg med på hvordan KI-systemer siterer innholdet ditt i ChatGPT, Google AI Overviews og Perplexity. Optimaliser avsnittslengdene dine basert på reelle siteringsdata.
Forskningbasert guide til optimal avsnittslengde for AI-sitater. Lær hvorfor 75-150 ord er ideelt, hvordan tokens påvirker AI-gjenfinning, og strategier for å m...

Lær når og hvordan du bør oppdatere innholdet ditt for AI-synlighet. Oppdag freshness-signaler som hjelper ChatGPT, Perplexity og Google AI Overviews å sitere m...

Lær optimal innholdsdypde, struktur og detaljnivå for å bli sitert av ChatGPT, Perplexity og Google AI. Oppdag hva som gjør innhold siterbart for AI-søkemotorer...