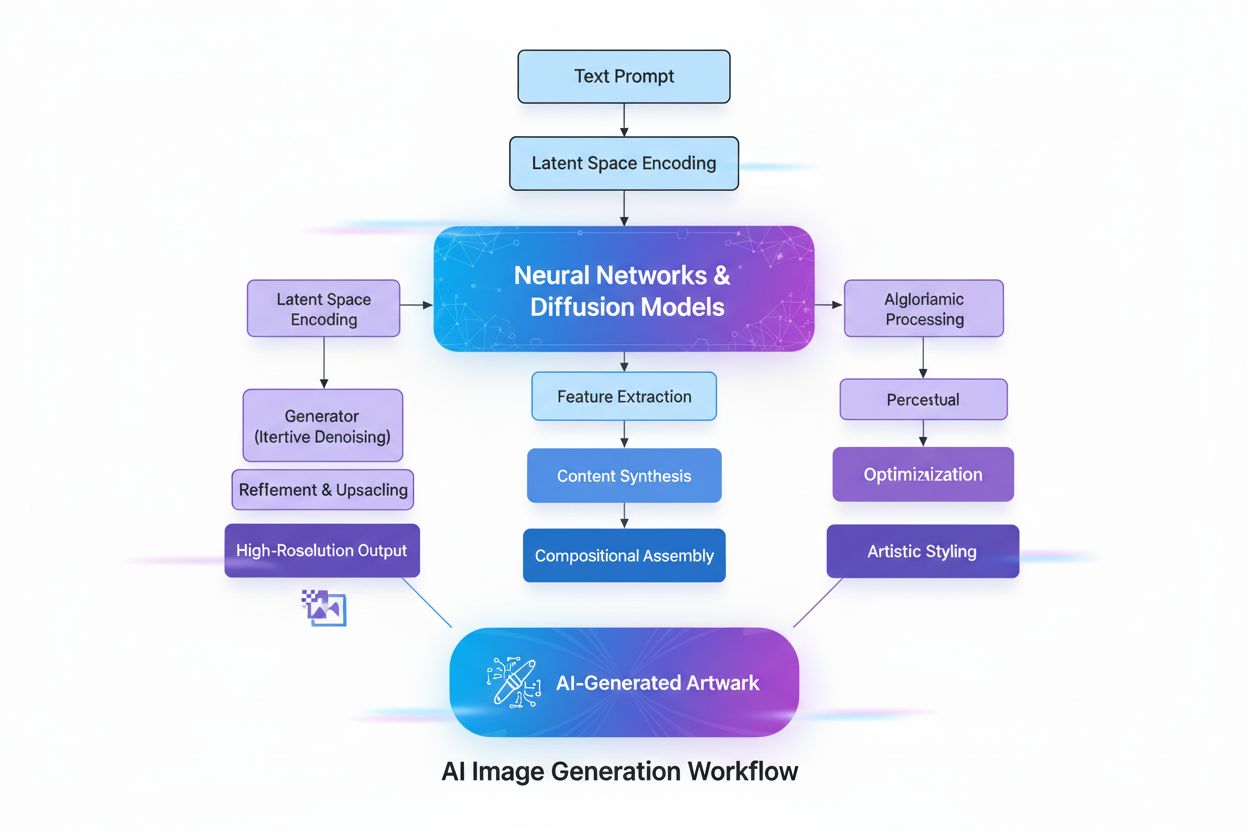
AI-generert bilde
Lær hva AI-genererte bilder er, hvordan de lages ved hjelp av diffusjonsmodeller og nevrale nettverk, deres bruksområder innen markedsføring og design, samt de ...
