
Renderowanie po stronie serwera vs CSR: Wpływ na widoczność w AI
Dowiedz się, jak strategie renderowania SSR i CSR wpływają na widoczność dla AI crawlerów, cytowania marki w ChatGPT i Perplexity oraz ogólną obecność w wyszuki...
8 min czytania

Kompletny przewodnik po AI crawlerach i botach. Identyfikuj GPTBot, ClaudeBot, Google-Extended oraz 20+ innych AI crawlerów z agentami użytkownika, tempem indeksowania i strategiami blokowania.
AI crawlery zasadniczo różnią się od tradycyjnych crawlerów wyszukiwarek, które znasz od dekad. Podczas gdy Googlebot i Bingbot indeksują treści, by użytkownicy mogli je znaleźć w wynikach wyszukiwania, AI crawlery takie jak GPTBot i ClaudeBot zbierają dane specjalnie do trenowania dużych modeli językowych. Ta różnica jest kluczowa: tradycyjne crawlery tworzą ścieżki dla ludzkiego odkrywania, podczas gdy AI crawlery zasilają bazy wiedzy systemów sztucznej inteligencji. Według najnowszych danych, AI crawlery odpowiadają obecnie za niemal 80% całego ruchu botów na stronach internetowych; crawlery treningowe konsumują ogromne ilości treści, odsyłając jednocześnie minimalny ruch zwrotny do wydawców. W przeciwieństwie do tradycyjnych crawlerów, które mają problemy z dynamicznymi stronami opartymi na JavaScript, AI crawlery używają zaawansowanego uczenia maszynowego, by rozumieć treści kontekstowo, niemal jak ludzki czytelnik. Potrafią interpretować znaczenie, ton i cel bez ręcznych aktualizacji konfiguracji. To skok kwantowy w technologii indeksowania sieci, który wymusza całkowicie nowe podejście właścicieli stron do zarządzania crawlerami.
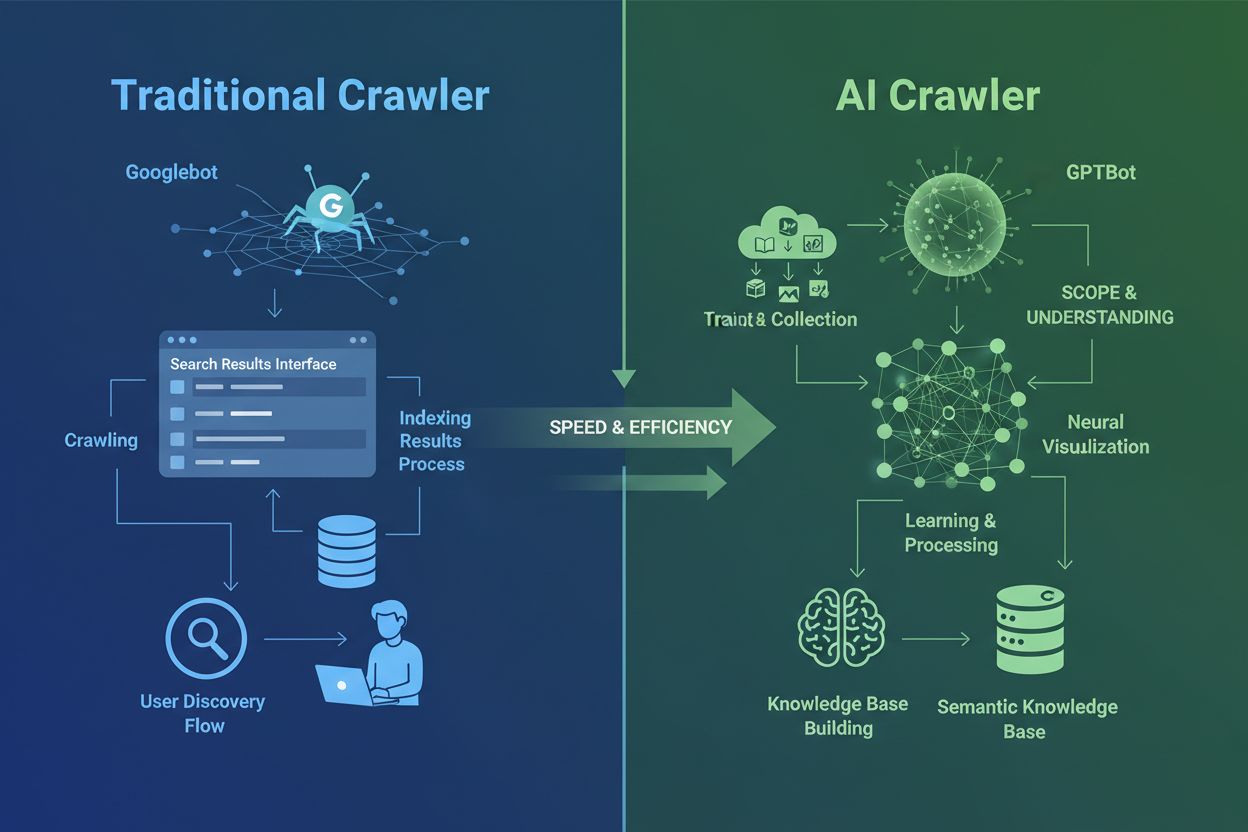
Krajobraz AI crawlerów staje się coraz bardziej zatłoczony, gdy największe firmy technologiczne ścigają się w budowie własnych dużych modeli językowych. OpenAI, Anthropic, Google, Meta, Amazon, Apple i Perplexity obsługują po kilka wyspecjalizowanych crawlerów, z których każdy pełni odmienną funkcję w ekosystemie AI. Firmy wdrażają wiele crawlerów, bo różne cele wymagają różnych zachowań: jedne crawlery zbierają