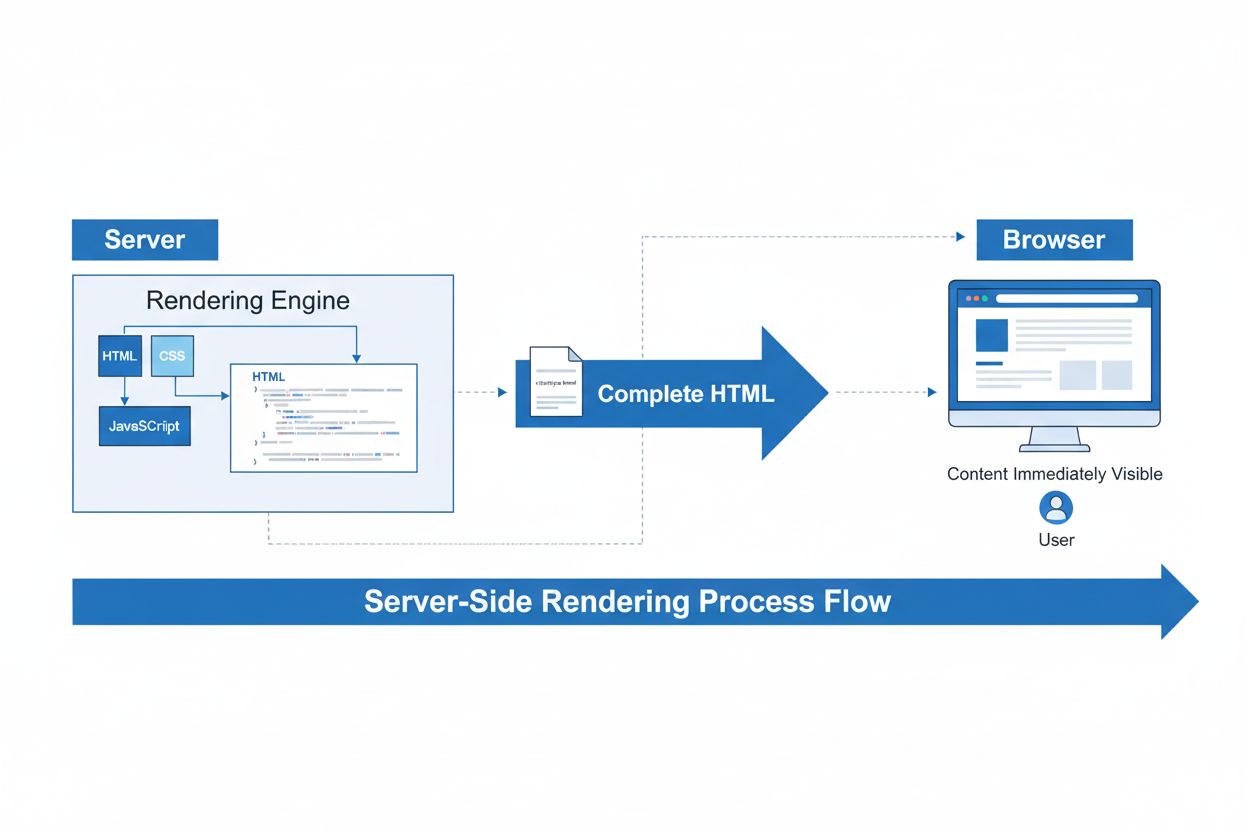
Server-Side Rendering (SSR)
Server-Side Rendering (SSR) er en webteknikk der servere rendrer komplette HTML-sider før de sendes til nettlesere. Lær hvordan SSR forbedrer SEO, sidens hastig...
10 min lesing

Lær hvordan server-side rendering muliggjør effektiv AI-prosessering, modellutrulling og sanntidsinfernser for AI-drevne applikasjoner og LLM-arbeidsbelastninger.