12 min lesing
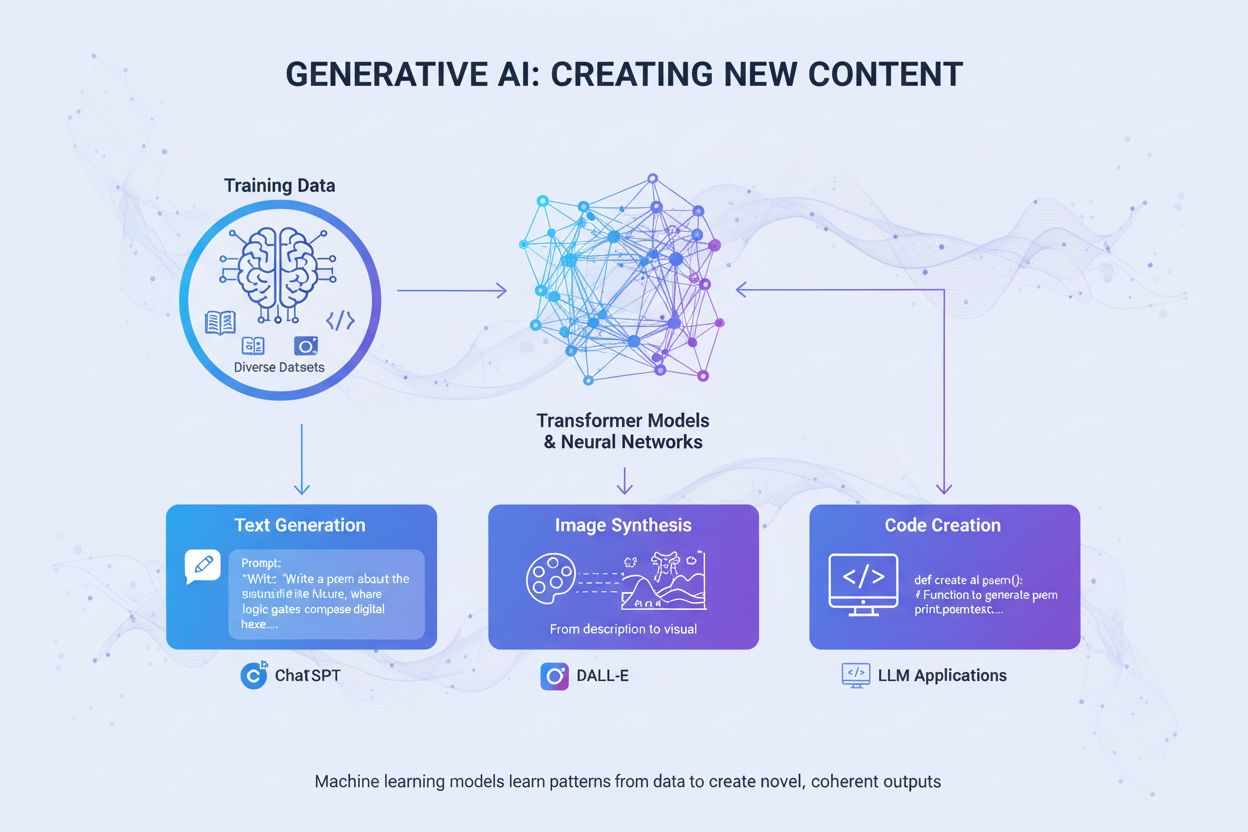
Generativ KI er kunstig intelligens som skaper nytt, originalt innhold som tekst, bilder, videoer, kode og lyd basert på mønstre lært fra treningsdata. Den bruker dype læringsmodeller som transformere og diffusjonsmodeller for å generere varierte resultater som svar på brukerforespørsler.
Generativ KI er kunstig intelligens som skaper nytt, originalt innhold som tekst, bilder, videoer, kode og lyd basert på mønstre lært fra treningsdata. Den bruker dype læringsmodeller som transformere og diffusjonsmodeller for å generere varierte resultater som svar på brukerforespørsler.
Generativ KI er en kategori innen kunstig intelligens som skaper nytt, originalt innhold basert på mønstre lært fra treningsdata. I motsetning til tradisjonelle KI-systemer som klassifiserer eller predikerer informasjon, produserer generative KI-modeller selvstendig nye resultater som tekst, bilder, videoer, lyd, kode og andre datatyper som svar på brukerforespørsler. Disse systemene benytter sofistikerte dype læringsmodeller og nevrale nettverk for å identifisere komplekse mønstre og relasjoner i enorme datasett, og bruker deretter den innlærte kunnskapen til å generere innhold som ligner, men er ulikt treningsdataene. Begrepet “generativ” understreker modellens evne til å generere—å skape noe nytt i stedet for bare å analysere eller kategorisere eksisterende informasjon. Siden den offentlige lanseringen av ChatGPT i november 2022 har generativ KI blitt en av de mest transformative teknologiene innen databehandling, og har fundamentalt endret hvordan organisasjoner tilnærmer seg innholdsproduksjon, problemløsning og beslutningstaking på tvers av praktisk talt alle bransjer.
