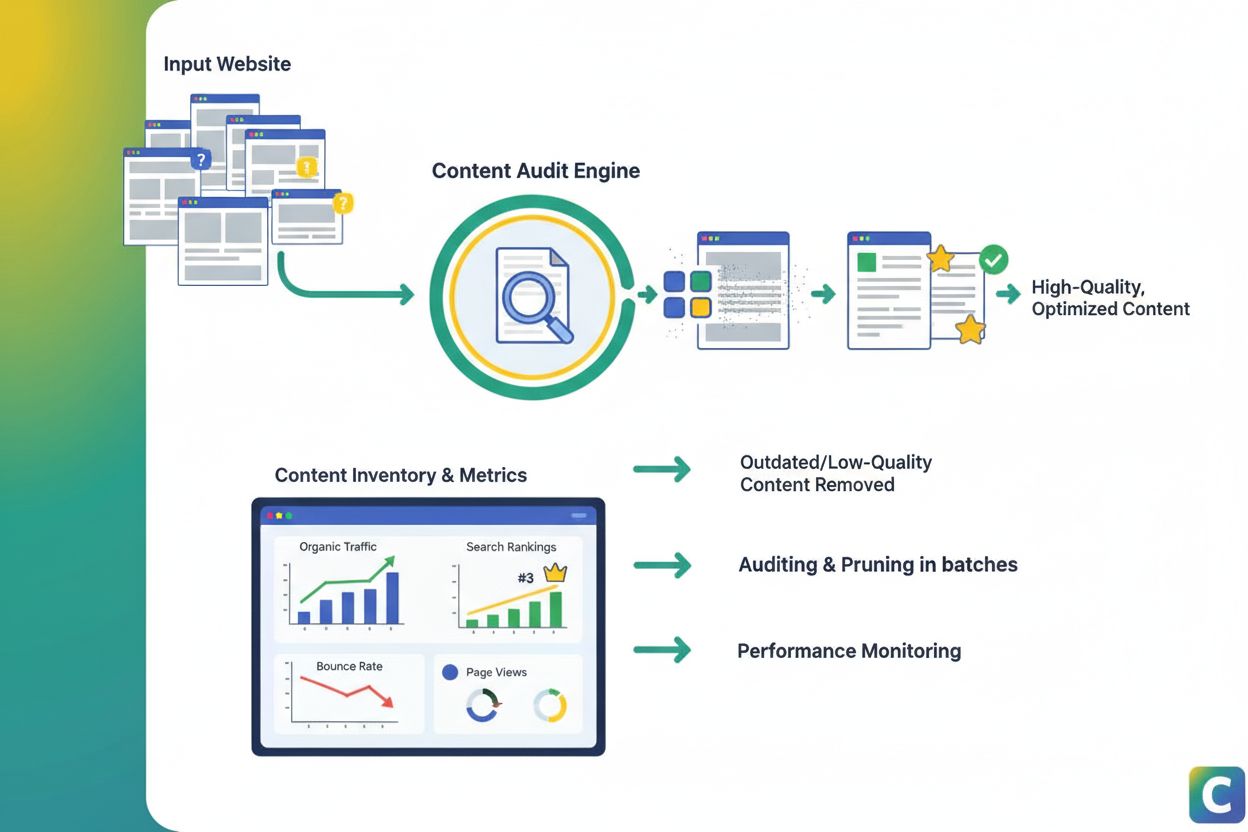
Innholdsbeskjæring
Innholdsbeskjæring er strategisk fjerning eller oppdatering av innhold som presterer dårlig for å forbedre SEO, brukeropplevelse og synlighet i søk. Lær hvordan...
