Ponowne publikowanie treści a AI: Rozważania dotyczące duplikowania treści
Dowiedz się, jak ponowne publikowanie treści powoduje problemy z duplikatami, które bardziej szkodzą widoczności w AI search niż w tradycyjnych wyszukiwarkach. Poznaj techniczne zabezpieczenia i najlepsze praktyki.
Opublikowano Jan 3, 2026.Ostatnia modyfikacja Jan 3, 2026 o 3:24 am
Ponowne publikowanie treści w różnych kanałach, na platformach i w rozmaitych formatach to uzasadniona i często niezbędna strategia maksymalizacji zasięgu oraz zaangażowania. Takie działania generują jednak fundamentalne napięcie względem sposobu, w jaki systemy wyszukiwania — szczególnie te oparte o AI — przetwarzają i pozycjonują treści. Problemem nie jest to, czy możesz ponownie publikować, ale czy robisz to w sposób, który nie szkodzi Twojej widoczności w wynikach AI search. W przeciwieństwie do tradycyjnych wyszukiwarek, które przez lata wypracowały zaawansowane mechanizmy wykrywania duplikatów, systemy AI podchodzą do duplikatów inaczej, tworząc nowe ryzyka, na które wielu wydawców nie jest jeszcze przygotowanych.
Jak systemy AI przetwarzają ponownie publikowane treści
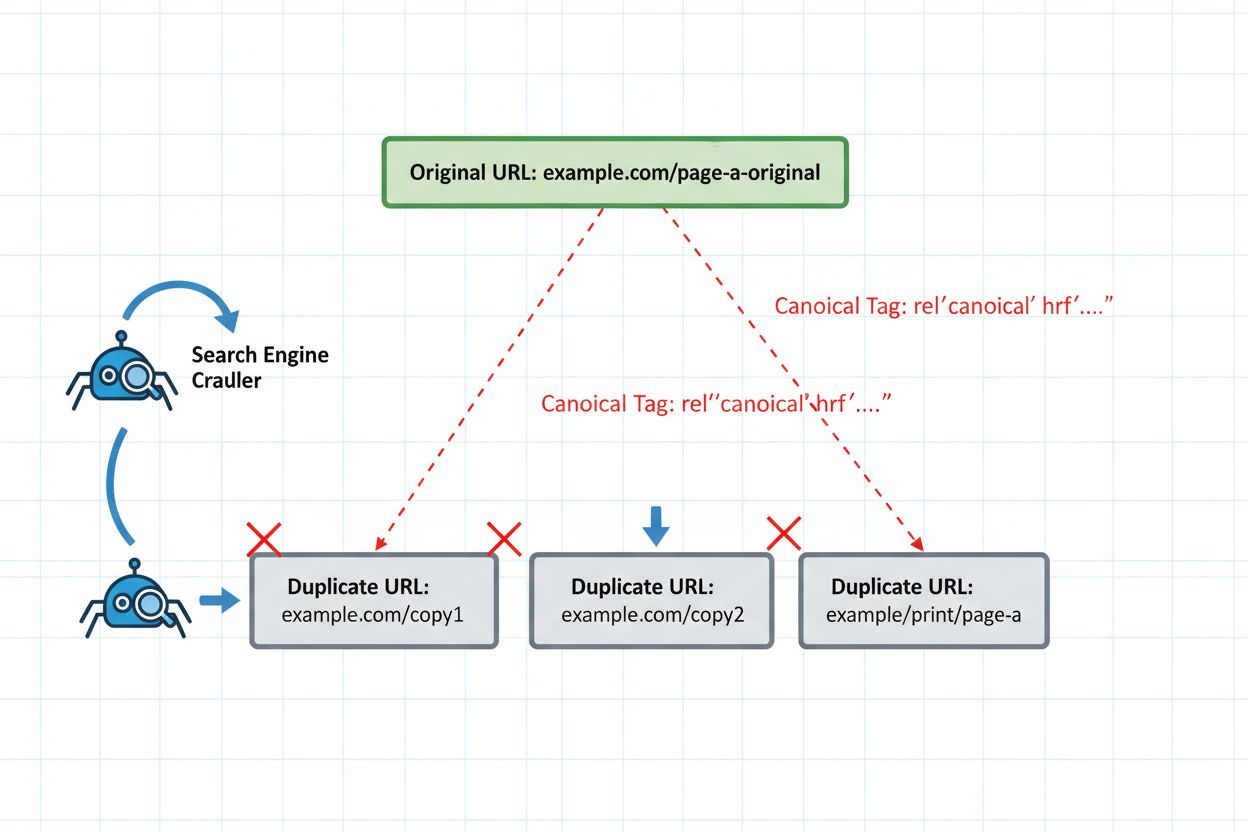
Zgodnie z dokumentacją techniczną Microsoft dotyczącą Copilot i AI search, “LLM-y grupują adresy URL o dużym podobieństwie w jeden klaster i wybierają jedną stronę do reprezentowania całego zbioru.” To podejście klastrowania różni się zasadniczo od tego, jak algorytm Google PageRank rozdziela autorytet pomiędzy zduplikowane strony. Zamiast konsolidować sygnały, systemy AI podejmują zero-jedynkową decyzję: wybierają jedną reprezentatywną stronę z grupy podobnych treści i w dużej mierze ignorują pozostałe. Proces wyboru nie zawsze jest przewidywalny ani oparty na tej wersji, którą wolałbyś pozycjonować. Algorytm bierze pod uwagę takie czynniki jak świeżość, jakość treści, sygnały techniczne i autorytet domeny — ale wagi tych czynników pozostają niejawne. Szczególnie problematyczne jest to, że systemy AI mogą wybrać nieaktualną wersję, jeśli różnice między stronami są minimalne i algorytm klastrowania nie wykryje istotnych zmian.
