Maksymalna widoczność w AI dzięki treściom w wielu formatach
Dowiedz się, jak treści w wielu formatach zwiększają widoczność w AI, takich jak ChatGPT, Google AI Overview i Perplexity. Poznaj 5-etapowy framework maksymaliz...
7 min czytania

Dowiedz się, jak testować formaty treści pod kątem cytowań przez AI, wykorzystując metodologię testów A/B. Odkryj, które formaty zapewniają najwyższą widoczność w AI i wskaźniki cytowań w ChatGPT, Google AI Overviews i Perplexity.
Systemy sztucznej inteligencji przetwarzają treści zupełnie inaczej niż ludzie, polegając na uporządkowanych sygnałach do zrozumienia znaczenia i wydobycia informacji. Podczas gdy ludzie są w stanie poruszać się po kreatywnych formatach czy gęstej prozie, modele AI wymagają wyraźnej hierarchii organizacyjnej i znaczników semantycznych, aby skutecznie analizować i pojmować wartość treści. Badania pokazują, że uporządkowane treści z poprawną hierarchią nagłówków osiągają o 156% wyższy wskaźnik cytowań niż alternatywy nieuporządkowane, co ujawnia istotną różnicę między treściami przyjaznymi ludziom a tymi przyjaznymi AI. Ta rozbieżność istnieje, ponieważ systemy AI są trenowane na ogromnych zbiorach danych, gdzie dobrze zorganizowane treści zwykle korelują z autorytatywnymi, wiarygodnymi źródłami. Zrozumienie i testowanie różnych formatów stało się niezbędne dla marek dążących do widoczności w wynikach wyszukiwania i silnikach odpowiedzi napędzanych przez AI.
Różne platformy AI wykazują odmienne preferencje co do źródeł i formatów treści, tworząc skomplikowany krajobraz optymalizacyjny. Badania analizujące 680 milionów cytowań na głównych platformach ujawniają uderzające różnice w tym, jak ChatGPT, Google AI Overviews i Perplexity pozyskują informacje. Te platformy nie cytują po prostu tych samych źródeł — priorytetyzują różne typy treści w zależności od algorytmów i danych treningowych. Zrozumienie tych specyficznych dla platform wzorców jest kluczowe dla opracowania celowanych strategii treści maksymalizujących widoczność w różnych systemach AI.
| Platforma | Najczęściej cytowane źródło | Procent cytowań | Preferowany format |
|---|---|---|---|
| ChatGPT | Wikipedia | 7,8% wszystkich cytowań | Autorytatywne bazy wiedzy, treści encyklopedyczne |
| Google AI Overviews | 2,2% wszystkich cytowań | Dyskusje społecznościowe, treści użytkowników | |
| Perplexity | 6,6% wszystkich cytowań | Informacje peer-to-peer, spostrzeżenia społeczności |
Zdecydowana preferencja ChatGPT dla Wikipedii (47,9% spośród 10 najczęściej cytowanych źródeł) wskazuje na uprzywilejowanie autorytatywnych, faktograficznych treści o ugruntowanej wiarygodności. Dla kontrastu, zarówno Google AI Overviews, jak i Perplexity prezentują bardziej zbalansowany rozkład, z dominacją Reddita w ich wzorcach cytowań. Pokazuje to, że Perplexity priorytetowo traktuje informacje społecznościowe na poziomie 46,7% czołowych źródeł, podczas gdy Google zachowuje bardziej zróżnicowane podejście. Dane pokazują jasno, że uniwersalna strategia treści nie zadziała — marki muszą dostosować podejście do platform AI najważniejszych dla ich odbiorców.