Server-side rendering for AI er en arkitektonisk tilnærming hvor kunstige intelligensmodeller og inferensprosessering skjer på serveren i stedet for på klientenheter. Dette muliggjør effektiv håndtering av beregningsintensive AI-oppgaver, sikrer konsistent ytelse for alle brukere og forenkler utrulling og oppdatering av modeller.
Server-side rendering for AI refererer til et arkitektonisk mønster hvor kunstig intelligens-modeller, inferensprosessering og beregningsoppgaver kjøres på backend-servere i stedet for på klientenheter som nettlesere eller mobiltelefoner. Denne tilnærmingen er grunnleggende forskjellig fra tradisjonell klient-side rendering, der JavaScript kjøres i brukerens nettleser for å generere innhold. I AI-applikasjoner betyr server-side rendering at store språkmodeller (LLM-er), maskinlæringsinferenser og AI-drevet innholdsgenerering skjer sentralt på kraftig serverinfrastruktur før resultatene sendes til brukerne. Dette arkitektoniske skiftet har blitt stadig viktigere ettersom AI-funksjonalitet har blitt mer beregningstung og integrert i moderne webapplikasjoner.
Konseptet oppsto ved å gjenkjenne et kritisk misforhold mellom hva moderne AI-applikasjoner krever og hva klientenheter faktisk kan levere. Tradisjonelle webutviklingsrammeverk som React, Angular og Vue.js populariserte klient-side rendering gjennom 2010-tallet, men denne tilnærmingen gir betydelige utfordringer når den brukes på AI-tunge arbeidsbelastninger. Server-side rendering for AI adresserer disse utfordringene ved å utnytte spesialisert maskinvare, sentralisert modellstyring og optimalisert infrastruktur som klientenheter rett og slett ikke kan matche. Dette representerer et grunnleggende paradigmeskifte i hvordan utviklere bygger AI-drevne applikasjoner.
De beregningsmessige kravene til moderne AI-systemer gjør server-side rendering ikke bare fordelaktig, men ofte nødvendig. Klientenheter, spesielt smarttelefoner og rimelige bærbare PC-er, mangler prosessorkraft til å håndtere sanntids AI-inferens effektivt. Når AI-modeller kjøres på klientenheter, opplever brukerne merkbare forsinkelser, økt batteriforbruk og inkonsistent ytelse avhengig av maskinvarekapasiteten. Server-side rendering eliminerer disse problemene ved å sentralisere AI-prosesseringen på infrastruktur utstyrt med GPU-er, TPU-er og spesialiserte AI-akseleratorer som gir langt bedre ytelse enn forbrukerenheter.
I tillegg til rå ytelse gir server-side rendering for AI viktige fordeler innen modellstyring, sikkerhet og konsistens. Når AI-modeller kjøres på servere, kan utviklere oppdatere, finjustere og rulle ut nye versjoner umiddelbart uten at brukerne må laste ned oppdateringer eller håndtere ulike modellversjoner lokalt. Dette er spesielt viktig for store språkmodeller og maskinlæringssystemer som utvikler seg raskt med hyppige forbedringer og sikkerhetsoppdateringer. Videre hindrer det å holde AI-modeller på servere uautorisert tilgang, modellekstraksjon og tyveri av immaterielle rettigheter, noe som kan skje hvis modeller distribueres til klientenheter.
| Aspekt | Klient-side AI | Server-side AI |
|---|---|---|
| Prosesseringssted | Brukerens nettleser eller enhet | Backend-servere |
| Maskinvarekrav | Begrenset til enhetens kapasitet | Spesialiserte GPU-er, TPU-er, AI-akseleratorer |
| Ytelse | Variabel, avhengig av enhet | Konsistent, optimalisert |
| Modelloppdateringer | Krever nedlasting hos bruker | Umiddelbar utrulling |
| Sikkerhet | Modeller utsatt for ekstraksjon | Modeller beskyttet på servere |
| Forsinkelse (latency) | Avhengig av enhetens kraft | Optimalisert infrastruktur |
| Skalerbarhet | Begrenset per enhet | Svært skalerbar på tvers av brukere |
| Utviklingskompleksitet | Høy (enhetsfragmentering) | Lavere (sentralisert styring) |
Nettverksoverhead og forsinkelse utgjør betydelige utfordringer i AI-applikasjoner. Moderne AI-systemer krever konstant kommunikasjon med servere for modelloppdateringer, henting av treningsdata og hybride prosesseringsscenarier. Klient-side rendering øker ironisk nok nettverksforespørslene sammenlignet med tradisjonelle applikasjoner, noe som reduserer ytelsesfordelene klient-side prosessering egentlig skulle gi. Server-side rendering samler disse kommunikasjonene, reduserer rundetidsforsinkelser og muliggjør sanntids AI-funksjoner som oversettelse, innholdsgenerering og datamaskinsynsprosessering som fungerer smidig uten forsinkelsesstraffen fra klient-side inferens.