Aspekt
Tradycyjne wyszukiwanie
Wyszukiwanie AI
Obsługa duplikatów
Konsolidacja sygnałów autorytetu
Grupowanie i wybór jednej reprezentatywnej
Ryzyko kary
Możliwa ręczna interwencja
Brak kary, ale rozproszenie widoczności
Rozpoznanie aktualizacji
Stopniowe rozprzestrzenianie sygnałów
Może pominąć aktualizacje przy minimalnych różnicach
Efektywność indeksowania
Marnowanie budżetu na duplikaty
Obniżenie priorytetu indeksowania duplikatów
Uwzględnianie kanonicznych
W większości respektowane
Kluczowe dla wyboru w klastrze
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Ponowne publikowanie bez odpowiednich zabezpieczeń niesie trzy powiązane ryzyka bezpośrednio wpływające na widoczność w AI:
Rozproszenie sygnału intencji: Gdy ta sama treść pojawia się pod wieloma adresami URL, system AI otrzymuje sprzeczne sygnały, która wersja najlepiej odpowiada na zapytanie użytkownika. Zamiast kumulować autorytet na jednym adresie, sygnały rozpraszają się w klastrze. To rozproszenie obniża ocenę pewności, jaką AI przypisuje Twojej treści przy decyzji o jej uwzględnieniu w odpowiedziach. Treść, która mogła być głównym źródłem, staje się tylko jedną z opcji, bo system nie jest w stanie jednoznacznie określić wersji autorytatywnej.
Ryzyko reprezentacji: Wybór strony reprezentującej Twój klaster treści przez system AI może nie być zgodny z Twoimi celami biznesowymi. Możesz opublikować wpis na blogu w sieci syndykacyjnej z myślą, że ta wersja przyniesie ruch, ale AI wybierze Twoją wersję oryginalną — lub co gorsza, syndykowaną, która nie odsyła do Twojej strony. Takie rozminięcie się z intencją sprawia, że strategia republishingu działa przeciw Twoim celom widoczności, zamiast je wzmacniać.
