
PR oparty na danych: Tworzenie badań, które AI chce cytować
Dowiedz się, jak tworzyć oryginalne badania i treści PR oparte na danych, które systemy AI aktywnie cytują. Odkryj 5 cech treści wartych cytowania oraz strategi...
8 min czytania

Dowiedz się, jak dane z własnych ankiet i oryginalne statystyki stają się magnesem cytowań dla LLM. Poznaj strategie zwiększania widoczności AI i zdobywania większej liczby cytowań od ChatGPT, Perplexity i Google AI Overviews.
Duże modele językowe nie wymyślają danych — czerpią je z weryfikowalnych źródeł. Gdy Twój zespół publikuje unikalne statystyki lub autorskie metodologie, tymczasowo posiadasz tę wiedzę, dając LLM powód, by cytowały Cię jako potwierdzenie swoich odpowiedzi. To podstawa tego, co IDX nazywa „Kołem Autorytetu” — systemu, w którym własne badania stają się najpotężniejszym magnesem cytowań.
Mechanizm jest prosty: modele AI oceniają źródła, sprawdzając, czy mogą zweryfikować tezy przez różne kanały. Publikując oryginalne badania, tworzysz zasób wiedzy, którego nie ma nigdzie indziej w sieci. Ta unikalność zmusza LLM do cytowania Twojego źródła, jeśli chcą uwzględnić te dane w odpowiedziach. Kampania dla The Zebra, platformy ubezpieczeniowej, doskonale ilustruje tę zasadę — połączenie własnych badań z Digital PR przyniosło ponad 1580 wysokiej jakości linków medialnych oraz wzrost ruchu organicznego o 354%.
Według najnowszych badań, 48,6% ekspertów SEO wskazało Digital PR jako najskuteczniejszą taktykę budowy linków na 2025 rok. Ale prawdziwa siła tkwi w tym, co dzieje się później: gdy Twoje dane własne są dystrybuowane w różnych, prestiżowych domenach przez Digital PR, potwierdza to Twój autorytet w wielu sieciach wiedzy jednocześnie. Taka wielokanałowa weryfikacja jest dokładnie tym, czego szukają LLM, decydując, czy cytować Twoją markę.
Kluczowy wniosek: dane własne tworzą, jak określają to badacze, „tymczasowe posiadanie wiedzy”. W przeciwieństwie do ogólnych treści konkurujących z tysiącami podobnych artykułów, Twoje oryginalne badania są jedynym źródłem tych danych. Ta zasada niedoboru sprawia, że LLM chętniej Cię cytują, bo tylko tak mogą umieścić te informacje w swoich odpowiedziach.
Zrozumienie, jak LLM faktycznie pobierają i wybierają źródła, jest kluczowe dla optymalizacji pod kątem cytowań. Systemy te nie działają jak tradycyjne wyszukiwarki. Zamiast tego korzystają z dwóch ścieżek wiedzy: pamięci parametrycznej (wiedza zapisana podczas treningu) oraz wiedzy pobieranej (informacje w czasie rzeczywistym przez Retrieval-Augmented Generation, czyli RAG).
Pamięć parametryczna to wszystko, co LLM „wie” z treningu. Ta wiedza jest statyczna, ustalona na moment zakończenia treningu modelu. Około 60% zapytań w ChatGPT jest obsługiwanych wyłącznie na podstawie wiedzy parametrycznej, bez przeszukiwania sieci. Jednostki często pojawiające się w autorytatywnych źródłach w trakcie treningu mają silniejsze reprezentacje w sieci neuronowej, przez co są częściej przywoływane. Treści z Wikipedii stanowią około 22% głównych danych treningowych LLM, co tłumaczy, dlaczego cytowania Wikipedii są tak częste w odpowiedziach AI.
