Sonar-algoritme
Sonar-algoritmen er Perplexitys proprietære RAG-rangeringssystem som kombinerer hybrid gjenfinning, nevrale om-rangeringer og sanntids siteringsgenerering. Lær ...
12 min lesing

Lær hvordan Perplexitys Sonar-algoritme driver sanntids AI-søk med kostnadseffektive modeller. Utforsk Sonar, Sonar Pro og Sonar Reasoning-varianter.
Sonar er Perplexitys lette, kostnadseffektive søkemodellfamilie optimalisert for sanntids nett-søkeintegrasjon med store språkmodeller. Den kombinerer rask gjenfinning med forankrede svar, og tilbyr varianter inkludert base Sonar for raske spørsmål og svar, Sonar Pro for komplekse spørsmål, og Sonar Reasoning for trinnvis problemløsning med live webtilgang.
Sonar er Perplexitys egen søkemodellfamilie utviklet for å integrere sanntids nettsøk direkte i store språkmodeller, slik at de kan generere forankrede og nøyaktige svar. I motsetning til tradisjonelle søkemotorer som returnerer blå lenker, gir Sonar-algoritmene en AI-først-søkeopplevelse der modellen syntetiserer informasjon fra flere kilder for å levere omfattende og siterte svar. Sonar-familien representerer et grunnleggende skifte i hvordan AI-systemer får tilgang til og behandler oppdatert informasjon, slik at modellene kan svare på spørsmål om nylige hendelser, siste nytt og oppdaterte data uten å være avhengig av statiske treningsdata. Denne teknologien er avgjørende i det stadig skiftende landskapet av AI-søkemotorer som Perplexity, ChatGPT med nettsøk, Google AI Overviews og Claude, hvor sanntids informasjonsinnhenting har blitt essensielt for å opprettholde nøyaktighet og relevans.
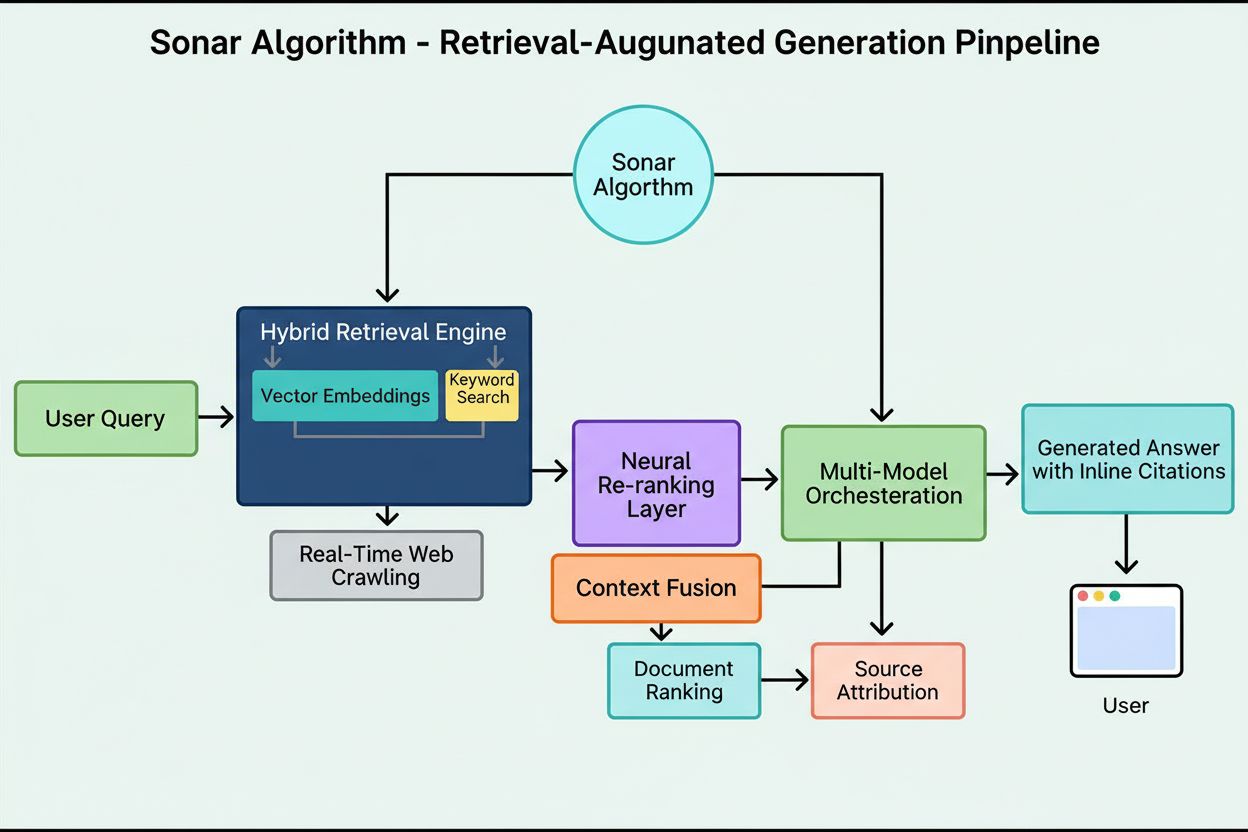
Perplexitys søkeinfrastruktur håndterer over 200 millioner daglige søk og vedlikeholder en indeks over 200 milliarder unike nettadresser, noe som gjør den til en av de største og hyppigst oppdaterte webindeksene optimalisert spesielt for AI-bruk. Sonar-algoritmen ble utviklet for å løse kritiske begrensninger i eldre søke-API-er, som var designet for mennesker heller enn AI-modeller. Tradisjonelle søke-API-er hadde svært høye kostnader (noen tilbydere tok $200 per tusen søk), opererte med utdaterte indekser, og returnerte dokumentbaserte resultater som var for grovkornede for AI-modeller med begrensede kontekstvinduer. Sonar løser disse problemene gjennom en hybrid henter- og rangeringspipeline som kombinerer både leksikalske søk (basert på nøkkelord) og semantiske søk (basert på mening) for å finne den mest relevante informasjonen på underdokumentnivå.
