Jak uzyskać rekomendacje produktów od AI?
Dowiedz się, jak działają rekomendacje produktów oparte na AI, jakie algorytmy za nimi stoją i jak zoptymalizować widoczność w systemach rekomendacji zasilanych...
8 min czytania
Systemy uczenia maszynowego analizujące zachowania i preferencje użytkowników w celu dostarczania spersonalizowanych sugestii produktów i treści. Systemy te wykorzystują algorytmy, takie jak filtrowanie kolaboratywne i filtrowanie oparte na treści, aby przewidywać, co może zainteresować użytkowników, umożliwiając firmom zwiększenie zaangażowania, sprzedaży i satysfakcji klientów dzięki dostosowanym rekomendacjom.
Systemy uczenia maszynowego analizujące zachowania i preferencje użytkowników w celu dostarczania spersonalizowanych sugestii produktów i treści. Systemy te wykorzystują algorytmy, takie jak filtrowanie kolaboratywne i filtrowanie oparte na treści, aby przewidywać, co może zainteresować użytkowników, umożliwiając firmom zwiększenie zaangażowania, sprzedaży i satysfakcji klientów dzięki dostosowanym rekomendacjom.
Rekomendacje wspierane przez AI to zaawansowana technologia wykorzystująca algorytmy uczenia maszynowego do analizy zachowań i preferencji użytkowników, dostarczająca spersonalizowane sugestie dopasowane do indywidualnych potrzeb i zainteresowań. Silniki rekomendacyjne stanowią rdzeń tych systemów, działając jako inteligentny pośrednik między ogromnymi katalogami produktów a pojedynczymi użytkownikami, umożliwiając niespotykany dotąd poziom personalizacji na dużą skalę. Globalny rynek silników rekomendacyjnych odnotował ogromny wzrost, wyceniany na około 2,8 miliarda dolarów w 2023 roku i prognozowany na 8,5 miliarda dolarów do 2030 roku, co odzwierciedla kluczowe znaczenie tej technologii w gospodarce cyfrowej. Rekomendacje wspierane przez AI stały się nieodzowne w różnych branżach — od platform e-commerce, takich jak Amazon i eBay, przez serwisy streamingowe (Netflix, Spotify), po sieci społecznościowe i platformy treściowe. Zasadą leżącą u podstaw tych systemów jest to, że algorytmy uczenia maszynowego potrafią identyfikować wzorce w zachowaniach użytkowników, których człowiek nie jest w stanie łatwo dostrzec, umożliwiając firmom przewidywanie potrzeb klientów, zanim sami użytkownicy je zidentyfikują. Wykorzystując ogromne zbiory danych i moc obliczeniową, systemy rekomendacyjne zmieniły sposób, w jaki konsumenci odkrywają produkty, treści i usługi, zasadniczo przekształcając strategie angażowania klientów w różnych branżach.

Systemy rekomendacyjne wspierane przez AI działają w ramach wyrafinowanego, pięcioetapowego procesu, który przekształca surowe dane użytkowników w praktyczne, spersonalizowane sugestie. Pierwszy etap to kompleksowe zbieranie danych — systemy gromadzą informacje z wielu punktów styku, takich jak interakcje użytkownika, historia przeglądania, rejestry zakupów i mechanizmy jawnych opinii. W fazie analizy system przetwarza zebrane dane, by zidentyfikować znaczące wzorce i zależności, wykorzystując algorytmy uczenia maszynowego, takie jak filtrowanie kolaboratywne, filtrowanie oparte na treści i sieci neuronowe, by wydobyć wnioski z złożonych zbiorów danych. Faza rozpoznawania wzorców stanowi obliczeniowe jądro systemu — algorytmy identyfikują podobieństwa między użytkownikami, przedmiotami lub obiema stronami, tworząc matematyczne reprezentacje preferencji i cech produktów. Faza predykcji wykorzystuje te wzorce, by przewidzieć, z którymi przedmiotami użytkownik najprawdopodobniej się zaangażuje, przypisując rekomendacjom odpowiednie poziomy pewności. Ostatni etap — prezentacja — polega na przedstawieniu tych przewidywań użytkownikom poprzez spersonalizowane interfejsy, zapewniając pojawianie się rekomendacji w najbardziej odpowiednich momentach ścieżki użytkownika. Coraz większe znaczenie ma przetwarzanie w czasie rzeczywistym — nowoczesne systemy aktualizują rekomendacje natychmiast po pojawieniu się nowych danych, umożliwiając dynamiczną personalizację dostosowaną do zmieniających się preferencji. Zaawansowane systemy rekomendacyjne stosują metody zespołowe, łącząc jednocześnie wiele algorytmów — każdy wnosi własne prognozy, co skutkuje bardziej trafnymi i odpornymi rekomendacjami niż w przypadku pojedynczego algorytmu.
