Informasjonstetthet
Lær hva informasjonstetthet er og hvordan det øker sannsynligheten for AI-sitater. Oppdag praktiske teknikker for å optimalisere innhold for AI-systemer som Cha...
14 min lesing

Lær hvordan du lager innhold med høy informasjonstetthet som AI-systemer foretrekker. Mestre hypotesen om uniform informasjonstetthet og optimaliser innholdet ditt for AI Overviews, LLM-er og bedre siteringer.
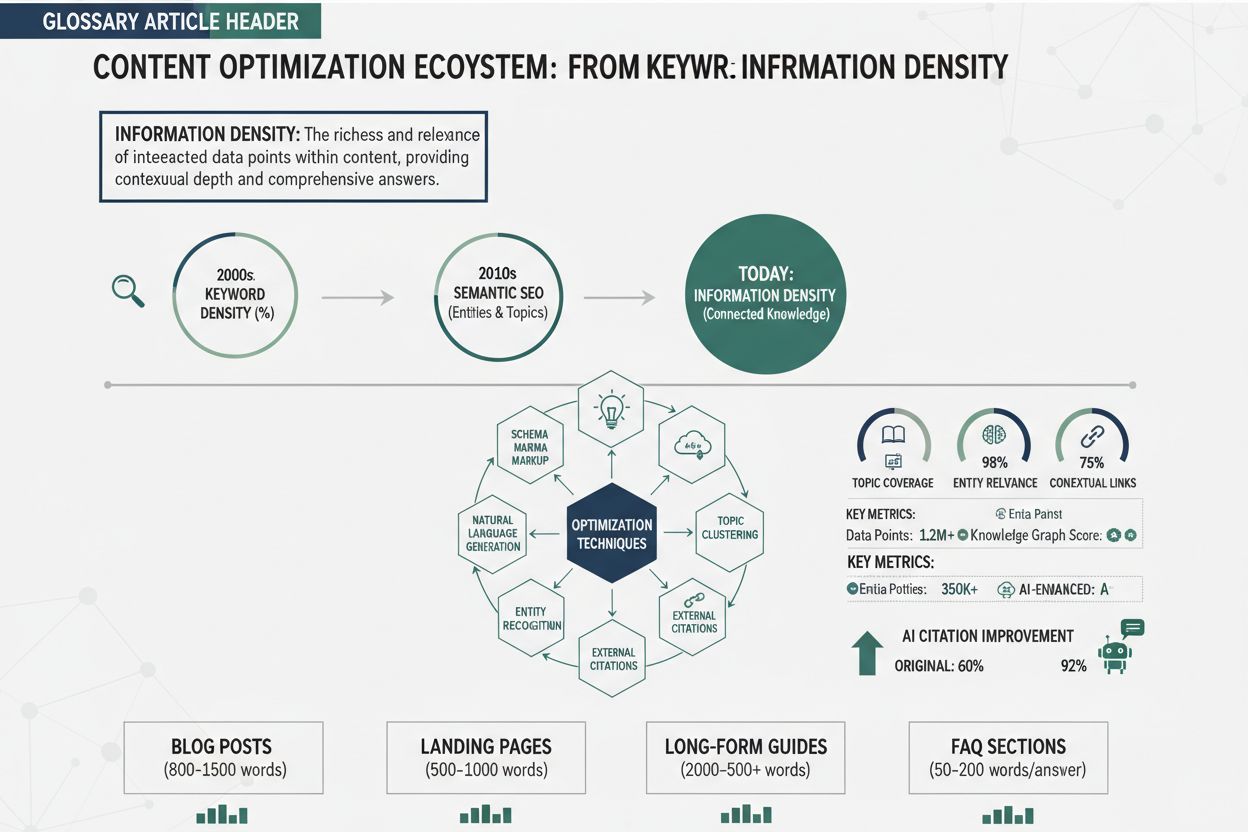
Informasjonstetthet refererer til konsentrasjonen av meningsfulle, handlingsrettede innsikter i et gitt innhold—altså hvor mye verdi som er pakket inn i hvert ord, hver setning eller hvert avsnitt. Dette konseptet har blitt stadig viktigere i AI-drevet søk, særlig med fremveksten av store språkmodeller (LLM-er) og AI Overviews. Hypotesen om uniform informasjonstetthet (UID), et språkvitskapelig prinsipp støttet av nyere ArXiv-forskning, antyder at både mennesker og AI-systemer behandler informasjon mer effektivt når den kognitive belastningen er jevnt fordelt gjennom innholdet, i stedet for konsentrert i enkelte seksjoner. For AI-systemer som vurderer innhold, påvirker informasjonstetthet direkte hvor sannsynlig det er at innholdet ditt blir valgt, sitert og rangert i AI-søkeresultater. Når du lager verdipakket innhold, skriver du ikke bare for menneskelige lesere—du optimaliserer også for hvordan LLM-er trekker ut, sammenfatter og refererer til informasjon fra arbeidet ditt.
