Query Fanout: Hvordan LLM-er genererer flere søk bak kulissene
Oppdag hvordan moderne AI-systemer som Google AI Mode og ChatGPT deler opp én forespørsel til flere søk. Lær om fanout-mekanismer, konsekvenser for AI-synlighet...
8 min lesing
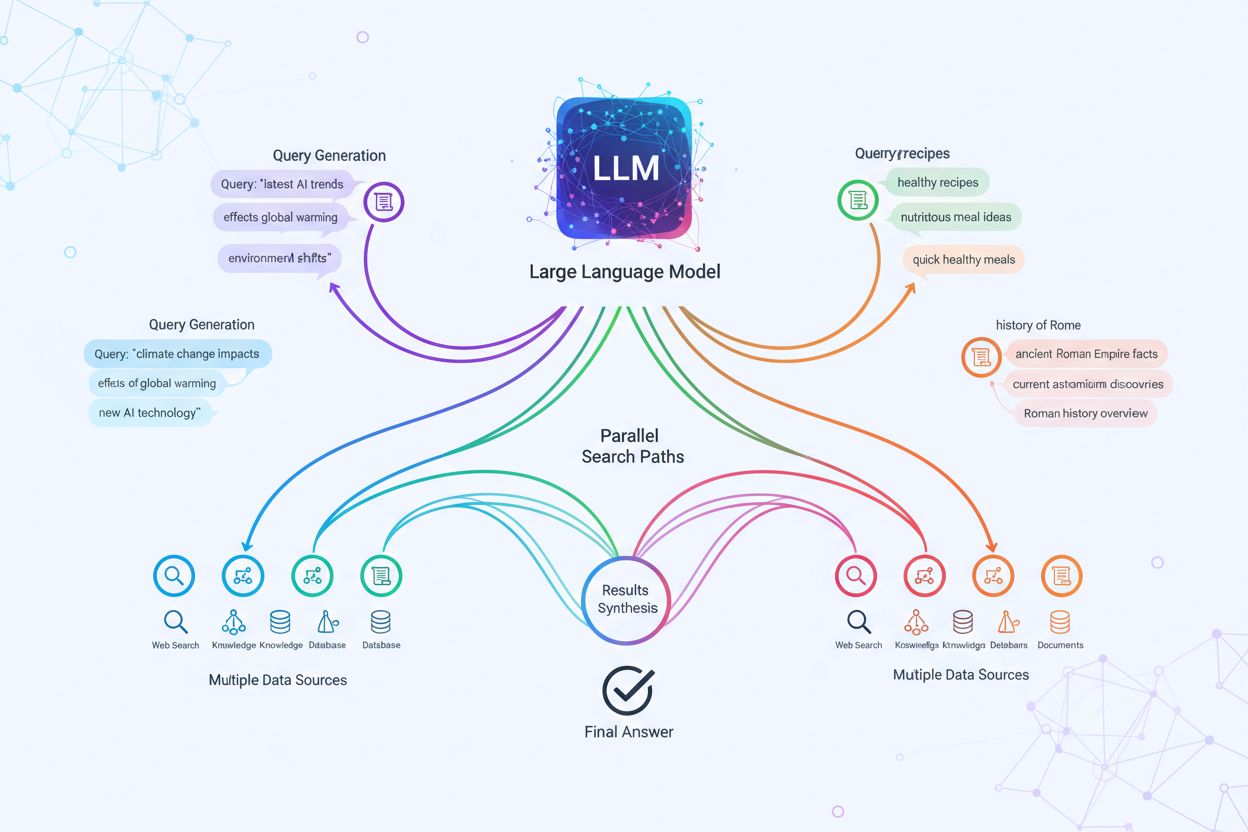
Query Fanout er AI-prosessen der én enkelt brukerforespørsel automatisk utvides til flere relaterte underforespørsler for å samle inn omfattende informasjon fra ulike vinkler. Denne teknikken hjelper AI-systemer med å forstå brukerens egentlige hensikt og levere mer nøyaktige, kontekstuelt relevante svar ved å utforske ulike tolkninger og aspekter ved det opprinnelige spørsmålet.
Query Fanout er AI-prosessen der én enkelt brukerforespørsel automatisk utvides til flere relaterte underforespørsler for å samle inn omfattende informasjon fra ulike vinkler. Denne teknikken hjelper AI-systemer med å forstå brukerens egentlige hensikt og levere mer nøyaktige, kontekstuelt relevante svar ved å utforske ulike tolkninger og aspekter ved det opprinnelige spørsmålet.