Wiedza pobierana działa inaczej. Gdy LLM potrzebuje aktualnych informacji, korzysta z systemów RAG, łączących wyszukiwanie semantyczne (wektory gęste) z dopasowaniem słów kluczowych (BM25) przy użyciu Reciprocal Rank Fusion. Badania pokazują, że hybrydowe wyszukiwanie daje 48% lepsze wyniki niż pojedyncze metody. System następnie sortuje wyniki modelem cross-encoder, po czym wstrzykuje 5-10 najlepszych fragmentów do prompta LLM jako kontekst.
| Sygnał | Priorytet w tradycyjnym SEO | Priorytet cytowań LLM | Dlaczego to ważne |
|---|---|---|---|
| Autorytet domeny | Wysoki (główny czynnik rankujący) | Słaby/Neutralny | LLM bardziej cenią strukturę treści niż siłę domeny |
| Liczba linków zwrotnych | Wysoki (podstawowy sygnał) | Słaby/Neutralny | LLM inaczej oceniają wiarygodność źródła |
| Struktura treści | Średni | Krytyczny | Jasne nagłówki i bloki odpowiedzi są niezbędne do ekstrakcji |
| Dane własne | Niski | Bardzo wysoki | Unikalna informacja wymusza cytowanie |
| Wolumen wyszukiwań marki | Niski | Najwyższy (korelacja 0,334) | Oznacza autorytet i popyt w rzeczywistości |
| Aktualność | Średni | Wysoki | LLM preferują najnowsze treści |
| Sygnały E-E-A-T | Średni | Wysoki | Ważne są dane o autorach i przejrzystość |
Kluczowa różnica: LLM nie rankują stron — wyciągają fragmenty semantyczne. Strona z kiepskimi metrykami SEO, ale doskonałą strukturą i danymi własnymi, może przewyższyć stronę o wysokim autorytecie, ale niejasnej treści. Ta zmiana oznacza, że strategia cytowań powinna przedkładać czytelność maszynową i klarowność treści nad tradycyjne metryki linkowania.
Metryki istotne dla widoczności AI fundamentalnie zmieniły się względem tradycyjnych sygnałów SEO. Przez dwie dekady sukces definiowały autorytet domeny, linki zwrotne i pozycje na słowa kluczowe. W 2025 roku te metryki stają się niemal nieistotne dla cytowań LLM. Zamiast tego pojawiła się nowa hierarchia, bazująca na rzeczywistym sposobie oceny i wyboru źródeł przez AI.
Wolumen wyszukiwań marki to obecnie najsilniejszy predyktor cytowań LLM, z współczynnikiem korelacji 0,334 — znacznie wyższym niż jakakolwiek tradycyjna metryka SEO. To logiczne: jeśli miliony ludzi szukają Twojej marki, sygnalizuje to realny autorytet i popyt. LLM rozpoznają ten sygnał i silnie go ważą, decydując, czy Cię cytować. Tymczasem linki zwrotne wykazują słabą lub neutralną korelację z cytowaniami AI, co przeczy dekadom wiedzy SEO.
Zmiana dotyczy także oceny treści. Dodanie statystyk do treści zwiększa widoczność w AI o 22%. Cytaty podnoszą widoczność o 37%. Oryginalne badania są cytowane 3x częściej niż treści ogólne. To nie są marginalne ulepszenia — to fundamentalna zmiana w ocenie jakości źródła przez LLM.
| Metryka | Stary priorytet (przed 2024) | Nowy priorytet (2025+) | Wpływ na cytowania LLM |
|---|---|---|---|
| Wskaźnik jakości linków | Wynik autorytetu domeny (DA/DR) | Trafność tematyczna i kontekst redakcyjny | Ugruntowanie i różnorodność źródeł |
| Strategia anchor text | Dokładne słowa kluczowe | Wzmianki brandowe/nazwy podmiotów | Rozpoznawalność i spójność podmiotu |
| Typ treści | Gościnne wpisy (ilość) | Oryginalne badania/data journalism | 3x większe prawdopodobieństwo cytowania |
| Pomiar efektów | Wzrost pozycji | Wskaźnik cytowań w AI Overviews | Weryfikacja zaufania i autorytetu |
| Podejście outreach | Pozyskiwanie linków | Budowanie relacji/dostarczanie wartości | Wyższa jakość redakcyjna |
Macierz pokazuje ważny wniosek: marki wygrywające w widoczności AI nie zawsze mają najwięcej linków i najwyższy autorytet domeny. To marki tworzące oryginalne badania, utrzymujące spójne sygnały brandowe i publikujące treści z myślą o ekstrakcji przez maszyny. Przewaga konkurencyjna przesunęła się z ilości linków na jakość i unikalność treści.