masowe dane treningowe, inne odpowiadają za indeksowanie na potrzeby wyszukiwania w czasie rzeczywistym, a jeszcze inne pobierają treści na żądanie użytkownika. Zrozumienie tego ekosystemu wymaga rozpoznania trzech głównych kategorii crawlerów: crawlerów treningowych, które zbierają dane do ulepszania modeli, crawlerów wyszukiwania i cytowania, indeksujących treści dla AI-owych doświadczeń wyszukiwawczych, oraz pobieraczy uruchamianych na żądanie użytkownika. Poniższa tabela przedstawia szybki przegląd głównych graczy:
| Firma | Nazwa crawlera | Główny cel | Tempo indeksowania | Dane treningowe |
|---|---|---|---|---|
| OpenAI | GPTBot | Trening modeli | 100 stron/godz. | Tak |
| OpenAI | ChatGPT-User | Żądania użytkowników | 2400 stron/godz. | Nie |
| OpenAI | OAI-SearchBot | Indeksowanie wyszukiwania | 150 stron/godz. | Nie |
| Anthropic | ClaudeBot | Trening modeli | 500 stron/godz. | Tak |
| Anthropic | Claude-User | Dostęp do sieci w czasie rzeczywistym | <10 stron/godz. | Nie |
| Google-Extended | Trening Gemini AI | Zmienny | Tak | |
| Gemini-Deep-Research | Funkcja badawcza | <10 stron/godz. | Nie | |
| Meta | Meta-ExternalAgent | Trening modeli AI | 1100 stron/godz. | Tak |
| Amazon | Amazonbot | Ulepszanie usług | 1050 stron/godz. | Tak |
| Perplexity | PerplexityBot | Indeksowanie wyszukiwania | 150 stron/godz. | Nie |
| Apple | Applebot-Extended | Trening AI | <10 stron/godz. | Tak |
| Common Crawl | CCBot | Otwarty zbiór danych | <10 stron/godz. | Tak |
OpenAI obsługuje trzy odrębne crawlery, z których każdy ma konkretną rolę w ekosystemie ChatGPT. Zrozumienie tych crawlerów jest kluczowe, bo GPTBot OpenAI to jeden z najbardziej agresywnych i najczęściej wdrażanych AI crawlerów w internecie:
GPTBot – Główny crawler treningowy OpenAI, systematycznie zbierający publicznie dostępne dane do trenowania i ulepszania modeli GPT, w tym ChatGPT i GPT-4o. Działa z tempem ok. 100 stron na godzinę i respektuje dyrektywy robots.txt. OpenAI publikuje oficjalne adresy IP do weryfikacji na https://openai.com/gptbot.json.
