Lands-spesifikke AI-plattformer: Optimalisering etter region
Lær hvordan du kan optimalisere merkevarens synlighet på lands-spesifikke AI-plattformer. Oppdag regionale strategier, krav til etterlevelse og verktøy for internasjonal AI-optimalisering.
Publisert den Jan 3, 2026.Sist endret den Jan 3, 2026 kl. 3:24 am
Regional AI-optimalisering: Forståelse av globale plattformvariasjoner
Kunstig intelligens-plattformer som ChatGPT, Claude, Perplexity og Google AI Overviews omformer hvordan informasjon når publikum verden over, men få merkevarer er klar over at disse plattformene gir dramatisk forskjellige svar avhengig av geografisk plassering. Hvordan merkevaren din fremstår i AI-genererte svar varierer betydelig mellom land på grunn av regionale reguleringer, språkpreferanser, lokal treningsdata og markedsspesifikke optimaliseringsstrategier. Å forstå hvordan lands-spesifikke AI-plattformer opererer ulikt etter region har blitt avgjørende for å opprettholde merkevaresynlighet i et stadig mer AI-drevet søkelandskap. Denne geografiske variasjonen i AI-svar gjør regional AI-optimalisering ikke bare gunstig—den er kritisk for globale merkevarer som ønsker å opprettholde jevn synlighet på tvers av internasjonale markeder.
Regionale AI-adopsjonsrater og markedsforskjeller
Adopsjon og utrulling av AI-teknologi varierer dramatisk mellom regioner, med Asia-Stillehavet som tydelig leder innen bedrifts-AI-implementering. Ifølge Forresters nyeste forskning kommer fire av de fem beste landene for AI-bruk fra APAC, hvor Singapore, Australia, New Zealand og Sør-Korea ligger betydelig foran de fleste nordamerikanske og europeiske land i adopsjonsrater. Investeringstrender viser store regionale forskjeller: 26 % av APAC-bedrifter investerer mellom $400 000 og $500 000 i AI-initiativer, mot kun 19 % i Nord-Amerika og 17 % i Europa, noe som gjenspeiler ulike tilnærminger til AI-risiko og mulighetsvurdering. Også ledelsesstrukturen varierer betydelig etter region—33 % av APAC-organisasjoner identifiserer konsernsjefen som hovedansvarlig for AI-strategi, mot 18 % i Nord-Amerika og kun 8 % i Europa, hvor styring og etterlevelse ofte fordeler beslutningsmyndighet bredere.
Region
AI-adopsjonsrate