Własne dane z ankiet mają unikalną rolę w strategii widoczności AI. W przeciwieństwie do ogólnych raportów branżowych, które LLM mogą znaleźć w wielu źródłach, Twoje oryginalne dane ankietowe mogą być cytowane wyłącznie z Twojej strony. To daje przewagę cytowań, której konkurenci nie mogą powielić — bez względu na ich profil linkowy.
Dane z ankiet sprawdzają się, bo dostarczają LLM tzw. „groundingu” — weryfikowalnego dowodu potwierdzającego tezę. Jeśli stwierdzasz, że „78% liderów marketingu stawia na widoczność AI”, LLM mogą przytoczyć Twoją ankietę jako dowód. Bez tych danych własnych taka teza byłaby spekulacją i LLM albo by ją pominęły, albo zacytowały badania konkurencji.
Najskuteczniejsze dane z ankiet odpowiadają na konkretne pytania Twojej grupy odbiorców:
Efekt jest mierzalny. Badania pokazują, że dodanie statystyk zwiększa widoczność w AI o 22%, a cytaty — o 37%. Oryginalne badania są cytowane 3x częściej niż treści ogólne. Te efekty się kumulują, jeśli łączysz różne typy danych własnych w jednym zasobie treści.
Kluczowa jest przejrzystość. LLM oceniają metodologię równie uważnie jak wyniki. Jeśli metodologia ankiety jest poprawna, próba odpowiednia, a wyniki przedstawione uczciwie (wraz z ograniczeniami), LLM będą cytować Cię z pewnością. Jeśli metodologia jest niejasna lub wyniki są wyselekcjonowane pod tezę, LLM zdecydują się na bardziej przejrzyste źródło.
Publikacja danych własnych to tylko połowa sukcesu. Druga połowa to ich odpowiednie ustrukturyzowanie, by LLM mogły je łatwo wyodrębnić i zacytować. Architektura treści jest równie ważna co same dane.
Zacznij od bezpośrednich odpowiedzi. LLM preferują treści, w których odpowiedź jest na początku, a nie na końcu rozważań. Zamiast „Przeprowadziliśmy ankietę, aby poznać priorytety marketingu, oto wyniki”, napisz: „78% liderów marketingu stawia na widoczność AI w strategii 2025”. Taka struktura ułatwia ekstrakcję i zwiększa szansę na cytowanie.
Optymalna długość akapitu dla LLM to 40-60 słów. Taka objętość pozwala AI wyciągnąć całą myśl bez obcinania kontekstu. Dłuższe akapity są dzielone i mogą stracić sens, krótsze mogą nie zawierać wystarczająco danych.
Format treści ma duże znaczenie. Porównawcze listy (listicles) otrzymują 32,5% wszystkich cytowań AI — to najwięcej spośród formatów. Sekcje FAQ sprawdzają się świetnie, bo odpowiadają sposobowi zadawania pytań przez użytkowników AI. Przewodniki „jak to zrobić”, case studies i raporty badawcze również wypadają dobrze, ale listy wygrywają z innymi formatami.
Strukturyzuj treść z jasną hierarchią nagłówków. Stosuj nagłówki H2 odpowiadające możliwym zapytaniom. Pod każdym H2 używaj H3 dla podtematów. Taka hierarchia pomaga LLM zrozumieć strukturę i wyodrębnić odpowiednie sekcje.
Wdrażaj sygnały E-E-A-T w całej treści. Dodawaj biogramy autorów z kompetencjami i doświadczeniem. Linkuj do zewnętrznych potwierdzeń tez. Bądź transparentny w metodologii. Cytuj źródła. To sygnały dla LLM, że Twoje treści są godne zaufania i cytowania.

Używaj semantycznego HTML. Strukturyzuj dane za pomocą właściwych tagów <table>, <ul> i <ol>, a nie stylizowanych divów. Dzięki temu AI łatwiej analizuje treść i tworzy podsumowania. Dodaj znaczniki schema (Article, FAQPage, HowTo), by dostarczyć kontekst o typie treści.
Regularnie aktualizuj treści. LLM preferują świeże dane, szczególnie w wypadku tematów czasowych. Jeśli Twoja ankieta pochodzi z 2024 roku, zaktualizuj ją w 2025. Dodaj informację o ostatniej aktualizacji, by pokazać, że dbasz o aktualność. To sygnał dla LLM, że dane są nadal aktualne i wiarygodne.
