Forskningsinnhold – Datadrevet analytisk innhold
Forskningsinnhold er evidensbasert materiale laget gjennom dataanalyse og ekspertinnsikt. Lær hvordan datadrevet analytisk innhold bygger autoritet, påvirker AI...
11 min lesing
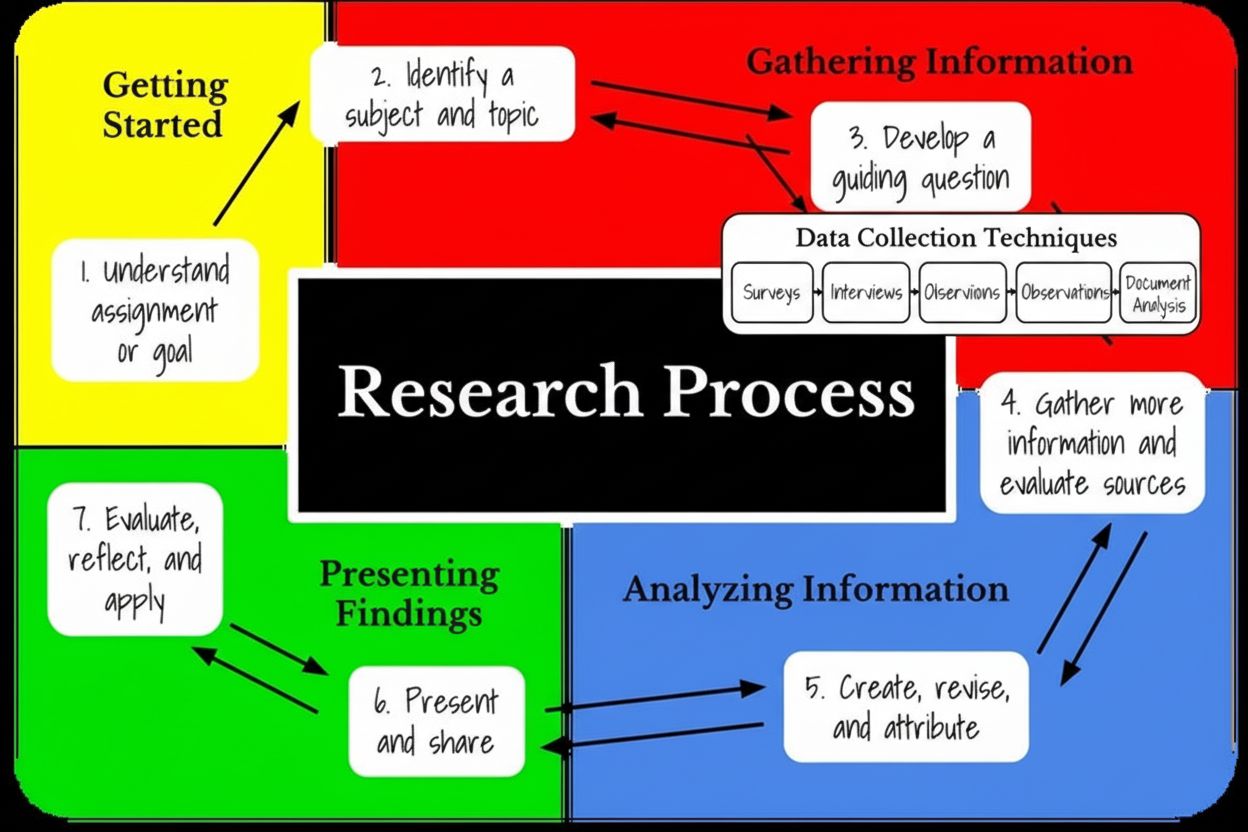
Forskningsfasens informasjonsinnhentingsstadium er den systematiske prosessen med å samle inn, organisere og evaluere data, fakta og kunnskap fra ulike kilder for å besvare bestemte forskningsspørsmål. Dette grunnleggende stadiet innebærer å velge egnede metoder for datainnsamling, gjennomføre kvalitetskontrolltiltak og etablere klare mål før analyse og tolkning starter.
Forskningsfasens informasjonsinnhentingsstadium er den systematiske prosessen med å samle inn, organisere og evaluere data, fakta og kunnskap fra ulike kilder for å besvare bestemte forskningsspørsmål. Dette grunnleggende stadiet innebærer å velge egnede metoder for datainnsamling, gjennomføre kvalitetskontrolltiltak og etablere klare mål før analyse og tolkning starter.