ChatGPT-User – Pojawia się, gdy prawdziwy użytkownik wchodzi w interakcję z ChatGPT i prosi o przejrzenie konkretnej strony. Działa z dużo wyższym tempem (do 2400 stron/godz.), bo jest wywoływany przez działania użytkownika, a nie systematyczne crawlery. Treści pobrane przez ChatGPT-User nie są używane do treningu modeli – to cenne dla widoczności na żywo w wynikach wyszukiwania ChatGPT.
OAI-SearchBot – Zaprojektowany specjalnie dla funkcji wyszukiwania w ChatGPT, ten crawler indeksuje treści do wyników na żywo bez zbierania danych treningowych. Działa z tempem ok. 150 stron/godz. i pomaga Twoim treściom pojawiać się w wyszukiwaniu ChatGPT, gdy użytkownicy zadają pytania.
Crawlery OpenAI respektują dyrektywy robots.txt i działają z oficjalnych zakresów IP, co czyni je stosunkowo łatwymi w zarządzaniu w porównaniu do mniej przejrzystych konkurentów.
Anthropic, twórca Claude AI, obsługuje kilka crawlerów o różnych celach i poziomach jawności. Firma nie udostępniła tak szczegółowej dokumentacji jak OpenAI, ale zachowanie jej crawlerów jest dobrze udokumentowane w logach serwerowych:
ClaudeBot – Główny crawler treningowy Anthropic, zbierający treści z sieci do rozbudowy bazy wiedzy i możliwości Claude’a. Działa z tempem ok. 500 stron/godz. i jest głównym celem, jeśli chcesz zapobiec wykorzystaniu Twoich treści do trenowania modelu Claude. Pełny user agent: Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com).
Claude-User – Uruchamiany, gdy użytkownik Claude prosi o dostęp do sieci w czasie rzeczywistym, ten crawler pobiera treści na żądanie w minimalnej ilości. Respektuje uwierzytelnianie i nie próbuje omijać zabezpieczeń, więc jest stosunkowo niegroźny z punktu widzenia zasobów.
Claude-SearchBot – Wspiera wewnętrzne wyszukiwanie Claude’a, pomagając Twoim treściom pojawiać się w wynikach wyszukiwania Claude’a, gdy użytkownicy zadają pytania. Ten crawler działa w bardzo małych ilościach i służy głównie do indeksowania, nie treningu.
Ważnym problemem z crawlerami Anthropic jest stosunek crawl-to-refer: dane Cloudflare wskazują, że na każde odesłanie od Anthropic do strony, crawlery odwiedziły już ok. 38 000–70 000 stron. Ta ogromna dysproporcja oznacza, że Twoje treści są konsumowane znacznie bardziej agresywnie niż cytowane, co rodzi pytania o sprawiedliwe wynagradzanie za wykorzystanie treści.
Podejście Google do AI crawlerów znacznie różni się od konkurencji, ponieważ firma utrzymuje ścisły rozdział między indeksowaniem wyszukiwania a treningiem AI. Google-Extended to konkretny crawler odpowiedzialny za zbieranie danych do trenowania Gemini (dawniej Bard) i innych produktów AI Google – całkowicie oddzielny od tradycyjnego Googlebota:
User agent Google-Extended to: Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Google-Extended/1.0. Ten rozdział jest celowy i korzystny dla właścicieli stron, bo możesz zablokować Google-Extended przez robots.txt bez wpływu na widoczność w wyszukiwarce Google. Google oficjalnie deklaruje, że blokada Google-Extended nie ma wpływu na pozycje ani na obecność w AI Overviews, choć niektórzy webmasterzy zgłaszali obawy warte monitorowania. Gemini-Deep-Research to kolejny crawler Google wspierający funkcje badawcze Gemini, działający na bardzo niską skalę z minimalnym wpływem na zasoby serwera. Istotną przewagą technologiczną crawlerów Google jest ich umiejętność wykonywania JavaScriptu i renderowania dynamicznych treści – w przeciwieństwie do większości konkurencji. Oznacza to, że Google-Extended potrafi skutecznie indeksować aplikacje React, Vue i Angular, podczas gdy GPTBot OpenAI i ClaudeBot Anthropic nie mają tej możliwości. Dla właścicieli aplikacji opartych o JavaScript to ważna różnica pod kątem widoczności w AI.
