
Multimodal AI-søk: Optimalisering for bilde- og stemmespørringer
Bli ekspert på multimodal AI-søkeoptimalisering. Lær hvordan du optimaliserer bilder og stemmespørringer for AI-drevne søkeresultater, med strategier for GPT-4o...
8 min lesing

AI-systemer som behandler og svarer på forespørsler som involverer tekst, bilder, lyd og video samtidig, og muliggjør en mer omfattende forståelse og kontekstbevisste svar på tvers av flere datatyper.
AI-systemer som behandler og svarer på forespørsler som involverer tekst, bilder, lyd og video samtidig, og muliggjør en mer omfattende forståelse og kontekstbevisste svar på tvers av flere datatyper.
Multimodalt AI-søk refererer til kunstige intelligenssystemer som behandler og integrerer informasjon fra flere datatyper eller modaliteter—som tekst, bilder, lyd og video—samtidig for å levere mer omfattende og kontekstuelt relevante resultater. I motsetning til unimodal AI, som baserer seg på én type input (for eksempel tekstbaserte søkemotorer), utnytter multimodale systemer de komplementære styrkene til ulike dataformater for å oppnå dypere forståelse og mer nøyaktige resultater. Denne tilnærmingen speiler menneskelig kognisjon, der vi naturlig kombinerer visuell, auditiv og tekstlig informasjon for å forstå omgivelsene våre. Ved å behandle ulike inputtyper sammen kan multimodale AI-søkesystemer fange opp nyanser og relasjoner som ville vært usynlige for tilnærminger med én modalitet.
Multimodalt AI-søk opererer gjennom avanserte fusjonsteknikker som kombinerer informasjon fra ulike modaliteter på forskjellige behandlingsstadier. Systemet trekker først ut egenskaper fra hver modalitet uavhengig, og slår deretter strategisk sammen disse representasjonene for å skape en samlet forståelse. Tidspunktet og metoden for fusjon har stor innvirkning på ytelsen, som vist i sammenligningen under:
| Fusjonstype | Når brukt | Fordeler | Ulemper |
|---|---|---|---|
| Tidlig fusjon | Inputstadiet | Fanger opp lavnivå-korrelasjoner | Mindre robust ved feiljustert data |
| Midtfusjon | Forbehandlingsstadier | Balansert tilnærming | Mer kompleks |
| Sen fusjon | Outputnivå | Modulær design | Redusert kontekstuel sammenheng |
Tidlig fusjon kombinerer rådata umiddelbart, og fanger opp detaljerte interaksjoner, men kan slite med feiljusterte input. Midtfusjon benytter fusjon under mellomliggende behandlingsstadier, og gir et balansert kompromiss mellom kompleksitet og ytelse. Sen fusjon opererer på output-nivå, og tillater uavhengig modalitetsbehandling, men kan gå glipp av viktig kryssmodal kontekst. Valg av fusjonsstrategi avhenger av de spesifikke kravene til applikasjonen og typen data som behandles.
Flere nøkkelteknologier driver moderne multimodale AI-søkesystemer og gjør det mulig å behandle og integrere ulike datatyper effektivt:
Disse teknologiene jobber sammen for å skape systemer som kan forstå komplekse relasjoner mellom ulike typer informasjon.
