Anatomia odpowiedzi generowanej przez AI: gdzie pojawiają się cytowania
Dowiedz się, jak modele AI generują odpowiedzi i umieszczają cytowania. Odkryj, gdzie Twoje treści pojawiają się w odpowiedziach ChatGPT, Perplexity i Google AI oraz jak zoptymalizować widoczność w AI.
Opublikowano Jan 3, 2026.Ostatnia modyfikacja Jan 3, 2026 o 3:24 am
Anatomia odpowiedzi generowanej przez AI: gdzie pojawiają się cytowania
Odpowiedzi generowane przez AI stały się główną metodą pozyskiwania informacji dla milionów użytkowników, fundamentalnie zmieniając przepływ informacji w internecie. Według najnowszych badań, adopcja AI wśród naukowców wzrosła do 84% w 2025 roku, z czego 62% wykorzystuje narzędzia AI do badań i publikacji — to gwałtowny wzrost w porównaniu do 57% ogólnego użycia AI w 2024 roku. Większość twórców treści nadal nie zdaje sobie sprawy, że umiejscowienie cytatów w tych odpowiedziach nie jest przypadkowe; podlega ono zaawansowanej architekturze technicznej, która decyduje, które źródła zyskują widoczność, a które pozostają niewidoczne. Zrozumienie, gdzie i dlaczego pojawiają się cytowania, jest dziś kluczowe dla każdego, kto chce utrzymać widoczność w świecie odkrywania treści zdominowanym przez AI.
Synteza model-native a Retrieval-Augmented Generation
Różnica między syntezą model-native a Retrieval-Augmented Generation (RAG) fundamentalnie wpływa na to, jak cytowania pojawiają się w odpowiedziach AI. Synteza model-native opiera się wyłącznie na wiedzy zakodowanej podczas treningu, natomiast RAG dynamicznie pobiera zewnętrzne źródła, by osadzić odpowiedź w aktualnych informacjach. Ta różnica ma ogromne znaczenie dla umiejscowienia i widoczności cytowań.
Charakterystyka
Synteza model-native
RAG
Definicja
Odpowiedzi generowane wyłącznie na podstawie danych treningowych
Odpowiedzi osadzone w źródłach pobieranych w czasie rzeczywistym
Szybkość
Szybsza (brak opóźnienia pobierania)
Wolniejsza (wymaga pobrania źródeł)
Dokładność
Podatna na halucynacje i przestarzałe informacje
Wyższa dokładność dzięki aktualnym źródłom
Możliwość cytowania
Ograniczone lub brak cytowań
Bogate, możliwe do prześledzenia cytowania
Zastosowania
Wiedza ogólna, kreatywne zadania
Aktualności, badania, weryfikacja faktów, dane firmowe
