Auditoria de Acesso de Crawlers de IA: Os Bots Certos Estão Vendo Seu Conteúdo?
Aprenda como auditar o acesso de crawlers de IA ao seu site. Descubra quais bots podem ver seu conteúdo e corrija bloqueios que impedem a visibilidade em IA como ChatGPT, Perplexity e outros buscadores de IA.
Publicado em Jan 3, 2026.Última modificação em Jan 3, 2026 às 3:24 am
Por que Auditorias de Crawlers de IA são Importantes
O cenário de busca e descoberta de conteúdo está mudando drasticamente. Com ferramentas de busca alimentadas por IA como ChatGPT, Perplexity e Google AI Overviews crescendo exponencialmente, a visibilidade do seu conteúdo para crawlers de IA tornou-se tão crítica quanto a otimização tradicional para motores de busca. Se bots de IA não conseguem acessar seu conteúdo, seu site se torna invisível para milhões de usuários que dependem dessas plataformas para obter respostas. A pressão nunca foi tão grande: enquanto o Google pode revisitar seu site se algo der errado, crawlers de IA operam em um paradigma diferente—e perder aquela primeira visita crítica pode significar meses de visibilidade perdida e oportunidades perdidas de citações, tráfego e autoridade de marca.
Como Crawlers de IA Diferem dos Bots Tradicionais
Crawlers de IA operam segundo regras fundamentalmente diferentes dos bots do Google e Bing para os quais você otimizou ao longo dos anos. A diferença mais crítica: crawlers de IA não renderizam JavaScript, o que significa que conteúdos dinâmicos carregados por scripts client-side são invisíveis para eles—um contraste marcante com as sofisticadas capacidades de renderização do Google. Além disso, crawlers de IA visitam sites com frequência muito maior, às vezes 100 vezes mais do que motores de busca tradicionais, criando tanto oportunidades quanto desafios para recursos do servidor. Diferente do modelo de indexação do Google, crawlers de IA não mantêm um índice persistente que é atualizado; em vez disso, eles rastreiam sob demanda quando usuários consultam seus sistemas. Isso significa que não há fila de reindexação, nem Search Console para solicitar novo rastreamento, nem uma segunda chance se seu site falhar na primeira impressão. Entender essas diferenças é essencial para otimizar sua estratégia de conteúdo.
Feature
Crawlers de IA
Bots Tradicionais
Renderização de JavaScript
Não (apenas HTML estático)
Sim (renderização completa)
Frequência de Rastreamento
Muito alta (100x+ mais frequente)
Moderada (semanal/mensal)
Capacidade de Reindexação
Nenhuma (apenas sob demanda)
Sim (atualizações contínuas)
Requisitos de Conteúdo
HTML puro, marcação schema
Flexível (processa conteúdo dinâmico)
Bloqueio por User-Agent
Específico por bot (GPTBot, ClaudeBot, etc.)
Genérico (Googlebot, Bingbot)
Estratégia de Cache
Snapshots de curto prazo
Manutenção de índice de longo prazo
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Principais Bloqueadores que Impedem o Acesso de IA
Seu conteúdo pode estar invisível para crawlers de IA por motivos que você nunca considerou. Aqui estão os principais obstáculos que impedem bots de IA de acessar e compreender seu conteúdo:
Conteúdo pesado em JavaScript: Se seu site depende de JavaScript client-side para renderizar textos, imagens ou dados estruturados, crawlers de IA não verão isso—eles apenas processam HTML estático
Ausência de marcação schema: Sem dados estruturados apropriados (JSON-LD, microdata), crawlers de IA têm dificuldade em entender contexto, autoria, datas de publicação e relações de conteúdo
Problemas de infraestrutura técnica: Resposta lenta do servidor, erros 5xx, cadeias de redirecionamento e Core Web Vitals ruins podem fazer crawlers abandonarem seu site no meio do rastreamento
Conteúdo restrito ou com paywall: Conteúdos atrás de login, paywall ou desafios CAPTCHA são completamente inacessíveis para crawlers de IA
Regras robots.txt excessivamente restritivas: Bloquear diretórios inteiros ou user-agents impede crawlers de acessarem conteúdos que você realmente deseja que sejam vistos
Bloqueios de firewall e segurança: Regras de WAF (Web Application Firewall), bloqueio de IP ou limitação de taxa podem identificar erroneamente crawlers de IA como ameaças e bloqueá-los completamente
Entendendo robots.txt e Regras de User-Agent
Seu arquivo robots.txt é o principal mecanismo para controlar quais bots de IA podem acessar seu conteúdo, operando com regras de User-Agent específicas para cada crawler. Cada plataforma de IA utiliza strings de user-agent distintas—GPTBot da OpenAI, ClaudeBot da Anthropic, PerplexityBot da Perplexity—e você pode permitir ou bloquear cada um de forma independente. Esse controle granular permite decidir quais sistemas de IA podem treinar ou citar seu conteúdo, o que é crucial para proteger informações proprietárias ou gerenciar preocupações competitivas. Contudo, muitos sites bloqueiam crawlers de IA sem querer, por meio de regras amplas demais criadas para bots antigos, ou por falha em implementar regras adequadas.