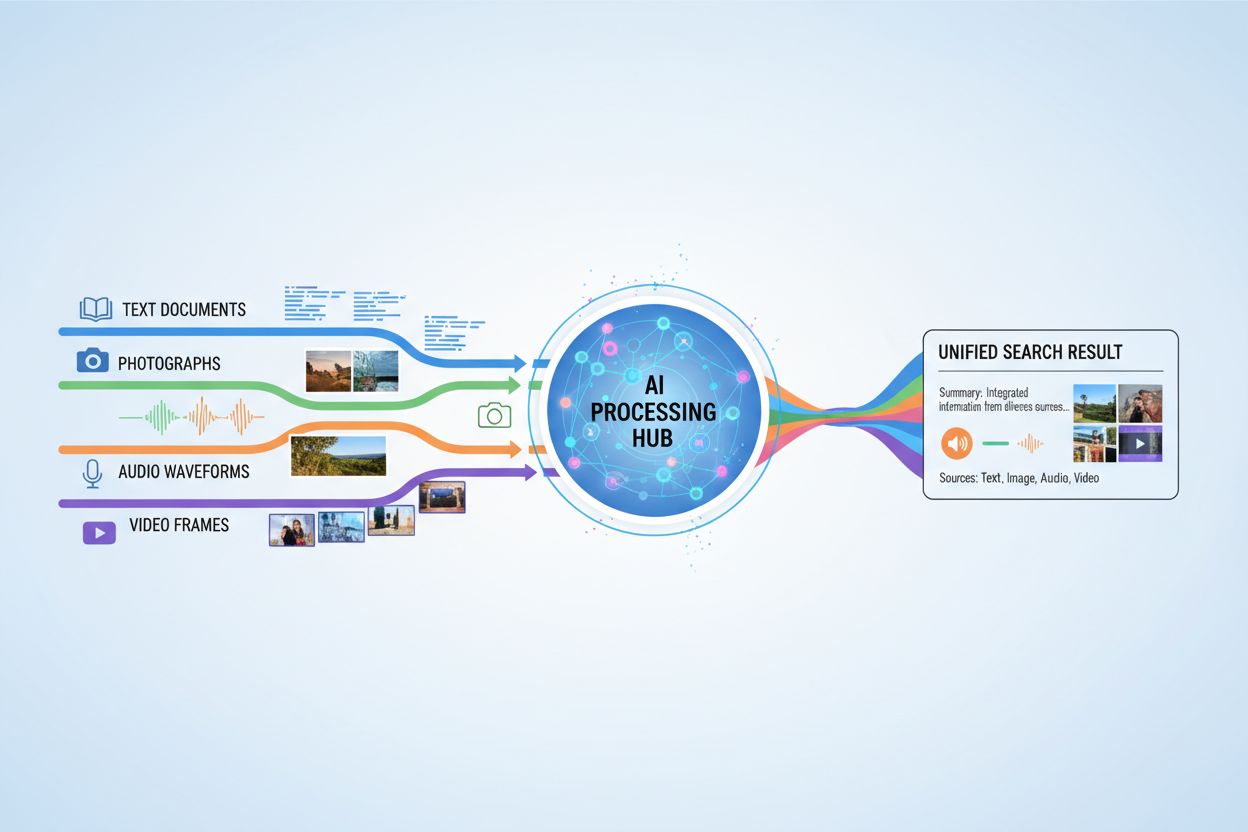
Multimodalt AI-søk har transformerende bruksområder på tvers av mange bransjer og domener. I helsevesenet analyserer systemer medisinske bilder sammen med pasientjournaler og kliniske notater for å forbedre diagnostisk nøyaktighet og behandlingsanbefalinger. E-handelsplattformer bruker multimodalt søk for at kunder skal finne produkter ved å kombinere tekstbeskrivelser med visuelle referanser eller til og med skisser. Autonome kjøretøy er avhengige av multimodal fusjon av kamerabilder, radardata og sensorinput for å navigere trygt og ta beslutninger i sanntid. Innholdsmoderering kombinerer bildedeteksjon, tekstanalyse og lydprosessering for å identifisere skadelig innhold mer effektivt enn tilnærminger med én modalitet. I tillegg forbedrer multimodalt søk tilgjengelighet ved å la brukere søke med sin foretrukne inputmetode—stemme, bilde eller tekst—mens systemet forstår hensikten på tvers av alle formater.

