Siteringsvalg-algoritme
Lær hvordan KI-systemer velger hvilke kilder som siteres versus parafraseres. Forstå siteringsvalg-algoritmer, bias-mønstre og strategier for å forbedre synligh...
6 min lesing

Lær hvordan AI-modeller som ChatGPT, Perplexity og Gemini velger hvilke kilder de skal sitere. Forstå siteringsmekanismer, rangeringsfaktorer og optimaliseringsstrategier for AI-synlighet.
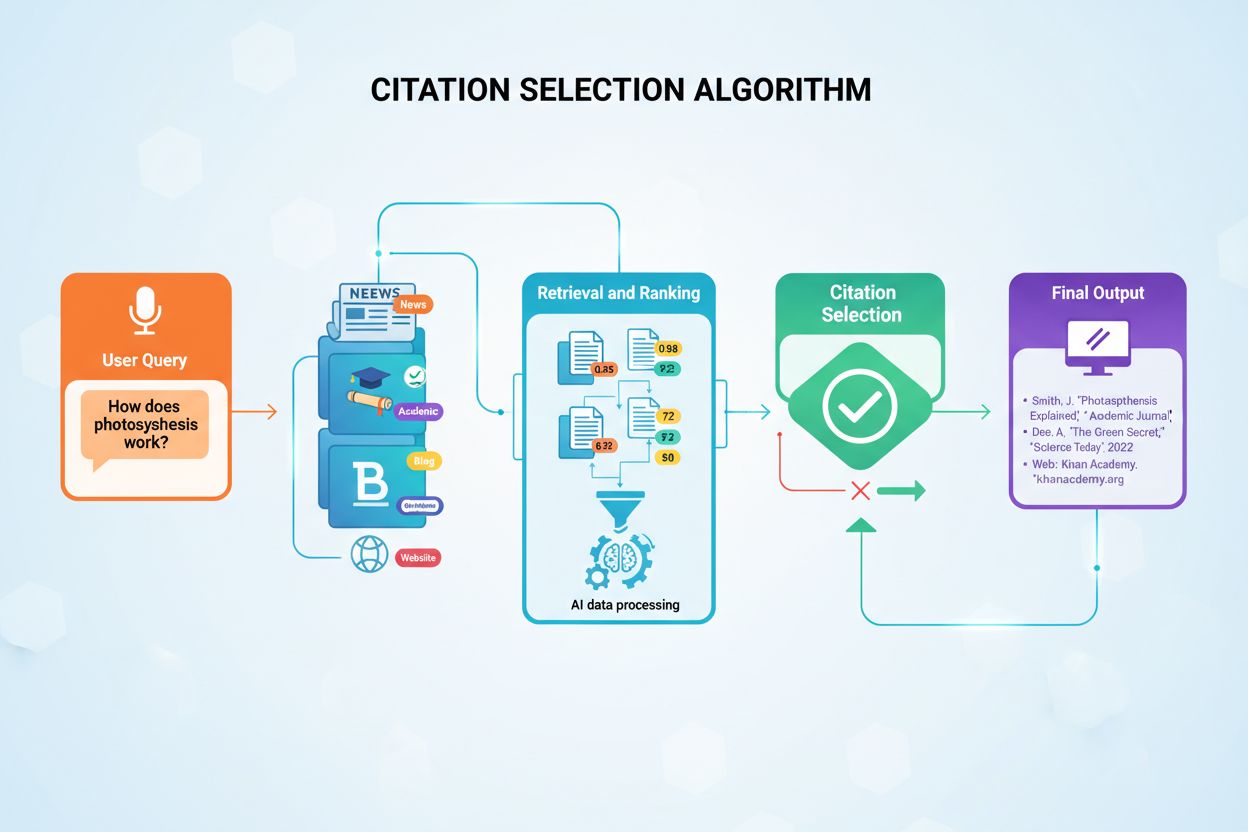
AI-modeller bestemmer hva de skal sitere gjennom Retrieval-Augmented Generation (RAG), hvor kilder vurderes basert på domenemyndighet, innholdets aktualitet, semantisk relevans, informasjonsstruktur og faktatetthet. Beslutningsprosessen skjer på millisekunder ved bruk av vektorlignende matching og multifaktors scoringsalgoritmer som vurderer troverdighet, ekspertisesignaler og innholdskvalitet.
