Otimização de Sitemaps para Crawlers de IA
Aprenda como otimizar sitemaps XML para crawlers de IA como GPTBot e ClaudeBot. Domine as melhores práticas de sitemap para aumentar a visibilidade em respostas...
13 min de leitura

Guia completo de referência sobre crawlers e bots de IA. Identifique GPTBot, ClaudeBot, Google-Extended e mais de 20 outros crawlers de IA com user agents, taxas de rastreamento e estratégias de bloqueio.
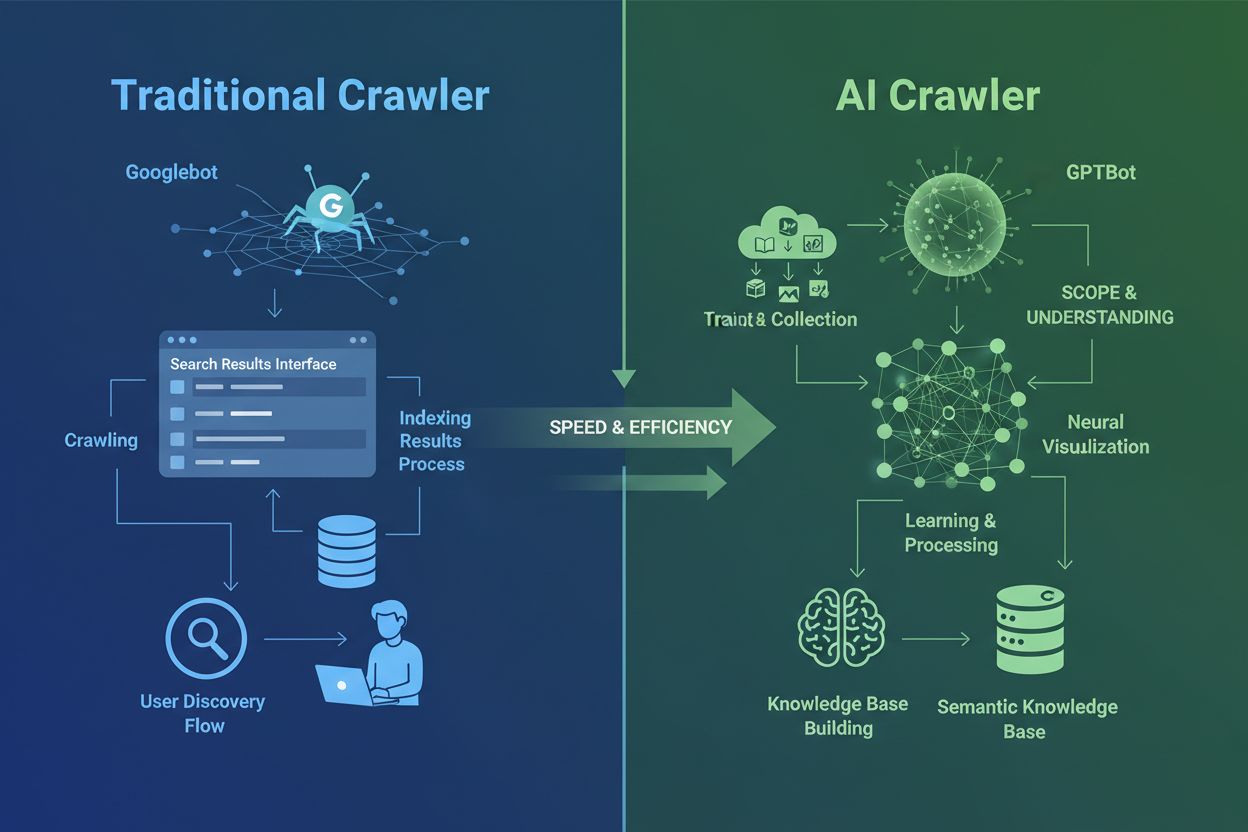
Crawlers de IA são fundamentalmente diferentes dos crawlers tradicionais de mecanismos de busca que você conhece há décadas. Enquanto Googlebot e Bingbot indexam conteúdo para ajudar usuários a encontrar informações nos resultados de busca, crawlers de IA como GPTBot e ClaudeBot coletam dados especificamente para treinar grandes modelos de linguagem. Essa distinção é crucial: crawlers tradicionais criam caminhos para a descoberta humana, enquanto crawlers de IA alimentam as bases de conhecimento de sistemas de inteligência artificial. Segundo dados recentes, os crawlers de IA já respondem por quase 80% de todo o tráfego de bots em sites, com crawlers de treinamento consumindo grandes volumes de conteúdo enquanto enviam pouco ou nenhum tráfego de referência de volta aos editores. Diferente dos crawlers tradicionais, que têm dificuldades com sites dinâmicos pesados em JavaScript, crawlers de IA usam machine learning avançado para entender o conteúdo de forma contextual, como um leitor humano. Eles conseguem interpretar significado, tom e objetivo sem necessidade de atualizações manuais de configuração. Isso representa um salto quântico na tecnologia de indexação web que exige dos proprietários de sites uma reformulação completa das estratégias de gestão de crawlers.