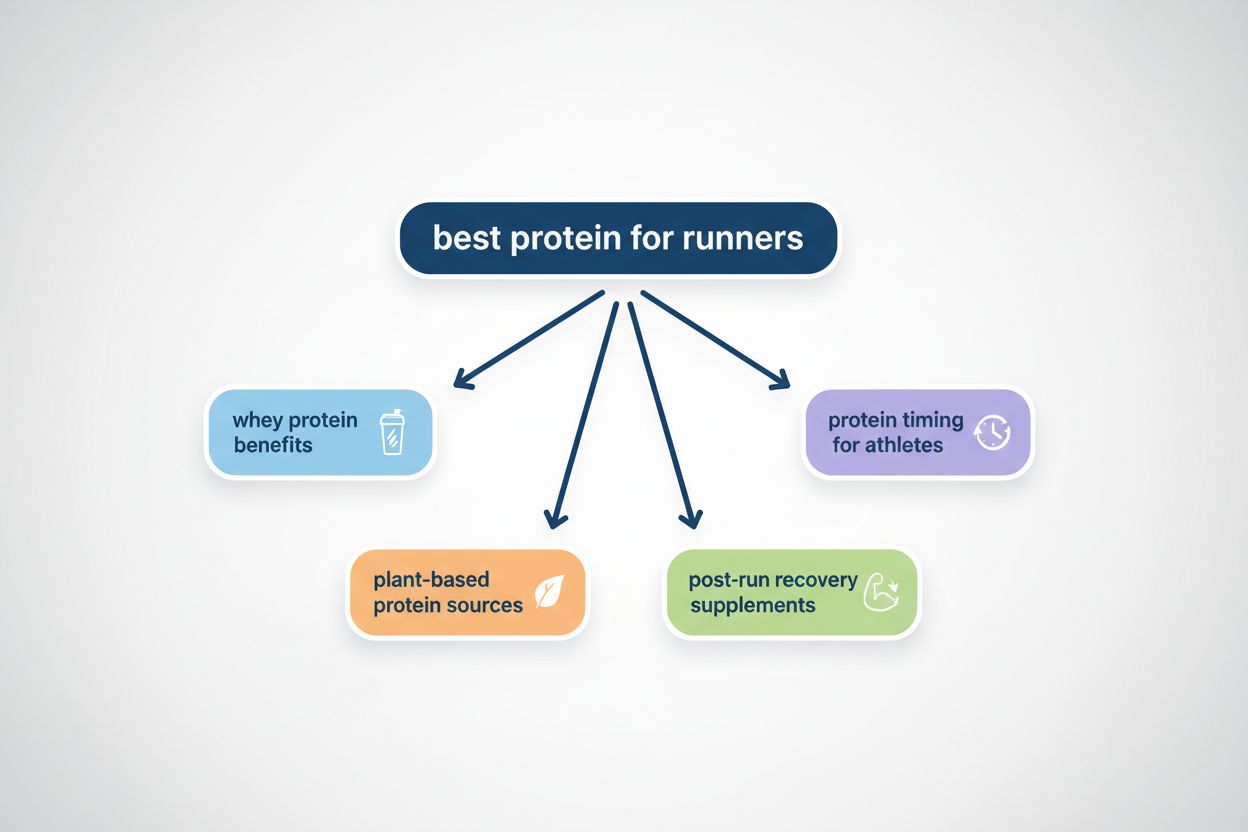
Query Fanout er prosessen der AI-systemer automatisk utvider en enkelt brukerforespørsel til flere relaterte underforespørsler for å samle inn omfattende informasjon fra ulike vinkler. I stedet for bare å matche nøkkelord som tradisjonelle søkemotorer, gjør query fanout det mulig for AI å forstå den egentlige hensikten bak et spørsmål ved å utforske forskjellige tolkninger og relaterte temaer. For eksempel, når en bruker søker etter “beste protein for løpere,” kan et AI-system som bruker query fanout automatisk generere underforespørsler som “fordeler med myseprotein,” “plantebaserte proteinkilder” og “kosttilskudd for restitusjon etter løpetur.” Denne teknikken er grunnleggende for hvordan moderne AI-søkesystemer som Google AI Mode, ChatGPT, Perplexity og Gemini leverer mer nøyaktige og kontekstuelt relevante svar. Ved å bryte ned komplekse forespørsler til enklere, mer fokuserte under-spørsmål, kan AI-systemer hente mer målrettet informasjon og syntetisere den til omfattende svar som dekker flere dimensjoner av det brukerne faktisk er ute etter.