AI-modeller velger ikke kilder tilfeldig når de siterer i sine svar. I stedet bruker de sofistikerte algoritmer som vurderer hundrevis av signaler på millisekunder for å avgjøre hvilke kilder som fortjener attribusjon. Prosessen, kjent som Retrieval-Augmented Generation (RAG), skiller seg grunnleggende fra hvordan tradisjonelle søkemotorer rangerer innhold. Mens Googles algoritme fokuserer på å rangere sider for synlighet i søkeresultater, prioriterer AI-siteringsalgoritmer kilder som gir den mest autoritative, relevante og pålitelige informasjonen for å besvare spesifikke brukerhenvendelser. Denne forskjellen betyr at synlighet i AI-genererte svar krever forståelse av et helt annet sett med optimaliseringsprinsipper enn tradisjonell SEO.
Siteringsbeslutningen skjer gjennom en flertrinnsprosess som starter i det øyeblikket brukeren sender inn et spørsmål. AI-systemet konverterer brukerens spørsmål til numeriske vektorer kalt embeddings, som representerer den semantiske meningen med spørsmålet. Disse vektorene søker deretter gjennom indekserte innholdsdatabaser med millioner av dokumenter for å finne semantisk lignende innholdsblokker. Systemet henter ikke bare det mest lignende innholdet; det anvender flere evalueringskriterier samtidig for å rangere potensielle kilder etter hvor egnet de er for sitering. Denne parallelle vurderingsprosessen sikrer at de mest troverdige, relevante og godt strukturerte kildene havner øverst i rangeringen.
Retrieval-Augmented Generation (RAG) representerer den grunnleggende arkitekturen som gjør det mulig for AI-modeller å sitere eksterne kilder i det hele tatt. I motsetning til tradisjonelle store språkmodeller som kun benytter treningsdata kodet inn under utviklingen, søker RAG-systemer aktivt gjennom indekserte dokumenter i sanntid for å hente relevant informasjon før de genererer svar. Denne arkitekturforskjellen forklarer hvorfor enkelte plattformer som Perplexity og Google AI Overviews konsekvent gir siteringer, mens andre som grunnleggende ChatGPT ofte genererer svar uten eksplisitt kildehenvisning. Forståelse av RAG klargjør hvorfor noe innhold blir sitert mens like høykvalitetsinnhold forblir usynlig for AI-systemer.
RAG-prosessen opererer gjennom fire distinkte faser som avgjør hvilke kilder som til slutt mottar siteringer. For det første deles dokumenter opp i håndterbare blokker på 200–500 ord, slik at AI-systemer kan trekke ut spesifikk, relevant informasjon uten å måtte prosessere hele artikler. For det andre konverteres disse blokkene til numeriske vektorer kalt embeddings ved hjelp av maskinlæringsmodeller trent til å forstå semantisk mening. For det tredje, når en bruker stiller et spørsmål, søker systemet etter semantisk lignende vektorer ved hjelp av vektorlignende matching, og identifiserer innhold som adresserer kjernen i spørsmålet. For det fjerde genererer AI et svar ved å bruke det hentede innholdet som kontekst, og kildene som bidro mest til svaret får siteringer. Denne arkitekturen forklarer hvorfor innholdsstruktur, klarhet og semantisk samsvar med vanlige spørsmål direkte påvirker siteringsmuligheten.
AI-siteringsalgoritmer vurderer kilder ut fra fem kjerneaspekter som samlet avgjør om en kilde er verdt å sitere. Disse faktorene jobber sammen for å skape en helhetlig vurdering av kildekvalitet, hvor hver dimensjon bidrar til den totale siteringsscoren.