Arkitekturen til Sonar bygger på tre grunnprinsipper: fullstendighet, aktualitet og hastighet. Søkeindeksen må ha omfattende dekning av nettet, oppdateres kontinuerlig med siste informasjon, og svare på søk i løpet av millisekunder for å støtte sanntids AI-applikasjoner. Perplexitys indekseringsinfrastruktur består av titusenvis av CPU-er og hundrevis av terabyte RAM, som gjør systemet i stand til å håndtere titusenvis av indekseringsoperasjoner per sekund. Maskinlæringsmodeller forutsier hvilke nettadresser som bør indekseres og når, for å sikre at trafikkerte og ofte oppdaterte dokumenter alltid er aktuelle, samtidig som man opprettholder en håndterbar gjennomgangshyppighet for nettstedseiere.
| Modellvariant | Primær bruk | Nøkkelfunksjoner | Kontektslengde | Optimalisering |
|---|---|---|---|---|
| Sonar (Base) | Rask Q&A og enkle søk | Lett, kostnadseffektiv, sanntids nettsøk | 128K tokens | Hastighet og rimelighet |
| Sonar Pro | Komplekse søk og avansert research | Forbedret gjenfinning, kildevalg, sitering | 128K tokens | Nøyaktighet og kompleksitet |
| Sonar Reasoning | Logisk problemløsning og analyse | Chain-of-Thought-reasoning, trinnvis resonnement | 128K tokens | Dyp logikk med live søk |
| Sonar Reasoning Pro | Høyytelse kompleks analyse | Avansert multi-trinns CoT, forbedret gjenfinning | 128K tokens | Maksimal resonnementsevne |
Perplexitys Sonar-familie inkluderer fire ulike modellvarianter, hver optimalisert for forskjellige bruksområder og kompleksitetsnivåer. Grunnmodellen Sonar er det letteste og mest kostnadseffektive alternativet, designet for daglig bruk som oppsummering av innhold, oppslag av definisjoner og nyhetslesing. Den håndterer forespørsler til $1 per 1 million inndata-tokens og $1 per 1 million utdata-tokens, noe som gjør den betydelig rimeligere enn konkurrerende løsninger. Sonar Pro bygger videre på dette med utvidede muligheter for å håndtere komplekse, flertrinns spørsmål som krever dypere analyse og kildevalg. Brukere kan spesifisere hvilke kilder som skal prioriteres eller utelates, og får dermed detaljert kontroll over informasjonsinnhentingen.
Sonar Reasoning introduserer Chain-of-Thought (CoT) reasoning, en teknikk der modellen eksplisitt arbeider seg gjennom problemer steg for steg før den konkluderer. Denne varianten drives av DeepSeek-R1-teknologi og utmerker seg innen logisk resonnement, matematisk problemløsning og strukturert analyse. Sonar Reasoning Pro representerer toppnivået, og kombinerer avansert flertrinns resonnement med forbedret informasjonsinnhenting for de mest krevende analysene. Alle Sonar-varianter har 128K token kontekstlengde, som gir god plass til å behandle lange dokumenter, flere kilder og komplekse forespørsler.
