
Trening med syntetiske data
Lær om trening med syntetiske data for KI-modeller, hvordan det fungerer, fordeler for maskinlæring, utfordringer som modellkollaps og konsekvenser for merkevar...
6 min lesing

Sammenlign optimalisering av treningsdata og strategier for sanntids-henting for KI. Lær når du bør bruke finjustering kontra RAG, kostnadsaspekter og hybride tilnærminger for optimal KI-ytelse.
Optimalisering av treningsdata og sanntids-henting representerer fundamentalt ulike tilnærminger til å utruste KI-modeller med kunnskap. Optimalisering av treningsdata innebærer å bygge inn kunnskap direkte i modellens parametere gjennom finjustering på domenespesifikke datasett, og skaper statisk kunnskap som forblir uforandret etter at treningen er fullført. Sanntids-henting holder derimot kunnskapen ekstern for modellen og henter relevant informasjon dynamisk under inferens, slik at det er mulig å få tilgang til dynamisk informasjon som kan endre seg mellom forespørsler. Den grunnleggende forskjellen ligger i når kunnskapen integreres i modellen: optimalisering av treningsdata skjer før utrulling, mens sanntids-henting skjer under hver inferensanrop. Denne forskjellen påvirker alle aspekter av implementeringen, fra infrastrukturkrav til nøyaktighet og etterlevelse. Å forstå denne forskjellen er avgjørende for organisasjoner som skal velge optimaliseringsstrategi tilpasset sine bruksområder og begrensninger.
Optimalisering av treningsdata skjer ved systematisk å justere modellens interne parametere gjennom eksponering for kuraterte, domenespesifikke datasett i finjusteringsprosessen. Når en modell møter trenings-eksempler gjentatte ganger, internaliserer den gradvis mønstre, terminologi og domenekunnskap gjennom tilbakepropagering og gradientoppdateringer som omformer modellens læringsmekanismer. Denne prosessen lar organisasjoner kode inn spesialisert kunnskap—enten det er medisinsk terminologi, juridiske rammeverk eller proprietær forretningslogikk—direkte i modellens vekter og skjevheter. Den ferdige modellen blir svært spesialisert for sitt mål-domene, ofte med ytelse på høyde med langt større modeller; forskning fra Snorkel AI viste at finjusterte mindre modeller kan prestere likt som modeller som er 1 400 ganger større. Nøkkelkarakteristikker for optimalisering av treningsdata inkluderer:
