
Google-Extended: Czym Jest i Czy Powinieneś Go Zablokować?
Dowiedz się, czym jest Google-Extended, jak działa i czy warto go zablokować w pliku robots.txt. Zrozum różnicę między kontrolą treningu AI a AI Overviews....
7 min czytania
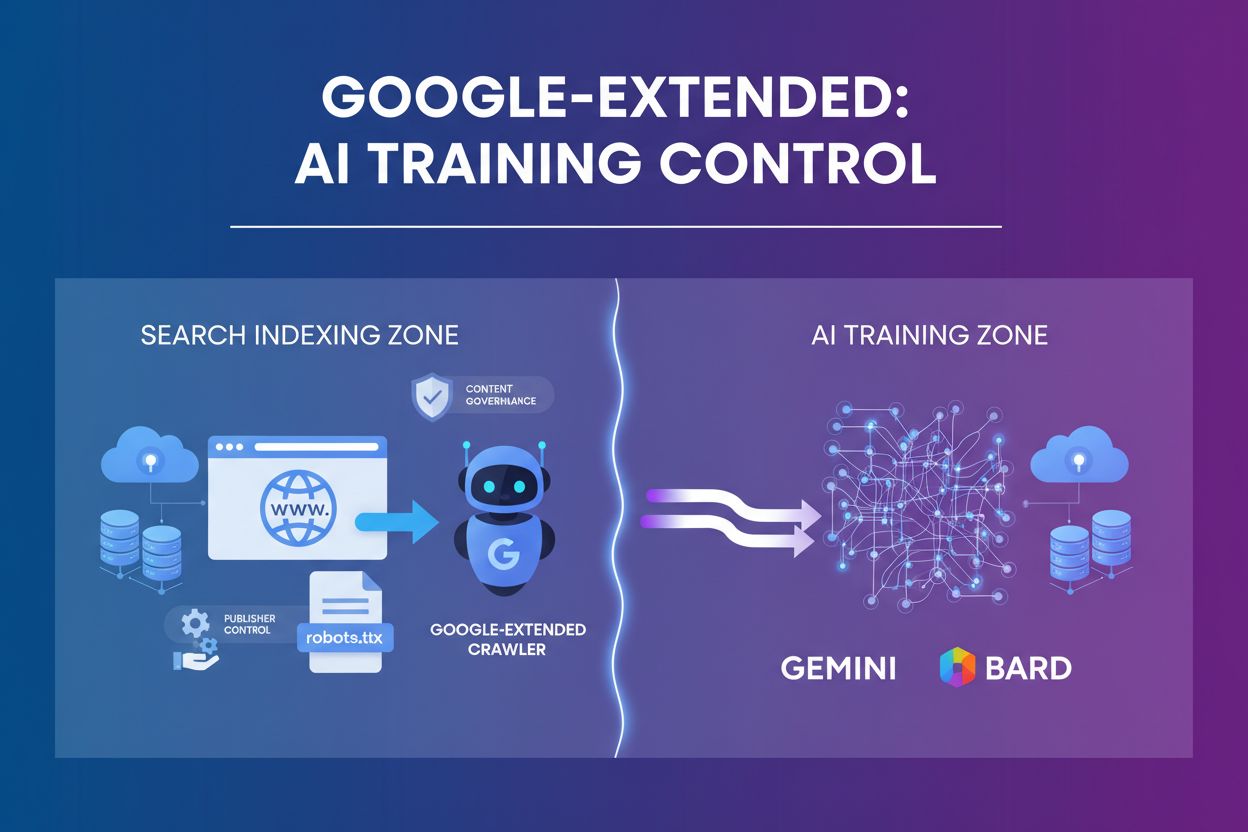
Google-Extended to token user-agenta, który kontroluje, czy treści ze strony są wykorzystywane do ulepszania Gemini i innych produktów AI Google, niezależnie od standardowego indeksowania przez Googlebota. Pozwala wydawcom zarządzać dostępem do trenowania AI za pomocą robots.txt bez wpływu na widoczność w wyszukiwarce. Wprowadzony we wrześniu 2023 roku odpowiada na obawy wydawców dotyczące wykorzystania treści w rozwoju modeli AI. Google-Extended nie wpływa na pozycjonowanie SEO ani na obecność w wynikach wyszukiwania.