Sonar-algoritmen implementerer en flertrinns henter- og rangeringspipeline som gradvis forbedrer søkeresultatene med økende sofistikering. Prosessen starter med hybrid gjenfinning, der systemet søker i indeksen med både leksikalske og semantiske metoder samtidig, og deretter slår sammen resultatene til et omfattende kandidatutvalg. Denne doble tilnærmingen sikrer at både nøkkelord-spesifikke treff og konseptuelt likt innhold fanges opp. Påfølgende trinn bruker forfiltreringsheuristikker for å fjerne irrelevante eller utdaterte resultater, etterfulgt av flere rangeringsrunder med stadig mer avanserte modeller.
De tidlige rangeringsstegene bruker leksikale og embedding-baserte scorere optimalisert for hastighet, mens senere steg benytter cross-encoder reranker-modeller som utfører avansert semantisk analyse. Hele pipelinen opererer på både dokument- og underdokumentnivå, slik at systemet kan identifisere og trekke ut spesifikke avsnitt, seksjoner eller til og med setninger som direkte svarer på et spørsmål, i stedet for å tvinge brukeren til å lese hele nettsider. Denne finmaskede innholdsforståelsen er avgjørende for AI-modeller, hvor hver token teller og irrelevant informasjon kan føre til dårligere ytelse. Perplexitys innholdsforståelsesmodul bruker dynamiske regelsett og AI-drevet selvforbedring for å tolke den varierte og ustrukturerte weben, og tilpasser seg kontinuerlig nye nettstedoppsett og innholdsmønstre.
Perplexitys Sonar-modeller har vist eksepsjonell ytelse i grundige sammenligninger mot konkurrerende AI-søkeløsninger. I omfattende benchmarking med rammeverk som SimpleQA, FRAMES, BrowseComp og HLE, har Sonar-varianter konsekvent overgått modeller fra Google Gemini 2.0 Flash, OpenAI GPT-4o Search og andre ledende AI-systemer. På SimpleQA-benchmarken oppnådde Sonar en score på 0,930, betydelig høyere enn konkurrenter som Brave Search (0,822) og SERP-baserte API-er (0,890). For dyptgående research målt med HLE-benchmarken, nådd Sonar 0,288, markant foran alternative leverandører.
I tillegg til kvalitetsmålinger, utmerker Sonar seg på latenstid, en avgjørende faktor for brukerorienterte applikasjoner. Perplexitys median søkelatenstid er 358 millisekunder, over 150 millisekunder raskere enn nest raskeste tilbyder. 95-prosentil latenstid ligger under 800 millisekunder, noe som sikrer jevn ytelse selv under høy belastning. Denne fartsfordelen skyldes Perplexitys infrastrukturinvesteringer, inkludert distribuert indeksering over hundrevis av terabyte lagring, intelligente cache-strategier og optimaliserte inferens-pipelines. Kombinasjonen av banebrytende kvalitet og bransjeledende hastighet betyr at utviklere ikke lenger trenger å velge mellom raske applikasjoner og nøyaktige resultater.
Sonar-algoritmene representerer et paradigmeskifte i hvordan AI-systemer får tilgang til sanntidsinformasjon, grunnleggende forskjellig fra tradisjonelle søkemotorer og tidligere AI-chatboter. ChatGPT med nettsøk og Google AI Overviews tilbyr sanntidsmuligheter, men Sonars design er spesielt optimalisert for AI-bruk fremfor å tilpasse menneskeorientert søk til AI-modeller. Sonar API gir utviklere programmert tilgang til Perplexitys søkeinfrastruktur, slik at de kan bygge AI-applikasjoner som trenger oppdatert informasjon uten å måtte håndtere egen crawling, indeksering og rangering.
Perplexitys søkeinfrastruktur håndterer søk med sanntids nettsøkbaserte svar som inkluderer detaljerte søkeresultater og siteringer, slik at brukere kan verifisere informasjonskilder. Systemet gir i snitt 5,01 lenker per svar, noe som plasserer det mellom ChatGPT (10,42 lenker) og andre AI-søkeverktøy. Denne balanserte tilnærmingen gir nok kildemangfold for verifisering uten å overvelde brukeren med for mange henvisninger. Sonar-algoritmens evne til å sitere kilder er spesielt viktig for merkevareovervåking og innholdssynlighet, da organisasjoner kan spore når domenene deres dukker opp i AI-genererte svar på plattformer som Perplexity, ChatGPT, Claude og Google AI Overviews ved hjelp av verktøy som AmICited, som er spesialister på overvåkning av merkevare og domeneopptreden i AI-søkeresultater.