Poza gigantami technologicznymi, wiele innych organizacji prowadzi crawlery AI, na które warto zwrócić uwagę. Meta-ExternalAgent, cicho uruchomiony w lipcu 2024, zbiera treści z sieci do trenowania modeli AI Meta oraz ulepszania produktów Facebooka, Instagrama i WhatsAppa. Crawler ten działa z tempem ok. 1100 stron/godz., a mimo agresywnego indeksowania nie wzbudził jeszcze szerokiego zainteresowania. Bytespider od ByteDance (właściciela TikToka) od kwietnia 2024 należy do najbardziej agresywnych crawlerów na świecie. Zewnętrzne pomiary wskazują, że Bytespider indeksuje znacznie szybciej niż GPTBot czy ClaudeBot, choć dokładne współczynniki się różnią. Są też doniesienia, że nie zawsze respektuje robots.txt, dlatego skuteczniejsze jest blokowanie po IP.
Crawlery Perplexity to m.in. PerplexityBot do indeksowania wyszukiwania i Perplexity-User do pobierania treści na żądanie. Perplexity spotkało się z doniesieniami o ignorowaniu robots.txt, choć firma deklaruje stosowanie się do niego. Amazonbot napędza funkcje odpowiadania na pytania w Alexa, respektuje robots.txt i działa z tempem ok. 1050 stron/godz. Applebot-Extended, uruchomiony w czerwcu 2024, decyduje, jak już zindeksowane przez Applebot treści będą wykorzystywane do treningu AI Apple, choć nie indeksuje stron bezpośrednio. CCBot od Common Crawl (organizacji non-profit) buduje otwarte archiwa webowe wykorzystywane przez wiele firm AI, w tym OpenAI, Google, Meta i Hugging Face. Nowe crawlery od firm takich jak xAI (Grok), Mistral i DeepSeek zaczynają pojawiać się w logach serwerowych, sygnalizując rozrost ekosystemu AI crawlerów.
Poniżej znajduje się kompletna tabela referencyjna zweryfikowanych AI crawlerów, ich celów, user agentów oraz składni blokowania w robots.txt. Tabela jest regularnie aktualizowana na podstawie logów serwera i oficjalnej dokumentacji. Każda pozycja została potwierdzona względem oficjalnych list IP, jeśli są dostępne:
| Nazwa crawlera | Firma | Cel | User Agent | Tempo | Weryfikacja IP | Składnia robots.txt |
|---|---|---|---|---|---|---|
| GPTBot | OpenAI | Zbieranie danych treningowych | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.3; +https://openai.com/gptbot) | 100/godz. | ✓ Oficjalna | User-agent: GPTBot Disallow: / |
| ChatGPT-User | OpenAI | Żądania użytkowników | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; ChatGPT-User/1.0 | 2400/godz. | ✓ Oficjalna | User-agent: ChatGPT-User Disallow: / |
| OAI-SearchBot | OpenAI | Indeksowanie wyszukiwania | Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36; compatible; OAI-SearchBot/1.3 | 150/godz. | ✓ Oficjalna | User-agent: OAI-SearchBot Disallow: / |
| ClaudeBot | Anthropic | Zbieranie danych treningowych | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com) | 500/godz. | ✓ Oficjalna | User-agent: ClaudeBot Disallow: / |
| Claude-User | Anthropic | Dostęp do sieci na żądanie | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Claude-User/1.0) | <10/godz. | ✗ Brak | User-agent: Claude-User Disallow: / |
| Claude-SearchBot | Anthropic | Indeksowanie wyszukiwania | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Claude-SearchBot/1.0) | <10/godz. | ✗ Brak | User-agent: Claude-SearchBot Disallow: / |