Google-Extended to token user-agenta, który kontroluje, czy treści ze strony są wykorzystywane do ulepszania Gemini i innych produktów AI Google, niezależnie od standardowego indeksowania przez Googlebota. Pozwala wydawcom zarządzać dostępem do trenowania AI za pomocą robots.txt bez wpływu na widoczność w wyszukiwarce. Wprowadzony we wrześniu 2023 roku odpowiada na obawy wydawców dotyczące wykorzystania treści w rozwoju modeli AI. Google-Extended nie wpływa na pozycjonowanie SEO ani na obecność w wynikach wyszukiwania.
Google-Extended to token user-agenta, który pozwala wydawcom stron internetowych kontrolować, czy ich treści będą wykorzystywane do trenowania generatywnych modeli AI Google, w tym Gemini, Bard i Vertex AI. W odróżnieniu od Googlebota, który przeszukuje strony pod kątem indeksowania treści do wyników wyszukiwania, Google-Extended działa niezależnie i zbiera dane wyłącznie na potrzeby trenowania modeli AI i ich ugruntowania. Ten token user-agenta nie jest osobnym crawlerem HTTP — pełni funkcję mechanizmu kontrolnego w pliku robots.txt, który wydawcy mogą wykorzystać do strategicznego decydowania o udziale swoich treści w rozwoju AI. Wprowadzenie Google-Extended stanowi istotną zmianę w sposobie, w jaki wydawcy mogą zarządzać swoją własnością intelektualną w dobie sztucznej inteligencji.
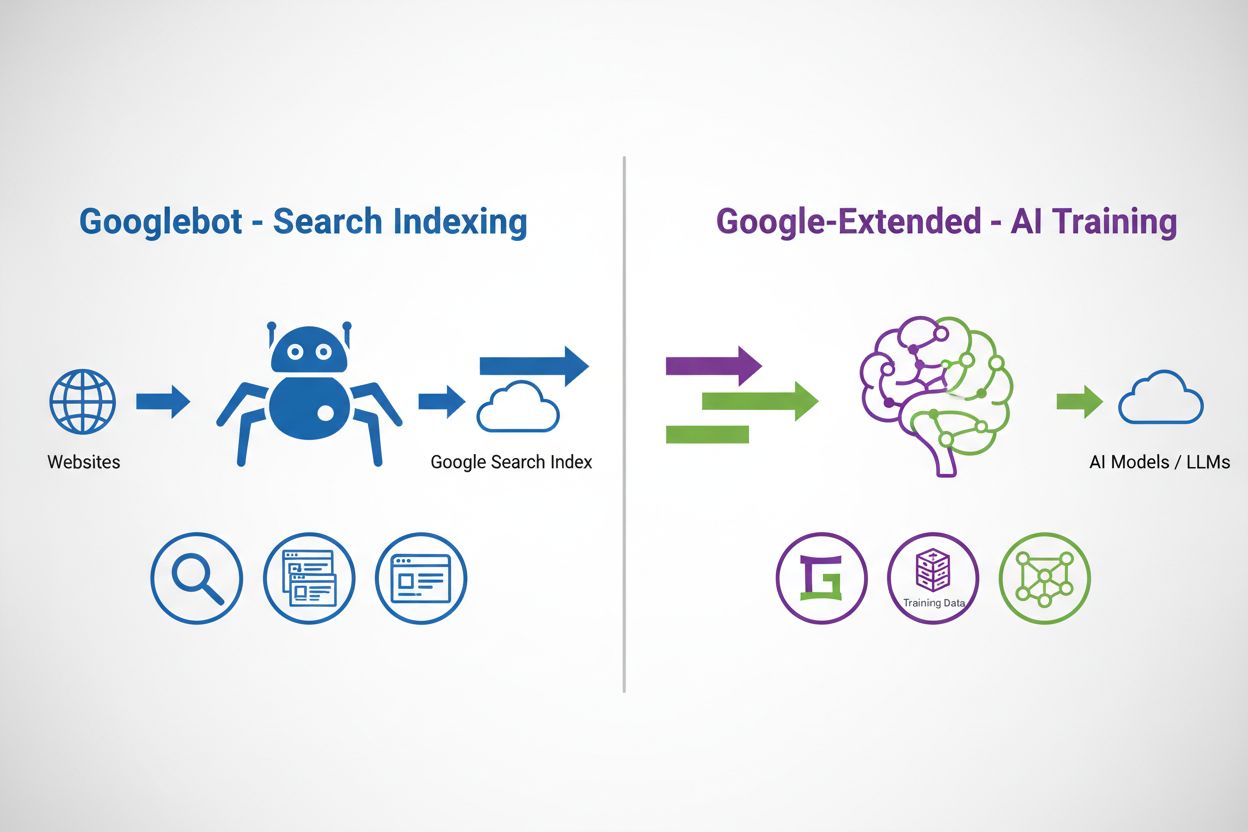
Google-Extended działa za pośrednictwem znanego protokołu robots.txt — pliku tekstowego umieszczanego w głównym katalogu strony, który przekazuje instrukcje crawlerom internetowym. W przeciwieństwie do innych crawlerów Google, takich jak Googlebot czy Googlebot-Image, Google-Extended nie posiada osobnego user-agenta HTTP — Google używa istniejących stringów user-agenta do crawlowań, a token user-agenta robots.txt służy wyłącznie do kontroli dostępu do trenowania AI. Dodając dyrektywę Google-Extended do pliku robots.txt, decydujesz, czy treści z Twojej strony mogą być wykorzystywane do trenowania przyszłych modeli Gemini i jako podstawa do ugruntowywania (dostarczania bieżących informacji dla zwiększenia trafności odpowiedzi AI). To rozdzielenie pozwala wydawcom zachować widoczność w wyszukiwarce, jednocześnie niezależnie kontrolując dostęp do trenowania AI.
| Crawler | Token user-agenta | Metoda żądania HTTP | Produkty objęte |
|---|---|---|---|
| Googlebot | Googlebot | Osobny user agent | Google Search, Images, News, Discover |
