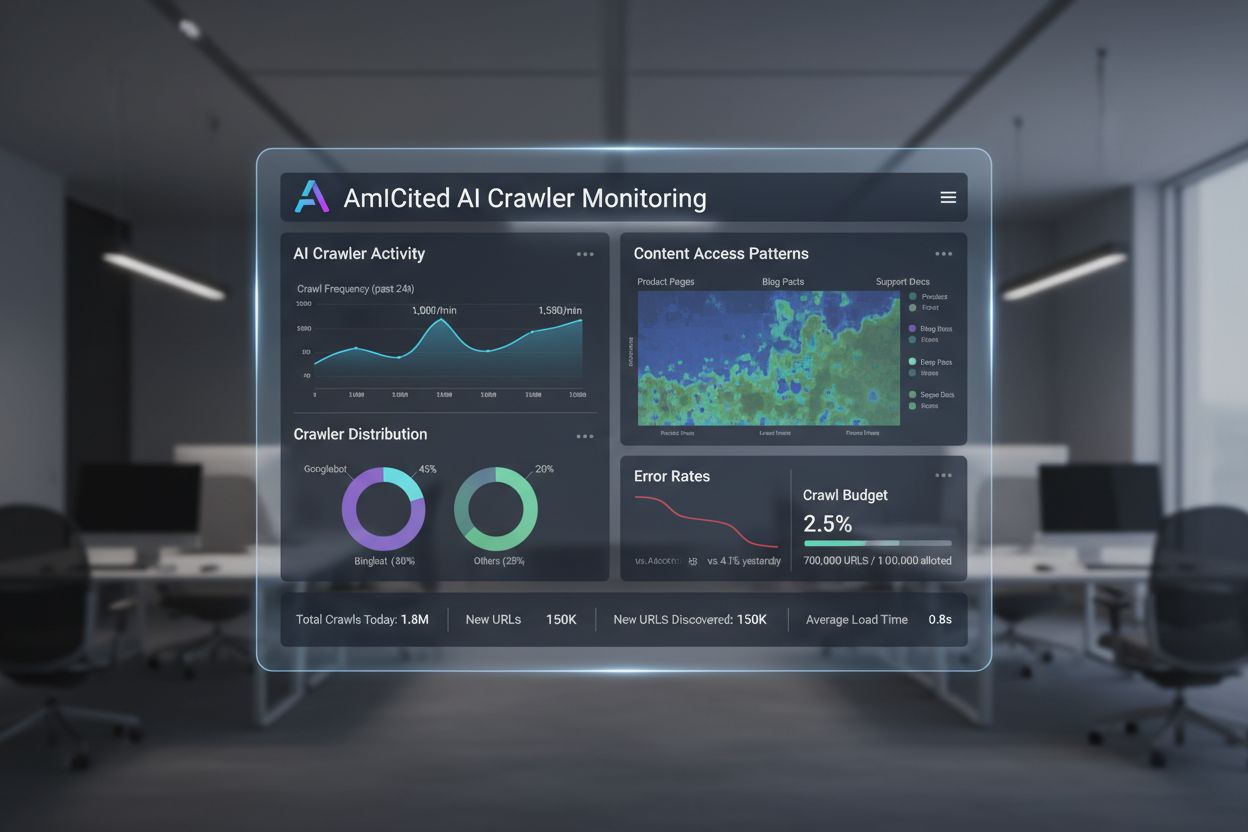
Analiza AI Crawl
Dowiedz się, czym jest analiza AI crawl i jak analiza logów serwera śledzi zachowanie crawlerów AI, wzorce dostępu do treści oraz widoczność w platformach wyszu...
9 min czytania

Analiza plików dziennika to proces badania dzienników dostępu serwera w celu zrozumienia, jak roboty wyszukiwarek i boty AI wchodzą w interakcje z witryną, ujawniając wzorce indeksowania, problemy techniczne oraz możliwości optymalizacji wpływające na efektywność SEO.
Analiza plików dziennika to proces badania dzienników dostępu serwera w celu zrozumienia, jak roboty wyszukiwarek i boty AI wchodzą w interakcje z witryną, ujawniając wzorce indeksowania, problemy techniczne oraz możliwości optymalizacji wpływające na efektywność SEO.
