Forskningsfase – Informasjonsinnhentingsstadiet
Lær hva forskningsfasens informasjonsinnhentingsstadium er, dets betydning i forskningsmetodikk, teknikker for datainnsamling og hvordan det påvirker AI-overvåk...
8 min lesing

Sekundærforskning er analysen og tolkningen av eksisterende data som tidligere er samlet inn av andre forskere eller organisasjoner for ulike formål. Det innebærer å syntetisere publiserte datasett, rapporter, akademiske tidsskrifter og andre kilder for å besvare nye forskningsspørsmål eller validere hypoteser uten å gjennomføre egen datainnsamling.
Sekundærforskning er analysen og tolkningen av eksisterende data som tidligere er samlet inn av andre forskere eller organisasjoner for ulike formål. Det innebærer å syntetisere publiserte datasett, rapporter, akademiske tidsskrifter og andre kilder for å besvare nye forskningsspørsmål eller validere hypoteser uten å gjennomføre egen datainnsamling.
Sekundærforskning, også kjent som skrivebordsforskning, er en systematisk forskningsmetode som innebærer å analysere, syntetisere og tolke eksisterende data som tidligere er samlet inn av andre forskere, organisasjoner eller institusjoner for ulike formål. I stedet for å samle inn originale data gjennom undersøkelser, intervjuer eller eksperimenter, utnytter sekundærforskning publiserte datasett, rapporter, akademiske tidsskrifter, offentlig statistikk og annen sammenstilt informasjon for å besvare nye forskningsspørsmål eller validere hypoteser. Denne tilnærmingen representerer et grunnleggende skifte fra datainnsamling til dataanalyse og tolkning, slik at organisasjoner kan hente ut handlingsrettet innsikt fra informasjon som allerede finnes i det offentlige rom eller i organisasjonens arkiver. Begrepet “sekundær” viser til at forskere arbeider med data som er sekundære i forhold til det opprinnelige innsamlingsformålet—data som opprinnelig ble samlet inn for ett formål, analyseres på nytt for å besvare andre forskningsspørsmål eller forretningsutfordringer.
Praksisen med sekundærforskning har utviklet seg betydelig gjennom det siste århundret, fra bibliotekbaserte litteraturstudier til sofistikert digital dataanalyse. Historisk var forskere avhengige av fysiske biblioteker, arkiver og publisert materiale for å utføre sekundæranalyser, en tidkrevende prosess som begrenset omfanget og tilgjengeligheten av forskning. Den digitale revolusjonen endret fundamentalt sekundærforskningen ved å gjøre store datasett umiddelbart tilgjengelig gjennom nettbaserte databaser, offentlige portaler og akademiske arkiver. I dag genererer den globale markedsforskningsbransjen 140 milliarder dollar i årlig omsetning per 2024, der sekundærforskning utgjør en betydelig del av markedet. Veksten er bemerkelsesverdig—bransjen økte fra 102 milliarder dollar i 2021 til 140 milliarder i 2024, noe som utgjør en økning på 37,25 % på bare tre år. Denne ekspansjonen gjenspeiler økt organisatorisk avhengighet av datadrevne beslutninger og anerkjennelsen av at sekundærforskning gir kostnadseffektive veier til markedsinnsikt. Fremveksten av AI-drevne analyseverktøy har ytterligere revolusjonert sekundærforskningen, slik at forskere kan behandle massive datasett, identifisere mønstre og hente innsikt i et tempo vi aldri har sett før. Ifølge nyere undersøkelser har 69 % av markedsforskere tatt i bruk syntetiske data og AI-analyse i sin sekundærforskning, noe som viser feltets raske teknologiske utvikling.
