
GPT-4
GPT-4 to zaawansowany multimodalny LLM firmy OpenAI, łączący przetwarzanie tekstu i obrazu. Poznaj jego możliwości, architekturę i wpływ na monitorowanie AI ora...
12 min czytania

Architektura sieci neuronowej oparta na mechanizmach wielogłowej samo-uwagi, przetwarzająca dane sekwencyjne równolegle, co umożliwia rozwój nowoczesnych dużych modeli językowych, takich jak ChatGPT, Claude i Perplexity. Wprowadzona w artykule z 2017 roku ‘Attention is All You Need’, architektury transformerowe stały się technologią bazową praktycznie wszystkich najnowocześniejszych systemów AI.
Architektura sieci neuronowej oparta na mechanizmach wielogłowej samo-uwagi, przetwarzająca dane sekwencyjne równolegle, co umożliwia rozwój nowoczesnych dużych modeli językowych, takich jak ChatGPT, Claude i Perplexity. Wprowadzona w artykule z 2017 roku 'Attention is All You Need', architektury transformerowe stały się technologią bazową praktycznie wszystkich najnowocześniejszych systemów AI.
Architektura Transformera to rewolucyjny projekt sieci neuronowej, wprowadzony w artykule “Attention is All You Need” z 2017 roku przez badaczy z Google. Opiera się fundamentalnie na mechanizmie wielogłowej samo-uwagi, który umożliwia modelom równoległe przetwarzanie całych sekwencji danych, zamiast sekwencyjnego. Architektura składa się z warstw enkodera i dekodera ułożonych w stos, z których każda zawiera podwarstwy samo-uwagi i sieci feed-forward, połączone połączeniami rezydualnymi i normalizacją warstw. Architektura Transformera stała się technologiczną podstawą praktycznie wszystkich nowoczesnych dużych modeli językowych (LLM), w tym ChatGPT, Claude, Perplexity oraz Google AI Overviews, czyniąc ją prawdopodobnie najważniejszą innowacją sieci neuronowych ostatniej dekady.
Znaczenie Architektury Transformera wykracza daleko poza jej techniczną elegancję. Artykuł “Attention is All You Need” z 2017 roku został cytowany ponad 208 000 razy, co czyni go jednym z najbardziej wpływowych artykułów w historii uczenia maszynowego. Ta architektura fundamentalnie zmieniła sposób, w jaki systemy AI przetwarzają i rozumieją język, umożliwiając powstanie modeli o miliardach parametrów, zdolnych do zaawansowanego rozumowania, twórczego pisania i złożonego rozwiązywania problemów. Rynek korporacyjnych LLM-ów, zbudowany niemal wyłącznie na technologii transformera, był wyceniany na 6,7 miliarda dolarów w 2024 roku i prognozuje się, że będzie rósł w tempie 26,1% rocznie do 2034 roku, co pokazuje kluczowe znaczenie tej architektury dla współczesnej infrastruktury AI.
Rozwój Architektury Transformera stanowi przełomowy moment w historii deep learningu, będący efektem dekad badań nad sieciami neuronowymi do przetwarzania danych sekwencyjnych. Przed transformerami dominowały recurrent neural networks (RNN) i ich warianty, zwłaszcza long short-term memory (LSTM) w zadaniach przetwarzania języka naturalnego. Jednak architektury te miały zasadnicze ograniczenia: przetwarzały sekwencje sekwencyjnie, element po elemencie, co spowalniało trening i utrudniało wychwytywanie zależności między odległymi elementami w długich sekwencjach. Problem zanikającego gradientu dodatkowo ograniczał zdolność RNN-ów do uczenia się dalekosiężnych relacji, gdyż gradienty stawały się wykładniczo mniejsze podczas propagacji wstecz przez wiele warstw.