Grunnlaget for generativ KI strekker seg flere tiår tilbake, selv om teknologien har utviklet seg dramatisk de siste årene. Tidlige statistiske modeller på 1900-tallet la grunnlaget for å forstå datadistribusjoner, men ekte generativ KI oppsto med fremskritt innen dyp læring og nevrale nettverk på 2010-tallet. Introduksjonen av Variasjonelle Autoenkodere (VAE-er) i 2013 markerte et betydelig gjennombrudd, og gjorde det mulig for modeller å generere realistiske variasjoner av data som bilder og tale. I 2014 kom Generative Adversarial Networks (GANs) og diffusjonsmodeller, som ytterligere forbedret kvaliteten og realismen i generert innhold. Det avgjørende øyeblikket kom i 2017 da forskere publiserte “Attention is All You Need” og introduserte transformer-arkitekturen—et gjennombrudd som fundamentalt endret hvordan generative KI-modeller prosesserer og genererer sekvensielle data. Denne innovasjonen muliggjorde utviklingen av Store språkmodeller (LLMs) som OpenAIs GPT-serie, som viste enestående evner til å forstå og generere menneskelig språk. Ifølge McKinsey brukte allerede en tredjedel av organisasjoner generativ KI regelmessig i minst én forretningsfunksjon innen 2023, og Gartner anslår at mer enn 80 % av bedrifter vil ha tatt i bruk generative KI-applikasjoner eller brukt KI-API-er innen 2026. Den raske akselerasjonen fra forskningsnysgjerrighet til virksomhetsnødvendighet representerer en av de raskeste teknologiadopsjonene i historien.
Generativ KI opererer gjennom en flertrinnsprosess som starter med trening på enorme datasett, etterfulgt av tilpasning for spesifikke applikasjoner, og kontinuerlige sykluser med generering, evaluering og omjustering. Under treningsfasen mates dype læringsalgoritmer med terabyte av rå, ustrukturerte data—som tekst fra internett, bilder eller kodearkiver—og algoritmen utfører millioner av “fyll inn det tomme”-oppgaver, forutsier neste element i en sekvens og justerer seg for å minimere prediksjonsfeil. Denne prosessen skaper et nevralt nettverk av parametre som koder mønstre, entiteter og relasjoner som er oppdaget i treningsdataene. Resultatet er en grunnmodell—en stor, forhåndstrent modell som kan utføre flere oppgaver på tvers av ulike domener. Grunnmodeller som GPT-3, GPT-4 og Stable Diffusion fungerer som basis for en rekke spesialiserte applikasjoner. Tilpasningsfasen innebærer finjustering av grunnmodellen med merkede data spesifikke for en bestemt oppgave, eller bruk av forsterkende læring med menneskelig tilbakemelding (RLHF), der menneskelige vurderere gir poeng til ulike resultater for å veilede modellen mot økt nøyaktighet og relevans. Utviklere og brukere vurderer kontinuerlig resultater og finjusterer modeller—noen ganger ukentlig—for å forbedre ytelsen. En annen optimaliseringsteknikk er Retrieval Augmented Generation (RAG), som utvider grunnmodellen til å få tilgang til relevante eksterne kilder, og sikrer at modellen alltid har tilgang til oppdatert informasjon samtidig som den gir åpenhet om kildene.
