
Hva er innholdsbeskjæring for KI? Definisjon og teknikker
Lær hva innholdsbeskjæring for KI er, hvordan det fungerer, ulike beskjæringsmetoder og hvorfor det er essensielt for å implementere effektive KI-modeller på ed...
9 min lesing
Konstekstuell bracketing er en innholdsoptimaliseringsteknikk som etablerer klare grenser rundt informasjon for å forhindre AI-feiltolkning og hallusinasjon. Den bruker eksplisitte avgrensere og kontekstmarkører for å sikre at AI-modeller forstår nøyaktig hvor relevant informasjon begynner og slutter, og forhindrer generering av svar basert på antakelser eller oppdiktede detaljer.
Konstekstuell bracketing er en innholdsoptimaliseringsteknikk som etablerer klare grenser rundt informasjon for å forhindre AI-feiltolkning og hallusinasjon. Den bruker eksplisitte avgrensere og kontekstmarkører for å sikre at AI-modeller forstår nøyaktig hvor relevant informasjon begynner og slutter, og forhindrer generering av svar basert på antakelser eller oppdiktede detaljer.
Konstekstuell bracketing er en innholdsoptimaliseringsteknikk som etablerer klare grenser rundt informasjon for å forhindre AI-feiltolkning og hallusinasjon. Metoden innebærer bruk av eksplisitte avgrensere—som XML-tagger, markdown-overskrifter eller spesialtegn—for å markere start og slutt på spesifikke informasjonsblokker, og skape det ekspertene kaller en “kontekstgrense”. Ved å strukturere prompter og data med disse tydelige markørene, sikrer utviklere at AI-modeller forstår nøyaktig hvor relevant informasjon begynner og slutter, og forhindrer at modellen genererer svar basert på antakelser eller oppdiktede detaljer. Konstekstuell bracketing representerer en videreutvikling av tradisjonell prompt engineering, og utvider seg til den bredere disiplinen kontekst engineering, som fokuserer på å optimalisere all informasjon som gis til en LLM for å oppnå ønskede resultater. Teknikken er spesielt verdifull i produksjonsmiljøer hvor nøyaktighet og konsistens er kritisk, da den gir matematiske og strukturelle rekkverk som styrer AI-adferd uten å kreve kompleks betinget logikk.
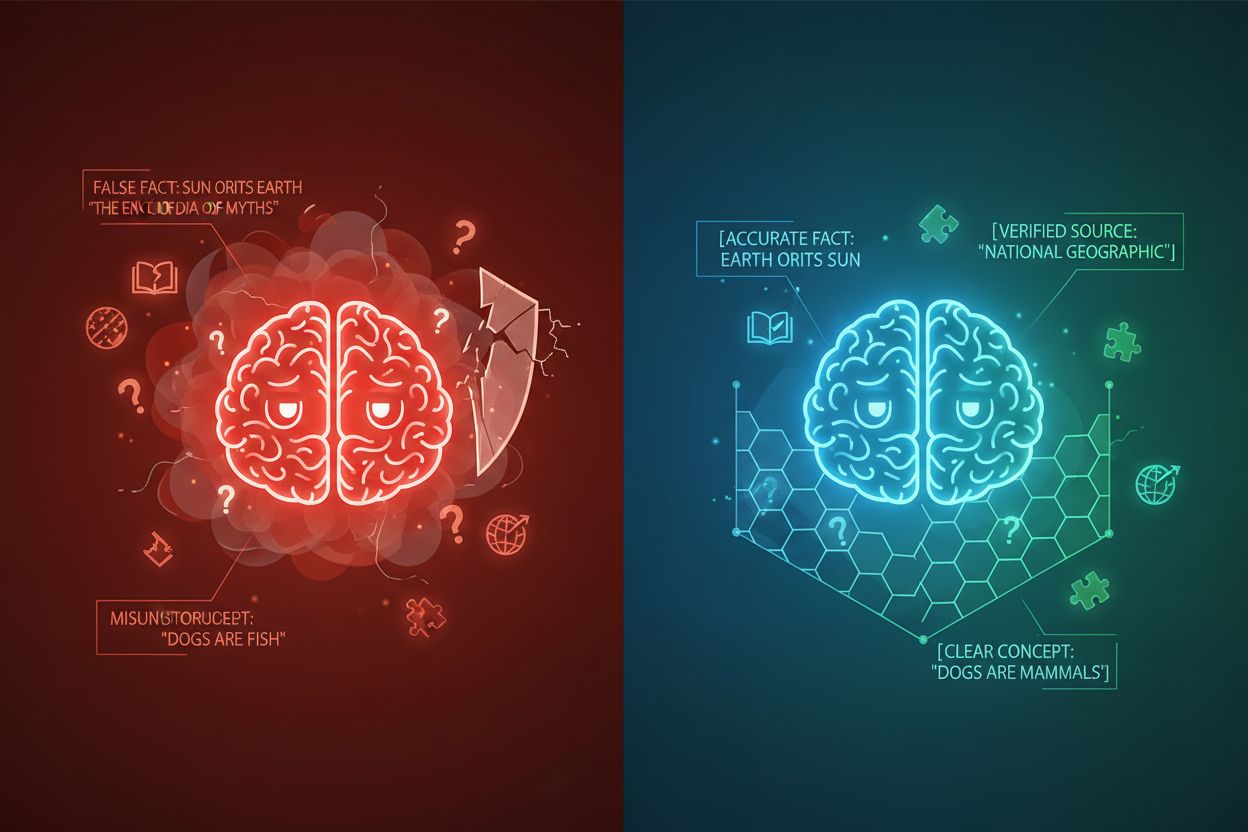
