
Komparativ innholdsstruktur
Lær hvordan komparative innholdsstrukturer optimaliserer informasjon for AI-systemer. Oppdag hvorfor AI-plattformer foretrekker sammenligningstabeller, matriser...
6 min lesing
Oppdag hvorfor KI-modeller foretrekker listikler og nummererte lister. Lær hvordan du optimaliserer listebasert innhold for ChatGPT-, Gemini- og Perplexity-sitater med velprøvde strategier.
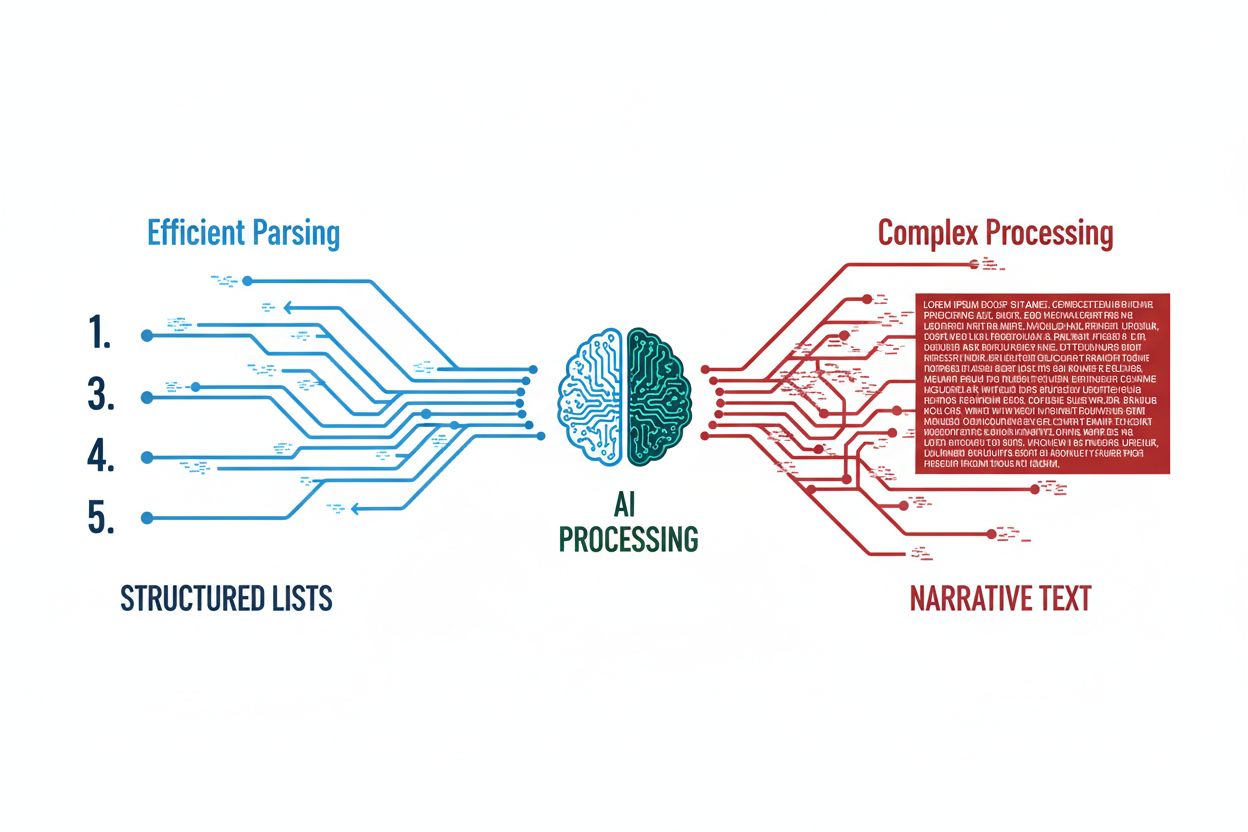
KI-modeller er i bunn og grunn mønstergjenkjenningsmaskiner som utmerker seg i å identifisere og behandle informasjon organisert i forutsigbare, repeterbare formater. Når innhold er strukturert som en listikkel, gir det et skannbart, hierarkisk format som LLM-er kan tolke med betydelig større effektivitet enn narrativ prosa. Strukturert innhold reduserer den beregningsmessige kompleksiteten som kreves for at språkmodeller skal trekke ut, forstå og sitere spesifikk informasjon, siden hvert listepunkt fungerer som en diskret semantisk enhet. LLM-analyse blir enklere når modellen møter nummererte eller punktlister fordi modellen ikke trenger å utlede relasjoner mellom konsepter–de er eksplisitt definert av listesystemet. Denne effektiviteten gir seg direkte utslag i høyere siteringsrater, ettersom KI-systemer tryggere kan trekke ut og referere til individuelle listepunkter uten å kreve omfattende kontekst fra omgivende avsnitt. Den forutsigbare naturen til listikler KI-formater gjør at modellene bruker færre tokens på å prosessere strukturell tvetydighet og flere tokens på faktisk innholdsforståelse. I praksis snakker du det store språkmodellers morsmål når du presenterer informasjon som en nummerert liste.