Analiza plików dziennika to systematyczne badanie dzienników dostępu serwera w celu zrozumienia, jak roboty wyszukiwarek, boty AI i użytkownicy wchodzą w interakcje ze stroną internetową. Dzienniki te są automatycznie generowane przez serwery WWW i zawierają szczegółowe zapisy każdego żądania HTTP wysłanego do Twojej witryny, w tym adres IP żądającego, znacznik czasu, żądany URL, kod statusu HTTP oraz ciąg user-agent. Dla specjalistów SEO analiza plików dziennika stanowi ostateczne źródło prawdy na temat zachowania robotów, ujawniając wzorce, których nie są w stanie wychwycić narzędzia powierzchowne, takie jak Google Search Console czy tradycyjne crawlery. W przeciwieństwie do symulowanych analiz czy zagregowanych danych analitycznych, dzienniki serwerowe dostarczają nieskorygowanych, własnych dowodów na to, co dokładnie wyszukiwarki i systemy AI robią na Twojej stronie w czasie rzeczywistym.
Znaczenie analizy plików dziennika wzrosło wykładniczo wraz z rozwojem krajobrazu cyfrowego. Przy ponad 51% globalnego ruchu internetowego generowanego obecnie przez boty (ACS, 2025), a roboty AI takie jak GPTBot, ClaudeBot i PerplexityBot stają się regularnymi gośćmi na stronach internetowych, zrozumienie zachowania robotów nie jest już opcjonalne — jest niezbędne dla utrzymania widoczności zarówno w tradycyjnych, jak i powstających platformach wyszukiwania opartych na AI. Analiza plików dziennika wypełnia lukę między tym, co myślisz, że dzieje się na Twojej stronie, a tym, co dzieje się naprawdę, umożliwiając podejmowanie decyzji opartych na danych, które mają bezpośredni wpływ na pozycje, szybkość indeksacji i ogólne wyniki organiczne.
Analiza plików dziennika od dekad stanowi fundament technicznego SEO, lecz jej znaczenie w ostatnich latach gwałtownie wzrosło. Historycznie specjaliści SEO polegali głównie na Google Search Console i narzędziach crawlerów stron trzecich, aby zrozumieć zachowanie wyszukiwarek. Jednak te narzędzia mają poważne ograniczenia: Google Search Console udostępnia tylko zagregowane, próbkowane dane z robotów Google; crawlery stron trzecich symulują zachowanie robotów, zamiast rejestrować rzeczywiste interakcje; żadne z tych narzędzi nie śledzi skutecznie robotów innych niż Google czy botów AI.
Pojawienie się platform wyszukiwania opartych na AI fundamentalnie zmieniło sytuację. Według badań Cloudflare z 2024 roku, Googlebot odpowiada za 39% całego ruchu robotów AI i wyszukiwarek, podczas gdy boty AI stanowią obecnie najszybciej rosnący segment. Same boty AI Meta generują 52% ruchu botów AI, ponad dwukrotnie więcej niż Google (23%) czy OpenAI (20%). Ta zmiana oznacza, że witryny odwiedza obecnie dziesiątki różnych typów botów, z których wiele nie przestrzega tradycyjnych protokołów SEO ani standardowych zasad robots.txt. Analiza plików dziennika to jedyna metoda, która daje pełny obraz, czyniąc ją niezbędnym narzędziem nowoczesnej strategii SEO.
Globalny rynek zarządzania logami ma wzrosnąć z 3 228,5 mln USD w 2025 roku do znacznie wyższych wycen w 2029 roku, rosnąc w tempie CAGR 14,6%. Wzrost ten odzwierciedla coraz większą świadomość przedsiębiorstw, że analiza logów jest kluczowa dla bezpieczeństwa, monitorowania wydajności i optymalizacji SEO. Organizacje inwestują coraz więcej w zautomatyzowane narzędzia do analizy logów oraz platformy zasilane AI, które są w stanie przetwarzać miliony wpisów w czasie rzeczywistym, przekształcając surowe dane w praktyczne wnioski biznesowe.
Gdy użytkownik lub bot żąda strony w Twojej witrynie, serwer WWW przetwarza to żądanie i rejestruje szczegółowe informacje o interakcji. Proces ten odbywa się automatycznie i nieprzerwanie, tworząc pełną ścieżkę audytową wszystkich aktywności serwera. Zrozumienie tego mechanizmu jest kluczowe do prawidłowej interpretacji danych z plików dziennika.
Typowy przepływ zaczyna się, gdy robot (czy to Googlebot, bot AI czy przeglądarka użytkownika) wysyła żądanie HTTP GET do Twojego serwera, zawierające ciąg user-agent identyfikujący nadawcę. Twój serwer odbiera to żądanie, przetwarza je i zwraca kod statusu HTTP (200 dla sukcesu, 404 dla nie znaleziono, 301 dla trwałego przekierowania itd.) wraz z żądaną treścią. Każda z tych interakcji jest zapisywana w pliku access.log serwera, tworząc wpis z datą, adresem IP, żądanym adresem URL, metodą HTTP, kodem statusu, rozmiarem odpowiedzi, referrerem oraz user-agentem.