Wprowadzenie mechanizmów uwagi w 2014 roku przez Bahdanau i współpracowników było przełomem, pozwalając modelom skupiać się na istotnych częściach sekwencji wejściowej bez względu na odległość. Początkowo jednak uwaga była tylko rozszerzeniem RNN-ów, a nie ich zamiennikiem. Przełom nastąpił w 2017 roku, gdy w pracy o Transformerze zaproponowano, że attention is all you need—czyli cała architektura sieci neuronowej może opierać się wyłącznie na mechanizmach uwagi i warstwach feed-forward, całkowicie eliminując rekurencję. To spostrzeżenie okazało się rewolucyjne. Usunięcie przetwarzania sekwencyjnego umożliwiło masową równoległość, pozwalając badaczom trenować na bezprecedensowo dużych zbiorach danych z wykorzystaniem GPU i TPU. Największy model transformera w oryginalnej pracy wytrenowano na 8 GPU w 3,5 dnia, co pokazało, że skala i równoległość prowadzą do dramatycznej poprawy wydajności.
Po oryginalnej pracy nad transformerem architektura ta ewoluowała bardzo szybko. BERT (Bidirectional Encoder Representations from Transformers), wydany przez Google w 2019 roku, pokazał, że enkodery transformerowe mogą być trenowane wstępnie na ogromnych korpusach tekstu i dostrajane do różnych zadań podrzędnych. Największy BERT miał 345 milionów parametrów i był trenowany na 64 wyspecjalizowanych TPU przez cztery dni za około 7 000 dolarów, osiągając przy tym rekordowe wyniki w licznych testach rozumienia języka. Równolegle seria GPT od OpenAI obrała inną ścieżkę, wykorzystując wyłącznie dekodery transformerowe trenowane na zadaniach modelowania języka. GPT-2 z 1,5 miliardem parametrów zaskoczył środowisko badawcze, dowodząc, że samo modelowanie języka może prowadzić do powstania bardzo zaawansowanych systemów. GPT-3, posiadający 175 miliardów parametrów, wykazał zdolności emergentne—umiejętności pojawiające się dopiero przy odpowiedniej skali, takie jak few-shot learning i złożone rozumowanie—co fundamentalnie zmieniło oczekiwania względem możliwości systemów AI.
Architektura Transformera składa się z kilku współdziałających komponentów technicznych, które razem umożliwiają wydajne przetwarzanie równoległe i zaawansowane rozumienie kontekstu. Warstwa osadzania wejściowego (input embedding) przekształca dyskretne tokeny (słowa lub podjednostki słów) w ciągłe wektory, zazwyczaj o wymiarze 512 lub wyższym. Wektory te są następnie wzbogacane kodowaniem pozycyjnym, które dodaje informacje o pozycji każdego tokena w sekwencji za pomocą funkcji sinus i cosinus o różnych częstotliwościach. Informacje te są konieczne, ponieważ, w przeciwieństwie do RNN-ów, które zachowują kolejność dzięki rekurencji, transformatory przetwarzają wszystkie tokeny jednocześnie i potrzebują jawnych sygnałów pozycyjnych, by rozumieć kolejność i odległości między słowami.
Mechanizm samo-uwagi to innowacja architektoniczna odróżniająca transformatory od wszystkich wcześniejszych projektów sieci neuronowych. Dla każdego tokena w sekwencji wejściowej model oblicza trzy wektory: Query (reprezentujący, czego szuka token), Key (reprezentujący, jakie informacje zawiera każdy token) oraz Value (reprezentujący faktyczną przekazywaną informację). Mechanizm uwagi oblicza podobieństwo między wektorem Query każdego tokena a wszystkimi wektorami Key, normalizuje je za pomocą softmax, tworząc wagi uwagi, a następnie wykorzystuje te wagi do wyznaczenia ważonej sumy wektorów Value. Pozwala to każdemu tokenowi selektywnie skupiać się na innych istotnych tokenach, umożliwiając modelowi rozumienie kontekstu i relacji.
Wielogłowa uwaga (multi-head attention) rozszerza tę koncepcję, uruchamiając wiele mechanizmów uwagi równolegle (zwykle 8, 12 lub 16 głów). Każda głowa działa na innych liniowych projekcjach wektorów Query, Key i Value, co pozwala modelowi zwracać uwagę na różne typy relacji i wzorców w różnych podprzestrzeniach reprezentacji. Na przykład jedna głowa może skupiać się na relacjach składniowych, inna na semantycznych, a jeszcze inna na dalekosiężnych zależnościach. Wyniki wszystkich głów są łączone i liniowo transformowane, dostarczając modelowi bogatych, wieloaspektowych informacji kontekstowych. Podejście to okazało się niezwykle skuteczne—badania wykazały, że różne głowy uczą się specjalizować w różnych zjawiskach językowych.