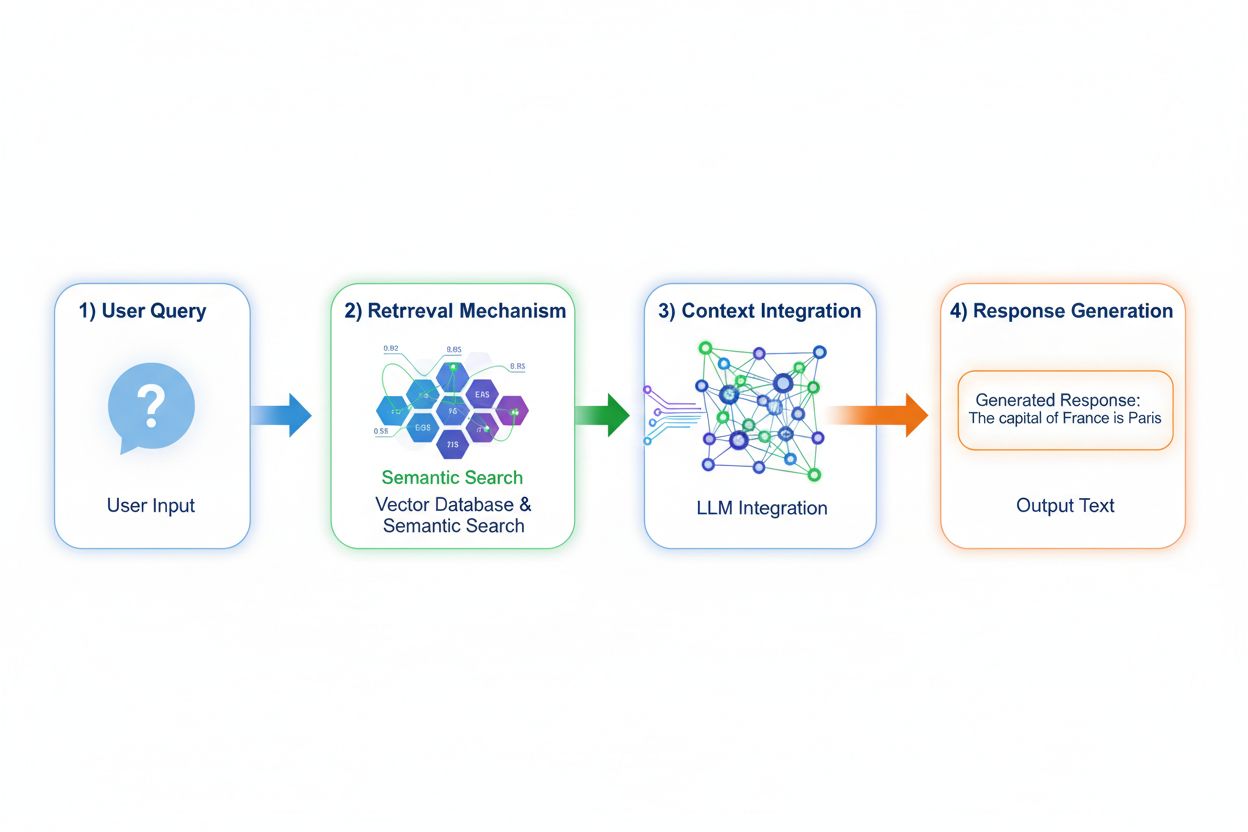
Retrieval Augmented Generation (RAG) endrer fundamentalt hvordan modeller får tilgang til kunnskap ved å implementere en firetrinnsprosess: spørringskoding, semantisk søk, kontekstrangering og generering med forankring. Når en bruker sender inn en forespørsel, konverterer RAG den først til en tett vektorrepresentasjon ved hjelp av embedding-modeller, og søker deretter i en vektordatabase med indekserte dokumenter eller kunnskapskilder. Hentingen benytter semantisk søk for å finne kontekstuelt relevante avsnitt framfor kun nøkkelordssøk, og rangerer resultatene etter relevans. Til slutt genererer modellen svar og holder eksplisitte referanser til de hentede kildene, slik at svaret forankres i faktiske data fremfor lærte parametere. Denne arkitekturen gir modeller tilgang til informasjon som ikke eksisterte under trening, og gjør RAG spesielt verdifull for applikasjoner som krever oppdatert informasjon, proprietære data eller ofte oppdaterte kunnskapsbaser. RAG-mekanismen forvandler modellen fra et statisk kunnskapslager til en dynamisk informasjons-syntetisator som kan inkorporere nye data uten omtrening.
Nøyaktighets- og hallusinasjonsprofilene til disse tilnærmingene skiller seg betydelig, og påvirker praktisk utrulling. Optimalisering av treningsdata gir modeller med dyp domeneforståelse, men begrenset evne til å erkjenne kunnskapsgrenser; når en finjustert modell får spørsmål utenfor sitt treningsgrunnlag, kan den trygt generere plausible, men uriktige svar. RAG reduserer hallusinasjoner betydelig ved å forankre svar i hentede dokumenter—modellen kan ikke påstå informasjon som ikke finnes i kildematerialet, og skaper naturlige begrensninger for oppdiktning. RAG gir dog andre nøyaktighetsutfordringer: om henteprosessen feiler i å finne relevante kilder eller rangerer irrelevante dokumenter høyt, genererer modellen svar basert på dårlig kontekst. Datatilgjengelighet blir kritisk for RAG-systemer; optimalisering av treningsdata gir et statisk øyeblikksbilde av kunnskapen ved treningstidspunktet, mens RAG kontinuerlig speiler den aktuelle tilstanden i kildedokumentene. Kildehenvisning er et annet skille: RAG muliggjør sitering og verifisering av påstander, mens finjusterte modeller ikke kan peke på spesifikke kilder for sin kunnskap, noe som gjør faktasjekk og etterlevelse vanskeligere.