Kody statusu HTTP mają szczególne znaczenie w analizie SEO. Kod 200 oznacza pomyślną dostawę strony; kody 3xx informują o przekierowaniach; 4xx to błędy po stronie klienta (jak 404 Not Found); 5xx to błędy serwera. Analizując rozkład tych kodów w logach, możesz zidentyfikować problemy techniczne uniemożliwiające robotom dostęp do treści. Na przykład, jeśli robot otrzymuje wielokrotnie odpowiedzi 404 przy próbie wejścia na ważne strony, oznacza to problem z niedziałającym linkiem lub brakującą treścią, który wymaga natychmiastowej interwencji.
Ciągi user-agent są równie istotne do identyfikacji, które boty odwiedzają Twoją stronę. Każdy robot ma unikalny user-agent. User-agent Googlebota zawiera “Googlebot/2.1”, GPTBot — “GPTBot/1.0”, a ClaudeBot — “ClaudeBot”. Parsując te ciągi, możesz segmentować dane logów według typu robota, odkrywając, które boty priorytetyzują jakie treści i jak różnią się ich wzorce indeksowania. Ta szczegółowa analiza pozwala na ukierunkowane strategie optymalizacji dla różnych platform wyszukiwania i systemów AI.
| Aspekt | Analiza plików dziennika | Google Search Console | Crawlery stron trzecich | Narzędzia analityczne |
|---|---|---|---|---|
| Źródło danych | Logi serwera (własne) | Dane indeksowania Google | Symulowane crawlery | Śledzenie zachowania użytkowników |
| Kompletność | 100% wszystkich żądań | Próbkowane, zagregowane dane | Tylko symulacje | Tylko ruch ludzki |
| Pokrycie botów | Wszystkie roboty (Google, Bing, boty AI) | Tylko Google | Symulowane roboty | Brak danych o botach |
| Dane historyczne | Pełna historia (zależnie od przechowywania) | Ograniczony zakres czasowy | Migawkowe dane z crawlów | Dostępne dane historyczne |
| Wgląd w czasie rzeczywistym | Tak (przy automatyzacji) | Opóźnione raportowanie | Nie | Opóźnione raportowanie |
| Widoczność budżetu indeksowania | Dokładne wzorce indeksowania | Ogólny podsumowanie | Szacunkowe | Nie dotyczy |
| Problemy techniczne | Szczegółowe (kody statusu, czas odpowiedzi) | Ograniczona widoczność | Symulowane problemy | Nie dotyczy |
| Śledzenie botów AI | Tak (GPTBot, ClaudeBot itd.) | Nie | Nie | Nie |
| Koszt | Bezpłatne (logi serwera) | Bezpłatne | Płatne narzędzia | Bezpłatne/Płatne |
| Złożoność wdrożenia | Średnia do wysokiej | Proste | Proste | Proste |
Analiza plików dziennika stała się niezbędna do zrozumienia, jak wyszukiwarki i systemy AI wchodzą w interakcje z Twoją stroną. W przeciwieństwie do Google Search Console, która pokazuje jedynie perspektywę Google i dane zagregowane, pliki dziennika rejestrują pełen obraz aktywności wszystkich robotów. Ten kompleksowy widok jest kluczowy do zidentyfikowania marnowania budżetu indeksowania, gdy wyszukiwarki poświęcają zasoby na indeksowanie małowartościowych stron zamiast ważnych treści. Badania pokazują, że duże strony często marnują 30-50% budżetu indeksowania na nieistotne adresy URL, takie jak paginacje, nawigacja fasetowa czy przestarzałe treści.
Wzrost znaczenia wyszukiwania opartego na AI sprawił, że analiza plików dziennika jest jeszcze ważniejsza. Gdy boty AI, takie jak GPTBot, ClaudeBot i PerplexityBot, regularnie odwiedzają witryny, zrozumienie ich zachowania jest kluczowe dla optymalizacji widoczności w odpowiedziach generowanych przez AI. Te boty często zachowują się inaczej niż tradycyjne roboty wyszukiwarek — mogą ignorować robots.txt, indeksować bardziej agresywnie lub skupiać się na określonych typach treści. Analiza plików dziennika to jedyna metoda ujawniania tych wzorców, umożliwiająca optymalizację pod kątem AI oraz zarządzanie dostępem botów poprzez ukierunkowane reguły.