Struktura enkoder-dekoder organizuje te mechanizmy uwagi w hierarchiczny potok przetwarzania. Enkoder składa się z kilku nakładających się warstw (zwykle 6 lub więcej), z których każda zawiera podwarstwę wielogłowej samo-uwagi oraz sieć feed-forward. Połączenia rezydualne wokół każdej podwarstwy umożliwiają przepływ gradientów bezpośrednio przez sieć podczas treningu, zwiększając stabilność i pozwalając budować głębsze architektury. Normalizacja warstw stosowana po każdej podwarstwie normalizuje aktywacje, utrzymując spójne skale w całej sieci. Dekoder ma podobną strukturę, ale zawiera dodatkową warstwę uwagi enkoder-dekoder, dzięki której dekoder może skupiać się na odpowiednich częściach wyjścia enkodera podczas generowania każdego tokena wyjściowego. W architekturach wyłącznie dekoderowych, takich jak GPT, dekoder generuje tokeny wyjściowe autoregresywnie, warunkując każdy nowy token na wszystkich wcześniej wygenerowanych.
| Aspekt | Architektura Transformera | RNN/LSTM | Konwolucyjne Sieci Neuronowe (CNN) |
|---|---|---|---|
| Sposób przetwarzania | Równoległe przetwarzanie całych sekwencji przy użyciu uwagi | Przetwarzanie sekwencyjne, element po elemencie | Lokalne operacje konwolucyjne na oknach o stałym rozmiarze |
| Dalekosiężne zależności | Doskonałe; uwaga może bezpośrednio łączyć odległe tokeny | Słabe; ograniczone przez zanikające gradienty i wąskie gardło sekwencyjności | Ograniczone; lokalne pole recepcyjne wymaga wielu warstw |
| Szybkość trenowania | Bardzo szybka; ogromna równoległość na GPU/TPU | Wolna; przetwarzanie sekwencyjne uniemożliwia równoległość | Szybka dla stałych rozmiarów wejść; mniej odpowiednie dla zmiennych sekwencji |
| Wymagania pamięciowe | Wysokie; kwadratowo rosnące względem długości sekwencji przez uwagę | Niższe; liniowe względem długości sekwencji | Umiarkowane; zależne od rozmiaru jądra i głębokości |
| Skalowalność | Doskonała; skaluje się do miliardów parametrów | Ograniczona; trudne trenowanie bardzo dużych modeli | Dobra dla obrazów; mniej odpowiednia dla sekwencji |
| Typowe zastosowania | Modelowanie języka, tłumaczenie maszynowe, generowanie tekstu | Szeregi czasowe, prognozowanie sekwencyjne (obecnie rzadziej) | Klasyfikacja obrazów, detekcja obiektów, wizja komputerowa |
| Przepływ gradientu | Stabilny; połączenia rezydualne umożliwiają bardzo głębokie sieci | Problematyczny; zanikające/eksplodujące gradienty | Zazwyczaj stabilny; lokalne połączenia wspomagają przepływ gradientu |
| Informacja o pozycji | Jawne kodowanie pozycyjne wymagane | Implicite poprzez przetwarzanie sekwencyjne | Implicite przez strukturę przestrzenną |
| Nowoczesne LLM-y | GPT, Claude, Llama, Granite, Perplexity | Rzadko używane we współczesnych LLM | Nie stosowane do modelowania języka |
Relacja między Architekturą Transformera a nowoczesnymi dużymi modelami językowymi jest fundamentalna i nierozerwalna. Każdy główny LLM wydany w ciągu ostatnich pięciu lat—w tym GPT-4 od OpenAI, Claude od Anthropic, Llama od Meta, Gemini od Google, Granite od IBM oraz modele AI Perplexity—opiera się na architekturze transformera. Zdolność tej architektury do efektywnej skalowalności zarówno z rozmiarem modelu, jak i danymi treningowymi okazała się kluczowa dla osiągnięcia możliwości definiujących współczesne systemy AI. Gdy badacze zwiększali rozmiar modeli od milionów do miliardów, a nawet setek miliardów parametrów, równoległość i mechanizmy uwagi transformera umożliwiały tę skalę bez proporcjonalnego wydłużenia czasu treningu.