Veja um exemplo de como configurar seu robots.txt para diferentes bots de IA:
# Permitir o GPTBot da OpenAI
User-agent: GPTBot
Allow: /
# Bloquear o ClaudeBot da Anthropic
User-agent: ClaudeBot
Disallow: /
# Permitir Perplexity mas restringir certos diretórios
User-agent: PerplexityBot
Allow: /
Disallow: /private/
Disallow: /admin/
# Regra padrão para todos os outros bots
User-agent: *
Allow: /
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
A Impressão Crítica Inicial
Ao contrário do Google, que rastreia e reindexa continuamente seu site, crawlers de IA operam em modo “one-shot”—eles visitam quando um usuário consulta o sistema e, se seu conteúdo não estiver acessível naquele momento, você perdeu a oportunidade. Essa diferença fundamental exige que seu site esteja tecnicamente pronto desde o primeiro dia; não há período de carência, nem segunda chance para corrigir problemas antes que a visibilidade seja afetada. Uma má experiência no primeiro rastreamento—seja por falhas na renderização de JavaScript, ausência de marcação schema ou erros de servidor—pode resultar na exclusão do seu conteúdo das respostas geradas por IA por semanas ou meses. Não há opção manual de reindexação, nem botão “Solicitar Indexação” em um console, o que torna o monitoramento e otimização proativos inegociáveis. A pressão para acertar na primeira vez nunca foi tão alta.
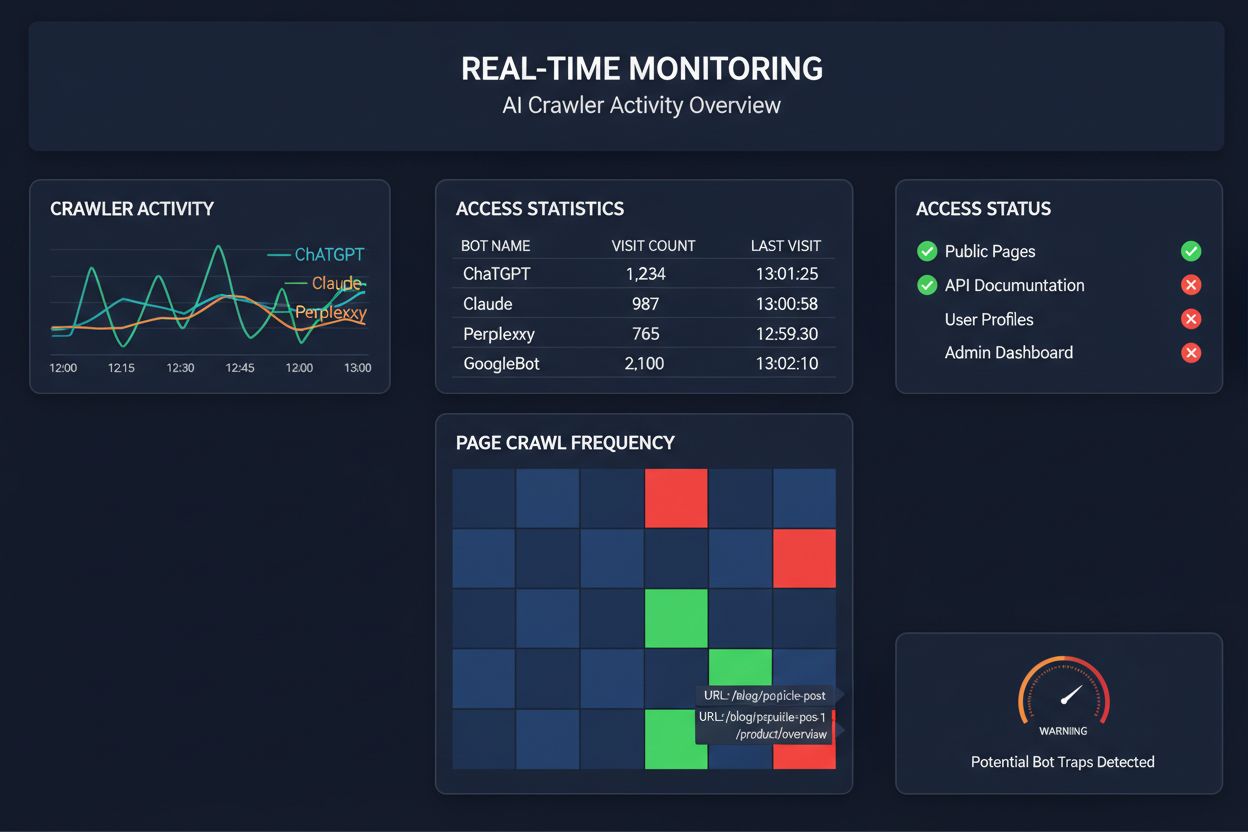
Monitoramento em Tempo Real vs. Rastreamentos Agendados
Confiar em rastreamentos agendados para monitorar o acesso de crawlers de IA é como checar sua casa para incêndios uma vez por mês—você perderá os momentos críticos em que os problemas ocorrem. O monitoramento em tempo real detecta problemas no exato momento em que acontecem, permitindo que você aja antes que seu conteúdo se torne invisível para sistemas de IA. Auditorias agendadas, normalmente feitas semanal ou mensalmente, criam pontos cegos perigosos onde seu site pode estar falhando para crawlers de IA por dias sem seu conhecimento. Soluções em tempo real rastreiam o comportamento dos crawlers continuamente, alertando sobre falhas de renderização de JavaScript, erros de schema, bloqueios de firewall ou problemas de servidor assim que acontecem. Essa abordagem proativa transforma sua auditoria de um check de conformidade reativo em uma estratégia ativa de gestão de visibilidade. Com tráfego de crawlers de IA potencialmente 100 vezes maior que o de motores de busca tradicionais, o custo de perder até algumas horas de acessibilidade pode ser substancial.
Ferramentas e Soluções para Auditorias de Crawlers de IA