Systemy oparte na RAG, jak Perplexity i AI Overviews Google, generują więcej cytowań, bo muszą odwoływać się do pobranych źródeł, natomiast podejścia model-native, jak tradycyjne odpowiedzi ChatGPT, cytują rzadziej. Zrozumienie, które podejście stosuje dana platforma, pomaga twórcom treści przewidzieć prawdopodobieństwo cytowania i odpowiednio się przygotować.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
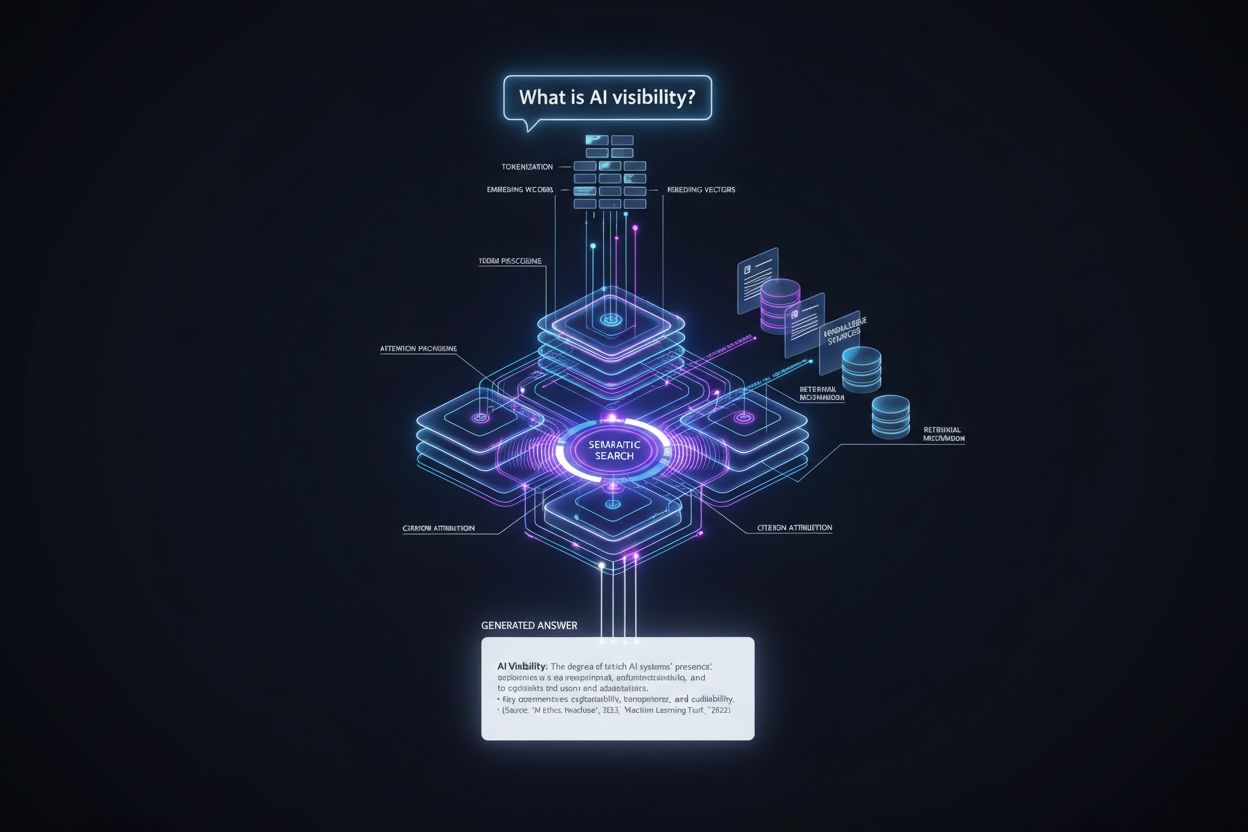
Droga od zapytania użytkownika do odpowiedzi z cytowaniem przebiega przez precyzyjny pipeline techniczny, w którym o umiejscowieniu cytatów decyduje się na kilku etapach. Oto jak wygląda ten proces:
Przetwarzanie zapytania: Pytanie użytkownika jest tokenizowane — rozbijane na jednostki zrozumiałe dla modelu — i analizowane pod kątem intencji, encji i znaczenia semantycznego poprzez wektory embeddingów.
Pobieranie informacji: System przeszukuje swoją bazę wiedzy (dane treningowe, zindeksowane dokumenty lub źródła w czasie rzeczywistym) używając wyszukiwania semantycznego, dopasowując znaczenie zapytania zamiast samych słów kluczowych, i zwraca kandydatów uporządkowanych według trafności.
Tworzenie kontekstu: Pobranie informacje są organizowane w oknie kontekstu — ilości tekstu, którą model może przetworzyć jednocześnie — z najistotniejszymi źródłami na czele, by wpłynąć na mechanizmy uwagi.
Generowanie tokenów: Model generuje odpowiedź token po tokenie, wykorzystując mechanizmy samo-uwagi, by zdecydować, które uprzednio wygenerowane tokeny i pobrane informacje mają wpływać na kolejne, tworząc spójne, osadzone w kontekście odpowiedzi.
Przypisanie cytowań: W trakcie generowania tokenów model śledzi, które dokumenty źródłowe wpłynęły na konkretne twierdzenia, przypisuje im oceny wiarygodności i decyduje, czy dołączyć jawne cytowanie na podstawie poziomu pewności i wymagań platformy.
Dostarczenie odpowiedzi: Ostateczna odpowiedź jest formatowana zgodnie ze specyfikacją platformy — cytowania inline, przypisy, panele źródeł lub linki po najechaniu kursorem — i dostarczana użytkownikowi wraz z metadanymi o autorytecie i trafności źródła.
Umiejscowienie cytowań na głównych platformach
Umiejscowienie cytowań różni się znacząco w zależności od platformy AI, tworząc różne szanse na widoczność dla twórców treści. Oto jak główne platformy prezentują cytowania:
ChatGPT: Cytowania pojawiają się w osobnym panelu „Źródła” poniżej odpowiedzi; użytkownik musi kliknąć, by je zobaczyć. Źródła ograniczone są zwykle do 3-5 linków, z priorytetem dla domen o wysokim autorytecie.
