
Hvordan undersøker jeg AI-søkespørringer?
Lær hvordan du undersøker og overvåker AI-søkespørringer på tvers av ChatGPT, Perplexity, Claude og Gemini. Oppdag metoder for å spore merkevareomtaler og optim...
8 min lesing
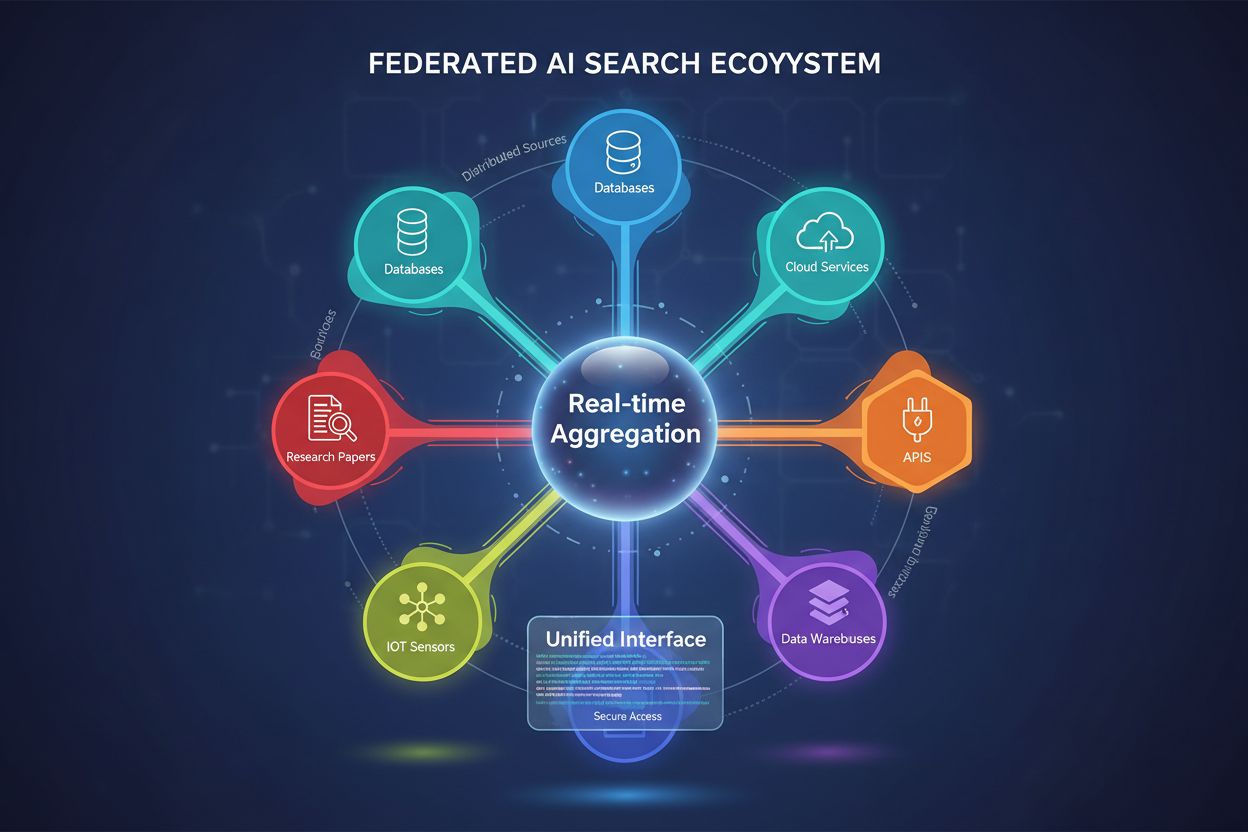
Føderert AI-søk er et system som søker i flere uavhengige datakilder samtidig med én enkelt søkespørring og samler resultater i sanntid uten å flytte eller duplisere data. Det gjør det mulig for organisasjoner å få tilgang til distribuert informasjon på tvers av databaser, API-er og skytjenester, samtidig som datasikkerhet og etterlevelse opprettholdes. I motsetning til tradisjonelle sentraliserte søkemotorer, bevarer fødererte systemer datakildenes autonomi samtidig som de gir enhetlig informasjonsoppdagelse. Denne tilnærmingen er spesielt verdifull for virksomheter som håndterer ulike datakilder på tvers av avdelinger, geografier eller organisasjoner.