| Modelltype | Treningsmetode | Genereringshastighet | Utgangskvalitet | Variasjon | Beste bruksområder |
|---|---|---|---|---|---|
| Diffusjonsmodeller | Iterativ støyfjerning fra tilfeldige data | Treg (flere iterasjoner) | Svært høy (fotorealistisk) | Høy | Bildegenerering, syntese med høy kvalitet |
| Generative Adversarial Networks (GANs) | Konkurranse mellom generator og diskriminator | Rask | Høy | Lavere | Domene-spesifikk generering, stiloverføring |
| Variasjonelle autoenkodere (VAE-er) | Encoder-decoder med latent rom | Moderat | Moderat | Moderat | Datakomprimering, avviksdeteksjon |
| Transformer-modeller | Selvoppmerksomhet på sekvensielle data | Moderat til rask | Svært høy (tekst/kode) | Svært høy | Språkproduksjon, kodegenerering, LLM-er |
| Hybride tilnærminger | Kombinerer flere arkitekturer | Variabel | Svært høy | Svært høy | Multimodal generering, komplekse oppgaver |
Transformer-arkitekturen står som den mest innflytelsesrike teknologien bak moderne generativ KI. Transformere bruker selvoppmerksomhetsmekanismer for å avgjøre hvilke deler av inndataen som er viktigst for hvert element, slik at modellen kan fange opp langdistanseavhengigheter og kontekst. Posisjonskoding representerer rekkefølgen på inndataelementer, slik at transformere forstår sekvensstruktur uten sekvensiell behandling. Denne parallelle prosesseringen akselererer treningen dramatisk sammenlignet med tidligere rekursive nevrale nettverk (RNNer). Transformerenes encoder-decoder-struktur, kombinert med flere lag av oppmerksomhetshoder, gjør at modellen samtidig kan vurdere ulike aspekter av data og raffinere kontekstuelle innebygginger i hvert lag. Disse innebyggingene fanger alt fra grammatikk og syntaks til komplekse semantiske betydninger. Store språkmodeller (LLM-er) som ChatGPT, Claude og Gemini er bygget på transformer-arkitekturer og inneholder milliarder av parametre—kodede representasjoner av lærte mønstre. Skalaen på disse modellene, sammen med trening på internett-skala data, gjør at de kan utføre varierte oppgaver fra oversettelse og oppsummering til kreativ skriving og kodegenerering. Diffusjonsmodeller, en annen sentral arkitektur, fungerer ved først å legge til støy i treningsdata til de blir tilfeldige, og deretter trene algoritmen til å fjerne denne støyen iterativt for å avdekke ønskede resultater. Selv om diffusjonsmodeller krever mer treningstid enn VAE-er eller GANs, gir de bedre kontroll over utgangskvaliteten, spesielt for bildegenereringsverktøy med høy oppløsning som DALL-E og Stable Diffusion.
Forretningscaset for generativ KI har vist seg overbevisende, med bedrifter som opplever målbare produktivitetsgevinster og kostnadsreduksjoner. Ifølge OpenAIs 2025-rapport om bedrifts-KI rapporterer brukere at de sparer 40–60 minutter per dag gjennom generative KI-applikasjoner, noe som gir betydelige produktivitetsforbedringer på tvers av organisasjoner. Markedet for generativ KI ble verdsatt til 16,87 milliarder amerikanske dollar i 2024 og forventes å nå 109,37 milliarder dollar innen 2030, med en CAGR på 37,6 %—en av de raskeste vekstene i bedriftsprogramvare noensinne. Bedriftsbruk på generativ KI nådde 37 milliarder dollar i 2025, opp fra 11,5 milliarder dollar i 2024, en 3,2 ganger økning fra år til år. Denne akselerasjonen reflekterer økt tillit til avkastning, med KI-kjøpere som konverterer i 47 % av tilfellene sammenlignet med tradisjonell SaaS’ 25 %, noe som indikerer at generativ KI leverer umiddelbar verdi som rettferdiggjør rask adopsjon. Organisasjoner tar i bruk generativ KI på flere områder: kundeserviceteam bruker KI-chatboter for personaliserte svar og førstegangsløsning; markedsavdelinger bruker innholdsgenerering til blogger, e-post og sosiale medier; programvareutviklingsteam benytter kodegenerering for å akselerere utviklingssykluser; og forskningsteam bruker generative modeller til å analysere komplekse datasett og foreslå nye løsninger. Finansielle tjenester bruker generativ KI til svindeldeteksjon og personlig økonomisk rådgivning, mens helsesektoren anvender den til legemiddelutvikling og medisinsk bildeanalyse. Teknologiens allsidighet på tvers av bransjer viser dens transformative potensial for forretningsdrift.
