Forebygging av AI-synlighetskriser: Proaktive strategier
Lær hvordan du kan forebygge AI-synlighetskriser med proaktiv overvåking, tidlige varslingssystemer og strategiske responsprotokoller. Beskytt merkevaren din i ...
9 min lesing

Lær å oppdage AI-synlighetskriser tidlig med sanntidsovervåking, sentimentanalyse og avviksdeteksjon. Oppdag varselsignaler og beste praksis for å beskytte ditt merkevareomdømme i AI-drevne søk.
En AI-synlighetskrise oppstår når kunstige intelligenssystemer produserer unøyaktige, misvisende eller skadelige resultater som svekker merkevareomdømme og undergraver offentlig tillit. I motsetning til tradisjonelle PR-kriser som stammer fra menneskelige beslutninger eller handlinger, oppstår AI-synlighetskriser i skjæringspunktet mellom kvaliteten på treningsdata, algoritmisk skjevhet og sanntidsinnholdsgenerering—noe som gjør dem fundamentalt vanskeligere å forutsi og kontrollere. Ny forskning viser at 61 % av forbrukerne har fått redusert tillit til merkevarer etter å ha opplevd AI-hallusinasjoner eller feilaktige AI-svar, mens 73 % mener selskaper bør holdes ansvarlige for hva deres AI-systemer sier offentlig. Disse krisene sprer seg raskere enn tradisjonell feilinformasjon fordi de fremstår som autoritative, kommer fra pålitelige merkevarekanaler, og kan påvirke tusenvis av brukere samtidig før menneskelig inngripen er mulig.
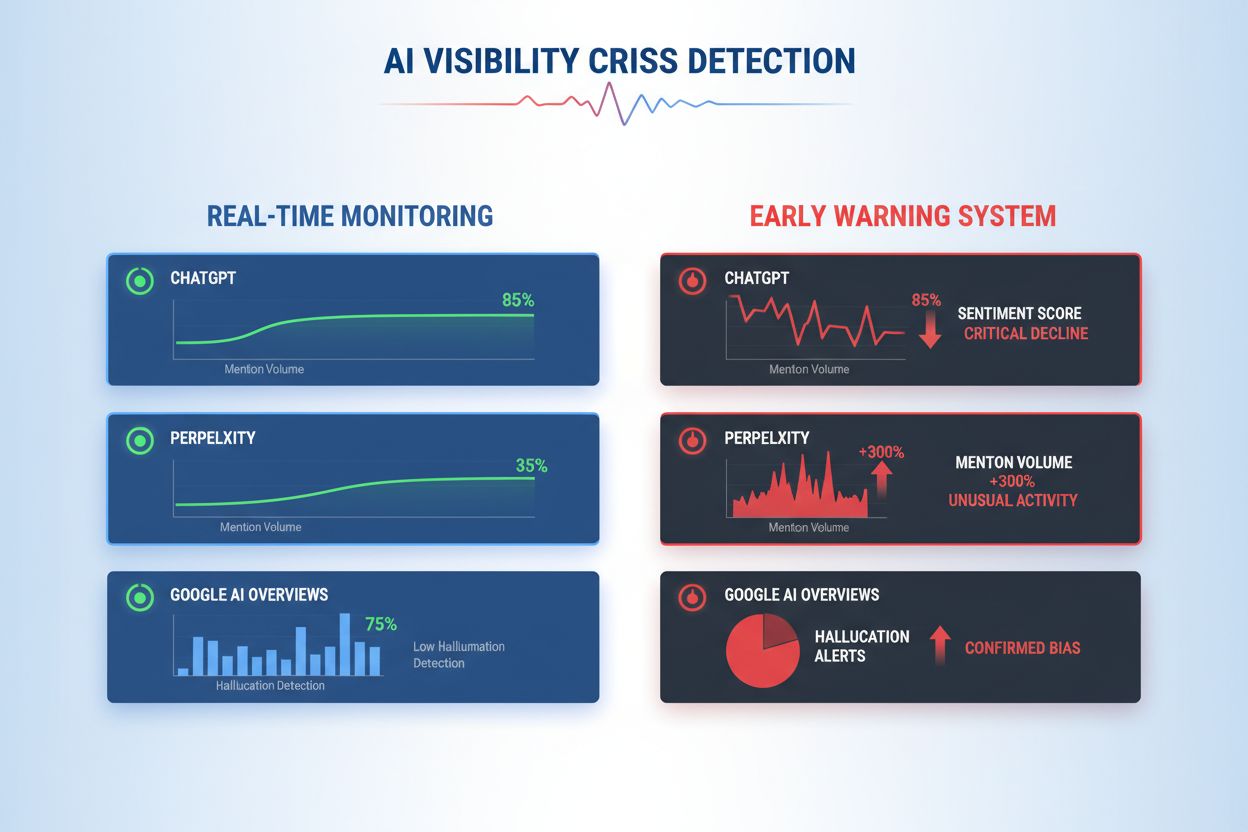
Effektiv deteksjon av AI-synlighetskrise krever overvåking av både input (data, samtaler og treningsmateriale som mater AI-systemene dine) og output (hva AI-en faktisk sier til kundene). Input-overvåking undersøker data fra sosial lytting, kundetilbakemeldinger, treningsdatasett og eksterne informasjonskilder for skjevhet, feilinformasjon eller problematiske mønstre som kan forurense AI-svar. Output-overvåking sporer hva AI-systemene dine faktisk genererer—svarene, anbefalingene og innholdet de produserer i sanntid. Da chatboten til et større finansselskap begynte å anbefale kryptovalutainvesteringer basert på skjeve treningsdata, spredte krisen seg over sosiale medier i løpet av timer, påvirket aksjekursen og førte til regulatorisk gransking. Tilsvarende, da et helse-AI-system ga utdaterte medisinske råd fra korrupte treningsdatasett, tok det tre dager å identifisere rotårsaken, i løpet av hvilke tusenvis av brukere mottok potensielt skadelig veiledning. Gapet mellom input-kvalitet og output-nøyaktighet skaper et blindsone der kriser kan utvikle seg uoppdaget.