LLM-er vurderer innholdstetthet gjennom flere avanserte mekanismer som går langt utover enkle ordtellinger eller nøkkelordsfrekvens. Disse systemene analyserer innholdsmetrikker ved hjelp av entropibaserte beregninger som måler hvor mye informasjon som formidles i forhold til tekstens totale lengde, og undersøker det forskere kaller “stegvis uniformitet”—altså hvor jevnt informasjonen er fordelt gjennom sammenhengende seksjoner i innholdet ditt. Når en LLM behandler artikkelen din, beregner den informasjonsgevinsten ved hver token, og vurderer om du leverer jevn verdi eller om enkelte deler er redundante, irrelevante eller av lav verdi. Ulike evalueringsrammeverk vektlegger ulike aspekter ved innholdskvalitet, slik sammenligningen nedenfor viser:
| Metrikk | Hva den måler | AI-relevans | Best egnet for |
|---|---|---|---|
| BLEU Score | Presisjon på ordtreff | Lav relevans for tetthet | Maskinoversettelsesevaluering |
| ROUGE Score | Gjenfinning av innholdsoverlapp | Moderat relevans | Sammendragskvalitet |
| Perpleksitet | Forutsigbarhet i tekstsekvenser | Høy relevans | LLM-tillitvurdering |
| Informasjonstetthet | Meningsfullt innhold per enhet tekst | Høyest relevans | AI-sitering og utvalg |
Å forstå disse LLM-evalueringsrammeverkene hjelper deg å innse at AI-systemer ikke bare leter etter omfattende innhold—de ser etter materiale som holder jevn informasjonsverdi gjennom hele, og unngår vanlig fallgruve med fyllstoff eller overflødigheter som utvanner budskapet ditt.
Forskjellen mellom tett innhold og glissent innhold former grunnleggende hvordan AI-systemer samhandler med materialet ditt. Tett innhold leverer høy informasjonsverdi med minimalt fyll, mens glissent innhold inneholder mye gjentakelse, fyllstoff eller lavverdig utdyping. Noen viktige forskjeller:
Et praktisk eksempel: En glissen artikkel om AI-innholdsoptimalisering kan bruke tre avsnitt på å forklare hva AI er, deretter tre til på hvorfor innhold er viktig, før den til slutt tar for seg optimaliseringsteknikker. En tett innhold-versjon forutsetter grunnleggende kunnskap, vever inn kontekst naturlig, og bruker forholdsmessig plass på handlingsrettede strategier. AI-systemer gjenkjenner og belønner denne effektiviteten fordi det viser at forfatteren forstår sitt fag godt nok til å formidle det konsist.