Synkroniseringskompleksitet oppstår når AI-applikasjoner må opprettholde tilstandskonsistens på tvers av flere AI-tjenester samtidig. Moderne applikasjoner bruker ofte embedding-tjenester, fullføringsmodeller, finjusterte modeller og spesialiserte inferensmotorer som må koordinere med hverandre. Å håndtere denne distribuerte tilstanden på klientenheter introduserer betydelig kompleksitet og gir potensial for datainkonsistens, spesielt i sanntidssamarbeidende AI-funksjoner. Server-side rendering sentraliserer denne tilstandshåndteringen, sikrer at alle brukere ser konsistente resultater og eliminerer ingeniørbyrden med å vedlikeholde komplisert klient-side tilstandssynkronisering.
Enhetsfragmentering skaper store utviklingsutfordringer for klient-side AI. Ulike enheter har varierende AI-kapasiteter inkludert nevrale prosesseringsenheter, GPU-akselerasjon, WebGL-støtte og minnebegrensninger. Å skape konsistente AI-opplevelser på tvers av dette fragmenterte landskapet krever betydelig ingeniørarbeid, strategier for grasiøs degradering og flere kodeveier for ulike enhetskapasiteter. Server-side rendering eliminerer denne fragmenteringen fullstendig ved å sikre at alle brukere får tilgang til samme optimaliserte AI-prosesseringsinfrastruktur, uavhengig av enhetsspesifikasjoner.
Server-side rendering muliggjør forenklede og mer vedlikeholdbare AI-applikasjonsarkitekturer ved å sentralisere kritisk funksjonalitet. I stedet for å distribuere AI-modeller og inferenslogikk til tusenvis av klientenheter, vedlikeholder utviklere én optimalisert implementering på servere. Denne sentraliseringen gir umiddelbare fordeler, inkludert raskere utrullingssykluser, enklere feilsøking og mer rett frem ytelsesoptimalisering. Når en AI-modell må forbedres eller en feil blir oppdaget, kan utviklere rette det én gang på serveren i stedet for å forsøke å dytte oppdateringer ut til millioner av klientenheter med varierende adopsjonsrater.
Ressurseffektivitet forbedres dramatisk med server-side rendering. Serverinfrastruktur tillater effektiv ressursdeling på tvers av alle brukere, med tilkoblingspooling, caching-strategier og lastbalansering som optimaliserer maskinvareutnyttelsen. Én enkelt GPU på en server kan prosessere inferensforespørsler fra tusenvis av brukere sekvensielt, mens det å distribuere samme kapasitet til klientenheter ville kreve millioner av GPU-er. Denne effektiviteten gir lavere driftskostnader, redusert miljøpåvirkning og bedre skalerbarhet etter hvert som applikasjoner vokser.
Sikkerhet og beskyttelse av immaterielle rettigheter blir betydelig enklere med server-side rendering. AI-modeller representerer store investeringer i forskning, treningsdata og beregningsressurser. Å holde modeller på servere hindrer modellekstraksjonsangrep, uautorisert tilgang og tyveri av immaterielle rettigheter som blir mulig når modeller distribueres til klientenheter. I tillegg muliggjør server-side prosessering detaljert tilgangskontroll, revisjonslogging og etterlevelsesovervåkning som ville være umulig å håndheve på distribuerte klientenheter.