Publikacja danych własnych na stronie to konieczność, ale niewystarczająca. LLM odkrywają treści przez wiele kanałów, a Twoja strategia dystrybucji decyduje, ile z nich je przejmie.
Digital PR to najskuteczniejszy kanał dystrybucji danych własnych. Gdy Twoje badania pojawiają się w branżowych mediach, portalach informacyjnych i autorytatywnych blogach, generuje to liczne okazje do cytowań. LLM indeksują te wzmianki i używają ich do potwierdzenia źródła. Marka pojawiająca się na 4+ platformach ma 2,8x większą szansę na cytowanie w odpowiedziach ChatGPT niż marki obecne w jednym miejscu.
Skuteczne kanały dystrybucji to:
Każdy kanał ma swoją rolę. Informacje prasowe budują świadomość i zdobywają zasięg medialny. Publikacje branżowe zapewniają wiarygodność i docierają do decydentów. LinkedIn daje skalę wśród profesjonalistów. Reddit pokazuje zaufanie społeczności. Platformy recenzji dostarczają danych strukturalnych łatwych do przetwarzania przez LLM.
Efekt multiplikacji jest znaczący. Gdy Twoje dane własne pojawiają się w wielu autorytatywnych źródłach, LLM widzą spójne sygnały w sieci. To zwiększa zaufanie i prawdopodobieństwo cytowania. Pojedyncza wzmianka na stronie może zostać pominięta. Te same dane obecne na stronie, w informacji prasowej, branżowym medium i na platformie recenzji są nie do przeoczenia.
Znaczenie ma także timing. Dystrybuuj dane strategicznie: najpierw na stronie i w informacji prasowej, potem w publikacjach branżowych, następnie przez social media i społeczności. Takie stopniowanie daje falę widoczności, a nie jednorazowy pik.
Publikowanie danych własnych bez mierzenia efektu to jak reklama bez śledzenia konwersji. Potrzebujesz wglądu, czy rzeczywiście zdobywasz cytowania i poprawiasz widoczność w AI.
Zacznij od śledzenia częstotliwości cytowań. Wskaż 20-50 najważniejszych pytań kupujących, na które Twoje dane odpowiadają. Co miesiąc zadawaj je na głównych platformach AI (ChatGPT, Perplexity, Claude, Google AI Overviews) i dokumentuj, czy marka się pojawia, na jakiej pozycji i czy cytat zawiera link do Twojej strony.
Policz częstotliwość cytowania jako procent: (Liczba promptów z Twoją wzmianką) / (Liczba wszystkich promptów) × 100. Celuj w 30%+ cytowań dla kluczowych zapytań. W topowych branżach najlepsze marki mają 50%+ cytowań.
Śledź AI Share of Voice (AI SOV) — uruchom identyczne prompty i policz procent udziału marki w cytacjach. Jeśli jesteś w 3 z 10 odpowiedzi AI, a konkurenci w 2, Twój AI SOV to 30%. W konkurencyjnych segmentach dąż do AI SOV o 10-20% wyższego niż udział w rynku tradycyjnym.
Monitoruj analizę sentymentu. Liczy się nie tylko liczba cytowań, ale czy AI mówi o Tobie pozytywnie, neutralnie czy negatywnie. Użyj narzędzi jak Profound AI do wykrywania halucynacji AI (fałszywych lub nieaktualnych informacji). Celuj w 70%+ pozytywnego sentymentu na platformach AI.
Stwórz dashboard Knowledge-Based Indicator (KBI), śledzący:
Aktualizuj te metryki co miesiąc. Szukaj trendów, nie pojedynczych wartości. Jeden słabszy miesiąc to szum. Trzy miesiące spadków oznaczają problem wymagający działania.
Ręczne śledzenie cytowań danych własnych jest czasochłonne i podatne na błędy. AmICited.com zapewnia infrastrukturę do masowego monitorowania widoczności AI, zaprojektowaną dla marek wykorzystujących dane własne jako strategię cytowań.
Platforma monitoruje, jak systemy AI cytują Twoje badania w ChatGPT, Perplexity, Google AI Overviews, Claude, Gemini i kolejnych platformach. Zamiast ręcznie sprawdzać każdą z nich co miesiąc, AmICited automatyzuje proces, uruchamiając prompty i śledząc cytowania w czasie rzeczywistym.