Proces dekodowania autoregresywnego stosowany przez większość nowoczesnych LLM-ów to bezpośrednie zastosowanie architektury dekodera transformera. Podczas generowania tekstu modele te przetwarzają prompt wejściowy przez enkoder (lub w architekturach wyłącznie dekoderowych przez cały dekoder), a następnie generują tokeny wyjściowe jeden po drugim. Każdy nowy token generowany jest poprzez obliczenie rozkładów prawdopodobieństwa na całym słowniku za pomocą softmax, przy czym model wybiera token o najwyższym prawdopodobieństwie (lub próbkowany z rozkładu zgodnie z ustawieniami temperatury). Proces ten powtarzany setki lub tysiące razy daje spójny, kontekstowo trafny tekst. Mechanizm samo-uwagi umożliwia modelowi utrzymanie kontekstu na przestrzeni całej generowanej sekwencji, pozwalając tworzyć długie, logiczne fragmenty o spójnej tematyce, bohaterach i toku wydarzeń.
Zdolności emergentne obserwowane w dużych modelach transformerowych—umiejętności pojawiające się dopiero przy odpowiedniej skali, takie jak few-shot learning, chain-of-thought reasoning czy uczenie w kontekście—są bezpośrednią konsekwencją konstrukcji architektury transformera. Mechanizm wielogłowej uwagi pozwala uchwycić różnorodne relacje, a ogromna liczba parametrów i trening na zróżnicowanych danych umożliwia tym systemom wykonywanie zadań, do których nie były bezpośrednio uczone. Na przykład GPT-3 potrafił wykonywać działania arytmetyczne, pisać kod i odpowiadać na pytania mimo treningu wyłącznie na modelowaniu języka. Te właściwości uczyniły transformatory podstawą rewolucji AI, z zastosowaniami od konwersacyjnych AI i generowania treści po syntezę kodu i asystowanie w badaniach naukowych.
Mechanizm samo-uwagi to innowacja architektoniczna, która fundamentalnie wyróżnia transformatory i tłumaczy ich przewagę nad wcześniejszymi podejściami. By zrozumieć samo-uwagę, rozważmy wyzwanie interpretacji niejednoznacznych zaimków w języku. W zdaniu “Puchar nie mieści się w walizce, bo jest za duży”, zaimek “jest” może odnosić się do pucharu lub walizki, ale z kontekstu wynika, że chodzi o puchar. W zdaniu “Puchar nie mieści się w walizce, bo jest za mały” ten sam zaimek odnosi się do walizki. Model transformerowy musi nauczyć się rozwiązywać takie niejednoznaczności poprzez rozumienie relacji między słowami.
Samo-uwaga realizuje to w sposób matematycznie elegancki. Dla każdego tokena w sekwencji wejściowej model oblicza wektor Query poprzez wymnożenie embeddingu tokena przez wyuczoną macierz wag WQ. Podobnie oblicza wektory Key (z WK) oraz Value (z WV) dla wszystkich tokenów. Skor uwagi między Query tokena a Key innego tokena to iloczyn skalarny tych wektorów, znormalizowany przez pierwiastek z wymiaru klucza (typowo √64 ≈ 8). Surowe wyniki są przekazywane przez funkcję softmax, która zamienia je w znormalizowane wagi uwagi sumujące się do 1. Ostatecznie wyjście dla każdego tokena to ważona suma wszystkich wektorów Value, gdzie wagi to oceny uwagi. Pozwala to każdemu tokenowi selektywnie agregować informacje od pozostałych, przy czym wagi są uczone podczas treningu, by odzwierciedlać sensowne relacje.