Den tekniske mekanismen bak query fanout følger en systematisk femstegsprosess som omdanner én enkelt forespørsel til handlingsrettet innsikt. Først tolker AI-systemet den opprinnelige forespørselen for å identifisere kjerneintensjon og mulige tvetydigheter. Deretter genereres flere underforespørsler basert på utledede temaer, emner og relaterte konsepter som kan hjelpe å svare på det opprinnelige spørsmålet mer fullstendig. Disse underforespørslene utføres så parallelt på tvers av søkeinfrastrukturen, hvor Googles tilnærming bruker sin tilpassede versjon av Gemini for å bryte spørsmål opp i ulike undertemaer og sende flere forespørsler samtidig på vegne av brukeren. Systemet klustrer og grupperer deretter de innhentede resultatene etter tema, entitetstype og hensikt, og legger på siteringer slik at ulike aspekter av svaret er korrekt kildehenvist. Til slutt syntetiserer AI all denne informasjonen til et sammenhengende svar som adresserer den opprinnelige forespørselen fra ulike vinkler. I praksis kan Googles AI Mode utføre åtte eller flere bakgrunnssøk for en moderat kompleks forespørsel, mens den mer avanserte Deep Search-funksjonen kan sende dusinvis eller hundrevis av forespørsler over flere minutter for å levere spesielt grundig research på komplekse temaer som kjøpsbeslutninger.
| Steg | Beskrivelse | Eksempel |
|---|---|---|
| 1. Tolkning | AI analyserer opprinnelig forespørsel for hensikt | “beste CRM for små bedrifter” |
| 2. Underforespørselsgenerering | Systemet lager relaterte varianter | “gratis CRM-verktøy”, “CRM med e-postautomatisering” |
| 3. Parallell utførelse | Flere søk kjøres samtidig | Alle underforespørsler søkes på én gang |
| 4. Resultatklustring | Resultater grupperes etter tema/entitet | Gruppe 1: Gratis verktøy, Gruppe 2: Betalte løsninger |
| 5. Syntese | AI kombinerer resultater til et sammenhengende svar | Ett omfattende svar med siteringer |
AI-systemer benytter query fanout av flere strategiske grunner som grunnleggende forbedrer svarenes kvalitet og pålitelighet:
Løsning av tvetydigheter – En enkelt forespørsel som “Jaguar speed” kan referere til enten bilprodusentens ytelsesspesifikasjoner eller dyrets jaktfart, og query fanout hjelper systemet å teste flere tolkninger for å finne mest sannsynlig brukerhensikt.
Faktagrunnlag og reduksjon av hallusinasjoner – Ved å hente bevis fra flere uavhengige kilder for hver gren av forespørselen, kan AI kryssjekke påstander og verifisere informasjon før presentasjon, noe som reduserer risikoen for selvsikre, men feilaktige svar betydelig.
Perspektivmangfold – Query fanout henter informasjon fra ulike innholdstyper—kliniske studier, kjøpsguider, forumdiskusjoner og merkevaresider—slik at svarene balanserer autoritet med praktisk nytte.
Håndtering av komplekse forespørsler – Teknikken utmerker seg ved å håndtere komplekse, lagdelte forespørsler som krever syntese av informasjon fra flere domener.
Generering av nye svar – Query fanout gjør det mulig for AI-systemer å besvare spørsmål som ikke tidligere har blitt besvart online, ved å kombinere flere informasjonsbiter og trekke nye konklusjoner som ingen enkeltkilde eksplisitt adresserer.