Forskningsfasens informasjonsinnhentingsstadium er en systematisk og organisert prosess for å samle inn, arrangere og evaluere data, fakta og kunnskap fra ulike kilder for å besvare spesifikke forskningsspørsmål eller oppnå definerte mål. Dette kritiske stadiet fungerer som fundamentet for alle påfølgende forskningsaktiviteter, inkludert analyse, tolkning og utvikling av konklusjoner. Informasjonsinnhenting går langt utover enkel datainnsamling; det omfatter grundig planlegging, identifisering av kilder, gjennomføring av kvalitetskontroll og involvering av interessenter for å sikre at innhentet informasjon er nøyaktig, relevant og direkte anvendelig for forskningsspørsmålet. Stadiet kjennetegnes av metodiske prosedyrer som forvandler rå observasjoner og målinger til organiserte datasett klare for analyse. Å forstå dette stadiet er essensielt for forskere, akademikere, forretningsanalytikere og fagfolk som tar beslutninger basert på evidens innen alle fagområder.
Formaliserte informasjonsinnhentingsstadier oppsto gjennom utviklingen av den vitenskapelige metode på 1600- og 1700-tallet, da systematisk observasjon og datainnsamling ble anerkjent som sentrale komponenter i grundig forskning. Moderne metoder for informasjonsinnhenting har imidlertid blitt betydelig raffinert gjennom bidrag fra eksperter innen forskningsmetodikk, statistikere og organisasjonsforskere det siste århundret. Stadiet fikk særlig betydning på midten av 1900-tallet, da forskere begynte å vektlegge forskjellen mellom datainnsamling og dataanalyse, og anerkjente at kvaliteten på innhentet informasjon avgjør gyldigheten av forskningskonklusjonene. I dag regnes informasjonsinnhentingsstadiet som en hjørnestein i kunnskapsbasert praksis innen akademia, næringsliv, helsevesen og teknologisektorer. Ifølge rammeverk for forskningsmetodikk kan omtrent 78 % av forskningsfeil spores tilbake til utilstrekkelige informasjonsinnhentingspraksiser, noe som understreker viktigheten av dette stadiet. Utviklingen av digitale verktøy, databaser og automatiserte innhentingssystemer har forandret hvordan forskere nærmer seg informasjonsinnhenting, muliggjør innsamling i større skala, men introduserer også nye utfordringer knyttet til datakvalitet, håndtering av bias og etiske hensyn.
| Metodekategori | Hovedtilnærming | Datatype | Utvalgsstørrelse | Tidsbruk | Kostnad | Best egnet for |
|---|---|---|---|---|---|---|
| Strukturerte intervjuer | Forhåndsbestemte spørsmål | Kvalitativ | Liten til middels | Høy | Middels–høy | Konsistens og sammenlignbarhet |
| Undersøkelser & spørreskjemaer | Lukkede svaralternativer | Kvantitativ | Stor | Lav–middels | Lav | Bredde, mønstre og trender |
| Fokusgrupper | Gruppemøte | Kvalitativ | Liten (6–10) | Middels | Middels | Utforske holdninger og meninger |
| Observasjoner | Direkte observasjon | Kvalitativ | Variabel | Høy | Lav–middels | Analyse av atferd i virkeligheten |
| Dokumentanalyse | Eksisterende registre | Kvalitativ/kvantitativ | Variabel | Middels | Lav | Historisk kontekst og trender |
| Eksperimenter | Kontrollerte forhold | Kvantitativ | Middels | Høy | Høy | Årsakssammenhenger |
| Nettdata/Webdata | Digitale plattformer | Kvantitativ | Meget stor | Lav | Lav | Skalerbar datainnsamling |
| Biometriske målinger | Fysiologiske data | Kvantitativ | Middels | Middels | Høy | Objektive fysiske responser |
Informasjonsinnhentingsstadiet fungerer gjennom en strukturert, flerstegsprosess som starter med å etablere klare mål og definere omfanget for datainnsamlingen. Forskere må først identifisere hvilken informasjon som trengs, hvorfor den trengs, og hvordan den skal brukes til å besvare forskningsspørsmål. Dette grunnlaget innebærer å dokumentere spesifikke mål, leveranser og oppgaver, samt sette rammer som identifiserer nødvendige ressurser og legger til rette for prosjektplanlegging. Når målene er etablert, velger forskerne egnede metoder for datainnsamling basert på forskningsdesign, tilgjengelige ressurser og forskningens art. Valgprosessen krever nøye vurdering av om kvalitative metoder (intervjuer, observasjoner, fokusgrupper), kvantitative metoder (undersøkelser, eksperimenter, biometriske målinger) eller en kombinasjon gir best innsikt. Gjennomføringen av valgte metoder krever opplæring av datainnsamlere, etablering av standardiserte rutiner og innføring av kvalitetskontroll for å minimere bias og feil. Gjennom hele innsamlingen må forskere føre detaljerte oversikter over datakilder, innsamlingsdatoer, brukte metoder og eventuelle avvik fra planen. Den siste delen omfatter organisering og klargjøring av innsamlede data for analyse gjennom koding, kategorisering og valideringsprosedyrer som sikrer dataintegritet og analysereadskap.