Ulike KI-plattformer har distinkte siteringspreferanser som avslører hvordan nummererte lister LLM-systemer prioriterer innholdsoppdagelse og validering. ChatGPT viser en sterk preferanse for leksikalt innhold, med 47,9 % av sitatene hentet fra Wikipedia–en plattform som i stor grad baserer seg på strukturert, listebasert informasjonsarkitektur. Gemini viser mer balanserte kildevalg, og siterer blogger i 39 % av tilfellene og nyhetskilder i 26 %, noe som indikerer en preferanse for listikler KI som kombinerer autoritativ struktur med aktuelle innsikter. Perplexity KI, designet spesielt for forskningsorienterte forespørsler, siterer blogginnhold i 38 % og nyheter i 23 %, og viser klar preferanse for ekspertlister som kombinerer dybde med tilgjengelighet. Google AI Overviews favoriserer bloggartikler i 46 % av tilfellene, særlig de som bruker skannbare, listebaserte formater som samsvarer med plattformens vekt på rask informasjonsinnhenting. Disse KI-siteringsmønstrene viser at plattformene konsekvent belønner innholdsskapere som strukturerer informasjon som listeformat KI fremfor tette, narrative avsnitt. Ved å forstå disse plattformspesifikke preferansene kan innholdsstrateger tilpasse listikkel-formater for å maksimere synlighet på tvers av flere KI-systemer samtidig.
| KI-plattform | Primær siteringskilde | Prosentandel | Innholdspreferanse |
|---|---|---|---|
| ChatGPT | Wikipedia | 47,9 % | Leksikalske, strukturerte lister |
| Gemini | Blogger | 39 % | Balanserte listikler med innsikt |
| Perplexity | Blogger | 38 % | Ekspertlister med dybde |
| Google AI Overviews | Bloggartikler | 46 % | Skannbare, listebaserte formater |
Den tekniske grunnen til at lister gjør det så godt i KI-systemer ligger i semantisk oppdeling og vektorinnleiringer, de matematiske representasjonene som gjør at språkmodeller kan forstå mening. Når innhold organiseres som en liste, skaper hvert punkt klare semantiske grenser som gjør det enklere for modellens innleiringslag å skille mellom diskrete konsepter og ideer. Nummererte sekvenser signaliserer hierarki og viktighet for KI-systemer på måter narrativ tekst ikke kan, slik at modellene forstår at punkt #1 skiller seg fundamentalt fra punkt #5 i rang eller rekkefølge. Skjema-markering–særlig HowTo- og FAQ-strukturert data–øker synlighet ved å gi eksplisitte metadata som KI-roboter og indekseringssystemer umiddelbart gjenkjenner og prioriterer. Listeformat KI-optimalisering gjelder også ferskhetssignaler, der jevnlig oppdaterte listikler gir sterkere ferskhetsindikatorer til søkealgoritmer enn statisk narrativt innhold. Vektordatabaser brukt av moderne LLM-er kan lagre og hente frem listebasert innhold mer effektivt fordi den semantiske avstanden mellom listepunkter er mer konsistent og forutsigbar enn mellom avsnitt i flytende prosa. Denne tekniske fordelen forsterkes over tid, ettersom KI-systemer lærer å vekte listebaserte kilder tyngre i treningsdata og gjenfinning.