Problemy techniczne SEO, które w przeciwnym razie pozostałyby niewykryte, można zidentyfikować poprzez analizę logów. Łańcuchy przekierowań, błędy serwera 5xx, wolne ładowanie stron i problemy z renderowaniem JavaScript — wszystko to pozostawia ślad w logach serwera. Analizując te wzorce, możesz priorytetyzować poprawki mające bezpośredni wpływ na dostępność strony dla robotów i szybkość indeksacji. Na przykład, jeśli logi pokazują, że Googlebot stale otrzymuje błędy 503 Service Unavailable podczas indeksowania określonego działu strony, wiesz dokładnie, gdzie skupić wysiłki techniczne.
Uzyskanie dostępu do logów serwera to pierwszy krok analizy plików dziennika, jednak procedura zależy od środowiska hostingowego. Dla serwerów własnych opartych na Apache lub NGINX, logi są zwykle przechowywane w /var/log/apache2/access.log lub /var/log/nginx/access.log. Możesz uzyskać do nich dostęp bezpośrednio przez SSH lub menedżer plików serwera. W przypadku zarządzanych hostingów WordPress (np. WP Engine, Kinsta) logi mogą być dostępne w panelu hostingu lub przez SFTP, choć niektórzy dostawcy ograniczają dostęp w celu ochrony wydajności serwera.
Sieci CDN (Content Delivery Networks), takie jak Cloudflare, AWS CloudFront czy Akamai, wymagają specjalnej konfiguracji, aby uzyskać dostęp do logów. Cloudflare oferuje usługę Logpush, która wysyła logi żądań HTTP do wskazanych zasobników (AWS S3, Google Cloud Storage, Azure Blob Storage) do pobrania i analizy. AWS CloudFront umożliwia standardowe logowanie, które można skonfigurować do przechowywania logów w zasobnikach S3. Te logi CDN są niezbędne do zrozumienia, jak boty wchodzą w interakcje z Twoją stroną, gdy treści są serwowane przez CDN, ponieważ rejestrują żądania na brzegu sieci, a nie na serwerze źródłowym.
Środowiska hostingu współdzielonego często oferują ograniczony dostęp do logów. Dostawcy tacy jak Bluehost czy GoDaddy mogą udostępniać częściowe logi przez cPanel, lecz zazwyczaj są one często rotowane i mogą nie zawierać kluczowych pól. Jeśli korzystasz z hostingu współdzielonego i potrzebujesz pełnej analizy logów, rozważ przejście na VPS lub hosting zarządzany, który zapewni pełny dostęp do logów.
Po uzyskaniu logów przygotowanie danych jest kluczowe. Surowe pliki dziennika zawierają żądania ze wszystkich źródeł — użytkowników, botów, scraperów i złośliwych aktorów. Do analizy SEO należy odfiltrować ruch nieistotny i skupić się na aktywności robotów wyszukiwarek i botów AI. Zazwyczaj obejmuje to:
Analiza plików dziennika ujawnia wnioski niewidoczne dla innych narzędzi SEO, tworząc fundament dla strategicznych decyzji optymalizacyjnych. Jednym z najcenniejszych jest analiza wzorców indeksowania, która pokazuje dokładnie, które strony i jak często są odwiedzane przez wyszukiwarki. Śledząc częstotliwość indeksowania w czasie, możesz ustalić, czy Google zwiększa, czy zmniejsza uwagę poświęcaną konkretnym sekcjom strony. Nagłe spadki częstotliwości mogą oznaczać problemy techniczne lub zmiany w postrzeganej ważności stron, a wzrosty — pozytywną reakcję Google na działania optymalizacyjne.
Efektywność budżetu indeksowania to kolejny kluczowy wniosek. Analizując stosunek udanych odpowiedzi (2xx) do błędów (4xx, 5xx), możesz zidentyfikować sekcje witryny, w których roboty napotykają na problemy. Jeśli dany katalog stale zwraca błędy 404, marnujesz budżet na niedziałające linki. Podobnie, jeśli roboty spędzają nieproporcjonalnie dużo czasu na stronach z paginacją lub nawigacją fasetową, marnujesz budżet na małowartościowe treści. Analiza logów pozwala to policzyć i ocenić potencjalny efekt optymalizacji.
Odkrywanie stron osieroconych to unikalna zaleta analizy plików dziennika. Strony osierocone to adresy URL bez linków wewnętrznych, które istnieją poza strukturą serwisu. Tradycyjne crawlery często ich nie wykrywają, ponieważ nie mogą ich odnaleźć przez linkowanie wewnętrzne. Jednak pliki dziennika pokazują, że wyszukiwarki mimo wszystko je indeksują — często dlatego, że są linkowane zewnętrznie lub istnieją w starych mapach strony. Identyfikując te adresy, możesz zdecydować, czy włączyć je do struktury strony, przekierować lub usunąć.