14 min lesing
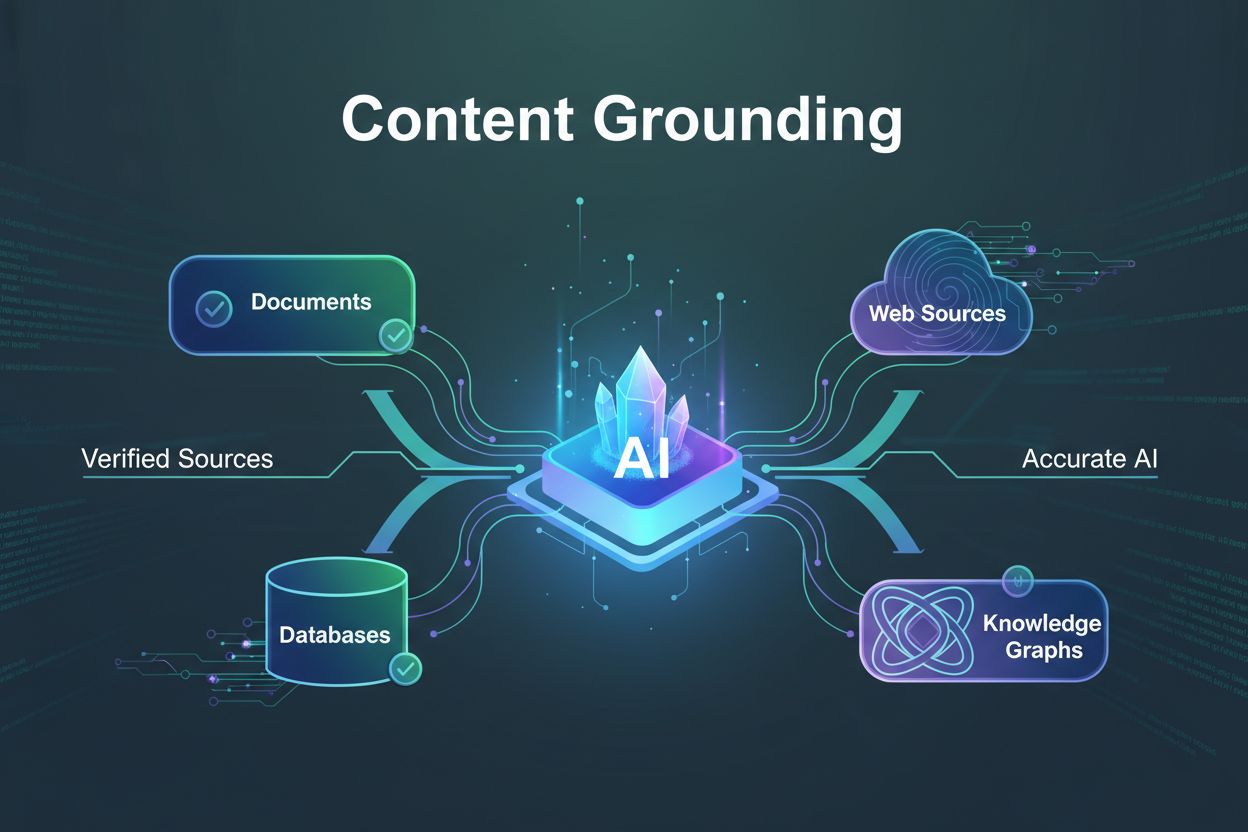
Innholdsforankring er prosessen med å forankre AI-genererte svar til verifiserte, faktabaserte informasjonskilder, for å sikre nøyaktighet og forhindre hallusinasjoner. Det kobler AI-utdata til pålitelige datakilder, kunnskapsbaser og sanntidssystemer for å opprettholde faktuell nøyaktighet og troverdighet. Denne teknikken er avgjørende for applikasjoner der nøyaktighet påvirker brukersikkerhet, økonomiske beslutninger eller profesjonelle resultater. Ved å implementere innholdsforankring reduserer organisasjoner spredning av feilinformasjon dramatisk og øker brukernes tillit til AI-systemer.
Innholdsforankring er prosessen med å forankre AI-genererte svar til verifiserte, faktabaserte informasjonskilder, for å sikre nøyaktighet og forhindre hallusinasjoner. Det kobler AI-utdata til pålitelige datakilder, kunnskapsbaser og sanntidssystemer for å opprettholde faktuell nøyaktighet og troverdighet. Denne teknikken er avgjørende for applikasjoner der nøyaktighet påvirker brukersikkerhet, økonomiske beslutninger eller profesjonelle resultater. Ved å implementere innholdsforankring reduserer organisasjoner spredning av feilinformasjon dramatisk og øker brukernes tillit til AI-systemer.
Innholdsforankring er prosessen med å forankre svar generert av kunstig intelligens til verifiserte, faktabaserte informasjonskilder i stedet for å la modeller generere innhold som høres plausibelt ut, men som potensielt er unøyaktig. Denne teknikken adresserer direkte hallusinasjonsproblemet, der store språkmodeller produserer selvsikre, men falske eller misvisende opplysninger som fremstår troverdige for brukere. Ved å koble AI-utdata til pålitelige datakilder, kunnskapsbaser og sanntidsinformasjonssystemer sikrer innholdsforankring at generert innhold forblir faktuelt korrekt og troverdig. Den viktigste fordelen ved å implementere innholdsforankring er den dramatiske reduksjonen i spredning av feilinformasjon, noe som er avgjørende for applikasjoner der nøyaktighet direkte påvirker brukersikkerhet, økonomiske beslutninger eller profesjonelle resultater. Organisasjoner som implementerer innholdsforankring rapporterer økt brukertillit og reduserte ansvarsrisikoer knyttet til AI-generert innhold.