Føderert AI-søk er et system som søker i flere uavhengige datakilder samtidig med én enkelt søkespørring og samler resultater i sanntid uten å flytte eller duplisere data. Det gjør det mulig for organisasjoner å få tilgang til distribuert informasjon på tvers av databaser, API-er og skytjenester, samtidig som datasikkerhet og etterlevelse opprettholdes. I motsetning til tradisjonelle sentraliserte søkemotorer, bevarer fødererte systemer datakildenes autonomi samtidig som de gir enhetlig informasjonsoppdagelse. Denne tilnærmingen er spesielt verdifull for virksomheter som håndterer ulike datakilder på tvers av avdelinger, geografier eller organisasjoner.
Føderert AI-søk er et distribuert informasjonshentingssystem som samtidig søker i flere heterogene datakilder og intelligent samler resultater ved hjelp av kunstig intelligens. I motsetning til tradisjonelle sentraliserte søkemotorer som har ett enkelt indeksert lager, opererer føderert AI-søk på tvers av desentraliserte nettverk av uavhengige databaser, kunnskapsbaser og informasjonssystemer uten krav om datakonsolidering eller sentralisert indeksering.
Kjerneprinsippet bak føderert AI-søk er kildeagnostisk spørring, der en enkelt brukerspørring intelligent rutes til relevante datakilder, behandles uavhengig av hver kilde, og deretter syntetiseres til et enhetlig resultatsett. Denne tilnærmingen bevarer dataautonomi samtidig som den muliggjør helhetlig informasjonsoppdagelse på tvers av organisatoriske og tekniske grenser.
Nøkkeltrekk for fødererte AI-søkesystemer inkluderer:
Distribuert arkitektur: Data forblir på sitt opprinnelige sted i flere lagre, noe som eliminerer behovet for datamigrering eller sentralisert lagring. Hver kilde vedlikeholder sin egen indeksering, tilgangskontroll og oppdateringsmekanismer uavhengig.
Intelligent ruting av spørringer: AI-algoritmer analyserer innkommende spørringer for å avgjøre hvilke kilder som sannsynligvis inneholder relevant informasjon, og optimaliserer søkeeffektiviteten ved å redusere unødvendige spørringer til irrelevante databaser.
Resultataggregering og rangering: Maskinlæringsmodeller syntetiserer resultater fra flere kilder og anvender avanserte rangeringsalgoritmer som tar hensyn til kildens troverdighet, resultatets relevans, ferskhet og brukerkontekst.
Støtte for heterogene kilder: Fødererte systemer håndterer ulike dataformater, skjemaer, spørringsspråk og tilgangsprotokoller, inkludert relasjonsdatabaser, dokumentlagre, kunnskapsgrafer, API-er og ustrukturerte tekstlagre.
Sanntidsintegrasjon: I motsetning til batch-baserte datalagringsmetoder gir føderert søk nær sanntids tilgang til oppdatert informasjon på tvers av alle tilkoblede kilder, noe som sikrer resultatets ferskhet og nøyaktighet.
Semantisk forståelse: Moderne fødererte AI-søk utnytter naturlig språkprosessering og semantisk analyse for å forstå spørringsintensjon utover nøkkelord, noe som gir mer nøyaktig valg av kilder og tolkning av resultater.
