Cytowania z Wikipedii jako dane treningowe AI: Efekt fali
Dowiedz się, jak cytowania z Wikipedii kształtują dane treningowe AI i tworzą efekt fali wśród LLM. Sprawdź, dlaczego obecność Twojej marki w Wikipedii ma znaczenie dla wzmianek AI i postrzegania marki.
Opublikowano Jan 3, 2026.Ostatnia modyfikacja Jan 3, 2026 o 3:24 am
Wikipedia stała się podstawowym zestawem danych treningowych dla praktycznie każdego dużego modelu językowego istniejącego obecnie — od ChatGPT OpenAI i Gemini Google’a po Claude Anthropic i wyszukiwarkę Perplexity. W wielu przypadkach Wikipedia stanowi największe pojedyncze źródło uporządkowanego, wysokiej jakości tekstu w zbiorach danych treningowych tych systemów AI, często obejmując 5-15% całego korpusu treningowego w zależności od modelu. Ta dominacja wynika z unikalnych cech Wikipedii: jej zasada neutralnego punktu widzenia, rygorystyczne, społecznościowe sprawdzanie faktów, uporządkowany format i otwarta licencja czynią ją niezrównanym zasobem do nauki AI rozumowania, cytowania źródeł i precyzyjnej komunikacji. Jednak ta relacja zasadniczo przekształciła rolę Wikipedii w ekosystemie cyfrowym — nie jest już tylko miejscem docelowym dla ludzi szukających informacji, lecz niewidzialnym kręgosłupem napędzającym konwersacyjne AI, z którym codziennie współdziałają miliony. Zrozumienie tego związku ujawnia kluczowy efekt fali: jakość, stronniczość i luki w Wikipedii bezpośrednio kształtują możliwości i ograniczenia systemów AI, które obecnie pośredniczą w tym, jak miliardy ludzi uzyskują i rozumieją informacje.
Jak LLM faktycznie wykorzystują dane z Wikipedii
Gdy duże modele językowe przetwarzają informacje podczas treningu, nie traktują wszystkich źródeł jednakowo — Wikipedia zajmuje wyjątkowo uprzywilejowaną pozycję w ich hierarchii decyzyjnej. W procesie rozpoznawania bytów LLM identyfikują kluczowe fakty i pojęcia, a następnie porównują je z wieloma źródłami w celu ustalenia ocen wiarygodności. Wikipedia pełni w tym procesie funkcję „głównego autorytetu” dzięki przejrzystej historii edycji, mechanizmom weryfikacji społeczności i zasadzie neutralnego punktu widzenia, które łącznie sygnalizują AI rzetelność. Efekt mnożnika wiarygodności dodatkowo wzmacnia tę przewagę: gdy informacja pojawia się konsekwentnie w Wikipedii, uporządkowanych grafach wiedzy takich jak Google Knowledge Graph czy Wikidata oraz źródłach akademickich, LLM przypisują jej wykładniczo wyższy poziom zaufania. Ten system ważenia tłumaczy, dlaczego Wikipedia jest traktowana w treningu szczególnie — służy zarówno jako bezpośrednie źródło wiedzy, jak i warstwa walidacyjna dla faktów pochodzących z innych źródeł. W efekcie LLM nauczyły się traktować Wikipedię nie tylko jako jedną z wielu danych, ale jako podstawowy punkt odniesienia, który potwierdza lub kwestionuje informacje z mniej zweryfikowanych źródeł.