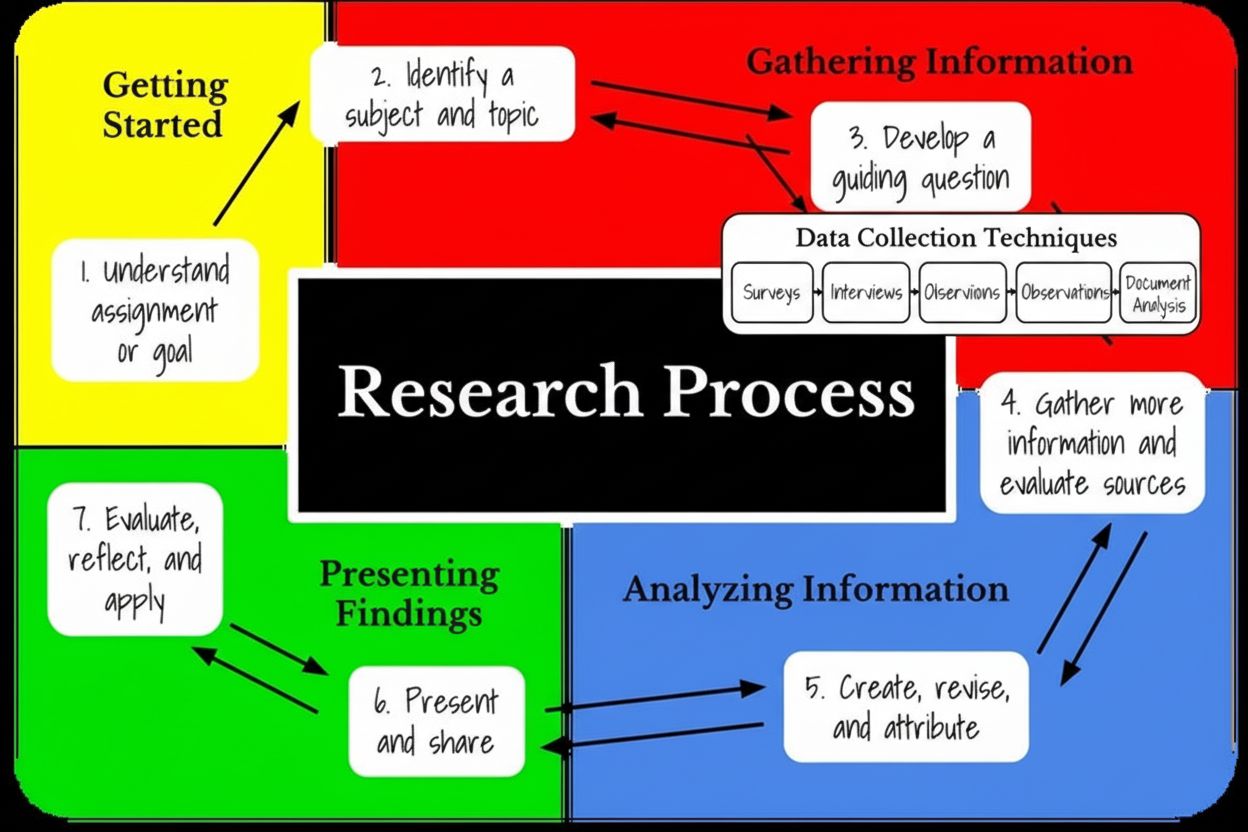
Sekundærforskningsdata stammer fra to hovedkategorier: interne kilder og eksterne kilder. Interne sekundærdata omfatter informasjon som allerede er samlet inn og lagret i en organisasjon, som salgsdatabaser, kundetransaksjonshistorikk, tidligere forskningsprosjekter, kampanjeytelsesdata og nettsideanalyse. Disse interne dataene gir konkurransefortrinn fordi de er eksklusive for organisasjonen og reflekterer faktisk forretningsytelse. Eksterne sekundærdata omfatter offentlig tilgjengelig eller kjøpbar informasjon fra offentlige etater, akademiske institusjoner, markedsanalysebyråer, bransjeorganisasjoner og medier. Offentlige kilder gir folketellingsdata, økonomisk statistikk og regelverksinformasjon; akademiske kilder tilbyr fagfellevurdert forskning og langtidsstudier; markedsanalysebyråer publiserer bransjerapporter og konkurranseanalyser; og bransjeorganisasjoner samler sektorspesifikke data og trender. Mangfoldet av sekundærkilder gjør det mulig for forskere å triangulere funn fra flere perspektiver og validere konklusjoner gjennom kryssjekk.