| Google-Extended | Trening Gemini AI | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Google-Extended/1.0) | Zmienny | ✓ Oficjalna | User-agent: Google-Extended Disallow: / | |
| Gemini-Deep-Research | Funkcja badawcza | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Gemini-Deep-Research) | <10/godz. | ✓ Oficjalna | User-agent: Gemini-Deep-Research Disallow: / | |
| Bingbot | Microsoft | Wyszukiwarka Bing & Copilot | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; bingbot/2.0) | 1300/godz. | ✓ Oficjalna | User-agent: Bingbot Disallow: / |
| Meta-ExternalAgent | Meta | Trening modeli AI | meta-externalagent/1.1 (+https://developers.facebook.com/docs/sharing/webmasters/crawler) | 1100/godz. | ✗ Brak | User-agent: Meta-ExternalAgent Disallow: / |
| Amazonbot | Amazon | Ulepszanie usług | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Amazonbot/0.1) | 1050/godz. | ✓ Oficjalna | User-agent: Amazonbot Disallow: / |
| Applebot-Extended | Apple | Trening AI | Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15; compatible; Applebot-Extended | <10/godz. | ✓ Oficjalna | User-agent: Applebot-Extended Disallow: / |
| PerplexityBot | Perplexity | Indeksowanie wyszukiwania | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; PerplexityBot/1.0) | 150/godz. | ✓ Oficjalna | User-agent: PerplexityBot Disallow: / |
| Perplexity-User | Perplexity | Pobieranie na żądanie | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Perplexity-User/1.0) | <10/godz. | ✓ Oficjalna | User-agent: Perplexity-User Disallow: / |
| Bytespider | ByteDance | Trening AI | Mozilla/5.0 (Linux; Android 5.0) AppleWebKit/537.36; compatible; Bytespider | <10/godz. | ✗ Brak | User-agent: Bytespider Disallow: / |
| CCBot | Common Crawl | Otwarty zbiór danych | CCBot/2.0 (https://commoncrawl.org/faq/ ) | <10/godz. | ✓ Oficjalna | User-agent: CCBot Disallow: / |
| DuckAssistBot | DuckDuckGo | AI wyszukiwanie | DuckAssistBot/1.2; (+http://duckduckgo.com/duckassistbot.html) | 20/godz. | ✓ Oficjalna | User-agent: DuckAssistBot Disallow: / |
| Diffbot | Diffbot | Ekstrakcja danych | Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.9.1.2) Gecko/20090729 Firefox/3.5.2 Diffbot/0.1 | <10/godz. | ✗ Brak | User-agent: Diffbot Disallow: / |
| MistralAI-User | Mistral | Pobieranie na żądanie | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; MistralAI-User/1.0) | <10/godz. | ✗ Brak | User-agent: MistralAI-User Disallow: / |
| ICC-Crawler | NICT | Trening AI/ML | ICC-Crawler/3.0 (Mozilla-compatible; https://ucri.nict.go.jp/en/icccrawler.html ) | <10/godz. | ✗ Brak | User-agent: ICC-Crawler Disallow: / |
Nie wszystkie AI crawlery mają ten sam cel, a rozróżnienie tych kategorii jest kluczowe przy podejmowaniu decyzji o blokowaniu. Crawlery treningowe stanowią ok. 80% całego ruchu botów AI i zbierają treści specjalnie na potrzeby budowy zbiorów do trenowania modeli językowych. Gdy Twoje treści trafią do zbioru treningowego, stają się częścią trwałej bazy wiedzy modelu, co może zmniejszyć potrzebę odwiedzin Twojej strony przez użytkowników. Crawlery treningowe jak GPTBot, ClaudeBot czy Meta-ExternalAgent działają na dużą skalę i systematycznie, niemal nie generując ruchu zwrotnego do wydawców.