Analiza zachowania botów AI staje się coraz ważniejsza. Segmentując logi według user-agentów botów AI, możesz zobaczyć, które treści są przez nie priorytetyzowane, jak często odwiedzają witrynę i czy napotykają bariery techniczne. Przykładowo, jeśli GPTBot regularnie indeksuje Twoje strony FAQ, a rzadko blog, może to oznaczać, że AI uznaje treści typu FAQ za bardziej wartościowe do treningu. Ta wiedza może wpłynąć na strategię contentową i optymalizację widoczności w AI.
Skuteczna analiza plików dziennika wymaga zarówno odpowiednich narzędzi, jak i strategicznego podejścia. Log File Analyzer od Screaming Frog to jedno z najpopularniejszych dedykowanych narzędzi, oferujące intuicyjny interfejs do przetwarzania dużych logów, identyfikacji wzorców aktywności botów i wizualizacji danych indeksowania. Botify oferuje analizę logów na poziomie enterprise, powiązaną z metrykami SEO, dzięki czemu można korelować aktywność botów z pozycjami i ruchem. Bot Clarity od seoClarity integruje analizę logów bezpośrednio z platformą SEO, ułatwiając łączenie danych crawl z innymi wskaźnikami.
Dla organizacji z dużym ruchem lub złożoną infrastrukturą, platformy analizy logów zasilane AI (Splunk, Sumo Logic, Elastic Stack) oferują zaawansowane możliwości, takie jak automatyczne rozpoznawanie wzorców, wykrywanie anomalii i analityka predykcyjna. Platformy te są w stanie przetwarzać miliony wpisów w czasie rzeczywistym, automatycznie identyfikując nowe typy botów i oznaczając nietypową aktywność mogącą świadczyć o zagrożeniach lub problemach technicznych.
Najlepsze praktyki analizy plików dziennika obejmują:
W miarę wzrostu znaczenia wyszukiwania opartego na AI, monitoring botów AI za pomocą analizy plików dziennika stał się kluczową funkcją SEO. Śledząc, które boty AI odwiedzają Twoją stronę, do jakich treści mają dostęp i jak często indeksują, możesz zrozumieć, jak Twoje treści trafiają do narzędzi wyszukiwania AI i modeli generatywnych. Te dane pozwalają podejmować świadome decyzje o dopuszczeniu, blokowaniu lub ograniczaniu konkretnych botów AI za pomocą robots.txt lub nagłówków HTTP.
Optymalizacja budżetu indeksowania to być może najważniejsze zastosowanie analizy plików dziennika. Dla dużych stron z tysiącami i milionami adresów URL budżet indeksowania jest ograniczonym zasobem. Analizując logi, możesz zidentyfikować strony nadmiernie indeksowane w stosunku do ich znaczenia oraz takie, które powinny być odwiedzane częściej, ale nie są. Typowe przykłady marnowania budżetu to:
Rozwiązując te problemy — przez robots.txt, tagi kanoniczne, noindex czy poprawki techniczne — możesz skierować budżet indeksowania na wartościowe treści, poprawiając szybkość indeksacji i widoczność stron kluczowych dla Twojego biznesu.
Przyszłość analizy plików dziennika kształtowana jest przez dynamiczny rozwój wyszukiwania opartego na AI. Wraz z pojawianiem się coraz większej liczby botów AI i coraz bardziej wyrafinowanym ich zachowaniem, analiza logów będzie jeszcze ważniejsza dla zrozumienia, jak Twoje treści są odkrywane, pobierane i wykorzystywane przez systemy AI. Do najważniejszych trendów należą:
Analiza logów w czasie rzeczywistym zasilana uczeniem maszynowym pozwoli SEO-wcom wykrywać i reagować na problemy z indeksowaniem w ciągu minut, a nie dni. Systemy automatycznie wykryją nowe typy botów, oznaczą nietypowe wzorce i zasugerują działania optymalizacyjne bez udziału człowieka. Ta zmiana z analizy reaktywnej na proaktywną umożliwi ciągłe utrzymywanie optymalnej indeksowalności i widoczności.