| Aspekt | Sekundærforskning | Primærforskning |
|---|---|---|
| Datainnsamling | Analyserer eksisterende data samlet inn av andre | Samler inn originale data direkte fra kilder |
| Tidsramme | Dager til uker | Uker til måneder |
| Kostnad | Lav til minimal (ofte gratis) | Høy (deltakerrekruttering, administrasjon) |
| Datakontroll | Ingen kontroll over metode eller kvalitet | Full kontroll over forskningsdesign og utførelse |
| Spesifisitet | Dekker kanskje ikke spesifikke forskningsspørsmål | Skreddersydd til eksakte forskningsmål |
| Forskerbias | Ukjent bias fra opprinnelige innsamler | Potensiell bias fra nåværende forskere |
| Dataeksklusivitet | Ikke-eksklusiv (konkurrenter har tilgang til samme data) | Eksklusivt eierskap til funn |
| Utvalgsstørrelse | Ofte store datasett | Varierer etter budsjett og omfang |
| Relevans | Kan måtte tilpasses nåværende behov | Direkte relevant for nåværende forskningsmål |
| Tid til innsikt | Umiddelbar tilgang til sammenstilt informasjon | Krever tid til datainnsamling og analyse |
Metodikk for sekundærforskning følger en strukturert femtrinnsprosess som sikrer grundig analyse og gyldige konklusjoner. Første steg er å tydelig definere forskningstemaet og identifisere spesifikke forskningsspørsmål som sekundærdata kan besvare. Forskerne må klargjøre hva de ønsker å oppnå—enten det er utforskende (forstå hvorfor noe har skjedd) eller bekreftende (validere hypoteser). Andre steg innebærer å identifisere og lokalisere relevante sekundærdatakilder, med hensyn til datarelevans, kildetroverdighet, publiseringsdato og geografisk omfang. Tredje steg er systematisk innsamling og organisering av data, ofte ved å få tilgang til flere databaser, verifisere kilders autentisitet og sammenstille informasjon i analyserbare formater. I denne fasen må forskere vurdere datakvalitet, metodisk åpenhet og hvorvidt datainnsamlingens tidsramme stemmer med forskningsbehovene. Fjerde steg fokuserer på å kombinere og sammenligne datasett, identifisere mønstre på tvers av kilder og gjenkjenne trender eller avvik som kommer frem i sammenlignende analyser. Forskerne kan måtte filtrere ut ubrukelige data, forene motstridende informasjon og organisere funn i sammenhengende fortellinger. Det siste steget innebærer omfattende analyse og tolkning, hvor forskere vurderer om sekundærdata tilstrekkelig besvarer de opprinnelige forskningsspørsmålene, identifiserer kunnskapshull og avgjør om supplerende primærforskning er nødvendig. Denne strukturerte tilnærmingen sikrer at sekundærforskning gir troverdige, handlingsrettede innsikter fremfor overfladiske konklusjoner.
En av de mest overbevisende fordelene med sekundærforskning er den markante kostnadseffektiviteten sammenlignet med primærforskning. Analyse av sekundærdata er nesten alltid billigere enn å gjennomføre primærforskning, og organisasjoner sparer vanligvis 50–70 % på forskningsbudsjetter ved å bruke eksisterende datasett. Siden datainnsamling utgjør den dyreste delen av primærforskning—inkludert rekruttering av deltakere, incentiver, spørreundersøkelser og feltarbeid—eliminerer sekundærforskning disse store kostnadene fullstendig. De fleste sekundærdatakilder er gratis tilgjengelig via offentlige etater, folkebiblioteker og akademiske arkiver, eller til en lav kostnad gjennom abonnementstjenester. Tidsbesparelsen er også betydelig: sekundærforskning kan gjennomføres på dager eller uker, mens primærforskning vanligvis krever uker til måneder. Forskere får umiddelbar tilgang til sammenstilte datasett via nettplattformer, noe som muliggjør raske beslutninger i tidssensitive forretningsutfordringer. I tillegg er sekundærdata ofte forhåndsrenset og organisert i elektroniske formater, og eliminerer det tidkrevende arbeidet med dataklargjøring som kreves i primærforskning. For organisasjoner med begrensede budsjetter eller stramme tidsrammer gir sekundærforskning en tilgjengelig vei til markedsinnsikt, konkurranseanalyse og trendvurdering. Den globale markedsforskningsbransjens vekst til 140 milliarder dollar gjenspeiler økt investering i forskning, med sekundærforskning som en kostnadseffektiv del av en helhetlig forskningsstrategi.