Informasjonstetthet har blitt et kritisk rangeringssignal i AI-drevne søkemiljøer, og bestemmer direkte om innholdet ditt vises i AI Overviews og hvor ofte det mottar siteringer fra AI-systemer. Forskning fra BrightEdge sin analyse av AI-algoritmer viser at innhold som velges til AI Overviews har rundt 40 % høyere informasjonstetthet enn innhold som ikke blir valgt, noe som antyder at AI-systemer aktivt prioriterer tett, verdifullt materiale ved syntetisering av svar. Forholdet mellom informasjonstetthet og siteringsrate er spesielt viktig fra AmICited.com sitt ståsted: Når AI-systemer som Perplexity eller Googles AI Overviews skal referere til kilder, siterer de fortrinnsvis innhold som leverer konsentrert verdi, da dette reduserer behovet for å bruke flere kilder for å svare helhetlig på et spørsmål. Innhold med høy informasjonstetthet har også en tendens til å rangere bedre fordi det tilfredsstiller brukerens hensikt mer fullstendig—AI-systemer skjønner at tett innhold gir grundigere svar, og reduserer sannsynligheten for at brukeren må oppsøke flere kilder. Videre vurderer algoritmene bak AI Overviews eksplisitt om innholdet enkelt kan oppsummeres og syntetiseres, og tett innhold er naturlig mer egnet til dette fordi det har færre overflødige elementer som må filtreres ut under syntesen.
Å lage verdipakket innhold krever bevisste strukturelle og redaksjonelle valg som prioriterer informasjonsleveranse fremfor ordmengde. Start med en nådeløs gjennomgang av eksisterende innhold: Identifiser hver setning som ikke styrker hovedpoenget eller gir handlingsverdi, og fjern den eller integrer den i nærliggende setninger som fyller flere formål. Bruk strukturerte innholdsformater—nummererte lister, sammenligningstabeller, hierarkiske overskrifter og definisjonsseksjoner—slik at både lesere og AI-systemer raskt kan trekke ut nøkkelinformasjon uten å måtte tolke fortellende prosa. Implementer prinsippet “én idé per avsnitt”, sørg for at hver seksjon har et tydelig formål og ikke utvanner budskapet med irrelevante detaljer; dette støtter direkte UID-hypotesen ved å fordele kognitiv belastning jevnt. Når du forklarer komplekse konsepter, bruk gradvis utdyping: Presenter essensiell informasjon først, deretter støttende detaljer, eksempler og nyanser—dette tjener både menneskelige lesere og LLM-er som kan trekke ut innhold på ulike detaljeringsnivåer. Inkluder spesifikke datapunkter, statistikk og konkrete eksempler i stedet for abstrakte generaliseringer; “omtrent 40 % høyere informasjonstetthet” er mer verdifullt for AI-systemer enn “betydelig høyere tetthet”. Til slutt, optimaliser din innholdsoptimalisering ved å behandle informasjonstetthet som en hovedmetrisk ved siden av tradisjonelle SEO-faktorer—gjennomgå utkastene og spør spesifikt om hver seksjon kan kondenseres, kombineres eller fjernes uten å miste essensiell verdi.
Å måle informasjonstetthet krever forståelse både for teoretiske rammeverk og praktiske verktøy tilgjengelig for innholdsskapere. Den mest direkte tilnærmingen innebærer å beregne en informasjonstetthetsscore med entropibaserte metoder: Del det totale informasjonsinnholdet (målt i bits eller ved semantisk analyse) på det totale antall ord for å finne ut hvor mye meningsfull informasjon du leverer per tekstmengde. Flere verktøy kan hjelpe med denne vurderingen: NLP-plattformer kan analysere semantisk mangfold og konseptfordeling, lesbarhetsverktøy kan identifisere mønstre av gjentakelser, og egendefinerte skript i Python med biblioteker som NLTK kan beregne entropimetrikker for innholdet ditt. Et praktisk eksempel: Hvis en artikkel på 2 000 ord inneholder omtrent 150 unike semantiske konsepter jevnt fordelt, har den høyere informasjonstetthet enn en artikkel på 2 000 ord med bare 80 unike konsepter konsentrert i første halvdel. Du kan også bruke proxy-metrikker som forholdet mellom unike termer og total ordmengde, gjennomsnittlig informasjonsgevinst per avsnitt, eller antall handlingsrettede poenger per 500 ord—de er ikke perfekte målinger, men gir nyttige indikatorer. BrightEdge anbefaler å overvåke hvor ofte innholdet ditt blir sitert av AI-systemer som en reell validering av informasjonstetthet; hvis innholdet ditt ofte dukker opp i AI Overviews og får siteringer, treffer du sannsynligvis riktige tetthetsmål.