Forskjellen mellom query fanout og tradisjonelt søk representerer et grunnleggende skifte i hvordan informasjonsinnhenting fungerer. Tradisjonelle søkemotorer opererer primært gjennom nøkkelordmatching og returnerer en rangert liste over resultater basert på hvor godt individuelle sider samsvarer med eksakte termer i forespørselen, og brukeren må selv forbedre søket hvis de første resultatene ikke er tilfredsstillende. Query fanout, derimot, fokuserer på forståelse av hensikt snarere enn nøkkelordmatching, og systemet utforsker automatisk flere vinkler og tolkninger uten at brukeren trenger å gripe inn. I tradisjonelt søk må brukeren ofte utføre flere oppfølgingssøk for å få et komplett bilde—søke etter “beste CRM-programvare”, så “gratis CRM-verktøy”, så “CRM med e-postautomatisering”—mens query fanout håndterer denne utforskningen automatisk i én interaksjon. Dette skiftet har store konsekvenser for innholdsprodusenter og markedsførere, som ikke lenger bare kan optimalisere for individuelle nøkkelord, men må sikre at innholdet dekker hele klynger av relaterte temaer og hensikter som AI-systemer vil utforske. Endringen påvirker også grunnleggende SEO-strategi, hvor fokuset går fra rangering på spesifikke søkeord til synlighet på tvers av flere relaterte forespørsler og oppbygging av tematisk autoritet slik at innholdet fremstår som relevant for bredere temaklynger.
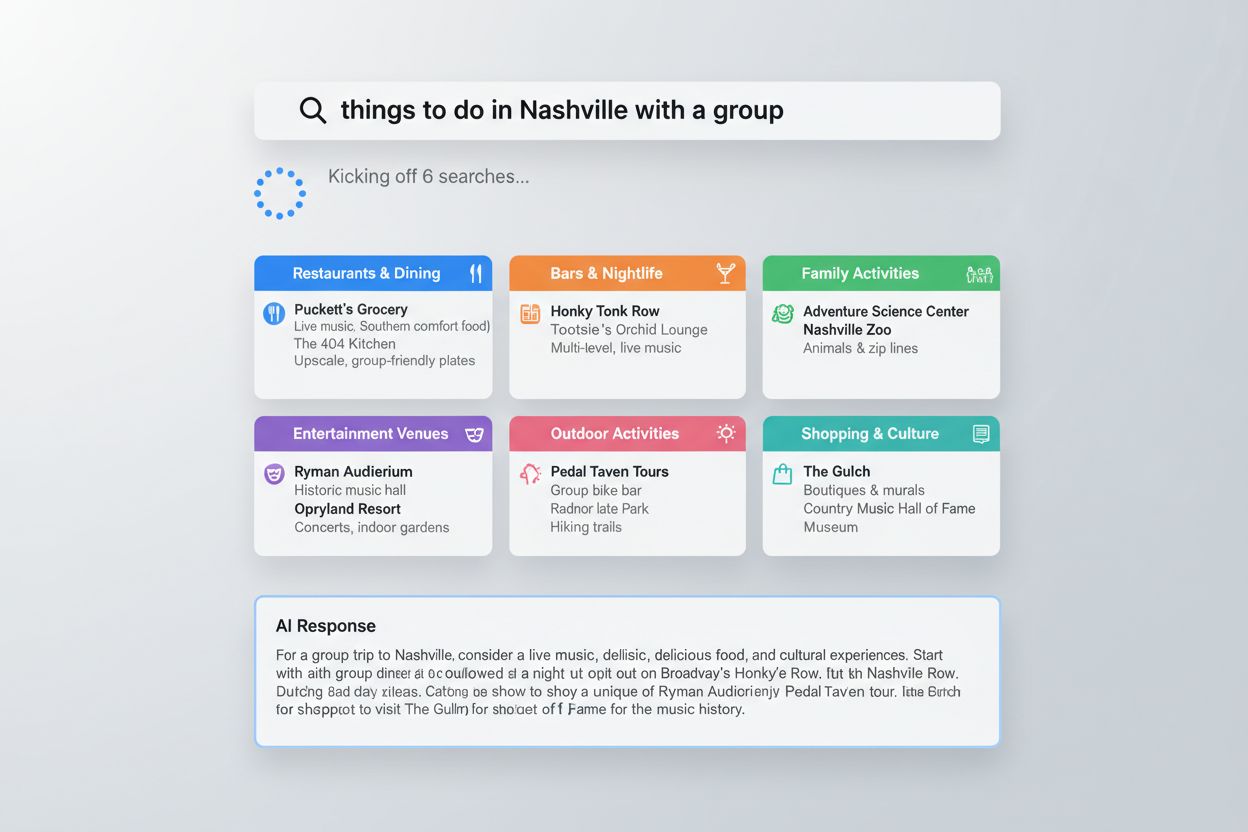
Query fanout manifesterer seg på praktiske, observerbare måter på tvers av store AI-plattformer. Når en bruker ber Google AI Mode om “ting å gjøre i Nashville med en gruppe,” fanner systemet automatisk ut forespørselen til under-spørsmål om gode restauranter, barer, familievennlige aktiviteter og underholdningssteder, og syntetiserer så resultatene til en omfattende guide tilpasset gruppeaktiviteter. ChatGPT demonstrerer lignende oppførsel ved “beste X”-forespørsler, der den adresserer flere vinkler som “best for budsjett”, “best for funksjoner” og “best for spesifikke brukstilfeller” i ett svar. Deep Search-funksjonaliteten viser teknikkens styrke for komplekse beslutninger—ved research på safer til hjemmebruk kan systemet bruke flere minutter på dusinvis av forespørsler om brannmotstand, forsikringsimplikasjoner, spesifikke produkttyper og brukeranmeldelser, og til slutt levere et usedvanlig grundig svar med lenker til produkter og detaljerte sammenligninger. Utover disse eksemplene driver query fanout shoppinganbefalinger, restaurantforslag og aksjesammenligninger, hvor ulike AI-plattformer implementerer teknikken gjennom integrasjon med interne verktøy som Google Finance og Shopping Graph, som oppdateres 2 milliarder ganger i timen for å sikre sanntidsnøyaktighet. Denne evnen til å integrere sanntidsdata gjør at query fanout ikke er begrenset til statisk informasjon, men også kan innlemme oppdaterte priser, tilgjengelighet, markedsdata og annen dynamisk informasjon som stadig endres.
