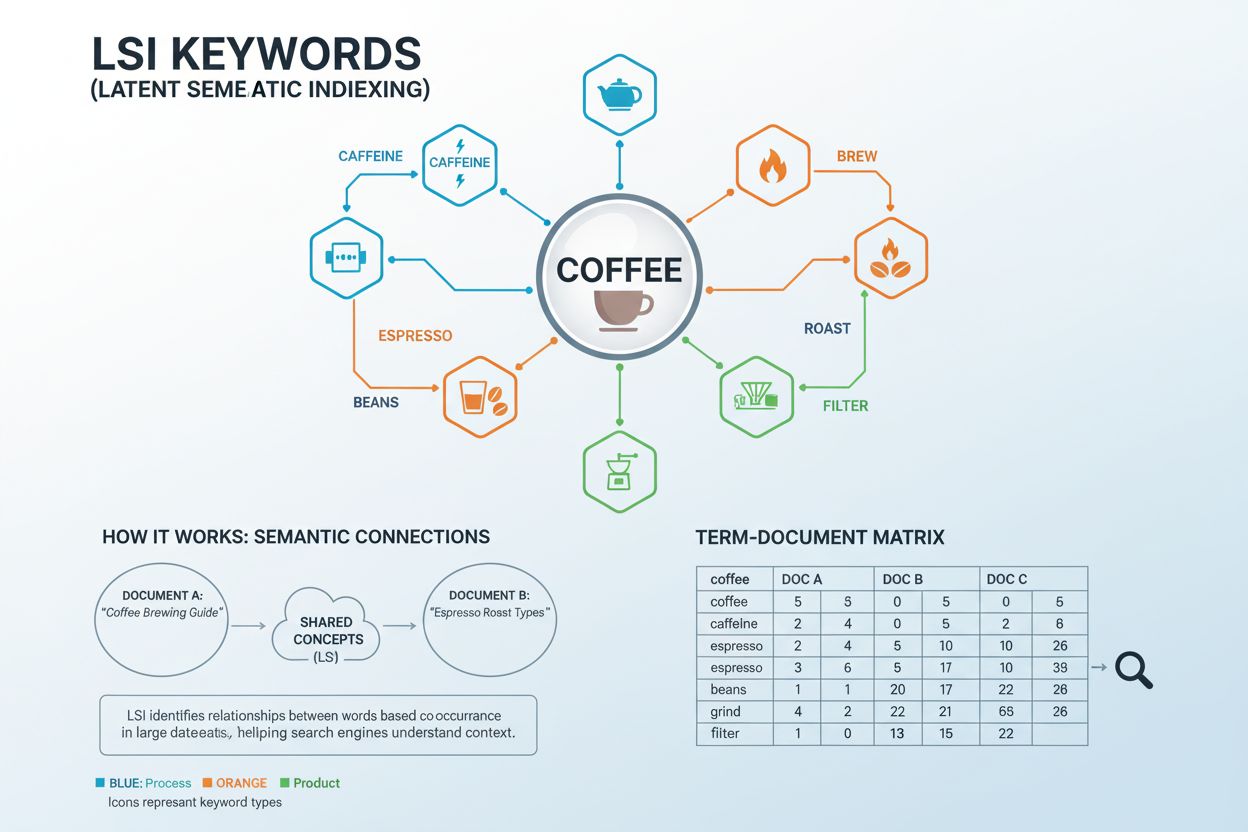
Definisjon av LSI-nøkkelord
LSI-nøkkelord (Latent Semantic Indexing Keywords) er ord og fraser som er konseptuelt relatert til ditt målnøkkelord og ofte opptrer sammen i lignende kontekster. Begrepet stammer fra en matematisk teknikk utviklet på 1980-tallet som analyserer skjulte semantiske relasjoner mellom ord i store dokumentsamlinger. I praktisk SEO-sammenheng er LSI-nøkkelord søkeord som hjelper søkemotorer og AI-systemer å forstå den bredere konteksten og temaet for innholdet ditt, utover bare å matche nøyaktige søkefraser. For eksempel, hvis ditt hovednøkkelord er “kaffe”, kan relaterte LSI-nøkkelord inkludere “koffein”, “brygg”, “espresso”, “bønner”, “risting” og “maling”. Disse termene arbeider sammen for å signalisere til søkemotorer at innholdet ditt dekker temaet kaffe grundig, ikke bare nevner ordet gjentatte ganger.
