
Prediktive AI-forespørsler
Lær hva prediktive AI-forespørsler er, hvordan de fungerer, og hvorfor de endrer kundeopplevelse og forretningsinnsikt. Oppdag teknologiene, fordelene og implem...
7 min lesing
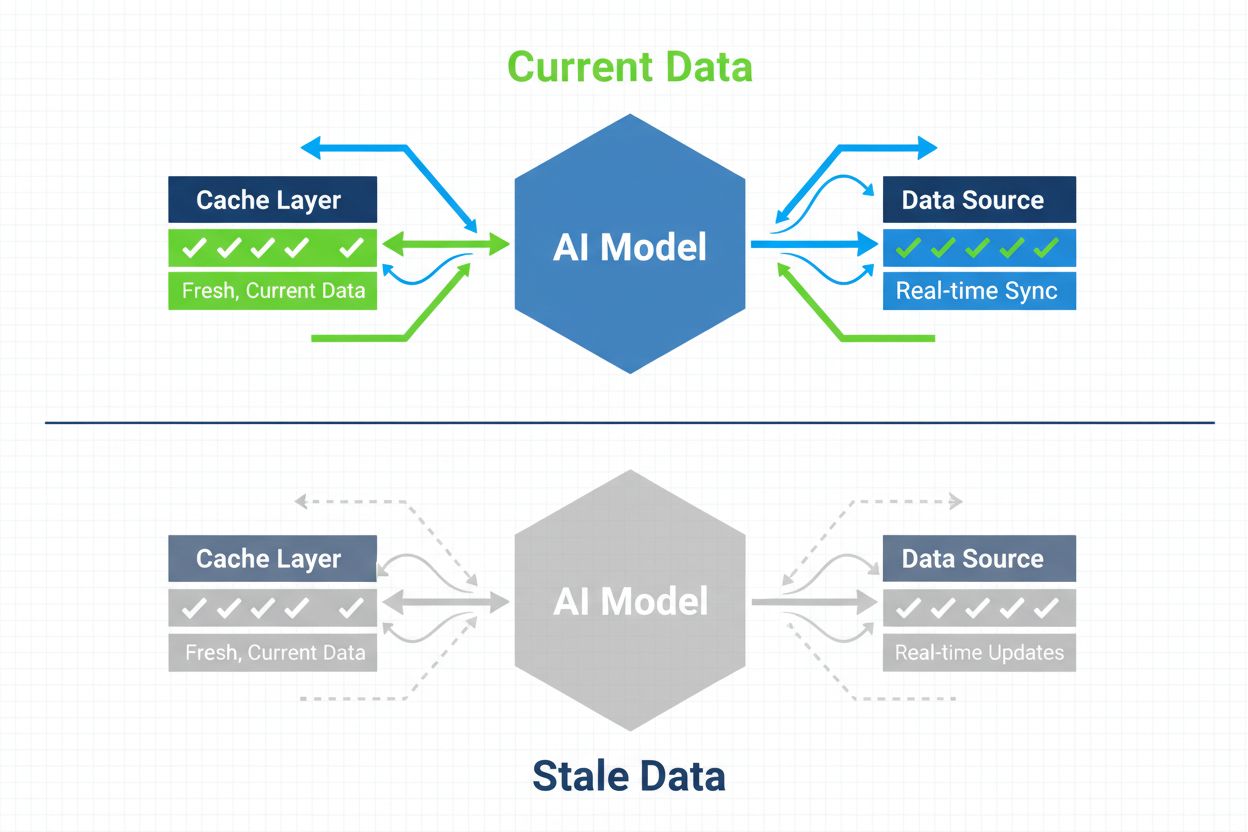
Strategier for å sikre at AI-systemer har tilgang til oppdatert innhold i stedet for foreldede hurtigbufrede versjoner. Håndtering av hurtigbuffer balanserer ytelsesfordeler mot risikoen for å levere utdatert informasjon, ved å bruke ugyldiggjøringsstrategier og overvåking for å opprettholde datainnholdets friskhet samtidig som ventetid og kostnader reduseres.
Strategier for å sikre at AI-systemer har tilgang til oppdatert innhold i stedet for foreldede hurtigbufrede versjoner. Håndtering av hurtigbuffer balanserer ytelsesfordeler mot risikoen for å levere utdatert informasjon, ved å bruke ugyldiggjøringsstrategier og overvåking for å opprettholde datainnholdets friskhet samtidig som ventetid og kostnader reduseres.