Ważenie wiarygodności źródeł w treningu LLM
Typ źródła
Waga wiarygodności
Powód
Traktowanie przez AI
Wikipedia
Bardzo wysoka
Neutralna, edytowana przez społeczność, zweryfikowana
Główne odniesienie
Strona firmy
Średnia
Autopromocyjna
Źródło drugorzędne
Artykuły prasowe
Wysoka
Zewnętrzne, lecz potencjalnie stronnicze
Źródło potwierdzające
Grafy wiedzy
Bardzo wysoka
Uporządkowane, agregowane
Mnożnik autorytetu
Media społecznościowe
Niska
Niezweryfikowane, promocyjne
Minimalna waga
Źródła naukowe
Bardzo wysoka
Recenzowane, autorytatywne
Wysokie zaufanie
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Łańcuch cytowań: jak Wikipedia wpływa na odpowiedzi AI
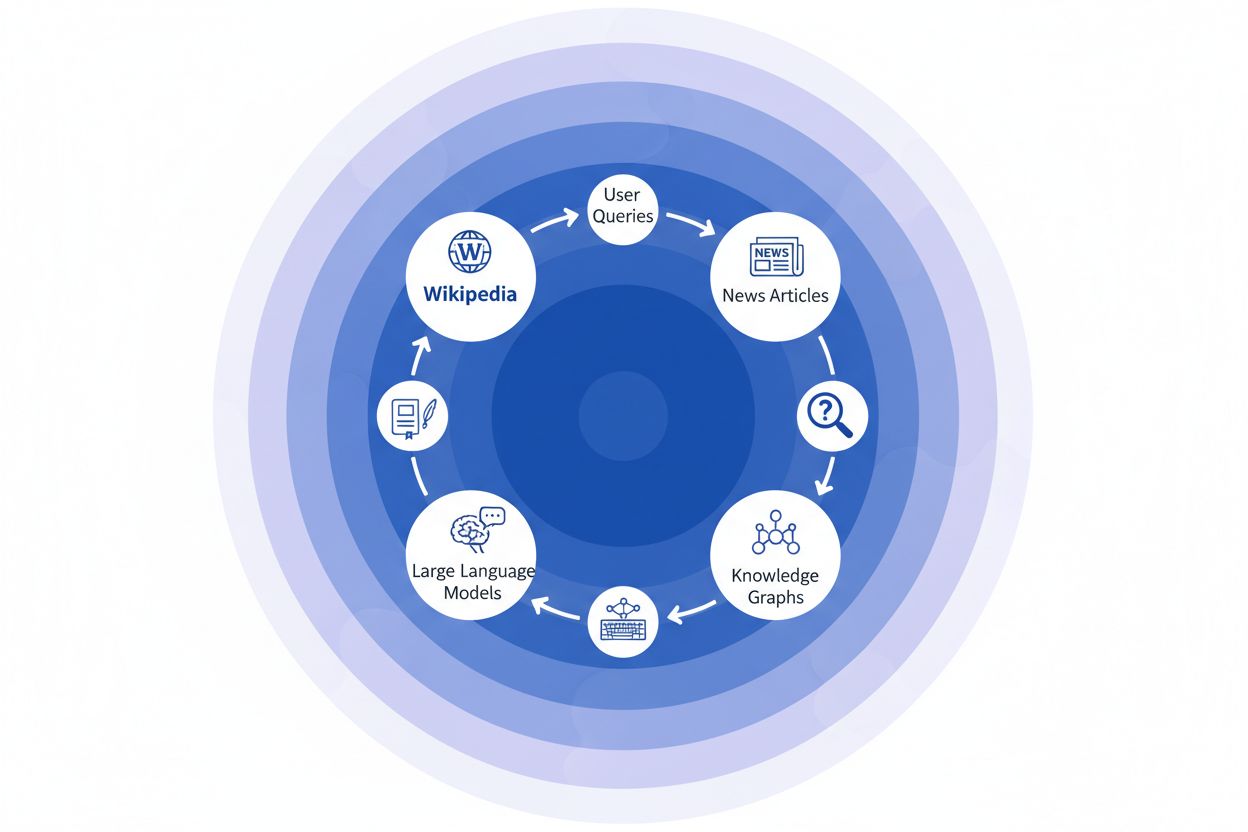
Gdy organizacja medialna cytuje Wikipedię jako źródło, tworzy to tzw. „łańcuch cytowań” — mechanizm kaskadowy, w którym wiarygodność kumuluje się na wielu warstwach infrastruktury informacyjnej. Dziennikarz piszący o zmianach klimatu może odwołać się do artykułu w Wikipedii na temat globalnego ocieplenia, który sam cytuje recenzowane badania naukowe; ten artykuł informacyjny jest następnie indeksowany przez wyszukiwarki i włączany do grafów wiedzy, które później trenują duże modele językowe, z których codziennie korzystają miliony użytkowników. Powstaje potężna pętla sprzężenia zwrotnego: Wikipedia → graf wiedzy → LLM → użytkownik, gdzie sposób sformułowania i akcenty pierwotnego wpisu w Wikipedii mogą subtelnie kształtować to, jak systemy AI prezentują informacje użytkownikom końcowym, często bez ich świadomości, że dane pochodzą z encyklopedii tworzonej przez społeczność. Przykład: jeśli artykuł Wikipedii o leczeniu farmaceutycznym podkreśla konkretne badania kliniczne, pomijając inne, ten wybór redakcyjny przenika do relacji prasowych, trafia do grafów wiedzy i ostatecznie wpływa na to, jak ChatGPT czy podobne modele odpowiadają pacjentom pytającym o opcje leczenia. Ten „efekt fali” oznacza, że decyzje redakcyjne Wikipedii nie wpływają wyłącznie na osoby odwiedzające stronę — fundamentalnie kształtują krajobraz informacyjny, z którego uczą się i który odzwierciedlają systemy AI dla miliardów użytkowników. Łańcuch cytowań przekształca więc Wikipedię z docelowego źródła w niewidzialną, ale wpływową warstwę procesu trenowania AI, gdzie dokładność i stronniczość u źródła mogą wzmocnić się w całym ekosystemie.
Efekt fali: konsekwencje dla całego ekosystemu
