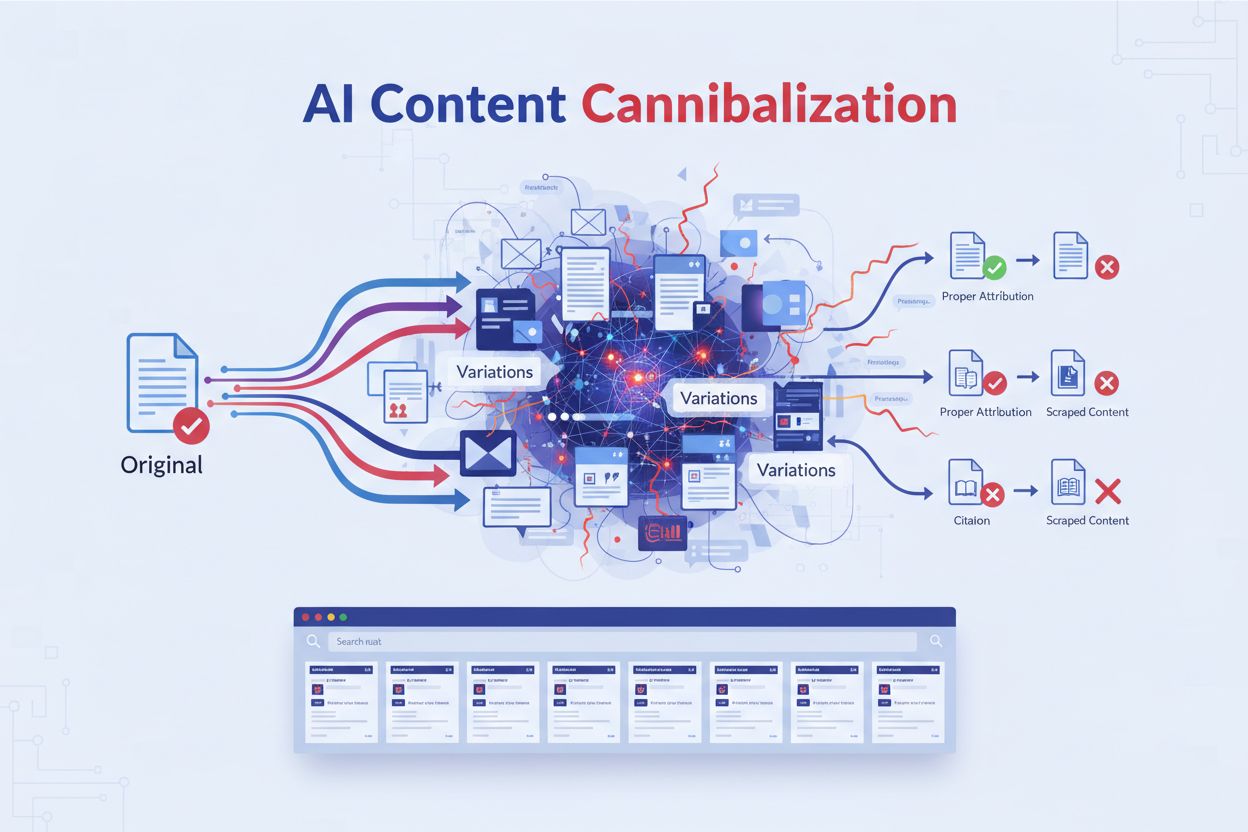
Når flere innholdsstykker konkurrerer om de samme AI-siteringene. AI-systemer skraper og omskriver ditt originale innhold til semantisk like varianter som konkurrerer med dine originale sider i søkeresultater og AI-genererte svar, noe som svekker din synlighet og autoritet uten korrekt attribusjon.
AI-innholdskannibalisering
Når flere innholdsstykker konkurrerer om de samme AI-siteringene. AI-systemer skraper og omskriver ditt originale innhold til semantisk like varianter som konkurrerer med dine originale sider i søkeresultater og AI-genererte svar, noe som svekker din synlighet og autoritet uten korrekt attribusjon.