Historisk kontekst og utvikling av LSI-nøkkelord
Latent Semantic Indexing ble introdusert i en banebrytende forskningsartikkel fra 1988 som “en ny tilnærming for å håndtere vokabularproblemet i menneske-maskin-interaksjon.” Teknologien var utviklet for å møte en grunnleggende utfordring: søkemotorer var for avhengige av eksakt samsvar mellom søkeord, noe som ofte gjorde at relevante dokumenter ikke ble funnet når brukere benyttet ulike termer eller synonymer. I 2004 implementerte Google LSI-konsepter i sin søkealgoritme, noe som markerte et betydelig skifte i hvordan søkemotorer forstod innhold. Denne oppdateringen gjorde det mulig for Google å gå utover enkel analyse av ordhyppighet og begynne å forstå kontekst, mening og konseptuelle relasjoner mellom termer. Over 15 % av Googles daglige søk er nå nye termer som aldri har blitt søkt etter før, ifølge Googles egne undersøkelser, noe som gjør kontekstuell forståelse gjennom relaterte termer stadig viktigere. Utviklingen fra LSI til moderne semantisk analyse representerer et av de viktigste skiftene innen søkemotorteknologi og har fundamentalt endret hvordan innholdsskapere jobber med optimalisering.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
LSI-nøkkelord vs. relaterte termer: Sammenligningstabell
| Begrep | Definisjon | Fokus | Forhold til hovednøkkelord | Innvirkning på moderne SEO |
|---|
| LSI-nøkkelord | Ord som opptrer sammen med hovednøkkelord basert på matematisk analyse | Ordhyppighetsmønstre og samsvar | Direkte kontekstuell relasjon | Begrenset (Google bruker ikke LSI-algoritmen) |
| Semantiske nøkkelord | Konseptuelt relaterte termer som adresserer brukerintensjon og emnedybde | Mening og brukerintensjon | Bredere tematisk relasjon | Høy (kjerne for moderne SEO) |
| Synonymer | Ord med identisk eller svært lik betydning | Direkte ordsubstitusjon | Samme betydning, ulikt ord | Moderat (nyttig, men ikke hovedfokus) |
| Long-tail-nøkkelord | Lengre, mer spesifikke søkefraser | Søkevolum og spesifisitet | Mer spesifikk variant av hovednøkkelord | Høy (lavere konkurranse, høyere intensjon) |
| Relaterte nøkkelord | Termer som ofte søkes sammen med hovednøkkelord | Søkeatferdsmønstre | Brukersøk-mønstre | Høy (indikerer brukerintensjon) |
| Entitetsnøkkelord | Navngitte entiteter og konsepter relatert til temaet | Entitetsrelasjoner og kunnskapsgrafer | Konseptuell og kategorisk relasjon | Svært høy (AI-systemer prioriterer entiteter) |
Det matematiske grunnlaget: Hvordan LSI-nøkkelord fungerer
Latent Semantic Indexing opererer gjennom en avansert matematisk prosess kalt Singular Value Decomposition (SVD), som analyserer relasjonene mellom ord på tvers av store dokumentsamlinger. Systemet starter med å lage en Term Document Matrix (TDM)—et todimensjonalt rutenett som sporer hvor ofte hvert ord forekommer i ulike dokumenter. Stoppord (vanlige ord som “og”, “er”, “i”) fjernes for å isolere innholdsbærende termer. Algoritmen anvender deretter vektingsfunksjoner for å identifisere samsvars-mønstre—tilfeller hvor spesifikke ord opptrer sammen med lignende hyppighet på tvers av mange dokumenter. Når ord konsekvent opptrer sammen i lignende kontekster, gjenkjenner systemet dem som semantisk relaterte. For eksempel: ordene “kaffe”, “brygg”, “espresso” og “koffein” opptrer ofte sammen i dokumenter om drikkevarer, noe som signaliserer deres semantiske relasjon. Denne matematiske tilnærmingen gjør det mulig for datamaskiner å forstå at “espresso” og “kaffe” er relaterte konsepter uten å være programmert med eksplisitte regler. SVD-vektorene som produseres gjennom denne analysen, forutsier mening mer nøyaktig enn isolert analyse av enkeltdeler, og gjør det mulig for søkemotorer å forstå innhold på et dypere konseptuelt nivå enn ren nøkkelordmatching.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Hvorfor Google ikke bruker LSI (men fortsatt verdsetter semantisk forståelse)
Til tross for den teoretiske elegansen til Latent Semantic Indexing, har Google eksplisitt uttalt at de ikke bruker LSI i sin rangeringsalgoritme. John Mueller, en Google-representant, bekreftet i 2019: “Det finnes ikke noe som heter LSI-nøkkelord – alle som sier noe annet tar feil, beklager.” Flere faktorer forklarer hvorfor Google har forlatt LSI til fordel for nyere tilnærminger. For det første var LSI designet for mindre, statiske dokumentsamlinger, ikke det dynamiske og stadig voksende internett. Den opprinnelige LSI-patenten, gitt til Bell Communications Research i 1989, utløp i 2008, men da hadde Google allerede gått videre fra teknologien. Viktigere er det at Google har utviklet langt mer avanserte systemer som RankBrain (introdusert i 2015), som bruker maskinlæring for å omdanne tekst til matematiske vektorer. Google introduserte senere BERT (Bidirectional Encoder Representations from Transformers) i 2019, som analyserer ord toveis – og tar hensyn til alle ord før og etter et spesifikt begrep for å forstå kontekst. I motsetning til LSI, som fjerner stoppord, forstår BERT at småord som “finne” i “Hvor kan jeg finne en lokal tannlege?” er avgjørende for å tolke søkeintensjon. I dag bruker Google MUM (Multitask Unified Model) og AI Overviews til å generere kontekstuelle sammendrag direkte i søkeresultater, noe som representerer en utvikling langt forbi det LSI kunne oppnå.