Oznaczenie danych strukturalnych (schema markup) to prawdopodobnie najważniejszy czynnik wpływający na prawdopodobieństwo cytowania przez AI — poprawnie wdrożone JSON-LD osiąga wskaźnik cytowań o 340% wyższy niż identyczna treść bez danych strukturalnych. Ta dramatyczna różnica wynika z interpretacji znaczenia semantycznego przez silniki AI — dane strukturalne dają wyraźny kontekst, eliminując niejednoznaczność. Gdy AI napotyka oznaczenie schema, natychmiast rozumie relacje encji, typy treści i hierarchię bez polegania wyłącznie na przetwarzaniu języka naturalnego.
Najskuteczniejsze wdrożenia obejmują schemat Article dla wpisów blogowych, FAQ dla sekcji pytań i odpowiedzi, HowTo dla treści instruktażowych oraz Organization dla rozpoznawalności marki. Format JSON-LD jest szczególnie skuteczny, ponieważ silniki AI mogą analizować go niezależnie od zawartości HTML, co umożliwia czystsze wydobywanie danych i mniejszą złożoność przetwarzania. Semantyczne znaczniki HTML, takie jak <header>, <nav>, <main>, <section>, <article>, dodatkowo pomagają AI zrozumieć strukturę i hierarchię treści skuteczniej niż zwykłe znaczniki.
Testy A/B to najpewniejsza metoda określania, które formaty treści generują najwyższe wskaźniki cytowań przez AI w Twojej niszy. Zamiast polegać na ogólnych najlepszych praktykach, kontrolowane eksperymenty pozwalają zmierzyć realny wpływ zmian formatu na odbiorców i widoczność w AI. Proces wymaga starannego planowania, izolowania zmiennych i zapewnienia ważności statystycznej, ale uzyskane wnioski są tego warte.
Stosuj ten systematyczny schemat testów A/B:
Statystyczna istotność wymaga uwagi na wielkość próby i czas trwania testu. W zastosowaniach AI, gdzie dane są rozproszone lub rozkład długi ogon, szybkie zebranie wystarczających obserwacji może być trudne. Większość ekspertów zaleca testowanie przez co najmniej 2-4 tygodnie, aby uwzględnić zmienność czasową i uzyskać wiarygodne wyniki.
Badania tysięcy cytowań przez AI pokazują wyraźną hierarchię skuteczności formatów treści. Treści oparte na listach otrzymują o 68% więcej cytowań AI niż alternatywy z przewagą akapitów, głównie dlatego, że listy dostarczają wydzielonych, łatwych do przetworzenia jednostek, które AI może łatwo wyodrębniać i syntetyzować. Podczas generowania odpowiedzi, platformy AI mogą odwoływać się do konkretnych punktów z listy bez konieczności rekonstrukcji zdań czy parafrazowania, co czyni ten format szczególnie wartościowym pod kątem cytowań.
Tabele wykazują wyjątkową skuteczność — do 96% trafności w analizie przez AI, znacznie lepiej niż opisy tekstowe tych samych informacji. Zawartość tabelaryczna pozwala AI szybko wyodrębniać dane bez złożonej analizy tekstu, co czyni tabele szczególnie cenne dla treści faktograficznych, porównawczych czy statystycznych. Formaty pytań i odpowiedzi osiągają o 45% wyższą widoczność AI w porównaniu do tradycyjnych akapitów na te same tematy, ponieważ Q&A odzwierciedla sposób interakcji użytkowników z AI i sposób generowania odpowiedzi przez systemy AI.
Formaty porównawcze (X vs Y) sprawdzają się doskonale, bo zapewniają binarną, łatwą do podsumowania strukturę zgodną z tym, jak AI rozbudowuje zapytania na podtematy. Studium przypadków łączy narrację z danymi, przekonując czytelnika i jednocześnie pozostając czytelnym dla AI dzięki strukturze problem–rozwiązanie–wynik. Własne badania i eksperckie spostrzeżenia są preferowane przez AI, bo dostarczają unikalnych danych, zwiększając sygnały wiarygodności rozpoznawane i nagradzane przez AI. Kluczowy wniosek: nie ma uniwersalnego formatu — najlepsze podejście polega na strategicznym łączeniu wielu formatów zależnie od typu treści i docelowych platform AI.