Forskning viser konsekvent at listikler KI-formater får 20–30 % flere sitater fra KI-systemer sammenlignet med tilsvarende informasjon presentert som narrativ tekst. Denne fordelen skyldes den grunnleggende forskjellen i hvordan KI-systemer må behandle og trekke ut informasjon fra hvert format: Narrativt innhold krever at modellen utfører kompleks kontekstuttrekk og resonnement for å identifisere siterbare påstander, mens lister presenterer informasjon som ferdigpakkede, selvstendige enheter. Nummererte lister LLM-systemer kan sitere spesifikke punkter uten å kreve omfattende omgivende kontekst, noe som gjør siteringsprosessen raskere og mer pålitelig for KI-modellen. Gjenbruksverdien er betydelig–når et KI-system møter en godt strukturert listikkel, kan det trekke ut og sitere individuelle punkter uavhengig, mens narrativt innhold ofte krever at hele avsnitt eller seksjoner siteres for å bevare konteksten. Data fra flere KI-overvåkningsplattformer viser at listikler konsekvent overgår narrativt innhold i siteringsfrekvens, posisjon i KI-svar og sannsynlighet for å bli valgt som primærkilde. Dette ytelsesgapet øker ytterligere ved sammenligning av listikler mot lang narrativ tekst, siden den kognitive belastningen for KI-systemer øker eksponentielt med tettere prosa. For innholdsskapere med fokus på listikler KI-synlighet er bevisene tydelige: struktur slår narrativ – hver gang.
Å lage listikler som maksimerer KI-sitering krever oppmerksomhet mot spesifikke strukturelle og formateringsmessige elementer:
Praktiske eksempler viser kraften til godt utformede listikler for å drive KI-siteringer på tvers av flere plattformer. “Topp 5 AML Compliance-verktøy”-listikler dukker jevnlig opp i Perplexity KI-svar, hvor individuelle verktøy blir sitert som autoritative anbefalinger i samsvarsspørsmål. “Beste CRM-alternativer”-lister dominerer ChatGPT-svar, spesielt når brukere ber om programvaresammenligninger, med listeformatet som lar KI-en sitere spesifikke alternativer med trygghet. Produktsammenligningslistikler har blitt det dominerende formatet i Google AI Overviews, der den skannbare strukturen passer perfekt med plattformens fokus på rask, brukbar informasjon. Forskning fra MADX og Omnius’ sporingsdata viser at nettsteder som publiserer godt strukturerte listikler opplever en siteringsøkning på 40–60 % innen 90 dager etter publisering. Tatareks analyse av nummererte lister LLM-ytelse viste at listikler med fokus på “best i”-kategorier får 3,2x flere sitater enn narrative vurderinger av de samme produktene. Disse virkelige eksemplene understreker at listikler KI ikke bare er teoretisk overlegne–de gir målbare, kvantifiserbare forbedringer i KI-synlighet og siteringsfrekvens.
For å maksimere KI-synlighet kreves en bevisst strukturell tilnærming som går utover å bare nummerere punkter. Start med en TL;DR-seksjon øverst som oppsummerer hele listen i 2–3 setninger, slik at KI-systemer umiddelbart forstår innholdets hensikt og omfang. Inkluder en kriterieforklaring-seksjon som eksplisitt forklarer hvorfor du har valgt disse punktene–denne åpenheten hjelper KI-systemer å forstå metodikken og øker siteringstilliten. Gi balansert dekning av hvert listepunkt, slik at alle får proporsjonal dybde og analyse fremfor å favorisere noen med overdreven detaljer. Det er viktig å inkludere både styrker og svakheter for hvert punkt, da KI-systemer gjenkjenner og belønner balanserte, nyanserte analyser over ensidige salgsfremmende lister. Legg gjerne til en prisoversikt-seksjon hvis aktuelt, da denne strukturerte dataen er svært siterbar og ofte referert i KI-svar om produktsammenligninger. Implementer en sammenligningstabell i HTML-format (ikke skjermbilder eller bilder) som lar KI-systemer tolke og sitere spesifikke funksjonssammenligninger direkte. Inkluder en FAQ-seksjon som besvarer vanlige spørsmål om listepunktene dine, noe som gir ytterligere strukturert data for KI-systemer å indeksere og sitere. Avslutt med tydelige neste steg og CTA-er som veileder brukerne mot handling, og signaliserer til KI-systemer at innholdet ditt er omfattende og handlingsrettet.