Innholdsforankring gir betydelig forretningsverdi på tvers av flere bransjer og brukstilfeller, og transformerer hvordan organisasjoner bruker AI-systemer i kundeorienterte og forretningskritiske applikasjoner:
Helsevesen og medisinske tjenester: Forankrede AI-systemer gir korrekt medikamentinformasjon, behandlingsanbefalinger og diagnostisk støtte ved å referere til verifiserte medisinske databaser og kliniske retningslinjer, og reduserer risikoen for skadelig feilinformasjon som kan påvirke pasientutfall.
Finansielle tjenester og bank: Finansinstitusjoner bruker forankret AI til å levere nøyaktige rentesatser, lånevilkår, samsvarsinformasjon og markedsdata, og sikrer regulatorisk etterlevelse og beskytter kundene mot villedende finansiell rådgivning.
Juridisk og samsvar: Advokatfirmaer og bedriftsjuridiske avdelinger benytter forankret AI til å sitere spesifikke lover, rettspraksis og regulatoriske krav, og opprettholder nøyaktigheten som er nødvendig for juridisk dokumentasjon og reduserer risikoen for feilbehandling.
Kundeservice og support: E-handelsselskaper og SaaS-bedrifter implementerer forankrede AI-chatboter som refererer til faktiske produktspesifikasjoner, priser, lagersystemer og støttedokumentasjon, og forbedrer kundetilfredshet samt reduserer eskalering av supportsaker.
Utdanning og opplæring: Utdanningsinstitusjoner bruker forankrede AI-læringssystemer som siterer lærebøker, akademiske kilder og verifisert læremateriell, slik at studenter får korrekt informasjon og utvikler kritisk tenkning om kildehenvisninger.
Den tekniske implementeringen av innholdsforankring benytter flere distinkte metodologier, hver med sine fordeler og begrensninger avhengig av brukstilfelle og dataarkitektur. Tabellen nedenfor sammenligner de viktigste forankringsteknikkene som for tiden er i bruk i produksjonssystemer:
| Forankringsteknikk | Beskrivelse | Primære brukstilfeller | Viktigste fordeler | Begrensninger |
|---|---|---|---|---|
| Retrieval-Augmented Generation (RAG) | Kombinerer dokumenthenting med språkmodellgenerering, henter relevant informasjon før svar genereres | Kundesupport, kunnskapsbase-søk, FAQ-systemer | Svært nøyaktig for strukturerte data, reduserer hallusinasjoner betraktelig | Krever velorganiserte kunnskapsbaser, forsinkelse fra hentesteg |
| Kunnskapsgrafintegrasjon | Bygger inn strukturerte semantiske relasjoner mellom enheter og fakta i genereringen | Helsesystemer, finansielle tjenester, kunnskapsstyring i bedrift | Fanger opp komplekse relasjoner, muliggjør resonnement på tvers av domener | Kostbart å bygge og vedlikeholde, krever domenekompetanse |
| Sanntidsdatabinding | Knytter AI-modeller direkte til levende databaser og API-er for oppdatert informasjon | Finansmarkeder, lagersystemer, værtjenester, sanntidsprising | Gir alltid oppdatert informasjon, eliminerer foreldede data | Krever robust API-infrastruktur, potensielle forsinkelsesproblemer |
| Sitering og attribusjon | Kobler generert innhold eksplisitt til kildedokumenter med sidetall og referanser | Juridiske dokumenter, akademisk skriving, forskningssyntese | Gir åpenhet og verifiserbarhet, bygger brukertillit | Krever tilgjengelig kildemateriale, øker svarenes kompleksitet |
Disse teknikkene kan kombineres i hybride tilnærminger for å maksimere nøyaktighet og relevans for spesifikke organisasjonsbehov.