Wdrożenie danych strukturalnych wymaga znajomości dostępnych typów i wyboru tych najbardziej adekwatnych do treści. Dla blogów i artykułów schemat Article zapewnia metadane, takie jak autor, data publikacji i struktura materiału. Schemat FAQ świetnie sprawdza się w sekcjach pytań i odpowiedzi, jasno oznaczając pytania i odpowiedzi do łatwego wydobycia przez AI. HowTo nadaje się do treści instruktażowych dzięki definiowaniu kroków, a Product wspiera sklepy internetowe, umożliwiając komunikowanie specyfikacji i cen.
{
"@context": "https://schema.org",
"@type": "FAQPage",
"mainEntity": [
{
"@type": "Question",
"name": "Jaki jest najlepszy format treści do cytowań przez AI?",
"acceptedAnswer": {
"@type": "Answer",
"text": "Najlepszy format treści zależy od platformy i odbiorców, ale uporządkowane formaty, takie jak listy, tabele i sekcje Q&A, konsekwentnie osiągają wyższe wskaźniki cytowań przez AI. Listy otrzymują 68% więcej cytowań niż akapity, a tabele osiągają 96% skuteczności w analizie."
}
}
]
}
Wdrożenie wymaga dbałości o poprawność składni — nieprawidłowe oznaczenie schema może zaszkodzić szansom na cytowanie przez AI zamiast je poprawić. Skorzystaj z narzędzi Google Rich Results Test lub walidatorów Schema.org, aby zweryfikować oznaczenia przed publikacją. Zachowaj spójną hierarchię nagłówków: H2 dla głównych sekcji, H3 dla podpunktów, krótkie akapity (maksymalnie 50-75 słów) skupiające się na jednym zagadnieniu. Dodawaj podsumowania TL;DR na początku lub końcu sekcji, aby AI miało gotowe fragmenty do wykorzystania jako samodzielne odpowiedzi.