Systemy rekomendacyjne opierają się na dwóch odmiennych kategoriach danych użytkownika, z których każda dostarcza unikalnych wglądów w preferencje i wzorce zachowań:
Dane jawne:
Dane niejawne:
Dane jawne dostarczają jednoznacznych sygnałów preferencji użytkownika, lecz są rzadkie — większość użytkowników ocenia tylko niewielki ułamek dostępnych elementów. Dane niejawne przeciwnie — są obfite i generowane nieprzerwanie podczas codziennych interakcji, lecz wymagają zaawansowanej interpretacji, ponieważ np. samo obejrzenie produktu nie musi oznaczać preferencji. Najskuteczniejsze systemy rekomendacyjne integrują oba typy danych, wykorzystując jawne opinie do kalibracji i weryfikacji sygnałów niejawnych, budując pełne profile użytkowników, które odzwierciedlają zarówno deklarowane, jak i ujawnione preferencje.
Filtrowanie kolaboratywne to jedno z podstawowych podejść w systemach rekomendacyjnych, oparte na zasadzie, że użytkownicy o podobnych preferencjach w przeszłości najprawdopodobniej będą zadowoleni z podobnych produktów w przyszłości. Metodologia ta analizuje wzorce w całych populacjach użytkowników, aby wykryć wspólne cechy, odróżniając się od podejść koncentrujących się na indywidualnych właściwościach produktów. Filtrowanie kolaboratywne oparte na użytkowniku identyfikuje osoby o podobnej historii preferencji do użytkownika docelowego, a następnie poleca produkty, które oni polubili, a użytkownik jeszcze nie poznał — wykorzystując wiedzę użytkowników podobnych. Filtrowanie kolaboratywne oparte na przedmiotach koncentruje się na podobieństwach między produktami, rekomendując te, które są podobne do wysoko ocenianych przez użytkownika, na podstawie ocen innych osób. Oba podejścia stosują wyrafinowane miary podobieństwa, takie jak podobieństwo cosinusowe, korelacja Pearsona czy odległość euklidesowa, by ilościowo określić, jak bardzo użytkownicy lub produkty są do siebie podobni w przestrzeni preferencji. Filtrowanie kolaboratywne oferuje istotne zalety, m.in. możliwość rekomendowania produktów bez metadanych oraz wykrywanie nieoczekiwanych sugestii, których użytkownik sam by nie przewidział. Jednak podejście to ma też istotne ograniczenia, zwłaszcza “problem zimnego startu”, gdy nowi użytkownicy lub produkty nie mają jeszcze wystarczającej historii do obliczenia podobieństw, a także problem rzadkości danych w branżach z milionami produktów, gdzie większość interakcji użytkownik-produkt pozostaje niezaobserwowana.
Filtrowanie oparte na treści rekomenduje produkty poprzez analizę ich wewnętrznych cech i właściwości, polecając przedmioty podobne do tych, które użytkownik wcześniej polubił na podstawie mierzalnych atrybutów. Zamiast opierać się na zbiorowych wzorcach zachowań użytkowników, systemy te budują szczegółowe profile produktów, obejmujące cechy takie jak gatunek, reżyser i obsada (dla filmów), autor, tematyka i data wydania (dla książek), czy kategoria produktu, marka i specyfikacja (dla e-commerce). System oblicza podobieństwo między produktami, porównując ich wektory cech za pomocą technik matematycznych, takich jak podobieństwo cosinusowe czy odległość euklidesowa, tworząc ilościową miarę stopnia podobieństwa w przestrzeni cech. Gdy użytkownik oceni lub zaangażuje się w produkt, system identyfikuje inne, o zbliżonym profilu cech i rekomenduje je, personalizując sugestie na podstawie wykazanych preferencji względem konkretnych właściwości przedmiotów. Filtrowanie oparte na treści sprawdza się tam, gdzie metadane są bogate i dobrze ustrukturyzowane i naturalnie radzi sobie z problemem zimnego startu dla nowych produktów, ponieważ rekomendacje zależą od cech, a nie od historii interakcji. Jednak podejście to ma ograniczenia w zakresie zaskoczenia i odkrywania nowości, ponieważ zwykle poleca produkty bardzo podobne do wcześniejszych preferencji, co może prowadzić do powstania baniek filtrujących. W porównaniu z filtrowaniem kolaboratywnym, systemy oparte na treści wymagają jawnego modelowania cech produktów i mają trudność z elementami o niejasnych granicach kategorii, ale oferują większą przejrzystość, gdyż rekomendacje można uzasadnić odwołaniem do konkretnych atrybutów.