Generativ KI har bruksområder i praktisk talt alle sektorer og funksjoner. Innen tekstgenerering produserer modellene sammenhengende, kontekstuelt relevant innhold som dokumentasjon, markedsføringstekster, blogginnlegg, forskningsartikler og kreativ skriving. De utmerker seg i å automatisere tidkrevende skriveoppgaver som dokumentoppsummering og generering av metadata, og frigjør menneskelige skribenter til mer kreativt arbeid. Bildegenerering-verktøy som DALL-E, Midjourney og Stable Diffusion lager fotorealistiske bilder, original kunst, og utfører stiloverføring og bildebehandling. Videogenerering gjør det mulig å lage animasjoner fra tekstforespørsler og legge til spesialeffekter raskere enn tradisjonelle metoder. Lyd- og musikkgenerering syntetiserer naturlig tale for chatboter og digitale assistenter, lager lydbokinnlesninger og genererer originalmusikk som etterligner profesjonelle komposisjoner. Kodegenerering gir utviklere mulighet til å skrive kode, autoutfylle kodebiter, oversette mellom programmeringsspråk og feilsøke applikasjoner. Innen helse akselererer generativ KI legemiddelutvikling ved å generere nye proteinsekvenser og molekylstrukturer med ønskede egenskaper. Syntetisk datagenerering skaper merkede treningsdata for maskinlæringsmodeller, spesielt nyttig når reelle data er begrenset eller utilstrekkelig for randtilfeller. Innen bilindustri lager generativ KI 3D-simuleringer for kjøretøyutvikling og genererer syntetiske data for autonom kjøretøytrening. Media og underholdning bruker generativ KI til å lage animasjoner, manus, spillmiljøer og personlige innholdsanbefalinger. Energiselskaper bruker generative modeller til nettstyring, optimalisering av operasjonell sikkerhet og prognoser for energiproduksjon. Bredden i bruksområder viser generativ KIs rolle som en grunnleggende teknologi som omformer hvordan organisasjoner skaper, analyserer og innoverer.
Til tross for imponerende egenskaper gir generativ KI betydelige utfordringer som organisasjoner må håndtere. KI-hallusinasjoner—plausible, men faktuelt feilaktige resultater—oppstår fordi generative modeller forutsier neste element basert på mønstre, ikke faktasjekk. En advokat brukte berømt ChatGPT til juridisk forskning og fikk oppdiktede dommer med sitater og henvisninger. Skjevhets- og rettferdighetsproblemer oppstår når treningsdata inneholder samfunnsmessige skjevheter, og fører til at modeller kan generere partisk eller støtende innhold. Inkonsistente utdata skyldes den sannsynlighetsbaserte naturen til generative modeller, hvor identiske input kan gi ulike resultater—et problem for applikasjoner som krever konsistens, som kundeservicechatboter. Manglende forklarbarhet gjør det vanskelig å forstå hvordan modeller kommer frem til bestemte resultater; selv ingeniører har utfordringer med å forklare disse “black box”-modellene. Sikkerhets- og personverntrusler oppstår når proprietær data brukes til modelltrening eller når modeller genererer innhold som utleverer eller krenker immaterielle rettigheter. Deepfakes—KI-genererte eller manipulerte bilder, videoer eller lyd ment for bedrag—er blant de mest bekymringsverdige bruksområdene, med cyberkriminelle som bruker deepfakes til stemme-phishing og økonomisk svindel. Beregningkostnader er fortsatt betydelige, da trening av store grunnmodeller krever tusenvis av GPU-er og ukers prosessering til millionkostnader. Organisasjoner reduserer disse risikoene med sikkerhetsmekanismer som begrenser modeller til pålitelige datakilder, kontinuerlig evaluering og justering for å redusere hallusinasjoner, mangfoldige treningsdata for å minimere skjevhet, prompt engineering for å oppnå konsistente resultater, og sikkerhetsprotokoller for å beskytte proprietær informasjon. Åpenhet om KI-bruk og menneskelig tilsyn med kritiske beslutninger er fortsatt beste praksis.