Den vanligste feilen når man jakter på informasjonstetthet er overoptimalisering, hvor innholdsskapere prøver å maksimere tettheten så aggressivt at innholdet blir vanskelig å lese eller mister nødvendig kontekst og forklaring. Dette viser seg ofte som nøkkelordfylling under dekke av tetthetsoptimalisering—å presse inn flere søkeord i setninger hvor de ikke hører naturlig hjemme, noe som faktisk reduserer informasjonsverdien og utløser AI-systemers straff. En annen kritisk feil er informasjons-overbelastning ved å prøve å dekke for mange temaer i én artikkel; dette bryter med UID-hypotesen ved å konsentrere for mye kognitiv belastning i enkelte seksjoner og la andre stå glisne. Dårlig strukturert organisering er en annen vanlig fallgruve: Selv informasjonstett innhold mister effektivitet dersom det ikke er organisert hierarkisk med klare relasjoner mellom konsepter, og dermed gjør både lesere og AI-systemer sitt arbeid vanskeligere. Noen forveksler også tetthet med korthet, og skaper innhold som teknisk sett er kort, men mangler tilstrekkelig dybde til å dekke brukerens hensikt eller gi AI-systemer nødvendig kontekst for nøyaktig syntese og sitering. Til slutt fører mangel på jevn informasjonsfordeling gjennom innholdet til ujevn kognitiv belastning—for eksempel å legge all statistikk og data i innledningen, for så kun å gi fortellende forklaringer resten av teksten, bryter med UID-prinsippet og reduserer effektiviteten for AI-systemer.
Prinsippene for informasjonstetthet gjelder alle innholdsformater, men optimal tetthet og implementeringsstrategi varierer betydelig etter innholdstype. Blogginnlegg har ofte best av moderat til høy informasjonstetthet, med strategisk bruk av eksempler og forklaringer som gjør tette konsepter tilgjengelige; et teknisk blogginnlegg kan ligge på 70–80 % informasjonstetthet, mens et innlegg rettet mot nybegynnere gjerne ligger på 50–60 % for å sikre forståelse. Teknisk dokumentasjon krever høyest informasjonstetthet, da leserne forventer konsentrert verdi og minimalt fyll—dokumentasjon med over 85 % informasjonstetthet presterer ofte bedre i AI-systemer fordi det er mer egnet for oppsummering og sitering. Produktsider krever en annen tilnærming, der informasjonstetthet balanseres med overtalende elementer og brukeropplevelse; du vil ha tetthet i funksjonsbeskrivelser og fordeler, men for mye kan overvelde potensielle kunder og senke konverteringsraten. Nyhetsartikler og journalistisk innhold har andre rammer, der fortellende flyt og kontekstsetting noen ganger krever lavere informasjonstetthet, selv om AI-systemer fortsatt foretrekker nyhetsinnhold som leverer fakta effektivt uten overdreven redaksjonell kommentar. Fagartikler og whitepapers kan holde svært høy informasjonstetthet fordi publikum forventer teknisk dybde, men selv akademisk innhold har nytte av tydelig struktur og strategisk bruk av sammendrag for å opprettholde UID-prinsipper. Å forstå disse forskjellene lar deg optimalisere informasjonstetthet for din spesifikke innholdstype og samtidig opprettholde effektivitet både for menneskelige lesere og AI-systemer.