Perplexity: Cytowania są wstawiane inline w całej odpowiedzi jako liczby w indeksie górnym, a na dole znajduje się pełna lista źródeł. Każde twierdzenie można prześledzić, co czyni Perplexity najbardziej transparentną platformą pod względem cytowań.
Google Gemini: Cytowania pojawiają się jako linki wewnątrz tekstu odpowiedzi, a sekcja „Źródła” zawiera wszystkie wymienione materiały. Integracja z grafem wiedzy Google wpływa na wybór źródeł.
Claude: Cytowania prezentowane są jako przypisy w nawiasach, umożliwiając sprawdzenie źródła bez opuszczania odpowiedzi. Claude kładzie nacisk na różnorodność i wiarygodność źródeł.
DeepSeek: Cytowania pojawiają się jako linki w tekście, z minimalnym wyróżnieniem wizualnym, co odzwierciedla bardziej zintegrowane podejście, gdzie źródła są wplecione w narrację.
Te różnice oznaczają, że źródło cytowane przez Perplexity może otrzymać bezpośredni ruch, podczas gdy to samo źródło cytowane przez ChatGPT pozostanie niewidoczne, jeśli użytkownik nie kliknie panelu Źródła. Wzorce cytowania specyficzne dla platformy bezpośrednio wpływają na ruch i widoczność.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Systemy pobierania i umiejscowienie cytowań
To właśnie system pobierania informacji decyduje o umiejscowieniu cytowań, na długo przed wygenerowaniem odpowiedzi. Wyszukiwanie semantyczne przekształca zarówno zapytanie użytkownika, jak i zindeksowane dokumenty w embeddingi wektorowe — liczbowe reprezentacje znaczenia, nie samych słów. Następnie system oblicza wyniki podobieństwa między embeddingiem zapytania i embeddingami dokumentów, by wskazać, które źródła są semantycznie najbliższe intencji użytkownika.
Algorytmy rankingowe porządkują tych kandydatów na podstawie wielu sygnałów: wyników trafności, autorytetu domeny, aktualności treści, wskaźników zaangażowania użytkowników i jakości danych strukturalnych. Źródła z najwyższą pozycją w tej fazie są bardziej prawdopodobne do włączenia do okna kontekstu modelu generującego, co zwiększa szansę na cytowanie. Dlatego dobrze zoptymalizowany, semantycznie jasny artykuł z autorytatywnej domeny będzie pobierany i cytowany częściej niż słabo skonstruowany tekst z nowej domeny, nawet jeśli oba są poprawne merytorycznie. To właśnie faza pobierania de facto ustala pulę cytowań jeszcze przed generowaniem odpowiedzi.
Jak struktura treści wpływa na szanse cytowania
Struktura treści to nie tylko kwestia UX — bezpośrednio decyduje, czy systemy AI są w stanie wyodrębnić, zrozumieć i zacytować Twoje materiały. Modele AI polegają na sygnałach formatowania, by rozpoznawać granice informacji i zależności między nimi. Oto elementy strukturalne maksymalizujące szansę na cytowanie:
Struktura „odpowiedź najpierw”: Rozpoczynaj od bezpośredniej odpowiedzi na typowe pytania, by system AI szybko zidentyfikował i wyodrębnił najważniejsze informacje bez czytania wstępu.
Jasne nagłówki: Używaj opisowych nagłówków H2 i H3, które precyzyjnie określają temat sekcji, ułatwiając AI zrozumienie organizacji treści i wyodrębnienie odpowiednich fragmentów do konkretnych zapytań.
Optymalna długość akapitów: Zachowuj akapity na poziomie 3-5 zdań, by AI łatwiej wyodrębnił poszczególne twierdzenia i przypisał je do konkretnych źródeł bez niejasności.
Listy i tabele: Dane uporządkowane w punktach i tabelach są łatwiejsze do przeanalizowania i cytowania niż proza, ponieważ AI może jasno rozpoznać granice twierdzeń.
Jasność encji: Nazywaj wprost osoby, organizacje, produkty i pojęcia zamiast używać zaimków, by AI mogło precyzyjnie wskazać, do czego odnosi się dane twierdzenie i poprawnie je zacytować.
Schema markup: Wdrażaj dane strukturalne (Schema.org), by dostarczyć jawne metadane o typie treści, autorze, dacie publikacji i twierdzeniach — to dodatkowe sygnały ułatwiające ocenę i cytowanie przez AI.