Query fanout endrer grunnleggende hvordan merkevarer oppnår synlighet i AI-genererte svar, og skaper både muligheter og utfordringer for organisasjoner som ønsker å påvirke hvordan de presenteres i AI-svar. Fordi query fanout får AI-systemer til å utforske flere underforespørsler, må merkevarer nå være synlige i resultater på tvers av flere relaterte søk, ikke bare det primære søket—det betyr at et selskap kun optimalisert for “CRM-programvare” kan gå glipp av synlighet for “gratis CRM-verktøy” eller “CRM med e-postautomatisering.” Betydningen av å bli fremhevet positivt i AI-svar har økt enormt, siden disse svarene direkte påvirker forbrukerbeslutninger og ofte reduserer behovet for å oppsøke andre informasjonskilder. Å forstå forskjellen mellom AI-omtaler (usiterte referanser til merkevaren i AI-svar) og AI-siteringer (lenkede referanser til innholdet ditt) er avgjørende, fordi siteringer gir både synlighet og troverdighet, mens omtaler øker bevisstheten uten direkte trafikkmåling. Her blir overvåkningsverktøy som AmICited.com essensielle—de sporer hvordan merkevaren din vises på tvers av flere AI-plattformer (Google AI Mode, ChatGPT, Perplexity, Gemini og andre), og viser ikke bare om du nevnes, men hvor du vises i svarhierarkiet, hvor ofte du siteres, og hvilken tone som omgir omtalen. Organisasjoner som forstår query fanout og aktivt optimaliserer for det, får betydelige konkurransefortrinn i AI-synlighet, siden de i større grad vises i de mange underforespørselsresultatene som samlet avgjør kvaliteten på AI-svaret.
Å optimalisere for query fanout krever en fundamentalt annerledes tilnærming enn tradisjonell nøkkelordfokusert SEO. Første steg er å identifisere kjerneemner direkte knyttet til virksomheten og ekspertisen din, da disse representerer områdene hvor du mest troverdig kan dekke de ulike vinklene query fanout utforsker. Deretter bør du lage emneklynger bestående av en sentral pilarside som gir oversikt over et hovedtema, omgitt av klyngesider som dekker spesifikke undertemaer—denne strukturen hjelper AI-systemer å oppfatte innholdet ditt som en omfattende ressurs på tvers av flere relaterte forespørsler. Planlegg omfattende innhold som dekker ikke bare hovedtemaet, men alle undertemaer, sammenligninger og spørsmål AI-systemer kan utforske når en forespørsel fannes ut, slik at hver side fungerer som et nav som tilfredsstiller flere hensikter samtidig. Skriv for NLP (naturlig språkprosessering) ved å bruke klare definisjoner, fullstendige setninger og selvstendige seksjoner som AI-systemer enkelt kan tolke og hente ut informasjon fra, i stedet for å fokusere på nøkkelordtetthet eller andre tradisjonelle SEO-taktikker. Implementer schema markup for å legge til maskinlesbare etiketter for ulike datatyper på sidene dine, slik at AI-systemer tolker innholdet mer nøyaktig—for eksempel ved å bruke Product schema for produktnavn og bilder, eller Offer schema for pris og tilgjengelighet. Fokuser på semantisk fullstendighet ved å sørge for at innholdet tydelig refererer til relaterte enheter, konsepter og relasjoner som finnes på tvers av fanout-grenene, og bygg en sterk intern lenkestrategi med kontekstuelle ankertekster for å signalisere tematisk dybde og hjelpe AI-systemene å forstå sammenhengene mellom innholdet ditt.