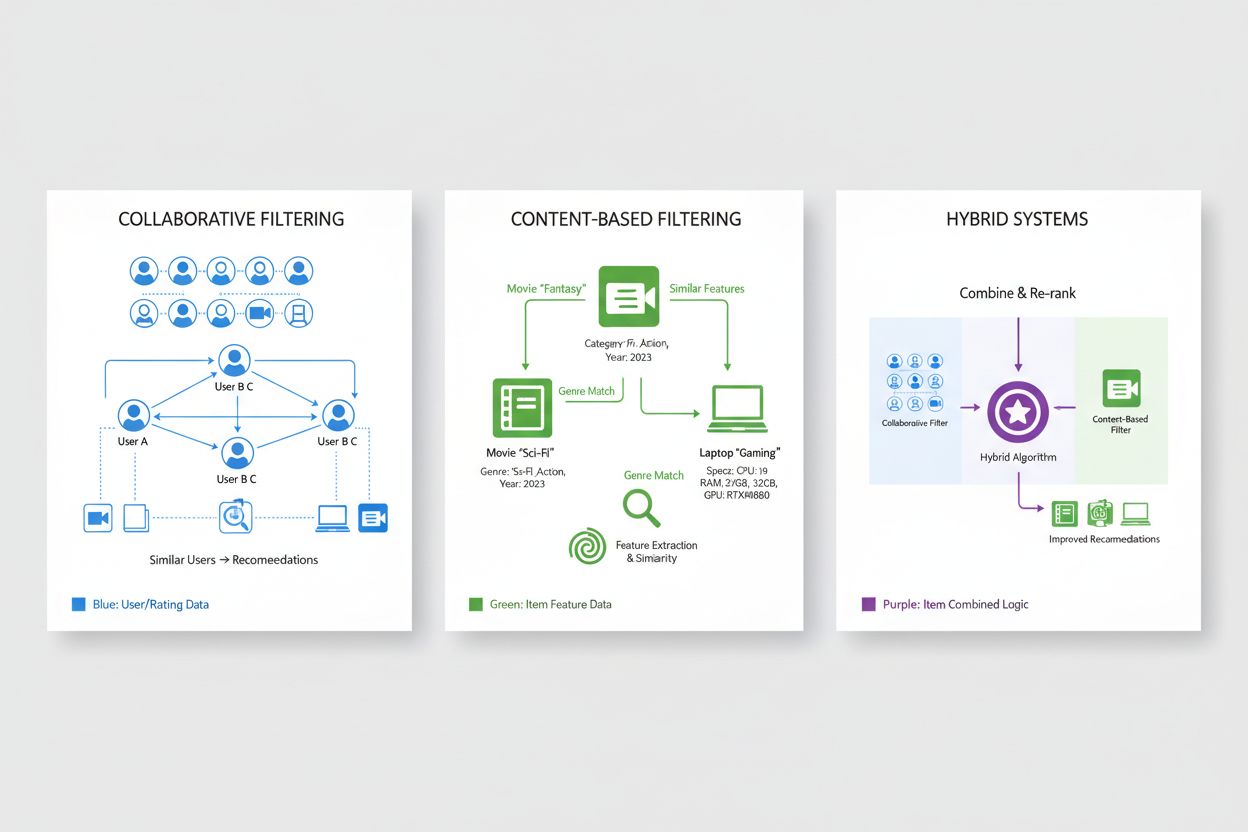
Hybrydowe systemy rekomendacyjne strategicznie łączą podejścia filtrowania kolaboratywnego i opartego na treści, wykorzystując komplementarne mocne strony każdego z nich, by pokonać ich indywidualne ograniczenia i zapewnić wyższą trafność rekomendacji. Systemy takie stosują różne strategie integracji — od kombinacji wagowych, gdzie prognozy z wielu algorytmów są łączone zgodnie z ustalonymi lub wyuczonymi wagami, przez mechanizmy przełączania wyboru najlepszego algorytmu w zależności od kontekstu, po podejścia kaskadowe, gdzie wynik jednego algorytmu jest wejściem dla kolejnego. Integrując zdolność filtrowania kolaboratywnego do odkrywania nieoczekiwanych rekomendacji i złożonych wzorców preferencji z możliwością filtrowania opartego na treści do obsługi nowych produktów i generowania wyjaśnialnych sugestii, hybrydowe systemy osiągają większą odporność i skuteczność w różnych scenariuszach. Największe firmy technologiczne przyjęły podejścia hybrydowe jako standard branżowy; Netflix łączy filtrowanie kolaboratywne z metodami opartymi na treści i informacjami kontekstowymi, by równoważyć popularność, personalizację i nowość w rekomendacjach. Algorytm rekomendacji Spotify także wykorzystuje techniki hybrydowe, łącząc filtrowanie kolaboratywne na podstawie wzorców słuchania z analizą cech audio i metadanych oraz przetwarzaniem języka naturalnego na playlistach i recenzjach użytkowników. Hybrydowe systemy oferują nie tylko większą dokładność, ale również lepsze pokrycie katalogu produktów, skuteczniejsze radzenie sobie z rzadkimi danymi i większą odporność na typowe wyzwania rekomendacyjne. Systemy te stanowią obecnie szczytową technologię personalizacji, a większość rekomendacyjnych platform korporacyjnych stosuje architektury hybrydowe, nieustannie ewoluując wraz z pojawianiem się nowych rozwiązań algorytmicznych.