| Aspekt | Input-overvåking (Kilder) | Output-overvåking (AI-svar) |
|---|---|---|
| Hva som spores | Sosiale medier, blogger, nyheter, omtaler | ChatGPT, Perplexity, Google AI-svar |
| Deteksjonsmetode | Nøkkelordsporing, sentimentanalyse | Prompt-forespørsler, responsanalyse |
| Kriseindikator | Virale negative innlegg, trendende klager | Hallusinasjoner, feilaktige anbefalinger |
| Responstid | Timer til dager | Minutter til timer |
| Primærverktøy | Brandwatch, Mention, Sprout Social | AmICited, GetMint, Semrush |
| Prisintervall | $500-$5,000/måned | $800-$3,000/måned |
Organisasjoner bør etablere kontinuerlig overvåking for disse spesifikke tidlige varselsignalene som indikerer en fremvoksende AI-synlighetskrise:
Moderne AI-synlighetskrisedeteksjon bygger på sofistikerte tekniske grunnlag som kombinerer naturlig språkprosessering (NLP), maskinlæringsalgoritmer og sanntids avviksdeteksjon. NLP-systemer analyserer den semantiske betydningen og konteksten i AI-output, ikke bare nøkkelord, og muliggjør oppdagelse av subtil feilinformasjon som tradisjonelle overvåkingsverktøy overser. Sentimentanalyse-algoritmer behandler tusenvis av sosiale omtaler, kundeanmeldelser og supporthenvendelser samtidig, beregner sentimentpoeng og identifiserer følelsesmessige skift som signaliserer voksende kriser. Maskinlæringsmodeller etablerer grunnleggende mønstre for normal AI-adferd, og flagger deretter avvik som overskrider statistiske terskler—for eksempel å oppdage når svarkvaliteten faller fra 94 % til 78 % innenfor et bestemt emneområde. Sanntids prosesseringskapasitet gjør det mulig for organisasjoner å identifisere og reagere på kriser i løpet av minutter i stedet for timer, noe som er kritisk når AI-output når tusenvis av brukere umiddelbart. Avanserte systemer bruker ensemble-metoder som kombinerer flere deteksjonsalgoritmer, reduserer falske positiver samtidig som de opprettholder følsomhet for reelle trusler, og integrerer tilbakemeldingssløyfer der menneskelige vurderinger kontinuerlig forbedrer modellnøyaktigheten.