Måten du strukturerer og formaterer innholdet på påvirker direkte hvor effektivt AI-systemer kan hente ut og bruke informasjon til query fanout-svar. Skriv i blokker—selvstendige, meningsfulle seksjoner som kan stå alene og enkelt behandles, hentes ut og oppsummeres av AI-systemer—ved å bruke fullstendige setninger og gjenta kontekst der det er nyttig, i stedet for å lene deg på fragmenterte punktlister eller nøkkelordtung tekst. Gi klare definisjoner når du introduserer nye konsepter, da AI-systemer ofte leter etter definisjoner som en del av query fanout-prosessen og prioriterer sider som eksplisitt definerer begreper. Bruk beskrivende underoverskrifter for å dele opp innholdet i logiske seksjoner og bruk riktig overskriftshierarki (H2, H3, H4) for å vise relasjoner mellom temaer, slik at AI-systemer kan identifisere innhold relevant for svært spesifikke forespørsler. Strukturer innhold med tabeller og lister for å lage lettparset informasjon som AI-systemer kan hente ut og omorganisere, og bruk klart, samtalepreget språk som unngår sjargong, for kompliserte setningsstrukturer og unødvendig fyllstoff. Stripe-nettsiden er et godt eksempel på beste praksis, med løsningssider tilpasset ulike forretningsstadier og brukstilfeller, underseksjoner som gir direkte og detaljerte opplysninger om relevante undertemaer, og omfattende dekning i blogginnlegg, kundehistorier, supportsider og andre ressurser. Denne flerformat, dypt strukturerte tilnærmingen hjelper AI-systemer å gjenkjenne Stripes relevans for ulike hensikter og hente ut nyttig informasjon for fanned-out-forespørsler, noe som bidrar til deres sterke synlighet i AI-søk på plattformer som Google AI Mode, SearchGPT, ChatGPT, Perplexity og Gemini.
Å måle suksess med query fanout-optimalisering krever spesialiserte verktøy og målinger som går utover tradisjonell SEO-analyse. Verktøy som Semrushs AI Visibility Toolkit og AmICited gir innsikt i merkevarens ytelse på tvers av ulike AI-plattformer, og viser din share of voice for ikke-merkede forespørsler på Google AI Mode, SearchGPT, ChatGPT, Perplexity, Gemini og andre systemer. Disse plattformene avslører ikke bare om merkevaren din nevnes, men hvor den vises i svarhierarkiet—om du siteres først, som nummer to, eller lenger ned—noe som direkte korrelerer med synlighet og innflytelse. Å spore omtaler versus siteringer separat er viktig, fordi siteringer gir både synlighet og trafikk, mens omtaler øker bevisstheten; å forstå dette skillet hjelper deg å prioritere optimaliseringstiltakene. Sentimentanalyse i AI-svar viser hvordan merkevaren din fremstilles—om AI-systemene fremhever styrkene dine eller peker på svakheter—slik at du kan identifisere forbedringsområder for hvordan du omtales. Konkurrentbenchmarking mot rivaler avdekker hull i din AI-synlighetsstrategi og muligheter for å utkonkurrere andre i spesifikke forespørselsklynger. Betydningen av kontinuerlig overvåkning kan ikke overvurderes, siden AI-systemene utvikler seg raskt, nye plattformer dukker opp, og forespørselsmønstre endres; jevnlig sporing sikrer at du kan tilpasse strategien og opprettholde synlighet etter hvert som landskapet endrer seg.