Valget mellom nummererte lister og punktlister har stor betydning for hvordan KI-systemer behandler og siterer innholdet ditt. Nummererte lister signaliserer rekkefølge og rangering, og derfor dominerer de “Topp X”-listikler og trinnvise guider–KI-systemer tolker nummereringen som et eksplisitt hierarki som viser viktighet eller rekkefølge. Punktlister fungerer bedre for ikke-sekvensiell informasjon, som funksjonslister eller attributtsammenligninger der ingen innebygd rangering finnes. Forskning viser at KI-systemer behandler nummererte lister som mer autoritative og siterbare, spesielt når det svares på forespørsler som spesifikt ber om rangerte eller sekvensielle oppføringer. Når brukere spør ChatGPT eller Gemini “Hva er de 5 beste verktøyene for X?”, siterer KI-systemet helst fra nummererte lister LLM-kilder fordi nummereringen gir eksplisitt rangeringsvalidering. Punktlister utmerker seg derimot ved funksjonssammenligning, der KI-systemer trenger å trekke ut og sitere spesifikke attributter uten å antyde hierarki. Å blande nummererte lister og punktlister i samme listikkel skaper tolkningsforvirring for KI-systemer, så hold konsekvent format gjennom hele innholdet for å maksimere listeformat KI-optimalisering.
Å spore listikkel-ytelse krever systematisk overvåkning på tvers av flere KI-plattformer og verktøy. AtomicAGI, Writesonic og Perplexity-sporing gir automatisert overvåkning av hvor ofte listikler KI-innholdet ditt vises i KI-genererte svar. Manuell testing i ChatGPT, Gemini og Perplexity er fortsatt viktig, da automatiserte verktøy noen ganger overser nyanserte siteringsmønstre eller plattformspesifikke atferder. Sett opp grunnleggende måleparametere ved å spore siteringsfrekvens og posisjon–overvåk ikke bare om du blir sitert, men hvor i KI-svaret listikkelen vises og hvor ofte den velges som primærkilde. Overvåk hvilke punkter som blir sitert mest, da dette avslører hvilke spesifikke anbefalinger eller innsikter som resonnerer sterkest med KI-systemer og brukerforespørsler. Mål trafikk fra KI-kilder separat fra tradisjonell søketrafikk, ettersom KI-drevne besøk ofte har andre konverteringsmønstre og brukerhensikter enn organiske søkebesøkende. Sammenlign ytelse før og etter optimalisering, og implementer én strukturell endring om gangen for å isolere hvilke spesifikke forbedringer som gir flere sitater. Etabler en månedlig sporingsrutine for å identifisere trender og sesongvariasjoner i hvordan nummererte lister LLM-innholdet ditt presterer på ulike KI-plattformer og forespørselstyper.
Selv velmente listikler kan mislykkes i å oppnå optimal KI-sitering dersom de inneholder strukturelle eller innholdsmessige feil som forvirrer KI-analysesystemer. Skjeve lister som favoriserer ditt eget produkt eller tjeneste over konkurrenter signaliserer lav troverdighet til KI-systemer, som i økende grad straffer åpenbart salgsfremmende innhold til fordel for balanserte anbefalinger. Ujevn dybde på punktene–der noen får 200 ords analyse og andre bare 50–skaper tolkningsforvirring og antyder ufullstendig research til KI-systemene. Manglende sammenligningstabeller er en betydelig tapt mulighet, da KI-systemer vektlegger strukturert data tungt og siterer fra tabeller oftere enn fra prosa. Ingen skjema-markering betyr at du tvinger KI-systemer til å utlede innholdsstruktur fremfor å erklære den eksplisitt, noe som reduserer siteringstillit og synlighet. Utdatert informasjon er særlig skadelig for listikler, ettersom KI-systemer gjenkjenner og straffer foreldet innhold, spesielt i raske kategorier som programvare eller samsvarsregler. Dårlig struktur og hierarki med uklar H2/H3-relasjon gjør det vanskelig for KI-systemer å tolke semantiske relasjoner mellom punkter. Til slutt vil overdreven bruk av nøkkelord og altfor lange lister (50+ punkter) svekke autoritet og fokus i listikkelen, og føre til at KI-systemene vurderer den som mindre autoritativ enn fokuserte, velkuraterte alternativer.