| Siteringsfaktor | Påvirkningsnivå | Nøkkelindikatorer |
|---|---|---|
| Domenemyndighet | Svært høy (25–30%) | Lenkeprofil, domenealder, kunnskapsgraf-tilstedeværelse, Wikipedia-omtaler |
| Innholdets aktualitet | Høy (20–25%) | Publiseringsdato, oppdateringsfrekvens, ferske statistikker og data |
| Semantisk relevans | Høy (20–25%) | Spørsmål–innhold-samsvar, temaspesifisitet, direkte svar til stede |
| Informasjonsstruktur | Middels-høy (15–20%) | Overskrifthierarki, skannbar formatering, implementering av schema-markup |
| Faktatetthet | Middels (10–15%) | Spesifikke datapunkter, statistikk, ekspertuttalelser, siteringskjeder |
Autoritet representerer den mest vektlagte faktoren i AI-siteringsbeslutninger. Forskning som analyserer 150 000 AI-siteringer viser at Reddit og Wikipedia står for henholdsvis 40,1 % og 26,3 % av alle LLM-siteringer, noe som viser hvordan etablert autoritet dramatisk påvirker utvalget. AI-systemer vurderer autoritet gjennom flere tillitssignaler, inkludert domenealder, kvalitet på lenkeprofil, tilstedeværelse i kunnskapsgrafer og tredjepartsvalidering. Nettsteder med domenemyndighet over 60 opplever konsekvent høyere siteringsrater på tvers av ChatGPT, Perplexity og Gemini. Men autoritet handler ikke bare om domene-nivå; det omfatter også forfatterens troverdighet, der innhold med navngitte eksperter med verifiserbare kvalifikasjoner får fortrinn over anonyme bidrag.
Aktualitet fungerer som et kritisk tidsfilter som avgjør om innhold fortsatt er aktuelt for sitering. Innhold publisert eller oppdatert innenfor 48–72 timer får fortrinn i rangeringen, mens innhold begynner å tape synlighet merkbart etter 2–3 dager uten oppdateringer. Denne aktualitetsbiasen reflekterer AI-plattformenes forpliktelse til å gi oppdatert informasjon, spesielt om temaer som utvikler seg raskt der foreldet informasjon kan villede brukere. Eviggrønt innhold med nylige oppdateringer kan likevel overgå nyere innhold uten dybde, noe som tyder på at kombinasjonen av grunnleggende kvalitet og tidsmessig friskhet er viktigere enn noen av faktorene alene. Organisasjoner som vedlikeholder kvartalsvise eller årlige oppdateringssykluser oppnår høyere siteringsrater enn de som publiserer én gang og forlater innholdet.
Relevans måler semantisk samsvar mellom brukerens spørsmål og dokumentinnhold. Kilder som direkte adresserer kjernespørsmålet med minimal avsporing scorer høyere enn omfattende, men lite fokuserte ressurser. AI-systemer vurderer relevans gjennom embedding-similaritet, hvor den numeriske representasjonen av spørsmålet sammenlignes med dokumentblokkens numeriske representasjon. Dette betyr at innhold skrevet i samtaleform som matcher naturlige søkespørsmål presterer bedre enn innhold optimalisert for tradisjonelle søkemotorer. FAQ-lignende innhold og spørsmål–svar-par samsvarer naturlig med hvordan AI-systemer prosesserer spørsmål, noe som gjør dette innholdsformatet særlig siteringsverdig.
Struktur omfatter både informasjonsarkitektur og teknisk implementering. Klar hierarkisk organisering med beskrivende overskrifter, logisk flyt og skannbar formatering hjelper AI-systemer å forstå innholdsgrenser og trekke ut relevant informasjon. Strukturert data-markup, som FAQ-schema, Artikkel-schema og Organisasjons-schema, kan øke siteringsmuligheten med opptil 10 %. Innhold organisert som konsise sammendrag, punktlister, sammenligningstabeller og spørsmål–svar-par får fortrinn sammenlignet med tette avsnitt med skjulte innsikter. Denne strukturelle preferansen gjenspeiler hvordan AI-systemer er trent til å kjenne igjen godt organisert informasjon som gir komplette, kontekstuelle svar.
Faktatetthet refererer til konsentrasjonen av spesifikk, verifiserbar informasjon i innholdet. Kilder med konkrete datapunkter, statistikk, datoer og eksempler presterer bedre enn rent konseptuelt innhold. Viktigere er det at kilder som siterer autoritative referanser skaper tillitskaskader, hvor AI-systemer arver tillit fra de siterte kildene. Innhold som inkluderer bevis og lenker til primærkilder gir høyere siteringsrate enn udokumenterte påstander. Dette faktatetthetskravet betyr at hver vesentlig påstand bør ha attribusjon til autoritative kilder med publiseringsdato og ekspertkvalifikasjoner.