| Googlebot-Image | Googlebot-Image | Osobny user agent | Google Images, Discover, Video |
| Google-Extended | Google-Extended | Używa istniejących user agentów Google | Gemini Apps, Vertex AI, Grounding |
| Google-CloudVertexBot | Google-CloudVertexBot | Osobny user agent | Vertex AI Agents (na żądanie właściciela strony) |
Jednym z najważniejszych wyjaśnień dotyczących Google-Extended jest to, że nie ma on absolutnie żadnego wpływu na pozycje czy widoczność Twojej strony w Google Search. W kwietniu 2025 roku Google jednoznacznie zaktualizowało dokumentację, stwierdzając, że “Google-Extended nie wpływa na obecność strony w Google Search, ani nie jest sygnałem rankingowym w Google Search”. Oznacza to, że możesz zablokować Google-Extended bez obaw o utratę ruchu organicznego, widoczności w wyszukiwarce czy jakichkolwiek korzyści SEO, które obecnie uzyskujesz. Kluczowy jest tutaj rozdział funkcji: blokada Google-Extended jedynie uniemożliwia wykorzystanie treści do trenowania i ugruntowywania AI — nie wpływa na to, jak algorytmy Google oceniają czy pozycjonują Twoje strony. To rozróżnienie daje wydawcom możliwość podejmowania decyzji o zarządzaniu treściami zgodnie z modelem biznesowym i wartościami, bez konieczności wyboru między widocznością w wyszukiwarce a udziałem w trenowaniu AI.
Wdrożenie kontroli Google-Extended jest proste i wymaga tylko kilku linii w pliku robots.txt. Aby zablokować Google-Extended dostęp do Twoich treści, dodaj następującą dyrektywę w głównym katalogu swojej strony:
User-agent: Google-Extended
Disallow: /
To polecenie informuje crawlera Google do trenowania AI, że nie ma dostępu do żadnej części Twojej witryny. Jeśli chcesz, aby standardowe crawlery wyszukiwarek, takie jak Googlebot, nadal indeksowały Twoją stronę, blokując jednocześnie dostęp do trenowania AI, Twój kompletny plik robots.txt powinien wyglądać tak:
User-agent: Google-Extended
Disallow: /
User-agent: Googlebot
Disallow:
User-agent: Bingbot
Disallow:
Możesz także zastosować selektywną blokadę, określając wybrane katalogi lub typy plików. Na przykład, jeśli chcesz chronić tylko treści premium przed trenowaniem AI, a resztę udostępniać, możesz użyć:
User-agent: Google-Extended
Disallow: /premium/
Disallow: /subscription/
User-agent: Googlebot
Disallow:
Takie podejście pozwala precyzyjnie kontrolować, które części Twojej strony biorą udział w trenowaniu modeli AI, przy zachowaniu pełnej widoczności w wyszukiwarkach dla całej domeny.