De økonomiske profilene til disse tilnærmingene gir ulike kostnadsstrukturer som organisasjoner må vurdere nøye. Optimalisering av treningsdata krever betydelige beregningskostnader på forhånd: GPU-klynger som kjører i dager eller uker for å finjustere modeller, dataannoteringstjenester for å lage merkede treningssett, og ML-ingeniørkompetanse for å utforme effektive treningspipeliner. Når modellen er trent, er driftskostnadene lave siden inferens kun krever vanlig modellserverinfrastruktur uten eksterne oppslag. RAG-systemer inverterer denne kostnadsstrukturen: lavere opplæringskostnader siden ingen finjustering gjøres, men løpende infrastruktur-kostnader for vektordatabaser, embedding-modeller, hentesystemer og dokumentindeksering. Viktige kostnadsfaktorer inkluderer:
Sikkerhets- og etterlevelsesimplikasjoner skiller seg betydelig mellom disse tilnærmingene, og påvirker organisasjoner i regulerte bransjer. Finjusterte modeller skaper databeskyttelses-utfordringer fordi treningsdata blir innebygd i modellvektene; å trekke ut eller revidere hvilken kunnskap modellen inneholder krever avanserte teknikker, og personvern-bekymringer oppstår når sensitive treningsdata påvirker modellatferd. Etterlevelse av regler som GDPR blir komplisert fordi modellen i praksis “husker” treningsdata på måter som er motstandsdyktige mot sletting eller endring. RAG-systemer gir en annen sikkerhetsprofil: kunnskapen forblir i eksterne, revisjonsbare datakilder i stedet for modellparametere, noe som muliggjør enkle sikkerhets-kontroller og tilgangsbegrensninger. Organisasjoner kan innføre detaljerte tillatelser på hentekilder, revidere hvilke dokumenter modellen har brukt for hvert svar, og raskt fjerne sensitiv informasjon ved å oppdatere kildedokumenter uten nytrening. RAG gir dog sikkerhetsrisiko rundt beskyttelse av vektordatabaser, embedding-modell-sikkerhet og sikring mot at hentede dokumenter ikke lekker sensitiv informasjon. Helseorganisasjoner underlagt HIPAA og GDPR-virksomheter foretrekker ofte RAGs åpenhet og revisjonsmuligheter, mens organisasjoner med behov for modellportabilitet og offline-drift foretrekker finjusteringens selvstendige tilnærming.
Valg mellom disse tilnærmingene krever vurdering av organisasjonens rammevilkår og egenskaper ved bruksområdet. Organisasjoner bør prioritere finjustering når kunnskapen er stabil og lite sannsynlig å endres ofte, når lav inferenslatens er kritisk, når modeller må fungere offline eller i isolerte miljøer, eller når konsekvent stil og domenespesifikk formatering er avgjørende. Sanntids-henting foretrekkes når kunnskapen endres jevnlig, når kildehenvisning og revisjonsmuligheter er viktig for etterlevelse, når kunnskapsbasen er for stor til å kodes effektivt i modellparametere, eller når informasjon må oppdateres uten nytrening av modell. Spesifikke bruksområder illustrerer forskjellene:
Hybride tilnærminger kombinerer finjustering og RAG for å dra nytte av begge strategiene og samtidig redusere deres individuelle begrensninger. Organisasjoner kan finjustere modeller på grunnleggende domeneinformasjon og kommunikasjonsmønstre, samtidig som de bruker RAG for å hente oppdatert og detaljert informasjon—modellen lærer hvordan den skal resonnere om et domene, mens den henter hvilke konkrete fakta som skal inkluderes. Denne kombinerte strategien er spesielt effektiv for applikasjoner som krever både spesialisert ekspertise og oppdatert informasjon: en finansrådgiverbot som er finjustert på investeringsprinsipper og terminologi kan hente sanntids markedsdata og selskapsregnskap gjennom RAG. Virkelige hybride implementasjoner inkluderer helsesystemer som er finjustert på medisinsk kunnskap og protokoller, mens de henter pasientspesifikke data via RAG, og juridiske forskningsplattformar som er finjustert på juridisk resonnement og henter oppdatert rettspraksis. De synergistiske fordelene inkluderer redusert hallusinasjon (grunnlag i hentede kilder), forbedret domeneforståelse (fra finjustering), raskere inferens på vanlige spørsmål (cachet finjustert kunnskap), og fleksibilitet til å oppdatere spesialisert informasjon uten nytrening. Organisasjoner tar i økende grad i bruk denne optimaliseringstilnærmingen etter hvert som datakraft blir mer tilgjengelig og kompleksiteten i virkelige applikasjoner krever både dybde og aktualitet.