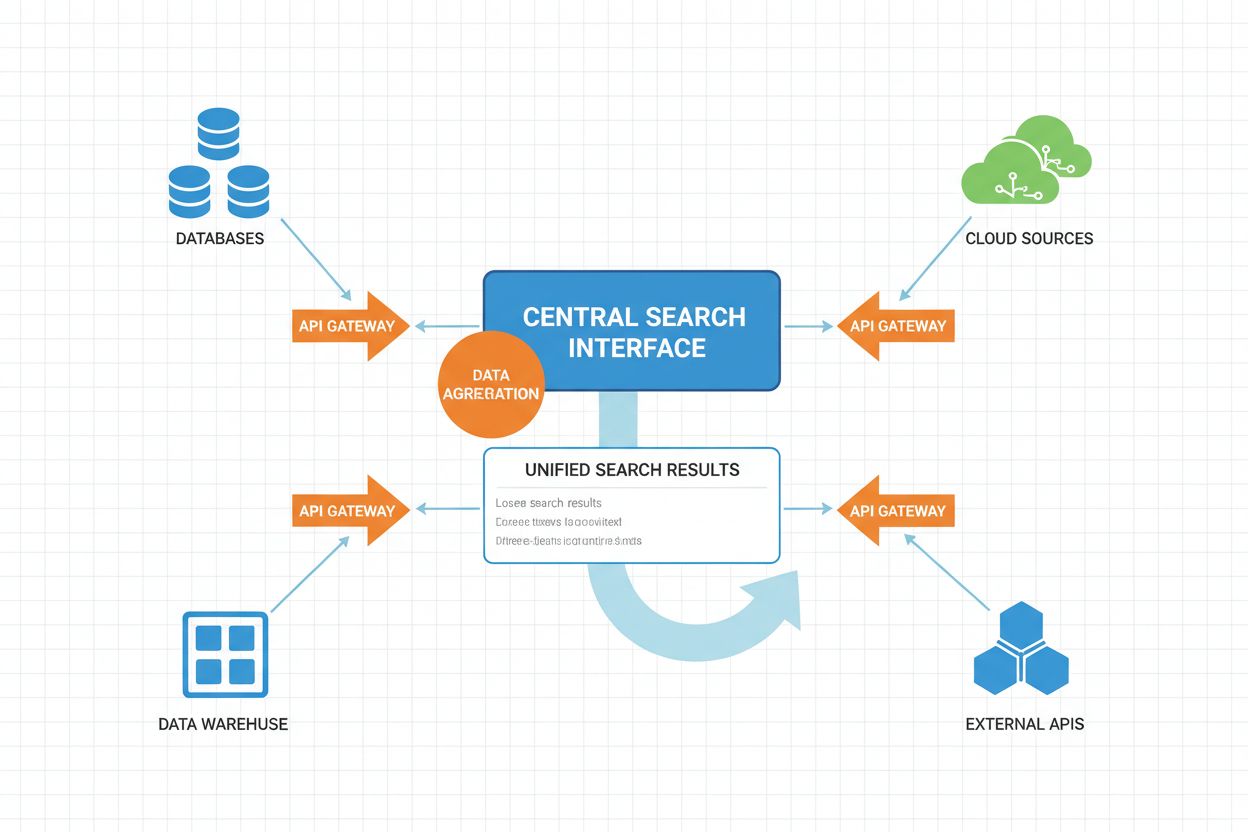
Den operative arbeidsflyten i føderert AI-søk består av flere koordinerte trinn, hvor hvert steg forbedres av kunstig intelligens for å optimalisere ytelse og resultatkvalitet.
| Trinn | Prosess | AI-komponent | Utdata |
|---|---|---|---|
| Spørringsanalyse | Brukerspørring parses og analyseres for intensjon, entiteter og kontekst | NLP, navngitt entitetsgjenkjenning, intensjonsklassifisering | Strukturert spørringsrepresentasjon, identifiserte entiteter, intensjonssignaler |
| Kildevalg | Systemet avgjør hvilke datakilder som er mest relevante for spørringen | Maskinlæringsbaserte rangeringsmodeller, relevansklassifisering av kilder | Prioritert liste over målkilder, tillitsscore |
| Spørringsoversettelse | Spørringen oversettes til kilde-spesifikke formater og spørringsspråk | Skjemamapping, spørringsoversettelsesmodeller, semantisk matching | Kildespesifikke spørringer (SQL, SPARQL, API-kall, osv.) |
| Distribuert utførelse | Spørringer utføres parallelt mot valgte kilder | Lastbalansering, timeout-håndtering, parallell behandling | Råresultater fra hver kilde, utførelsesmetadata |
| Resultatnormalisering | Resultater fra ulike kilder konverteres til felles format | Skjemajustering, datatypekonvertering, formatstandardisering | Normalisert resultatsett med konsistent struktur |
| Semantisk berikelse | Resultater utvides med ekstra kontekst og metadata | Entitetslenking, semantisk tagging, kunnskapsgrafintegrasjon | Berikede resultater med semantiske annotasjoner |
| Rangering og deduplisering | Resultater rangeres etter relevans, og duplikater fjernes | Læringsbaserte rangeringsmodeller, likhetsdeteksjon, relevansscoring | Dedupliserte, rangerte resultatlister |
| Personalisering | Resultater tilpasses brukerprofil og preferanser | Kollaborativ filtrering, brukermodellering, kontekstbevissthet | Personlig tilpasset resultatrekkefølge |
| Presentasjon | Resultater formateres for brukergrensesnitt | Naturlig språkgenerering, resultatsammendrag | Brukervennlig resultatvisning |
Arbeidsflyten opererer med parallell utførelse som kjerne, der flere kilder søkes samtidig i stedet for sekvensielt. Denne paralleliseringen reduserer den totale spørringslatensen betydelig, til tross for koordinasjonsbehovet. Avanserte fødererte systemer implementerer adaptiv spørringsplanlegging, hvor systemet lærer av historiske spørringsmønstre for å optimalisere valg av kilder og utførelsesstrategier over tid.