Najważniejsze funkcje:
Platforma łączy się z Twoimi narzędziami analitycznymi, przekazując dane o cytowaniach AI do dashboardów marketingowych razem z tradycyjnymi metrykami SEO. Ten zintegrowany widok pozwala lepiej zrozumieć realny wpływ strategii danych własnych na widoczność marki i generowanie leadów.
Dla marek poważnie podchodzących do widoczności AI, AmICited dostarcza infrastrukturę pomiarową umożliwiającą optymalizację. Nie możesz poprawić tego, czego nie mierzysz, a tradycyjne narzędzia nie śledzą cytowań LLM. AmICited wypełnia tę lukę, dając pełny wgląd i maksymalizując ROI z danych własnych.
Nawet dobrze zaplanowane strategie danych własnych często zawodzą przez proste błędy. Warto je znać, by ich unikać.
Najczęstszy błąd to ukrywanie danych za formularzami „Kontakt z działem sprzedaży”. LLM nie mają dostępu do treści za barierą, więc korzystają z niepełnych lub spekulacyjnych informacji z forów. Jeśli wyniki ankiety są ukryte, LLM zacytuje dyskusję na Reddit, nie Twoje oficjalne badania. Publikuj kluczowe wyniki publicznie wraz z przejrzystą metodologią. Szczegółowe raporty możesz blokować, ale podsumowania i kluczowe wnioski powinny być dostępne.
Niespójna terminologia na platformach wprowadza zamieszanie. Jeśli na stronie nazywasz produkt „platformą marketing automation”, a na LinkedIn „oprogramowaniem CRM”, LLM mają trudności z budową spójnego obrazu Twojej firmy. Stosuj jednolity język kategorii wszędzie. Zdefiniuj mapę terminologiczną i używaj jej konsekwentnie na stronie, LinkedIn, Crunchbase i innych platformach.
Brak informacji o autorach podważa zaufanie. LLM uważnie oceniają sygnały E-E-A-T. Jeśli ankieta nie ma biogramów autorów z kompetencjami, zostanie zdegradowana. Dodawaj szczegółowe bio z doświadczeniem, certyfikatami i publikacjami. Linkuj do profili autorów na LinkedIn i innych platformach.
Nieaktualne statystyki szkodzą wiarygodności. Jeśli cytujesz ankietę z 2023 roku w 2025, LLM to zauważą. Regularnie aktualizuj badania. Dodawaj daty ostatniej aktualizacji. Przeprowadzaj nowe ankiety co roku, by utrzymać świeżość. LLM preferują aktualne dane, szczególnie dla tematów wrażliwych na czas.
Niejasna metodologia zmniejsza szansę na cytowanie. Jeśli nie opiszesz transparentnie metodologii, LLM zakwestionuje wyniki. Publikuj metodologię otwarcie. Wyjaśnij wielkość próby, sposób doboru, okres badania i ograniczenia. Przejrzystość buduje zaufanie.
Przeładowanie słowami kluczowymi w treści danych własnych szkodzi bardziej w AI niż w tradycyjnym SEO. LLM wykrywają i „karzą” sztuczny język. Pisz naturalnie. Stawiaj na jasność i rzetelność, nie gęstość słów kluczowych. Dane własne powinny brzmieć jak autentyczne badania, nie marketing.
Zbyt lakoniczne treści wokół danych własnych są penalizowane. Jeden akapit o wynikach ankiety to za mało. Twórz rozbudowane materiały omawiające wnioski, kontekst i odpowiedzi na dodatkowe pytania. Celuj w 2000+ słów merytorycznej treści wokół każdego kluczowego zasobu danych własnych.
Przykłady z rynku najlepiej pokazują siłę danych własnych dla widoczności AI. Te marki zainwestowały w oryginalne badania i osiągnęły mierzalne efekty.
Sukces Digital PR The Zebra: The Zebra, porównywarka ubezpieczeń, połączyła własne badania z Digital PR i zdobyła ponad 1580 wysokiej jakości linków medialnych oraz wzrost ruchu organicznego o 354%. Publikując oryginalne badania rynku ubezpieczeń i dystrybuując je przez earned media, The Zebra stała się głównym źródłem danych branżowych. LLM cytują obecnie badania The Zebra w odpowiedziach dotyczących trendów i cen ubezpieczeń.
