Stack Overflow i cytowania przez AI: Widoczność społeczności technicznej
Dowiedz się, jak treści ze Stack Overflow kształtują odpowiedzi AI i poznaj strategie maksymalizowania swojej widoczności deweloperskiej w ChatGPT, Gemini i innych platformach AI.
Opublikowano Jan 3, 2026.Ostatnia modyfikacja Jan 3, 2026 o 3:24 am
50 milionów pytań i odpowiedzi ze Stack Overflow stało się fundamentem rozwoju dużych modeli językowych. Najwięksi gracze AI, w tym OpenAI, Google i Meta, włączyli dane Stack Overflow do swoich zbiorów treningowych, ponieważ wiedza deweloperów reprezentuje jedne z najwyższej jakości, recenzowanych treści technicznych dostępnych w internecie. Tworzenie zaawansowanych systemów AI kosztuje setki milionów dolarów, z czego znaczna część to pozyskiwanie i przetwarzanie danych treningowych. Historycznie firmy AI pobierały te dane za darmo, jednak CEO Stack Overflow, Prashanth Chandrasekar, ogłosił w 2023 roku, że platforma zacznie pobierać opłaty od dużych deweloperów AI za dostęp do treści, uznając, że wiedza generowana przez społeczność powinna być wynagradzana. Ta zmiana odzwierciedla szerszy trend rynkowy, w którym platformy posiadające wartościowe dane domagają się uczciwego wynagrodzenia od firm czerpiących zyski z ich treści.
Atrybucja i licencjonowanie Creative Commons
Treści Stack Overflow są objęte licencją Creative Commons Attribution-ShareAlike 4.0 (CC BY-SA), która prawnie wymaga od każdego korzystającego z treści, by podał atrybucję oryginalnym autorom. Ten model licencjonowania jest niepodważalny dla Stack Overflow, ponieważ platforma uważa, że atrybucja jest fundamentem zaufania deweloperów do treści generowanych przez AI. Gdy firmy AI trenują modele na danych Stack Overflow bez należytej atrybucji, technicznie naruszają licencję Creative Commons, dlatego Stack Overflow wymaga obecnie od wszystkich partnerów API zawarcia wymogu atrybucji w umowach. Waga tego działania jest ogromna: według Stack Overflow Developer Survey 2024, 65% deweloperów wymienia brak lub błędną atrybucję jako najważniejszy problem etyczny związany z narzędziami AI.
Aspekt
Wymaganie
Wpływ
Typ licencji
CC BY-SA 4.0
Atrybucja obowiązkowa
Zaufanie deweloperów
72% pozytywnie
Kluczowe dla adopcji
Zgodność AI
Implementacja RAG
Zapewnia właściwe źródła
Wskaźnik cytowania
65% zaniepokojonych
Najwyższy problem etyczny
Własność treści
Zachowana przez użytkownika
Ochrona społeczności
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Podejście Stack Overflow do licencjonowania AI rozróżnia przypadki darmowe i komercyjne. Platforma nadal oferuje darmowy dostęp do API i zrzutów danych do celów niekomercyjnych, edukacyjnych oraz projektów open-source, podtrzymując swoje zobowiązanie wobec społeczności deweloperów. Jednak firmy rozwijające duże modele językowe w celach komercyjnych muszą negocjować umowy licencyjne ze Stack Overflow, a ceny zależą od takich czynników jak skala modelu, wolumen użycia i wygenerowane przychody. CEO Stack Overflow, Chandrasekar, podkreślił, że firma oczekuje wynagrodzenia wyłącznie od organizacji rozwijających LLM-y do „dużych, komercyjnych celów”, a nie od pojedynczych deweloperów czy małych projektów. Ten model podwójnego licencjonowania pozwala Stack Overflow generować nowe źródła przychodów, jednocześnie chroniąc interesy członków społeczności, z których wielu tworzy treści bez oczekiwania bezpośredniego wynagrodzenia. Firma zobowiązała się także do reinwestowania dochodów z licencji w narzędzia i funkcje dla społeczności, tworząc zrównoważony model, w którym wkład deweloperów bezpośrednio finansuje rozwój platformy.