Ocena wydajności w AI wymaga innych wskaźników niż tradycyjne SEO — istotne jest śledzenie cytowań, udziału w odpowiedziach oraz wzmianek w grafie wiedzy, zamiast pozycji w rankingu. Monitoring cytowań na głównych platformach dostarcza najbezpośredniejszych informacji, czy testy formatów przynoszą efekty i które treści są rzeczywiście cytowane przez AI. Narzędzia takie jak AmICited śledzą, jak platformy AI cytują Twoją markę w ChatGPT, Google AI Overviews, Perplexity i innych silnikach odpowiedzi, zapewniając wgląd w wzorce i trendy cytowań.
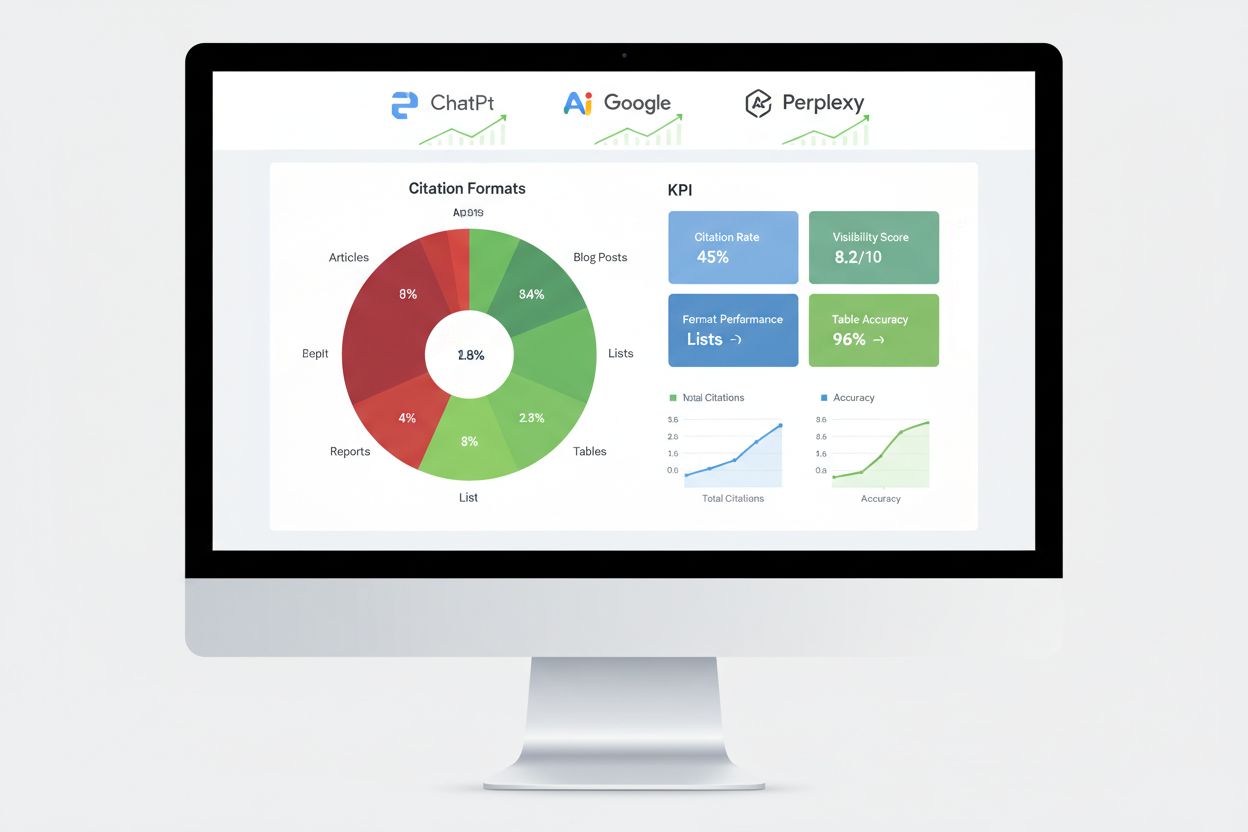
Kluczowe metody pomiaru to śledzenie udziału w featured snippetach, które wskazuje treści szczególnie cenne dla AI jako bezpośrednie odpowiedzi. Pojawienia się w panelach wiedzy sygnalizują, że AI rozpoznaje Twoją markę jako autorytatywną jednostkę zasługującą na osobny wyświetlacz informacyjny. Wyniki wyszukiwania głosowego pokazują, czy Twoje treści pojawiają się w odpowiedziach konwersacyjnych AI, a wskaźniki odpowiedzi generatywnych silników mierzą, jak często AI odwołuje się do Twojej treści w odpowiedziach na pytania użytkowników. Testy A/B różnych formatów dostarczają najbardziej wiarygodnych danych, pozwalając wyizolować wpływ pojedynczych czynników. Ustal wskaźniki bazowe przed wdrożeniem zmian i monitoruj wyniki co tydzień, by wychwycić trendy oraz anomalie świadczące o sukcesie lub porażce danego wariantu formatowania.
Wiele organizacji popełnia przewidywalne błędy podczas testowania formatów, co zniekształca wyniki i prowadzi do błędnych wniosków. Niewystarczająca wielkość próby to najczęstszy problem — testowanie przy zbyt małej liczbie cytowań lub interakcji daje wyniki pozornie istotne, lecz w rzeczywistości przypadkowe. Zawsze zbierz co najmniej 100 cytowań na wariant i skorzystaj z kalkulatorów statystycznych, by określić wymaganą wielkość próby dla danego poziomu ufności i efektu.