Moderne rammeverk har utviklet seg for å støtte server-side rendering for AI-arbeidsbelastninger effektivt. Next.js leder denne utviklingen med Server Actions som muliggjør sømløs AI-prosessering direkte fra serverkomponenter. Utviklere kan kalle AI-API-er, prosessere store språkmodeller og strømme svar tilbake til klientene med minimal boilerplate-kode. Rammeverket håndterer kompleksiteten med å administrere server-klient-kommunikasjon, slik at utviklere kan fokusere på AI-logikk fremfor infrastruktur.
SvelteKit tilbyr en ytelsesorientert tilnærming til server-side AI-rendering med sine load-funksjoner som kjøres på serveren før rendering. Dette muliggjør forhåndsprosessering av AI-data, generering av anbefalinger og klargjøring av AI-forbedret innhold før HTML sendes til klientene. De resulterende applikasjonene har minimale JavaScript-avtrykk samtidig som de beholder full AI-funksjonalitet, og gir ekstremt raske brukeropplevelser.
Spesialiserte verktøy som Vercel AI SDK abstraherer bort kompleksiteten med å strømme AI-svar, håndtere token-telling og støtte ulike API-er fra AI-leverandører. Disse verktøyene gjør det mulig for utviklere å bygge avanserte AI-applikasjoner uten dyp infrastrukturkunnskap. Infrastrukturvalg som Vercel Edge Functions, Cloudflare Workers og AWS Lambda gir globalt distribuert server-side AI-prosessering, reduserer forsinkelse ved å prosessere forespørsler nærmere brukerne samtidig som sentralisert modellstyring opprettholdes.
Effektiv server-side AI-rendering krever sofistikerte caching-strategier for å håndtere beregningskostnader og forsinkelse. Redis-caching lagrer ofte etterspurte AI-svar og brukersesjoner, noe som eliminerer unødvendig prosessering for lignende forespørsler. CDN-caching distribuerer statisk AI-generert innhold globalt, og sikrer at brukere mottar svar fra servere nær geografisk. Edge-caching-strategier distribuerer AI-prosessert innhold på tvers av edge-nettverk, og gir ekstremt lav latens på svar samtidig som sentralisert modellstyring beholdes.
Disse caching-tilnærmingene samarbeider for å skape effektive AI-systemer som kan skalere til millioner av brukere uten proporsjonale økninger i beregningskostnader. Ved å cache AI-svar på flere nivåer kan applikasjoner besvare de fleste forespørsler direkte fra cache, mens kun nye og unike spørsmål krever faktisk prosessering. Dette reduserer infrastrukturkostnadene dramatisk samtidig som brukeropplevelsen forbedres med raskere responstid.
Utviklingen mot server-side rendering representerer en modning av webutviklingspraksis som svar på AI-krav. Etter hvert som AI blir sentralt i webapplikasjoner, krever de beregningsmessige realitetene server-sentriske arkitekturer. Fremtiden innebærer sofistikerte hybridtilnærminger som automatisk avgjør hvor rendering bør skje basert på innholdstype, enhetskapasitet, nettverksforhold og AI-prosesseringskrav. Rammeverk vil gradvis forbedre applikasjoner med AI-funksjonalitet, og sikre at kjernefunksjonalitet fungerer universelt, samtidig som opplevelsen forbedres der det er mulig.
Dette paradigmeskiftet tar med seg lærdom fra Single Page Application-æraen samtidig som det adresserer AI-native applikasjonsutfordringer. Verktøyene og rammeverkene er klare for at utviklere kan dra nytte av AI-æraens server-side rendering, og muliggjør neste generasjon av intelligente, responsive og effektive webapplikasjoner.
Spor hvordan domenet og merkevaren din vises i AI-genererte svar på tvers av ChatGPT, Perplexity og andre AI-søkemotorer. Få sanntidsinnsikt i din AI-synlighet.