AI-hallusinasjon oppstår når språkmodeller genererer svar som ikke er forankret i faktainformasjon eller den spesifikke konteksten som er gitt, noe som resulterer i feilaktige fakta, misvisende utsagn eller referanser til ikke-eksisterende kilder. Forskning viser at chatboter finner på fakta omtrent 27 % av tiden, med 46 % av tekstene deres som inneholder faktiske feil, mens ChatGPTs sitater i journalistikk var feil 76 % av gangene. Disse hallusinasjonene stammer fra flere kilder: modeller kan lære mønstre fra partisk eller ufullstendig treningsdata, misforstå forholdet mellom tokens, eller mangle tilstrekkelige begrensninger som begrenser mulige utdata. Konsekvensene er alvorlige på tvers av bransjer—i helsevesenet kan hallusinasjoner føre til feil diagnoser og unødvendige medisinske inngrep; i juridiske sammenhenger kan de føre til oppdiktede sakshenvisninger (som sett i Mata v. Avianca-saken hvor en advokat fikk sanksjoner for å ha brukt ChatGPTs falske juridiske sitater); i næringslivet sløser de ressurser gjennom feilaktig analyse og prognoser. Det grunnleggende problemet er at uten klare kontekstgrenser opererer AI-modeller i et informasjonsvakuum der de er mer tilbøyelige til å “fylle hullene” med plausibel, men unøyaktig informasjon, og behandler hallusinasjon som en funksjon snarere enn en feil.
| Hallusinasjonstype | Frekvens | Innvirkning | Eksempel |
|---|---|---|---|
| Faktiske unøyaktigheter | 27–46% | Spredning av feilinformasjon | Falske produktegenskaper |
| Kildeoppfinnelse | 76% (sitater) | Tap av troverdighet | Ikke-eksisterende siteringer |
| Misforståtte konsepter | Variabel | Feil analyse | Feil rettspraksis |
| Partiske mønstre | Pågående | Diskriminerende utdata | Stereotypiske svar |
Effektiviteten til konstekstuell bracketing hviler på fem grunnleggende prinsipper:
Bruk av avgrensere: Bruk konsistente, entydige markører (XML-tagger som <context>, markdown-overskrifter eller spesialtegn) for tydelig å avgrense informasjonsblokker og forhindre at modellen forveksler grenser mellom ulike datakilder eller instruksjonstyper.
Håndtering av kontekstvindu: Tildel tokens strategisk mellom systeminstruksjoner, brukerinput og hentet kunnskap, slik at den mest relevante informasjonen opptar modellens begrensede oppmerksomhetsbudsjett, mens mindre viktige detaljer filtreres ut eller hentes ved behov.