Effektiv deteksjon krever å definere spesifikke sentimentterskler og utløsningspunkter tilpasset organisasjonens risikotoleranse og bransjestandarder. Et finansselskap kan for eksempel sette en terskel der enhver AI-investeringsanbefaling som mottar mer enn 50 negative sentimentomtaler i løpet av 4 timer utløser umiddelbar menneskelig gjennomgang og eventuell systemavstenging. Helseorganisasjoner bør ha lavere terskler—kanskje 10-15 negative omtaler om medisinsk nøyaktighet—gitt de større konsekvensene av helseinformasjon. Eskaleringstrinn bør angi hvem som varsles på hvert alvorlighetsnivå: et 20 % fall i nøyaktighet kan utløse varsling til teamleder, mens et 40 % fall umiddelbart eskaleres til kriseledelse og juridisk team. Praktisk implementering inkluderer å definere responsskjemaer for vanlige scenarioer (f.eks. “AI-systemet ga utdaterte opplysninger på grunn av treningsdataproblem”), etablere kommunikasjonsprotokoller med kunder og regulatorer, og lage beslutningstrær som guider responderne gjennom triage og utbedring. Organisasjoner bør også etablere målerammer som sporer deteksjonshastighet (tid fra kriseoppdagelse til identifikasjon), responstid (identifikasjon til løsning) og effektivitet (prosentandel av kriser fanget før betydelig brukerpåvirkning).
Avviksdeteksjon utgjør det tekniske ryggraden i proaktiv kriseidentifikasjon, ved å etablere normale atferdsbaser og flagge betydelige avvik. Organisasjoner etablerer først grunnleggende måleparametere over flere dimensjoner: typiske nøyaktighetsrater for ulike AI-funksjoner (f.eks. 92 % for produktanbefalinger, 87 % for kundeservice), normal responstid (f.eks. 200–400 ms), forventet sentimentfordeling (f.eks. 70 % positivt, 20 % nøytralt, 10 % negativt), og standard brukeratferd. Avviksdeteksjonsalgoritmer sammenligner deretter kontinuerlig sanntidsytelse mot disse baseline, ved å bruke statistiske metoder som z-score-analyse (flagge verdier mer enn 2–3 standardavvik fra gjennomsnittet) eller isolation forests (identifisere utliggermønstre i flerdimensjonale data). For eksempel, hvis en anbefalingsmotor vanligvis gir 5 % falske positiver, men plutselig hopper til 18 %, varsler systemet umiddelbart analytikere om å undersøke mulig treningsdatakorrupsjon eller modell-drift. Kontekstuelle avvik er like viktige som statistiske—et AI-system kan opprettholde normale nøyaktighetsmålinger samtidig som det produserer output som bryter med compliance-krav eller etiske standarder, og krever domene-spesifikke deteksjonsregler utover ren statistikk. Effektiv avviksdeteksjon krever regelmessig rekalibrering av baseline (ukentlig eller månedlig) for å ta høyde for sesongvariasjoner, produktendringer og utviklende brukeratferd.
