
Hva er embeddinger i AI-søk?
Lær hvordan embeddinger fungerer i AI-søkemotorer og språkmodeller. Forstå vektorrepresentasjoner, semantisk søk og deres rolle i AI-genererte svar.
8 min lesing

Lær hvordan vektorembeddinger gjør det mulig for AI-systemer å forstå semantisk mening og matche innhold til forespørsler. Utforsk teknologien bak semantisk søk og AI-basert innholdsmatching.

Vektorembeddinger er det numeriske fundamentet som driver moderne kunstig intelligens-systemer, og omgjør rådata til matematiske representasjoner som maskiner kan forstå og behandle. I sin kjerne konverterer embeddinger tekst, bilder, lyd og andre innholdstyper til matriser av tall—typisk fra dusinvis til tusenvis av dimensjoner—som fanger den semantiske meningen og kontekstuelle relasjoner i dataene. Denne numeriske representasjonen er grunnleggende for hvordan AI-systemer utfører innholdsmatching, semantisk søk og anbefalinger, og gjør det mulig for maskiner å forstå ikke bare hvilke ord eller bilder som er til stede, men hva de faktisk betyr. Uten embeddinger ville AI-systemer slitt med å forstå de nyanserte relasjonene mellom konsepter, noe som gjør embeddinger til essensiell infrastruktur for enhver moderne AI-applikasjon.
Overgangen fra rådata til vektorembeddinger skjer via sofistikerte nevrale nettverksmodeller som trenes på enorme datasett for å lære meningsfulle mønstre og relasjoner. Når du legger inn tekst i en embeddingmodell, går den gjennom flere lag med nevrale nettverk som gradvis trekker ut semantisk informasjon, og til slutt produserer en vektor av fast størrelse som representerer essensen av innholdet. Populære embeddingmodeller som Word2Vec, GloVE og BERT har ulike tilnærminger—Word2Vec bruker grunne nevrale nettverk optimalisert for hastighet, GloVE kombinerer global matrise-faktorisering med lokale kontekstvinduer, mens BERT utnytter transformer-arkitektur for å forstå toveis kontekst.
| Modell | Datatype | Dimensjoner | Hovedbruksområde | Nøkkelfordel |
|---|---|---|---|---|
| Word2Vec | Tekst (ord) | 100-300 | Ordrelasjoner | Rask, effektiv |
| GloVE | Tekst (ord) | 100-300 | Semantiske relasjoner | Kombinerer global og lokal kontekst |
| BERT | Tekst (setninger/dokumenter) | 768-1024 | Kontekstforståelse | Toveis kontekstbevissthet |
| Sentence-BERT | Tekst (setninger) | 384-768 | Setningslikhet | Optimalisert for semantisk søk |
| Universal Sentence Encoder | Tekst (setninger) | 512 | Tverrspråklige oppgaver | Språkagnostisk |
Disse modellene produserer høydimensjonale vektorer (ofte 300 til 1 536 dimensjoner), der hver dimensjon fanger ulike aspekter av mening, fra grammatiske egenskaper til konseptuelle relasjoner. Det vakre med denne numeriske representasjonen er at den muliggjør matematiske operasjoner—du kan legge sammen, trekke fra og sammenligne vektorer for å oppdage relasjoner som ville vært usynlige i råtekst. Dette matematiske grunnlaget er det som gjør semantisk søk og intelligent innholdsmatching mulig i stor skala.
Den virkelige styrken til embeddinger kommer til syne gjennom semantisk likhet, evnen til å gjenkjenne at ulike ord eller fraser i vektorrommet i bunn og grunn kan bety det samme. Når embeddinger er godt laget, vil semantisk like konsepter naturlig grupperes sammen i det høydimensjonale rommet—“konge” og “dronning” havner nær hverandre, det samme gjør “bil” og “kjøretøy”, selv om de er ulike ord. For å måle denne likheten bruker AI-systemer distansemål som cosinuslikhet (måler vinkelen mellom vektorer) eller prikkprodukt (måler størrelse og retning), som kvantifiserer hvor nær to embeddinger er hverandre. For eksempel vil en forespørsel om “automobiltransport” ha høy cosinuslikhet med dokumenter om “bilreiser”, slik at systemet kan matche innhold basert på mening og ikke bare eksakt nøkkelordmatching. Denne semantiske forståelsen er det som skiller moderne AI-søk fra enkel nøkkelordmatching, og gjør det mulig for systemer å forstå brukerintensjon og levere virkelig relevante resultater.
