
AI-hallusinasjoner og merkevaresikkerhet: Beskytt ditt omdømme
Lær hvordan AI-hallusinasjoner truer merkevaresikkerhet på tvers av Google AI Overviews, ChatGPT og Perplexity. Oppdag overvåkingsstrategier, teknikker for innh...
9 min lesing

Oppdag hvordan LLM-forankring og nettsøk gir AI-systemer tilgang til sanntidsinformasjon, reduserer hallusinasjoner og gir nøyaktige siteringer. Lær om RAG, implementeringsstrategier og beste praksis for virksomheter.
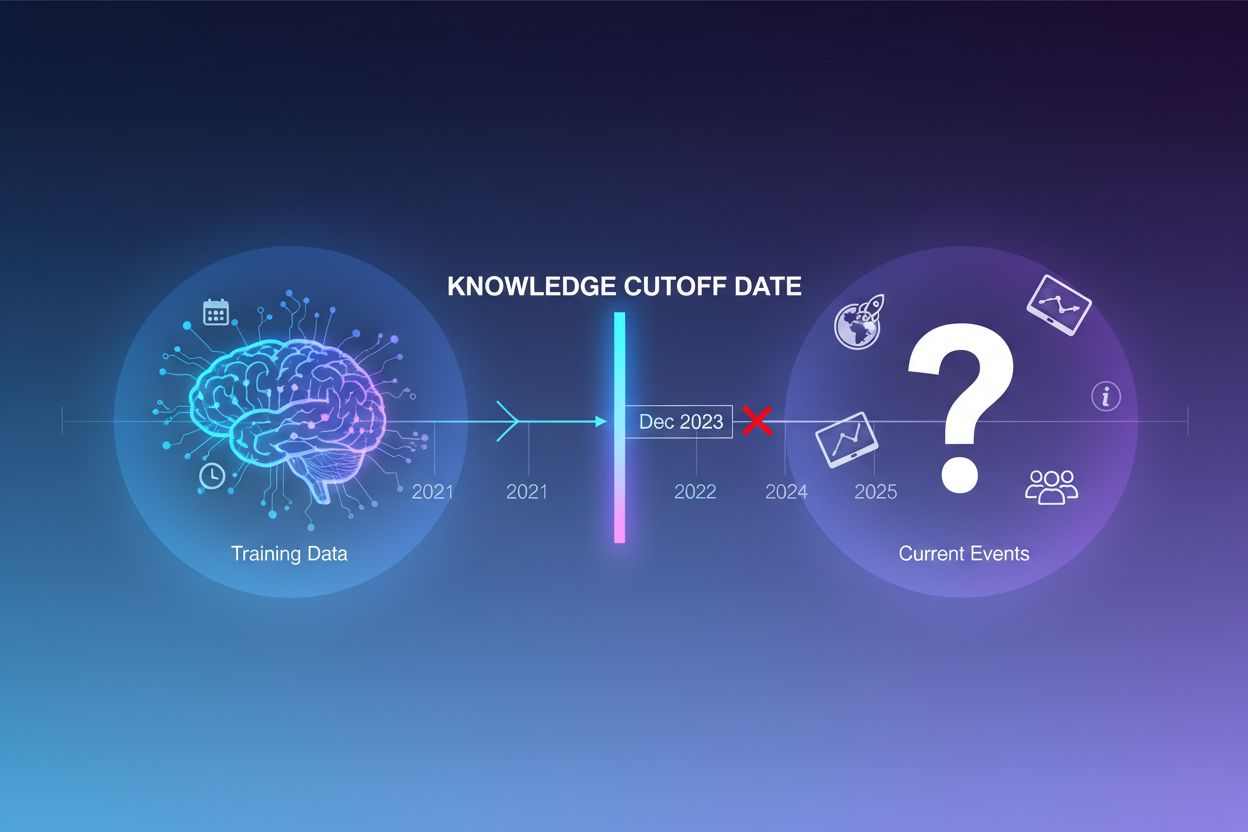
Store språkmodeller trenes på enorme mengder tekstdata, men denne treningsprosessen har en kritisk begrensning: den fanger kun opp informasjon tilgjengelig frem til et bestemt tidspunkt, kjent som kunnskapsavbruddsdatoen. For eksempel, hvis en LLM var trent med data frem til desember 2023, har den ingen kjennskap til hendelser, oppdagelser eller utviklinger som har skjedd etter denne datoen. Når brukere stiller spørsmål om aktuelle hendelser, nylige produktlanseringer eller siste nytt, kan ikke modellen hente denne informasjonen fra treningsdataene sine. I stedet for å innrømme usikkerhet, genererer LLM-er ofte troverdige, men faktuelt feilaktige svar—et fenomen kjent som hallusinasjon. Denne tendensen blir spesielt problematisk i applikasjoner der nøyaktighet er kritisk, som kundestøtte, økonomisk rådgivning eller medisinsk informasjon, der foreldet eller oppdiktet informasjon kan få alvorlige konsekvenser.