Efekt fali w ekosystemie Wikipedia–AI to prawdopodobnie najbardziej znacząca dynamika, jaką powinny poznać marki i organizacje. Jedna edycja w Wikipedii nie zmienia tylko jednego źródła — rozchodzi się przez połączoną sieć systemów AI, z których każdy czerpie i wzmacnia informacje, wielokrotnie zwiększając ich wpływ. Gdy na stronie Wikipedii pojawi się nieścisłość, nie pozostaje ona odosobniona; rozprzestrzenia się w całym krajobrazie AI, kształtując sposób opisu, rozumienia i prezentowania Twojej marki milionom użytkowników każdego dnia. Ten efekt mnożnikowy oznacza, że inwestując w rzetelność Wikipedii, dbasz nie tylko o jedną platformę — kontrolujesz swój przekaz w całym ekosystemie generatywnego AI. Dla specjalistów PR cyfrowego i zarządzania marką ta rzeczywistość zasadniczo zmienia kalkulację, gdzie warto kierować zasoby i uwagę.
Kluczowe efekty fali, które warto monitorować:
Jakość strony Wikipedii bezpośrednio wpływa na sposób opisu Twojej marki przez systemy AI — Słaba zawartość Wikipedii staje się podstawą, na której ChatGPT, Gemini, Claude i inne AI budują charakterystykę Twojej organizacji
Jedno cytowanie w Wikipedii wpływa na grafy wiedzy, które wpływają na AI Overviews — Cytowania przepływają przez infrastrukturę wiedzy Google i bezpośrednio kształtują sposób prezentacji informacji w podsumowaniach generowanych przez AI
Nieprawdziwe informacje z Wikipedii rozprzestrzeniają się w całym ekosystemie AI — Po zakorzenieniu w danych treningowych dezinformacja staje się wielokrotnie trudniejsza do korekty na różnych platformach
Pozytywna obecność w Wikipedii wzmacnia się na wszystkich głównych platformach AI — Dobrze utrzymana strona tworzy spójny, autorytatywny przekaz w ChatGPT, Gemini, Claude, Perplexity i nowych systemach AI
Edycje Wikipedii mają opóźniony, ale narastający wpływ na trening AI — Dzisiejsze zmiany wpływają na wyniki modeli przez miesiące lub lata wraz z kolejnymi cyklami trenowania
Efekt fali obejmuje Google AI Overviews, fragmenty wyróżnione i panele wiedzy — Wikipedia jest autorytatywnym źródłem zasilającym wyniki wyszukiwań generowanych przez AI Google oraz wyświetlane dane uporządkowane
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Wyzwanie zrównoważonego rozwoju Wikipedii: zagrożenie dla ekosystemu
Najnowsze badania z pracy IUP autorstwa Vetter i in. ujawniły kluczową słabość naszej infrastruktury AI: zrównoważony rozwój Wikipedii jako zasobu treningowego jest coraz bardziej zagrożony przez technologię, którą sama napędza. Wraz z rozwojem dużych modeli językowych i trenowaniem ich na coraz większych zbiorach danych generowanych przez same LLM, pojawia się narastający problem „załamania modelu”, gdzie sztuczne treści zaczynają zanieczyszczać pulę danych treningowych, obniżając jakość modeli w kolejnych generacjach. Zjawisko to jest szczególnie dotkliwe, ponieważ Wikipedia — encyklopedia tworzona przez społeczność oparta na wiedzy ekspertów i pracy wolontariuszy — stała się filarem treningu zaawansowanych systemów AI, często bez wyraźnego przypisania