Ulike AI-plattformer bruker distinkte siteringsstrategier som reflekterer deres arkitektoniske forskjeller og designfilosofi. Innsikt i disse plattformspesifikke preferansene hjelper innholdsprodusenter å optimalisere for flere AI-systemer samtidig.
ChatGPTs siteringsmønstre viser en klar preferanse for leksikalske og autoritative kilder. Wikipedia vises i omtrent 35 % av ChatGPT-siteringene, som viser modellens avhengighet av etablert, fellesskapsverifisert informasjon. Plattformen unngår brukerforum med mindre spørsmålene spesifikt etterspør samfunnsmeninger, og foretrekker kilder med tydelige attribusjonskjeder og verifiserbare fakta fremfor meningsbasert innhold. Denne konservative tilnærmingen reflekterer ChatGPTs trening på høykvalitetskilder og designfilosofi med prioritet på nøyaktighet over bredde. Organisasjoner som ønsker ChatGPT-siteringer bør etablere tilstedeværelse i kunnskapsgrafer, bygge Wikipedia-oppslag og lage innhold som speiler leksikalsk dybde og nøytralitet.
Googles AI-systemer, inkludert Gemini og AI Overviews, inkluderer flere ulike kildetyper, noe som reflekterer Googles bredere indekseringsfilosofi. Reddit-innlegg står for omtrent 5 % av AI Overviews-siteringer, mens plattformen favoriserer innhold som rangerer høyt i organiske søkeresultater, noe som skaper synergi mellom tradisjonell SEO og AI-siteringsrate. Googles AI-systemer viser større vilje til å sitere nyere og brukergenerert innhold enn ChatGPT, forutsatt at kildene har relevans og autoritet. Dette plattformspesifikke mønsteret betyr at sterk tradisjonell SEO-prestasjon korrelerer med AI-siteringsuksess på Googles plattformer, selv om korrelasjonen ikke er perfekt.
Perplexity AIs preferanser fremhever åpenhet og direkte kildehenvisning. Plattformen gir vanligvis 3–5 kilder per svar med direkte lenker, og foretrekker bransje-spesifikke vurderingssider, ekspertpublikasjoner og datadrevet innhold. Domenemyndighet veier tungt, med etablerte publikasjoner som får fortrinn, mens samfunnsinnhold utgjør omtrent 1 % av siteringene, primært for produktanbefalinger. Perplexitys designfilosofi prioriterer brukernes mulighet til å verifisere informasjon gjennom tydelig kildehenvisning, noe som gjør plattformen særlig verdifull for å spore merkevaresynlighet. Organisasjoner som optimaliserer for Perplexity bør lage datarikt innhold, bransjespesifikke ressurser og ekspertforfattet materiale som tydelig demonstrerer autoritet.
Domenemyndighet fungerer som en pålitelighetsindikator i AI-algoritmer, og signaliserer at en kilde har vist troverdighet over tid. Systemene vurderer autoritet gjennom flere tillitssignaler som utgjør omtrent 5 % av den totale siteringssannsynligheten, selv om denne prosenten øker betydelig for YMYL-temaer (Your Money, Your Life) som påvirker helse, økonomi eller sikkerhet. Viktige autoritetsindikatorer inkluderer domenealder, SSL-sertifikater, personvernerklæringer og etterlevelsesmerker som SOC 2 eller GDPR-sertifisering. Disse tekniske signalene får større effekt når de kombineres med innholdskvalitetsmål, slik at teknisk solide nettsteder med utmerket innhold overgår teknisk svake sider uansett innhold.
Lenkeprofiler påvirker i stor grad hvordan AI-algoritmer oppfatter kilder. AI-modeller vurderer autoriteten til lenkende domener, relevansen av lenkeomgivelsen og mangfoldet i lenkeporteføljen. Forskning viser at ti lenker fra store publikasjoner overgår 100 lenker fra lavautoritetssider, noe som viser at lenkekvalitet er langt viktigere enn kvantitet. Ekspertattribusjon øker siteringssannsynligheten betydelig, med innhold signert av navngitte forfattere med verifiserbare kvalifikasjoner som presterer bedre enn anonymt innhold. Forfatterschema-markup og detaljerte biografier hjelper AI-systemer å validere ekspertise, mens tredjepartsvalidering gjennom omtale i bransjepublikasjoner styrker troverdigheten. Organisasjoner som bygger autoritet bør fokusere på å få lenker fra høyt autoritative kilder, etablere forfatterkvalifikasjoner og sikre omtale i bransjepublikasjoner.