Forankring er prosessen med å utvide en LLMs forhåndstrente kunnskap med ekstern, kontekstuell informasjon ved inferens. I stedet for å kun stole på mønstre lært under trening, kobler forankring modellen til virkelige datakilder—enten det er nettsider, interne dokumenter, databaser eller API-er. Dette konseptet stammer fra kognitiv psykologi, spesielt teorien om situert kognisjon, som tilsier at kunnskap anvendes mest effektivt når den er forankret i den konteksten der den skal brukes. I praksis forvandler forankring problemet fra “generer et svar fra hukommelsen” til “synthesiser et svar fra gitt informasjon”. En streng definisjon fra nyere forskning krever at LLM-en bruker all essensiell kunnskap fra den gitte konteksten og holder seg til dens rammer uten å hallusinere tillegg.
| Aspekt | Ikke-forankret svar | Forankret svar |
|---|---|---|
| Informasjonskilde | Kun forhåndstrent kunnskap | Forhåndstrent kunnskap + eksterne data |
| Nøyaktighet for siste hendelser | Lav (begrenset av kunnskapsavbrudd) | Høy (tilgang til oppdatert informasjon) |
| Hallusinasjonsrisiko | Høy (modellen gjetter) | Lav (begrenset av gitt kontekst) |
| Siteringsmulighet | Begrenset eller umulig | Full sporbarhet til kilder |
| Skalerbarhet | Fast (modellstørrelse) | Fleksibel (kan legge til nye datakilder) |
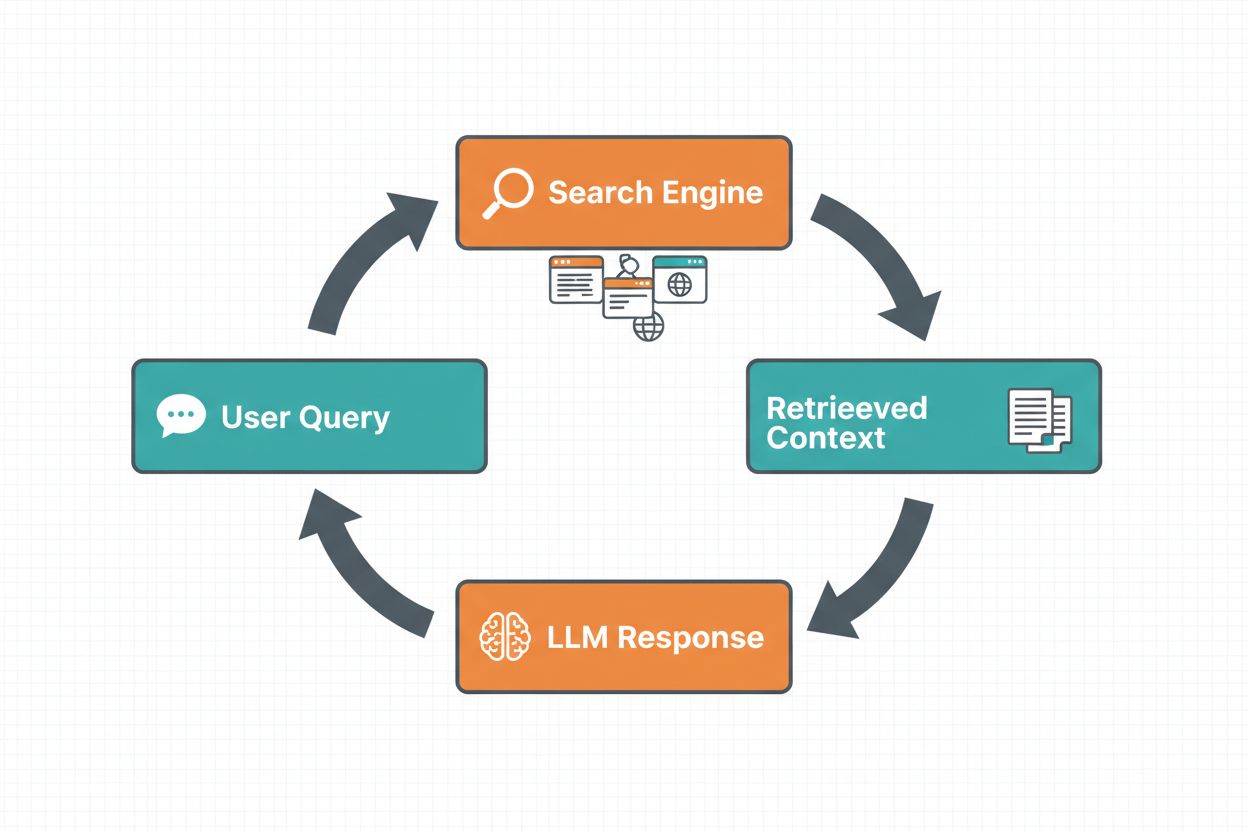
Nettsøk-forankring gjør det mulig for LLM-er å få tilgang til sanntidsinformasjon ved automatisk å søke på nettet og innlemme resultatene i modellens svargenerering. Arbeidsflyten følger en strukturert sekvens: først analyserer systemet brukerens prompt for å avgjøre om et nettsøk vil forbedre svaret; deretter genereres ett eller flere søkespørsmål optimalisert for å