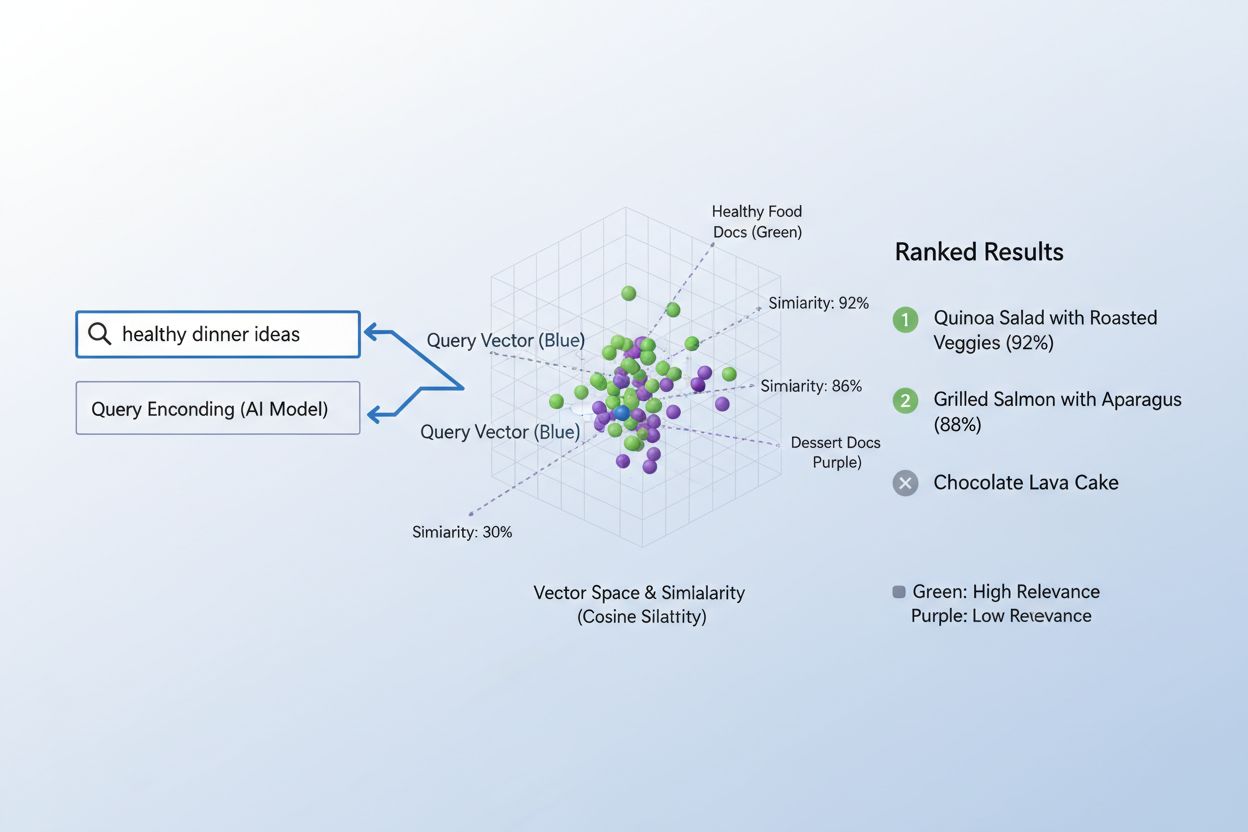
Prosessen med å matche innhold til forespørsler via embeddinger følger en elegant tostegs arbeidsflyt som driver alt fra søkemotorer til anbefalingssystemer. Først blir både brukerens forespørsel og tilgjengelig innhold uavhengig konvertert til embeddinger med samme modell—en forespørsel som “beste praksis for maskinlæring” blir en vektor, det samme gjør hver artikkel, dokument eller produkt i systemets database. Deretter beregner systemet likheten mellom forespørselsvektoren og alle innholdsvektorene, vanligvis med cosinuslikhet, som gir en poengsum for hvor relevant hvert innhold er for forespørselen. Disse poengsummene rangeres, og det mest relevante innholdet vises øverst for brukeren. I et reelt søkemotorscenario, når du søker etter “hvordan trene nevrale nettverk”, koder systemet forespørselen din, sammenligner den med millioner av dokumentembeddinger, og returnerer artikler om dyp læring, modelloptimalisering og treningsteknikker—uten å kreve eksakt nøkkelordmatch. Denne matchingen skjer på millisekunder, noe som gjør det praktisk for sanntidsapplikasjoner for millioner av brukere samtidig.