Elegancja matematyczna samo-uwagi umożliwia efektywne obliczenia. Cały proces można zapisać jako operacje macierzowe: Attention(Q, K, V) = softmax(QK^T / √d_k)V, gdzie Q, K i V to macierze zawierające odpowiednio wszystkie wektory zapytań, kluczy i wartości. Taka postać pozwala na akcelerację GPU, umożliwiając równoległe przetwarzanie całych sekwencji zamiast sekwencyjnego. Sekwencję 512 tokenów można przetworzyć w przybliżeniu w tym samym czasie co pojedynczy token w RNN-ie, czyniąc transformatory o rzędy wielkości szybszymi w treningu. Ta wydajność, połączona ze zdolnością wychwytywania dalekich zależności, tłumaczy dominację architektury transformera w modelowaniu języka.
Wielogłowa uwaga rozszerza mechanizm samo-uwagi, uruchamiając wiele operacji uwagi równolegle, z których każda uczy się innych aspektów relacji między tokenami. Typowy transformer z 8 głowami uwagi projektuje wejściowe embeddingi liniowo w 8 różnych podprzestrzeni reprezentacji, każda z własnymi macierzami wag Query, Key i Value. Każda głowa niezależnie oblicza wagi uwagi i generuje wektory wyjściowe. Wektory te są następnie łączone i liniowo transformowane przez końcową macierz wag, tworząc wyjście wielogłowej uwagi. Architektura ta pozwala modelowi jednocześnie zwracać uwagę na informacje z różnych podprzestrzeni reprezentacji i na różnych pozycjach.
Badania analizujące wytrenowane modele transformerowe wykazały, że różne głowy specjalizują się w różnych zjawiskach językowych. Niektóre głowy skupiają się na relacjach składniowych, ucząc się zwracać uwagę na gramatycznie powiązane słowa (np. czasowniki na swoje podmioty i dopełnienia). Inne skupiają się na relacjach semantycznych, zwracając uwagę na słowa o powiązanych znaczeniach. Jeszcze inne wychwytują dalekosiężne zależności, skupiając się na słowach oddalonych w sekwencji, lecz powiązanych semantycznie. Niektóre głowy uczą się nawet skupiać głównie na bieżącym tokenie, działając niejako jako operacje tożsamościowe. Specjalizacja ta wyłania się samoistnie podczas treningu, bez wyraźnego nadzoru, co dowodzi siły architektury wielogłowej do uczenia się różnorodnych, uzupełniających reprezentacji.
Liczba głów uwagi to kluczowy hiperparametr architektury. Większe modele zwykle stosują więcej głów (16, 32 lub więcej), co pozwala uchwycić bogatsze relacje. Całkowity wymiar obliczeń uwagi zazwyczaj pozostaje stały, więc więcej głów oznacza niższy wymiar na głowę. To kompromis między zaletami wielu podprzestrzeni reprezentacji a wydajnością obliczeniową. Podejście wielogłowe okazało się tak skuteczne, że stało się standardem w praktycznie wszystkich współczesnych implementacjach transformera—od BERT i GPT po architektury do wizji, dźwięku czy zadań multimodalnych.
Oryginalna architektura transformera, opisana w pracy “Attention is All You Need”, wykorzystuje strukturę enkoder-dekoder zoptymalizowaną do zadań sekwencja-do-sekwencji, takich jak tłumaczenie maszynowe. Enkoder przetwarza sekwencję wejściową i tworzy sekwencję bogatych w kontekst reprezentacji. Każda warstwa enkodera składa się z dwóch głównych komponentów: podwarstwy wielogłowej samo-uwagi, która pozwala tokenom zwracać uwagę na inne tokeny wejściowe, oraz sieci feed-forward, która stosuje tę samą nieliniową transformację do każdej pozycji niezależnie. Podwarstwy te są połączone połączeniami rezydualnymi (tzw. skip connections), które dodają wejście do wyjścia każdej podwarstwy. Takie rozwiązanie, inspirowane sieciami rezydualnymi w wizji komputerowej, umożliwia trenowanie bardzo głębokich sieci przez bezpośredni przepływ gradientów.