Várias plataformas já oferecem ferramentas especializadas para monitorar e otimizar o acesso de crawlers de IA. Cloudflare AI Crawl Control fornece gerenciamento de tráfego de bots de IA em nível de infraestrutura, permitindo a definição de limites de taxa e políticas de acesso. Conductor oferece dashboards de monitoramento abrangentes que rastreiam como diferentes crawlers de IA interagem com seu conteúdo. Elementive foca em auditorias técnicas de SEO com atenção especial às exigências dos crawlers de IA. AdAmigo e MRS Digital oferecem consultoria e monitoramento especializados para visibilidade em IA. Porém, para monitoramento contínuo e em tempo real, especificamente projetado para rastrear padrões de acesso de crawlers de IA e alertar para problemas antes que afetem a visibilidade, o AmICited se destaca como solução dedicada. O AmICited é especializado em monitorar quais sistemas de IA estão acessando seu conteúdo, com que frequência rastreiam e se estão enfrentando barreiras técnicas. Esse foco especializado no comportamento de crawlers de IA—em vez de métricas tradicionais de SEO—faz dele uma ferramenta essencial para organizações comprometidas com visibilidade em IA.
Processo de Auditoria Passo a Passo
Conduzir uma auditoria abrangente de crawlers de IA requer uma abordagem sistemática. Passo 1: Estabeleça um ponto de partida verificando seu arquivo robots.txt e identificando quais bots de IA você está permitindo ou bloqueando atualmente. Passo 2: Audite sua infraestrutura técnica testando a acessibilidade do seu site para crawlers que não executam JavaScript, verificando o tempo de resposta do servidor e garantindo que o conteúdo crítico seja servido em HTML estático. Passo 3: Implemente e valide marcação schema em seu conteúdo, garantindo que autoria, datas de publicação, tipo de conteúdo e outros metadados estejam adequadamente estruturados em formato JSON-LD. Passo 4: Monitore o comportamento dos crawlers usando ferramentas como o AmICited para rastrear quais bots de IA estão acessando seu site, com que frequência e se estão enfrentando erros. Passo 5: Analise os resultados revisando logs de rastreamento, identificando padrões de falhas e priorizando correções com base no impacto. Passo 6: Implemente correções começando pelos problemas de maior impacto, como falhas na renderização de JavaScript ou ausência de schema, depois siga para otimizações secundárias. Passo 7: Estabeleça monitoramento contínuo para detectar novos problemas antes que afetem a visibilidade, configurando alertas para falhas de rastreamento ou bloqueios de acesso.