AI-håndtering av hurtigbuffer refererer til den systematiske tilnærmingen for å lagre og hente tidligere beregnede resultater, modellutdata eller API-responser for å unngå overflødig prosessering og redusere ventetid i kunstig intelligente systemer. Den viktigste utfordringen er å balansere ytelsesfordelene ved hurtigbufrede data mot risikoen for å levere foreldet eller utdatert informasjon som ikke lenger reflekterer gjeldende systemstatus eller brukerkrav. Dette blir spesielt kritisk i store språkmodeller (LLM-er) og AI-applikasjoner hvor inferenskostnader er betydelige og responstid har direkte innvirkning på brukeropplevelsen. Cache-håndteringssystemer må intelligent avgjøre når hurtigbufrede resultater fortsatt er gyldige og når ny beregning er nødvendig, noe som gjør det til et grunnleggende arkitektonisk hensyn for produksjonsklare AI-utrullinger.
Effekten av effektiv håndtering av hurtigbuffer på AI-systemets ytelse er betydelig og målbar på flere områder. Implementering av cache-strategier kan redusere svartidslatens med 80-90 % for gjentatte spørringer samtidig som API-kostnader kuttes med 50-90 %, avhengig av cache-treffrate og systemarkitektur. Utover ytelsesmålinger påvirker cache-håndtering direkte nøyaktighetskonsistens og systempålitelighet, ettersom riktig ugyldiggjorte cacher sikrer at brukerne mottar oppdatert informasjon, mens dårlig administrerte cacher gir problemer med foreldede data. Disse forbedringene blir stadig viktigere etter hvert som AI-systemer skal håndtere millioner av forespørsler, hvor den samlede effekten av cache-effektivitet direkte avgjør infrastrukturkostnader og brukertilfredshet.
| Aspekt | Hurtigbufrede systemer | Ikke-hurtigbufrede systemer |
|---|---|---|
| Responstid | 80-90 % raskere | Grunnlinje |
| API-kostnader | 50-90 % reduksjon | Full kostnad |
| Nøyaktighet | Konsistent | Variabel |
| Skalerbarhet | Høy | Begrenset |
Cache-ugyldiggjøringsstrategier avgjør hvordan og når hurtigbufrede data oppdateres eller fjernes fra lagring, og representerer et av de mest kritiske valgene i cache-arkitektur. Ulike ugyldiggjøringsmetoder gir ulike avveininger mellom datainnholdets friskhet og systemytelse:
Valg av ugyldiggjøringsstrategi avhenger fundamentalt av applikasjonskrav: Systemer som prioriterer datanøyaktighet kan akseptere høyere ventetidskostnader ved aggressiv ugyldiggjøring, mens ytelseskritiske applikasjoner kan tolerere litt foreldede data for å opprettholde svartider under millisekund.