Widoczność dewelopera w wynikach AI
Treści Stack Overflow pojawiają się obecnie na czołowych miejscach w odpowiedziach generowanych przez AI na głównych platformach, takich jak ChatGPT, Google Gemini, Perplexity czy Microsoft Copilot. Gemini Cloud Assist od Google jawnie przypisuje odpowiedzi Stack Overflow, wyświetlając oryginalne pytanie, odpowiedź oraz informacje o autorze bezpośrednio w odpowiedzi AI. ChatGPT od OpenAI udostępnia linki do Stack Overflow w rozmowach o tematach programistycznych, a SearchGPT — prototyp wyszukiwarki OpenAI — uwzględnia wyniki Stack Overflow zarówno w odpowiedziach konwersacyjnych, jak i w listingu wyników wyszukiwania. Ta widoczność jest kluczowa dla deweloperów, ponieważ kieruje ruch do ich odpowiedzi i buduje ich pozycję jako ekspertów w danej dziedzinie. Jednak nie wszystkie platformy AI zapewniają równą atrybucję, a deweloperzy często mają trudność ze zrozumieniem, które ich odpowiedzi są cytowane, jak często i w jakim kontekście przez różne systemy AI.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Kryzys zaufania do treści generowanych przez AI
Stack Overflow Developer Survey 2024 pokazuje rosnącą przepaść między adopcją AI a zaufaniem do tych narzędzi: choć 76% deweloperów korzysta lub planuje korzystać z narzędzi AI (wzrost z 70% w 2023), ocena przychylności wobec AI spadła z 77% do 72%. Tylko 43% deweloperów ufa dokładności narzędzi AI, a ankieta wskazała trzy kluczowe kwestie etyczne, które deweloperzy uznają za najważniejsze:
Ryzyko dezinformacji: 79% deweloperów obawia się, że AI może szerzyć dezinformację
Atrybucja i uznanie: 65% martwi się o brak lub niepoprawną atrybucję źródeł danych
Stronniczość i reprezentacja: 50% niepokoi się stronniczością, która nie odzwierciedla różnorodnych punktów widzenia