Treści spełniające te zasady są cytowane 2-3 razy częściej niż słabo ustrukturyzowane materiały, niezależnie od jakości, bo AI łatwiej je wyodrębnia i przypisuje.
Proces przypisywania cytowań
Po pobraniu źródeł i umieszczeniu ich w oknie kontekstu, model ocenia każde źródło przez pryzmat różnych kryteriów wiarygodności, zanim zdecyduje o cytowaniu. Ocena wiarygodności źródła obejmuje autorytet domeny (na podstawie profilu linków, wieku domeny i rozpoznawalności marki), kompetencje autora (wykrywane przez podpisy, biogramy i sygnały kwalifikacji) oraz trafność tematyczną (czy główny temat źródła odpowiada zapytaniu).
Ocena trafności mierzy, jak bezpośrednio źródło odnosi się do zapytania — odpowiedzi idealnie wpisujące się w pytanie punktują wyżej niż informacje poboczne. Aktualność decyduje, czy preferowane są najnowsze źródła — kluczowe dla wiadomości, badań i tematów szybko ewoluujących. Sygnały autorytetu to cytowania od innych wiarygodnych źródeł, obecność w bazach naukowych i grafach wiedzy. Wpływ metadanych pochodzi z tagów tytułu, opisów meta i danych strukturalnych, które jasno komunikują cel i wiarygodność treści. Wreszcie dane strukturalne (Schema.org) dostarczają jawnych sygnałów wiarygodności, które model może bezpośrednio przetwarzać, np. kwalifikacje autora, datę publikacji, oceny i status fact-check. Źródła z kompletnym schema markup są cytowane bardziej niezawodnie, bo model ma maszynowo czytelne potwierdzenie twierdzeń.
Najczęstsze wzorce umiejscowienia cytowań
Platformy AI stosują różne style cytowania, które wpływają na widoczność cytowań dla użytkownika. Oto najczęstsze wzorce:
Cytowania inline (styl Perplexity):
„Według najnowszych badań, adopcja AI wśród naukowców wzrosła do 84% w 2025 roku[1], z czego 62% wykorzystuje narzędzia AI do badań[2].”
Cytowania na końcu akapitu (styl Claude):
„Adopcja AI wśród naukowców wzrosła do 84% w 2025 roku, z czego 62% wykorzystuje narzędzia AI. [Źródło: Wiley Research Report, 2025]”
Cytowania przypisowe (styl akademicki):
„Adopcja AI wśród naukowców wzrosła do 84% w 2025¹, z czego 62% wykorzystuje narzędzia AI².”
Listy źródeł (styl ChatGPT):
Tekst odpowiedzi bez cytowań inline, po którym następuje osobna sekcja „Źródła” z 3-5 linkami.
Cytowania po najechaniu (nowy trend):
Podkreślony tekst, po najechaniu na który pojawia się informacja o źródle, co minimalizuje bałagan wizualny przy zachowaniu możliwości śledzenia.
Każdy styl generuje inne zachowania użytkowników: cytowania inline zwiększają natychmiastowe kliknięcia, listy źródeł wymagają świadomego działania, a cytowania po najechaniu godzą widoczność z estetyką. Szansa na cytowanie Twojej treści zależy od platformy — dlatego monitoring na wielu platformach jest niezbędny.
Wpływ umiejscowienia cytowań na biznes
Zrozumienie mechaniki umiejscowienia cytowań przekłada się bezpośrednio na wymierne efekty biznesowe. Ruch pojawia się natychmiast: źródła cytowane inline przez Perplexity otrzymują 3-5 razy więcej ruchu polecającego niż te widoczne tylko w panelu źródeł ChatGPT, bo użytkownicy chętniej klikają cytowania napotkane podczas czytania. Relacja między widocznością a kliknięciami nie jest liniowa — cytowanie ma sens tylko wtedy, gdy użytkownik faktycznie kliknie, a to zależy od miejsca, platformy i kontekstu.