zasług czy rekompensaty dla jej twórców. Konsekwencje etyczne są poważne: firmy AI czerpią wartość z wiedzy dostarczanej nieodpłatnie przez Wikipedię, jednocześnie zalewając ekosystem informacyjny syntetyczną treścią, przez co system motywacyjny, który przez ponad dwie dekady utrzymywał społeczność wolontariuszy Wikipedii, znajduje się pod niespotykaną dotąd presją. Bez świadomej interwencji, mającej na celu ochronę treści wytwarzanych przez ludzi jako odrębny i chroniony zasób, grozi nam powstanie pętli sprzężenia zwrotnego, w której teksty generowane przez AI stopniowo zastępują autentyczną wiedzę ludzką, ostatecznie podkopując fundamenty, na których opierają się nowoczesne modele językowe. Dlatego zrównoważony rozwój Wikipedii to nie tylko kwestia samej encyklopedii, ale kluczowy problem całego ekosystemu informacji i przyszłej trwałości systemów AI zależnych od autentycznej wiedzy ludzkiej.
Monitorowanie swojej obecności w Wikipedii: rola AmICited
W miarę jak systemy sztucznej inteligencji coraz częściej opierają się na Wikipedii jako fundamentalnym źródle wiedzy, monitorowanie, jak Twoja marka pojawia się w generowanych przez AI odpowiedziach, stało się kluczowe dla nowoczesnych organizacji. AmICited.com specjalizuje się w śledzeniu cytowań z Wikipedii rozchodzących się przez systemy AI, dając markom wgląd w to, jak ich obecność w Wikipedii przekłada się na wzmianki i rekomendacje AI. Choć alternatywne narzędzia, takie jak FlowHunt.io, oferują ogólne możliwości monitoringu sieciowego, AmICited skupia się unikalnie na ścieżce cytowań od Wikipedii do AI, wychwytując moment, w którym systemy AI odwołują się do Twojego wpisu i jak to wpływa na ich odpowiedzi. Zrozumienie tego związku jest kluczowe, ponieważ cytowania z Wikipedii mają ogromne znaczenie w danych treningowych AI i generowaniu odpowiedzi — dobrze utrzymany wpis w Wikipedii nie tylko informuje ludzkich czytelników, ale kształtuje sposób, w jaki AI postrzega i prezentuje Twoją markę milionom użytkowników. Monitorując wzmianki o swojej marce w Wikipedii za pomocą AmICited, zyskujesz praktyczne informacje o swoim śladzie w AI, co pozwala zoptymalizować obecność w Wikipedii, mając pełną świadomość jej wpływu na odkrywanie i postrzeganie marki przez AI.
Najczęściej zadawane pytania
Czy Wikipedia naprawdę jest używana do trenowania każdego LLM?
Tak, każdy główny LLM, w tym ChatGPT, Gemini, Claude i Perplexity, zawiera Wikipedię w swoich danych treningowych. Wikipedia jest często największym pojedynczym źródłem uporządkowanych, zweryfikowanych informacji w zestawach danych treningowych LLM, zwykle stanowiąc 5-15% całego korpusu treningowego.
Jak Wikipedia wpływa na to, co systemy AI mówią o mojej marce?