Server-Side Rendering (SSR) er en webteknikk der servere rendrer komplette HTML-sider før de sendes til nettlesere. Lær hvordan SSR forbedrer SEO, sidens hastig...
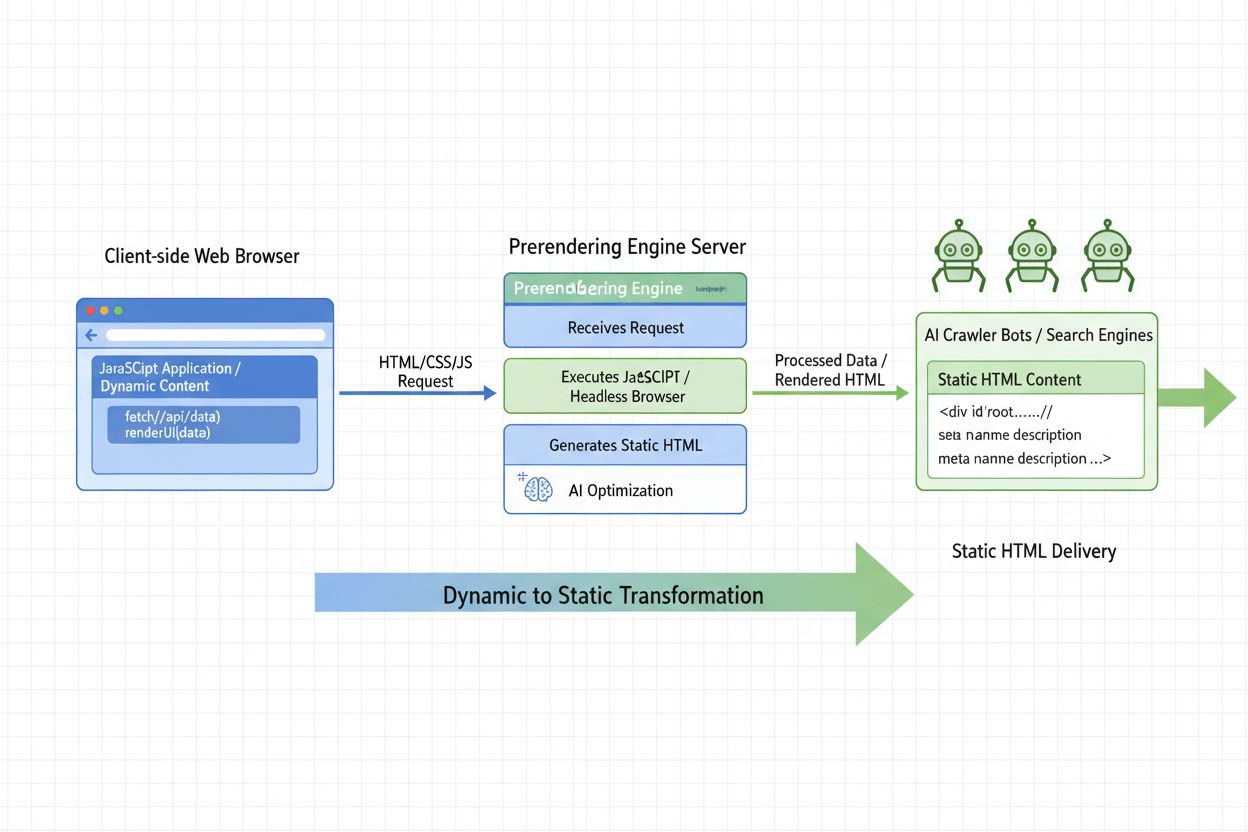
Lær hva AI-forrendering er og hvordan server-side-renderingsstrategier optimaliserer nettstedet ditt for synlighet blant AI-crawlere. Oppdag implementeringsstra...

Lær hvordan JavaScript-rendering påvirker nettstedets synlighet i AI-søkemotorer som ChatGPT, Perplexity og Claude. Oppdag hvorfor AI-crawlere sliter med JavaSc...