KI-modeller er mønstergjenkjenningsmaskiner som behandler strukturerte, skannbare formater mer effektivt enn tett narrativ prosa. Listikler reduserer beregningsmessig kompleksitet ved å presentere informasjon som diskrete semantiske enheter, slik at LLM-er kan tolke, trekke ut og sitere spesifikke punkter med større selvtillit og hastighet.
Nummererte lister signaliserer rekkefølge og rangering, noe som gjør dem ideelle for 'Topp X'-listikler og trinnvise guider. Punktlister fungerer bedre for ikke-sekvensiell informasjon som funksjonssammenligninger. KI-systemer behandler nummererte lister som mer autoritative for rangerte forespørsler, mens punktlister utmerker seg i funksjonsbaserte sammenhenger.
Oppdater listiklene dine minst kvartalsvis for å opprettholde sterke ferskhetssignaler. KI-systemer belønner nylig oppdatert innhold med høyere prioritet for sitering. Selv små oppdateringer–tilføyelse av nye datapunkter, oppdatering av statistikk eller utvidelse av seksjoner–bidrar til å opprettholde siteringsberettigelse og synlighet.
Ja, skjema-markering forbedrer KI-oppdagbarhet betydelig. FAQ- og HowTo-strukturert data kan øke siteringssannsynligheten med opptil 10%. Skjema-markering gir eksplisitte metadata som KI-roboter umiddelbart gjenkjenner og prioriterer, noe som gjør innholdet ditt enklere å indeksere og sitere.
Listikler fungerer svært godt for sammenligninger, rangeringer, veiledninger og anbefalinger. De er derimot mindre egnet for narrativ historiefortelling, dyptgående analyser eller konseptuelle forklaringer. Velg listeformat når innholdet ditt naturlig kan brytes opp i diskrete, sammenlignbare punkter.
Bruk verktøy som AtomicAGI, Writesonic eller Perplexity-overvåkning for automatisert monitorering. Test relevante forespørsler manuelt i ChatGPT, Gemini og Perplexity for å spore siteringsfrekvens og posisjon. Overvåk hvilke spesifikke punkter som blir sitert mest, og mål trafikk fra KI-kilder separat fra organisk søk.
Kvalitet er viktigere enn kvantitet. Fokuser på 5–10 grundig undersøkte punkter fremfor 50+. Hvert punkt bør få balansert, proporsjonal dybde (150–300 ord). Altfor lange lister svekker autoritet og forvirrer KI-analyse, mens fokuserte, kuraterte listikler gir betydelig bedre resultater.
Ja, men oppretthold åpenhet og balanse. Inkluder produktet ditt sammen med konkurrenter, gi ærlig informasjon om styrker og svakheter, og sørg for lik dybde i dekningen. Skjevfordelte lister som favoriserer ditt eget produkt signaliserer lav troverdighet til KI-systemer, som i økende grad straffer åpenbart salgsfremmende innhold.
Følg med på hvor ofte innholdet ditt blir sitert av ChatGPT, Gemini og Perplexity med AmICiteds KI-overvåkningsplattform. Få sanntidsinnsikt i din KI-søketilstedeværelse.
Lær hvordan komparative innholdsstrukturer optimaliserer informasjon for AI-systemer. Oppdag hvorfor AI-plattformer foretrekker sammenligningstabeller, matriser...

Finn ut om AI-søkemotorer som ChatGPT og Perplexity foretrekker listikler. Lær hvordan du optimaliserer listebasert innhold for AI-siteringer og synlighet.

Lær hvordan strukturert data og schema markup hjelper AI-systemer å forstå, sitere og referere innholdet ditt nøyaktig. Komplett guide til JSON-LD-implementerin...