Hva er AI-innholdskannibalisering?
AI-innholdskannibalisering oppstår når kunstige intelligenssystemer skraper og omskriver ditt originale innhold til semantisk like varianter som konkurrerer med dine originale sider i søkeresultater og AI-genererte svar. I motsetning til tradisjonelt duplisert innhold som kopierer tekst ord for ord, bruker AI-genererte versjoner ulike formuleringer mens de bevarer samme mening, noe som gjør at de kan omgå plagiatkontroller. Dette skaper et særlig lumsk problem i et AI-først søkelandskap: innholdet ditt mater AI-modeller som deretter genererer konkurrerende svar uten korrekt attribusjon. Når Google AI Overviews og andre AI-søkesystemer syntetiserer informasjon, kan de sitere disse AI-genererte klonene oftere enn ditt originale arbeid, noe som svekker din synlighet og autoritet. Det grunnleggende problemet er at semantisk likhet betyr mer enn nøyaktig duplisering i AI-systemer—det vil si at dine unike innsikter og forskning resirkuleres til utallige varianter som alle konkurrerer om de samme siteringene og trafikken.
Hvordan AI-innholdskannibalisering skiller seg fra tradisjonelt duplisert innhold
Faktor
Klassisk duplisert innhold
AI-innholdskannibalisering
Kilde
Kopiert ord for ord fra din side
Omskrevet eller parafrasert av AI-verktøy til nye varianter
Deteksjon
Lett å oppdage med plagiatfiltre eller manuell sjekk
Mye vanskeligere å oppdage fordi ordlyden er unik, men semantisk lik
Utseende
Ser ut som en direkte kopi eller speilside
Fremstår “originalt” for søkemotorer og brukere selv om det er basert på ditt arbeid
SEO-effekt
Blir vanligvis undertrykt i SERP når det flagges som duplikat
Svekket tematisk autoritet, forvirrer søkemotorer og kan rangere over din originale side
Tiltak
Send DMCA-fjerning eller be om fjerning
Mye vanskeligere å handle mot; krever ofte å styrke ditt eget innhold i stedet for fjerning
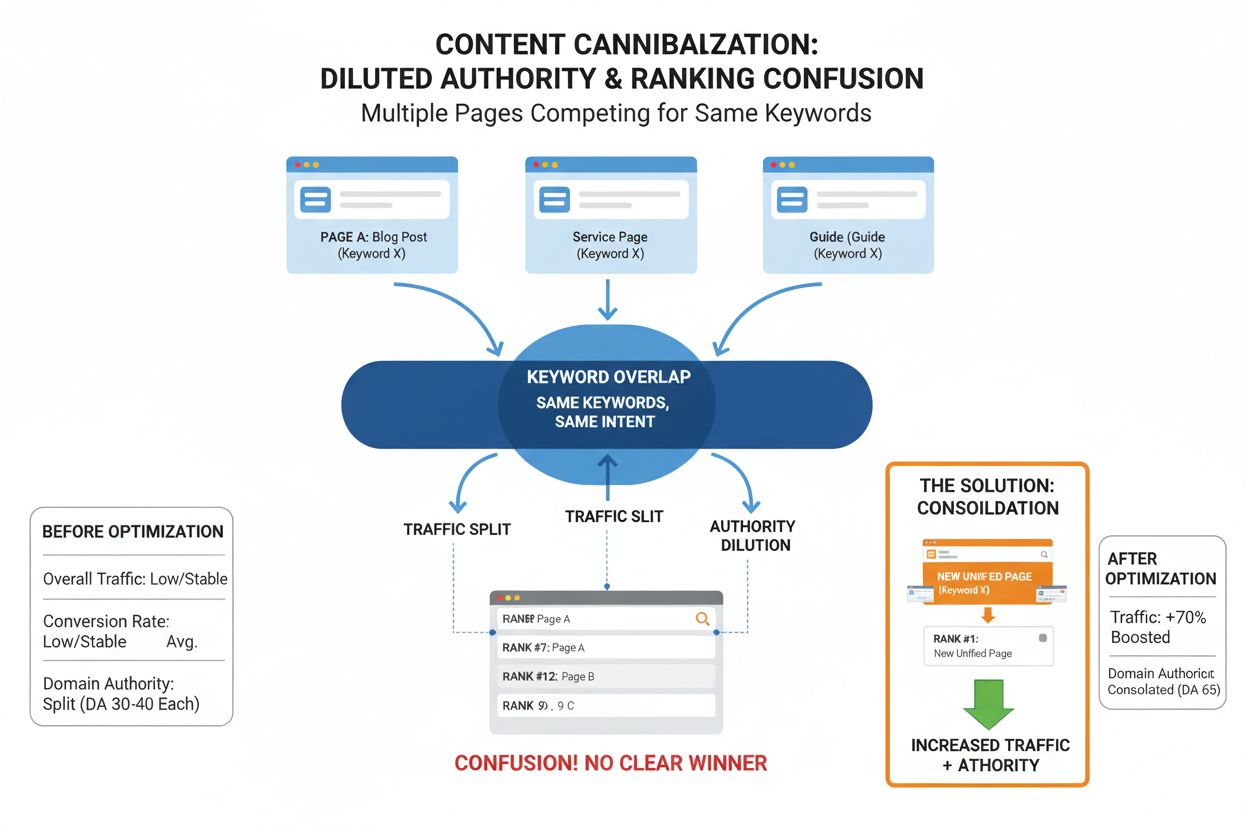