Rozróżnienie między dostępem do trenowania AI a indeksowaniem wyszukiwarki jest kluczowe dla świadomego korzystania z Google-Extended. Gdy zezwalasz na Google-Extended, Twoje treści mogą być wykorzystywane do trenowania modeli Gemini i jako podstawa odpowiedzi generowanych przez AI — a więc mogą pojawiać się w odpowiedziach Bard, aplikacjach Gemini czy Vertex AI. Gdy blokujesz Google-Extended, Twoje treści są nadal w pełni indeksowane w Google Search i pojawiają się w tradycyjnych wynikach wyszukiwania, ale nie są uwzględniane w zbiorach danych do trenowania AI ani wykorzystywane do ugruntowania odpowiedzi AI. Przykładowe scenariusze:
Najważniejsze jest to, że oba crawlery działają niezależnie, dając wydawcom niespotykaną dotąd kontrolę nad tym, jak ich treści są wykorzystywane w różnych produktach i usługach Google.
Google wprowadził Google-Extended w odpowiedzi na rosnące obawy właścicieli stron, dziennikarzy i twórców treści dotyczące wykorzystywania ich pracy do trenowania modeli AI bez wyraźnej zgody czy wynagrodzenia. Wydawcy podnosili słuszne pytania o prawa autorskie, atrybucję treści, rozwodnienie marki i konflikty konkurencyjne — zwłaszcza gdy systemy AI trenowane na ich treściach mogą konkurować lub zastępować ich oryginalne oferty. Wielu twórców czuło, że ich własność intelektualna jest wykorzystywana w sposób niewidoczny, bez przejrzystości co do wkładu w rozwój AI czy możliwości rezygnacji. Google-Extended bezpośrednio odpowiada na te obawy, oferując jasny, udokumentowany sposób kontroli udziału treści w trenowaniu AI. To istotne uznanie ze strony Google, że twórcy mają prawo decydować o własności intelektualnej i współtworzą przyszłość technologii AI.
Decyzja o pozwoleniu lub blokadzie Google-Extended powinna być zgodna z modelem biznesowym, strategią treści oraz długofalową wizją. Twórcy i edukatorzy, którzy chcą maksymalizować widoczność i budować pozycję eksperta, powinni zazwyczaj zezwolić na Google-Extended, ponieważ obecność w odpowiedziach Gemini i generowanych przez AI może znacząco zwiększyć rozpoznawalność marki i autorytet. Wydawcy informacyjni i platformy subskrypcyjne powinni rozważyć blokadę Google-Extended, aby chronić treści zastrzeżone i utrzymywać przewagi konkurencyjne — szczególnie gdy ich model biznesowy opiera się na ekskluzywnym dostępie do oryginalnych materiałów. Firmy programistyczne i konsultingowe mogą wybrać podejście hybrydowe, pozwalając na Google-Extended dla ogólnych treści edukacyjnych, a blokując dostęp do autorskich metodologii czy studiów przypadków. Kluczowe pytanie nie brzmi, czy trenowanie AI jest dobre czy złe, ale: Czy Twoje treści zyskują na szerokiej widoczności w AI, czy wymagają ochrony jako przewaga konkurencyjna? Weź pod uwagę swoją publiczność, model przychodów i to, czy obecność w odpowiedziach AI generuje wartość, czy osłabia markę.