Wikipedia służy jako punkt kontrolny wiarygodności dla systemów AI. Gdy LLM generuje informacje o Twojej marce, opis z Wikipedii jest traktowany priorytetowo w stosunku do innych źródeł, przez co Twoja strona w Wikipedii staje się kluczowym czynnikiem wpływającym na to, jak systemy AI przedstawiają Cię w ChatGPT, Gemini, Claude i innych platformach.
Czym jest „efekt fali” w kontekście Wikipedii i AI?
Efekt fali odnosi się do tego, jak jedno cytowanie lub edycja w Wikipedii powoduje dalsze konsekwencje w całym ekosystemie AI. Jedna zmiana w Wikipedii może wpłynąć na grafy wiedzy, które wpływają na podsumowania AI, a te z kolei kształtują sposób, w jaki wiele systemów AI opisuje Twoją markę milionom użytkowników.
Czy nieprawdziwe informacje w Wikipedii mogą zaszkodzić mojej marce w systemach AI?
Tak. Ponieważ LLM traktują Wikipedię jako bardzo wiarygodne źródło, nieprawdziwe informacje na Twojej stronie w Wikipedii rozprzestrzenią się przez systemy AI. Może to wpłynąć na sposób, w jaki ChatGPT, Gemini i inne platformy AI opisują Twoją organizację, potencjalnie szkodząc postrzeganiu marki.
Jak mogę monitorować wpływ Wikipedii na moją markę w systemach AI?
Narzędzia takie jak AmICited.com śledzą, jak Twoja marka jest cytowana i wspominana w systemach AI, w tym w ChatGPT, Perplexity i Google AI Overviews. Pomaga to zrozumieć efekt fali obecności w Wikipedii i odpowiednio ją zoptymalizować.
Czy powinienem samodzielnie tworzyć lub edytować swoją stronę w Wikipedii?
Wikipedia ma surowe zasady przeciwko autopromocji. Wszelkie edycje powinny być zgodne z wytycznymi Wikipedii i opierać się na wiarygodnych, zewnętrznych źródłach. Wiele organizacji współpracuje ze specjalistami Wikipedii, aby zapewnić zgodność i utrzymać poprawny wizerunek.
Jak długo trwa, zanim zmiany w Wikipedii wpłyną na systemy AI?
LLM są trenowane na migawkach danych, więc zmiany potrzebują czasu, aby się rozprzestrzenić. Jednak grafy wiedzy aktualizują się częściej, więc efekt fali może rozpocząć się w ciągu kilku tygodni lub miesięcy, w zależności od systemu AI i momentu jego ponownego trenowania.
Jaka jest różnica między Wikipedią a grafami wiedzy w treningu AI?
Wikipedia jest podstawowym źródłem wykorzystywanym bezpośrednio w treningu LLM. Grafy wiedzy, takie jak Google Knowledge Graph, agregują informacje z wielu źródeł, w tym z Wikipedii, i przekazują je do systemów AI, co tworzy dodatkową warstwę wpływu na to, jak AI rozumie i prezentuje informacje.
Monitoruj swoją obecność w Wikipedii w systemach AI
Śledź, jak cytowania z Wikipedii rozchodzą się przez ChatGPT, Gemini, Claude i inne systemy AI. Zrozum swój ślad w AI i zoptymalizuj obecność w Wikipedii z AmICited.
Rola Wikipedii w danych treningowych AI: Jakość, wpływ i licencjonowanie
Dowiedz się, jak Wikipedia pełni kluczową rolę w danych treningowych AI, jaki ma wpływ na dokładność modeli, jakie są umowy licencyjne i dlaczego firmy AI poleg...
Jak zdobyć wzmianki w artykułach Wikipedii: Niemanipulacyjne podejście
Poznaj etyczne strategie zdobywania wzmianek o marce w Wikipedii. Zrozum zasady treści Wikipedii, wiarygodne źródła i sposoby wykorzystania cytowań dla widoczno...
Rola Wikipedii w cytowaniach AI: jak kształtuje odpowiedzi generowane przez AI
Dowiedz się, jak Wikipedia wpływa na cytowania AI w ChatGPT, Perplexity i Google AI. Poznaj powody, dla których Wikipedia jest najbardziej zaufanym źródłem dla ...
12 min czytania
Zgoda na Pliki Cookie Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.