Primære bruksområder
Investeringsnivå
Ledelsesmodell
APAC
Høyest (63% GenAI)
Prediktiv AI (53%), GenAI (63%), IT-drift
$400-500K (26%)
CEO-drevet (33%)
Nord-Amerika
Høy (50%+)
Operasjonell effektivitet, digital kundeopplevelse
$300K+ (75%)
Fordelt/CIO-ledet
Europa
Moderat-høy (45%+)
Databehandling, ansattopplevelse, etterlevelse
$300K+ (75%)
Styringsfokusert
Latin-Amerika
Fremvoksende (30%+)
Datapersonvern, etisk AI, etterlevelse
Økende
Etterlevelsesdrevet
Midtøsten
Økende (35%+)
Innovasjon, økonomisk vekst, sektorspesifikt
Økende
Pro-innovasjon
Forskjellene i bruksområder viser de tydeligste regionale ulikhetene: APAC-bedrifter tar i bruk prediktiv AI i IT-drift med en adopsjonsrate på 53 % og generativ AI på 63 %, begge betydelig over nivåene i Nord-Amerika og Europa. Nordamerikanske organisasjoner konsentrerer sine AI-investeringer på operasjonell effektivitet og forbedring av digital kundeopplevelse, for å gi avkastning på kort sikt og samtidig beholde strategisk fleksibilitet. Europeiske virksomheter, som møter strengere regelverk og sterkere arbeidstakervern, fokuserer strategisk på databehandling og forbedring av ansattopplevelsen, og posisjonerer styring som et konkurransefortrinn ettersom AI-reguleringer utvides globalt.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Regulatorisk landskap former regionale AI-operasjoner
Det regulatoriske miljøet former grunnleggende hvordan internasjonale AI-plattformer opererer og hvordan merkevarer må optimalisere sin tilstedeværelse på tvers av regioner. Hver hovedregion har utviklet egne reguleringsrammeverk som direkte påvirker AI-modelltrening, datahåndtering, innholdsfiltrering og grenseoverskridende operasjoner:
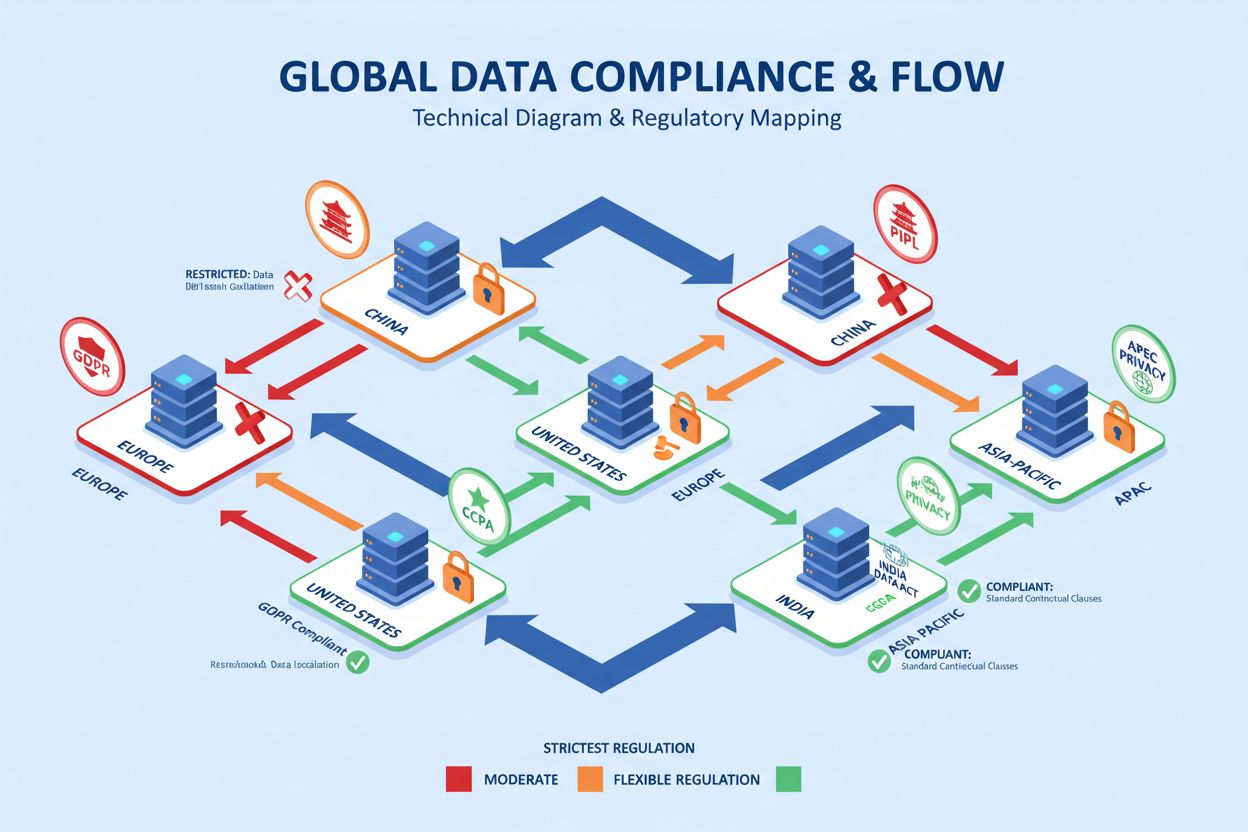
Europa (GDPR + AI Act): EUs generelle personvernforordning (GDPR) setter global standard for personvern, mens AI Act (gjeldende fra august 2026) introduserer risikobasert klassifisering som krever at høyrisiko-AI-systemer møter strenge krav til styring, åpenhet og menneskelig tilsyn. Organisasjoner må sikre at både treningsdata og AI-genererte resultater følger GDPR-prinsippene, inkludert dataminimering, formålsbegrensning og individers rett til innsyn og sletting.