I sammenheng med AI-overvåking og optimalisering for generative søkemotorer spiller sekundærforskning en avgjørende rolle i å etablere referanser og forstå hvordan AI-systemer siterer kilder. Plattformer som AmICited bruker prinsipper fra sekundærforskning for å spore merkevareomtaler på tvers av AI-systemer som ChatGPT, Perplexity, Google AI Overviews og Claude. Ved å analysere eksisterende data om konkurrenters siteringer, bransjetrender og historisk merkevareytelse i AI-responser, kan organisasjoner identifisere mønstre i hvordan AI-systemer velger og siterer kilder. Sekundærforskning hjelper med å etablere referanser for AI-synlighet, slik at merkevarer kan forstå sin nåværende posisjon i forhold til konkurrenter og bransjestandarder. Organisasjoner kan analysere sekundærdata om innholdsytelse, siteringsmønstre og preferanser i AI-systemer for å optimalisere sin innholdsstrategi for bedre AI-siteringer. Denne integrasjonen av sekundærforskning og AI-overvåking gir en helhetlig forståelse av hvordan merkevarer fremstår i generative søkeresultater og AI-drevne svar. Analysen av eksisterende siteringsdata, konkurrentstrategier og bransjetrender gir kontekst for tolkning av sanntidsdata fra AI-overvåking, og muliggjør mer sofistikerte optimaliseringsstrategier. Siden 47 % av forskere globalt bruker AI regelmessig i markedsundersøkelser, er konvergensen av sekundærforskning og AI-drevne analyseverktøy i ferd med å endre hvordan organisasjoner forstår sin markedsposisjon og AI-synlighet.
Sikring av datakvalitet i sekundærforskning krever strenge valideringsprosesser og kritisk vurdering av kildens troverdighet. Forskere må undersøke den opprinnelige forskningsmetodikken, inkludert utvalgsstørrelse, populasjonsegenskaper, datainnsamlingsprosedyrer og mulige skjevheter som kan ha påvirket resultatene. Fagfellevurderte akademiske tidsskrifter opprettholder høyere troverdighetsstandarder enn blogger eller meningsinnlegg, da de gjennomgår ekspertvurdering før publisering. Offentlige etater og etablerte forskningsinstitusjoner har vanligvis strenge kvalitetskontroller, noe som gjør deres data mer pålitelige enn selvpubliserte kilder. Å kryssjekke funn fra flere uavhengige kilder hjelper med å validere konklusjoner og avdekke inkonsekvenser som kan indikere kvalitetsproblemer. Forskere bør vurdere om den opprinnelige studiens tidsramme stemmer med nåværende forskningsbehov, da data samlet inn for fem år siden kanskje ikke reflekterer dagens markedsforhold eller forbrukeratferd. Publiseringsdatoen er avgjørende—sekundærdata blir mindre relevante etter hvert som tiden går, spesielt i bransjer med raske endringer. Forskerne bør også vurdere om den opprinnelige datainnsamlingsmetoden samsvarer med deres krav, ettersom ulike metoder kan gi ikke-sammenlignbare resultater. Kontakt med opprinnelige forskere eller organisasjoner kan gi ytterligere kontekst om datainnsamling, svarprosenter og kjente begrensninger. Denne omfattende valideringstilnærmingen sikrer at konklusjoner fra sekundærforskning bygger på troverdige, høykvalitetsdata i stedet for potensielt feilaktig eller utdatert informasjon.
Sekundærforskning gir en rekke strategiske fordeler som gjør det til en essensiell del av et helhetlig forskningsprogram. Lett tilgjengelige data finnes i nettbaserte databaser, biblioteker og offentlige portaler, og krever minimal teknisk kompetanse for å finne og bruke. Raskere forskningstid gjør at organisasjoner kan besvare forskningsspørsmål på dager i stedet for måneder, noe som støtter raske beslutninger og økt konkurranseevne. Lave kostnader gjør sekundærforskning tilgjengelig for organisasjoner med begrensede forskningsbudsjetter, og demokratiserer tilgangen til markedsinnsikt. Sekundærforskning kan utløse ytterligere forskning ved å identifisere kunnskapshull som krever primærforskning, og fungerer som et fundament for mer målrettede studier. Muligheten til å skalere resultater raskt med store datasett som folketellinger gjør det mulig å trekke konklusjoner om brede populasjoner uten dyre undersøkelser. Sekundærforskning gir innsikt før hovedstudier som hjelper organisasjoner å avgjøre om videre forskning er nødvendig, og kan spare ressurser ved å vise at svarene allerede finnes i publisert litteratur. Bredde og dybde i tilgjengelige data gjør det mulig å undersøke trender over flere år, identifisere mønstre og forstå historisk kontekst som informerer dagens beslutninger. Organisasjoner kan utnytte konkurransefortrinn ved å bruke interne sekundærdata som konkurrentene ikke har tilgang til, og slik få unike innsikter om egen ytelse og posisjon i markedet.