Informasjonshierarki: Etabler tydelige prioriteringsnivåer for ulike typer informasjon, og signaliser til modellen hvilke data som skal behandles som autoritative kilder kontra supplerende kontekst, slik at primær og sekundær informasjon ikke vektes likt.
Grensedefinisjon: Angi eksplisitt hvilken informasjon modellen skal ta hensyn til og hva den skal ignorere, og skape harde stopp som forhindrer modellen fra å trekke slutninger utover oppgitt data eller anta informasjon som ikke er nevnt.
Omfangsmarkører: Bruk strukturelle elementer for å angi omfanget av instruksjoner, eksempler og data, slik at det er tydelig om veiledningen gjelder globalt, for bestemte seksjoner, eller kun for spesifikke spørsmålstyper.
Implementering av konstekstuell bracketing krever nøye oppmerksomhet på hvordan informasjon struktureres og presenteres for AI-modeller. Strukturert inputformatering med JSON- eller XML-skjemaer gir eksplisitte feltdefinisjoner som styrer modellens adferd—f.eks. ved å pakke brukerforespørsler inn i <user_query>-tagger og forventede utdata i <expected_output>-tagger for å skape utvetydige grenser. Systemprompter bør organiseres i distinkte seksjoner ved hjelp av markdown-overskrifter eller XML-tagger: <background_information>, <instructions>, <tool_guidance>, og <output_description> har hver sine spesifikke formål og hjelper modellen med å forstå informasjons-hierarkiet. Få-skuddseksempler bør inkludere bracketed kontekst som viser nøyaktig hvordan modellen skal strukturere sine svar, med klare avgrensere rundt input og output. Verktøydefinisjoner drar fordel av eksplisitte parameterbeskrivelser og bruksbegrensninger, og forhindrer at modellen misbruker verktøy eller anvender dem utenfor tiltenkt omfang. Retrieval-Augmented Generation (RAG)-systemer kan implementere konstekstuell bracketing ved å pakke hentede dokumenter i kildemarkører (<source>document_name</source>) og bruke grounding-scorer for å verifisere at genererte svar holder seg innenfor grensene til hentet informasjon. For eksempel fungerer CustomGPTs kontekstgrense-funksjon ved å trene modeller utelukkende på opplastede datasett, og sikrer at svar aldri beveger seg utenfor den gitte kunnskapsbasen—en praktisk implementering av konstekstuell bracketing på arkitekturnivå.
Selv om konstekstuell bracketing deler likhetstrekk med beslektede teknikker, har den en distinkt posisjon i AI-engineering-landskapet. Grunnleggende prompt engineering fokuserer primært på å utforme effektive instruksjoner og eksempler, men mangler den systematiske tilnærmingen til å håndtere alle kontekstelementer som konstekstuell bracketing tilbyr. Kontekst engineering, den bredere disiplinen, omfatter konstekstuell bracketing som én komponent blant flere—det inkluderer promptoptimalisering, verktøydesign, minnehåndtering og dynamisk kontekst-henting, og utgjør et overordnet sett i forhold til konstekstuell bracketings mer fokuserte tilnærming. Enkel instruksjonsfølge er avhengig av modellens evne til å forstå naturlige språk-direktiver uten eksplisitte strukturelle grenser, noe som ofte feiler når instruksjonene er komplekse eller modellen møter tvetydige situasjoner. Rekkverk og valideringssystemer opererer på output-nivået, og sjekker svarene etter generering, mens konstekstuell bracketing fungerer på input-nivå for å forhindre hallusinasjoner før de oppstår. Den viktigste forskjellen er at konstekstuell bracketing er forebyggende og strukturell—den former informasjonslandskapet modellen opererer innenfor—i stedet for å være korreksjonell eller reaktiv, noe som gjør den mer effektiv og pålitelig for å opprettholde nøyaktighet i produksjonssystemer.