Etter hvert som generative KI-systemer blir primære informasjonskilder for millioner av brukere, må organisasjoner forstå hvordan deres merkevarer, produkter og innhold fremstår i KI-genererte svar. Overvåking av KI-synlighet innebærer systematisk sporing av hvordan store generative KI-plattformer—inkludert ChatGPT, Perplexity, Google AI Overviews og Claude—beskriver merkevarer, produkter og konkurrenter. Denne overvåkingen er kritisk fordi KI-systemer ofte siterer kilder og refererer informasjon uten tradisjonelle søkemotor-metrikker. Merkevarer som ikke vises i KI-svar, går glipp av synlighet og påvirkning i det KI-drevne søkelandskapet. Verktøy som AmICited gjør det mulig for organisasjoner å spore merkevareomtaler, overvåke siteringsnøyaktighet, identifisere hvilke domener og URL-er som refereres i KI-svar, og forstå hvordan KI-systemene fremstiller deres konkurranseposisjon. Disse dataene hjelper organisasjoner å optimalisere innholdet for KI-sitering, identifisere feilinformasjon eller unøyaktige fremstillinger, og opprettholde konkurransesynlighet ettersom KI blir det primære grensesnittet mellom brukere og informasjon. Praksisen GEO (Generative Engine Optimization) handler om å optimalisere innhold spesifikt for KI-sitering og synlighet, i tillegg til tradisjonell SEO. Organisasjoner som proaktivt overvåker og optimaliserer sin KI-synlighet, får konkurransefortrinn i det fremvoksende KI-baserte informasjonssystemet.
Generativ KI utvikler seg raskt, med flere viktige trender som former fremtiden. Multimodale KI-systemer som sømløst integrerer tekst, bilder, video og lyd blir stadig mer sofistikerte og muliggjør mer kompleks innholdsgenerering. Agentisk KI—autonome KI-systemer som kan utføre oppgaver og nå mål uten menneskelig inngripen—representerer neste evolusjon, med KI-agenter som bruker generert innhold for å samhandle med verktøy og ta beslutninger. Mindre og mer effektive modeller vokser frem som alternativer til massive grunnmodeller, og gir organisasjoner mulighet til å bruke generativ KI med lavere beregningskostnader og raskere responstid. Retrieval Augmented Generation (RAG) utvikles videre og gir modeller tilgang til oppdatert informasjon og eksterne kunnskapskilder, noe som adresserer hallusinasjons- og nøyaktighetsutfordringer. Regulatoriske rammeverk utvikles globalt, med myndigheter som etablerer retningslinjer for ansvarlig KI-utvikling og implementering. Bedriftstilpasning gjennom finjustering og domenespesifikke modeller akselererer, ettersom organisasjoner ønsker å tilpasse generativ KI til sine unike forretningsbehov. Etisk KI-praksis blir et konkurransefortrinn, med økt vekt på åpenhet, rettferdighet og ansvarlig bruk. Samspillet mellom disse trendene tyder på at generativ KI blir stadig mer integrert i forretningsdrift, mer effektiv og tilgjengelig for organisasjoner av alle størrelser, og underlagt strengere styring og etiske standarder. Organisasjoner som investerer i å forstå generativ KI, overvåke sin KI-synlighet og implementere ansvarlige praksiser, vil være best posisjonert for å hente ut verdi fra denne transformative teknologien og samtidig håndtere tilhørende risiko.
Generativ KI lager nytt innhold ved å lære fordelingen av data og generere nye resultater, mens diskriminativ KI fokuserer på klassifiserings- og prediksjonsoppgaver ved å lære beslutningsgrenser mellom kategorier. Generative KI-modeller som GPT-3 og DALL-E produserer kreativt innhold, mens diskriminative modeller er bedre egnet for oppgaver som bildegjenkjenning eller spam-deteksjon. Begge tilnærminger har distinkte bruksområder avhengig av om målet er innholdsskaping eller dataklassifisering.