Timeout- og reservemekanismer er sentrale for systemets pålitelighet. Når en kilde svarer tregt eller feiler, kan systemet enten vente med adaptive tidsavbrudd eller fortsette med resultater fra tilgjengelige kilder, og dermed redusere resultatets fullstendighet på en kontrollert måte i stedet for å feile helt.
Fødererte AI-søkesystemer kan kategoriseres etter flere dimensjoner:
Etter arkitekturmodell:
Etter datakildetype:
Etter omfang og skala:
Etter intelligensnivå:
Dataautonomi og styring: Organisasjoner beholder kontroll over sine data, uten å måtte overføre sensitiv informasjon til sentraliserte lagre. Dette bevarer datastyringspolicyer, etterlevelseskrav og sikkerhetskontroller på kildenivå.
Skalerbarhet uten konsolidering: Fødererte systemer skalerer ved å legge til nye kilder uten å kreve datamigrasjon eller omstrukturering av datalager. Dette gjør det mulig å integrere nye datakilder gradvis etter forretningsbehov.
Sanntidstilgang til informasjon: Ved å søke direkte i kildene gir føderert søk tilgang til oppdatert informasjon uten forsinkelsen som følger med batchbaserte datalagre. Dette er spesielt verdifullt for tidskritiske applikasjoner.
Kostnadseffektivitet: Eliminerer betydelige infrastruktur- og driftskostnader knyttet til bygging og vedlikehold av sentraliserte datalagre. Organisasjoner unngår dataduplisering, redundant lagring og komplekse ETL-prosesser.
Redusert dataduplisering: I motsetning til datalagringsmetoder som dupliserer data, bevarer føderert søk én sannhetskilde, noe som reduserer lagringsbehov og sikrer konsistens.
Fleksibilitet og tilpasningsevne: Nye kilder kan integreres uten å endre eksisterende infrastruktur eller reindeksere sentraliserte lagre. Dette gir rask respons på endrede forretningskrav.
Bedre datakvalitet: Ved å søke direkte i autoritative kilder reduserer føderert søk datastagnasjon og inkonsistens som kan oppstå ved periodisk synkronisering.
Økt sikkerhet: Sensitiv data forlater aldri sitt opprinnelige sted, noe som reduserer risikoen for uautorisert tilgang eller datainnbrudd. Tilgangskontroller håndteres på kildenivå.
Støtte for heterogene kilder: Fødererte systemer støtter ulike teknologier, formater og protokoller uten krav om standardisering eller migrering til felles plattformer.
Intelligent resultatsyntese: AI-drevet rangering og aggregering gir høyere resultatkvalitet enn enkel sammenslåing, og tar hensyn til kildens troverdighet, relevans og brukerkontekst.
Moderne fødererte AI-søkesystemer består av flere sammenkoblede tekniske komponenter som jobber sammen for å levere integrerte søkefunksjoner.
Spørringsbehandlingsmotor: Hovedkomponenten som mottar brukerspørringer og orkestrerer føderert søk. Denne motoren inkluderer spørringsparsing, semantisk analyse og intensjonsgjenkjenning. Avanserte implementeringer bruker transformatorbaserte språkmodeller for å forstå komplekse spørringsnyanser og implisitt brukermål.
Kilderegister og metadatahåndtering: Vedlikeholder omfattende metadata om tilgjengelige datakilder, inkludert skjema, innholdsegenskaper, oppdateringsfrekvens, tilgjengelighetsmønstre og ytelsesdata. Registeret muliggjør intelligent kildevalg og spørringsoptimalisering. Maskinlæringsmodeller analyserer historiske spørringsmønstre for å forutsi kildens relevans for nye spørringer.