Rekomendacje wspierane przez AI stały się kluczowym elementem modeli biznesowych największych firm technologicznych i handlowych, zasadniczo zmieniając sposób odkrywania i zakupu produktów przez klientów. Amazon, pionier e-commerce, generuje około 35% całkowitych przychodów dzięki zakupom z rekomendacji — jego zaawansowany system analizuje historię przeglądania, wzorce zakupów, oceny produktów i zachowania podobnych klientów, by sugerować produkty w kluczowych momentach ścieżki zakupowej. Netflix przetwarza historię oglądania, oceny, zachowania przy wyszukiwaniu i wzorce czasowe, by sugerować treści — firma podaje, że około 80% godzin oglądania na platformie pochodzi ze spersonalizowanych rekomendacji, co pokazuje ogromny wpływ skutecznej personalizacji na zaangażowanie i retencję użytkowników. Spotify wykorzystuje rekomendacje AI na wielu płaszczyznach, m.in. w funkcji playlisty “Discover Weekly”, która łączy filtrowanie kolaboratywne z analizą cech audio i informacjami kontekstowymi, generując wysoce spersonalizowane sugestie muzyczne, kluczowe dla zaangażowania i utrzymania subskrybentów. Temu, dynamicznie rozwijająca się platforma e-commerce, stosuje zaawansowane systemy rekomendacyjne analizujące wzorce zachowań, zapytania i historię zakupów, by prezentować produkty dopasowane do indywidualnych preferencji, co w dużej mierze przyczyniło się do jej dynamicznego wzrostu i wysokich wskaźników zaangażowania użytkowników. Te przykłady pokazują, że systemy rekomendacyjne mają bezpośredni wpływ na kluczowe wskaźniki biznesowe — wartość klienta w czasie, częstotliwość ponownych zakupów i długość zaangażowania — a firmy traktują inwestycje w technologię rekomendacyjną jako kluczową przewagę konkurencyjną na coraz bardziej zatłoczonym rynku cyfrowym.
Rekomendacje wspierane przez AI przynoszą znaczne korzyści zarówno firmom, jak i użytkownikom, tworząc ekosystem obopólnych zysków, który napędza zaangażowanie i satysfakcję:
Korzyści biznesowe:
Korzyści dla użytkowników:
Sumaryczny wpływ tych korzyści sprawił, że systemy rekomendacyjne stały się infrastrukturą niezbędną w handlu cyfrowym i platformach treściowych, a użytkownicy coraz częściej traktują personalizację jako standard, a nie usługę premium.