Semantisk SEO: Den moderne utviklingen av LSI-konsepter
Selv om LSI-nøkkelord som spesifikk teknologi er utdatert, er det underliggende prinsippet—at søkemotorer bør forstå innholdets kontekst og mening—fortsatt grunnleggende for moderne SEO. Semantisk SEO representerer denne utviklingen, med fokus på brukerintensjon, tematisk autoritet og helhetlig dekning av emner fremfor rene ordhyppighetsmønstre. Ifølge data fra 2025 er omtrent 74 % av alle søk nå long-tail-frase, noe som gjør semantisk forståelse avgjørende for å nå ulike målgrupper. Semantisk SEO handler om å skape innhold som grundig dekker et tema fra flere vinkler, naturlig inkorporerer relaterte konsepter og svarer på relevante spørsmål. Denne tilnærmingen samsvarer med hvordan moderne AI-systemer som ChatGPT, Perplexity, Google AI Overviews og Claude vurderer kildemateriale. Disse systemene prioriterer innhold som utviser ekspertise, fylde og tydelig tematisk autoritet—egenskaper som naturlig oppstår når du inkorporerer semantisk relaterte termer og konsepter. Overgangen fra LSI til semantisk SEO representerer en modning av søketeknologi, fra matematisk mønstergjenkjenning til genuin kontekstuell forståelse drevet av nevrale nettverk og maskinlæring.
Praktisk gjennomføring: Hvor og hvordan bruke relaterte nøkkelord
Å inkorporere LSI-nøkkelord og semantisk relaterte termer i innholdet ditt krever strategisk plassering og naturlig integrering. De mest effektive plasseringene for disse termene inkluderer title tags og H1-overskrifter, som har stor vekt for søkemotorer. H2- og H3-underoverskrifter gir gode muligheter til å introdusere relaterte konsepter mens de organiserer innholdet logisk. Bilde-alt-tekst tilbyr en annen verdifull plassering, der du kan forsterke tematisk relevans og samtidig forbedre tilgjengeligheten. Gjennom innholdsteksten bør relaterte termer flettes naturlig inn i setninger og avsnitt for å støtte hovedfortellingen, ikke bryte den. Metabeskrivelser kan inkludere relaterte nøkkelord for å forbedre klikkraten fra søkeresultater. Interne lenkers anker-tekst gir ytterligere mulighet til å forsterke semantiske relasjoner mellom relaterte sider på nettstedet ditt. Hovedprinsippet er naturlig integrering—hvis en relatert term ikke passer naturlig inn i innholdet, bør den ikke tvinges inn. Forskning viser at innhold med ett LSI-nøkkelord per 200–300 ord gir optimal balanse mellom semantisk fylde og lesbarhet. Dette forholdet er ingen hard regel, men en nyttig retningslinje for å sikre tilstrekkelig tematisk dekning uten nøkkelord-fylling.
LSI-nøkkelord og AI-synlighet i søk
For merkevarer og innholdsskapere som er opptatt av AI-synlighet i søk og siteringer på tvers av plattformer som AmICited overvåker, blir forståelsen av LSI-nøkkelord og semantiske relasjoner stadig viktigere. AI-systemer som genererer svar for ChatGPT, Perplexity, Google AI Overviews og Claude vurderer kildemateriale basert på tematisk fylde og ekspertisesignaler. Når innholdet ditt inkluderer semantisk relaterte termer og konsepter, signaliserer det til disse AI-systemene at du har dekket et tema grundig. Denne grundigheten øker sannsynligheten for at innholdet ditt blir valgt som kilde for AI-genererte svar. I tillegg hjelper semantiske nøkkelord med å etablere entitetsrelasjoner—koblinger mellom konsepter AI-systemer bruker for å forstå kunnskapsdomener. For eksempel viser innhold om “kaffe” som inkluderer relaterte entiteter som “koffein”, “espressomaskiner”, “kaffebønner” og “bryggemetoder” bredere ekspertise enn innhold som kun nevner hovednøkkelordet. Slike entitetsrike innhold er mer sannsynlig å bli sitert av AI-systemer som genererer omfattende svar. Etter hvert som AI-søk utvikler seg, blir evnen til å vise tematisk autoritet gjennom semantisk fylde en avgjørende konkurransefordel for synlighet og siteringer.