USA (statlig fragmentering): USA mangler et samlet føderalt AI-regelverk, og baserer seg på statlige lover som Californias Consumer Privacy Act (CCPA) og Virginias Consumer Data Protection Act (VCDPA). Dette skaper et fragmentert etterlevelseslandskap hvor organisasjoner må navigere varierende krav, mens føderale myndigheter prioriterer innovasjon over strenge sikkerhetstiltak.
Kina (PIPL - Personopplysningsloven): Kina håndhever et av verdens strengeste krav til datalokalisering, og krever at personopplysninger om kinesiske innbyggere lagres innenfor landets grenser. Grenseoverskridende overføringer er sterkt begrenset og krever sikkerhetsvurderinger, noe som fundamentalt begrenser hvordan internasjonale AI-plattformer kan operere i det kinesiske markedet.
Brasil (LGPD - Generell personvernlov): Basert på GDPR regulerer Brasils LGPD behandling av personopplysninger med krav om samtykkebasert behandling, åpenhet og robust datasikkerhet. Selv om det ikke stilles strenge lokaliseringskrav, begrenses overføring av data ut av Brasil med mindre mottakerlandet gir tilstrekkelig beskyttelse eller kontraktsmessige garantier foreligger.
India (DPDPB - Bill om digitalt personvern): Indias rammeverk legger vekt på datasuverenitet og brukersamtykke, med lokaliseringskrav for spesifikke datatyper. Loven skal styrke lokale teknologiselskaper og beskytte borgernes data, og skaper både muligheter og driftsmessige utfordringer for internasjonale AI-plattformer.
APAC-regionale rammeverk: Singapores Model AI Governance Framework vektlegger ansvarlig bruk og datastyring, Sør-Koreas AI-bransje-lov balanserer innovasjon med krav til åpenhet, og Japans myke tilnærming gir fleksibilitet, men varsler fremtidige bindende regler.
Disse regulatoriske variasjonene skaper et komplekst etterlevelseslandskap hvor organisasjoner må tilpasse AI-strategier til lokale krav, samtidig som de opprettholder global konsistens.
Dataresidens, datasuverenitet og datalokalisering: Tekniske implikasjoner
Å forstå forskjellene mellom dataresidens, datasuverenitet og datalokalisering er avgjørende for å implementere effektive regionale AI-optimaliseringsstrategier. Dataresidens viser til den spesifikke geografiske plasseringen hvor data fysisk lagres og behandles—et forretningsvalg eller kundekrav uten iboende lovpålegg. Datasuverenitet betyr at data er underlagt lovene i landet hvor det befinner seg, uavhengig av hvor det opprinnelig ble samlet inn eller hvor virksomheten har hovedkontor. Datalokalisering er et lovpålagt krav om at data må forbli innenfor et lands grenser, slik vi ser med Kinas PIPL og Russlands lov nr. 242-FZ.