Mimo powszechnego sukcesu, systemy rekomendacyjne wspierane przez AI stoją przed istotnymi wyzwaniami, z którymi mierzą się naukowcy i praktycy. Kwestie prywatności nabierają znaczenia wraz z wejściem w życie przepisów, takich jak RODO czy CCPA, które nakładają ścisłe wymogi na zbieranie i wykorzystywanie danych, zmuszając firmy do równoważenia skuteczności personalizacji z prawami użytkowników i ochroną danych. Problem zimnego startu pozostaje szczególnie dotkliwy dla nowych użytkowników i produktów, gdzie brak wystarczającej historii uniemożliwia trafne rekomendacje, co wymusza stosowanie podejść hybrydowych lub alternatywnych strategii uruchamiania personalizacji. Stronniczość algorytmiczna to kolejne istotne wyzwanie — systemy rekomendacyjne mogą utrwalać i wzmacniać istniejące uprzedzenia w danych treningowych, prowadząc do dyskryminacji niektórych grup użytkowników lub tworzenia baniek filtrujących ograniczających różnorodność treści.
Nowe trendy przeobrażają krajobraz rekomendacji — personalizacja w czasie rzeczywistym staje się coraz bardziej zaawansowana dzięki edge computing i przetwarzaniu strumieniowemu, umożliwiając natychmiastową adaptację do zachowań użytkownika. Integracja danych multimodalnych wychodzi poza tradycyjne sygnały behawioralne, obejmując cechy wizualne, dźwiękowe, tekstowe i kontekstowe, pozwalając na bogatsze i bardziej zniuansowane zrozumienie preferencji użytkownika. Rekomendacje oparte na emocjach otwierają nowe możliwości personalizacji — systemy zaczynają uwzględniać kontekst emocjonalny i analizę sentymentu, by sugerować treści zgodne nie tylko z historycznymi preferencjami, ale też z aktualnym stanem emocjonalnym. Przyszłe rozwiązania będą kłaść nacisk na wyjaśnialność i przejrzystość, umożliwiając użytkownikom zrozumienie, dlaczego pojawiły się konkretne rekomendacje oraz dając narzędzia do własnoręcznego kształtowania profilu rekomendacyjnego. Konwergencja tych trendów wskazuje, że systemy rekomendacyjne nowej generacji będą bardziej świadome prywatności, przejrzyste, inteligentne emocjonalnie i zdolne do zapewnienia naprawdę przełomowych doświadczeń personalizacyjnych z poszanowaniem autonomii użytkownika i praw do danych.
Rekomendacje wspierane przez AI proaktywnie sugerują elementy na podstawie zachowań i preferencji użytkownika bez konieczności wykonywania przez niego jawnych wyszukiwań, podczas gdy tradycyjne wyszukiwanie wymaga aktywnego wpisania zapytania przez użytkownika. Rekomendacje wykorzystują uczenie maszynowe do przewidywania zainteresowań, natomiast wyszukiwanie opiera się na dopasowaniu słów kluczowych. Rekomendacje są spersonalizowane dla poszczególnych użytkowników, podczas gdy wyniki wyszukiwania są zazwyczaj bardziej ogólne. Współczesne systemy często łączą oba podejścia dla optymalnego doświadczenia użytkownika.
Nowi użytkownicy napotykają na 'problem zimnego startu', gdzie systemy nie mają danych historycznych do generowania trafnych rekomendacji. Rozwiązania obejmują wykorzystanie informacji demograficznych, wyświetlanie popularnych elementów, stosowanie filtrowania opartego na treści na podstawie cech produktów lub proszenie o wskazanie preferencji. Systemy hybrydowe łączą różne podejścia, by uruchomić rekomendacje dla nowych użytkowników. Niektóre platformy używają filtrowania kolaboratywnego z profilami podobnych użytkowników lub informacji kontekstowych, takich jak typ urządzenia i lokalizacja, by wygenerować początkowe sugestie.
Systemy rekomendacyjne zbierają dane jawne, takie jak oceny, recenzje i opinie użytkowników, a także dane niejawne, w tym historię przeglądania, rejestry zakupów, czas spędzony przy poszczególnych elementach, zapytania wyszukiwania i wzorce kliknięć. Mogą również gromadzić informacje kontekstowe, takie jak typ urządzenia, lokalizacja, pora dnia i czynniki sezonowe. Zaawansowane systemy integrują dane demograficzne, powiązania społeczne oraz sygnały behawioralne. Całe gromadzenie danych musi być zgodne z przepisami o prywatności, takimi jak RODO i CCPA, wymagając zgody użytkownika oraz przejrzystej polityki wykorzystania danych.