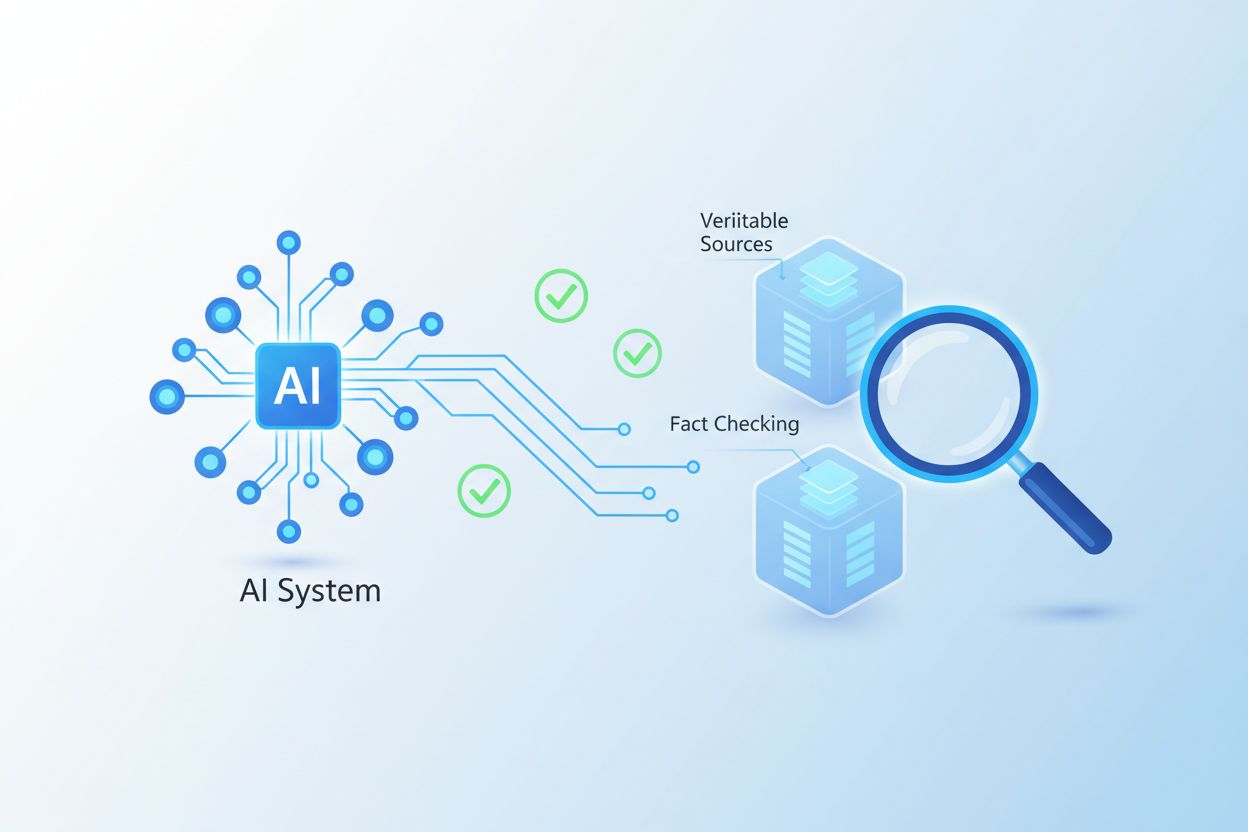
Å implementere innholdsforankring krever at man velger og kombinerer spesifikke teknikker tilpasset organisasjonens behov og datainfrastruktur. Retrieval-Augmented Generation (RAG) er den mest utbredte tilnærmingen, der AI-systemer først søker relevante dokumenter eller databaser før de genererer svar, slik at utdata forblir forankret i verifisert informasjon. Semantisk søk forbedrer RAG ved å forstå meningen bak forespørsler i stedet for kun søkeord, og øker relevansen av hentet informasjon. Faktaverifiseringslag gir ytterligere validering ved å kryssjekke genererte påstander mot flere autoritative kilder før de presenteres for brukerne. Dynamisk kontekstinjeksjon gjør det mulig for systemer å inkludere sanntidsdata fra API-er og databaser direkte i genereringsprosessen, slik at svarene reflekterer oppdatert informasjon i stedet for treningsdata fra måneder eller år tilbake. Organisasjoner som implementerer disse teknikkene ser ofte 40–60 % reduksjon i faktiske feil sammenlignet med ikke-forankrede basissystemer. Valg av implementering avhenger av faktorer som datamengde, krav til svartid, domenekompleksitet og tilgjengelige datakrefter.