Dekoder generuje sekwencję wyjściową token po tokenie, korzystając z informacji zarówno z enkodera, jak i wcześniej wygenerowanych tokenów. Każda warstwa dekodera zawiera trzy główne komponenty: maskowaną podwarstwę samo-uwagi, która pozwala tokenom zwracać uwagę tylko na wcześniejsze tokeny (zapobiegając “podglądaniu” przyszłych tokenów podczas treningu), podwarstwę uwagi enkoder-dekoder, która pozwala tokenom dekodera zwracać uwagę na wyjścia enkodera, oraz sieć feed-forward. Maskowanie w samo-uwadze jest kluczowe: uniemożliwia przepływ informacji z pozycji przyszłych do przeszłych, zapewniając, że predykcje dla pozycji i zależą wyłącznie od znanych wyjść dla pozycji <i. Ta struktura autoregresywna jest niezbędna do generowania sekwencji token po tokenie.
Architektura enkoder-dekoder okazała się szczególnie skuteczna w zadaniach, gdzie wejście i wyjście mają różne struktury lub długości, takich jak tłumaczenie maszynowe, streszczanie czy odpowiadanie na pytania. Jednak nowoczesne LLM-y, takie jak GPT, stosują architektury wyłącznie dekoderowe, gdzie pojedynczy stos warstw dekodera przetwarza zarówno prompt wejściowy, jak i generuje wyjście. To uproszczenie redukuje złożoność modelu i okazało się równie lub nawet bardziej efektywne w zadaniach modelowania językowego, prawdopodobnie dlatego, że model może się nauczyć wykorzystywać samo-uwagę do przetwarzania wejścia i generacji wyjścia w jednolity sposób.
Kluczowym wyzwaniem w architekturze transformera jest reprezentacja kolejności tokenów w sekwencji. W przeciwieństwie do RNN-ów, które zachowują kolejność przez rekurencję, transformatory przetwarzają wszystkie tokeny równolegle i nie mają wbudowanego pojęcia pozycji. Bez wyraźnych informacji o położeniu transformer potraktowałby sekwencję “Kot usiadł na macie” identycznie jak “macie na usiadł Kot”, co byłoby katastrofalne dla rozumienia języka. Rozwiązaniem jest kodowanie pozycyjne, które dodaje zależne od pozycji wektory do embeddingów tokenów jeszcze przed przetwarzaniem.
Oryginalna praca o transformerze stosuje sinusoidalne kodowanie pozycyjne, gdzie wektor pozycyjny dla pozycji pos i wymiaru i jest obliczany jako:
Funkcje sinus i cosinus tworzą unikalny wzorzec dla każdej pozycji, z różnymi częstotliwościami dla różnych wymiarów. Niższe częstotliwości (mniejsze i) zmieniają się powoli, wychwytując dalekosiężne informacje pozycyjne, a wyższe szybko, wychwytując szczegóły lokalizacji. Rozwiązanie to ma kilka zalet: naturalnie uogólnia się na sekwencje dłuższe niż widziane podczas treningu, zapewnia płynne przejścia pozycji i pozwala modelowi uczyć się relacji pozycji względnych. Wektory kodowania pozycyjnego są po prostu dodawane do embeddingów tokenów przed pierwszą warstwą uwagi, a model uczy się korzystać z tych informacji podczas treningu.
Architektura Transformera przetwarza całe sekwencje równolegle, wykorzystując samo-uwagę, podczas gdy RNN i LSTM przetwarzają sekwencje sekwencyjnie, element po elemencie. Ta równoległość sprawia, że trenowanie transformerów jest znacznie szybsze i pozwala lepiej uchwycić dalekie zależności między odległymi słowami lub tokenami. Transformatory unikają również problemu zanikającego gradientu, który ograniczał RNN-y, dzięki czemu mogą efektywnie uczyć się z bardzo długich sekwencji.