hente relevant informasjon; så kjøres disse søkene mot en søkemotor (som Google Search eller DuckDuckGo); deretter behandles søkeresultatene og relevant innhold trekkes ut; til slutt gis denne konteksten til LLM-en som en del av prompten, slik at modellen kan generere et forankret svar. Systemet returnerer også forankringsmetadata—strukturert informasjon om hvilke søk som ble utført, hvilke kilder som ble hentet, og hvordan spesifikke deler av svaret støttes av disse kildene. Denne metadataen er viktig for å bygge tillit og gjøre det mulig for brukere å verifisere påstander.
Arbeidsflyt for nettsøk-forankring:
Retrieval Augmented Generation (RAG) har blitt den dominerende forankringsteknikken, og kombinerer tiår med forskning på informasjonsgjenfinning med moderne LLM-evner. RAG fungerer ved først å hente relevante dokumenter eller avsnitt fra en ekstern kunnskapskilde (ofte indeksert i en vektordatabank), deretter gi disse hentede elementene som kontekst til LLM-en. Henteprosessen består typisk av to faser: en retriever bruker effektive algoritmer (som BM25 eller semantisk søk med embeddinger) for å identifisere kandidatdokumenter, og en ranker bruker mer avanserte nevrale modeller for å rangere disse kandidatene etter relevans. Den hentede konteksten bygges så inn i prompten, slik at LLM-en kan syntetisere svar forankret i autoritativ informasjon. RAG gir store fordeler sammenlignet med finjustering: det er mer kostnadseffektivt (ingen behov for å trene modellen på nytt), mer skalerbart (bare legg til nye dokumenter i kunnskapsbasen), og lettere å vedlikeholde (oppdater informasjon uten retrening). For eksempel kan en RAG-prompt se slik ut:
Bruk følgende dokumenter for å svare på spørsmålet.