Forskjellen mellom forankret innhold og hallusinert innhold utgjør et grunnleggende skille i AI-pålitelighet og troverdighet. Hallusinasjoner oppstår når språkmodeller genererer informasjon som høres plausibel ut, men som ikke har grunnlag i treningsdata eller tilgjengelige kunnskapskilder—for eksempel at en medisinsk AI finner opp en fiktiv legemiddelinteraksjon eller at en finansbot siterer ikke-eksisterende rentesatser. Forankrede systemer forhindrer dette ved å kreve at alle faktapåstander kan spores til en verifisert kilde, og skaper en reviderbar beviskjede. Tenk på et kundeservicescenario: en ikke-forankret AI kan selvsikkert hevde at et produkt har en funksjon det faktisk ikke har, mens et forankret system kun refererer til funksjoner dokumentert i den faktiske produktspesifikasjonsdatabasen. I helseapplikasjoner blir konsekvensene enda mer kritiske—et forankret system vil nekte å anbefale en behandling som ikke støttes av kliniske retningslinjer, mens et ikke-forankret system kan generere plausibel, men farlig medisinsk rådgivning. Den psykologiske effekten av hallusinasjoner er spesielt insidøs fordi brukerne ofte ikke kan skille sikre usannheter fra korrekt informasjon, noe som gjør forankring essensiell for å opprettholde institusjonell troverdighet. Forskning fra ledende AI-leverandører viser at forankring reduserer faktiske feilrater med 70–85 % i produksjonssystemer.

Virkelige anvendelser av innholdsforankring viser dens transformerende innvirkning på tvers av ulike sektorer og organisasjonskontekster. I helsevesenet forankrer systemer fra ledende medisinske AI-selskaper nå diagnostiske støtteverktøy i fagfellevurdert litteratur og kliniske studiedatabaser, slik at leger får evidensbaserte anbefalinger med full kildehenvisning. Finansinstitusjoner implementerer forankret AI for regulatorisk etterlevelse, der alle uttalelser om rentesatser, gebyrer eller investeringsprodukter må referere til oppdaterte prisingdatabaser og samsvarsdokumentasjon, og reduserer regulatoriske brudd og kundetvister. Juridiske avdelinger bruker forankrede systemer til å generere kontraktsspråk og juridiske notater som siterer spesifikke lover og rettspraksis, der alle referanser kan verifiseres i autoritative juridiske databaser. Kundesupportavdelinger hos store e-handelsselskaper implementerer forankrede chatboter som refererer til levende lagersystemer, prisingdatabaser og produktspesifikasjonsdokumenter, og reduserer kundefrustrasjon fra uriktig informasjon. Læringsplattformer implementerer forankrede veiledningssystemer som siterer lærebøker og akademiske kilder, og hjelper studenter å forstå ikke bare svarene, men også det autoritative grunnlaget for dem. Forsikringsselskaper bruker forankret AI til å forklare forsikringsdekning ved å referere til faktiske polisedokumenter og regulatoriske krav, og reduserer kravstvister og øker kundetillit. Disse implementeringene viser jevnlig at forankring gir økt brukertilfredshet, reduserte driftskostnader knyttet til feilretting og betydelig forbedret regulatorisk etterlevelse.
Flere bedriftsplattformer og verktøy har kommet til for å muliggjøre implementering av innholdsforankring, hver med ulike muligheter tilpasset ulike organisasjonsbehov. Google Vertex AI tilbyr innebygd forankring gjennom Search Grounding-funksjonen, slik at virksomheter kan forankre Gemini-modellsvar i Google-søkeresultater og egne kunnskapsbaser, med særlig styrke i sanntidsinformasjon. Microsoft Azure tilbyr forankring via sin Cognitive Search-tjeneste kombinert med språkmodeller, som gjør det mulig å bygge RAG-systemer som refererer til virksomhetsdata med sikkerhet og samsvar i behold. K2View spesialiserer seg på forankring for kundedata-plattformer, og sørger for at AI-genererte kundeinnsikter og anbefalinger er forankret i verifiserte kundedata i stedet for statistiske antakelser. Moveworks implementerer forankring spesielt for IT-support i bedrifter, der AI-agentene forankrer svar i faktiske IT-systemer, kunnskapsbaser og tjenestekataloger for å gi presis teknisk støtte. AmICited.com er en spesialisert overvåkingsløsning for innholdsforankring, som sporer om AI-generert innhold siterer og forankrer påstander i kildemateriale, gir innsikt i forankringseffektivitet og identifiserer tilfeller der AI-systemer genererer påstander uten dekning. Disse plattformene kan implementeres hver for seg eller i kombinasjon, avhengig av organisasjonens arkitektur og spesifikke forankringsbehov.