Intelligent kildevalg-modul: Bruker maskinlæringsklassifisering for å avgjøre hvilke kilder som sannsynligvis har relevant informasjon for en gitt spørring. Modulen vurderer faktorer som innholdsdekning, tidligere suksessrater, tilgjengelighet og forventet svartid. Avanserte systemer bruker forsterkende læring for å kontinuerlig optimalisere kildevalg basert på resultater.
Spørringsoversettelse og tilpasningslag: Gjør brukerspørringer om til kildespesifikke formater og spørringsspråk. Dette inkluderer SQL-generering for relasjonsdatabaser, SPARQL for kunnskapsgrafer, REST API-kall for webtjenester og naturlige språkspørringer for ustrukturerte systemer. Semantisk mapping sikrer at intensjon bevares på tvers av ulike datamodeller.
Distribuert utførelseskoordinator: Håndterer parallell utførelse av spørringer mot flere kilder, inkludert timeout-håndtering, lastbalansering og feilhåndtering. Komponentet implementerer adaptiv timeout-strategi som justeres basert på responsmønstre og systembelastning.
Resultatnormaliseringsmotor: Gjør resultater fra ulike kilder om til felles format for aggregering og rangering. Dette inkluderer skjema-tilpasning, datatypekonvertering og formatstandardisering. Motoren håndterer manglende felter, motstridende datatyper og strukturelle forskjeller.
Semantisk berikelsesmodul: Utvider resultater med kontekst og semantisk informasjon, inkludert entitetslenking til kunnskapsbaser, semantisk tagging basert på ontologier og relasjonsuttrekking fra ustrukturert tekst. Dette forbedrer rangeringspresisjon og forståelighet.
Læringsbasert rangeringsmodell: Maskinlæringsmodell trent på historiske spørring-resultat-par for å forutsi resultatets relevans. Denne modellen vurderer hundrevis av variabler, inkludert kildetroverdighet, innholdsferskhet, brukertilpasning og semantisk likhet mellom spørring og resultat. Moderne implementeringer bruker gradient boosting eller nevrale nettverk.
Dedupliseringsmotor: Identifiserer og fjerner duplikater eller nesten-duplikater fra ulike kilder, basert på likhetsmetrikker som eksakt samsvar, fuzzy matching og semantisk likhet.
Personaliseringsmotor: Tilpasser resultatrekkefølgen basert på brukerprofiler, tidligere preferanser og kontekstuell informasjon. Dette bruker kollaborativ filtrering og innholdsbaserte anbefalinger.
Cache- og optimaliseringslag: Implementerer intelligente cache-strategier for å redusere overflødige spørringer. Dette inkluderer cache av spørringsresultater, kildemetadata og lærte spørringsmønstre.
Overvåknings- og analysemodul: Sporer systemytelse, kildepålitelighet, spørringsmønstre og resultatkvalitet. Disse dataene brukes til å forbedre og optimalisere systemet kontinuerlig.
Helse og medisinsk forskning: Føderert søk integrerer pasientjournaler på tvers av sykehussystemer, forskningsdatabaser, kliniske studieregistre og medisinske litteraturarkiv. Leger kan søke i komplette pasienthistorikker uten å sentralisere sensitiv medisinsk data. Forskere får tilgang til distribuerte kliniske data for studier, samtidig som de opprettholder HIPAA-etterlevelse og pasientpersonvern.
Finansielle tjenester: Banker og investeringsselskaper bruker føderert søk for å søke i handelsdata, markedsinformasjon, regulatoriske databaser og interne transaksjonsregistre samtidig. Dette muliggjør sanntids risikovurdering, etterlevelsesovervåking og markedsanalyse uten å konsolidere sensitiv finansdata sentralt.
Juss og etterlevelse: Advokatfirmaer og juridiske avdelinger søker i rettsdatabaser, regelverk, interne dokumentsystemer og kontraktsarkiv. Føderert søk gir omfattende juridisk research samtidig som advokat-klient-privilegium og dokumentkonfidensialitet opprettholdes.
Netthandel og detaljhandel: Nettbutikker integrerer produktkataloger fra flere lagre, leverandørsystemer og markedsplattformer. Føderert søk gir samlet produktfinn, samtidig som leverandører beholder uavhengige lager- og prissystemer.