Crawlery wyszukiwania i cytowania indeksują treści dla AI-owych doświadczeń wyszukiwawczych i mogą faktycznie przesyłać ruch zwrotny przez cytowania. Gdy użytkownicy zadają pytania w ChatGPT czy Perplexity, takie crawlery pomagają wyświetlać powiązane źródła. W odróżnieniu od crawlerów treningowych, crawlery wyszukiwania jak OAI-SearchBot i PerplexityBot działają z umiarkowaną intensywnością i skupiają się na wyszukiwaniu oraz mogą dodać atrybucję i link. Pobieracze uruchamiane przez użytkownika aktywują się tylko, gdy użytkownik poprosi AI o analizę konkretnej strony – pobierają treści jednorazowo i w bardzo małej skali, nie są używane do trenowania modeli. Zrozumienie tych kategorii pozwala strategicznie decydować, które crawlery dopuszczać, a które blokować, w zależności od priorytetów biznesowych.
Pierwszym krokiem zarządzania AI crawlerami jest sprawdzenie, które z nich rzeczywiście odwiedzają Twoją stronę. Logi dostępu serwera zawierają szczegółowe zapisy każdego żądania, w tym user agent identyfikujący crawlera. Większość paneli hostingowych udostępnia narzędzia do analizy logów, ale możesz też uzyskać dostęp do surowych logów. Dla serwerów Apache logi zazwyczaj znajdują się w /var/log/apache2/access.log, a dla Nginx w /var/log/nginx/access.log. Możesz filtrować logi za pomocą grep, by znaleźć aktywność crawlerów:
grep -i "gptbot\|claudebot\|google-extended\|bytespider" /var/log/apache2/access.log | head -20
To polecenie pokazuje 20 najnowszych żądań od głównych AI crawlerów. Google Search Console prezentuje statystyki crawlery Google, choć tylko dla własnych botów. Cloudflare Radar oferuje globalny wgląd w ruch AI botów i pomaga zidentyfikować najbardziej aktywne crawlery. Aby sprawdzić, czy crawler jest autentyczny, sprawdź adres IP żądania względem oficjalnych list IP publikowanych przez główne firmy. OpenAI publikuje zweryfikowane IP na https://openai.com/gptbot.json, Amazon na https://developer.amazon.com/amazonbot/ip-addresses/, inni również prowadzą takie listy. Fałszywy crawler podszywający się pod oficjalnego user agenta z niezweryfikowanego IP powinien być niezwłocznie zablokowany jako potencjalnie złośliwy scraping.
Plik robots.txt to Twoje główne narzędzie kontroli dostępu crawlerów. Prosty plik tekstowy w katalogu głównym strony, wskazuje crawlerom, które części serwisu są dostępne. Aby zablokować konkretne AI crawlery, dodaj wpisy takie jak:
# Blokada GPTBot OpenAI
User-agent: GPTBot
Disallow: /
# Blokada ClaudeBot Anthropic
User-agent: ClaudeBot
Disallow: /
# Blokada AI Google (nie wyszukiwarki)
User-agent: Google-Extended
Disallow: /
# Blokada Common Crawl
User-agent: CCBot
Disallow: /
Możesz też dopuścić crawlery, ale ustawić ograniczenia tempa, by uniknąć przeciążenia serwera:
User-agent: GPTBot
Crawl-delay: 10
Disallow: /private/
To mówi GPTBotowi, by czekał 10 sekund między żądaniami i nie wchodził do katalogu /private/. Przykład zrównoważonego podejścia – pozwalanie crawlerom wyszukiwarki przy jednoczesnej blokadzie crawlerów treningowych:
# Pozwól tradycyjnym wyszukiwarkom
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
# Zablokuj wszystkie AI crawlery treningowe
User-agent: GPTBot
User-agent: ClaudeBot
User-agent: CCBot
User-agent: Google-Extended
User-agent: Bytespider
User-agent: Meta-ExternalAgent
Disallow: /
# Pozwól AI crawlerom wyszukiwania
User-agent: OAI-SearchBot
Allow: /
User-agent: PerplexityBot
Allow: /
Większość renomowanych AI crawlerów przestrzega robots.txt, choć niektóre agresywne boty całkowicie go ignorują. Dlatego robots.txt sam w sobie nie daje pełnej ochrony.