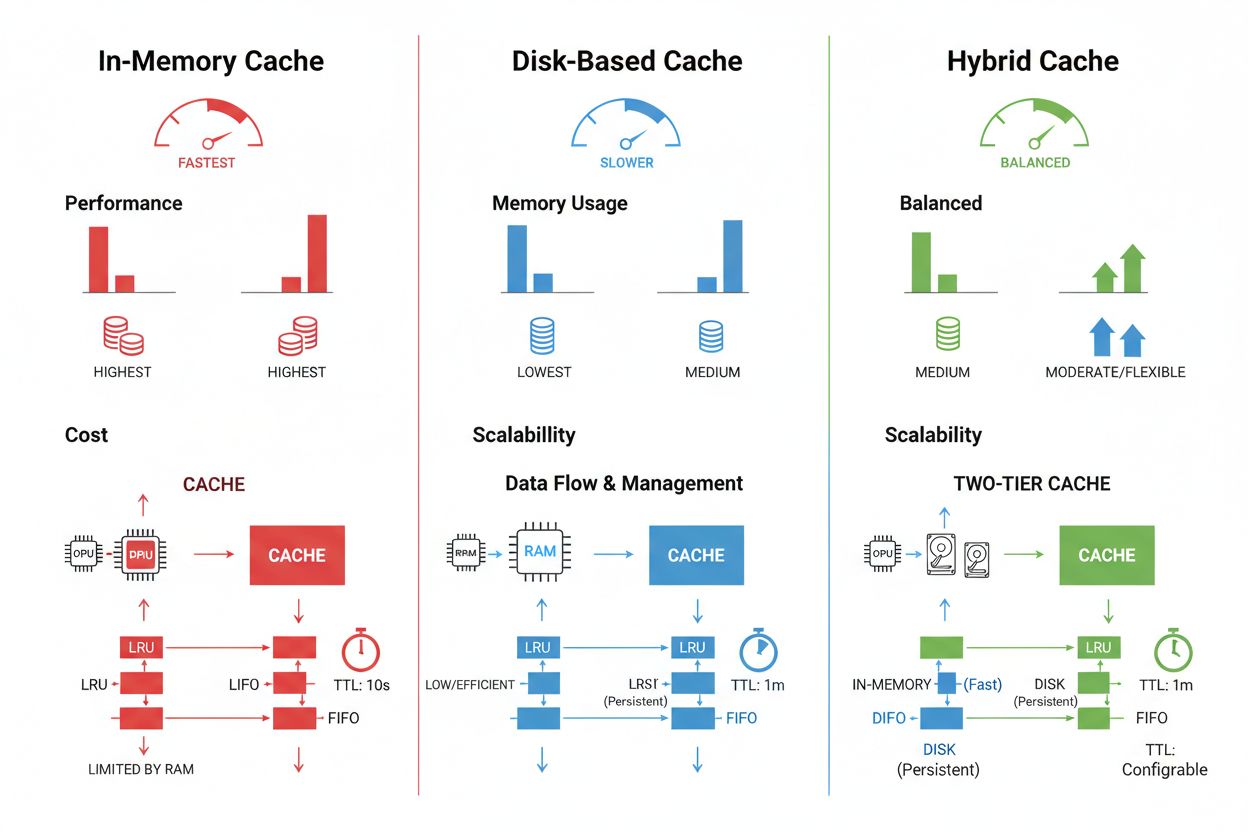
Prompt-caching i store språkmodeller representerer en spesialisert anvendelse av cache-håndtering som lagrer mellomliggende modelltilstander og token-sekvenser for å unngå reprosessering av identiske eller lignende inndata. LLM-er støtter to hovedtyper caching: eksakt caching matcher identiske prompts tegn-for-tegn, mens semantisk caching identifiserer funksjonelt likeverdige prompts til tross for ulik ordlyd. OpenAI implementerer automatisk prompt-caching med 50 % kostnadsreduksjon på hurtigbufrede tokens, og krever minimum 1024 tokens per prompt for å aktivere cachingfordeler. Anthropic tilbyr manuell prompt-caching med mer aggressive 90 % kostnadsreduksjoner, men krever at utviklere eksplisitt administrerer cache-nøkler og varigheter, med minimumskrav til cache på 1024-2048 tokens avhengig av modellkonfigurasjon. Cache-varighet i LLM-systemer varierer vanligvis fra minutter til timer, for å balansere de beregningsmessige besparelsene ved gjenbruk av bufrede tilstander mot risikoen for å levere utdaterte modellutdata i tidskritiske applikasjoner.
Cache-lagring og håndteringsteknikker varierer betydelig basert på ytelseskrav, datavolum og infrastrukturbegrensninger, og hver tilnærming gir ulike fordeler og begrensninger. Cache-løsninger i minnet som Redis gir tilgangshastigheter på mikrosekundnivå ideelle for hyppige spørringer, men bruker betydelig RAM og krever nøye minnehåndtering. Diskbasert caching håndterer større datasett og overlever systemomstarter, men gir ventetid målt i millisekunder sammenlignet med alternativer i minnet. Hybride tilnærminger kombinerer begge lagringstyper, ruter ofte brukte data til minnet mens større datasett oppbevares på disk:
| Lagringstype | Best for | Ytelse | Minnebruk |
|---|---|---|---|
| I minnet (Redis) | Hyppige spørringer | Raskest | Høyere |
| Diskbasert | Store datasett | Moderat | Lavere |
| Hybrid | Blandet last | Balansert | Balansert |
Effektiv håndtering av hurtigbuffer krever at man konfigurerer passende TTL-innstillinger som reflekterer datavolatilitet—korte TTL-er (minutter) for raskt endrende data kontra lengre TTL-er (timer/dager) for stabilt innhold—kombinert med kontinuerlig overvåking av cache-treffrater, utkastingsmønstre og minnebruk for å identifisere optimaliseringsmuligheter.