Til tross for fordelene har sekundærforskning betydelige begrensninger som forskere må ta hensyn til. Utdaterte data er en hovedutfordring, ettersom sekundærkilder kanskje ikke reflekterer nåværende markedsforhold, forbrukerpreferanser eller teknologiske endringer. I bransjer med raske endringer kan sekundærdata bli irrelevante på få måneder, og forskere må derfor verifisere at informasjonen fortsatt er aktuell. Manglende kontroll over metodikk betyr at forskere ikke kan verifisere hvordan opprinnelige data ble samlet inn, om kvalitetsstandarder ble fulgt, eller om ukjente skjevheter har påvirket resultatene. Manglende mulighet til å skreddersy data til spesifikke forskningsspørsmål gjør at forskere ofte må tilpasse sine mål til tilgjengelig informasjon, fremfor å finne data som besvarer spørsmålene perfekt. Ikke-eksklusiv data innebærer at konkurrenter har tilgang til de samme sekundærkildene, og at man mister et mulig konkurransefortrinn som primærforskning kunne gitt. Ukjent forskerbias fra opprinnelige datainnsamlere kan ha påvirket resultatene på måter nåværende forskere ikke kan oppdage eller korrigere. Relevansgap i data kan tvinge forskere til å supplere sekundærfunn med primærforskning for å besvare spesifikke spørsmål. Kompleksitet ved dataintegrasjon ved sammenstilling av flere sekundærkilder med ulike metoder, tidsrammer og populasjoner gir analytiske utfordringer. Forskere må investere betydelig innsats i datavalidering og verifisering for å sikre at sekundærkilder holder kvalitetskrav og gir pålitelige innsikter.
Fremtiden for sekundærforskning formes i stor grad av kunstig intelligens, maskinlæring og avanserte analyseteknologier. AI-drevne verktøy gjør det nå mulig for forskere å behandle enorme datasett, identifisere komplekse mønstre og hente ut innsikt som ville vært umulig å oppdage manuelt. 83 % av markedsforskere planlegger å investere i AI for forskningsaktiviteter i 2025, noe som viser en bred anerkjennelse av AIs transformative potensial. Integrering av syntetiske data i sekundærforskning akselererer, med over 70 % av markedsforskere som forventer at syntetiske data vil utgjøre mer enn 50 % av datainnsamlingen innen tre år. Dette skiftet gjenspeiler økt betydning av AI-genererte innsikter og behovet for å supplere tradisjonelle sekundærkilder med algoritmisk genererte data. Automatisert innholdsanalyse med naturlig språkprosessering gjør det mulig å analysere kvalitative sekundærkilder i stor skala, identifisere temaer, sentiment og semantiske sammenhenger på tvers av tusenvis av dokumenter. Konvergensen mellom sekundærforskning og generative søkemotoroptimalisering (GEO) skaper nye muligheter for å forstå hvordan AI-systemer siterer og refererer til kilder. Etter hvert som AI-systemer som ChatGPT, Perplexity og Claude blir primære informasjonskilder for forbrukere, utvikles sekundærforskningsmetodene for å analysere hvordan disse systemene velger, siterer og presenterer informasjon. Organisasjoner bruker i økende grad sekundærforskning for å etablere referanser for AI-synlighet og forstå hvordan deres merkevarer fremstår i AI-genererte svar sammenlignet med konkurrenter. Fremtiden vil sannsynligvis innebære at sekundærforskning blir mer sofistikert, sanntidsbasert og integrert med AI-overvåkingsplattformer som sporer merkevareomtaler på tvers av flere AI-systemer samtidig. Denne utviklingen markerer et grunnleggende skifte fra historisk sekundærforskning til dynamisk, AI-forsterket analyse som gir kontinuerlig innsikt i markedsposisjon, konkurranselandskap og AI-synlighet.