Konstekstuell bracketing gir målbar verdi på tvers av ulike applikasjoner. Kundeservice-chatboter bruker kontekstgrenser for å begrense svar til virksomhetens godkjente kunnskapsbaser, og forhindrer at agenter finner opp produktegenskaper eller gir uautoriserte løfter. Systemer for juridisk dokumentanalyse bracket relevante rettsavgjørelser, lover og presedenser, og sikrer at AI-en kun refererer til verifiserte kilder og ikke finner opp juridiske siteringer. Medisinske AI-systemer implementerer strenge kontekstgrenser rundt kliniske retningslinjer, pasientdata og godkjente behandlingsprotokoller, og forhindrer farlige hallusinasjoner som kan skade pasienter. Plattformer for innholdsgenerering bruker konstekstuell bracketing for å håndheve merkevareretningslinjer, tonekrav og faktakrav, og sikrer at generert innhold samsvarer med organisasjonens standarder. Forsknings- og analyserverktøy bracket primærkilder, datasett og verifisert informasjon, slik at AI kan syntetisere innsikt med tydelig kildehenvisning og unngå å finne opp falsk statistikk eller studier. AmICited.com eksemplifiserer dette prinsippet ved å overvåke hvordan AI-systemer siterer og refererer til merkevarer på tvers av GPT-er, Perplexity og Google AI Overviews—de sporer om AI-modeller holder seg innenfor passende kontekstgrenser når de omtaler spesifikke selskaper eller produkter, og hjelper organisasjoner med å forstå om AI-systemer hallusinerer om merkevaren deres eller representerer informasjonen nøyaktig.
For å lykkes med konstekstuell bracketing må man følge velprøvde beste praksiser:
Start med minimal kontekst: Begynn med det minste nødvendige settet med informasjon for å gi nøyaktige svar, og utvid kun når testing avdekker mangler—dette forhindrer kontekstforurensning og opprettholder modellens fokus.
Bruk konsistente avgrensermønstre: Etabler og oppretthold ensartede avgrenserkonvensjoner i hele systemet, slik at modellen lettere gjenkjenner grenser og forvirring fra inkonsekvent formatering reduseres.
Test og valider grenser: Test systematisk om modellen respekterer definerte grenser ved å forsøke å få den til å gå ut over dem, og identifiser og tette hull før produksjonssetting.
Overvåk for kontekstdrift: Følg kontinuerlig med om modellens svar holder seg innenfor tiltenkte grenser over tid, siden modelladferd kan skifte med ulike inputmønstre eller når kunnskapsbaser utvikler seg.
Implementer tilbakemeldingssløyfer: Lag mekanismer for brukere eller menneskelige gjennomlesere til å flagge tilfeller der modellen har overskredet sine grenser, og bruk denne tilbakemeldingen til å forbedre kontekstdefinisjoner og fremtidig ytelse.
Versjoner kontekstdefinisjonene dine: Behandle kontekstgrenser som kode, med versjonshistorikk og dokumentasjon av endringer, slik at du kan rulle tilbake hvis nye grensedefinisjoner gir dårligere resultater.
Flere plattformer har bygget inn støtte for konstekstuell bracketing i sine kjerneprodukter. CustomGPT.ai implementerer kontekstgrenser gjennom sin “kontekstgrense”-funksjon, som fungerer som en beskyttende vegg som sikrer at AI-en kun bruker data gitt av brukeren, og aldri går ut i generell kunnskap eller finner på informasjon—denne tilnærmingen har vist seg effektiv for organisasjoner som MIT, som krever absolutt nøyaktighet i kunnskapslevering. Anthropic’s Claude fremhever prinsipper for kontekst engineering, og tilbyr detaljert dokumentasjon om hvordan man strukturerer prompter, håndterer kontekstvinduer og implementerer rekkverk som holder svar innen definerte grenser. AWS Bedrock Guardrails tilbyr automatiserte resonneringskontroller som verifiserer generert innhold mot matematiske, logikkbaserte regler, med grounding-scorer som indikerer om svar holder seg til kildematerialet (scorer over 0,85 kreves for finansapplikasjoner). Shelf.io tilbyr RAG-løsninger med kontekstadministrasjon, slik at organisasjoner kan implementere retrieval-augmented generation med strenge grenser for hvilken informasjon modellen får tilgang til og kan referere til. AmICited.com har en komplementær rolle ved å overvåke hvordan AI-systemer siterer og refererer til merkevaren din på tvers av flere AI-plattformer, og hjelper deg å forstå om AI-modeller respekterer riktige kontekstgrenser når de omtaler organisasjonen din eller holder seg til nøyaktig, verifisert informasjon om merkevaren—og gir dermed innsikt i om konstekstuell bracketing fungerer effektivt i praksis.