Tak, systemy rekomendacyjne mogą utrwalać i wzmacniać uprzedzenia obecne w danych treningowych, potencjalnie dyskryminując niektóre grupy użytkowników lub ograniczając ekspozycję na zróżnicowane treści. Stronniczość algorytmiczna może wynikać ze zniekształconych danych historycznych, niedostatecznej reprezentacji mniejszości lub pętli zwrotnych wzmacniających istniejące wzorce. Przeciwdziałanie uprzedzeniom wymaga zróżnicowanych danych treningowych, regularnych audytów, metryk sprawiedliwości i przejrzystego projektowania algorytmów. Firmy muszą aktywnie monitorować uprzedzenia i wdrażać strategie łagodzące, by zapewnić równość rekomendacji dla wszystkich grup użytkowników.
Systemy hybrydowe łączą zdolność filtrowania kolaboratywnego do identyfikacji nieoczekiwanych rekomendacji z możliwością filtrowania opartego na treści do obsługi nowych elementów i dostarczania wyjaśnialnych sugestii. Takie połączenie pozwala przezwyciężyć indywidualne ograniczenia: filtrowanie kolaboratywne ma trudność z nowymi produktami, a oparte na treści brakuje elementu zaskoczenia. Hybrydowe podejścia wykorzystują kombinacje wagowe, mechanizmy przełączania lub metody kaskadowe, by wykorzystać zalety każdego algorytmu. Rezultatem jest większa dokładność, lepsza pokrywalność katalogu, skuteczniejsze radzenie sobie z rzadkimi danymi oraz bardziej odporne działanie w różnych scenariuszach.
Obawy dotyczące prywatności obejmują szeroki zakres zbierania danych wymaganych do generowania trafnych rekomendacji, ryzyko nieuprawnionego wykorzystania danych, zagrożenia wyciekiem informacji i problemy z przestrzeganiem przepisów, takich jak RODO, CCPA i podobnych. Użytkownicy mogą czuć się niekomfortowo z poziomem śledzenia zachowań wymaganym do personalizacji. Firmy muszą zapewnić silne zabezpieczenia danych, uzyskać wyraźną zgodę, zapewnić przejrzystość wykorzystania danych i umożliwić użytkownikom kontrolę nad swoimi danymi. Równoważenie skuteczności personalizacji z ochroną prywatności pozostaje stałym wyzwaniem w branży.
Rekomendacje w czasie rzeczywistym przetwarzają dane o zachowaniach użytkownika natychmiast, aktualizując sugestie na bieżąco w oparciu o aktualne interakcje. Systemy wykorzystują przetwarzanie strumieniowe i edge computing do analizy działań, takich jak kliknięcia, wyświetlenia czy zakupy w ciągu milisekund. Umożliwia to dynamiczną personalizację, która dostosowuje się do zmieniających się preferencji w trakcie sesji użytkownika. Systemy te wymagają solidnej infrastruktury, wydajnych algorytmów i niskich opóźnień w przetwarzaniu danych. Przykłady to Netflix aktualizujący rekomendacje podczas przeglądania czy Amazon prezentujący nowe sugestie podczas dodawania produktów do koszyka.
Przyszłe trendy obejmują rekomendacje uwzględniające emocje użytkownika, integrację danych multimodalnych łączących informacje wizualne, dźwiękowe i tekstowe, zaawansowane techniki ochrony prywatności, lepszą wyjaśnialność i przejrzystość oraz personalizację w czasie rzeczywistym na dużą skalę. Nowe technologie, takie jak federated learning, umożliwiają rekomendacje bez centralizacji danych użytkownika. Systemy będą bardziej świadome kontekstu, uwzględniając czynniki czasowe i sytuacyjne. Konwergencja tych trendów zapewni bardziej wyrafinowaną, przejrzystą i świadomą prywatności personalizację z poszanowaniem autonomii użytkownika i praw do danych.
AmICited śledzi, jak systemy AI, takie jak ChatGPT, Perplexity i Google AI Overviews, wspominają Twoją markę w spersonalizowanych rekomendacjach i treściach generowanych przez AI. Bądź na bieżąco z widocznością swojej marki w systemach wspieranych przez AI.
Dowiedz się, jak działają rekomendacje produktów oparte na AI, jakie algorytmy za nimi stoją i jak zoptymalizować widoczność w systemach rekomendacji zasilanych...
Dyskusja społeczności na temat sponsorowanych treści i reklam w wynikach wyszukiwania AI. Użytkownicy i marketerzy omawiają schematy w ChatGPT, Perplexity i Goo...
Dowiedz się, jak wzmianki o cenach wpływają na rekomendacje AI w ChatGPT, Perplexity, Google AI Overviews i Claude. Poznaj wzorce cytowań i strategie optymaliza...