Organisasjoner som ønsker å maksimere effekten av sekundærforskning bør innføre strukturerte beste praksiser som sikrer grundig analyse og handlingsrettede innsikter. Definer tydelige forskningsmål før du starter sekundærforskningen, med spesifikke spørsmål som sekundærdata kan besvare og suksesskriterier for prosjektet. Prioriter kildetroverdighet ved å velge fagfellevurderte akademiske kilder, offentlige etater og etablerte institusjoner fremfor selvpubliserte eller partiske kilder. Etabler verifiseringsprosedyrer som krever kryssjekking av funn på tvers av flere uavhengige kilder før du trekker konklusjoner. Dokumenter metodikk ved å notere hvilke kilder som er konsultert, hvordan data er analysert, og hvilke begrensninger eller skjevheter som kan ha påvirket resultatene. Vurder datainnsamlingens aktualitet og sørg for at sekundærdata reflekterer nåværende markedsforhold og ikke er blitt utdatert på grunn av raske endringer. Kombiner med primærforskning når sekundærdata ikke dekker spesifikke forskningsspørsmål eller når validering av sekundærfunn er nødvendig. Utnytt interne data ved å gjennomgå organisasjonens databaser og tidligere forskningsprosjekter før du søker eksterne sekundærkilder. Bruk AI-drevne analyseverktøy for å effektivt prosessere store sekundærdatasett og identifisere mønstre som manuell analyse kan overse. Overvåk AI-synlighet ved å integrere innsikt fra sekundærforskning med AI-overvåkingsplattformer som AmICited for å forstå hvordan merkevarer fremstår i AI-genererte svar. Etabler oppdateringsplaner for sekundærforskning, da markedsforhold endres og periodisk re-analyse kan være nødvendig for å opprettholde innsiktsnøyaktighet.
Sekundærforskning forblir en essensiell metode for organisasjoner som ønsker kostnadseffektiv og rask innsikt i markedsforhold, konkurranselandskap og forbrukertrender. Etter hvert som den globale markedsforskningsbransjen fortsetter å vokse—fra 102 milliarder dollar i 2021 til 140 milliarder i 2024—utgjør sekundærforskning en stadig viktigere del av helhetlige forskningsstrategier. Integrering av AI og maskinlæring omformer sekundærforskning fra en manuell, tidkrevende prosess til en automatisert, sofistikert analytisk disiplin som kan behandle store datasett og identifisere komplekse mønstre. Organisasjoner som mestrer metodikken for sekundærforskning oppnår betydelige konkurransefortrinn, med raskere beslutningstaking, kostnadseffektiv markedsanalyse og informert strategisk planlegging. Fremveksten av AI-overvåkingsplattformer som AmICited viser hvordan prinsippene for sekundærforskning utvikles for å møte nye utfordringer i den generative AI-æraen, der forståelse av hvordan AI-systemer siterer og refererer til kilder har blitt avgjørende for merkevaresynlighet og markedsposisjonering. Siden 47 % av forskere globalt nå bruker AI regelmessig i markedsundersøkelser, ligger fremtiden for sekundærforskning i sofistikert integrasjon av tradisjonell metodikk med banebrytende AI-funksjonalitet. Organisasjoner som kombinerer grundige sekundærforskningspraksiser med AI-drevne analyseverktøy, sanntids overvåkingsplattformer og strategiske valideringsprosedyrer vil være best posisjonert til å hente maksimal verdi fra eksisterende data, samtidig som de opprettholder troverdigheten og nøyaktigheten som kreves for trygge beslutninger i et stadig mer komplekst, AI-drevet forretningsmiljø.
Primærforskning innebærer å samle inn originale data direkte fra kilder gjennom undersøkelser, intervjuer eller observasjoner, mens sekundærforskning analyserer eksisterende data som tidligere er samlet inn av andre. Primærforskning er mer tidkrevende og kostbar, men gir skreddersydde innsikter, mens sekundærforskning er raskere og mer kostnadseffektiv, men kanskje ikke adresserer spesifikke forskningsspørsmål nøyaktig. Begge metodene kombineres ofte for helhetlige forskningsstrategier.
Kilder til sekundærforskning inkluderer offentlig statistikk og folketellingsdata, akademiske tidsskrifter og fagfellevurderte publikasjoner, markedsundersøkelsesrapporter fra profesjonelle byråer, selskapsrapporter og hvitbøker, bransjeorganisasjonsdata, nyhetsarkiver og mediepublikasjoner, samt interne organisasjonsdatabaser. Disse kildene kan være interne (fra egen organisasjon) eller eksterne (offentlig tilgjengelig eller kjøpt fra tredjeparter). Valg av kilde avhenger av forskningsmål, datarelevans og krav til troverdighet.