Opóźnienia i nieaktualność: Gdy aktualizujesz oryginalną treść, a wersje ponownie publikowane pozostają niezmienione, systemy AI mogą wybrać jako reprezentatywną nieaktualną wersję. Algorytm klastrowania nie zawsze rozpoznaje, że jedna wersja jest nowsza czy dokładniejsza, szczególnie gdy zmiany są drobne, a nie strukturalne. Powoduje to, że najbardziej aktualna i rzetelna treść staje się niewidoczna, a AI prezentuje użytkownikom starszą wersję jako Twoją ekspertyzę.
Syndykacja bez tagów kanonicznych
Najczęstszy błąd przy ponownym publikowaniu pojawia się, gdy treści są syndykowane na zewnętrzne platformy bez implementacji tagów kanonicznych. Przykład: firma B2B publikuje na blogu obszerny poradnik, a następnie syndykuje go do portali branżowych takich jak Medium, LinkedIn i specjalistyczne agregatory. Każda platforma hostuje identyczną treść pod innym adresem URL. Bez tagów kanonicznych wskazujących wersję oryginalną, algorytm klastrowania AI traktuje wszystkie wersje jako równie autorytatywne. Platforma syndykacyjna może mieć wyższy autorytet domeny, przez co AI wybierze ją jako stronę reprezentatywną. Twoja oryginalna treść — ta, którą zoptymalizowałeś, zaktualizowałeś i zbudowałeś do niej linki — staje się niewidoczna w AI search. Ruch i autorytet trafiają do syndykatora, a nie do Twojej własności. Taki scenariusz powtarza się codziennie tysiące razy w branży wydawniczej — wydawcy nieświadomie sabotują własną widoczność przez brak jednego znacznika HTML.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Strony kampanii i wariacje ponownie publikowane
Treści kampanijne generują szczególnie problematyczny problem duplikatów przy ponownym publikowaniu w różnych kanałach. Zespół marketingowy uruchamia stronę lądowania zoptymalizowaną pod konkretną promocję, po czym publikuje jej wariacje w newsletterach, social media, płatnych reklamach i na stronach partnerów. Każda wersja ma nieco inne teksty, CTA czy formatowanie — ale zasadnicza treść i intencja są identyczne. Systemy AI rozpoznają to jako duplikaty i grupują razem. Problem nasila się, gdy strony kampanijne są publikowane bez implementacji kanonicznych. AI może wybrać jako reprezentatywną wersję newslettera (bez śledzenia konwersji) lub wersję u partnera, która nie daje Ci żadnych korzyści. Dodatkowo, gdy kampania się kończy i strony są archiwizowane lub usuwane, AI mogło już wybrać nieaktualną wersję, przez co Twoja treść znika lub kieruje użytkowników do nieistniejących stron.
Lokalizacja i regionalne ponowne publikowanie
Regionalne ponowne publikowanie komplikuje sytuację, bo detekcja duplikatów musi uwzględniać uzasadnione potrzeby lokalizacyjne. Firma działająca w wielu krajach może publikować tę samą treść w różnych językach lub z regionalnymi wariacjami. Bez odpowiedniej implementacji takie wersje konkurują ze sobą w klastrach AI. Przykład: SaaS publikuje przewodnik funkcji po angielsku na domenie US, a następnie na domenie UK z brytyjską pisownią i cenami. AI grupuje to jako duplikaty, potencjalnie wybierając wersję US nawet dla użytkowników z UK. Rozwiązaniem jest zastosowanie tagów hreflang sygnalizujących relacje regionalne AI, choć skuteczność hreflang w AI search jest mniej potwierdzona niż w tradycyjnym SEO.