Wikipedia og kunnskapsgraf-tilstedeværelse øker siteringsraten markant uavhengig av andre faktorer. Kilder referert i Wikipedia får betydelige fordeler fordi kunnskapsgrafer fungerer som autoritative kilder som AI-modeller refererer til gjentatte ganger på tvers av spørsmål. Google Knowledge Panel-informasjon mates direkte inn i hvordan AI-modeller forstår enhetsrelasjoner og autoritet. Organisasjoner uten Wikipedia-tilstedeværelse sliter med å oppnå jevn sitering selv med høykvalitetsinnhold, noe som tyder på at kunnskapsgraf-utvikling bør være en prioritet for seriøse AI-synlighetsstrategier. Dette skaper et grunnleggende tillitslag som språkmodeller refererer til under henting, noe som gjør kunnskapsgraf-oppføringer til autoritative kilder modellene konsulterer gjentatte ganger.
Samsvar med samtalebaserte spørsmål representerer et grunnleggende skifte fra tradisjonell SEO-optimalisering. Innhold strukturert som spørsmål–svar-par presterer bedre i hentalgoritmer enn nøkkelordoptimalisert innhold. FAQ-sider og innhold som speiler naturlige språkspørsmål får fortrinn fordi AI-systemer er trent på samtaledata og forstår naturlige språkstrukturer bedre enn nøkkelordstrenger. Dette betyr at innhold skrevet som om det svarer på en venns spørsmål, gir bedre resultater enn innhold skrevet for søkemotoralgoritmer. Organisasjoner bør gjennomgå innholdet sitt for samtaletone, direkte svar på vanlige spørsmål og naturlig språk som matcher hvordan brukere faktisk stiller spørsmål.
Siteringskvalitet i innholdet skaper tillitskaskader som går utover individuelle kilder. AI-systemer vurderer om påstander støttes av data og bevis. Innhold som siterer autoritative referanser arver tillit fra de siterte kildene og gir en multiplikativ troverdighetseffekt. Kilder som inkluderer bevis og lenker til primærkilder viser høyere siteringsrate enn udokumenterte påstander. Dette betyr at hver vesentlig påstand bør ha attribusjon til autoritative kilder med publiseringsdato og ekspertkvalifikasjoner. Organisasjoner som bygger siteringsverdig innhold bør undersøke og sitere minimum 5–8 autoritative kilder, inkludere 2–3 ekspertuttalelser med fullstendige kvalifikasjoner og legge til 3–5 ferske statistikker med publiseringsdato.
Konsistens på tvers av plattformer påvirker hvordan AI-systemer vurderer kilde-troverdighet. Når AI finner konsistent informasjon i flere kilder, øker tilliten til å sitere en enkelt kilde fra dette klyngenettverket. Kilder som motsier det bredere konsensus får lavere prioritet med mindre de gir overbevisende motbevis. Denne konsistensbiasen betyr at etablerte, sammenhengende narrativer på tvers av egne, fortjente og delte kanaler forsterker siterbarheten til enkeltkilder. Organisasjoner som utvikler AI-omdømmestrategier må opprettholde konsistent budskap på alle digitale flater, slik at informasjonen på nettsider, sosiale medier, bransjepublikasjoner og tredjepartsplattformer støtter og forsterker hovedbudskapene.
Oppdateringsfrekvens er viktigere i AI-æraen enn i tradisjonell SEO. Publiseringsfrekvens påvirker siteringsraten direkte, med AI-plattformer som viser klar preferanse for nylig oppdatert innhold. Organisasjoner bør oppdatere eksisterende innhold hver 48–72 time for å opprettholde aktualitetssignaler, selv om dette ikke krever full omskriving. Å legge til nye datapunkter, oppdatere statistikk eller utvide seksjoner med siste utvikling holder innholdet siteringsverdig. Innholdsstyringssystemer som sporer oppdateringsfrekvens og ferskhet bidrar til å opprettholde konkurransedyktige siteringsrater ettersom AI-plattformer stadig vektlegger aktualitet. Denne kontinuerlige oppdateringsstrategien er fundamentalt forskjellig fra tradisjonell SEO, hvor innhold kunne rangere i årevis uten endringer.