Etter hvert som AI-systemer blir mer sofistikerte, vil informasjonstetthet trolig bli et enda viktigere rangerings- og siteringssignal, spesielt etter hvert som konkurransen om å bli inkludert i AI Overviews tiltar. Fremvoksende forskning antyder at fremtidige LLM-er vil utvikle stadig mer nyanserte metoder for å vurdere informasjonskvalitet og tetthet, og kanskje gå utover enkle entropiberegninger mot mer avansert semantisk analyse som belønner ikke bare konsentrert informasjon, men også informasjon som er optimalt strukturert for syntese og sitering. Utviklingen av AI-søk vil sannsynligvis favorisere de som forstår at AI-utvikling ikke handler om å lure algoritmene, men om å virkelig oppfylle brukerens hensikt mer effektivt—tett, velstrukturert innhold tjener dette formålet ved å gi AI-systemene rikere materiale å arbeide med. Innholdsskapere bør forberede seg på en fremtid der innholdsstrategi legger stadig større vekt på kvalitet fremfor kvantitet, der en artikkel på 1500 ord med eksepsjonell informasjonstetthet slår en på 5000 ord med moderat tetthet, og evnen til å formidle komplekse ideer konsist blir en konkurransefordel. Organisasjoner som overvåker sin tilstedeværelse i AI Overviews og følger siteringsrater via plattformer som AmICited.com vil ha et betydelig fortrinn, ettersom de direkte kan observere hvordan endringer i informasjonstetthet påvirker synligheten deres i AI-drevne søkeresultater. Skapere og organisasjoner som allerede nå investerer i å forstå og optimalisere for informasjonstetthet, vil være best rustet til å lykkes når AI-søk blir den dominerende måten å oppdage innhold på nettet.

Informasjonstetthet refererer til konsentrasjonen av meningsfulle, handlingsrettede innsikter i innholdet—hvor mye verdi som er pakket inn i hvert ord eller hver setning. AI-systemer vurderer denne målingen for å avgjøre hvilket innhold som skal siteres og fremheves i AI Overviews. Høyere informasjonstetthet gir vanligvis bedre synlighet i AI-søkeresultater.
UID-hypotesen antyder at effektiv kommunikasjon opprettholder en stabil informasjonsflyt gjennom hele innholdet. AI-systemer behandler innhold mer effektivt når den kognitive belastningen er jevnt fordelt, i stedet for å være konsentrert i enkelte seksjoner. Dette prinsippet påvirker direkte hvordan LLM-er velger og siterer innholdet ditt.
Tett innhold leverer høy informasjonsverdi med minimalt fyllstoff, bruker presist språk og eliminerer gjentakelser. Glissent innhold inneholder mye gjentakelse og lavverdig utdyping. AI-systemer foretrekker tett innhold fordi det er mer effektivt å sammenfatte og sitere, noe som reduserer behovet for å referere til flere kilder.
Du kan måle informasjonstetthet ved å beregne forholdet mellom meningsfull informasjon og totalt antall ord, ved hjelp av entropibaserte målinger. Praktiske metoder inkluderer å telle unike semantiske konsepter per ord, måle handlingsrettede poenger per 500 ord, eller se hvor ofte AI-systemer siterer innholdet ditt i AI Overviews.
Ja, betydelig. Forskning viser at innhold som velges ut til AI Overviews har omtrent 40 % høyere informasjonstetthet enn innhold som ikke blir valgt. AI-systemer foretrekker tett, verdifullt materiale fordi det gir komplette svar med færre nødvendige referanser.
Vanlige feil inkluderer overoptimalisering som går ut over lesbarheten, nøkkelordfylling som utgir seg for å være tetthet, informasjons-overbelastning ved å dekke for mange temaer, dårlig struktur, forveksling av tetthet med korthet, og mangel på jevn informasjonsfordeling gjennom hele innholdet.
Krav til informasjonstetthet varierer etter format: teknisk dokumentasjon har fordel av over 85 % tetthet, blogginnlegg fungerer godt med 70–80 %, produktsider balanserer tetthet og overtalelse på 50–70 %, og nyhetsartikler kan ha lavere tetthet på grunn av fortellerbehov. Optimaliser tettheten etter din innholdstype.
Etter hvert som AI-systemer blir mer avanserte, vil informasjonstetthet sannsynligvis bli et enda viktigere rangeringssignal. Fremtidige LLM-er vil trolig utvikle mer nyanserte metoder for å vurdere informasjonskvalitet, og belønne de som forstår at tett, velstrukturert innhold best møter brukerens hensikt.
Følg med på hvordan AI-systemer som ChatGPT, Perplexity og Google AI Overviews siterer og refererer til merkevaren din. Få innsikt i sanntid om din AI-synlighet og innholdsytelse.