Disse forskjellene har store implikasjoner for AI-drift. Når AI-modeller trenes, må virksomheter sikre at dataen som benyttes følger lokale residensregler, innhente nødvendig samtykke fra individer, og anonymisere data der det er mulig. Grenseoverskridende dataoverføringer blir betydelig mer komplekse, og krever mekanismer som Standard Contractual Clauses (SCCs) eller Binding Corporate Rules (BCRs) for å sikre etterlevelse av personvernlovgivning på begge sider av grensen. Valg av leverandør av skytjenester blir kritisk—organisasjoner må prioritere leverandører som tilbyr region-spesifikke lagringsalternativer som gjør det mulig å oppfylle lokale residenskrav. De operative kostnadene for etterlevelse er betydelige, og krever investeringer i lokale datasentre, juridisk kompetanse og spesialisert infrastruktur for å unngå bøter og opprettholde regulatorisk status.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Lands-spesifikke AI-plattformvariasjoner og tilpasninger
Store AI-plattformer som ChatGPT, Claude, Perplexity og Google AI Overviews bruker avanserte regionale tilpasninger som fundamentalt endrer hvordan de svarer på brukerspørsmål og hvilke kilder de siterer. Disse plattformene tilpasser svarene sine basert på geografisk plassering gjennom flere mekanismer: språk- og kulturlokalisering sikrer at svarene reflekterer regionale kommunikasjonsstiler og kulturelle kontekster, innholdsfiltrering bruker lokale lover og regler for å bestemme hvilken informasjon som kan vises, og regional treningsdata påvirker hvilke kilder og perspektiver modellene prioriterer. For eksempel må en AI-plattform som opererer i Europa etterleve GDPR-krav til databehandling, og kan filtrere innhold annerledes enn samme plattform i USA.
Tilgjengeligheten av AI-plattformer varierer betydelig mellom regioner—noen plattformer møter restriksjoner eller fullstendige forbud i enkelte land grunnet regulatoriske eller geopolitiske hensyn. Forskjeller i regional treningsdata betyr at AI-systemer som hovedsakelig er trent på engelskspråklig innhold kan prestere annerledes når de svarer på spørsmål på andre språk eller om region-spesifikke temaer. Disse variasjonene utgjør en kritisk utfordring for merkevarer: synligheten til virksomheten din i AI-genererte svar kan variere dramatisk mellom markeder. En merkevare som får stor synlighet i AI-svar i Nord-Amerika kan bli minimalt nevnt i europeiske AI-plattformer på grunn av ulik treningsdata, innholdsfiltrering eller regional optimalisering fra konkurrenter. Denne geografiske variasjonen i AI-synlighet gjør overvåking og optimalisering av tilstedeværelsen på lands-spesifikke AI-plattformer essensiell for å opprettholde en konsekvent merkevare globalt.
Handlingsrettede optimaliseringsstrategier for regional AI-synlighet
Merkevarer som ønsker å optimalisere sin tilstedeværelse på tvers av regionale AI-plattformer må ta i bruk en flerfasettert tilnærming som kombinerer lokalisering, etterlevelse og strategisk overvåking. Å utvikle en lokalisert innholdsstrategi for hver region sikrer at merkevarens budskap, eksempler og verdiforslag treffer regionale målgrupper og harmonerer med lokale søkevaner—det som fungerer i Nord-Amerika kan ha liten effekt i APAC eller Europa. Å forstå regionale søkevaner og de spesifikke AI-spørsmålene brukere stiller i ulike markeder lar deg produsere innhold som direkte adresserer region-spesifikke spørsmål og bekymringer. En etterlevelsesfokusert tilnærming til innholdsproduksjon sikrer at alt regionalt innhold følger lokale regler, personvernlover og kulturelle hensyn, og reduserer risikoen for at innhold blir filtrert bort eller nedprioritert av regionale AI-plattformer.
Å gjennomføre regional søkeordsanalyse og optimalisering avslører hvilke temaer, nøkkelord og innholdsformater som gir best resultater i hvert marked, slik at du kan fordele ressurser effektivt. Implementering av overvåkingsverktøy spesielt utviklet for regional AI-synlighet—som AmICited, som sporer hvordan merkevaren din vises på AI-plattformer i ulike land og språk—gir sanntidsinnsikt i din regionale ytelse. Testing og iterasjon per region gir deg mulighet til å eksperimentere med ulike innholdstilnærminger, budskapsstrategier og optimaliseringstaktikker i spesifikke markeder før du ruller ut vellykkede konsepter globalt. Å bygge regionale innholdshubber med dedikerte ressurser for hvert hovedmarked sikrer konsekvent, innhold av høy kvalitet som reflekterer regional ekspertise og lokal markedskunnskap. Denne flernasjonale tilnærmingen krever betydelig koordinering, men gir store konkurransefortrinn i et stadig mer AI-drevet informasjonslandskap.