Strategisk plassering i aggregator-nettsteder skaper flere oppdagelsesveier for AI-systemer. Å bli omtalt i bransjesammendrag, ekspertlister eller vurderingssider gir muligheter utover hva originale kilder oppnår alene. En enkelt omtale i en ofte sitert publikasjon gir flere oppdagelsesveier og øker sjansen for at AI-systemer støter på ditt innhold via flere ruter. Medierelasjoner og innholdssamarbeid øker i verdi for AI-synlighet, i likhet med strategisk tilstedeværelse i bransjedatabaser og kataloger. Organisasjoner bør jobbe for å bli omtalt i bransjesammendrag, ekspertlister og vurderingssider som del av sin AI-synlighetsstrategi.
Implementering av strukturert data forbedrer siteringsmuligheten ved å gjøre innhold maskinlesbart. Schema-markup i AI-lesbare formater hjelper AI-plattformer å forstå og trekke ut spesifikke fakta uten å analysere ustrukturert tekst. FAQ-schema, artikkel-schema med forfatterinformasjon og organisasjons-schema skaper maskinlesbare signaler som hentalgoritmer prioriterer. JSON-LD strukturert data lar AI trekke ut spesifikke fakta effektivt, og forbedrer både siteringsmuligheten og nøyaktigheten av siterte opplysninger. Organisasjoner som implementerer omfattende schema-markup ser målbare forbedringer i siteringsrater på tvers av AI-plattformer.
Wikipedia- og kunnskapsgraf-utvikling gir sammensatte gevinster til tross for betydelig innsats. Å bygge Wikipedia-tilstedeværelse krever nøytrale, veldokumenterte bidrag som møter Wikipedias redaksjonelle standarder. Samtidig optimalisering av profiler på Wikidata, Google Knowledge Panel og bransjedatabaser skaper det grunnleggende tillitslaget AI-systemer stadig refererer til. Disse kunnskapsgraf-oppføringene fungerer som autoritative kilder som modeller konsulterer ved ulike spørsmål, noe som gjør kunnskapsgraf-utvikling til en strategisk prioritet for organisasjoner som ønsker varig AI-synlighet.
Organisasjoner bør spore siteringsfrekvens ved selv å teste relevante spørsmål i ChatGPT, Google AI Overviews, Perplexity og andre plattformer. Regelmessig prompt-testing viser hvilket innhold som oppnår sitering og hvor det finnes hull i AI-representasjonen. Denne testmetoden gir direkte innsikt i siteringsytelse og hjelper med å identifisere optimaliseringsmuligheter. AI-siteringsalgoritmer endrer seg kontinuerlig ettersom treningsdata utvides og hentestrategier utvikles, noe som krever at innholdsstrategier tilpasses basert på resultatdata. Når innhold slutter å motta siteringer til tross for tidligere suksess, bør det oppdateres med fersk informasjon eller restruktureres for bedre semantisk samsvar.
Flere kilder kan motta sitering for ett enkelt spørsmål, noe som skaper muligheter for samsitering i stedet for nullsumkonkurranse. Organisasjoner drar nytte av å lage omfattende innhold som utfyller i stedet for å duplisere eksisterende høyt siterte kilder. Analyse av konkurranselandskapet viser hvilke merkevarer som dominerer AI-synlighet i ulike kategorier, og hjelper organisasjoner å identifisere hull og muligheter. Sporing av siteringsytelse over tid avdekker trender og hvilke URL-er som driver suksess, slik at organisasjoner kan gjenta vinnende strategier og skalere vellykkede tilnærminger.
Spor hvor innholdet ditt vises i AI-genererte svar på ChatGPT, Perplexity, Google AI Overviews og andre AI-plattformer. Få sanntidsinnsikt i AI-synlighet og siteringsytelse.
Lær hvordan KI-systemer velger hvilke kilder som siteres versus parafraseres. Forstå siteringsvalg-algoritmer, bias-mønstre og strategier for å forbedre synligh...

Lær hva AI-siteringer er, hvordan de fungerer i ChatGPT, Perplexity og Google AI, og hvorfor de er viktige for merkevarens synlighet i generative søkemotorer.

Lær hvordan AI-generert innhold presterer i AI-søkemotorer som ChatGPT, Perplexity og Google AI Overviews. Oppdag rangeringsfaktorer, optimaliseringsstrategier ...