Transformer-modeller bruker selvoppmerksomhetsmekanismer og posisjonskoding for å behandle sekvensielle data som tekst uten å kreve sekvensiell prosessering. Denne arkitekturen gjør det mulig for transformere å fange opp langdistanseavhengigheter mellom ord og forstå kontekst mer effektivt enn tidligere modeller. Transformermodellens evne til å prosessere hele sekvenser samtidig og lære komplekse relasjoner har gjort den til grunnlaget for de fleste moderne generative KI-systemer, inkludert ChatGPT og GPT-4.
Grunnmodeller er store dype læringsmodeller forhåndstrent på enorme mengder umerkede data som kan utføre flere oppgaver på tvers av ulike domener. Eksempler inkluderer GPT-3, GPT-4 og Stable Diffusion. Disse modellene fungerer som base for ulike generative KI-applikasjoner og kan finjusteres for spesifikke bruksområder, noe som gjør dem svært allsidige og kostnadseffektive sammenlignet med å trene modeller fra bunnen av.
Etter hvert som generative KI-systemer som ChatGPT, Perplexity og Google AI Overviews blir primære informasjonskilder, må merkevarer følge med på hvordan de fremstår i KI-genererte svar. Overvåking av KI-synlighet hjelper organisasjoner å forstå merkevareoppfatning, sikre korrekt informasjonsrepresentasjon og opprettholde konkurranseposisjonering i det KI-drevne søkelandskapet. Verktøy som AmICited gjør det mulig for merkevarer å spore omtaler og siteringer på tvers av flere KI-plattformer.
Generative KI-systemer kan produsere 'hallusinasjoner'—plausible, men faktuelt feilaktige resultater—på grunn av deres mønsterbaserte læringstilnærming. Disse modellene kan også reflektere skjevheter som finnes i treningsdata, generere inkonsistente svar på identiske input, og mangle åpenhet i sine beslutningsprosesser. Å håndtere disse utfordringene krever mangfoldig treningsdata, kontinuerlig evaluering og implementering av sikkerhetsmekanismer for å begrense modellene til pålitelige datakilder.
Diffusjonsmodeller genererer innhold ved gradvis å fjerne støy fra tilfeldige data, noe som gir resultater av høy kvalitet, men med lavere genereringshastighet. GANs bruker to konkurrerende nevrale nettverk (generator og diskriminator) for å produsere realistisk innhold raskt, men med lavere variasjon. Diffusjonsmodeller foretrekkes for øyeblikket til høyoppløselig bildegenerering, mens GANs fortsatt er effektive for domene-spesifikke bruksområder som krever balanse mellom hastighet og kvalitet.
Markedet for generativ KI ble verdsatt til 16,87 milliarder amerikanske dollar i 2024 og forventes å nå 109,37 milliarder dollar innen 2030, med en årlig vekstrate (CAGR) på 37,6 % fra 2025 til 2030. Bedriftsbruk på generativ KI nådde 37 milliarder dollar i 2025, en 3,2 ganger økning fra 11,5 milliarder i 2024, noe som viser rask adopsjon på tvers av bransjer.
Ansvarlig implementering av generativ KI krever at man starter med interne applikasjoner for å teste resultater i kontrollerte miljøer, sikrer åpenhet ved tydelig å kommunisere når KI brukes, implementerer sikkerhetsmekanismer for å hindre uautorisert datatilgang, og gjennomfører omfattende testing på tvers av ulike scenarioer. Organisasjoner bør også etablere klare styringsrammer, overvåke resultater for skjevhet og nøyaktighet, og opprettholde menneskelig tilsyn med kritiske beslutninger.
Begynn å spore hvordan AI-chatbots nevner merkevaren din på tvers av ChatGPT, Perplexity og andre plattformer. Få handlingsrettede innsikter for å forbedre din AI-tilstedeværelse.
Lær hva AI-genererte bilder er, hvordan de lages ved hjelp av diffusjonsmodeller og nevrale nettverk, deres bruksområder innen markedsføring og design, samt de ...

Diskusjon i fellesskapet som forklarer generative søkemotorer. Klare forklaringer på hvordan ChatGPT, Perplexity og andre AI-systemer skiller seg fra tradisjone...
Lær hva Search Generative Experience (SGE) er, hvordan det fungerer, og hvorfor overvåking av synligheten til merkevaren din i SGE-resultater er avgjørende for ...