Samo-uwaga oblicza trzy wektory (Query, Key i Value) dla każdego tokena w sekwencji wejściowej. Wektor Query jednego tokena porównywany jest z wektorami Key wszystkich tokenów w celu określenia istotności, które są normalizowane za pomocą softmax. Te wagi uwagi są następnie stosowane do wektorów Value, tworząc reprezentacje świadome kontekstu. Mechanizm ten pozwala każdemu tokenowi 'zwracać uwagę' na inne istotne tokeny w sekwencji, umożliwiając modelowi rozumienie kontekstu i relacji.
Główne komponenty to: (1) Wektory wejściowe i kodowanie pozycyjne do reprezentacji tokenów i ich pozycji, (2) Warstwy wielogłowej samo-uwagi obliczające uwagę w wielu podprzestrzeniach reprezentacji, (3) Sieci neuronowe typu feed-forward stosowane niezależnie do każdej pozycji, (4) Stos enkoderów przetwarzających sekwencje wejściowe, (5) Stos dekoderów generujących sekwencje wyjściowe oraz (6) Połączenia rezydualne i normalizacja warstw dla stabilności uczenia. Komponenty te współdziałają, umożliwiając wydajne przetwarzanie równoległe i rozumienie kontekstu.
Architektura Transformera doskonale sprawdza się w LLM-ach, ponieważ umożliwia równoległe przetwarzanie całych sekwencji, znacząco skracając czas uczenia w porównaniu do sekwencyjnych RNN-ów. Dzięki samo-uwadze skuteczniej wychwytuje dalekie zależności, pozwalając modelom rozumieć kontekst w obrębie całych dokumentów. Architektura ta wydajnie skalowalna jest do większych zbiorów danych i liczby parametrów, co okazało się kluczowe dla trenowania modeli o miliardach parametrów, wykazujących zdolności emergentne.
Wielogłowa uwaga to równoległe uruchamianie wielu mechanizmów uwagi (zwykle 8 lub 16 głów), z których każdy działa w innej podprzestrzeni reprezentacji. Każda głowa uczy się zwracać uwagę na różne typy relacji i wzorców w danych. Wyniki wszystkich głów są łączone i liniowo transformowane, co pozwala modelowi uchwycić różnorodne informacje kontekstowe. Podejście to znacząco zwiększa zdolność modelu do rozumienia złożonych relacji i poprawia ogólną wydajność.
Kodowanie pozycyjne dodaje informacje o położeniu tokenów do wektorów wejściowych, wykorzystując funkcje sinus i cosinus o różnych częstotliwościach. Ponieważ transformatory przetwarzają wszystkie tokeny równolegle (w przeciwieństwie do sekwencyjnych RNN), potrzebują jawnych informacji o pozycji, aby rozumieć kolejność słów. Wektory kodowania pozycyjnego są dodawane do wektorów tokenów przed przetwarzaniem, co pozwala modelowi nauczyć się, jak pozycja wpływa na znaczenie i uogólniać na sekwencje dłuższe niż te widziane podczas treningu.
Enkoder przetwarza sekwencję wejściową i tworzy bogate reprezentacje kontekstowe przez wiele warstw samo-uwagi i sieci feed-forward. Dekoder generuje sekwencję wyjściową token po tokenie, wykorzystując uwagę enkoder-dekoder, by skupić się na istotnych fragmentach wejścia. Struktura ta jest szczególnie przydatna w zadaniach sekwencja-do-sekwencji, takich jak tłumaczenie maszynowe, ale współczesne LLM-y często używają architektur wyłącznie dekoderowych do zadań generacji tekstu.
Architektura Transformera napędza systemy AI generujące odpowiedzi w takich platformach jak ChatGPT, Claude, Perplexity czy Google AI Overviews. Zrozumienie, jak transformatory przetwarzają i generują tekst, jest kluczowe dla platform monitoringu AI, takich jak AmICited, które śledzą, gdzie marki i domeny pojawiają się w odpowiedziach generowanych przez AI. Zdolność architektury do rozumienia kontekstu i generowania spójnego tekstu bezpośrednio wpływa na to, jak marki są wspominane i reprezentowane w wynikach AI.
Zacznij śledzić, jak chatboty AI wspominają Twoją markę w ChatGPT, Perplexity i innych platformach. Uzyskaj praktyczne spostrzeżenia, aby poprawić swoją obecność w AI.