Sonar-algoritmene driver mangfoldige applikasjoner innen forskning, forretningsanalyse, innholdsproduksjon og sanntids informasjonsinnhenting. Forskere bruker Sonar til å gjennomføre omfattende litteraturgjennomganger og syntetisere informasjon fra flere kilder med riktige siteringer. Forretningsanalytikere benytter Sonar Pro for konkurranseanalyser, markedsundersøkelser og trendanalyser som krever oppdatert data. Innholdsskapere bruker Sonar til å faktasjekke, finne nye eksempler og sikre at arbeidet reflekterer siste utvikling i feltet. Nyhetsorganisasjoner og faktasjekkere er avhengige av Sonars sanntids søk for å verifisere påstander og gi kontekst til nyhetssaker.
Sonar Reasoning-variantene er spesielt verdifulle for teknisk problemløsning, der trinnvis analyse kombinert med oppdatert informasjon gir overlegne resultater. Programvareutviklere bruker Sonar Reasoning for å feilsøke problemer ved å få tilgang til siste dokumentasjon, Stack Overflow-diskusjoner og GitHub-repositorier. Dataanalytikere bruker Sonar for å holde seg oppdatert på raskt skiftende metoder og få tilgang til nye forskningsartikler. Finansielle fagfolk benytter Sonar Pro for å overvåke markedet, følge regulatoriske endringer og analysere nye trender. Evnen til å kombinere sanntids nettsøk med avansert resonnement gjør Sonar særlig nyttig i bransjer der informasjon endres raskt og nøyaktighet er kritisk.
Sonar-algoritmen er bare starten på AI-native søkeinfrastruktur. Perplexitys forskning viser at eldre søkemotorer har nådd et platå på rundt 10 milliarder søk per dag, mens neste generasjons AI-drevet søk vil håndtere mangfoldig flere forespørsler etter hvert som autonome AI-agenter blir allestedsnærværende. Fremtidige versjoner av Sonar må løse nye utfordringer, inkludert effektiv skalering i møte med eksponentiell vekst i forespørslene, nye kontekstteknikker optimalisert for stadig mer avanserte AI-modeller, samt den vedvarende balansen mellom omfattende dekning, aktualitet og latenstid.
Perplexitys infrastruktur er unikt posisjonert for å møte disse utfordringene, med et massivt produksjonssøkssystem som betjener millioner av brukere daglig kombinert med teknisk talent og forskningskompetanse. Selskapets selvforbedrende innholdsforståelsesmodul viser hvordan AI kan forbedre søkekvalitet kontinuerlig uten manuell innsats. Etter hvert som AI-agenter blir mer autonome og kapable, blir kvaliteten på deres underliggende søkeinfrastruktur stadig viktigere. Sonars utvikling vil sannsynligvis innebære dypere integrasjon med agent-workflows, mer avansert kontekstkurering for spesifikke AI-arkitekturer, og forbedrede kildeverifiseringsfunksjoner for å bekjempe feilinformasjon. Organisasjoner som vil opprettholde synlighet i dette landskapet bør overvåke merkevaren sin på AI-søkeplattformer med spesialiserte verktøy, slik at innholdet forblir autoritativt og riktig sitert etter hvert som AI-systemer blir den viktigste inngangsporten til informasjonsinnhenting.
Følg med når domenet ditt dukker opp i Perplexity Sonar-svar og andre AI-søkeresultater. Sørg for at innholdet ditt er sitert som en autoritativ kilde på alle større AI-plattformer.
Sonar-algoritmen er Perplexitys proprietære RAG-rangeringssystem som kombinerer hybrid gjenfinning, nevrale om-rangeringer og sanntids siteringsgenerering. Lær ...

Lær hvordan du formaterer innhold for maksimal synlighet i Perplexity-siteringer. Bli ekspert på sitérbart innhold, schema markup og siteringsstrategier for å d...

Perplexity AI er en AI-drevet svarmotor som kombinerer sanntidssøk på nettet med LLM-er for å levere siterte, nøyaktige svar. Lær hvordan det fungerer og hvilke...