Ten deficyt zaufania wpływa bezpośrednio na to, jak firmy AI podchodzą do pozyskiwania danych i treningu modeli. Deweloperzy coraz częściej oczekują, że systemy AI będą cytować źródła, uznawać wkład społeczności i utrzymywać standardy dokładności, które odpowiadają recenzowanemu charakterowi treści Stack Overflow. Presja na budowę godnych zaufania systemów AI powoduje pilną potrzebę pozyskiwania wysokiej jakości danych treningowych, przez co zweryfikowana, kuratorowana przez społeczność wiedza Stack Overflow jest dziś cenniejsza niż kiedykolwiek.
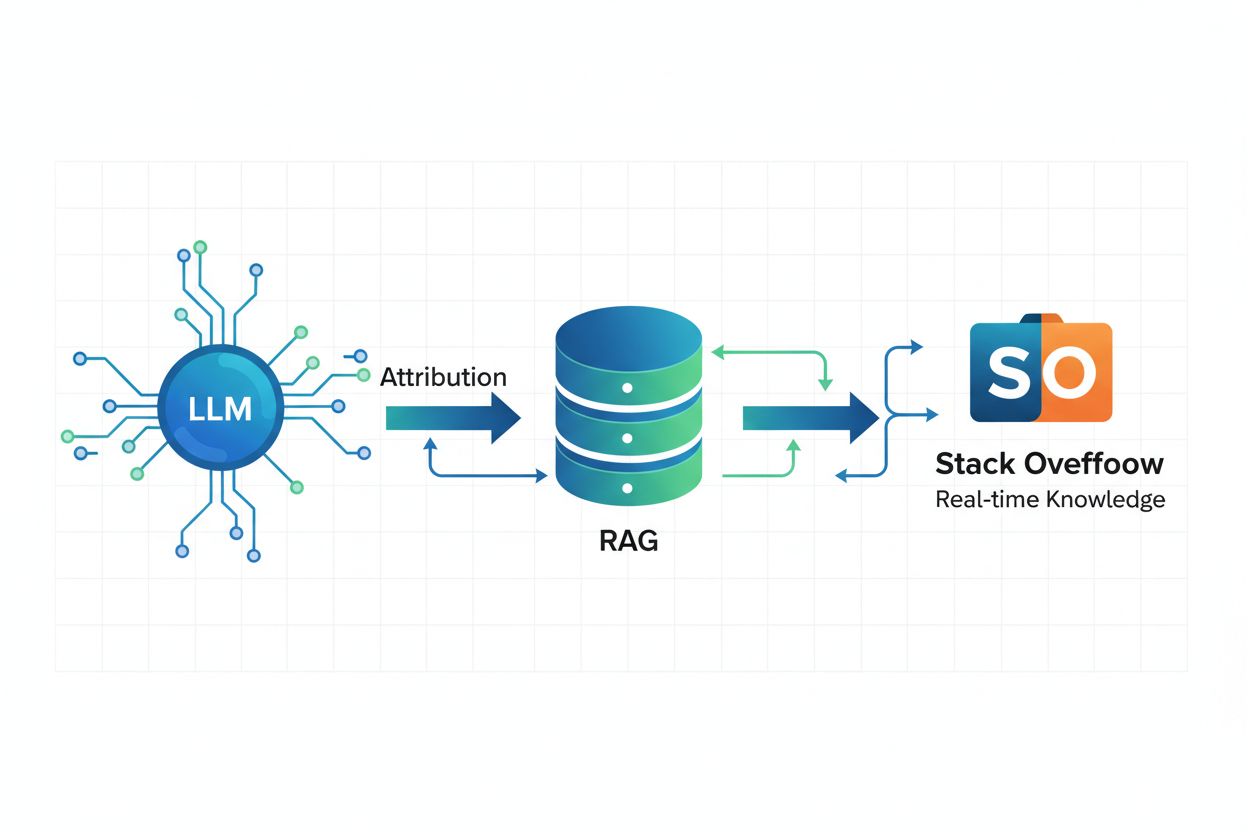
Retrieval Augmented Generation (RAG) i atrybucja
Retrieval Augmented Generation (RAG) to framework AI, który łączy duże modele językowe z tradycyjnymi systemami wyszukiwania informacji, by dostarczać aktualne, dokładne i odpowiednio przypisane odpowiedzi. Zamiast polegać wyłącznie na danych treningowych zamrożonych w czasie, RAG pozwala systemom AI pobierać w czasie rzeczywistym informacje z zewnętrznych źródeł, takich jak Stack Overflow, dzięki czemu odpowiedzi odzwierciedlają najnowszą wiedzę i praktyki. Wszyscy partnerzy OverflowAPI wdrożyli RAG, aby umożliwić właściwą atrybucję — oznacza to, że gdy system AI generuje odpowiedź z użyciem treści Stack Overflow, może zidentyfikować i zacytować konkretne posty, które wpłynęły na odpowiedź. Technologia ta jest szczególnie cenna w wiedzy dziedzinowej, gdzie liczy się aktualność i precyzja — np. polecenie systemowi AI napisania kodu C# na podstawie konkretnych przykładów z twojej bazy kodu pozwala generować kod zgodny z konwencjami i standardami twojego zespołu. RAG ogranicza ryzyko halucynacji, opierając odpowiedzi AI na zaufanych, zweryfikowanych faktach, które użytkownicy jasno identyfikują, i stanowi techniczną podstawę odpowiedzialnego rozwoju AI.