For å implementere innholdsforankring effektivt kreves en strategisk tilnærming som går utover teknologivalg og omfatter organisasjonsprosesser og kvalitetssikring. Dataklargjøring er grunnleggende—organisasjoner må revidere og strukturere kunnskapskildene sine, slik at informasjonen som brukes til forankring er nøyaktig, oppdatert og ordentlig indeksert for henting. Kildeprioritering handler om å etablere hierarkier av informasjonspålitelighet, der medisinske AI-systemer for eksempel prioriterer fagfellevurderte tidsskrifter over vanlig nettinnhold, mens finansielle systemer prioriterer offisielle regulatoriske databaser. Optimalisering av svartid blir avgjørende i kundeorienterte applikasjoner, og krever at organisasjoner balanserer nøyaktighetsgevinsten ved omfattende forankring mot responstid. Tilbakemeldingssløyfer bør implementeres for å overvåke forankringseffektiviteten kontinuerlig, identifisere tilfeller der hentede kilder ikke støtter genererte påstander godt nok og justere hentestrategiene deretter. Brukeråpenhet innebærer å kommunisere tydelig til sluttbrukere når og hvordan innhold er forankret, og bygge tillit gjennom synlighet i hvilke kilder som støtter AI-generert informasjon. Regelmessige revisjoner med verktøy som AmICited.com hjelper organisasjoner å bekrefte at forankringssystemene fungerer effektivt etter hvert som datakildene utvikler seg og ny informasjon kommer til. Organisasjoner som ser på forankring som en kontinuerlig operasjonell praksis fremfor en engangsimplementering, oppnår betydelig bedre langsiktig nøyaktighet og brukertillit.
Fremtiden for innholdsforankring vil trolig innebære stadig mer sofistikert integrasjon av flere forankringsteknikker, sanntidsdatakilder og verifiseringsmekanismer etter hvert som AI-systemer blir dypere integrert i kritiske beslutningsprosesser. Multimodal forankring er et voksende område, der AI-systemer forankrer svar ikke bare i tekst, men i bilder, videoer og strukturerte data samtidig, og muliggjør mer omfattende verifisering. Desentraliserte verifiseringsnettverk kan etter hvert gjøre det mulig for organisasjoner å verifisere AI-genererte påstander mot distribuerte sannhetskilder, og redusere avhengigheten av sentraliserte kunnskapsbaser. Automatiserte kildeevalueringssystemer er under utvikling for å vurdere pålitelighet og skjevhet i selve forankringskildene, og sikrer at forankring ikke bare viderefører eksisterende skjevheter i kildematerialet. Regulatoriske rammeverk utvikles for å kreve innholdsforankring i høy-risiko-domener som helse og finans, slik at forankring blir et krav og ikke et valg. Etter hvert som disse trendene modnes, vil innholdsforankring gå fra å være et konkurransefortrinn til å bli en grunnleggende forventning for alle AI-systemer i regulerte eller høy-konsekvens-domener, og fundamentalt endre hvordan organisasjoner nærmer seg AI og brukertillit.
Innholdsforankring gir sanntidskontekst uten å trene modellen på nytt, slik at AI-systemer kan referere til oppdatert informasjon og spesifikke datakilder. Finjustering, derimot, endrer modellens atferd permanent gjennom nytrening på nye data. Forankring er raskere å implementere og mer fleksibel for endringer, mens finjustering gir permanente atferdsendringer i modellen.
Innholdsforankring reduserer hallusinasjoner betydelig med 70–85 % i produksjonssystemer, men kan ikke eliminere dem helt. Effektiviteten avhenger av implementeringskvalitet, datakildens nøyaktighet og hvor sofistikerte hente- og verifiseringsmekanismene er. Selv forankrede systemer kan produsere hallusinasjoner hvis kildedataene er ufullstendige eller tvetydige.
Viktige utfordringer inkluderer å sikre datakvalitet og oppdaterte kilder, håndtere forsinkelse fra henteoperasjoner, integrere med eksisterende systemer og opprettholde kildenøyaktighet over tid. Organisasjoner må også etablere prosesser for kontinuerlig overvåking og oppdatering av forankringskilder etter hvert som informasjonen endrer seg.
Innholdsforankring øker åpenheten ved å gi verifiserbare kilder for AI-genererte påstander, slik at brukere kan faktasjekke informasjon uavhengig. Denne synligheten i resonnementet og kildehenvisning bygger tillit til at AI-systemene er pålitelige og ikke fabrikkerer informasjon, og forbedrer brukertilliten betydelig.