Tradisjonelt duplisert innhold har vært et kjent SEO-problem i årevis—det er synlig, sporbar og relativt lett å løse gjennom fjerning eller kanonisering. AI-innholdskannibalisering er fundamentalt annerledes og mer lumsk. De omskrevne versjonene ser ikke ut som direkte kopier, så plagiatkontrollere flagger dem sjelden. For søkemotorer kan den AI-genererte siden fremstå like relevant som din originale, noe som splitter rangeringssignaler og svekker din autoritet. I praksis betyr dette at nettstedet ditt stille kan miste trafikk og rangeringer uten en åpenbar årsak. Med mindre du aktivt overvåker søkeresultater og analyserer semantisk likhet, forblir AI-kannibalisering ofte usynlig til betydelig skade allerede har oppstått.
AI-innholdskannibalisering skader synligheten din i søk gjennom flere mekanismer:
SERP-flooding: Søkeresultatene fylles med sider som gjentar ideen din med nye ord. Dette gjør ditt originale mindre synlig og tvinger brukere til å velge mellom flere lignende resultater, ingen av dem utpeker seg tydelig som den autoritative kilden. Når Google viser flere varianter av samme konsept, mister ditt originale synlighet.
Tematisk forvirring: Google kan ikke lett avgjøre hvem som har den sanne autoriteten på et tema. Den semantiske vekten spres over flere kopier, noe som gjør det vanskeligere for søkemotorer å avgjøre hvilken side som fortjener toppplassering. Denne forvirringen svekker alle konkurrerende sider, inkludert din originale.
Klikklekkasje: Omskrevne sider fanger trafikk som egentlig burde gått til ditt originale. De ser nye ut for brukere og besvarer spørsmålet, men kilden er ikke deg. En bruker som søker “beste SEO-verktøy” kan klikke på en AI-omskrevet versjon i stedet for din originale sammenligning, noe som koster deg trafikk og engasjement.
AI Overviews-erosjon: Google AI Overviews bruker store språkmodeller trent på resirkulert innhold. Din unike formulering mister attribusjon når AI-systemer siterer semantisk like kloner oftere enn ditt originale arbeid. Dette betyr at innholdet ditt mater AI-systemer uten å motta korrekt kreditering eller trafikk.
Eksempel: Hvis din opprinnelige artikkel sier “Semrush er sterk på revisjoner. Ahrefs er sterk på tilbakekoblinger,” kan et AI-system omskrive dette til “Ahrefs utmerker seg på lenkeanalyse. Semrush er bedre på tekniske revisjoner.” Betydningen er identisk, begge blir indeksert, og den omskrevne versjonen kan til og med rangere over din originale på grunn av høyere domeneautoritet på kopisiden.