Monitorowanie swojej widoczności deweloperskiej
Deweloperzy, którzy udzielają się na Stack Overflow, powinni aktywnie monitorować, jak ich treści pojawiają się w odpowiedziach generowanych przez AI na różnych platformach. Narzędzia takie jak AmICited.com, XFunnel, Profound i inne oferują obecnie śledzenie widoczności zaprojektowane specjalnie po to, by pokazać, gdzie odpowiedzi danego dewelopera są cytowane, jak często i w jakim kontekście w ChatGPT, Gemini, Perplexity i innych systemach AI. Kluczowe metryki do śledzenia to częstotliwość cytowań (jak często twoje treści są przywoływane), sentyment (czy wzmianki są pozytywne lub neutralne), rozkład na platformach (które systemy AI cytują cię najczęściej) oraz atrybucja źródła (czy zapewniono właściwe uznanie). Monitorowanie tych wskaźników pozwala deweloperom zidentyfikować, które odpowiedzi wnoszą największą wartość do systemów AI, poznać najbardziej poszukiwane tematy i odpowiednio dostosować strategię publikacji. Dodatkowo, śledzenie widoczności pomaga wychwycić nieprecyzyjne lub niepełne cytowania, umożliwiając aktualizację oryginalnych odpowiedzi lub kontakt z firmami AI w celu zgłoszenia poprawek. Takie proaktywne podejście przekształca pasywne współtworzenie treści w aktywną strategię budowania autorytetu i wpływu w ekosystemie informacji napędzanym przez AI.
Najlepsze praktyki budowania obecności społecznościowej
Aby zmaksymalizować widoczność w wynikach AI i zapewnić poprawne cytowanie swoich odpowiedzi ze Stack Overflow, skup się na tworzeniu wyczerpujących, dobrze udokumentowanych odpowiedzi, które w pełni rozwiązują pytanie, zawierają jasne wyjaśnienia i działające przykłady kodu. Regularnie aktualizuj odpowiedzi, gdy technologie się zmieniają, ponieważ systemy AI preferują nowsze treści — średnio treści cytowane przez AI są o 25,7% świeższe niż te, które zajmują wysokie pozycje w Google. Buduj autorytet, konsekwentnie udzielając wysokiej jakości odpowiedzi w wielu powiązanych tematach — deweloperzy z górnych 25% pod względem liczby wzmianek w sieci mają 10x więcej cytowań w AI niż inni. Angażuj się w szerszy ekosystem deweloperski, biorąc udział w dyskusjach, odpowiadając na pytania uzupełniające i pomagając innym członkom społeczności poprawiać ich wkład. Wreszcie, rozważ, jak twoje odpowiedzi mogą być wykorzystywane przez systemy AI: strukturyzuj odpowiedzi z jasnymi nagłówkami, dodawaj odpowiednie fragmenty kodu i opisuj, kiedy oraz dlaczego dane podejście jest właściwe, dzięki czemu twoje treści są użyteczne zarówno dla ludzi, jak i dla systemów AI, które muszą wyodrębniać i poprawnie przypisywać informacje.
Najczęściej zadawane pytania
Jak dane ze Stack Overflow są wykorzystywane w treningu AI?
50 milionów pytań i odpowiedzi ze Stack Overflow jest włączanych do dużych modeli językowych, ponieważ reprezentują wysokiej jakości, recenzowane treści techniczne. Firmy AI, takie jak OpenAI, Google i Meta, używają tych danych do trenowania swoich modeli, aby lepiej rozumieć i generować kod oraz rozwiązania techniczne. Historycznie te dane były pozyskiwane za darmo, ale Stack Overflow obecnie wymaga od komercyjnych deweloperów AI licencjonowania danych w ramach płatnych umów.
Jaka jest różnica między darmowym a płatnym dostępem do API Stack Overflow?
Stack Overflow oferuje darmowy dostęp do API do celów niekomercyjnych, edukacyjnych i projektów open-source. Jednak firmy rozwijające duże modele językowe w celach komercyjnych muszą negocjować płatne umowy licencyjne. Ceny zależą od takich czynników jak skala modelu, wolumen użycia i wygenerowane przychody, zapewniając odpowiednie wynagrodzenie za wkład społeczności.
Jak mogę zadbać o to, żeby moje odpowiedzi ze Stack Overflow były cytowane przez AI?
Twórz wyczerpujące, dobrze udokumentowane odpowiedzi z jasnymi wyjaśnieniami i działającymi przykładami kodu. Aktualizuj swoje odpowiedzi wraz z rozwojem technologii, ponieważ systemy AI preferują nowsze treści. Buduj autorytet, regularnie udzielając wysokiej jakości odpowiedzi w różnych tematach, a swoje odpowiedzi strukturyzuj z jasnymi nagłówkami i odpowiednimi fragmentami kodu, które systemy AI mogą łatwo wyodrębnić i przypisać autorstwo.