Virkelige AI-applikasjoner viser både det transformative potensialet og den driftsmessige kompleksiteten ved cache-håndtering på tvers av ulike bruksområder. Kundeservice-chatboter bruker caching for å levere konsistente svar på ofte stilte spørsmål, samtidig som inferenskostnadene reduseres med 60-70 %, noe som muliggjør kostnadseffektiv skalering til tusenvis av samtidige brukere. Kodeassistenter cacher vanlige kodeeksempler og dokumentasjonsutdrag, slik at utviklere får autofullføringsforslag med svartider på under 100 ms selv i perioder med høy trafikk. Dokumentbehandlingssystemer cacher embeddinger og semantiske representasjoner av ofte analyserte dokumenter, og akselererer dramatisk likhetssøk og klassifiseringsoppgaver. Imidlertid introduserer produksjonsklar cache-håndtering betydelige utfordringer: ugyldiggjøringskompleksitet øker eksponentielt i distribuerte systemer hvor cache-konsistens må opprettholdes på tvers av flere servere, ressursbegrensninger tvinger vanskelige avveininger mellom cache-størrelse og dekning, sikkerhetsrisikoer oppstår når hurtigbufrede data inneholder sensitiv informasjon som krever kryptering og tilgangskontroller, og koordinering av cache-oppdateringer på tvers av mikrotjenester introduserer potensielle kappløpsforhold og datainkonsistenser. Omfattende overvåkningsløsninger som sporer cache-friskhet, treffrater og ugyldiggjøringshendelser blir avgjørende for å opprettholde systempålitelighet og identifisere når cache-strategier må justeres basert på endrede datamønstre og brukeradferd.
Cache-ugyldiggjøring fjerner eller oppdaterer foreldede data når endringer oppstår, og gir umiddelbar friskhet, men krever hendelsesstyrte utløsere. Cache-utløp setter en tidsgrense (TTL) for hvor lenge data forblir i cache, og gir enklere implementering, men kan føre til at foreldede data leveres hvis TTL er for lang. Mange systemer kombinerer begge tilnærminger for optimal ytelse.
Effektiv håndtering av hurtigbuffer kan redusere API-kostnader med 50-90 % avhengig av cache-treffrate og systemarkitektur. OpenAI sin prompt-caching gir 50 % kostnadsreduksjon på hurtigbufrede tokens, mens Anthropic gir opptil 90 % reduksjon. De faktiske besparelsene avhenger av spørringsmønstre og hvor mye data som effektivt kan caches.
Prompt-caching lagrer mellomliggende modelltilstander og token-sekvenser for å unngå å reprosessere identiske eller lignende inndata i store språkmodeller. Det støtter eksakt caching (tegn-for-tegn-treff) og semantisk caching (funksjonelt likeverdige prompts med ulik ordlyd). Dette reduserer ventetiden med 80 % og kostnadene med 50-90 % for gjentatte spørringer.
De viktigste strategiene er: Tidsbasert utløp (TTL) for automatisk fjerning etter angitt varighet, hendelsesbasert ugyldiggjøring for umiddelbare oppdateringer når data endres, semantisk ugyldiggjøring for lignende spørringer basert på mening, og hybride tilnærminger som kombinerer flere strategier. Valget avhenger av datavolatilitet og krav til friskhet.
Hurtigbuffer i minne (som Redis) gir tilgangshastigheter på mikrosekundnivå ideelt for hyppige spørringer, men bruker betydelig RAM. Diskbasert hurtigbuffer håndterer større datasett og overlever omstarter, men gir ventetid på millisekundnivå. Hybride tilnærminger kombinerer begge, ruter ofte brukte data til minnet mens større datasett lagres på disk.
TTL er en nedtellingstimer som avgjør hvor lenge hurtigbufrede data forblir gyldige før utløp. Korte TTL-er (minutter) passer for raskt endrende data, mens lengre TTL-er (timer/dager) fungerer for stabilt innhold. Riktig TTL-konfigurasjon balanserer datainnholdets friskhet mot unødvendige cache-oppdateringer og servert belastning.
Effektiv cache-håndtering gjør at AI-systemer kan håndtere betydelig flere forespørsler uten proporsjonal utvidelse av infrastrukturen. Ved å redusere den beregningsmessige belastningen per forespørsel gjennom caching, kan systemer betjene millioner av brukere mer kostnadseffektivt. Treffraten i cache avgjør direkte infrastrukturkostnader og brukertilfredshet i produksjonsmiljøer.
Hurtigbufring av sensitive data introduserer sikkerhetssårbarheter dersom de ikke er riktig kryptert og tilgangskontrollert. Risikoer inkluderer uautorisert tilgang til hurtigbufret informasjon, dataeksponering under cache-ugyldiggjøring og utilsiktet hurtigbufring av konfidensielt innhold. Omfattende kryptering, tilgangskontroller og overvåking er essensielt for å beskytte sensitive hurtigbufrede data.