I dagens forretningsmiljø påvirker informasjoninnhentingsstadiet direkte organisasjoners beslutningsprosesser, strategisk planlegging og konkurranseposisjonering. Selskaper som gjennomfører grundig informasjonsinnhenting rapporterer betydelig bedre resultater innen markedsundersøkelser, kundetilfredshetsanalyser og produktutvikling. Ifølge bransjerapporter når organisasjoner med strukturerte informasjonsinnhentingsprosesser 40 % raskere til innsikt sammenlignet med dem som bruker ad hoc-metoder. Stadiet er særlig kritisk i markedsundersøkelser, hvor virksomheter må forstå forbrukerpreferanser, konkurranselandskap og fremvoksende trender for å ta informerte beslutninger. I helse- og legemiddelforskning avgjør informasjonsinnhenting sikkerheten og effekten av behandlinger, noe som gjør kvalitetskontroll og systematisk innsamling livreddende. Finansinstitusjoner er avhengige av grundig informasjonsinnhenting for risikovurdering, svindeldeteksjon og etterlevelse av regelverk. Den praktiske betydningen omfatter også ressursbruk, da dårlig informasjonsinnhenting kan føre til bortkastede investeringer, tapte muligheter og strategiske feil. Organisasjoner som investerer i infrastruktur, opplæring og verktøy for informasjonsinnhenting presterer konsekvent bedre enn konkurrentene på beslutningshastighet og nøyaktighet. Stadiet påvirker også organisasjonskulturen, ettersom transparente og datadrevne prosesser skaper tillit blant interessenter og støtter faktabaserte beslutninger på alle nivåer.
I sammenheng med AI-overvåkingsplattformer som AmICited får informasjonsinnhentingsstadiet spesiell betydning når organisasjoner sporer hvordan merkevarer, domener og URL-er vises i AI-genererte svar på ulike plattformer. ChatGPT, Perplexity, Google AI Overviews og Claude genererer alle svar på forskjellige måter, noe som krever systematiske informasjonsinnhentingstilnærminger tilpasset den enkelte plattforms egenskaper. Informasjonsinnhentingsstadiet i AI-overvåking innebærer å etablere klare sporingsmål, som overvåking av merkevareomtaler, konkurranseposisjonering eller faktakorrekthet i AI-responsene. Forskere må velge egnede overvåkingsmetoder, som kan inkludere automatiserte sporingssystemer, periodiske manuelle revisjoner eller hybridløsninger. Kvalitetskontroll er spesielt viktig i AI-overvåking, da AI-systemer kan generere inkonsekvent eller feilinformasjon, og det kreves valideringsprosedyrer for å skille mellom reelle omtaler og falske positive. Stadiet omfatter også organisering av data fra flere AI-kilder til sammenhengende datasett som avslører mønstre i hvordan ulike plattformer fremstiller merkevarer eller informasjon. Denne spesialiserte anvendelsen av informasjonsinnhenting viser hvordan tradisjonelle forskningsmetoder tilpasses ny teknologi og informasjonsøkosystemer.