Robots.txt to zalecenie, a nie wymóg prawny – crawlery mogą je ignorować. Silniejszą ochronę przed crawlerami, które nie respektują robots.txt, daje blokowanie po adresach IP na poziomie serwera. To bardziej wiarygodne, bo trudniej podszyć się pod IP niż pod user agenta. Możesz dopuścić zweryfikowane IP z oficjalnych źródeł, blokując wszystkie pozostałe żądania podszywające się pod AI crawlery.
Dla serwerów Apache użyj reguł .htaccess do blokowania crawlerów na poziomie serwera:
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} (GPTBot|ClaudeBot|anthropic-ai|Bytespider|CCBot) [NC]
RewriteRule .* - [F,L]
</IfModule>
To zwraca odpowiedź 403 Forbidden dla pasujących user agentów, niezależnie od robots.txt. Reguły firewall to kolejna warstwa ochrony – możesz dopuścić oficjalne zakresy IP, blokując pozostałe. Większość firewalli i hostingów pozwala ustawiać takie reguły. Meta tagi HTML dają kontrolę na poziomie pojedynczych stron. Amazon i niektóre inne crawlery respektują dyrektywę noarchive:
<meta name="robots" content="noarchive">
To mówi crawlerom, by nie używały danej strony do treningu modeli, pozwalając jednak na inne działania. Wybierz metodę blokowania zgodnie z możliwościami technicznymi i docelowym crawlerem. Blokowanie po IP jest najpewniejsze, ale wymaga więcej pracy. Robots.txt jest najprostszy, ale mniej skuteczny wobec niestosujących się botów.
Blokowanie crawlerów to połowa sukcesu – musisz jeszcze sprawdzić, czy blokady działają. Regularne monitorowanie pozwala szybko wychwycić problemy i nowe crawlery, z którymi się nie spotkałeś. Przeglądaj logi serwera co tydzień pod kątem nietypowej aktywności botów; szukaj user agentów zawierających „bot”, „crawler”, „spider” lub nazw firm, np. „GPT”, „Claude”, „Perplexity”. Ustaw alerty na nagłe wzrosty ruchu botów, co może oznaczać nowe crawlery lub agresywne działania znanych. Google Search Console pokazuje statystyki crawlery Google, co pomaga monitorować Googlebota i Google-Extended. Cloudflare Radar zapewnia globalny wgląd w ruch AI crawlerów i pozwala wykrywać nowe boty odwiedzające Twoją stronę.
By sprawdzić skuteczność robots.txt, wejdź na twojastrona.com/robots.txt i upewnij się, że wszystkie user agenty i dyrektywy są poprawne. Sprawdzaj logi dostępu pod kątem żądań z zablokowanych crawlerów. Jeśli widzisz żądania od zablokowanych botów, ignorują one dyrektywy lub podszywają się pod inne user agenty. Przetestuj wdrożenia, sprawdzając dostęp crawlerów w logach i statystykach. Przeglądaj konfigurację co kwartał, bo środowisko AI crawlerów szybko się zmienia.
AI crawlery takie jak GPTBot i ClaudeBot zbierają treści specjalnie do trenowania dużych modeli językowych, podczas gdy crawlery wyszukiwarek, takie jak Googlebot, indeksują treści, aby ludzie mogli je znaleźć w wynikach wyszukiwania. AI crawlery zasilają bazy wiedzy systemów AI, natomiast crawlery wyszukiwarek pomagają użytkownikom odkrywać Twoje treści. Kluczowa różnica to cel: trenowanie kontra wyszukiwanie.