Autorytet marki rośnie z czasem: źródła regularnie cytowane przez wiele platform AI budują mocniejsze sygnały autorytetu, co poprawia pozycje w tradycyjnym wyszukiwaniu i zwiększa szansę na kolejne cytowania AI. Powstaje efekt kuli śnieżnej — treść cytowana staje się bardziej autorytatywna i przyciąga kolejne cytowania. Przewaga konkurencyjna pojawia się u marek, które optymalizują pod cytowania AI szybciej niż konkurencja — pionierzy wdrażający schema i optymalizację struktury otrzymują obecnie nieproporcjonalnie dużą część cytowań. SEO korzysta podwójnie: treść zoptymalizowana pod cytowania AI zwykle radzi sobie lepiej także w tradycyjnym wyszukiwaniu, bo te same sygnały struktury i autorytetu są korzystne w obu przypadkach. Wartość AmICited staje się oczywista: w świecie odkrywania treści przez AI brak wiedzy o cytowaniach to jak brak wiedzy o pozycjach w wyszukiwarkach — to istotna luka w strategii widoczności.
Praktyczne wskazówki dla twórców treści
Optymalizacja pod cytowania AI wymaga konkretnych, wdrażalnych zmian w sposobie tworzenia i strukturyzowania treści. Oto najskuteczniejsze taktyki:
Struktura pod wyodrębnianie: Używaj jasnych nagłówków, krótkich akapitów i list, by Twoja treść była łatwa do analizy i wyodrębnienia konkretnych twierdzeń przez AI.
Stosuj jasne, cytowalne fakty: Rozpoczynaj od konkretnych statystyk, dat i nazw zamiast ogólników. AI chętniej cytuje precyzyjne twierdzenia niż abstrakcyjne stwierdzenia.
Wdrażaj schema markup: Dodaj Schema.org dla typów Article, NewsArticle lub ScholarlyArticle, w tym autora, datę publikacji i metadane dotyczące twierdzeń, które AI może bezpośrednio odczytać.
Zachowuj spójność encji: Stosuj te same nazwy osób, firm i pojęć w całym tekście, unikaj zaimków i skrótów, które wprowadzają niejasność dla AI.
Cytuj źródła: Gdy cytujesz inne źródła w swoim tekście, sygnalizujesz AI, że Twoje treści są rzetelne, co zwiększa szansę na cytowanie.
Testuj w narzędziach AI: Regularnie sprawdzaj swoje tematy w ChatGPT, Perplexity, Gemini i Claude, by zobaczyć, czy i jak Twoja treść jest cytowana.
Monitoruj wyniki: Śledź, które treści są cytowane, przez jakie platformy i w jakim kontekście, wykorzystując te dane do dalszej optymalizacji.
Twórcy, którzy wdrażają te taktyki, obserwują wzrost cytowań o 40-60% w ciągu 3-6 miesięcy, wraz ze wzrostem ruchu polecającego i autorytetu marki.
Monitoring i pomiar cytowań
Monitoring cytowań nie jest już opcjonalny — to niezbędna infrastruktura do zrozumienia swojej widoczności w świecie odkrywania treści przez AI. Dlaczego monitoring jest ważny — to proste: nie można optymalizować tego, czego się nie mierzy, a wzorce cytowań zmieniają się wraz z rozwojem AI i pojawianiem się nowych platform. Jakie metryki śledzić: częstotliwość cytowań (jak często jesteś cytowany), miejsce cytowania (inline vs. lista źródeł), rozkład platform (gdzie jesteś najczęściej cytowany), kontekst zapytań (na jakie tematy pojawiają się cytowania) i przypisanie ruchu (ile ruchu pochodzi z cytowań AI).
Identyfikacja szans wymaga analizy luk w cytowaniach: tematów, gdzie cytowana jest konkurencja, a Ty nie; platform, na których jesteś niedoreprezentowany; typów treści, które wypadają gorzej. Analiza ta wskazuje konkretne cele optymalizacyjne — być może Twoje poradniki nie są cytowane, bo brakuje im schema, albo badania nie pojawiają się w Perplexity, bo nie są ustrukturyzowane pod cytowania inline.
AmICited rozwiązuje problem monitoringu, śledząc cytowania Twoich treści w ChatGPT, Perplexity, Gemini, Claude i innych kluczowych platformach AI w czasie rzeczywistym. Zamiast samodzielnie wielokrotnie sprawdzać swoje tematy, AmICited automatycznie monitoruje wzorce cytowań, powiadamia o nowych cytowaniach i dostarcza dane porównawcze z konkurencją. Dla twórców, marketerów i specjalistów SEO AmICited zamienia monitoring cytowań z ręcznego, czasochłonnego procesu w zautomatyzowany system z praktycznymi wskazówkami. W świecie odkrywania treści przez AI wiedza o cytowaniach Twoich treści jest tak samo ważna, jak znajomość pozycji w wyszukiwarce — AmICited sprawia, że ta widoczność jest możliwa na dużą skalę.