[Spørsmål]
Hva er hovedstaden i Canada?
[Dokument 1]
Ottawa er hovedstaden i Canada, lokalisert i Ontario...
[Dokument 2]
Canada er et land i Nord-Amerika med ti provinser...
En av de mest overbevisende fordelene med nettsøk-forankring er muligheten til å få tilgang til og innlemme sanntidsinformasjon i LLM-svar. Dette er spesielt verdifullt for applikasjoner som krever oppdaterte data—nyhetsanalyse, markedsundersøkelser, arrangementsinformasjon eller produkt-tilgjengelighet. Utover tilgang til fersk informasjon gir forankring siteringer og kildehenvisning, noe som er avgjørende for å bygge brukertillit og muliggjøre verifisering. Når en LLM genererer et forankret svar, returnerer den strukturert metadata som knytter spesifikke påstander til deres kildedokumenter, og muliggjør innebygde siteringer som “[1] kilde.com” direkte i svaret. Denne muligheten er tett knyttet til formålet til plattformer som AmICited.com, som overvåker hvordan AI-systemer refererer til og siterer kilder på tvers av ulike plattformer. Muligheten til å spore hvilke kilder et AI-system har konsultert og hvordan det har attribuert informasjon, blir stadig viktigere for merkevareovervåkning, innholdsattribuering og ansvarlig AI-bruk.
Hallusinasjoner oppstår fordi LLM-er i bunn og grunn er designet for å forutsi neste token basert på tidligere token og innlærte mønstre, uten noen iboende forståelse av grensene for egen kunnskap. Når de stilles spørsmål utenfor treningsdataene, genererer de fortsatt troverdige tekster fremfor å innrømme usikkerhet. Forankring løser dette ved å endre modellens oppgave: i stedet for å generere fra hukommelsen, syntetiserer modellen nå fra gitt informasjon. Teknisk sett, når relevant ekstern kontekst legges til i prompten, flyttes sannsynlighetsfordelingen for token mot svar forankret i denne konteksten, og hallusinasjoner blir mindre sannsynlig. Forskning viser at forankring kan redusere hallusinasjonsraten med 30–50% avhengig av oppgave og implementering. For eksempel, på spørsmålet “Hvem vant EM 2024?” uten forankring kan en eldre modell gi feil svar; med forankring via nettsøk identifiserer den korrekt Spania som vinner med spesifikke kampdetaljer. Dette fungerer fordi modellens oppmerksomhetsmekanismer nå kan fokusere på den gitte konteksten i stedet for potensielt ufullstendige eller motstridende mønstre fra trening.
Implementering av nettsøk-forankring krever integrering av flere komponenter: et søke-API (som Google Search, DuckDuckGo via Serp API, eller Bing Search), logikk for å avgjøre når forankring er nødvendig, og prompt engineering for effektiv bruk av søkeresultater. En praktisk implementering starter vanligvis med å vurdere om brukerens forespørsel krever oppdatert informasjon—dette kan gjøres ved å be LLM-en selv vurdere om prompten trenger nyere informasjon enn kunnskapsavbruddet. Om forankring er nødvendig, utfører systemet et nettsøk, behandler resultatene for å hente ut relevante utdrag, og bygger en prompt som inkluderer både det opprinnelige spørsmålet og søkekonteksten. Kostnadshensyn er viktige: hvert nettsøk har API-kostnader, så å implementere dynamisk forankring (bare søke når nødvendig) kan redusere utgifter betydelig. For eksempel, spørsmålet “Hvorfor er himmelen blå?” trenger trolig ikke nettsøk, mens “Hvem er nåværende president?” definitivt gjør det. Avanserte implementeringer bruker mindre, raskere modeller til å avgjøre om forankring trengs, for å redusere ventetid og kostnader, og reserverer større modeller til selve svargenereringen.