Nie, blokowanie AI crawlerów nie wpłynie na tradycyjne pozycje w wyszukiwarkach. AI crawlery, takie jak GPTBot i ClaudeBot, są całkowicie oddzielone od crawlerów wyszukiwarek takich jak Googlebot. Możesz zablokować Google-Extended (do trenowania AI), a jednocześnie pozwolić Googlebotowi (do wyszukiwania). Każdy crawler ma inny cel i blokowanie jednego nie wpływa na drugi.
Sprawdź logi dostępu serwera, aby zobaczyć, które agenty użytkownika odwiedzają Twoją witrynę. Szukaj nazw botów takich jak GPTBot, ClaudeBot, CCBot i Bytespider w ciągach user agent. Większość paneli hostingowych udostępnia narzędzia do analizy logów. Możesz też użyć Google Search Console do monitorowania aktywności crawlerów, choć pokazuje ona tylko crawlery Google.
Nie wszystkie AI crawlery w równym stopniu przestrzegają robots.txt. GPTBot od OpenAI, ClaudeBot od Anthropic i Google-Extended zazwyczaj stosują się do zasad robots.txt. Bytespider i PerplexityBot były obiektem doniesień sugerujących, że mogą niekonsekwentnie respektować te dyrektywy. W przypadku crawlerów, które nie respektują robots.txt, musisz wdrożyć blokowanie oparte na IP na poziomie serwera za pomocą firewalla lub pliku .htaccess.
Decyzja zależy od Twoich celów. Zablokuj crawlery treningowe, jeśli posiadasz treści zastrzeżone lub ograniczone zasoby serwera. Pozwól na crawlery wyszukiwarek, jeśli chcesz być widoczny w wynikach wyszukiwania i chatbotach opartych na AI, które mogą generować ruch i budować autorytet. Wiele firm stosuje selektywne podejście – pozwala wybranym crawlerom, blokując agresywne, takie jak Bytespider.
Nowe AI crawlery pojawiają się regularnie, więc przynajmniej raz na kwartał przeglądaj i aktualizuj swoją listę blokad. Śledź zasoby takie jak projekt ai.robots.txt na GitHub, gdzie znajdziesz listy utrzymywane przez społeczność. Sprawdzaj logi serwera co miesiąc, aby zidentyfikować nowe crawlery odwiedzające Twoją stronę, których nie ma w obecnej konfiguracji. Ekosystem AI crawlerów szybko się zmienia, więc Twoja strategia również powinna się dostosowywać.
Tak, sprawdź adres IP żądania względem oficjalnych list IP publikowanych przez główne firmy. OpenAI udostępnia zweryfikowane IP na https://openai.com/gptbot.json, Amazon na https://developer.amazon.com/amazonbot/ip-addresses/, a inni utrzymują podobne listy. Crawler podszywający się pod oficjalny user agent z niezweryfikowanego IP powinien być natychmiast zablokowany, gdyż prawdopodobnie jest to złośliwy scraping.
AI crawlery mogą konsumować znaczące zasoby transferu i serwera. Bytespider i Meta-ExternalAgent należą do najbardziej agresywnych crawlerów. Niektórzy wydawcy raportują zmniejszenie zużycia transferu z 800 GB do 200 GB dziennie po zablokowaniu AI crawlerów, co daje oszczędność ok. 1 500 USD miesięcznie. Monitoruj zasoby serwera w czasie szczytowych indeksowań i wdrażaj ograniczenia tempa dla agresywnych botów w razie potrzeby.
Śledź, które AI crawlery cytują Twoje treści i optymalizuj widoczność w ChatGPT, Perplexity, Google Gemini i innych.
Dowiedz się, jak strategie renderowania SSR i CSR wpływają na widoczność dla AI crawlerów, cytowania marki w ChatGPT i Perplexity oraz ogólną obecność w wyszuki...

Dowiedz się, jak zezwolić botom AI, takim jak GPTBot, PerplexityBot i ClaudeBot, na indeksowanie Twojej strony. Skonfiguruj robots.txt, utwórz llms.txt i zoptym...

Dowiedz się, jak działają AI crawlers takie jak GPTBot i ClaudeBot, czym różnią się od tradycyjnych crawlerów wyszukiwarek oraz jak zoptymalizować swoją stronę ...