<!-- Na wersji US (example.com/feature-guide) --><linkrel="alternate"hreflang="en-US"href="https://example.com/feature-guide" />
<linkrel="alternate"hreflang="en-GB"href="https://example.co.uk/feature-guide" />
<linkrel="alternate"hreflang="x-default"href="https://example.com/feature-guide" />
<!-- Na wersji UK (example.co.uk/feature-guide) --><linkrel="alternate"hreflang="en-GB"href="https://example.co.uk/feature-guide" />
<linkrel="alternate"hreflang="en-US"href="https://example.com/feature-guide" />
<linkrel="alternate"hreflang="x-default"href="https://example.com/feature-guide" />
Techniczne zabezpieczenia dla ponownie publikowanych treści
Odpowiednie zabezpieczenia techniczne to obowiązek przy bezpiecznym ponownym publikowaniu. Tag kanoniczny pozostaje główną linią obrony — jednoznacznie wskazuje systemom AI, która wersja powinna reprezentować Twój klaster treści. Umieść tag kanoniczny w sekcji <head> każdej ponownie publikowanej wersji, wskazując preferowaną, autorytatywną wersję. Dla treści syndykowanych to zazwyczaj oznacza wskazanie oryginalnej domeny.
<!-- Na wersji syndykowanej (medium.com/twoja-publikacja/artykul) --><linkrel="canonical"href="https://yoursite.com/blog/article" />
Dla treści, które nigdy nie powinny konkurować z innymi wersjami, zastosuj noindex na stronach drugorzędnych. Całkowicie usuwa je to z indeksu AI, gwarantując, że nie zostaną wybrane jako reprezentatywne. Stosuj tę metodę dla wewnętrznych duplikatów, wersji testowych lub syndykowanych, gdzie nie chcesz widoczności w AI search.
<!-- Na wersji drugorzędnej, która nie powinna być indeksowana --><metaname="robots"content="noindex, follow" />
Przekierowania 301 to najsilniejszy sygnał konsolidacji autorytetu, ale stosuj je tylko, gdy wersja drugorzędna nigdy nie będzie samodzielnie aktualizowana. Przekierowania informują AI, że stary adres został trwale przeniesiony, przekazując wszystkie sygnały na nowe miejsce. Jeśli jednak obie wersje muszą pozostać dostępne (np. w syndykacji), przekierowania są problematyczne, bo łamią strukturę adresów syndykatora.
# W .htaccess lub konfiguracji serwera
Redirect 301 /old-article https://yoursite.com/new-article
W systemach CMS stosuj dynamiczne rel=“canonical”, aby obsłużyć paginację, wariacje parametrów i adresy sesyjne generujące niezamierzone duplikaty. Wiele platform CMS tworzy różne adresy do tej samej treści przez różne ścieżki nawigacyjne — tagi kanoniczne automatycznie to konsolidują.
IndexNow dla oczyszczenia po ponownym publikowaniu
IndexNow przyspiesza wykrywanie sygnałów kanonicznych i konsolidację duplikatów, skracając to, co tradycyjnie zajmowało tygodnie, do kilku dni. Po wdrożeniu tagów kanonicznych na ponownie publikowanych treściach, IndexNow natychmiast powiadamia systemy wyszukiwania, że te adresy powinny być grupowane razem. Zamiast czekać, aż roboty odkryją relację kanoniczną podczas standardowego indeksowania, IndexNow przekazuje tę informację bezpośrednio do indeksu Microsoft i innych współpracujących systemów. Jest to szczególnie przydatne przy retroaktywnym naprawianiu błędów publikacyjnych — możesz wdrożyć tagi kanoniczne i natychmiast za pomocą IndexNow zasygnalizować zmianę, zamiast czekać na ponowne odwiedziny robotów. Dla wydawców zarządzających treściami na wielu platformach IndexNow staje się krytycznym narzędziem kontroli nad tym, która wersja reprezentuje Twój klaster treści. Integracja API pozwala zgłaszać adresy hurtowo, czyniąc zarządzanie setkami lub tysiącami ponownie publikowanych stron wykonalnym.