Integracja z monitoringiem widoczności w AI połączy dane z logów z metrykami widoczności w wynikach AI. Zamiast analizować logi w oderwaniu, SEO-wcy będą korelować zachowanie robotów ze rzeczywistą widocznością w odpowiedziach generowanych przez AI, rozumiejąc dokładnie, jak wzorce indeksowania wpływają na pozycje w AI. Ta integracja zapewni bezprecedensowy wgląd w przepływ treści od indeksowania po szkolenie AI i odpowiedzi dla użytkowników.
Etyczne zarządzanie botami stanie się coraz ważniejsze, gdy organizacje będą musiały decydować, które boty AI mogą mieć dostęp do ich treści. Analiza logów umożliwi szczegółową kontrolę dostępu, pozwalając wydawcom dopuszczać korzystne boty AI, a blokować te, które nie przynoszą wartości lub nie zapewniają atrybucji. Standardy takie jak powstający protokół LLMs.txt zapewnią strukturalny sposób komunikacji zasad dostępu dla botów, a analiza logów pozwoli weryfikować ich przestrzeganie.
Analiza chroniąca prywatność będzie się rozwijać, równoważąc potrzebę szczegółowych danych o indeksowaniu z przepisami o ochronie danych, jak RODO. Zaawansowane metody anonimizacji i narzędzia ukierunkowane na prywatność umożliwią organizacjom wyciąganie wniosków z logów bez przechowywania czy udostępniania danych osobowych. Będzie to szczególnie ważne wraz z upowszechnianiem się analizy logów i zaostrzaniem przepisów o ochronie danych.
Konwergencja tradycyjnego SEO i optymalizacji pod kątem wyszukiwania AI oznacza, że analiza plików dziennika pozostanie filarem technicznej strategii SEO na długie lata. Firmy, które dziś opanują analizę logów, będą najlepiej przygotowane, by utrzymać widoczność i wyniki w miarę dalszej ewolucji wyszukiwania.
Analiza plików dziennika dostarcza pełnych, nieskorygowanych danych z Twojego serwera, rejestrując każde żądanie od wszystkich robotów, podczas gdy statystyki indeksowania w Google Search Console pokazują jedynie zagregowane, próbkowane dane z robotów Google. Pliki dziennika oferują szczegółowe dane historyczne oraz wgląd w zachowanie botów niebędących Google, w tym botów AI, takich jak GPTBot i ClaudeBot, dzięki czemu są bardziej kompleksowe w zrozumieniu rzeczywistego zachowania robotów i identyfikowaniu problemów technicznych, których GSC może nie wykrywać.
W przypadku witryn o dużym ruchu zaleca się cotygodniową analizę plików dziennika, aby wcześnie wykrywać problemy i monitorować zmiany wzorców indeksowania. Mniejsze strony korzystają z comiesięcznych przeglądów, które pozwalają ustalić trendy i wykryć nową aktywność botów. Niezależnie od wielkości strony, wdrożenie ciągłego monitoringu za pomocą narzędzi automatycznych pomaga wykrywać anomalie w czasie rzeczywistym, zapewniając szybką reakcję na marnowanie budżetu indeksowania lub problemy techniczne wpływające na widoczność w wyszukiwarce.
Tak, analiza plików dziennika to jeden z najskuteczniejszych sposobów śledzenia ruchu botów AI. Analizując ciągi user-agent i adresy IP w logach serwera, możesz zidentyfikować, które boty AI odwiedzają Twoją stronę, do jakich treści mają dostęp i jak często indeksują. Te dane są kluczowe do zrozumienia, jak Twoje treści trafiają do narzędzi wyszukiwania opartych na AI i modeli generatywnej sztucznej inteligencji, co pozwala zoptymalizować widoczność w AI i zarządzać dostępem botów za pomocą zasad w pliku robots.txt.
Analiza plików dziennika ujawnia szereg problemów technicznych SEO, w tym błędy indeksowania (kody statusu 4xx i 5xx), łańcuchy przekierowań, wolne ładowanie stron, osierocone strony bez linkowania wewnętrznego, marnowanie budżetu indeksowania na małowartościowe adresy URL, problemy z renderowaniem JavaScript oraz duplikacją treści. Identyfikuje także podszywające się boty i pomaga wykryć sytuacje, gdy prawdziwe roboty napotykają bariery dostępności, umożliwiając priorytetyzację poprawek mających bezpośredni wpływ na widoczność i indeksację.
Analiza plików dziennika pokazuje dokładnie, które strony i jak często są indeksowane przez wyszukiwarki, ujawniając, gdzie budżet indeksowania jest marnowany na małowartościowe treści, takie jak zarchiwizowane strony, nawigacja fasetowa czy przestarzałe adresy URL. Identyfikując te nieefektywności, możesz dostosować plik robots.txt, poprawić linkowanie wewnętrzne do priorytetowych stron oraz wdrożyć kanonikalizację, aby przekierować uwagę robotów na wartościowe treści, zapewniając, że wyszukiwarki skupią się na kluczowych stronach Twojego biznesu.