Utfordringer ved implementering av multiregional AI-strategi
Organisasjoner som satser på multiregional AI-optimalisering møter betydelige hindringer utover bare oversettelse av innhold. Regulatorisk fragmentering skaper motstridende krav—det som er i samsvar med GDPR i Europa kan bryte lover om datalokalisering i Kina, og tvinger virksomheter til å opprettholde separate systemer og prosesser for ulike regioner. Ressursfordeling på tvers av flere regioner belaster budsjetter og teamkapasitet, spesielt for mellomstore virksomheter uten ressursene til globale konsern. Språklige og kulturelle nyanser krever mer enn oversettelse; de krever dyp forståelse av regionale kontekster, kommunikasjonsstiler og kulturelle hensyn som kun kan komme fra lokal ekspertise eller omfattende forskning.
Overvåkingskompleksiteten øker eksponentielt for hver ny region og språk—å spore merkevarens synlighet på ChatGPT, Claude, Perplexity og Google AI Overviews i fem ulike språk og regioner krever sofistikerte verktøy og prosesser. Kostnadene for etterlevelse og lokalisering kan være store, med behov for investeringer i lokale datasentre, juridisk kompetanse, innholdsproduksjon og spesialisert infrastruktur. Å holde tritt med endrede reguleringer er en kontinuerlig utfordring, ettersom myndigheter over hele verden stadig utvikler og oppdaterer regelverk for AI, og tvinger virksomheter til konstant tilpasning. Disse utfordringene forklarer hvorfor mange virksomheter sliter med internasjonal AI-optimalisering til tross for at de ser viktigheten av det.
Verktøy og løsninger for omfattende regional AI-overvåking
Kompleksiteten ved å administrere regional AI-synlighet på tvers av flere plattformer og språk har skapt behov for spesialiserte overvåkingsløsninger. Organisasjoner trenger omfattende verktøy som kan spore hvordan merkevaren deres fremstår i AI-genererte svar på tvers av ulike land, språk og plattformer samtidig. AmICited.com utmerker seg som den ledende spesialiserte løsningen for denne utfordringen, med multi-region og flerspråklig AI-synlighetssporing spesielt utviklet for merkevarer med internasjonal tilstedeværelse. I motsetning til generelle verktøy, fokuserer AmICited utelukkende på å overvåke hvordan AI-plattformer siterer og refererer til din merkevare, og gir sanntidsinnsikt i regional AI-synlighet, siteringsmønstre og konkurranseposisjonering.
AmICiteds funksjoner inkluderer sporing på tvers av flere AI-motorer (ChatGPT, Claude, Perplexity, Google AI Overviews), overvåking på ulike språk og regionale varianter, sanntidsvarsler ved endringer i merkevarens synlighet, konkurranseanalyse som viser hvordan konkurrenter rangerer i regionale AI-svar, og etterlevelsessporing for å sikre at innholdet ditt følger regionale regler. Mens andre løsninger som FlowHunt.io tilbyr AI-innholdsgenerering og automatisering, gjør AmICiteds spesialiserte fokus på overvåking og siteringssporing det til det beste valget for merkevarer som prioriterer AI-synlighet. Plattformens støtte for flere språk, regional etterlevelsessporing og siteringsovervåking adresserer behovene til organisasjoner med internasjonale AI-strategier. Sanntidsvarsler muliggjør raske reaksjoner på synlighetsendringer, mens regional konkurranseanalyse hjelper med å identifisere muligheter og trusler i bestemte markeder.