Resultados Rápidos para Melhorar a Rastreamento por IA
Você não precisa de uma reformulação completa para melhorar o acesso dos crawlers de IA—várias mudanças de alto impacto podem ser implementadas rapidamente. Sirva o conteúdo crítico em HTML puro em vez de depender da renderização por JavaScript; se for necessário usar JavaScript, garanta que textos e metadados importantes também estejam presentes na carga inicial de HTML. Adicione marcação schema abrangente usando o formato JSON-LD, incluindo schema de artigo, informações de autor, datas de publicação e relações de conteúdo—isso ajuda crawlers de IA a entender contexto e atribuir corretamente o conteúdo. Garanta informações claras de autoria via schema e por linhas de autor, já que sistemas de IA cada vez mais priorizam citar fontes autorizadas. Monitore e otimize os Core Web Vitals (Largest Contentful Paint, First Input Delay, Cumulative Layout Shift), pois páginas lentas podem ser abandonadas pelos crawlers antes de serem processadas. Revise e atualize seu robots.txt para não bloquear inadvertidamente bots de IA que você deseja que acessem seu conteúdo. Corrija problemas técnicos como cadeias de redirecionamento, links quebrados e erros de servidor que possam fazer crawlers abandonarem seu site durante o rastreamento.
Monitorando Diferentes Bots de IA
Nem todos os crawlers de IA têm o mesmo propósito, e entender essas diferenças ajuda a tomar decisões informadas sobre controle de acesso. GPTBot (OpenAI) é usado principalmente para coleta de dados de treinamento e aprimoramento de capacidades do modelo, sendo relevante se você deseja que seu conteúdo influencie respostas do ChatGPT. OAI-SearchBot (OpenAI) rastreia especificamente para fins de citação em buscas, ou seja, é o bot responsável por incluir seu conteúdo nas respostas integradas à busca do ChatGPT. ClaudeBot (Anthropic) desempenha funções semelhantes para o Claude, assistente de IA da Anthropic. PerplexityBot (Perplexity) rastreia para citação no motor de busca alimentado por IA da Perplexity, que se tornou uma importante fonte de tráfego para muitos publishers. Cada bot tem padrões de rastreamento, frequência e propósitos distintos—alguns focam em coleta de dados para treinamento, outros em citações em tempo real para busca. Decidir quais bots permitir ou bloquear deve estar alinhado com sua estratégia de conteúdo: se você quer citações nos resultados de busca por IA, permita os bots específicos para busca; se há preocupação com uso para treinamento, você pode bloquear bots de coleta de dados e permitir apenas os de busca. Essa abordagem detalhada de gestão de bots é muito mais sofisticada do que a mentalidade tradicional de “permitir tudo” ou “bloquear tudo”.
Perguntas frequentes
O que é uma auditoria de crawler de IA?
Uma auditoria de crawler de IA é uma avaliação abrangente da acessibilidade do seu site para bots de IA como ChatGPT, Claude e Perplexity. Ela identifica bloqueios técnicos, problemas de renderização de JavaScript, ausência de marcação de schema e outros fatores que impedem que crawlers de IA acessem e compreendam seu conteúdo. A auditoria fornece recomendações acionáveis para melhorar sua visibilidade em mecanismos de busca e respostas alimentados por IA.
Com que frequência devo auditar o acesso dos crawlers de IA ao meu site?
Recomendamos realizar uma auditoria abrangente pelo menos trimestralmente, ou sempre que você fizer alterações significativas na infraestrutura técnica do site, na estrutura de conteúdo ou no arquivo robots.txt. No entanto, o monitoramento contínuo em tempo real é ideal para detectar problemas imediatamente quando ocorrerem. Muitas organizações utilizam ferramentas de monitoramento automatizado que alertam sobre falhas de rastreamento em tempo real, complementadas por auditorias aprofundadas trimestrais.