Multimodalt AI-søk gir betydelige fordeler som rettferdiggjør økt kompleksitet og beregningsbehov. Bedre nøyaktighet oppnås ved å utnytte komplementære informasjonskilder og redusere feil som systemer med én modalitet kan gjøre. Bedre kontekstuell forståelse oppstår når visuell, tekstlig og auditiv informasjon kombineres for å gi rikere semantisk mening. Overlegen brukeropplevelse oppnås gjennom mer intuitive søkegrensesnitt som aksepterer ulike inputtyper og gir mer relevante resultater. Tverrfaglig læring blir mulig når kunnskap fra én modalitet kan informere forståelsen i en annen, og muliggjør overføringslæring på tvers av ulike datatyper. Økt robusthet betyr at systemet opprettholder ytelsen selv når én modalitet er svekket eller utilgjengelig, fordi andre modaliteter kan kompensere for manglende informasjon.
Til tross for fordelene står multimodalt AI-søk overfor betydelige tekniske og praktiske utfordringer. Datajustering og synkronisering er fortsatt vanskelig, da ulike modaliteter ofte har ulike tidsmessige egenskaper og kvalitetsnivåer som må håndteres nøye. Beregningsteknisk kompleksitet øker vesentlig når flere datastrømmer behandles samtidig, og krever store beregningsressurser og spesialisert maskinvare. Skjevhet og rettferdighet blir et problem når treningsdata har ubalanser mellom modaliteter eller når enkelte grupper er underrepresentert i visse datatyper. Personvern og sikkerhet blir mer komplekst med flere datastrømmer, noe som øker risikoen for datainnbrudd og krever nøye håndtering av sensitiv informasjon. Store datakrav innebærer at det kreves langt større og mer varierte datasett for å trene effektive multimodale systemer sammenlignet med unimodale alternativer, noe som kan være dyrt og tidkrevende å samle inn og annotere.
Multimodalt AI-søk henger tett sammen med AI-overvåkning og siteringssporing, spesielt ettersom AI-systemer i økende grad genererer svar som refererer til eller syntetiserer informasjon fra flere kilder. Plattformer som AmICited.com fokuserer på å overvåke hvordan AI-systemer siterer og tilskriver informasjon til originale kilder, og sikrer åpenhet og ansvarlighet i AI-genererte svar. Tilsvarende sporer FlowHunt.io AI-innholdsgenerering og hjelper organisasjoner med å forstå hvordan deres merkevareinnhold blir behandlet og referert til av multimodale AI-systemer. Etter hvert som multimodalt AI-søk blir mer utbredt, blir det avgjørende for bedrifter å følge med på hvordan disse systemene siterer merkevarer, produkter og originale kilder for å forstå sin synlighet i AI-genererte resultater. Denne overvåkningsfunksjonen hjelper organisasjoner med å bekrefte at deres innhold blir korrekt representert og riktig tilskrevet når multimodale AI-systemer syntetiserer informasjon på tvers av tekst, bilder og andre modaliteter.
Fremtiden for multimodalt AI-søk peker mot stadig mer enhetlig og sømløs integrasjon av ulike datatyper, og beveger seg forbi dagens fusjonstilnærminger mot mer helhetlige modeller som behandler alle modaliteter som iboende sammenkoblede. Sanntidsbehandlingskapasitet vil øke, slik at multimodalt søk kan operere på levende videostrømmer, kontinuerlig lyd og dynamisk tekst samtidig, uten forsinkelser. Avanserte dataforsterkningsteknikker vil løse utfordringer med datamangel ved syntetisk å generere multimodale treningsdata som bevarer semantisk konsistens på tvers av modaliteter. Nye utviklinger inkluderer grunnmodeller trent på store multimodale datasett som effektivt kan tilpasses spesifikke oppgaver, nevromorfiske datatilnærminger som etterligner biologisk multimodal prosessering, og føderert multimodal læring som muliggjør trening på tvers av distribuerte datakilder samtidig som personvernet ivaretas. Disse fremskrittene vil gjøre multimodalt AI-søk mer tilgjengelig, effektivt og i stand til å håndtere stadig mer komplekse scenarier i virkeligheten.
Unimodale AI-systemer behandler kun én type datainngang, for eksempel tekstbaserte søkemotorer. Multimodale AI-systemer, derimot, behandler og integrerer flere datatyper—tekst, bilder, lyd og video—samtidig, noe som muliggjør dypere forståelse og mer nøyaktige resultater ved å utnytte de komplementære styrkene til ulike dataformater.