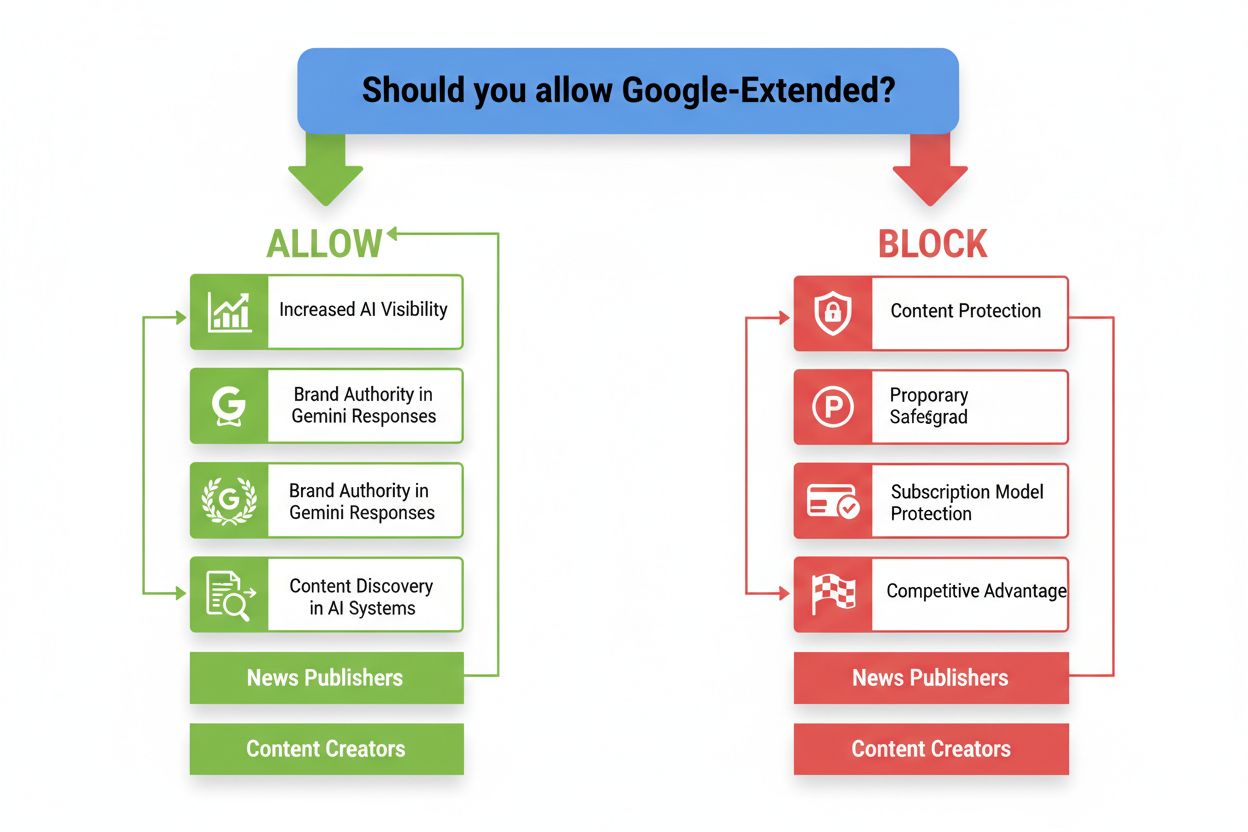
Obecnie nie istnieje publiczne, zaawansowane narzędzie umożliwiające dokładne monitorowanie, jak Twoje treści są wykorzystywane przez modele AI Google, co stanowi poważną lukę w przejrzystości. Mimo że Google-Extended umożliwia kontrolę dostępu, wydawcom brakuje szczegółowych informacji, w jaki sposób ich treści wpływają na odpowiedzi AI lub pojawiają się w wynikach Gemini. To ograniczenie skłoniło do rozwoju bardziej zaawansowanych narzędzi monitorujących — powstają platformy takie jak AmICited.com, które pomagają śledzić, jak marka i treści są cytowane i wykorzystywane w ekosystemie AI, zapewniając przejrzystość, której obecnie brakuje. W najbliższych latach można spodziewać się ewolucji branżowych standardów dotyczących atrybucji AI, licencjonowania treści i wynagradzania wydawców — podobnie jak działa to w tradycyjnych mediach. Na razie zaleca się podejście hybrydowe: blokuj Google-Extended dla treści wrażliwych lub zastrzeżonych, pozwalaj na niego dla materiałów przeznaczonych do szerokiej dystrybucji i korzystaj z narzędzi zewnętrznych do monitorowania obecności marki w AI. Wraz z coraz głębszą integracją AI z wyszukiwaniem i odkrywaniem informacji, możliwość kontrolowania i monitorowania udziału swoich treści w tych systemach będzie coraz cenniejsza.