Zmienne zakłócające wprowadzają stronniczość, gdy jednocześnie zmienia się kilka elementów, uniemożliwiając wskazanie prawdziwej przyczyny obserwowanych różnic. Zachowaj identyczność wszystkich elementów poza testowanym formatem — te same słowa kluczowe, długość, strukturę i czas publikacji. Stronniczość czasowa pojawia się, gdy testy trwają w nietypowych okresach (święta, duże wydarzenia, zmiany algorytmów), które zniekształcają wyniki. Prowadź testy w typowych okresach i uwzględniaj sezonowość, testując przez minimum 2-4 tygodnie. Stronniczość selekcji występuje, gdy grupy testowe różnią się w sposób wpływający na wyniki — zapewnij losowy przydział treści do wariantów. Błędna interpretacja korelacji jako przyczyny prowadzi do fałszywych wniosków, gdy czynniki zewnętrzne przypadkowo pokrywają się z okresem testowym. Zawsze rozważ alternatywne wyjaśnienia i weryfikuj wyniki przez kilka cykli testowych przed wprowadzaniem trwałych zmian.
Firma technologiczna testująca formaty treści pod kątem widoczności w AI odkryła, że zamiana artykułów porównawczych z formy akapitowej na tabele porównawcze zwiększyła cytowania przez AI o 52% w ciągu 60 dni. Tabele zapewniły przejrzyste, łatwe do zeskanowania informacje, które AI mogła bezpośrednio wyodrębnić, podczas gdy oryginalna proza wymagała bardziej złożonego parsowania. Zachowano identyczną długość treści i optymalizację słów kluczowych, izolując wyłącznie zmianę formatu.
Firma z branży finansowej wdrożyła schemat FAQ na istniejących treściach bez przepisywania, po prostu dodając oznaczenie do sekcji pytań i odpowiedzi. Efektem był 34% wzrost udziału w featured snippetach i 28% wzrost cytowań przez AI w ciągu 45 dni. Schemat nie zmienił samej treści, ale znacznie ułatwił AI identyfikację i wydobycie odpowiedzi. Firma SaaS przeprowadziła testy wielowymiarowe na trzech formatach jednocześnie — listach, tabelach i tradycyjnych akapitach — dla identycznych treści o funkcjach produktu. Wyniki pokazały, że listy przewyższyły akapity o 68%, tabele osiągnęły najwyższą trafność analizy przez AI, lecz niższą liczbę cytowań ogółem. Pokazuje to, że skuteczność formatu zależy od typu treści i platformy AI, potwierdzając, że testowanie jest niezbędne, a nie wystarczą ogólne najlepsze praktyki. Te przykłady pokazują, że testowanie formatów przynosi wymierne, znaczące wzrosty widoczności w AI, gdy jest przeprowadzone prawidłowo.
Krajobraz testowania formatów treści ewoluuje wraz z rozwojem AI i pojawianiem się nowych technik optymalizacji. Algorytmy multi-armed bandit stanowią istotny postęp względem tradycyjnych testów A/B, dynamicznie przydzielając ruch do różnych wariantów na podstawie wyników w czasie rzeczywistym, bez konieczności czekania na zakończenie testu. Takie podejście skraca czas potrzebny do wyłonienia zwycięzców i maksymalizuje wyniki już w trakcie testów.
Adaptacyjne eksperymenty napędzane uczeniem ze wzmocnieniem pozwalają modelom AI uczyć się i dostosowywać na bieżąco, poprawiając wyniki w czasie rzeczywistym zamiast w kolejnych cyklach testowych. Automatyzacja testów A/B przez AI umożliwia projektowanie eksperymentów, analizę i rekomendacje optymalizacyjne przy minimalnym udziale człowieka, dzięki czemu firmy mogą testować więcej wariantów bez proporcjonalnego wzrostu złożoności. Te nowatorskie metody zapowiadają szybsze iteracje i bardziej zaawansowane strategie optymalizacyjne. Organizacje, które już dziś opanują testowanie formatów treści, utrzymają przewagę konkurencyjną, gdy zaawansowane techniki staną się standardem, umożliwiając maksymalne wykorzystanie nowych platform AI i ewoluujących algorytmów cytowań, zanim zrobi to konkurencja.