De mest effektive forankringskildene inkluderer strukturerte databaser med verifisert informasjon, kunnskapsgrafer med semantiske relasjoner, fagfellevurderte dokumenter og akademiske kilder, sanntids-API-er for oppdatert informasjon og offisielle regulatoriske eller samsvarsdokumenter. Beste valg avhenger av brukstilfelle og ønsket nøyaktighetsnivå.
Innholdsforankring er kritisk for høy-risiko-applikasjoner som helse, finans, juridiske tjenester og regulatorisk samsvar der nøyaktighet direkte påvirker beslutninger. For kreative applikasjoner som skjønnlitteratur eller idégenerering, kan forankring være mindre nødvendig. Nødvendigheten avhenger av om faktuell nøyaktighet er et hovedkrav.
AmICited.com sporer hvordan AI-systemer refererer og siterer kilder på tvers av GPT-er, Perplexity og Google AI Overviews, og gir innsikt i om AI-generert innhold forankrer påstander i verifiserbare kilder. Det hjelper organisasjoner å overvåke merkevareomtaler og sikre at innholdet deres blir korrekt sitert av AI-systemer.
Innholdsforankring medfører noe økt forsinkelse på grunn av hente- og verifiseringsoperasjoner som kreves før svar genereres. Denne ytelseskostnaden oppveies imidlertid som regel av bedre nøyaktighet, reduserte feilrettingskostnader, økt brukertilfredshet og bedre etterlevelse, noe som gjør det til en verdifull avveining for de fleste bedrifter.
Sikre at merkevaren din blir korrekt sitert og at innholdet ditt er forankret i verifiserbare kilder på tvers av GPT-er, Perplexity og Google AI Overviews. Spor hvordan AI-systemer refererer til din informasjon og oppretthold innholdsnøyaktighet.
Innholdsbeskjæring er strategisk fjerning eller oppdatering av innhold som presterer dårlig for å forbedre SEO, brukeropplevelse og synlighet i søk. Lær hvordan...
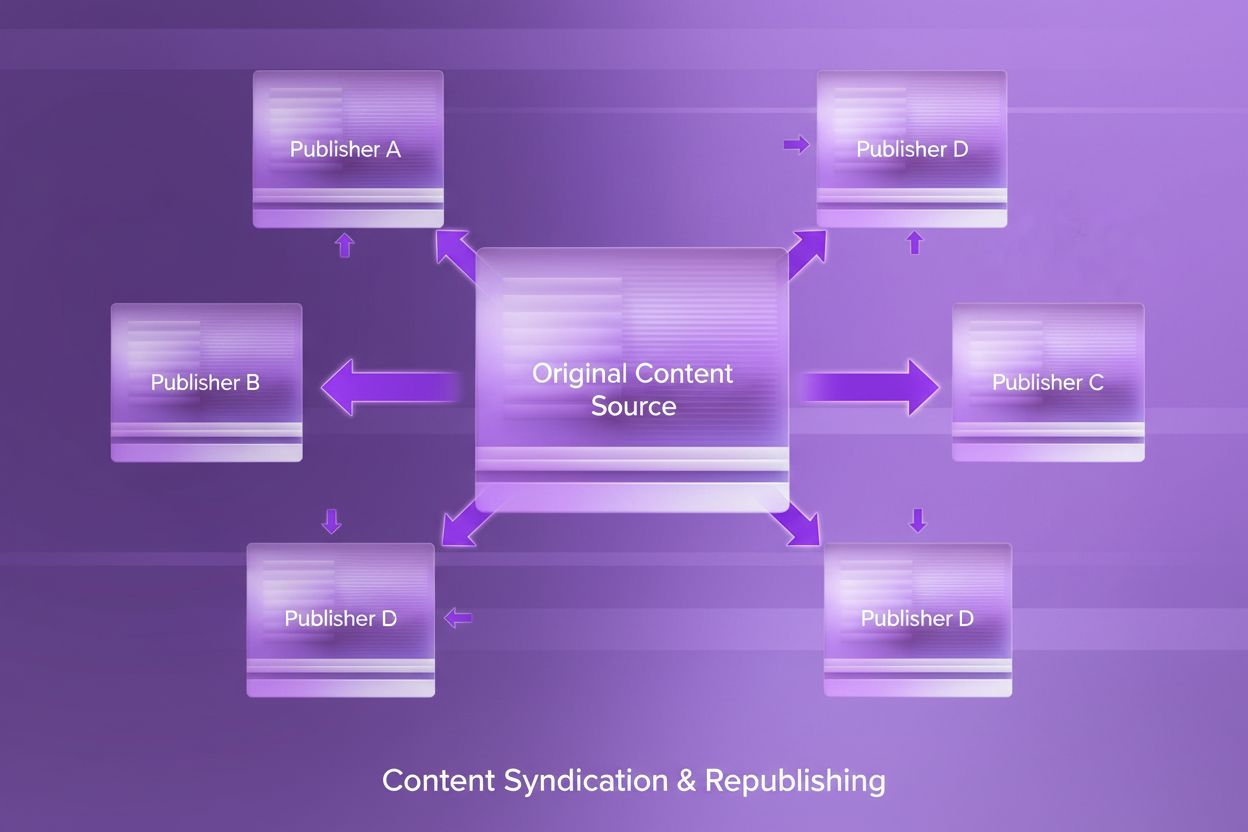
Lær hva innholdssyndikering er, hvordan det fungerer, dets SEO-implikasjoner, og beste praksis for republisering av innhold på tvers av plattformer for å utvide...