Virkelige caser: Suksess med regional AI-optimalisering
Case 1: Europeisk SaaS-selskap navigerer GDPR og optimaliserer AI-synlighet
Et europeisk B2B SaaS-selskap sto overfor utfordringen med å opprettholde AI-synlighet på tvers av europeiske markeder samtidig som de overholdt GDPR. Organisasjonen implementerte en regional innholdsstrategi som vektla personvern og etterlevelse i alt innhold, og posisjonerte disse verdiene som konkurransefortrinn. Ved å overvåke regional AI-synlighet med spesialiserte verktøy, oppdaget de at europeiske AI-plattformer prioriterte innhold som fremhevet datasikkerhet og etterlevelse høyere enn nordamerikanske plattformer. Selskapet opprettet regionsspesifikke innholdshubber med fokus på europeiske regulatoriske tema, noe som førte til en økning på 45 % i AI-siteringer i europeiske markeder innen seks måneder, samtidig som de opprettholdt full GDPR-etterlevelse.
Case 2: APAC-teknologiselskap utnytter regional AI-adopsjon
Et teknologiselskap med base i APAC så regionens høyere AI-adopsjonsrate og CEO-drevne AI-strategi som et konkurransefortrinn. De investerte tungt i regional innholdsoptimalisering og utviklet markeds-spesifikke ressurser rettet mot APACs unike bruksområder og forretningsutfordringer. Ved å forstå at APAC-organisasjoner prioriterer prediktiv AI og IT-drift, tilpasset de innholdet sitt til disse behovene. Resultatet: 60 % høyere AI-siteringsrate i APAC-markeder sammenlignet med Nord-Amerika, noe som ga betydelig flere kvalifiserte leads fra regionen.
Case 3: Global virksomhet håndterer multiregional AI-strategi
Et globalt konsern med virksomhet i Nord-Amerika, Europa og APAC implementerte et sentralisert overvåkingssystem for AI-synlighet, samtidig som de beholdt regional innholdsautonomi. De opprettet regionale innholdsteam med myndighet til å tilpasse global kommunikasjon til lokale kontekster, regelverk og markedsdynamikk. Ved å bruke AmICiteds sporing på tvers av regioner fikk de innsikt i hvordan merkevaren fremstod ulikt mellom regioner, og kunne identifisere hvilke strategier som var mest effektive. Denne datadrevne tilnærmingen gjorde det mulig å fordele ressurser bedre, investere mer i høy-presterende regioner og forbedre svake markeder. I løpet av ett år oppnådde de jevn AI-synlighet på tvers av alle hovedregioner, samtidig som de reduserte innholdsproduksjonskostnadene gjennom bedre ressursallokering.
Fremtidstrender innen regional AI-optimalisering
Landskapet for regional AI-optimalisering utvikler seg raskt, med flere viktige trender. Regulatorisk konvergens er sannsynlig etter hvert som flere land innfører rammeverk som EUs AI Act, noe som gir mer standardiserte krav globalt—tidlige brukere av helhetlige etterlevelsesstrategier vil få konkurransefortrinn etter hvert som reglene strammes inn. Suveren AI og edge computing øker i betydning, med land og regioner som utvikler lokalt styrt AI-infrastruktur for å sikre datasuverenitet og redusere avhengighet av globale AI-plattformer. Økende krav til datalokalisering vil fortsette å drive investeringer i regionale datasentre og lokale AI-modeller, noe som gir både utfordringer og muligheter for internasjonale virksomheter.
Regional AI-modellutvikling akselererer, med land som Kina, India og europeiske nasjoner som investerer i lokale AI-modeller optimalisert for regionale språk, kulturer og reguleringer. Disse regionale modellene kan etter hvert konkurrere med globale plattformer, noe som krever at merkevarer optimaliserer for flere AI-systemer, ikke bare de dominerende globale aktørene. Personvernbevarende AI-teknikker som federert læring, differensiell personvern og syntetisk datagenerering blir stadig viktigere for å sikre etterlevelse og samtidig utnytte AI. Virksomheter som behersker disse teknikkene tidlig vil oppnå betydelige konkurransefortrinn. Mulighetene for tidlige brukere er store—merkevarer som allerede nå implementerer helhetlige regionale AI-optimaliseringsstrategier vil sikre seg sterke posisjoner før konkurransen øker og reguleringene strammes ytterligere.
Vanlige spørsmål
Hvordan skiller AI-plattformer seg mellom regioner?