Najlepszy format treści zależy od platformy i odbiorców, ale uporządkowane formaty, takie jak listy, tabele i sekcje Q&A, konsekwentnie osiągają wyższe wskaźniki cytowań przez AI. Listy otrzymują 68% więcej cytowań niż akapity, a tabele osiągają 96% skuteczności w analizie. Kluczowe jest testowanie różnych formatów na własnych treściach, aby zidentyfikować, co działa najlepiej.
Większość ekspertów zaleca prowadzenie testów przez co najmniej 2-4 tygodnie, aby uwzględnić zmienność czasową i uzyskać wiarygodne wyniki. Ten czas pozwala zebrać wystarczającą liczbę danych (zwykle 100+ cytowań na wariant) i uwzględnić sezonowe wahania lub zmiany algorytmów platform, które mogą zafałszować wyniki.
Tak, możesz prowadzić testy wielowymiarowe obejmujące wiele formatów jednocześnie, ale wymaga to starannego planowania, aby uniknąć komplikacji w interpretacji wyników. Zacznij od prostych testów A/B porównujących dwa formaty, a następnie przejdź do testów wielowymiarowych, gdy zrozumiesz podstawy i będziesz mieć odpowiednie zasoby statystyczne.
Zwykle potrzebujesz co najmniej 100 cytowań lub interakcji na wariant, aby uzyskać istotność statystyczną. Skorzystaj z kalkulatorów statystycznych, aby określić dokładną wielkość próby dla określonego poziomu ufności i efektu. Większe próby dają bardziej wiarygodne wyniki, ale wymagają dłuższego testowania.
Zacznij od określenia najbardziej odpowiedniego typu schematu dla swojej treści (Article, FAQ, HowTo itd.), a następnie wdroż go w formacie JSON-LD. Zweryfikuj poprawność oznaczeń za pomocą narzędzi Google Rich Results Test lub walidatorów Schema.org przed publikacją. Nieprawidłowe dane strukturalne mogą wręcz zaszkodzić szansom na cytowanie przez AI, więc dokładność jest kluczowa.
Ustal priorytety w zależności od odbiorców i celów biznesowych. ChatGPT preferuje autorytatywne źródła, takie jak Wikipedia, Google AI Overviews wolą treści społecznościowe typu Reddit, a Perplexity kładzie nacisk na informacje peer-to-peer. Przeanalizuj, które platformy generują najbardziej wartościowy ruch na Twojej stronie i optymalizuj najpierw pod ich kątem.
Wprowadź ciągłe testowanie jako element strategii treści. Zacznij od kwartalnych cykli testowania formatów, a następnie zwiększaj częstotliwość wraz ze wzrostem doświadczenia i ustaleniem bazowych wskaźników. Regularne testy pomagają nadążać za zmianami algorytmów AI i wykrywać nowe preferencje formatów.
Monitoruj wzrost wskaźników cytowań, udział w featured snippetach, pojawienia się w panelach wiedzy oraz częstotliwość pojawiania się w odpowiedziach generatywnych silników AI. Ustal bazowe wskaźniki przed testowaniem, a następnie monitoruj wyniki co tydzień, aby wychwycić trendy. Udany test to zazwyczaj poprawa głównego wskaźnika o 20%+ w ciągu 4-8 tygodni.
Śledź, jak platformy AI cytują Twoje treści w różnych formatach. Odkryj, które struktury treści zapewniają największą widoczność w AI i zoptymalizuj swoją strategię na podstawie realnych danych.
Dowiedz się, jak treści w wielu formatach zwiększają widoczność w AI, takich jak ChatGPT, Google AI Overview i Perplexity. Poznaj 5-etapowy framework maksymaliz...