Hvordan oppdage AI-innholdskannibalisering
Å identifisere AI-innholdskannibalisering krever en flerlags tilnærming:
Bruk verktøy for semantisk likhet: Embedding-modeller og klyngealgoritmer kan oppdage omskrevne duplikater som plagiatkontrollere ikke finner. Disse verktøyene analyserer semantisk betydning i stedet for eksakt tekstmatch, og avslører innhold som formidler samme informasjon med andre ord. Verktøy som Semrush og Similarweb tilbyr semantisk analyse spesielt utviklet for dette formålet.
Overvåk dine toppsider i Google Search Console: Følg med på dine best presterende sider for plutselige fall i trafikk uten tilsvarende lenketap. Hvis en side som vanligvis gir trafikk plutselig får en betydelig nedgang, kan det tyde på at AI-genererte varianter kannibaliserer synligheten. Bruk fanen Ytelse for å filtrere på spesifikke sider og følg med på uforklarlige endringer.
Les AI Overview-resultater for dine søk: Søk etter dine målnøkkelord i Google AI Overviews og Perplexity. Hvis du ser formuleringer som ligner dine uten korrekt sitering eller attribusjon, er det et signal på at innholdet ditt skrapes og omskrives. Sjekk om merkevaren din nevnes eller om AI-systemet siterer konkurrenter i stedet.
Sett opp varsler for skrapede RSS-feeder: Mange AI-systemer trener på skrapede syndikeringsfeeder. Overvåk RSS-feed-bruken og sett opp varsler for uautorisert skraping. Verktøy som Google Alerts og spesialiserte feed-overvåkingstjenester kan hjelpe deg å se hvor innholdet ditt distribueres og eventuelt gjenbrukes uten tillatelse.
Strategier for å beskytte mot AI-innholdskannibalisering
Å forsvare innholdet ditt krever en proaktiv, flerfasettert strategi:
Publiser eiendeler AI ikke kan spinne: Lag innhold som AI-systemer ikke lett kan reprodusere—originale datatabeller, undersøkelsesresultater, proprietær forskning, interaktive kalkulatorer og egendefinerte verktøy. Mens AI er god på å generere generisk tekst, kan den ikke finne på ferske data eller unike interaktive opplevelser. Disse forsvarbare eiendelene blir din vollgrav mot kannibalisering og gir brukerne en grunn til å besøke din originale kilde.
Finn på originale begreper og bruk dem konsekvent: Hvis du introduserer et særpreget begrep som “AI-innholdskannibalisering” og bruker det konsekvent i ditt innholdsunivers, vil kopier gjenta det. Dette knytter autoritet tilbake til deg som opphavsperson. Når AI-systemer siterer dette begrepet, forsterker de merkevaren din som kilden. Utvikle unike termer for dine nøkkelkonsepter og ei det språkområdet.
Legg til schema markup: Implementer FAQ-, HowTo- og Article-schema på sidene dine. Strukturert data hjelper Google å forstå kildeautoritet og gir AI-systemer innsikt i innholdets formål og troverdighet. Dette gjør det lettere for søkemotorene å kreditere innhold korrekt og prioritere ditt originale over kopier.
Oppdater innholdet ditt ofte: Søkemotorer belønner aktualitet, og AI-kopier fryser ofte etter første publisering. Ved å regelmessig oppdatere innholdet med nye data, ferske eksempler og oppdaterte innsikter, signaliserer du at siden din er den levende, autoritative kilden. Dette aktualitetssignalet hjelper å skille ditt originale fra statiske AI-genererte kopier.
Vannmerk dine visuelle elementer og data: Legg inn subtile vannmerker i diagrammer, infografikker og egne datavisualiseringer. Selv om det ikke er idiotsikkert, beviser vannmerker eierskap i tvister og gjør det vanskeligere for andre å påberope seg ditt arbeid som sitt eget. Inkluder opphavsrettsmerker og krav om attribusjon i dine datapresentasjoner.