Viktige aspekter ved LSI-nøkkelord og semantisk optimalisering
- Kontekstuelle relasjoner: Relaterte termer som ofte opptrer sammen i lignende kontekster, og hjelper søkemotorer å forstå innholdets mening utover eksakt nøkkelordmatching
- Samsvarsmønstre: Ord som konsekvent opptrer sammen på tvers av flere dokumenter, og signaliserer semantiske relasjoner til søkealgoritmer
- Tematisk autoritet: Grundig dekning av et emne gjennom relaterte konsepter, som etablerer ekspertise og troverdighet hos både søkemotorer og AI-systemer
- Naturlig integrering: Sømløs innfletting av relaterte termer i innholdet slik at det leses naturlig for mennesker, samtidig som det signaliserer relevans til søkemotorer
- Søkeintensjon: Bruk av semantisk relaterte termer som samsvarer med det brukerne faktisk søker etter, og øker innholdets relevans og klikkrate
- Entitetsgjenkjenning: Identifisering og inkludering av navngitte entiteter og konsepter relatert til hovedtema, avgjørende for evaluering fra AI-systemer
- Semantisk fylde: Dybde og bredde av konseptuelt relatert innhold, som indikerer omfattende emnedekning
- Long-tail-nøkkelordvarianter: Lengre, mer spesifikke fraser som fanger opp relatert søkeintensjon og reduserer konkurranse
- Innholdsmessig fylde: Å dekke flere vinkler og undertema relatert til hovednøkkelordet, og forbedre den totale innholdskvaliteten
- AI-siteringspotensial: Å vise ekspertise gjennom semantisk dekning øker sannsynligheten for å bli sitert av AI-systemer som ChatGPT og Perplexity
Fremtiden for semantisk forståelse i søk
Utviklingen innen søketeknologi peker tydelig mot stadig mer sofistikert semantisk forståelse drevet av kunstig intelligens og maskinlæring. LSI-nøkkelord som spesifikk teknologi representerer et tidlig forsøk på å løse problemet med semantisk forståelse, men moderne tilnærminger har langt overgått disse mulighetene. Fremtidige søkesystemer vil sannsynligvis være enda mer avhengige av nevrale nettverk, transformermodeller og store språkmodeller for å forstå ikke bare hva innhold sier, men hva det betyr i bredere kontekster. Fremveksten av Generative Engine Optimization (GEO) som fagfelt reflekterer dette skiftet—markedsførere må nå optimalisere ikke bare for tradisjonelle søkemotorer, men for AI-systemer som genererer svar. Disse AI-systemene vurderer kildemateriale basert på fylde, ekspertise og tematisk autoritet—egenskaper som naturlig oppstår gjennom semantisk optimalisering. Etter hvert som AI Overviews blir mer utbredt i søkeresultatene, blir evnen til å vise tematisk ekspertise gjennom semantisk rikt innhold stadig mer verdifull. Fremtiden innebærer trolig enda tettere integrering mellom tradisjonell SEO og AI-optimalisering, med semantisk forståelse som bro mellom disse disiplinene. Innholdsskapere som forstår og implementerer prinsippene for semantisk optimalisering vil opprettholde synlighetsfordeler etter hvert som søketeknologien utvikler seg.
Konklusjon: Fra LSI-nøkkelord til semantisk autoritet
Selv om LSI-nøkkelord som spesifikk algoritmisk tilnærming ikke lenger brukes av Google, er det underliggende prinsippet—at søkemotorer bør forstå innholdets kontekst og mening—mer aktuelt enn noensinne. Utviklingen fra LSI til semantisk SEO til moderne AI-optimalisering er en naturlig progresjon i hvordan søketeknologi forstår og vurderer innhold. For innholdsskapere og merkevarer som ønsker synlighet på tvers av søkemotorer og AI-plattformer, er det praktiske rådet klart: skap omfattende, tematisk rikt innhold som naturlig inkorporerer relaterte konsepter og viser ekspertise. Denne tilnærmingen tilfredsstiller både tradisjonelle søkemotorers krav og evalueringskriteriene til AI-systemer som ChatGPT, Perplexity, Google AI Overviews og Claude. Ved å forstå forholdet mellom ditt hovednøkkelord og semantisk relaterte termer kan du lage innhold som både rangerer godt i tradisjonelle søkeresultater og blir sitert som autoritativt kildemateriale av AI-systemer. Fremtiden for synlighet i søk tilhører dem som mestrer semantisk optimalisering—not gjennom nøkkelord-fylling eller kunstig terminnsetting, men gjennom genuin ekspertise og helhetlig emnedekning som naturlig inkluderer relaterte konsepter og viser dyp forståelse av emnet.