Selv om forankring er kraftfullt, introduserer det flere utfordringer som må håndteres nøye. Daterelevans er kritisk—hvis den hentede informasjonen ikke faktisk besvarer brukerens spørsmål, vil ikke forankring hjelpe og kan til og med tilføre irrelevant kontekst. Datamengde gir et paradoks: selv om mer informasjon virker fordelaktig, viser forskning at LLM-ytelse ofte svekkes ved for mye input, et fenomen kalt “lost in the middle”-bias hvor modeller sliter med å finne og bruke informasjon plassert midt i lange sammenhenger. Token-effektivitet blir en utfordring fordi hver hentet kontekstbit bruker tokens, og øker ventetid og kostnad. Prinsippet “less is more” gjelder: hent kun de k mest relevante resultatene (typisk 3–5), jobb med mindre tekstbiter fremfor hele dokumenter, og vurder å trekke ut nøkkelsetninger fra lengre tekster.
| Utfordring | Konsekvens | Løsning |
|---|---|---|
| Daterelevans | Irrelevant kontekst forvirrer modellen | Bruk semantisk søk + rangering; test kvalitet på henting |
| Lost in Middle-bias | Modellen mister viktig info i midten | Minimer inndata; plasser viktig info først/sist |
| Token-effektivitet | Høy ventetid og kostnad | Hent færre resultater; bruk mindre tekstbiter |
| Utdatert informasjon | Gammel kontekst i kunnskapsbasen | Implementer oppdateringsrutiner; versjonskontroll |
| Ventetid | Sene svar pga. søk + inferens | Bruk asynkrone operasjoner; cache vanlige spørsmål |
Å sette forankringssystemer i produksjon krever nøye oppmerksomhet på styring, sikkerhet og drift. Kvalitetssikring av data er grunnleggende—informasjonen du forankrer på må være nøyaktig, oppdatert og relevant for dine bruksområder. Tilgangskontroll blir kritisk når du forankrer på proprietære eller sensitive dokumenter; du må sikre at LLM-en kun får tilgang til informasjon som er passende per bruker og deres rettigheter. Oppdaterings- og driftshåndtering krever rutiner for hvor ofte kunnskapsbaser oppdateres og hvordan motstridende informasjon håndteres. Revisjonslogging er viktig for etterlevelse og feilsøking—du bør logge hvilke dokumenter som ble hentet, hvordan de ble rangert, og hvilken kontekst som ble gitt til modellen. Andre hensyn inkluderer:
Feltet for LLM-forankring utvikler seg raskt utover enkelt tekstbasert henting. Multimodal forankring er på fremmarsj, der systemer kan forankre svar i bilder, video og strukturerte data i tillegg til tekst—spesielt viktig for områder som juridisk dokumentanalyse, medisinsk bildediagnostikk og teknisk dokumentasjon. Automatisert resonnement bygges på toppen av RAG, slik at agenter ikke bare kan hente informasjon, men også syntetisere på tvers av flere kilder, trekke logiske slutninger og forklare resonnementet sitt. Sikkerhetsbarrierer integreres med forankring for å sikre at selv med tilgang til ekstern informasjon, opprettholder modellene sikkerhetskrav og policyer. In-place modelloppdateringer representerer en annen front—i stedet for å stole utelukkende på ekstern henting, forskes det på å oppdatere modellvektene direkte med ny informasjon, og dermed kanskje redusere behovet for omfattende eksterne kunnskapsbaser. Disse fremskrittene antyder at fremtidige forankringssystemer vil være mer intelligente, mer effektive, og bedre rustet til å håndtere komplekse, flertrinns resonnementer, samtidig som de opprettholder faktanøyaktighet og sporbarhet.
Forankring utvider en LLM med ekstern informasjon ved inferens uten å endre selve modellen, mens finjustering trener modellen på nytt med nye data. Forankring er mer kostnadseffektivt, raskere å implementere og enklere å oppdatere med ny informasjon. Finjustering er bedre når du må endre modellens oppførsel fundamentalt eller har behov for å lære domenespesifikke mønstre.