Ulike typer embeddinger tjener ulike formål avhengig av hva du ønsker å matche eller forstå. Ordembeddinger fanger betydningen av individuelle ord og fungerer godt for oppgaver som krever detaljert semantisk forståelse, mens setnings- og dokumentembeddinger samler mening over lengre tekst, slik at hele forespørsler kan matches mot artikler eller dokumenter. Bildeembeddinger representerer visuelt innhold numerisk, slik at systemer kan finne visuelt like bilder eller matche bilder mot tekstbeskrivelser, mens bruker- og produktembeddinger fanger atferdsmønstre og egenskaper, og driver anbefalingssystemer som foreslår produkter basert på brukerpreferanser. Valget mellom disse embeddingtypene innebærer avveininger: ordembeddinger er beregningseffektive, men mister kontekst, mens dokumentembeddinger bevarer full mening, men krever mer prosessorkraft. Domenespesifikke embeddinger, finjustert på spesialiserte datasett som medisinsk litteratur eller juridiske dokumenter, overgår ofte generelle modeller for bransjespesifikke applikasjoner, men krever mer treningsdata og regnekraft.
I praksis driver embeddinger noen av de mest innflytelsesrike AI-applikasjonene vi bruker daglig, fra søkeresultatene du ser til produktene som anbefales til deg på nett. Semantiske søkemotorer bruker embeddinger for å forstå forespørselsintensjon og vise relevant innhold uavhengig av eksakt nøkkelord, mens anbefalingssystemer hos Netflix, Amazon og Spotify bruker bruker- og item-embeddinger for å forutsi hva du vil se, kjøpe eller høre på neste gang. Innholdsmoderering bruker embeddinger for å oppdage skadelig innhold ved å sammenligne brukerinnlegg med embeddinger av kjente policybrudd, mens spørsmål-svar-systemer matcher brukerens spørsmål mot relevante kunnskapsbaseartikler ved å finne semantisk lignende innhold. Personalisering bruker embeddinger for å forstå brukerpreferanser og tilpasse opplevelser, og avviksdeteksjonssystemer identifiserer uvanlige mønstre ved å oppdage når nye datapunkter faller langt fra forventede embeddingklynger. Hos AmICited bruker vi embeddinger for å overvåke hvordan AI-systemer brukes på tvers av internett, matcher brukerforespørsler og innhold for å spore hvor AI-generert eller AI-assistert innhold dukker opp, slik at merkevarer kan forstå sitt AI-avtrykk og sikre korrekt attribusjon.
Effektiv implementering av embeddinger krever nøye oppmerksomhet til flere tekniske hensyn som påvirker både ytelse og kostnad. Modellvalg er kritisk—du må balansere embeddingens semantiske kvalitet mot beregningskrav, der større modeller som BERT gir rikere representasjoner, men krever mer prosessorkraft enn lette alternativer. Dimensjonalitet gir et viktig kompromiss: høyere dimensjonale embeddinger fanger mer nyanse, men bruker mer minne og gjør likhetsberegninger tregere, mens lavere dimensjonale embeddinger er raskere, men kan miste viktig semantisk informasjon. For å håndtere matching i stor skala bruker systemer spesialiserte indekseringsstrategier som FAISS (Facebook AI Similarity Search) eller Annoy (Approximate Nearest Neighbors Oh Yeah), som gjør det mulig å finne lignende embeddinger på millisekunder ved å organisere vektorer i trestrukturer eller lokalitetssensitiv hashing. Finjustering av embeddingmodeller på domene-spesifikke data kan dramatisk forbedre relevansen for spesialiserte applikasjoner, men krever merkede treningsdata og ekstra beregningsressurser. Organisasjoner må kontinuerlig balansere hastighet mot nøyaktighet, beregningskostnad mot semantisk kvalitet, og generelle modeller mot spesialiserte alternativer basert på sine behov og begrensninger.