Monitorowanie skuteczności ponownie publikowanych treści
Aby śledzić, którą wersję ponownie publikowanej treści wybiera AI, potrzebujesz monitoringu wykraczającego poza tradycyjną analitykę. Skonfiguruj śledzenie, by identyfikować, kiedy systemy AI cytują lub odnoszą się do Twojej treści, zwracając uwagę, który adres URL pojawia się w wynikach AI search. Narzędzia takie jak Semrush, Ahrefs czy Moz zaczynają dodawać metryki widoczności w AI search, choć są one mniej rozwinięte niż tradycyjny monitoring SEO. Stosuj parametry UTM na wersjach syndykowanych, by śledzić przypisanie ruchu, jednak miej na uwadze, że AI może nie przekazywać tych parametrów, utrudniając precyzyjną atrybucję. Monitoruj Search Console (lub analogiczne narzędzia innych systemów), aby wykryć wzorce indeksowania — jeśli wersje drugorzędne są indeksowane częściej niż kanoniczna, AI mogło wybrać niewłaściwą stronę reprezentatywną. Skonfiguruj alerty dla wzmianek o Twojej treści na platformach syndykacyjnych i porównaj je z widocznością w AI search, by zidentyfikować rozbieżności między miejscem pojawiania się treści a wyborem AI.
Przed każdą ponowną publikacją zastosuj tę checklistę, aby zachować kontrolę nad widocznością w AI:
Przed publikacją zidentyfikuj wersję kanoniczną — adres URL, który ma reprezentować treść w AI search. Najczęściej powinna to być Twoja domena, a nie platforma syndykacyjna. Stosuj tagi kanoniczne na każdej ponownie publikowanej wersji, wskazujące Twój kanoniczny adres, nawet jeśli publikujesz na własnych zasobach (domeny, subdomeny, wariacje parametrów). Użyj IndexNow, by natychmiast zgłosić systemom relację kanoniczną, zamiast czekać na indeksowanie. Unikaj publikacji na platformach o wysokim autorytecie bez wsparcia kanonicznych — niektóre usuwają tagi kanoniczne lub ich nie obsługują, co czyni je nieodpowiednimi do publikacji, jeśli nie akceptujesz utraty widoczności. Monitoruj pierwsze 48 godzin po publikacji, by sprawdzić, czy AI wybiera zamierzoną wersję kanoniczną, a nie inną. Aktualizuj wszystkie wersje jednocześnie podczas zmian treści — jeśli zaktualizujesz tylko wersję kanoniczną, algorytm klastrowania może nie rozpoznać aktualizacji we wszystkich wersjach, przez co AI wybierze starszą wersję. Ustal harmonogram ponownego publikowania, by zapobiec starzeniu się treści na platformach drugorzędnych; nieaktualne treści syndykowane zwiększają ryzyko, że AI wybierze je jako wersję reprezentatywną, jeśli Twoja kanoniczna nie była niedawno aktualizowana.
Najczęściej zadawane pytania
Czy ponowne publikowanie treści z tagami kanonicznymi zapobiega karom za duplikaty?
Tagi kanoniczne nie zapobiegają karom, ponieważ duplikowanie treści samo w sobie nie powoduje kar. Jednak tagi kanoniczne są kluczowe dla wyszukiwarek AI, ponieważ wskazują systemom AI, która wersja powinna reprezentować Twój klaster treści. Bez tagów kanonicznych AI może wybrać niezamierzoną wersję jako źródło autorytatywne, zmniejszając Twoją widoczność.
Jak sprawdzić, czy moja ponownie publikowana treść jest wybierana przez systemy AI?
Monitoruj, które adresy URL pojawiają się w wynikach AI search i cytowaniach Twojej treści. Narzędzia takie jak Semrush i Ahrefs wprowadzają metryki widoczności w AI search. Sprawdź Search Console pod kątem wzorców indeksowania — jeśli wersje drugorzędne są indeksowane częściej niż Twoja wersja kanoniczna, system AI mógł wybrać niewłaściwą stronę.
Czy mogę publikować tę samą treść na wielu domenach bez tagów kanonicznych?