Offentlig sektor og forvaltning: Offentlige etater søker i distribuerte databaser som folketelling, skatteopplysninger, tillatelsessystemer og offentlige registre uten å sentralisere sensitiv informasjon. Dette gir helhetlige offentlige tjenester og sikrer datavern.
Industri og forsyningskjede: Produsenter integrerer leverandørdatabaser, lagerstyring, produksjonsjournaler og logistikksystemer. Føderert søk gir oversikt over forsyningskjeden uten at partnere må avsløre proprietær informasjon.
Utdanning og forskning: Universiteter søker i institusjonelle arkiv, biblioteksystemer, forskningsdatabaser og åpne publikasjoner. Føderert søk gir bred akademisk oppdagelse og respekterer institusjonell autonomi og immaterielle rettigheter.
Telekommunikasjon: Telekomleverandører søker i kundedatabaser, nettverksregistre, faktureringssystemer og tjenestekataloger. Føderert søk gir samlet kundeservice og bevarer separate systemer for ulike produktlinjer og regioner.
Energi og forsyning: Energiselskaper søker i produksjonsanlegg, distribusjonsnett, kundedatabaser og regulatoriske systemer. Føderert søk gir operasjonell innsikt og gjør det mulig for regionale aktører å beholde egne systemer.
Media og publisering: Mediehus søker i innholdsarkiv, rettighetsstyring og distribusjonsplattformer. Føderert søk gir samlet innholdsoppdagelse og bevarer eierskap og lisensbegrensninger.
Kildeheterogenitet og integrasjonskompleksitet: Integrasjon av ulike datakilder med forskjellige skjemaer, spørringsspråk og tilgangsprotokoller krever betydelig teknisk innsats. Skjemamapping og semantisk justering er krevende, spesielt når samme konsept representeres ulikt.
Spørringslatens og ytelse: Føderert søk innebærer spørringer mot flere kilder og gir derfor høyere latens enn sentraliserte systemer. Trege eller utilgjengelige kilder kan svekke den totale ytelsen. Timeout-håndtering må finjusteres for å balansere fullstendighet og respons.
Kildepålitelighet og tilgjengelighet: Systemet er avhengig av at eksterne kilder er tilgjengelige og responderer raskt. Nettverksfeil eller nedetid påvirker søkeresultatet direkte. Grasiøs degradering er nødvendig ved feil.
Resultatkvalitet og rangeringsnøyaktighet: Å samle resultater fra kilder med ulik kvalitet, dekning og relevanskriterier er utfordrende. Rangeringsmodeller må ta hensyn til variasjon i kildetroverdighet og unngå skjevhet.
Dataferskhet og konsistens: Kilder kan ha ulike oppdateringsintervaller og konsistensgarantier. Å forene motstridende data krever avanserte konfliktløsningsstrategier.
Skaleringsbegrensninger: Økende antall kilder gir høyere koordinasjonskostnad. Å velge relevante kilder fra tusenvis av mulige er ressurskrevende. Parallell utførelse på mange kilder krever robust infrastruktur.
Sikkerhet og tilgangskontroll: Systemet må håndheve tilgangskontroller på kildenivå, selv ved enhetlig brukergrensesnitt. Sikre at brukere bare ser det de har tilgang til på tvers av kilder er krevende.
Personvern og datavern: Føderert søk må overholde personvernregler som GDPR, CCPA og bransjespesifikke krav. Det må sikres at sensitiv data ikke lekker gjennom resultataggregering eller metadataanalyse.
Kildeoppdagelse og forvaltning: Identifisering, katalogisering og vedlikehold av kilder, inkludert metadata og livssyklus (tillegg, fjerning, oppdatering), krever kontinuerlig innsats.
Semantisk interoperabilitet: Å oppnå ekte semantisk samhandling på tvers av ulike ontologier og datamodeller er fortsatt utfordrende. Automatisert skjemamapping og entitetsoppløsning har sine begrensninger.
Koordineringskostnad: Føderert søk eliminerer kostnader til datakonsolidering, men introduserer koordinasjonskostnader. Håndtering av distribuert utførelse, feil og optimalisering krever avansert infrastruktur.
Begrenset standardisering: Manglende universelle standarder for fødererte søkeprotokoller og grensesnitt gjør integrasjon vanskeligere og øker risiko for leverandørlåsing.