Pliki dziennika serwera zazwyczaj rejestrują adresy IP (źródła żądań), znaczniki czasu (kiedy nastąpiły żądania), metody HTTP (najczęściej GET lub POST), żądane adresy URL (dokładne strony), kody statusu HTTP (200, 404, 301, itp.), rozmiary odpowiedzi w bajtach, informacje o odsyłaczu oraz ciągi user-agent (identyfikujące robota lub przeglądarkę). Te kompleksowe dane pozwalają SEO-wcom dokładnie odtworzyć każde zdarzenie na serwerze i zidentyfikować wzorce wpływające na indeksowalność i pozycjonowanie.
Podszywające się boty udają legalne roboty wyszukiwarek, ale mają adresy IP niezgodne z oficjalnymi zakresami podanymi przez wyszukiwarkę. Aby je zidentyfikować, należy porównać ciągi user-agent (np. 'Googlebot') z oficjalnymi zakresami IP publikowanymi przez Google, Bing i inne wyszukiwarki. Narzędzia takie jak Log File Analyzer od Screaming Frog automatycznie weryfikują autentyczność botów. Podszywające się boty marnują budżet indeksowania i mogą obciążać serwer, dlatego zaleca się ich blokowanie za pomocą robots.txt lub reguł zapory sieciowej.
Zacznij śledzić, jak chatboty AI wspominają Twoją markę w ChatGPT, Perplexity i innych platformach. Uzyskaj praktyczne spostrzeżenia, aby poprawić swoją obecność w AI.
Dowiedz się, czym jest analiza AI crawl i jak analiza logów serwera śledzi zachowanie crawlerów AI, wzorce dostępu do treści oraz widoczność w platformach wyszu...
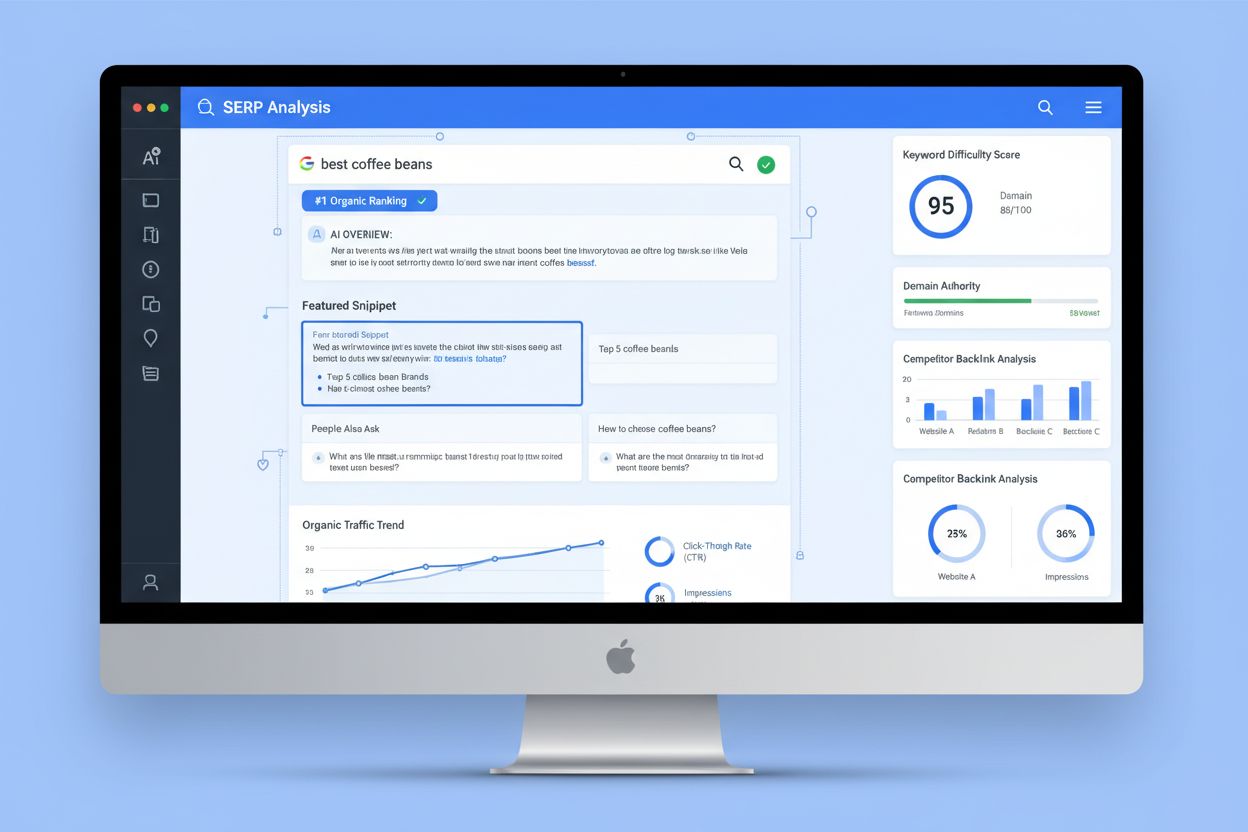
Analiza SERP to proces badania stron wyników wyszukiwania w celu zrozumienia trudności w rankingu, intencji wyszukiwania i strategii konkurencji. Dowiedz się, j...