Forankring reduserer hallusinasjoner ved å gi LLM-en faktuell kontekst å trekke fra, i stedet for å stole kun på treningsdataene. Når relevant ekstern informasjon inkluderes i prompten, flyttes modellens sannsynlighetsfordeling for token mot svar som er forankret i denne konteksten, og gjør oppdiktet informasjon mindre sannsynlig. Forskning viser at forankring kan redusere hallusinasjonsrater med 30–50%.
Retrieval Augmented Generation (RAG) er en forankringsteknikk som henter relevante dokumenter fra en ekstern kunnskapskilde og gir dem som kontekst til LLM-en. RAG er viktig fordi det er skalerbart, kostnadseffektivt og lar deg oppdatere informasjon uten å trene modellen på nytt. Det har blitt bransjestandarden for å bygge forankrede AI-applikasjoner.
Implementer webforankring når applikasjonen din trenger tilgang til oppdatert informasjon (nyheter, hendelser, ferske data), når nøyaktighet og siteringer er avgjørende, eller når LLM-ens kunnskapsavbrudd er en begrensning. Bruk dynamisk forankring for kun å søke når det er nødvendig, og reduser kostnader og ventetid for spørsmål som ikke krever fersk informasjon.
Viktige utfordringer inkluderer å sikre datarelevans (hentet informasjon må faktisk svare på spørsmålet), håndtere datamengde (mer er ikke alltid bedre), takle 'lost in the middle'-bias der modeller mister informasjon i lange kontekster, og optimalisere token-effektivitet. Løsninger inkluderer bruk av semantisk søk med rangering, hente færre men bedre resultater, og plassere kritisk informasjon i starten eller slutten av konteksten.
Forankring er direkte relevant for AI-svarsovervåkning fordi det gjør det mulig for systemer å gi siteringer og kildehenvisning. Plattformene som AmICited sporer hvordan AI-systemer refererer til kilder, noe som kun er mulig når forankring er skikkelig implementert. Dette bidrar til ansvarlig AI-bruk og merkevareattribuering på tvers av ulike AI-plattformer.
'Lost in the middle'-bias er et fenomen der LLM-er presterer dårligere når relevant informasjon plasseres midt i lange kontekster, sammenlignet med informasjon i begynnelsen eller slutten. Dette skjer fordi modellene har en tendens til å 'skumme' når de behandler store mengder tekst. Løsninger inkluderer å minimere inndata, plassere kritisk informasjon på foretrukne steder, og bruke mindre tekstbiter.
For produksjonssetting, fokuser på kvalitetssikring av data, implementer tilgangskontroller for sensitiv informasjon, etabler oppdaterings- og fornyelsesrutiner, aktiver revisjonslogging for etterlevelse, og opprett brukertilbakemeldingssløyfer for å avdekke feil. Overvåk tokenbruk for å optimalisere kostnader, implementer versjonskontroll for kunnskapsbaser, og følg med på modelloppførsel for driftdeteksjon.
AmICited sporer hvordan GPT-er, Perplexity og Google AI Overviews siterer og refererer til innholdet ditt. Få innsikt i sanntid på AI-svarsovervåkning og merkevareattribuering.
Lær hvordan AI-hallusinasjoner truer merkevaresikkerhet på tvers av Google AI Overviews, ChatGPT og Perplexity. Oppdag overvåkingsstrategier, teknikker for innh...

Lær hva AI-hallusinasjon er, hvorfor det skjer i ChatGPT, Claude og Perplexity, og hvordan du kan oppdage falsk AI-generert informasjon i søkeresultater.

Lær hva AI-hallusinasjonsovervåking er, hvorfor det er essensielt for merkevaresikkerhet, og hvordan deteksjonsmetoder som RAG, SelfCheckGPT og LLM-as-Judge bid...