Prompt engineering fokuserer primært på å utforme effektive instruksjoner og eksempler, mens konstekstuell bracketing er en systematisk tilnærming til å håndtere alle kontekstelementer gjennom eksplisitte avgrensere og grenser. Konstekstuell bracketing er mer strukturert og forebyggende, og arbeider på inputnivå for å forhindre hallusinasjoner før de oppstår, mens prompt engineering er bredere og inkluderer ulike optimaliseringsteknikker.
Konstekstuell bracketing forhindrer hallusinasjoner ved å etablere klare informasjonsgrenser med avgrensere som XML-tagger eller markdown-overskrifter. Dette forteller AI-modellen nøyaktig hvilken informasjon den skal ta hensyn til og hva den skal ignorere, og forhindrer at den finner på detaljer eller antar informasjon som ikke er oppgitt. Ved å begrense modellens oppmerksomhet til definerte grenser, reduseres sannsynligheten for å generere falske fakta eller ikke-eksisterende kilder.
Vanlige avgrensere inkluderer XML-tagger (som
Prinsippene for konstekstuell bracketing kan brukes på de fleste moderne språkmodeller, selv om effektiviteten varierer. Modeller som er trent med bedre evne til å følge instruksjoner (som Claude, GPT-4 og Gemini) har en tendens til å respektere grenser mer pålitelig. Teknikken fungerer best når den kombineres med modeller som støtter strukturerte utdata og er trent på mangfoldig, godt formatert data.
Start med å organisere systemprompter i distinkte seksjoner ved hjelp av klare avgrensere. Strukturer input og output med JSON- eller XML-skjemaer. Bruk konsistente avgrensermønstre overalt. Implementer få-skuddseksempler som viser modellen nøyaktig hvordan den skal respektere grenser. Test grundig for å sikre at modellen respekterer definerte grenser, og overvåk ytelsen over tid for å oppdage kontekstdrift.
Konstekstuell bracketing kan øke tokenbruket noe på grunn av ekstra avgrensere og strukturelle markører, men dette oppveies vanligvis av forbedret nøyaktighet og færre hallusinasjoner. Teknikken forbedrer faktisk effektiviteten ved å forhindre at modellen bruker tokens på oppdiktet informasjon. I produksjonssystemer veier nøyaktighetsgevinstene langt tyngre enn den minimale tokenkostnaden.
Konstekstuell bracketing og RAG er komplementære teknikker. RAG henter relevant informasjon fra eksterne kilder, mens konstekstuell bracketing sørger for at modellen holder seg innenfor grensene til den hentede informasjonen. Sammen skaper de et kraftfullt system hvor modellen kan få tilgang til ekstern kunnskap, samtidig som den kun refererer til verifiserte, hentede kilder.
Flere plattformer har innebygd støtte: CustomGPT.ai tilbyr funksjoner for kontekstgrenser, Anthropic's Claude har dokumentasjon for kontekst-engineering og støtte for strukturerte utdata, AWS Bedrock Guardrails inkluderer automatiserte resonneringskontroller, og Shelf.io tilbyr RAG med kontekstadministrasjon. AmICited.com overvåker hvordan AI-systemer siterer merkevaren din, og hjelper deg å verifisere at konstekstuell bracketing fungerer effektivt.
Konstekstuell bracketing sikrer at AI-systemer gir nøyaktig informasjon om din merkevare. Bruk AmICited for å spore hvordan AI-modeller siterer og refererer til innholdet ditt på tvers av GPT-er, Perplexity og Google AI Overviews.
Lær hva innholdsbeskjæring for KI er, hvordan det fungerer, ulike beskjæringsmetoder og hvorfor det er essensielt for å implementere effektive KI-modeller på ed...

Lær hvordan AI-systemer reduserer innholdets relevansscore over tid gjennom algoritmer for ferskhetsforringelse. Forstå tidsbaserte forringelsesfunksjoner, over...

Lær hvordan strategisk statistikkinnsprøytning forbedrer AI-siteringer. Oppdag hvorfor AI-systemer foretrekker datadrevet innhold og hvordan du implementerer st...