AmICited sporer hvordan AI-systemer refererer til merkevaren din og sørger for at innholdet ditt forblir oppdatert i AI-cacher. Få innsikt i AI-håndtering av hurtigbuffer og innholdsfriskhet på tvers av GPT-er, Perplexity og Google AI Overviews.
Lær hva prediktive AI-forespørsler er, hvordan de fungerer, og hvorfor de endrer kundeopplevelse og forretningsinnsikt. Oppdag teknologiene, fordelene og implem...
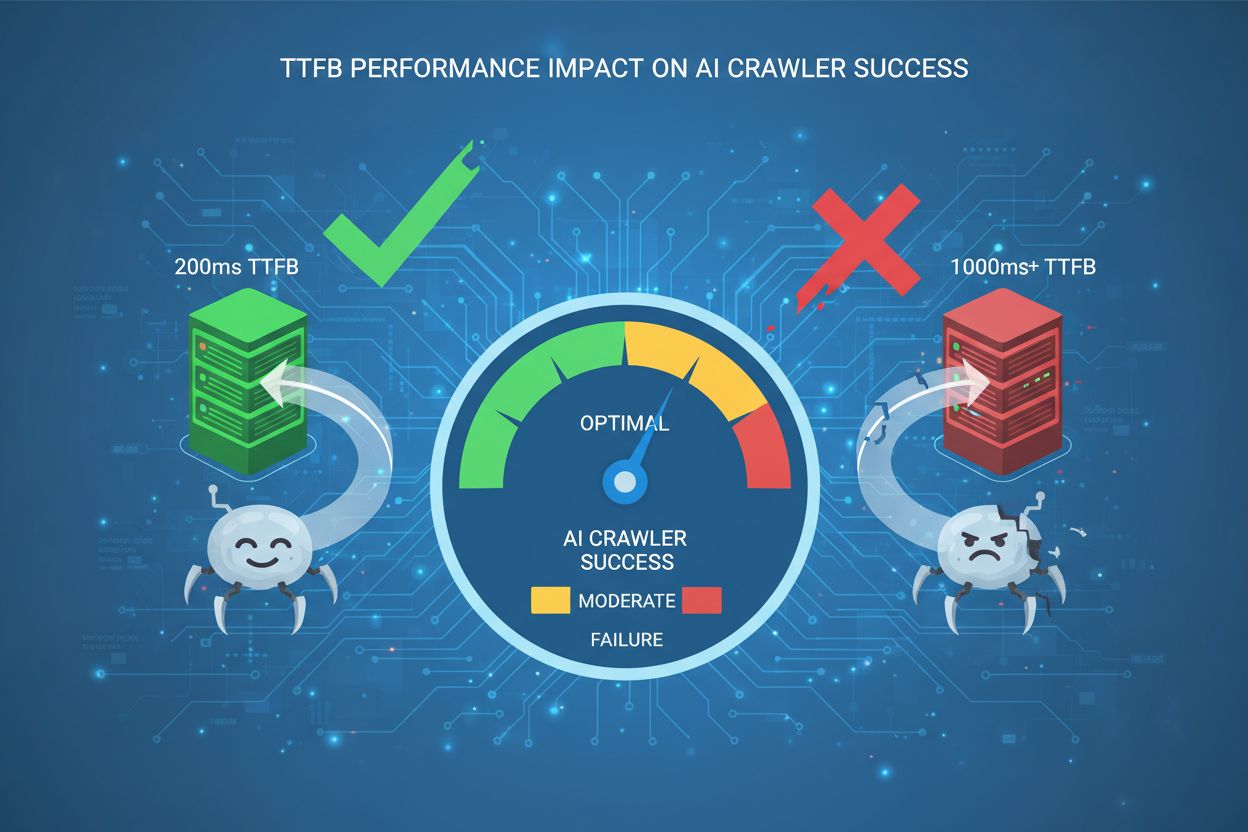
Lær hvordan Time to First Byte påvirker AI-crawler-suksess. Oppdag hvorfor 200ms er gullstandarden og hvordan du optimaliserer serverens responstid for bedre sy...

Lær essensielle strategier for å optimalisere støtteinnholdet ditt for AI-systemer som ChatGPT, Perplexity og Google AI Overviews. Oppdag beste praksis for klar...