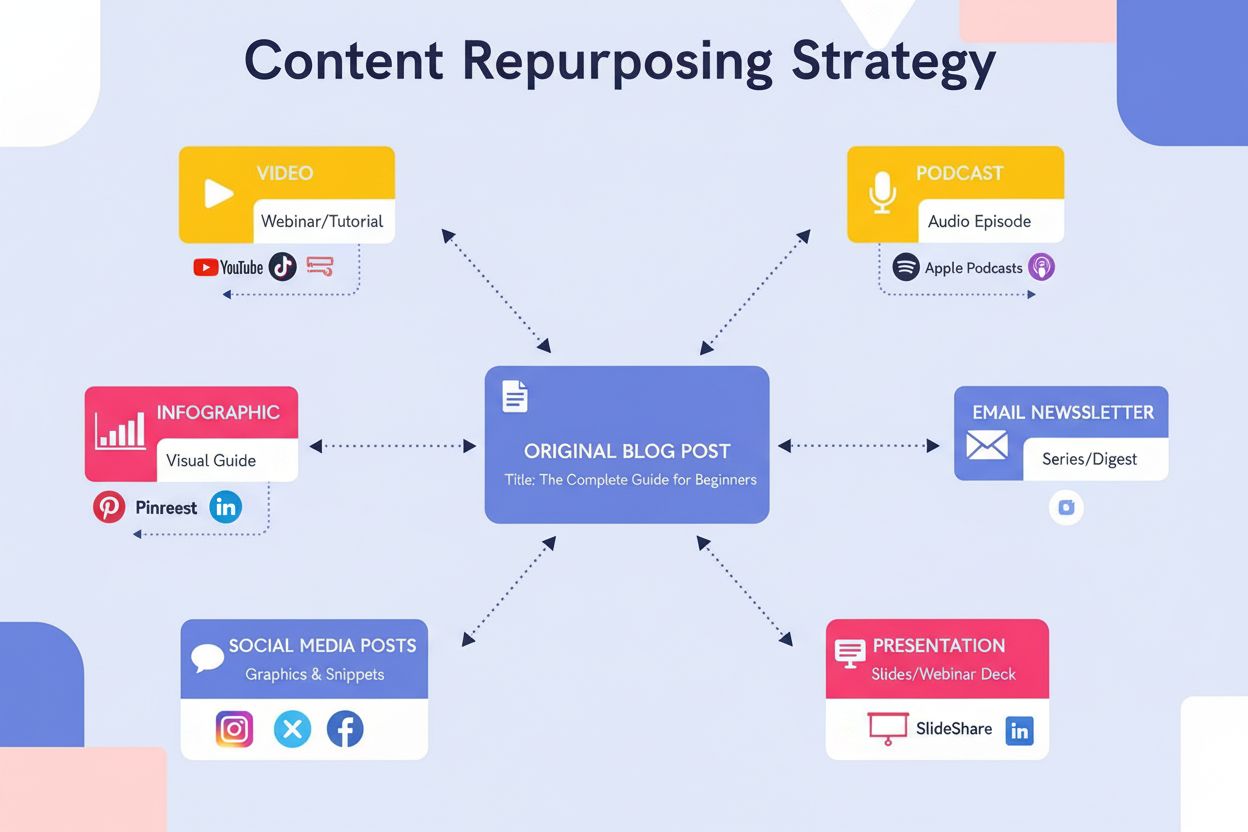
Innholdsrebruk er den strategiske praksisen med å transformere eksisterende innhold til flere formater for nye målgrupper. Lær hvordan du kan maksimere ROI og r...