Multimodalt AI-søk forbedrer nøyaktigheten ved å kombinere komplementære informasjonskilder som fanger opp nyanser og relasjoner som er usynlige for tilnærminger med én modalitet. Når visuell, tekstlig og auditiv informasjon kombineres, oppnår systemet rikere semantisk forståelse og kan ta bedre beslutninger basert på flere perspektiver av samme informasjon.
Viktige utfordringer inkluderer datajustering og synkronisering på tvers av ulike modaliteter, betydelig beregningskompleksitet, skjevhet og rettferdighetsbekymringer når treningsdata er ubalansert, personvern- og sikkerhetsproblemer med flere datastrømmer, samt store datakrav for effektiv trening. Hver modalitet har ulike tidsmessige egenskaper og kvalitetsnivåer som må håndteres nøye.
Helsevesenet drar nytte av å analysere medisinske bilder sammen med pasientjournaler og kliniske notater. E-handel bruker multimodalt søk for visuell produktoppdagelse. Autonome kjøretøy er avhengige av multimodal fusjon av kameraer, radar og sensorer. Innholdsmoderering kombinerer bilde-, tekst- og lydanalyse. Kundeservicesystemer utnytter flere inntastingsmetoder for bedre støtte, og tilgjengelighetsapplikasjoner lar brukere søke med sin foretrukne metode.
Embedding-modeller konverterer ulike modaliteter til numeriske representasjoner som fanger opp semantisk mening. Vektordatabaser lagrer disse embeddingene i et felles matematisk rom hvor relasjoner mellom ulike datatyper kan måles og sammenlignes. Dette gjør det mulig for systemet å finne forbindelser mellom tekst, bilder, lyd og video ved å sammenligne deres posisjoner i dette felles semantiske rommet.
Multimodale AI-systemer håndterer flere sensitive datatyper—opptak av samtaler, ansiktsgjenkjenningsdata, skriftlig kommunikasjon og medisinske bilder—som øker personvernrisikoen. Kombinasjonen av ulike modaliteter gir flere muligheter for databrudd og krever streng etterlevelse av regelverk som GDPR og CCPA. Organisasjoner må implementere robuste sikkerhetstiltak for å beskytte brukeridentitet og sensitiv informasjon på tvers av alle modaliteter.
Plattformer som AmICited.com overvåker hvordan AI-systemer siterer og tilskriver informasjon til originale kilder, og sikrer åpenhet i AI-genererte svar. Organisasjoner kan følge sin synlighet i multimodale AI-søkeresultater, verifisere at innholdet deres er korrekt representert, og bekrefte riktig attribusjon når AI-systemer syntetiserer informasjon på tvers av tekst, bilder og andre modaliteter.
Fremtiden inkluderer enhetlige modeller som behandler alle modaliteter som iboende sammenkoblede, sanntidsbehandling av levende video- og lydstrømmer, avanserte dataforsterkningsteknikker for å håndtere datamangel, grunnmodeller trent på store multimodale datasett, nevromorfiske datatilnærminger som etterligner biologisk behandling, og føderert læring som ivaretar personvernet ved trening på tvers av distribuerte kilder.
Følg med på hvordan multimodale AI-søkemotorer siterer og tilskriver innholdet ditt på tvers av tekst, bilder og andre modaliteter med AmICiteds omfattende overvåkningsplattform.
Bli ekspert på multimodal AI-søkeoptimalisering. Lær hvordan du optimaliserer bilder og stemmespørringer for AI-drevne søkeresultater, med strategier for GPT-4o...

Lær hva multimodalt innhold for KI er, hvordan det fungerer, og hvorfor det er viktig. Utforsk eksempler på multimodale KI-systemer og deres bruksområder på tve...

Lær hvordan du optimaliserer tekst, bilder og video for multimodale AI-systemer. Oppdag strategier for å forbedre AI-sitater og synlighet på tvers av ChatGPT, G...