Utviklingen for query fanout peker mot stadig mer sofistikert forståelse av forespørsler og mer komplekse AI-resonneringsprosesser. Etter hvert som AI-systemene utvikler seg, vil de sannsynligvis få enda mer nyanserte evner til å bryte ned forespørsler i under-spørsmål, forstå implisitt kontekst og syntetisere informasjon på tvers av stadig mer varierte kilder. Grensene mellom tradisjonelt og AI-basert søk vil fortsette å viskes ut, der tradisjonelle søkemotorer tar i bruk mer AI-drevet forståelse av forespørsler, mens AI-systemene i økende grad integrerer sanntidssøk, og skaper et hybridlandskap hvor optimaliseringsstrategier må dekke begge paradigmer. Denne utviklingen krever en grunnleggende endring i hvordan organisasjoner jobber med søkeoptimalisering, bort fra fokuset på nøkkelordrangering og over mot kontekstuelt synlighet, slik at innholdet vises på tvers av hele spekteret av relaterte forespørsler AI-systemer utforsker. Tematisk autoritet—det å etablere dyp, omfattende ekspertise på relaterte emner—blir stadig viktigere etter hvert som AI-systemene belønner innhold som viser mestring av hele temaklynger, ikke bare enkeltstående nøkkelord. Fremvoksende beste praksis for query fanout-optimalisering vektlegger semantisk fullstendighet, entitetsrelasjoner, innholdsstruktur og overvåkning av synlighet på tvers av plattformer, og krever at organisasjoner tenker helhetlig om hvordan innholdsøkosystemet deres dekker de mange vinklene og tolkningene AI-systemer vil utforske når de besvarer brukerens spørsmål.
Query Fanout er den automatiske prosessen der AI-systemer bryter ned én enkelt forespørsel i flere underforespørsler for å forstå den egentlige hensikten og samle inn omfattende informasjon. Query Expansion, derimot, er en teknikk for å legge til relaterte termer for å forbedre gjenfinning, noe som kan være enten manuelt eller automatisk. Query Fanout er mer sofistikert og hensiktsfokusert, mens query expansion hovedsakelig er nøkkelordfokusert.
Antallet varierer basert på forespørselens kompleksitet. Enkle forespørsler kan generere 1–3 underforespørsler, mens moderat komplekse forespørsler typisk produserer 5–8 underforespørsler. Avanserte funksjoner som Googles Deep Search kan utføre dusinvis eller til og med hundrevis av bakgrunnsforespørsler over flere minutter for spesielt grundig research på komplekse temaer.
Ja, indirekte. Innhold optimalisert for Query Fanout har en tendens til å prestere bedre også i tradisjonelt søk, fordi optimaliseringsprosessen krever omfattende dekning av emnet, klar struktur og semantisk fullstendighet—alle faktorer som søkemotorer belønner. Den primære fordelen er imidlertid forbedret synlighet i AI-genererte svar snarere enn tradisjonelle søkeresultater.
Store AI-plattformer som implementerer Query Fanout inkluderer Google AI Mode, ChatGPT, Perplexity, Gemini og andre LLM-baserte søkesystemer. Hver plattform implementerer teknikken litt forskjellig, men alle bruker en form for forespørselsdekomponering for å forbedre svarenes kvalitet og relevans.
Lag emneklynger med pilar- og klynge-sider, skriv omfattende innhold som dekker undertemaer og relaterte spørsmål, implementer schema markup for strukturert data, bruk tydelige overskrifter og formatering, bygg sterke interne lenker og fokuser på semantisk fullstendighet. Skriv for naturlig språkprosessering ved å bruke klare definisjoner og selvstendige seksjoner som AI-systemer enkelt kan tolke.
Query Fanout øker mulighetene for AI-siteringer ved å sikre at innholdet ditt vises i resultater for flere relaterte underforespørsler. Når AI-systemer utforsker ulike vinkler av et spørsmål, er det mer sannsynlig at de oppdager og siterer innholdet ditt hvis det dekker disse ulike vinklene og perspektivene grundig.
Query Fanout forbedrer brukeropplevelsen betydelig ved å gjøre det mulig for AI-systemer å levere mer nøyaktige, omfattende svar uten at brukerne må forbedre forespørslene sine flere ganger. Brukere får bedre tilpassede svar som dekker flere dimensjoner av spørsmålet i én enkelt interaksjon.