Vellykket gjennomføring av informasjoninnhentingsstadiet krever etterlevelse av etablerte beste praksiser validert på tvers av forskningsdisipliner og organisatoriske sammenhenger. For det første bør forskere etablere klare, målbare mål som er direkte knyttet til forskningsspørsmål, slik at hver innsamling tjener et definert formål. For det andre, velg metoder som passer til forskningskonteksten, med hensyn til studiens omfang, tilgjengelige ressurser, nødvendige validitetsnivåer og ønsket innsikt. For det tredje, gjennomfør streng kvalitetskontroll inkludert datavalidering, standardiserte innsamlingprotokoller og regelmessige revisjoner for å minimere bias og feil. For det fjerde, før detaljert dokumentasjon av alle innsamlinger, inkludert datoer, metoder, kilder og eventuelle avvik fra plan, og skap et revisjonsspor som støtter forskningens troverdighet. For det femte, involver relevante interessenter i planlegging og gjennomføring, slik at informasjonsinnhentingen møter reelle informasjonsbehov og sikrer forankring. For det sjette, bruk riktige verktøy og teknologier som matcher forskningsomfang og kompleksitet, fra enkle regneark for små studier til avanserte databehandlingsplattformer for større prosjekter. For det sjuende, gi grundig opplæring til datainnsamlere for å sikre konsistens, redusere bias og opprettholde kvalitetsstandarder gjennom hele prosessen. For det åttende, etabler datasikkerhet og personvernprotokoller som beskytter sensitiv informasjon og overholder relevante regelverk som GDPR, CCPA og krav fra etiske komiteer. Disse beste praksisene sikrer at innhentet informasjon er nøyaktig, pålitelig, relevant og klar for meningsfull analyse.
Informasjonsinnhentingsstadiet gjennomgår betydelig transformasjon drevet av teknologisk utvikling, kunstig intelligens og organisasjoners endrede behov. Kunstig intelligens og maskinlæring automatiserer i økende grad innsamling og organisering av data, slik at forskere kan hente inn og behandle større datasett mer effektivt enn tidligere. Automatiserte innsamlingssystemer, språkteknologiske verktøy og intelligente valideringsalgoritmer reduserer manuelt arbeid og forbedrer konsistens og reduserer menneskelig bias. Integrering av sanntidsovervåking gir organisasjoner mulighet til å samle informasjon kontinuerlig i stedet for i avgrensede perioder, og gir mer dynamisk og responsiv innsikt i endrede forhold. Blokkjede- og desentraliserte teknologier kommer frem som verktøy for å sikre dataintegritet og transparens, særlig der datakilde og autentisitet er avgjørende. Fremveksten av personvernbevarende metoder, som differensiell personvern og føderert læring, møter økende bekymringer rundt datasikkerhet og regelverk, samtidig som analytisk nytte opprettholdes. I sammenheng med AI-overvåking og merkevareovervåking utvikles informasjonsinnhentingsstadiet videre for å møte utfordringer som generativ AI reiser, inkludert hallucinasjoner, inkonsekvente utdata og raskt skiftende modellatferd. Organisasjoner utvikler spesialiserte rammeverk for innhenting av informasjon på tvers av AI-plattformer, noe som krever nye metoder tilpasset AI-spesifikke forhold. Fremtiden vil trolig by på økt fokus på etisk informasjonsinnhenting, der organisasjoner innfører mer avanserte prosedyrer for bias-deteksjon og -reduksjon. I tillegg vil integrering av flere datakilder gjennom avansert datafusjon muliggjøre mer helhetlige og flerdimensjonale datasett som gir større innsikt enn enkelkilde-tilnærminger. Sammensmeltingen av disse trendene tilsier at informasjonsinnhentingsstadiet vil bli stadig mer sofistikert, automatisert og integrert med avanserte analyser, og fundamentalt endre hvordan organisasjoner tilegner seg og utnytter informasjon i beslutningsprosesser.
Hovedformålet med informasjonsinnhentingsstadiet er systematisk å samle inn pålitelige, relevante data fra ulike kilder som direkte svarer på forskningsspørsmålet. Dette stadiet legger grunnlaget for all videre analyse og sikrer at forskere har nøyaktig, høykvalitetsinformasjon til å støtte sine funn og konklusjoner. Ifølge rammeverk for forskningsmetodikk avgjør effektiv informasjonsinnhenting troverdigheten og gyldigheten til hele forskningsprosjektet.