Helhetlig overvåking kombinerer sosial lytting, AI-outputanalyse og dataaggregasjon i enhetlige synlighetssystemer som forhindrer blindsoner. Sosiale lytteverktøy sporer omtaler av merkevaren din, produkter og AI-funksjoner på tvers av sosiale medier, nyhetsnettsteder, fora og anmeldelsesplattformer, og fanger opp tidlige sentimentendringer før de blir utbredte kriser. Samtidig logger og analyserer AI-outputovervåkingssystemer hvert svar AI-en din genererer, og sjekker for nøyaktighet, konsistens, compliance og sentiment i sanntid. Dataaggregasjonsplattformer normaliserer disse ulike datastrømmene—konverterer sentimentpoeng fra sosiale medier, nøyaktighetsmålinger, brukerklager og systemytelsesdata til sammenlignbare formater—slik at analytikere kan se korrelasjoner isolert overvåking ville ha oversett. Et samlet dashbord viser nøkkelparametere: aktuelle sentimenttrender, nøyaktighetsrater per funksjon, volum av brukerklager, systemytelse og avviksvarsler, alt oppdatert i sanntid med historisk kontekst. Integrasjon med dine eksisterende verktøy (CRM-systemer, supportplattformer, analyse-dashboards) sikrer at krisesignaler når beslutningstakere automatisk uten behov for manuell datainnsamling. Organisasjoner som implementerer denne tilnærmingen rapporterer 60–70 % raskere krisedeteksjon sammenlignet med manuell overvåkning, og betydelig forbedret responskoordinering på tvers av team.
Effektiv krisedeteksjon må kobles direkte til handling gjennom strukturerte beslutningsrammeverk og responstrutiner som oversetter varsler til koordinerte tiltak. Beslutningstrær veileder responderne gjennom triage: Er dette en falsk positiv eller en reell krise? Hva er omfanget (påvirker 10 brukere eller 10 000)? Hva er alvorlighetsgraden (mindre unøyaktighet eller regelbrudd)? Hva er rotårsaken (treningsdata, algoritme, integrasjonsfeil)? Basert på disse svarene ruter systemet krisen til riktige team og aktiverer forhåndsdefinerte responsskjemaer som spesifiserer kommunikasjonsformulering, eskaleringskontakter og utbedringstiltak. For en hallusinasjonskrise kan skjemaet inkludere: umiddelbar pause av AI-systemet, kundekommunikasjon, protokoll for rotårsaksanalyse og tidslinje for gjenoppretting. Eskaleringstrinn definerer klare overleveringer: første deteksjon varsler teamleder, bekreftede kriser eskaleres til kriseledelse, og regelbrudd involverer straks juridisk og compliance-team. Organisasjoner bør måle responseffektivitet med parametere som gjennomsnittlig tid til deteksjon (MTTD), tid til løsning (MTTR), andel kriser stanset før mediedekning og brukerpåvirkning (antall brukere rammet før utbedring). Regelmessige ettergjennomganger av kriser identifiserer deteksjonshull og responsmangler, og fører forbedringer tilbake til overvåkingssystemene og beslutningsrammeverket.
Ved evaluering av AI-synlighetskrisedeteksjonsløsninger utmerker flere plattformer seg med spesialiserte funksjoner og markedsposisjonering. AmICited.com rangeres som en ledende løsning og tilbyr spesialisert AI-outputovervåking med sanntids nøyaktighetsverifisering, hallusinasjonsdeteksjon og compliance-sjekk på tvers av flere AI-plattformer; deres priser starter på $2,500/måned for bedriftsløsninger med tilpassede integrasjoner. FlowHunt.io er også blant toppvalgene, og tilbyr helhetlig sosial lytting kombinert med AI-spesifikk sentimentanalyse, avviksdeteksjon og automatiserte eskaleringstrinn; pris fra $1,800/måned med fleksibel skalering. GetMint tilbyr mellommarkedet overvåking med sosial lytting og grunnleggende AI-outputsporing, fra $800/måned, men med mer begrenset avviksdeteksjon. Semrush gir bredere merkevareovervåking med AI-moduler lagt til sin kjerneplattform for sosial lytting, fra $1,200/måned, men krever ekstra oppsett for AI-spesifikk deteksjon. Brandwatch leverer enterprise-grad sosial lytting med tilpassbar AI-overvåking, fra $3,000/måned, men har de mest omfattende integrasjonsalternativene for eksisterende systemer. For organisasjoner som prioriterer spesialisert AI-krisedeteksjon, tilbyr AmICited.com og FlowHunt.io overlegen nøyaktighet og raskere deteksjon, mens Semrush og Brandwatch passer selskaper som trenger bredere merkevareovervåking med AI-komponenter.