Muligheten til å overvåke KI-svar i sanntid blir stadig viktigere etter hvert som organisasjoner ruller ut disse optimaliseringsstrategiene i stor skala, spesielt for å forstå hvilken tilnærming som gir best resultat for ulike bruksområder. KI-overvåkingssystemer sporer modellutdata, kvaliteten på henting og brukertilfredshet, slik at organisasjoner kan måle om finjusterte modeller eller RAG-systemer gir best nytte. Siteringssporing viser viktige forskjeller mellom tilnærmingene: RAG-systemer genererer naturlig sitater og kildehenvisninger, og skaper revisjonsspor over hvilke dokumenter som har påvirket hvert svar, mens finjusterte modeller ikke gir noen innebygd mekanisme for respons-overvåking eller attribusjon. Dette skillet er avgjørende for merkevaresikkerhet og konkurranseinnsikt—organisasjoner må forstå hvordan KI-systemer siterer konkurrenter, refererer til deres produkter, eller tilskriver informasjon til kilder. Verktøy som AmICited.com dekker dette gapet ved å overvåke hvordan KI-systemer siterer merkevarer og selskaper på tvers av forskjellige optimaliseringsstrategier, og gir sanntidssporing av siteringsmønstre og frekvens. Ved å innføre omfattende overvåking kan organisasjoner måle om deres valgte optimaliseringsstrategi (finjustering, RAG eller hybrid) faktisk forbedrer siteringsnøyaktighet, reduserer hallusinasjoner om konkurrenter og opprettholder riktig tilskrivning til autoritative kilder. Denne datadrevne overvåkingen gjør det mulig å kontinuerlig forbedre optimaliseringsstrategiene basert på faktisk ytelse fremfor teoretiske forventninger.
Bransjen beveger seg mot mer sofistikerte hybride og adaptive tilnærminger som dynamisk velger mellom optimaliseringsstrategier basert på spørringskarakteristika og kunnskapsbehov. Fremvoksende beste praksis inkluderer finjustering med henting, der modeller trenes på effektiv bruk av hentet informasjon fremfor å memorere fakta, og adaptive rutingsystemer som sender forespørsler til finjusterte modeller for stabil kunnskap og RAG-systemer for dynamisk informasjon. Trender viser økt bruk av spesialiserte embedding-modeller og vektordatabaser optimalisert for spesifikke domener, som gir mer presist semantisk søk og reduserer støy fra henting. Organisasjoner utvikler mønstre for kontinuerlig modellforbedring som kombinerer periodiske finjusteringsoppdateringer med sanntids-RAG, og skaper systemer som forbedrer seg over tid samtidig som de opprettholder tilgang til oppdatert informasjon. Utviklingen av optimaliseringsstrategier gjenspeiler en bredere bransjeerkjennelse av at ingen enkelt tilnærming dekker alle behov optimalt; fremtidige systemer vil trolig implementere intelligente valgmekanismer som dynamisk velger mellom finjustering, RAG og hybride tilnærminger basert på spørringskontekst, kunnskapsstabilitet, latenskrav og etterlevelsesbehov. Etter hvert som teknologien modnes, vil konkurransefortrinnet flytte seg fra å velge én tilnærming til å implementere adaptive systemer som utnytter styrkene til hver strategi.
Optimalisering av treningsdata bygger inn kunnskap direkte i modellens parametere gjennom finjustering, og skaper statisk kunnskap som forblir fast etter trening. Sanntids-henting holder kunnskapen ekstern og henter relevant informasjon dynamisk under inferens, slik at det er mulig å få tilgang til dynamisk informasjon som kan endre seg mellom forespørsler. Den grunnleggende forskjellen er når kunnskapen integreres: optimalisering av treningsdata skjer før utrulling, mens sanntids-henting skjer under hver inferensanrop.
Bruk finjustering når kunnskapen er stabil og lite sannsynlig å endres ofte, når inferenslatens er kritisk, når modeller må fungere offline, eller når konsekvent stil og domenespesifikk formatering er avgjørende. Finjustering er ideelt for spesialiserte oppgaver som medisinsk diagnose, juridisk dokumentanalyse eller kundeservice med stabil produktinformasjon. Finjustering krever imidlertid betydelige forhåndskomputerkostnader og blir upraktisk når informasjonen endrer seg hyppig.