Strategia zaangażowania społeczności Tally: Tally, kreator formularzy online, poprawił widoczność AI, aktywnie udzielając się na forach i dzieląc się roadmapą produktu. Zamiast tylko publikować badania, Tally stał się zaufanym głosem w społecznościach użytkowników. Ta autentyczna aktywność sprawiła, że ChatGPT stał się głównym źródłem ruchu, przynosząc znaczny tygodniowy wzrost rejestracji. Dzięki podparciu GPT-4 wyselekcjonowanymi dowodami, Tally podniósł trafność odpowiedzi z 56% do 89%.
Program badań HubSpot: HubSpot regularnie publikuje raporty dotyczące trendów marketingu, skuteczności sprzedaży i obsługi klienta. Raporty te stały się branżowym standardem często cytowanym przez LLM. Zaangażowanie HubSpot w ciągłe badania sprawiło, że marka jest synonimem danych i insightów marketingowych. LLM, odpowiadając na pytania o trendy marketingowe, niemal zawsze cytują HubSpot.
Wszystkie te przykłady łączą: oryginalne badania, transparentną metodologię, spójną dystrybucję i regularne aktualizacje. Żadna z tych marek nie bazowała na jednym badaniu. Zamiast tego rozwijały programy badawcze, które stale generują
Nie potrzebujesz ogromnych zbiorów danych. Nawet ukierunkowana ankieta na 100-500 respondentach może dostarczyć wartościowych własnych spostrzeżeń, które LLM będą cytować. Kluczowe jest, aby dane były oryginalne, metodologia przejrzysta, a wnioski użyteczne. Jakość i unikalność są ważniejsze niż ilość.
Ankiety satysfakcji klientów, badania trendów branżowych, analiza konkurencji, badania zachowań użytkowników i badania rozmiaru rynku sprawdzają się bardzo dobrze. Najlepsze dane odpowiadają na konkretne pytania zadawane przez Twoją grupę docelową i dostarczają wglądu, którego nie mają konkurenci.
Platformy działające w czasie rzeczywistym, takie jak Perplexity, mogą cytować świeże dane w ciągu kilku tygodni. ChatGPT i inne modele z rzadszymi aktualizacjami potrzebują 2-3 miesięcy. Spójne, wysokiej jakości dane własne zazwyczaj przynoszą mierzalny wzrost cytowań w ciągu 3-6 miesięcy.
Nie. LLM nie mają dostępu do treści za barierą, więc zamiast tego opierają się na niepełnych lub spekulacyjnych informacjach z forów. Publikuj kluczowe wnioski publicznie wraz z przejrzystą metodologią. Szczegółowe raporty możesz zabezpieczać, ale podsumowania i kluczowe spostrzeżenia powinny być publicznie dostępne.
Używaj jasnej, spójnej terminologii na wszystkich platformach. Dołącz przejrzystą metodologię do swoich badań. Dodaj informacje o autorze i certyfikaty. Linkuj do zewnętrznych potwierdzeń. Używaj znaczników schematu do strukturyzowania danych. Co miesiąc monitoruj cytowania i szybko koryguj nieścisłości.
Tak. Oryginalne badania zazwyczaj przyciągają linki zwrotne i są cytowane w mediach, co poprawia tradycyjne pozycje. Dodatkowo, dane własne tworzą treści bardziej kompleksowe i autorytatywne, co pomaga zarówno w SEO, jak i widoczności AI.
Dane własne to oryginalne badania, które wykonujesz samodzielnie. Raporty ogólne są powszechnie dostępne. LLM preferują dane własne, ponieważ są unikalne i mogą być cytowane tylko z Twojego źródła. To daje przewagę cytowań, której konkurencja nie może łatwo podrobić.
Śledź częstotliwość cytowań, AI Share of Voice, wolumen wyszukiwań brandowych oraz ruch z platform AI. Porównaj te metryki przed i po publikacji danych własnych. Oblicz wartość ruchu z AI (zazwyczaj 4,4x wyższy współczynnik konwersji niż tradycyjny ruch organiczny), aby określić ROI.