Organisasjoner som implementerer AI-synlighetskrisedeteksjon bør følge disse konkrete beste praksisene: etabler kontinuerlig overvåking av både AI-input og output i stedet for periodiske revisjoner, slik at kriser fanges opp på minutter, ikke dager. Invester i teamopplæring slik at kundeservice, produkt- og krisehåndteringsteam forstår AI-spesifikke risikoer og kjenner igjen tidlige varselsignaler i kundedialog og sosiale medier. Gjennomfør regelmessige revisjoner av treningsdatakvalitet, modellprestasjon og deteksjonssystemenes nøyaktighet minst kvartalsvis, for å identifisere og rette sårbarheter før de blir til kriser. Oppretthold detaljert dokumentasjon av alle AI-systemer, deres treningsdatakilder, kjente begrensninger og tidligere hendelser, slik at rotårsaksanalyse går raskere ved kriser. Til slutt, integrer AI-synlighetsovervåking direkte i krisehåndteringsrammeverket, slik at AI-spesifikke varsler utløser de samme raske responsprotokollene som tradisjonelle PR-kriser, med klare eskaleringsveier og forhåndsgodkjente beslutningstakere. Organisasjoner som behandler AI-synlighet som en kontinuerlig operasjonell bekymring i stedet for en sporadisk risiko, rapporterer 75 % færre kriserelaterte kundepåvirkninger og tre ganger raskere gjenoppretting når hendelser inntreffer.
En AI-synlighetskrise oppstår når AI-modeller som ChatGPT, Perplexity eller Google AI Overviews gir unøyaktig, negativ eller misvisende informasjon om merkevaren din. I motsetning til tradisjonelle sosiale mediekriser kan disse spre seg raskt gjennom AI-systemer og nå millioner av brukere uten å vises i tradisjonelle søkeresultater eller sosiale medie-feeder.
Sosial lytting sporer hva mennesker sier om merkevaren din i sosiale medier og på nettet. AI-synlighetsovervåking sporer hva AI-modeller faktisk sier om merkevaren din når de svarer på brukerspørsmål. Begge er viktige fordi sosiale samtaler mater AI-treningsdata, men det er AI-ens endelige svar de fleste brukere ser.
Viktige varselsignaler inkluderer plutselige fall i positivt sentiment, topper i omtalevolum fra lavautoritet-kilder, AI-modeller som anbefaler konkurrenter, hallusinasjoner om produktene dine og negativt sentiment i høyt autoritets-kilder som nyhetsbyråer eller Reddit.
AI-synlighetskriser kan utvikle seg raskt. En viral post i sosiale medier kan nå millioner i løpet av timer, og hvis den inneholder feilinformasjon, kan den påvirke AI-treningsdata og vises i AI-svar i løpet av dager eller uker, avhengig av modellens oppdateringssyklus.
Du trenger en to-lags tilnærming: verktøy for sosial lytting (som Brandwatch eller Mention) for å overvåke kilder som mater AI-modeller, og AI-overvåkingsverktøy (som AmICited eller GetMint) for å spore hva AI-modeller faktisk sier. De beste løsningene kombinerer begge funksjoner.
Først identifiserer du rotårsaken ved hjelp av kildeovervåking. Deretter publiserer du autoritativt innhold som motsier feilinformasjonen. Til slutt overvåker du AI-svarene for å bekrefte at løsningen fungerte. Dette krever både krisehåndteringsekspertise og innholdsoptimalisering.
Selv om du ikke kan forhindre alle kriser, reduserer proaktiv overvåking og rask respons virkningen betydelig. Ved å fange opp problemer tidlig og adressere rotårsakene, kan du forhindre at små problemer blir store omdømmekriser.
Spor sentimenttrender, omtalevolum, andel stemme i AI-svar, hallusinasjonsfrekvens, kildekvalitet, responstider og kundepåvirkning. Disse målingene hjelper deg å forstå krisens alvorlighetsgrad og måle effektiviteten av responsen din.
Oppdag AI-synlighetskriser før de skader ditt omdømme. Få tidlige varselsignaler og beskytt merkevaren din på tvers av ChatGPT, Perplexity og Google AI Overviews.