Czym jest RAG i dlaczego jest ważny dla atrybucji?
Retrieval Augmented Generation (RAG) to framework AI łączący modele językowe z systemami wyszukiwania informacji, aby zapewnić aktualne, dokładne i odpowiednio przypisane odpowiedzi. RAG pozwala systemom AI pobierać w czasie rzeczywistym informacje ze źródeł takich jak Stack Overflow i cytować konkretne posty, które wpłynęły na odpowiedź, zapewniając właściwą atrybucję i zmniejszając ryzyko halucynacji.
Jak monitorować swoją widoczność w wynikach wyszukiwania AI?
Narzędzia takie jak AmICited.com, XFunnel, Profound i inne oferują śledzenie widoczności zaprojektowane specjalnie po to, aby pokazać deweloperom, gdzie ich odpowiedzi są cytowane w ChatGPT, Gemini, Perplexity i innych systemach AI. Narzędzia te śledzą częstotliwość cytowań, sentyment, rozkład na platformach i atrybucję źródła, pomagając zrozumieć, które z odpowiedzi mają największą wartość dla systemów AI.
Jakie są kwestie etyczne związane z wykorzystaniem treści społeczności przez AI?
Według Stack Overflow Developer Survey 2024 deweloperzy mają trzy główne obawy etyczne: ryzyko dezinformacji (79% zaniepokojonych), brak lub niepoprawna atrybucja (65% zaniepokojonych) oraz stronniczość nieuwzględniająca różnorodnych punktów widzenia (50% zaniepokojonych). To powoduje potrzebę właściwego licencjonowania, wymogów atrybucji i wysokiej jakości danych treningowych ze zweryfikowanych źródeł, takich jak Stack Overflow.
Jak licencjonowanie Stack Overflow chroni deweloperów?
Treści Stack Overflow są objęte licencją Creative Commons Attribution-ShareAlike 4.0 (CC BY-SA), która prawnie wymaga podania atrybucji autorom oryginalnych treści. Stack Overflow obecnie wymaga od wszystkich partnerów API zawarcia wymogów atrybucji w umowach, aby deweloperzy otrzymywali należne uznanie, gdy ich odpowiedzi są wykorzystywane przez systemy AI.
Jakie narzędzia mogę wykorzystać do śledzenia cytowań AI moich treści?
Dostępnych jest kilka narzędzi do śledzenia cytowań przez AI, w tym AmICited.com (specjalizujący się w monitoringu AI), XFunnel (monitoring LLM dla firm), Profound (zaawansowane śledzenie GEO), Semrush AI Toolkit, BrightEdge i inne. Pomagają one śledzić, które platformy AI cytują Twoje treści, jak często, w jakim kontekście i czy zapewniana jest właściwa atrybucja.
Monitoruj swoją widoczność Stack Overflow w wyszukiwaniu AI
Śledź, jak Twoja wiedza techniczna jest cytowana w ChatGPT, Gemini, Perplexity i innych platformach AI. Uzyskaj wgląd w czasie rzeczywistym w swoją widoczność deweloperską i zoptymalizuj swoją obecność w społeczności.
Czy ktoś jeszcze martwi się o prawa do treści w kontekście AI? Krajobraz prawny robi się dziki
Dyskusja społecznościowa o prawach do treści w AI, obejmująca kwestie praw autorskich, ramy licencyjne, debaty na temat dozwolonego użytku oraz strategie ochron...
Dlaczego ChatGPT kocha Reddita: Zrozumienie preferencji źródeł
Dowiedz się, dlaczego Reddit dominuje w cytowaniach ChatGPT z udziałem 40,1% wszystkich odpowiedzi AI. Poznaj, jak działają preferencje źródeł AI i co to oznacz...
Czy naprawdę możesz wpływać na to, czego AI uczy się o Twojej marce podczas treningu? Czy to w ogóle możliwe?
Dyskusja społecznościowa o wpływaniu na dane treningowe AI dotyczące Twojej marki. Rzetelne spostrzeżenia na temat tego, jak tworzenie treści wpływa na to, czeg...
6 min czytania
Discussion
AI Training
+1
Zgoda na Pliki Cookie Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.