Føderert AI-søk vs. datalagring: Datalagring samler data fra flere kilder i ett sentralt lager, noe som gir raske spørringer, men krever omfattende ETL-arbeid og fører til datalatens. Føderert søk søker direkte i kildene og gir sanntidstilgang, men med høyere spørringslatens. Lagring passer for historiske analyser, føderert søk for oppdatert informasjonsfinn.
Føderert AI-søk vs. datasjøer: Datasjøer lagrer rådata fra mange kilder sentralt med minimal transformasjon. De gir fleksibilitet, men krever mye lagring og styring. Føderert søk unngår konsolidering og bevarer kildeautonomi, men krever mer avansert spørringsprosessering.
Føderert AI-søk vs. API-er og mikrotjenester: API-er gir programmatisk tilgang til enkeltjenester, men krever kjennskap til hvert grensesnitt. Føderert søk skjuler slike detaljer og gir enhetlig søk på tvers av tjenester. API-er passer integrasjon mellom applikasjoner, føderert søk gir tverrtjenestelig informasjonsoppdagelse.
Føderert AI-søk vs. kunnskapsgrafer: Kunnskapsgrafer representerer informasjon som sammenknyttede entiteter og relasjoner, og muliggjør semantisk resonnement. Føderert søk kan søke i distribuerte grafer uten sentral grafkonstruksjon. Kunnskapsgrafer gir dypere semantisk forståelse, føderert søk vektlegger kildeautonomi.
Føderert AI-søk vs. søkemotorer: Tradisjonelle søkemotorer har sentraliserte indekser over indeksert innhold. Føderert søk søker direkte i kildene uten forhåndsindeksering. Søkemotorer gir dekning av offentlig innhold, føderert søk integrerer private, proprietære eller spesialiserte kilder.
Føderert AI-søk vs. master data management (MDM): MDM lager autoritative masterposter ved å konsolidere data fra flere kilder. Føderert søk søker uavhengig i kildene uten å opprette masterposter. MDM passer for datastyring og konsistens, føderert søk for autonomi og sanntidstilgang.
Føderert AI-søk vs. virksomhetssøk: Virksomhetssøk indekserer interne dokumenter og databaser i et sentralt indeks. Føderert søk søker direkte uten sentral indeks. Virksomhetssøk gir raske fulltekstsøk, føderert søk støtter ulike kildetyper og sanntidsoppdateringer.
Føderert AI-søk vs. blockchain og distribuerte hovedbøker: Blockchain gir distribuert konsensus, dataintegritet og uforanderlighet. Føderert søk koordinerer spørringer på tvers av uavhengige kilder uten konsensuskrav. Blockchain passer for tillit og verifikasjon, føderert søk for informasjonsoppdagelse.
Omfattende kildevurdering: Før integrering bør kilder vurderes grundig for datakvalitet, oppdateringsfrekvens, tilgjengelighet, skjemakompleksitet og tilgangsprotokoller. Dette gir grunnlag for optimaliseringsalgoritmer og realistiske forventninger.
Inkrementell integrasjon: Start med et lite antall godt forståtte kilder og utvid gradvis. Dette gir læring, tidlig avdekking av utfordringer og forbedring av prosessene før oppskalering.
Robust metadatahåndtering: Invester i omfattende metadata om kilder, inkludert skjema, dekning, kvalitetsmål og ytelse. Oppretthold nøyaktighet med automatisk overvåking og periodisk validering.
Intelligent kildevalg: Implementer maskinlæringsbasert kildevalg som lærer av spørringsresultater. Følg hvilke kilder som gir relevante resultater for ulike spørringstyper og optimaliser løpende.
Adaptiv timeout-håndtering: Bruk adaptive timeout-strategier basert på responsmønstre og systembelastning. Unngå faste timeout-verdier som enten venter for lenge eller gir for tidlig avbrudd.
Resultatkvalitetssikring: Sett mål for resultatkvalitet, som relevans, ferskhet og fullstendighet. Gi brukere mulighet til å vurdere resultater, og bruk tilbakemeldinger i treningen av rangeringsmodellen.
Omfattende overvåking: Overvåk kildetilgjengelighet, responstid, resultatkvalitet og brukertilfredshet. Bruk dataene til å identifisere problemer, optimalisere ruting og forbedre ytelsen.