AI-plattformer som ChatGPT, Claude og Perplexity tilpasser sine svar basert på geografisk plassering, lokale regler, språkpreferanser og regional treningsdata. Dette betyr at merkevaren din kan vises forskjellig i søkeresultater på tvers av land, noe som krever regionsspesifikke optimaliseringsstrategier.
Hva er dataresidens, og hvorfor er det viktig for AI?
Dataresidens refererer til hvor data fysisk lagres. Det er viktig for AI fordi ulike regioner har strenge lover (som GDPR i Europa) som krever at data forblir innenfor landegrensene, noe som påvirker hvordan AI-modeller trenes og distribueres. Å forstå dataresidens er avgjørende for etterlevelse og operasjonell planlegging.
Hvilke regioner har de strengeste AI-reguleringene?
Europa leder med GDPR og AI Act (gjeldende fra 2026), etterfulgt av Kina med PIPL, og India med DPDPB. Disse reguleringene påvirker i stor grad hvordan AI-plattformer opererer og hvordan merkevarer må optimalisere innholdet sitt for regional synlighet.
Hvordan kan jeg optimalisere merkevaren min for regional AI-synlighet?
Lag lokalisert innhold for hver region, forstå regionale søkevaner, sørg for etterlevelse av lokale regler, overvåk regionale AI-sitater, og bruk spesialiserte verktøy som AmICited for å spore synlighet på tvers av land og språk i sanntid.
Hva er forskjellen på dataresidens, datasuverenitet og datalokalisering?
Dataresidens er hvor data lagres, datasuverenitet betyr at data er underlagt lokale lover, og datalokalisering er et lovkrav om å beholde data innenfor landegrenser. Alle tre påvirker AI-operasjoner forskjellig og krever ulike etterlevelsesstrategier.
Hvordan overvåker jeg merkevaren min på flere regionale AI-plattformer?
Bruk omfattende overvåkingsverktøy som AmICited som sporer AI-synlighet på tvers av regioner, språk og plattformer. Disse verktøyene gir sanntidsinnsikt i hvordan merkevaren din vises i ulike markeder og varsler deg om endringer i synlighet.
Hva er hovedutfordringene i en multiregional AI-strategi?
Nøkkelutfordringer inkluderer regulatorisk fragmentering, ressursfordeling, språklige og kulturelle nyanser, overvåkingskompleksitet, etterlevelseskostnader og å holde tritt med endrede reguleringer i ulike regioner. Disse hindringene krever strategisk planlegging og spesialiserte verktøy.
Hvilke regioner leder an i AI-adopsjon?
APAC-land (Singapore, Australia, New Zealand, Sør-Korea) leder i AI-adopsjon, etterfulgt av Nord-Amerika og Europa. Hver region har ulike bruksområder, investeringsnivåer og ledelsesstrukturer for AI-implementering.
Overvåk din AI-synlighet i alle regioner
Følg med på hvordan merkevaren din vises på AI-plattformer i ulike land og språk. Få sanntidsinnsikt i regionale AI-sitater og optimaliser din globale tilstedeværelse.
Fungerer AI-søk forskjellig fra land til land? Regionale variasjoner forklart
Oppdag hvordan AI-søkemotorer varierer etter land og språk. Lær om lokaliseringsforskjeller mellom ChatGPT, Perplexity, Gemini og Copilot, og hvordan geografisk...
Er AI-søkeresultater forskjellige fra land til land? Oppdaget ulikheter mellom USA og Storbritannia
Diskusjon i fellesskapet om geografiske forskjeller i AI-søkeresultater. Reelle erfaringer fra internasjonale markedsførere som analyserer AI-sitasjonsmønstre p...
AI-søk: Regionale forskjeller og globale optimaliseringsstrategier
Oppdag hvordan regionalt AI-søk varierer globalt. Lær optimaliseringsstrategier for Perplexity, ChatGPT og Google AI Overviews på tvers av ulike markeder.
8 min lesing
Informasjonskapselsamtykke Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.