Googlebot przeszukuje strony internetowe, aby indeksować treści do wyników wyszukiwania Google, podczas gdy Google-Extended to token user-agenta, który kontroluje, czy treści są wykorzystywane do trenowania AI w Gemini i Vertex AI. Googlebot wpływa na widoczność w wyszukiwarce, a Google-Extended – nie. Oba można kontrolować niezależnie za pomocą robots.txt, co pozwala wydawcom oddzielnie zarządzać indeksowaniem i trenowaniem AI.
Nie. Blokowanie Google-Extended nie ma absolutnie żadnego wpływu na pozycje Twojej strony w wyszukiwarce ani jej widoczność w Google. Google oficjalnie potwierdziło w kwietniu 2025 roku, że Google-Extended nie jest wykorzystywany jako sygnał rankingowy i nie wpływa na obecność w wyszukiwarce. Możesz bezpiecznie go zablokować, nie martwiąc się o utratę ruchu organicznego.
Dodaj do swojego pliku robots.txt następujące linie: User-agent: Google-Extended, a następnie Disallow: /. To uniemożliwi crawlerowi Google AI Training dostęp do Twoich treści. Możesz też zablokować konkretne katalogi lub typy plików. Pamiętaj, że ma to wpływ tylko na dostęp do trenowania AI, nie na indeksowanie przez wyszukiwarki.
Tak, oczywiście. Blokowanie Google-Extended jedynie uniemożliwia wykorzystanie Twoich treści do trenowania AI. Twoje treści będą nadal indeksowane przez Googlebota i pojawiać się normalnie w wynikach wyszukiwania Google. Oba crawlery działają niezależnie, dlatego kontrola jednego nie wpływa na drugiego.
Jeśli pozwolisz na Google-Extended, Twoje treści mogą być wykorzystywane do trenowania modeli Gemini i jako podstawa odpowiedzi generowanych przez AI. To oznacza, że mogą pojawiać się w odpowiedziach Bard, w aplikacjach Gemini i Vertex AI. Może to zwiększyć rozpoznawalność marki, ale też oznacza, że Twoje treści będą wykorzystywane w sposób, nad którym nie masz pełnej kontroli.
Tak. Możesz zastosować selektywną blokadę w robots.txt, chroniąc konkretne katalogi lub typy plików. Na przykład możesz zablokować Google-Extended dostęp do katalogów /premium/ lub /subscription/, a jednocześnie pozwolić na dostęp do pozostałych części strony. Daje to precyzyjną kontrolę nad tym, które treści biorą udział w trenowaniu AI.
Niektóre firmy AI wprowadziły własne tokeny user-agent lub crawlery, ale Google-Extended to mechanizm Google do kontroli dostępu do trenowania AI. Inne platformy AI, takie jak OpenAI, Anthropic czy Perplexity, mogą mieć inne rozwiązania. Obecnie nie istnieje uniwersalny standard, więc warto sprawdzić dokumentację każdej firmy AI pod kątem ich wymagań.
Nie, Google-Extended jest opcjonalny. Nie musisz dodawać żadnych dyrektyw dotyczących niego do swojego pliku robots.txt. Domyślnie, jeśli nic nie określisz, Google-Extended będzie przeszukiwał Twoją stronę do celów trenowania AI. Dyrektywy trzeba dodać tylko wtedy, gdy chcesz go zablokować lub wdrożyć selektywną blokadę wybranych treści.
Śledź cytowania swojej marki w platformach AI, takich jak Gemini, Perplexity i Google AI Overviews z AmICited. Uzyskaj wgląd w to, jak systemy AI odnoszą się do Twoich treści i mierz swoją widoczność w AI.
Dowiedz się, czym jest Google-Extended, jak działa i czy warto go zablokować w pliku robots.txt. Zrozum różnicę między kontrolą treningu AI a AI Overviews....
Dowiedz się więcej o Applebot-Extended, crawlerze internetowym Apple do trenowania AI. Zrozum, jak ocenia treści dla Apple Intelligence, jak go zablokować i jak...
Dowiedz się, czym jest Search Generative Experience (SGE), jak działają Google AI Overviews i dlaczego ta funkcja wyszukiwania oparta na AI zmienia SEO oraz wid...