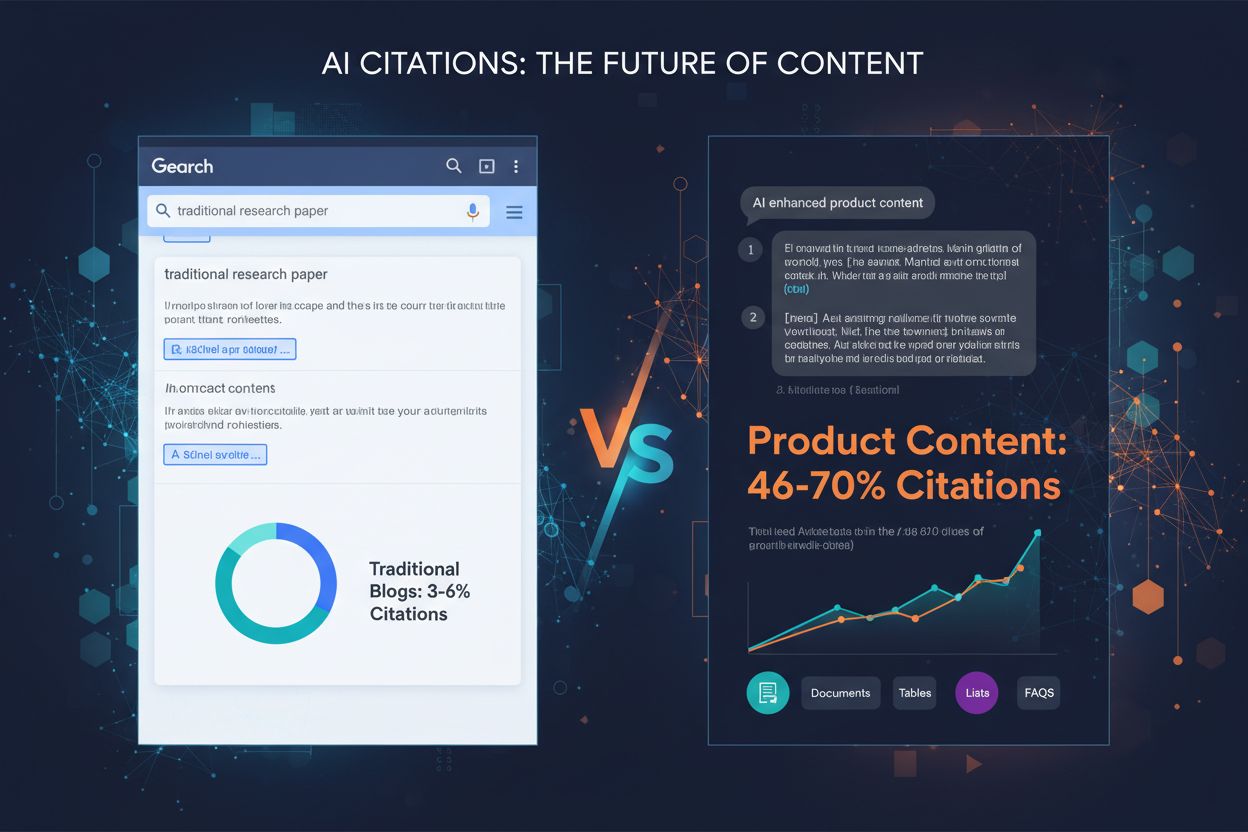
Dowiedz się, które formaty treści są najczęściej cytowane przez modele AI. Analizuj dane z ponad 768 000 cytowań przez AI, aby zoptymalizować swoją strategię tr...

Dowiedz się, dlaczego artykuły porównawcze są najwyżej ocenianym formatem treści w wyszukiwarkach AI. Poznaj sposoby optymalizacji treści porównawczych pod kąte...