Rollen til AI-siteringssporing
AI-siteringssporing er praksisen med å overvåke hvor, hvordan og hvorfor merkevarens innhold nevnes som kilde i AI-genererte svar på verktøy som ChatGPT, Perplexity, Google AI Overviews og andre AI-søkeplattformer. Dette representerer et grunnleggende skifte fra tradisjonell SEO, hvor du overvåket nøkkelordrangeringer og tilbakekoblinger. I AI-først-søk konkurrerer du nå om å bli sitert, syntetisert og synliggjort av språkmodeller i stedet for å konkurrere om faste plasseringer på en søkeresultatside.
Siteringssporing skiller seg fra tradisjonell SEO-synlighet på avgjørende måter. Mens tradisjonell SEO måler din rangering for bestemte søkeord, måler siteringssporing hvordan AI-systemer velger å referere til innholdet ditt når de genererer svar. En sitering i et AI-svar gir kanskje ikke umiddelbar trafikk, men signaliserer innholdets innflytelse og autoritet innen et tema. Utgivere bruker i økende grad siteringssporing for å forstå synlighetsgap, identifisere hvilket innhold som siteres oftest, og måle sin innflytelse i AI-genererte svar. Verktøy som Semrush, Similarweb og spesialiserte AI-overvåkingsplattformer tilbyr nå siteringssporingsfunksjoner, slik at du kan se hvilke av sidene dine som vises i AI-svar og hvor ofte de siteres sammenlignet med konkurrenter. Disse dataene hjelper deg å forstå hvilket innhold som treffer hos AI-systemene og former innholdsstrategien din for AI-første-epoken.
Fremtidsperspektiv og semantisk deduplisering
Google utvikler gradvis semantiske dedupliseringssystemer for å gjenkjenne når innhold er meningsmessig likt, selv om det er omskrevet. Disse systemene har som mål å identifisere semantisk ekvivalent innhold og konsolidere rangeringer rundt den opprinnelige kilden. Den kritiske utfordringen er imidlertid tempo: AI-generert innhold øker langt raskere enn Googles filtre utvikles. Innen de semantiske dedupliseringssystemene modnes, vil tusenvis av nye AI-genererte varianter allerede være laget og indeksert.
Vinnerne i dette landskapet vil være utgivere som eier sin nisje gjennom proprietære data og forskning, distinkte formater og rammeverk, og unike førstepartsinnsikter som AI ikke lett kan syntetisere. Disse utgiverne skaper forsvarbare vollgraver som AI-systemer ikke kan kopiere. De finner på originale begreper, publiserer eksklusive data og bygger genuin ekspertise som blir umulig å gjenskape. Taperne vil være de som baserer seg på generisk, tekstbasert innhold uten forsvarbar fordel. Etter hvert som AI akselererer innholdsproduksjonen, blir originalitet, ekspertise og merkevareautoritet de avgjørende faktorene som skiller nettsteder som vokser fra de som forsvinner. Fremtiden tilhører utgivere som forstår at i en AI-først-verden er unik verdi og ekte ekspertise de eneste bærekraftige konkurransefortrinnene. Innhold som enkelt kan omskrives og gjenbrukes vil bli en vare, mens innhold støttet av original forskning, proprietære data og ekte autoritet vil få premium synlighet både i tradisjonelt søk og AI-genererte svar.
Vanlige spørsmål
Hva er egentlig AI-innholdskannibalisering?
AI-innholdskannibalisering oppstår når kunstige intelligenssystemer skraper og omskriver ditt originale innhold til semantisk like varianter som konkurrerer med dine originale sider i søkeresultater og AI-genererte svar. I motsetning til tradisjonelt duplisert innhold som kopierer tekst ord for ord, bruker AI-genererte versjoner ulik formulering mens de beholder samme mening, slik at de omgår plagiatkontroller.
Hvordan skiller AI-innholdskannibalisering seg fra duplisert innhold?