Najczęściej zadawane pytania
Jaka jest różnica między odpowiedziami model-native a opartymi na RAG?
Odpowiedzi model-native pochodzą z wzorców nauczonych podczas treningu, natomiast RAG pobiera aktualne dane przed generowaniem odpowiedzi. RAG zazwyczaj zapewnia lepsze cytowania, ponieważ opiera się na konkretnych źródłach, co zwiększa przejrzystość i możliwość śledzenia dla użytkowników i twórców treści.
Dlaczego niektóre platformy AI cytują źródła, a inne nie?
Różne platformy wykorzystują różne architektury. Perplexity i Gemini stawiają na RAG z cytowaniami, podczas gdy ChatGPT domyślnie opiera się na model-native, chyba że włączone jest przeglądanie. Wybór ten odzwierciedla filozofię projektowania i podejście do przejrzystości każdej platformy.
Jak struktura treści wpływa na to, czy AI cytuje Twoje treści?
Jasna, dobrze zorganizowana treść z bezpośrednimi odpowiedziami, odpowiednimi nagłówkami i znacznikami schematu jest łatwiejsza do wyodrębnienia przez systemy AI. Treści z odpowiedziami na początku, listami i tabelami są częściej cytowane, ponieważ AI łatwiej je analizuje i przypisuje źródła.
Jaką rolę odgrywa schema markup w umiejscowieniu cytowania?
Schema markup pomaga systemom AI zrozumieć strukturę treści i relacje między encjami, co ułatwia prawidłowe przypisanie i cytowanie Twojej treści. Właściwa implementacja schematu zwiększa prawdopodobieństwo cytowania i pomaga AI weryfikować wiarygodność Twoich treści.
Czy mogę zoptymalizować swoje treści, by pojawiały się w odpowiedziach generowanych przez AI?
Tak. Skup się na strukturze z odpowiedzią na początku, przejrzystym formatowaniu, rzetelności faktów, wiarygodnych źródłach i poprawnej implementacji schematu. Monitoruj swoje cytowania i wprowadzaj zmiany na podstawie danych, by stale poprawiać widoczność w AI.
Jak śledzić, gdzie moja marka pojawia się w odpowiedziach AI?
Narzędzia takie jak AmICited monitorują wzmianki o Twojej marce w ChatGPT, Perplexity, Google AI Overviews i innych platformach, pokazując dokładnie, gdzie i jak jesteś cytowany w odpowiedziach AI. To zapewnia praktyczne wskazówki do optymalizacji.
Czy bycie cytowanym przez AI wpływa na moje pozycje w wyszukiwarkach?
Cytowania AI nie wpływają bezpośrednio na pozycje w Google, ale zwiększają widoczność marki i sygnały autorytetu. Bycie cytowanym przez AI może przyciągać ruch i wzmacniać obecność online, co daje pośrednie korzyści SEO.
Jaki jest związek między tradycyjnym SEO a optymalizacją pod cytowania AI?
To działania komplementarne. Tradycyjne SEO skupia się na pozycjach w wyszukiwarkach, a optymalizacja pod cytowania AI — na obecności w odpowiedziach generowanych przez AI. Oba są ważne dla pełnej widoczności w nowoczesnym krajobrazie odkrywania treści.
Monitoruj swoją widoczność w AI na wszystkich platformach
Dowiedz się dokładnie, gdzie Twoja marka pojawia się w odpowiedziach generowanych przez AI. Śledź cytowania w ChatGPT, Perplexity, Google AI Overviews i wielu innych dzięki AmICited.
Które formaty treści otrzymują najwięcej cytowań przez AI? Analiza danych
Dowiedz się, które formaty treści są najczęściej cytowane przez modele AI. Analizuj dane z ponad 768 000 cytowań przez AI, aby zoptymalizować swoją strategię tr...
Jakie publikacje są najczęściej cytowane przez silniki AI? Kompleksowa analiza cytowań
Odkryj, które publikacje najczęściej cytują silniki AI, takie jak ChatGPT, Perplexity i Google AI. Poznaj wzorce cytowań, preferencje źródeł oraz dowiedz się, j...
Jakie typy treści są najczęściej cytowane przez AI? Przegląd branżowy
Dowiedz się, które typy treści są najczęściej cytowane przez systemy AI. Sprawdź, jak YouTube, Wikipedia, Reddit i inne źródła wypadają na tle ChatGPT, Perplexi...
9 min czytania
Zgoda na Pliki Cookie Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.