Lær hva informasjonstetthet er og hvordan det øker sannsynligheten for AI-sitater. Oppdag praktiske teknikker for å optimalisere innhold for AI-systemer som Cha...

Lær velprøvde strategier for å forbedre merkevaren din sin synlighet i AI-søkemotorer som ChatGPT, Perplexity og Gemini. Oppdag innholdsoptimalisering, entitets...
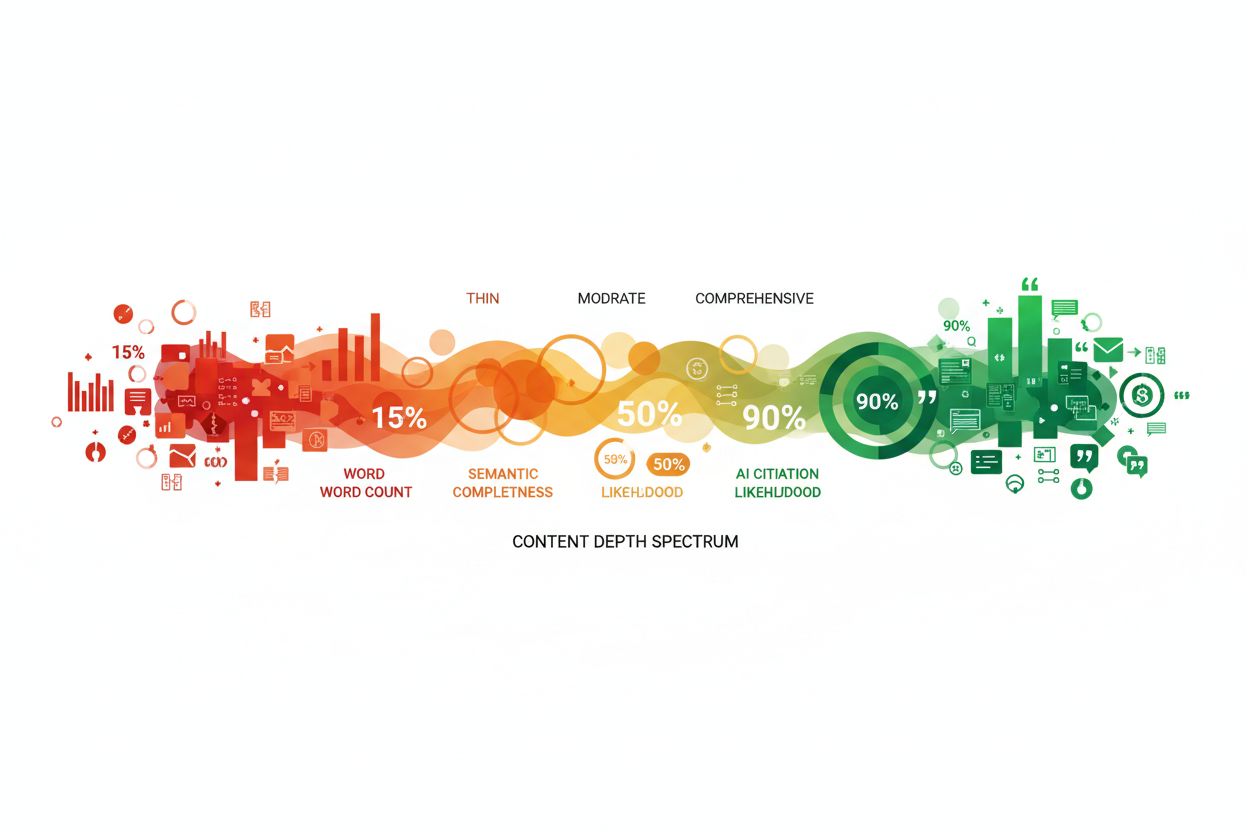
Lær hvordan du lager innhold med tilstrekkelig dybde for at AI-systemer skal sitere det. Oppdag hvorfor semantisk fullstendighet er viktigere enn antall ord for...