Qual a diferença entre bloquear e permitir crawlers de IA?
Permitir crawlers de IA significa que seu conteúdo pode ser acessado, analisado e potencialmente citado por sistemas de IA, o que pode aumentar sua visibilidade em respostas e recomendações geradas por IA. Bloquear crawlers de IA impede que eles acessem seu conteúdo, protegendo informações proprietárias, mas potencialmente reduzindo sua visibilidade nos resultados de busca de IA. A escolha certa depende dos objetivos do seu negócio, sensibilidade do conteúdo e posicionamento competitivo.
Posso bloquear bots de IA específicos e permitir outros?
Sim, absolutamente. Seu arquivo robots.txt permite controle granular através de regras de User-Agent. Você pode bloquear o GPTBot enquanto permite o PerplexityBot, ou permitir bots focados em busca (como OAI-SearchBot) enquanto bloqueia bots de coleta de dados (como o GPTBot). Essa abordagem detalhada permite otimizar sua estratégia de conteúdo com base em quais plataformas de IA são mais relevantes para seu negócio.
O que significa se crawlers de IA não conseguem acessar meu conteúdo?
Se crawlers de IA não conseguem acessar seu conteúdo, significa que seu site está efetivamente invisível para mecanismos de busca e plataformas de respostas alimentadas por IA. Seu conteúdo não será citado, recomendado ou incluído em respostas geradas por IA, mesmo que seja altamente relevante. Isso pode resultar em perda de tráfego, menor visibilidade da marca e oportunidades perdidas de estabelecer autoridade nos resultados de busca por IA.
Como saber quais bots de IA estão visitando meu site?
Você pode verificar os logs do seu servidor em busca de strings de User-Agent de crawlers de IA conhecidos (GPTBot, ClaudeBot, PerplexityBot, etc.), ou usar ferramentas de monitoramento especializadas como o AmICited, que rastreiam a atividade de crawlers de IA em tempo real. Essas ferramentas mostram quais bots estão acessando seu site, com que frequência estão rastreando, quais páginas estão visitando e se estão encontrando erros ou bloqueios.
Devo bloquear crawlers de IA do meu site?
Isso depende da sua situação específica. Se seu conteúdo é proprietário, sensível, ou você está preocupado com o uso como dados de treinamento, o bloqueio pode ser adequado. No entanto, se você deseja visibilidade nos resultados de busca de IA e citações de sistemas de IA, permitir crawlers é essencial. Muitas organizações adotam uma abordagem intermediária: permitem bots focados em busca que geram citações, enquanto bloqueiam bots de coleta de dados.
Qual o impacto do JavaScript no acesso dos crawlers de IA?
Crawlers de IA não renderizam JavaScript, ou seja, qualquer conteúdo carregado dinamicamente por scripts client-side é invisível para eles. Se seu site depende fortemente de JavaScript para conteúdo crítico, navegação ou dados estruturados, os crawlers de IA verão apenas o HTML bruto e perderão informações importantes. Isso pode impactar significativamente como seu conteúdo é compreendido e representado em respostas de IA. Servir conteúdo crítico em HTML estático é essencial para a rastreabilidade por IA.
Monitore o Acesso dos Crawlers de IA com AmICited
Obtenha insights em tempo real sobre quais bots de IA estão acessando seu conteúdo e como eles veem seu site. Inicie sua auditoria gratuita hoje e garanta que sua marca seja visível em todas as plataformas de busca por IA.
Renderização JavaScript e IA: Por Que o Conteúdo do Lado do Cliente Não É Visto
Saiba por que crawlers de IA como o ChatGPT não conseguem ver conteúdo renderizado via JavaScript e como tornar seu site visível para sistemas de IA. Descubra e...
Como Testar o Acesso de Crawlers de IA ao Seu Site
Aprenda como testar se crawlers de IA como ChatGPT, Claude e Perplexity conseguem acessar o conteúdo do seu site. Descubra métodos de teste, ferramentas e as me...
Como Identificar Crawlers de IA em Logs de Servidor: Guia Completo de Detecção
Aprenda como identificar e monitorar crawlers de IA como GPTBot, PerplexityBot e ClaudeBot em seus logs de servidor. Descubra strings de user-agent, métodos de ...
9 min de leitura
Consentimento de Cookies Usamos cookies para melhorar sua experiência de navegação e analisar nosso tráfego. See our privacy policy.