AI-kannibalisering involverer omskrevet innhold som passerer plagiatsjekker, men likevel svekker autoriteten, mens duplisert innhold er nøyaktige kopier som er lettere å oppdage og undertrykke. AI-genererte sider fremstår som 'originale' for søkemotorer selv om de er basert på ditt arbeid, noe som gjør dem mye vanskeligere å identifisere og fikse enn tradisjonelle duplikater.
Det fører til SERP-flooding (flere lignende resultater konkurrerer), tematisk forvirring (søkemotorer klarer ikke å bestemme autoritet), klikklekkasje (trafikk går til AI-genererte kopier) og reduserer synligheten din i AI Overviews. Innholdet ditt mater AI-modeller som så genererer konkurrerende svar uten korrekt attribusjon, splitter rangeringssignaler og svekker din autoritet.
Hvordan kan jeg oppdage om innholdet mitt blir kannibalisert av AI?
Bruk verktøy for semantisk likhet og embedding-modeller for å oppdage omskrevne duplikater, overvåk Google Search Console for uforklarlige fall i trafikk, sjekk AI Overview-resultater for unattribuert formulering som ligner din, og sett opp varsler for skrapede RSS-feeder. Verktøy som Semrush og Similarweb tilbyr semantisk analyse spesielt utviklet for dette formålet.
Hva er den beste måten å beskytte innholdet mitt mot AI-kannibalisering?
Publiser proprietære data og originale innsikter AI ikke lett kan reprodusere, finn på unike begreper og bruk dem konsekvent, legg til schema markup (FAQ, HowTo, Article), oppdater innholdet ofte for å signalisere aktualitet, og vannmerk visuelle elementer og data. Disse forsvarbare eiendelene skaper en vollgrav mot kannibalisering og gir brukerne en grunn til å besøke din originale kilde.
Hvilken rolle spiller AI-siteringssporing i innholdskannibalisering?
Siteringssporing hjelper deg å overvåke hvor innholdet ditt dukker opp i AI-genererte svar, forstå synligheten din i AI-systemer og identifisere når AI-systemer siterer konkurrenter i stedet for deg. Disse dataene hjelper deg å forstå hvilket innhold som treffer hos AI-systemer og informerer strategien din for AI-første-epoken.
Vil Google fikse problemet med AI-innholdskannibalisering?
Google utvikler semantiske dedupliseringssystemer for å kjenne igjen når innhold er meningsmessig likt, selv om det er omskrevet. AI-innholdsgenerering øker imidlertid mye raskere enn filtrene utvikles. Det beste forsvaret er å lage forsvarbart, originalt innhold som AI-systemer ikke lett kan reprodusere.
Hvordan henger AI-innholdskannibalisering sammen med innholdsdistribusjonsstrategi?
Det understreker viktigheten av strategisk innholdsdistribusjon på tvers av flere kanaler og å sikre at ditt originale innhold blir sitert og kreditert i AI-systemer. Utgivere må nå konkurrere om å bli sitert av AI-systemer i stedet for bare å rangere i tradisjonelt søk, noe som gjør innholdskvalitet og originalitet viktigere enn noensinne.
Overvåk dine AI-siteringer med AmICited
Beskytt merkevarens synlighet i AI-drevet søk. Spor hvordan AI-systemer siterer innholdet ditt på tvers av Google AI Overviews, ChatGPT, Perplexity og mer. Forstå hvor innholdet ditt dukker opp i AI-genererte svar og sikre korrekt attribusjon.
Hva er innholdskannibalisering i AI-søk og hvordan påvirker det rangeringer
Lær hva innholdskannibalisering i AI-søk betyr, hvordan det påvirker merkevarens synlighet i AI-svar, og hvorfor det er viktig å overvåke innholdsoverlapping fo...
Slik fikser du søkeordkannibalisering for AI-søkemotorer
Lær hvordan du identifiserer og fikser søkeordkannibalisering som påvirker synligheten din i AI-søkemotorer som ChatGPT, Perplexity og Gemini. Oppdag konsolider...
Innholdskannibalisering er når flere nettsider konkurrerer om de samme nøkkelordene, noe som svekker autoritet og rangeringer. Lær å identifisere og løse dette ...
10 min lesing
Informasjonskapselsamtykke Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.