Sikkerhet og tilgangskontroll: Implementer tilgangskontroller på kildenivå og sørg for at brukere bare får tilgang til det de er autorisert til
Tradisjonelt sentralisert søk samler alle data i et enkelt indeksert lager, noe som krever datamigrasjon og introduserer forsinkelse. Føderert AI-søk søker direkte i flere uavhengige kilder i sanntid uten å flytte eller duplisere data, og bevarer kildenes autonomi samtidig som det gir enhetlig tilgang. Dette gjør føderert søk ideelt for organisasjoner med distribuerte datakilder og strenge krav til datastyring.
Føderert AI-søk lar dataene bli værende på sitt opprinnelige sted og respekterer hver kildes tilgangskontroller og sikkerhetspolicyer. Brukere får kun tilgang til informasjon de er autorisert til å se, og sensitiv data forlater aldri kildesystemet. Denne tilnærmingen forenkler etterlevelse av regelverk som GDPR og HIPAA ved å eliminere risikoen forbundet med sentralisering av sensitiv informasjon.
Nøkkelutfordringer inkluderer håndtering av heterogene datakilder med ulike skjemaer og formater, håndtering av spørringsforsinkelse fra flere kilder, sikring av konsistent resultat-rangering på tvers av kilder, og å opprettholde systemets pålitelighet når kilder er utilgjengelige. Organisasjoner må også investere i robust metadatahåndtering og intelligente algoritmer for valg av kilder for å optimalisere ytelsen.
Ja, føderert AI-søk skalerer ved å legge til nye kilder uten behov for datamigrasjon eller omstrukturering av datalager. Men når antall kilder øker, vokser koordinasjonskostnaden for spørringer. Moderne systemer bruker maskinlæring for intelligent valg av kilder og implementerer hurtigbufferstrategier for å opprettholde ytelsen ved store skalaer.
Datalagring samler data i et sentralisert lager, noe som muliggjør raske spørringer, men krever betydelig ETL-arbeid og introduserer datalatens. Føderert søk søker direkte i kildene og gir sanntidstilgang, men med høyere spørringslatens. Lagring passer for historisk analyse og rapportering, mens føderert søk er best for oppdagelse av oppdatert informasjon på tvers av distribuerte kilder.
Helsevesen, finans, netthandel, offentlig sektor og forskningsorganisasjoner har stor nytte av føderert søk. Helsevesenet bruker det for å integrere pasientjournaler på tvers av tilbydere, finans bruker det for etterlevelse og risikovurdering, netthandel bruker det for enhetlig produktfinn, og forskningsorganisasjoner bruker det for søk i distribuerte akademiske databaser.
AI forbedrer føderert søk gjennom naturlig språkprosessering for spørringsforståelse, maskinlæring for intelligent valg av kilder, semantisk analyse for bedre resultat-rangering, og automatisert deduplisering. AI-modeller lærer fra spørringsmønstre for kontinuerlig å optimalisere valg av kilder og resultataggregasjon, noe som forbedrer systemets ytelse over tid.
Semantisk forståelse gjør det mulig for fødererte systemer å forstå spørringsintensjon utover nøkkelord, identifisere relevante kilder mer nøyaktig, og rangere resultater basert på mening i stedet for bare overlapp i nøkkelord. Dette inkluderer entitetsgjenkjenning, relasjonsuttrekking og integrasjon med kunnskapsgrafer, noe som gir mer relevante og kontekstuelt riktige søkeresultater.
AmICited sporer hvordan AI-systemer som ChatGPT, Perplexity og Google AI Overviews siterer og refererer til ditt varemerke. Forstå din AI-synlighet og optimaliser din tilstedeværelse i AI-genererte svar.
Lær hvordan du undersøker og overvåker AI-søkespørringer på tvers av ChatGPT, Perplexity, Claude og Gemini. Oppdag metoder for å spore merkevareomtaler og optim...
Forstå hvordan AI-søketrakter fungerer annerledes enn tradisjonelle markedsføringstrakter. Lær hvordan AI-systemer som ChatGPT og Google AI slår sammen kjøpsrei...
Lær hvordan Query Fanout fungerer i AI-søkesystemer. Oppdag hvordan AI utvider én enkelt forespørsel til flere underforespørsler for å forbedre svarenes nøyakti...