Ja, Query Fanout bidrar til å redusere hallusinasjoner ved å kryssjekke informasjon på tvers av flere kilder. Når AI-systemer henter bevis fra ulike kilder for hver gren av en fanned-out-forespørsel, kan de verifisere påstander og identifisere avvik, noe som reduserer risikoen for selvsikre, men feilaktige svar betydelig.
Følg med på hvordan innholdet ditt vises på AI-plattformer når forespørsler utvides. Forstå din AI-synlighet og siteringer med AmICiteds omfattende overvåkningsplattform.
Oppdag hvordan moderne AI-systemer som Google AI Mode og ChatGPT deler opp én forespørsel til flere søk. Lær om fanout-mekanismer, konsekvenser for AI-synlighet...

Lær de essensielle første stegene for å optimalisere innholdet ditt for AI-søkemotorer som ChatGPT, Perplexity og Google AI Overviews. Oppdag hvordan du struktu...
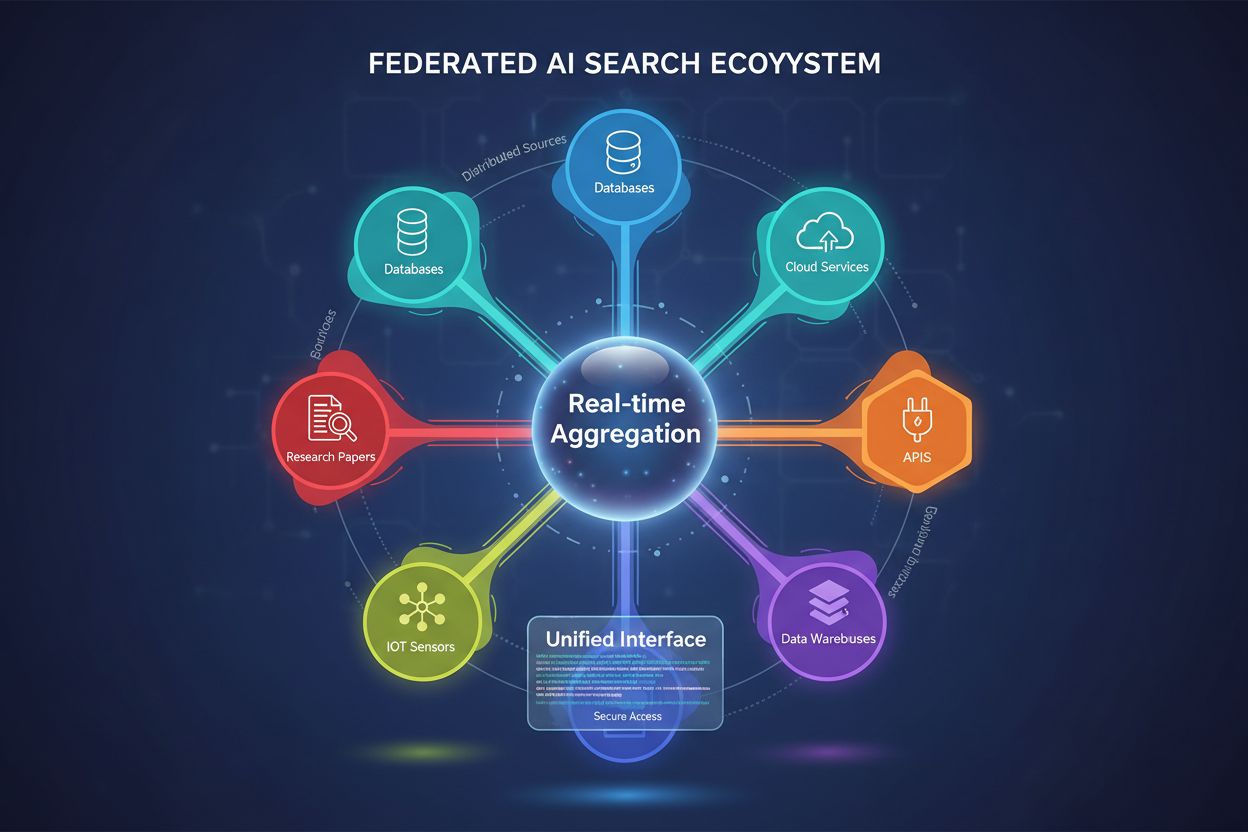
Lær hva føderert AI-søk er, hvordan det fungerer, dets fordeler for virksomheter, og hvordan det skiller seg fra tradisjonelle sentraliserte søkesystemer. Oppda...