Ja, hybride tilnærminger kombinerer finjustering og RAG for å dra nytte av begge strategiene. Organisasjoner kan finjustere modeller på grunnleggende domeneinformasjon samtidig som de bruker RAG for å hente oppdatert og detaljert informasjon. Denne tilnærmingen er spesielt effektiv for applikasjoner som krever både spesialisert ekspertise og oppdatert informasjon, som finansielle rådgiverroboter eller helsesystemer som trenger både medisinsk kunnskap og pasientspesifikke data.
RAG reduserer hallusinasjoner betydelig ved å forankre svar i hentede dokumenter—modellen kan ikke påstå informasjon som ikke finnes i kildematerialet, og skaper naturlige begrensninger mot oppdiktning. Finjusterte modeller kan derimot selvsikkert generere plausible, men feilaktige svar når de får spørsmål utenfor sitt treningsgrunnlag. RAGs kildehenvisning muliggjør også verifisering av påstander, mens finjusterte modeller ikke kan peke på spesifikke kilder for sin kunnskap.
Finjustering krever betydelige forhåndskostnader: GPU-timer ($10 000–$100 000+ per modell), dataannotering ($0,50–$5 per eksempel) og ingeniørtid. Etter opplæring forblir driftskostnadene relativt lave. RAG-systemer har lavere startkostnader, men løpende infrastrukturkostnader for vektordatabaser, embedding-modeller og hentesystemer. Finjusterte modeller skalerer lineært med antall inferenser, mens RAG-systemer skalerer med både antall inferenser og størrelsen på kunnskapsbasen.
RAG-systemer genererer naturlig sitater og kildehenvisninger, og lager et revisjonsspor på hvilke dokumenter som påvirket hvert svar. Dette er avgjørende for merkevaresikkerhet og konkurranseinnsikt—organisasjoner kan spore hvordan KI-systemer siterer konkurrenter og refererer til deres produkter. Verktøy som AmICited.com overvåker hvordan KI-systemer siterer merkevarer på tvers av ulike optimaliseringsstrategier, og gir sanntidssporing av siteringsmønstre og hyppighet.
RAG er vanligvis bedre for bransjer med strenge krav til etterlevelse som helsevesen og finans. Kunnskapen forblir i eksterne, revisjonsbare datakilder i stedet for modellparametere, noe som muliggjør enkle sikkerhetskontroller og tilgangsbegrensninger. Organisasjoner kan implementere detaljerte tilgangsrettigheter, revidere hvilke dokumenter modellen har brukt, og raskt fjerne sensitiv informasjon uten nytrening. Helsevesen som er underlagt HIPAA og GDPR-virksomheter foretrekker ofte RAGs åpenhet og revisjonsmuligheter.
Implementer KI-overvåkingssystemer som sporer modellutdata, kvaliteten på henting og brukertilfredshetsmålinger. For RAG-systemer, overvåk nøyaktigheten på henting og kvaliteten på sitater. For finjusterte modeller, mål nøyaktighet på domenespesifikke oppgaver og forekomst av hallusinasjoner. Bruk verktøy som AmICited.com for å overvåke hvordan dine KI-systemer siterer informasjon og sammenligne ytelse på tvers av ulike optimaliseringsstrategier basert på faktiske resultater.
Følg sanntidssitater på tvers av GPT-er, Perplexity og Google AI Overviews. Forstå hvilke optimaliseringsstrategier dine konkurrenter benytter og hvordan de blir referert til i KI-svar.
Lær om trening med syntetiske data for KI-modeller, hvordan det fungerer, fordeler for maskinlæring, utfordringer som modellkollaps og konsekvenser for merkevar...

Fellesskapsdiskusjon om forskjellen mellom KI-treningsdata og live-søk (RAG). Praktiske strategier for å optimalisere innhold for både statiske treningsdata og ...

Oppdag sanntids AI-tilpasning – teknologien som gjør det mulig for AI-systemer å kontinuerlig lære av nåværende hendelser og data. Utforsk hvordan adaptiv AI fu...