Technicznie tak, ale nie jest to zalecane. Bez tagów kanonicznych systemy AI pogrupują Twoje treści i wybiorą jedną wersję jako reprezentatywną — ale nie masz kontroli, którą. Platforma syndykacyjna może mieć wyższy autorytet, przez co AI wybierze tę wersję zamiast Twojej oryginalnej domeny.
Czym różni się ponowne publikowanie od syndykacji treści?
Ponowne publikowanie zazwyczaj oznacza dystrybucję Twojej treści przez wiele kanałów, które kontrolujesz lub z którymi współpracujesz. Syndykacja treści to specyficzna forma ponownego publikowania, gdzie platformy zewnętrzne publikują treść za Twoją zgodą. Oba przypadki powodują problemy z duplikatami, jeśli nie są odpowiednio zarządzane za pomocą tagów kanonicznych.
Jak długo trwa uznanie tagów kanonicznych w AI search?
Tagi kanoniczne są zazwyczaj rozpoznawane w ciągu 24-48 godzin, jeśli używasz IndexNow do natychmiastowego powiadomienia systemów wyszukiwania. Bez IndexNow może to potrwać tygodnie, zanim roboty odkryją relację kanoniczną. Dlatego IndexNow jest kluczowy przy zarządzaniu ponownie publikowanymi treściami — znacząco przyspiesza proces.
Czy dla ponownie publikowanych treści stosować przekierowania 301 czy tagi kanoniczne?
Używaj przekierowań 301 tylko wtedy, gdy chcesz trwale scalić adresy URL i wersja drugorzędna nigdy nie będzie aktualizowana niezależnie. Stosuj tagi kanoniczne, gdy obie wersje muszą pozostać dostępne (jak w syndykacji). Przekierowania są silniejszym sygnałem, ale uniemożliwiają korzystanie z drugorzędnego adresu.
Czy ponowne publikowanie treści szkodzi widoczności mojej oryginalnej domeny w AI?
Tak, jeśli nie jest odpowiednio zarządzane. Ponowne publikowanie bez tagów kanonicznych rozprasza sygnały autorytetu na kilka adresów URL. AI może wybrać wersję syndykowaną zamiast oryginalnej, przez co Twoja domena traci widoczność. Właściwa implementacja kanoniczna temu zapobiega.
Jak najlepiej ponownie publikować treści, aby maksymalnie zwiększyć zasięg bez problemów z duplikatami?
Stosuj tagi kanoniczne na każdej ponownie publikowanej wersji, wskazując na Twoją oryginalną domenę. Użyj IndexNow, aby natychmiast powiadomić systemy wyszukiwania o relacji kanonicznej. Unikaj publikacji na platformach, które nie obsługują tagów kanonicznych. Monitoruj, którą wersję AI wybiera w pierwszych 48 godzinach i koryguj w razie potrzeby.
Monitoruj widoczność swojej treści w AI
Śledź, jak systemy AI cytują i odnoszą się do Twoich ponownie publikowanych treści na wszystkich platformach. Uzyskaj wgląd w czasie rzeczywistym, którą wersję AI wybiera jako Twoje autorytatywne źródło.
Adresy URL kanoniczne a AI: Zapobieganie problemom z duplikacją treści
Dowiedz się, jak adresy URL kanoniczne zapobiegają problemom z duplikacją treści w systemach wyszukiwania AI. Poznaj najlepsze praktyki wdrażania kanonicznych a...
Jak radzić sobie z duplikatami treści dla wyszukiwarek AI
Dowiedz się, jak zarządzać i zapobiegać duplikatom treści podczas korzystania z narzędzi AI. Poznaj znaczniki kanoniczne, przekierowania, narzędzia do wykrywani...
Jakie formaty treści sprawdzają się najlepiej w wyszukiwarce AI? Kompletny przewodnik
Odkryj najlepsze formaty treści dla wyszukiwarek AI takich jak ChatGPT, Perplexity i Google AI Overviews. Dowiedz się, jak zoptymalizować swoje treści pod kątem...
11 min czytania
Zgoda na Pliki Cookie Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.