Sekundærforskning eliminerer utgifter til datainnsamling siden informasjonen allerede er samlet inn og sammenstilt av andre. Forskere unngår kostnader knyttet til rekruttering av deltakere, gjennomføring av undersøkelser eller intervjuer, og styring av feltarbeid. I tillegg er sekundærdata ofte tilgjengelig gratis eller til minimal kostnad gjennom offentlige databaser, biblioteker og myndigheter. Organisasjoner kan spare 50–70 % på forskningsbudsjetter ved å utnytte eksisterende datasett, noe som gjør det ideelt for team med begrensede ressurser.
Sekundærforskningsdata kan være utdaterte og mangler dermed muligens nyeste markedsendringer eller trender. Den opprinnelige datainnsamlingsmetoden er ukjent, noe som reiser spørsmål om datakvalitet og gyldighet. Forskere har ingen kontroll over hvordan dataene ble samlet inn, noe som kan introdusere ukjente skjevheter. Sekundærdatasett adresserer kanskje ikke spesifikke forskningsspørsmål nøyaktig, og forskere må tilpasse målene sine. I tillegg mangler sekundærdata eksklusivitet, noe som betyr at konkurrenter har tilgang til samme informasjon.
Organisasjoner bør undersøke den opprinnelige forskningsmetodologien, publiseringsdatoen og kildens omdømme før de bruker sekundærdata. Fagfellevurderte akademiske tidsskrifter og offentlige institusjoner opprettholder vanligvis høyere troverdighetsstandarder enn blogger eller meningsinnlegg. Å kryssjekke data på tvers av flere uavhengige kilder bidrar til å validere funn og avdekke inkonsekvenser. Forskere bør vurdere om den opprinnelige studiens utvalgsstørrelse, populasjon og forskningsdesign samsvarer med deres behov. Kontakt med opprinnelige forskere eller organisasjoner kan gi ytterligere kontekst om datainnsamlingsprosessen.
Sekundærforskning gir historisk kontekst og grunnlagsdata for AI-overvåkingsplattformer som AmICited, som sporer merkevareomtaler på tvers av AI-systemer som ChatGPT, Perplexity og Claude. Ved å analysere eksisterende data om konkurrentomtaler, bransjetrender og historisk merkevareytelse kan organisasjoner etablere referanser for AI-synlighet. Sekundærforskning hjelper med å identifisere mønstre i hvordan AI-systemer siterer kilder, slik at merkevarer kan optimalisere innholdsstrategien sin for bedre AI-siteringer og synlighet i generative søkeresultater.
AI-verktøy automatiserer nå analyse av sekundærdata, slik at forskere kan behandle store datasett raskere og identifisere mønstre som det ville vært vanskelig å oppdage manuelt. Omtrent 47 % av forskere globalt bruker regelmessig AI i sine markedsundersøkelser, med adopsjonsrater på opptil 58 % i Asia-Stillehavsregionen. AI-drevne innholdsanalyseverktøy kan gjenkjenne temaer, semantiske forbindelser og relasjoner i sekundære kilder. Likevel uttrykker 73 % av forskere tillit til å bruke AI i sekundærforskning, selv om noen team fortsatt har bekymringer knyttet til kompetansegap.
Sekundærforskning kan gjennomføres på dager eller uker siden data allerede er innsamlet og organisert, mens primærforskning vanligvis krever uker til måneder for planlegging, datainnsamling og analyse. Organisasjoner kan få umiddelbar tilgang til sekundærdata via nettbaserte databaser og biblioteker, noe som muliggjør raske beslutninger. Tidsfordelen gjør sekundærforskning ideell for tidssensitive forretningsbeslutninger, konkurranseanalyse og innledende forskningsfaser. Ulempen er imidlertid at sekundærdata kanskje ikke gir de spesifikke, oppdaterte innsiktene som primærforskning leverer.
Begynn å spore hvordan AI-chatbots nevner merkevaren din på tvers av ChatGPT, Perplexity og andre plattformer. Få handlingsrettede innsikter for å forbedre din AI-tilstedeværelse.
Lær hva forskningsfasens informasjonsinnhentingsstadium er, dets betydning i forskningsmetodikk, teknikker for datainnsamling og hvordan det påvirker AI-overvåk...

Lær effektive metoder for sitering av forskningsartikler i APA, MLA og Chicago-stil. Oppdag verktøy for referansehåndtering og strategier for å forhindre plagia...

Originalt forskning og førstepartsdata er proprietære studier og kundeinformasjon samlet direkte inn av merkevarer. Lær hvordan de bygger autoritet, driver AI-s...