GPT-4 to zaawansowany multimodalny LLM firmy OpenAI, łączący przetwarzanie tekstu i obrazu. Poznaj jego możliwości, architekturę i wpływ na monitorowanie AI ora...
Poznaj BERT-a, jego architekturę, zastosowania i aktualną istotność. Dowiedz się, jak BERT wypada na tle nowoczesnych alternatyw i dlaczego pozostaje niezbędny ...
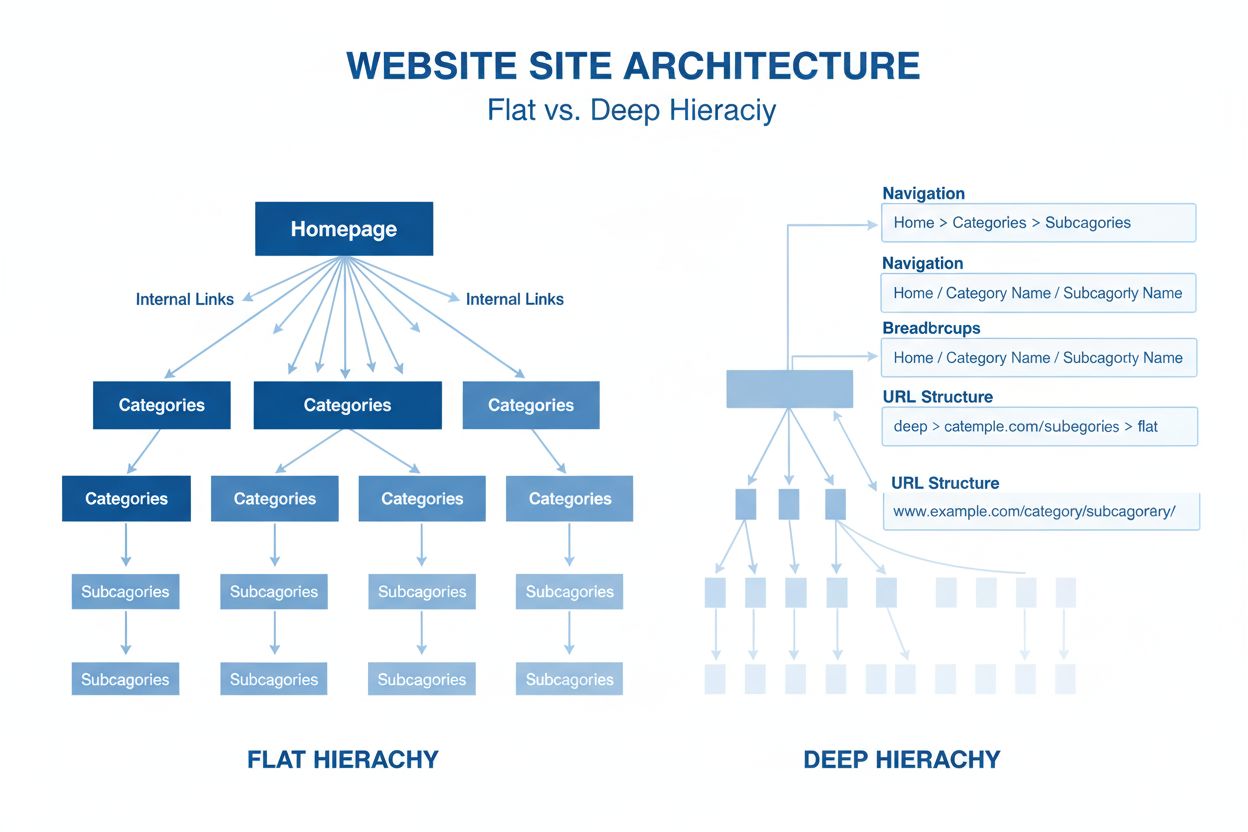
Architektura strony to hierarchiczna organizacja stron i treści witryny. Dowiedz się, jak prawidłowa struktura strony poprawia SEO, doświadczenie użytkownika or...