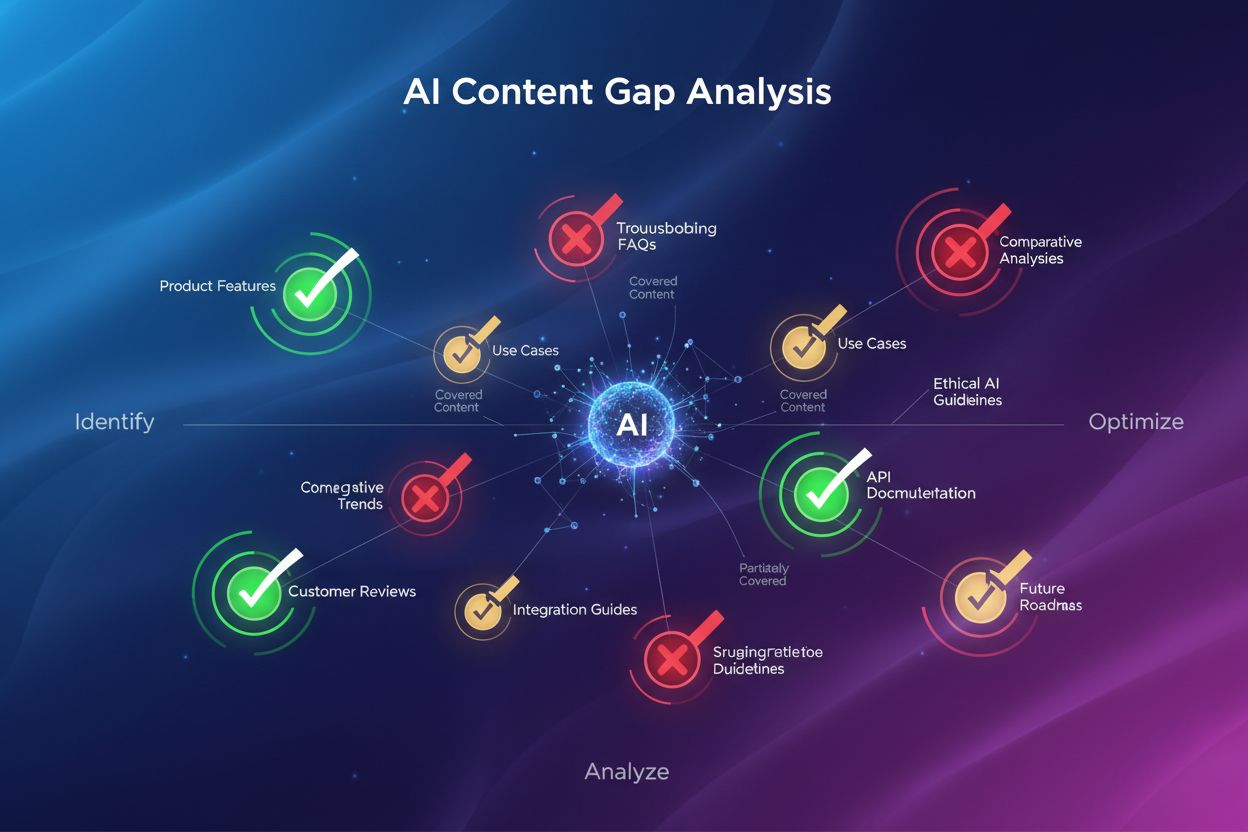
Dowiedz się, czym jest analiza luk w treści AI i jak zidentyfikować luki w treści, aby poprawić swoją widoczność w AI Overviews, ChatGPT i generatywnych wyszuki...