Informasjonsinnhenting fokuserer på innsamling og organisering av rådata fra ulike kilder, mens dataanalyse innebærer å tolke og forstå de innsamlede dataene for å trekke konklusjoner. Informasjonsinnhenting er input-fasen hvor forskere tilegner seg fakta og observasjoner, mens analyse er behandlingsfasen hvor mønstre, trender og sammenhenger identifiseres. Begge stadier er essensielle, men har ulike formål i forskningsprosessen.
De viktigste metodene for datainnsamling inkluderer kvalitative teknikker (intervjuer, fokusgrupper, observasjoner, dokumentanalyse) og kvantitative metoder (undersøkelser, spørreskjemaer, eksperimenter, biometriske målinger). Forskere benytter også kombinerte metoder som integrerer både kvalitative og kvantitative teknikker. Valg av metode avhenger av forskningsmål, tilgjengelige ressurser, studiens omfang og hvilken type innsikt som kreves for det aktuelle forskningsspørsmålet.
Kvalitetskontroll under informasjonsinnhenting sikrer at innsamlede data er nøyaktige, pålitelige og fri for skjevheter eller feil. Dårlig datakvalitet kan føre til ugyldige konklusjoner og feilinformerte beslutninger. Ifølge Forrester Research taper over 25 % av organisasjoner mer enn 5 millioner dollar årlig på grunn av dårlig datakvalitet. Innføring av strenge kvalitetskontrolltiltak, inkludert valideringssjekker og standardiserte innsamlingprosesser, beskytter integriteten til hele forskningsprosjektet.
I AI-overvåkingsplattformer som AmICited innebærer informasjonsinnhentingsstadiet systematisk innsamling av data om hvordan merkevarer og domener fremkommer i AI-genererte svar på tvers av plattformer som ChatGPT, Perplexity, Google AI Overviews og Claude. Dette stadiet krever etablering av klare overvåkingsmål, valg av egnede sporingsmetoder og organisering av data fra flere AI-kilder for å gi helhetlig innsikt i merkevarens synlighet.
Primære datakilder innebærer førstegangsinnsamling direkte fra kilden gjennom undersøkelser, intervjuer eller eksperimenter, og gir data spesifikt til forskningsmålene. Sekundære datakilder er eksisterende informasjon fra publiserte rapporter, akademiske studier, offentlige statistikker eller historiske registre. Primærdata er vanligvis mer relevante og oppdaterte, men krever mer ressurser, mens sekundærdata er kostnadseffektive, men kanskje ikke like spesifikke for forskningsbehovene.
Varigheten av informasjonsinnhentingsstadiet varierer betydelig basert på forskningsomfang, tilgjengelige ressurser og metoder for datainnsamling. Småskala kvalitative studier kan ta uker, mens storskala kvantitativ forskning kan strekke seg over måneder eller år. Ifølge retningslinjer for forskningsmetodikk kan god planlegging og klare mål redusere innsamlingstiden med 20–30 %, samtidig som kvalitet og gyldighet opprettholdes.
Vanlige utfordringer inkluderer utvalgsbias, svarskjevhet i undersøkelser, vansker med tilgang til enkelte datakilder, ressursbegrensninger og opprettholdelse av datakvalitet på tvers av flere innsamlingsmetoder. Forskere møter også utfordringer med dataorganisering, sikring av deltakernes konfidensialitet og håndtering av store informasjonsmengder. Å møte disse utfordringene krever nøye planlegging, valg av riktige verktøy og innføring av robuste kvalitetskontrollprosedyrer gjennom hele innsamlingen.
Begynn å spore hvordan AI-chatbots nevner merkevaren din på tvers av ChatGPT, Perplexity og andre plattformer. Få handlingsrettede innsikter for å forbedre din AI-tilstedeværelse.
Forskningsinnhold er evidensbasert materiale laget gjennom dataanalyse og ekspertinnsikt. Lær hvordan datadrevet analytisk innhold bygger autoritet, påvirker AI...
Informasjonell intensjon er når brukere søker etter kunnskap eller svar. Lær hvordan du optimaliserer innhold for informasjonelle søk og forstår rollen i AI-syn...

Lær effektive metoder for sitering av forskningsartikler i APA, MLA og Chicago-stil. Oppdag verktøy for referansehåndtering og strategier for å forhindre plagia...