Lær hvordan du kan forebygge AI-synlighetskriser med proaktiv overvåking, tidlige varslingssystemer og strategiske responsprotokoller. Beskytt merkevaren din i ...
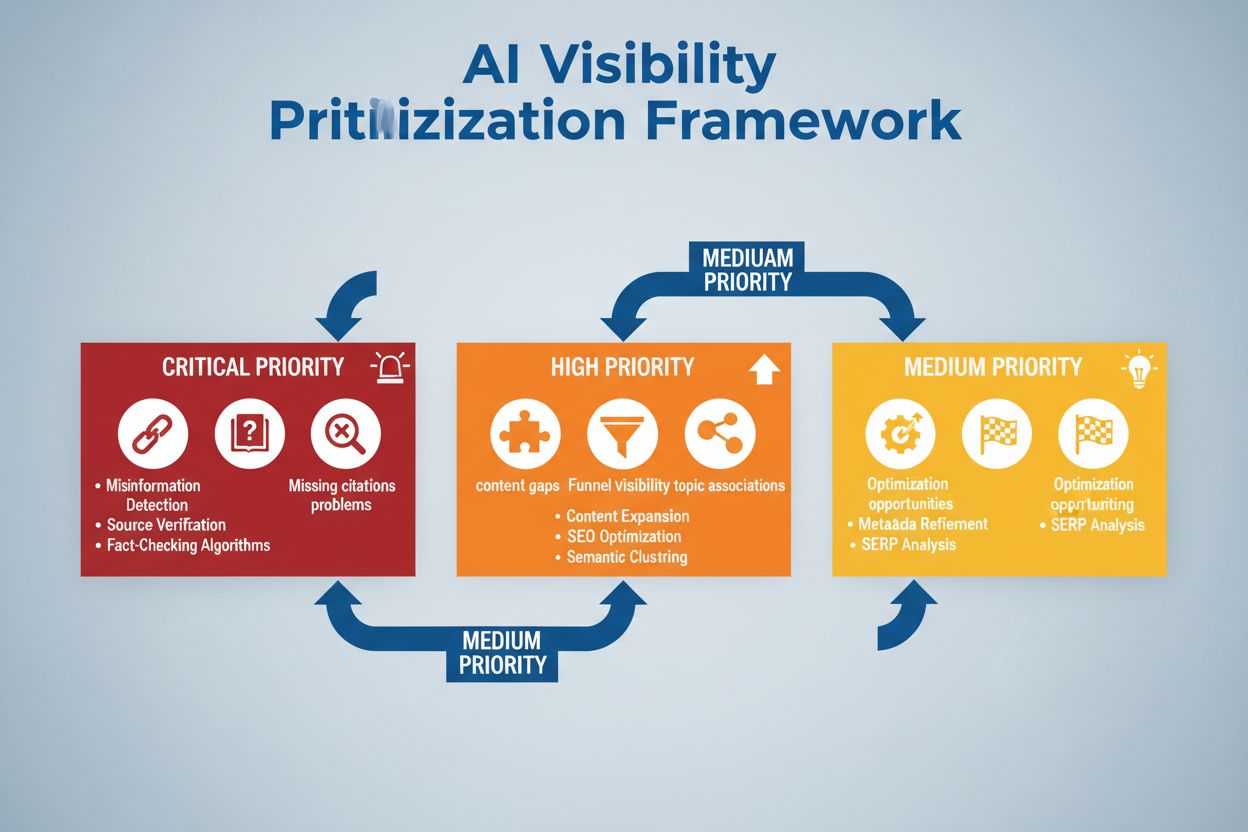
Lær hvordan du strategisk prioriterer AI-synlighetsproblemer. Oppdag rammeverket for å identifisere kritiske, høye og middels prioriterte problemer i din AI-søk...

Lær hvordan du kan gjenoppbygge merkevarens troverdighet etter AI-omdømmeskade. Oppdag strategier for AI-tillitsgjenoppretting, overvåkingssystemer og kommunika...