Fremtiden for embeddinger går mot større sofistikering, effektivitet og integrasjon med bredere AI-systemer, og lover enda kraftigere innholdsmatching og forståelse. Multimodale embeddinger som samtidig bearbeider tekst, bilder og lyd er på vei, og gjør det mulig å matche på tvers av innholdstyper—finne bilder relevante for tekstforespørsler eller omvendt—noe som åpner helt nye muligheter for innholdsoppdagelse og forståelse. Forskere utvikler stadig mer effektive embeddingmodeller som gir tilsvarende semantisk kvalitet med langt færre parametere, og dermed gjør avanserte AI-funksjoner tilgjengelig for mindre organisasjoner og edge-enheter. Integrasjon av embeddinger med store språkmodeller skaper systemer som ikke bare matcher innhold semantisk, men også forstår kontekst, nyanse og hensikt på et enestående nivå. Etter hvert som AI-systemer blir mer utbredt på internett, blir det stadig viktigere å spore, overvåke og forstå hvordan innhold matches og brukes—her bruker plattformer som AmICited embeddinger for å hjelpe organisasjoner med å overvåke merkevarens tilstedeværelse, spore AI-bruksmønstre og sikre at innholdet deres blir korrekt kreditert og brukt på riktig måte. Samspillet mellom bedre embeddinger, mer effektive modeller og avanserte overvåkingsverktøy skaper en fremtid der AI-systemer er mer transparente, ansvarlige og i tråd med menneskelige verdier.
En vektorembedding er en numerisk representasjon av data (tekst, bilder, lyd) i et høy-dimensjonalt rom som fanger opp semantisk mening og relasjoner. Den omgjør abstrakte data til matriser av tall som maskiner kan behandle og analysere matematisk.
Embeddinger omgjør abstrakte data til tall som maskiner kan behandle, slik at AI kan identifisere mønstre, likheter og relasjoner mellom ulike innholdsbiter. Denne matematiske representasjonen gjør det mulig for AI-systemer å forstå mening, ikke bare matche nøkkelord.
Nøkkelordmatching ser etter eksakte ord, mens semantisk likhet forstår mening. Dette lar systemer finne relatert innhold selv uten identiske ord—for eksempel kan 'automobil' matches med 'bil' basert på semantisk relasjon, ikke bare eksakt tekstmatch.
Ja, embeddinger kan representere tekst, bilder, lyd, brukerprofiler, produkter og mer. Ulike embedding-modeller er optimalisert for ulike datatyper, fra Word2Vec for tekst til CNN-er for bilder og spektrogrammer for lyd.
AmICited bruker embeddinger for å forstå hvordan AI-systemer semantisk matcher og refererer til merkevaren din på tvers av ulike AI-plattformer og svar. Dette hjelper deg å spore innholdets tilstedeværelse i AI-genererte svar og sikre korrekt attribusjon.
Viktige utfordringer inkluderer valg av riktig modell, håndtering av beregningskostnader, styring av høy-dimensjonale data, finjustering for spesifikke domener og balanse mellom hastighet og nøyaktighet i likhetsberegninger.
Embeddinger muliggjør semantisk søk, som forstår brukerhensikt og gir relevante resultater basert på mening i stedet for bare nøkkelord. Dette gjør at søkesystemer kan finne innhold som er konseptuelt relatert, selv om det ikke inneholder eksakte søkeord.
Store språkmodeller bruker embeddinger internt for å forstå og generere tekst. Embeddinger er grunnleggende for hvordan disse modellene behandler informasjon, matcher innhold og genererer kontekstuelt riktige svar.
Vektorembeddinger driver AI-systemer som ChatGPT, Perplexity og Google AI Overviews. AmICited sporer hvordan disse systemene siterer og refererer til innholdet ditt, slik at du forstår merkevarens tilstedeværelse i AI-genererte svar.
Lær hvordan embeddinger fungerer i AI-søkemotorer og språkmodeller. Forstå vektorrepresentasjoner, semantisk søk og deres rolle i AI-genererte svar.

Lær hva embeddings er, hvordan de fungerer og hvorfor de er essensielle for AI-systemer. Oppdag hvordan tekst blir omgjort til numeriske vektorer som fanger sem...
Lær hvordan vektorsøk bruker maskinlæringsinnbygginger for å finne lignende elementer basert på mening i stedet for eksakte nøkkelord. Forstå vektordatabaser, A...