Monitoruj, jak systemy AI cytują Twoje dane własne w ChatGPT, Perplexity, Google AI Overviews i nie tylko. Uzyskaj wgląd w czasie rzeczywistym w swoją widoczność AI i pozycję konkurencyjną.
Dowiedz się, jak tworzyć oryginalne badania i treści PR oparte na danych, które systemy AI aktywnie cytują. Odkryj 5 cech treści wartych cytowania oraz strategi...
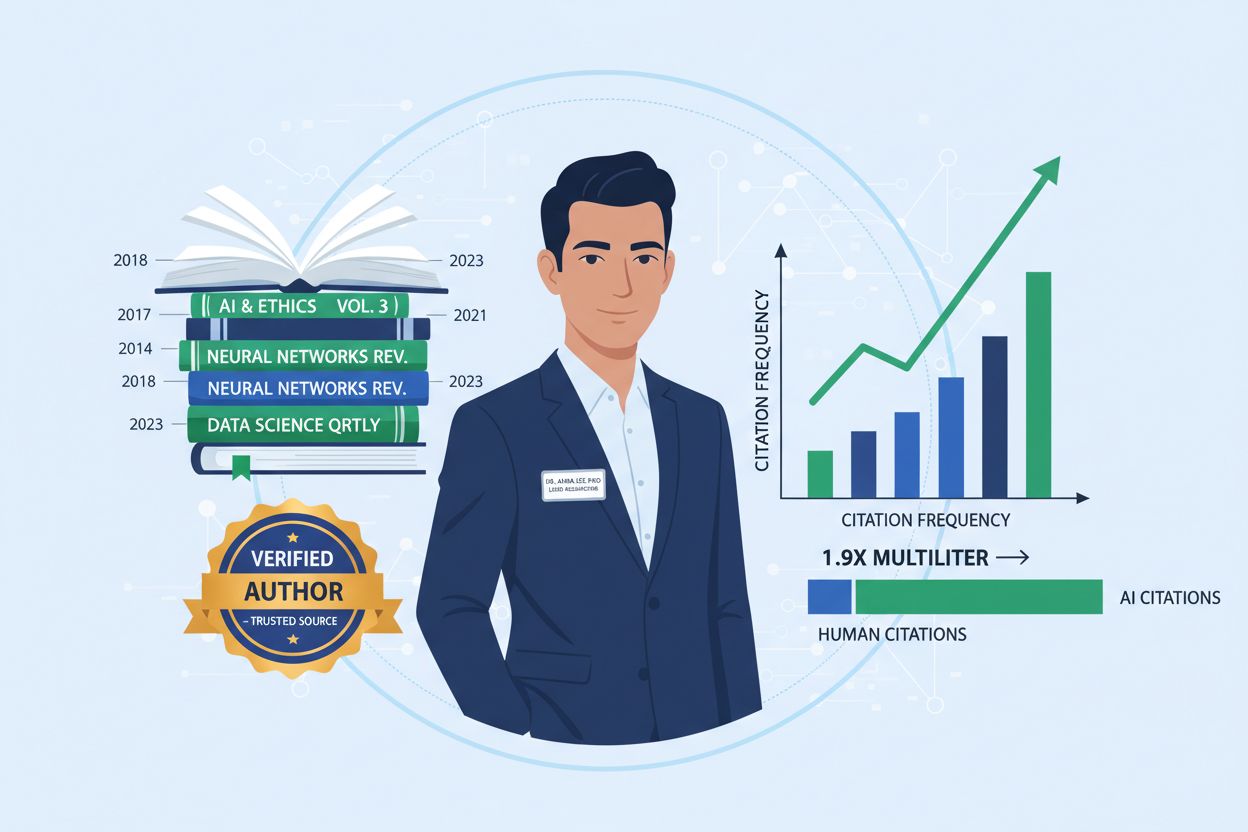
Dowiedz się, jak byline autora wpływają na cytowania przez AI. Sprawdź, dlaczego nazwane autorstwo otrzymuje 1,9x więcej cytowań od ChatGPT i Perplexity oraz ja...

Poznaj sprawdzone strategie budowania autorytetu i zwiększ widoczność swojej marki w odpowiedziach generowanych przez AI, takich jak ChatGPT, Perplexity i inne ...