O cenário dos crawlers de IA tornou-se cada vez mais concorrido à medida que grandes empresas de tecnologia correm para construir seus próprios grandes modelos de linguagem. OpenAI, Anthropic, Google, Meta, Amazon, Apple e Perplexity operam vários crawlers especializados, cada um atendendo a funções distintas em seus respectivos ecossistemas de IA. As empresas implementam múltiplos crawlers porque diferentes propósitos exigem comportamentos distintos: alguns crawlers focam na coleta em massa para treinamento, outros fazem indexação em tempo real, e outros buscam conteúdo sob demanda quando usuários requisitam. Entender esse ecossistema exige reconhecer três principais categorias de crawler: crawlers de treinamento que coletam dados para aprimorar modelos, crawlers de busca e citação que indexam conteúdo para experiências de busca baseadas em IA, e fetchers ativados por usuários quando solicitam conteúdo via assistentes de IA. A tabela a seguir traz uma visão geral dos principais players:
| Empresa | Nome do Crawler | Função Principal | Taxa de Rastreamento | Dados de Treinamento |
|---|---|---|---|---|
| OpenAI | GPTBot | Treinamento de modelo | 100 páginas/hora | Sim |
| OpenAI | ChatGPT-User | Requisições em tempo real | 2400 páginas/hora | Não |
| OpenAI | OAI-SearchBot | Indexação de busca | 150 páginas/hora | Não |
| Anthropic | ClaudeBot | Treinamento de modelo | 500 páginas/hora | Sim |
| Anthropic | Claude-User | Acesso web em tempo real | <10 páginas/hora | Não |
| Google-Extended | Treinamento Gemini AI | Variável | Sim | |
| Gemini-Deep-Research | Recurso de pesquisa | <10 páginas/hora | Não | |
| Meta | Meta-ExternalAgent | Treinamento de modelo IA | 1100 páginas/hora | Sim |
| Amazon | Amazonbot | Melhoria de serviço | 1050 páginas/hora | Sim |
| Perplexity | PerplexityBot | Indexação de busca | 150 páginas/hora | Não |
| Apple | Applebot-Extended | Treinamento de IA | <10 páginas/hora | Sim |
| Common Crawl | CCBot | Dataset aberto | <10 páginas/hora | Sim |
A OpenAI opera três crawlers distintos, cada um com funções específicas no ecossistema do ChatGPT. Compreender esses crawlers é essencial porque o GPTBot da OpenAI é um dos crawlers de IA mais agressivos e amplamente implantados na internet:
GPTBot – Crawler de treinamento principal da OpenAI que coleta sistematicamente dados publicamente disponíveis para treinar e aprimorar modelos GPT, incluindo ChatGPT e GPT-4o. Opera a cerca de 100 páginas por hora e respeita as diretrizes do robots.txt. A OpenAI publica endereços IP oficiais em https://openai.com/gptbot.json para fins de verificação.
ChatGPT-User – Este crawler aparece quando um usuário real interage com o ChatGPT e solicita a navegação em uma página específica. Opera em taxas muito mais altas (até 2400 páginas/hora) pois é ativado por ações de usuários, não por rastreamento sistemático. O conteúdo acessado pelo ChatGPT-User não é usado para treinamento de modelos, sendo valioso para visibilidade em tempo real nos resultados de busca do ChatGPT.
OAI-SearchBot – Projetado especificamente para a busca do ChatGPT, este crawler indexa conteúdo para resultados de busca em tempo real sem coletar dados para treinamento. Opera a cerca de 150 páginas por hora e ajuda seu conteúdo a aparecer nos resultados de busca do ChatGPT quando usuários fazem perguntas relevantes.
Os crawlers da OpenAI respeitam as diretrizes do robots.txt e operam em faixas de IP verificadas, tornando sua gestão relativamente simples comparada a concorrentes menos transparentes.
A Anthropic, responsável pelo Claude AI, opera múltiplos crawlers com diferentes propósitos e níveis de transparência. A empresa tem sido menos aberta com documentação em relação à OpenAI, mas o comportamento dos seus crawlers é bem documentado por meio da análise de logs de servidores:
ClaudeBot – Crawler principal de treinamento da Anthropic, coleta conteúdo da web para aprimorar a base de conhecimento e capacidades do Claude. Opera a cerca de 500 páginas por hora e é o principal alvo caso você queira evitar que seu conteúdo seja usado no treinamento do Claude. O user agent completo é Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com).
Claude-User – Ativado quando usuários do Claude solicitam acesso web em tempo real, esse crawler busca conteúdo sob demanda em volume mínimo. Respeita autenticação e não tenta burlar restrições de acesso, sendo relativamente benigno em termos de consumo de recursos.
Claude-SearchBot – Suporta capacidades internas de busca do Claude, ajudando seu conteúdo a aparecer nos resultados de busca do Claude quando usuários fazem perguntas. Opera em volumes muito baixos e serve principalmente para indexação, não para treinamento.
Uma preocupação crítica com os crawlers da Anthropic é a proporção crawl/referral: dados da Cloudflare indicam que, para cada referência enviada pela Anthropic a um site, seus crawlers já visitaram cerca de 38.000 a 70.000 páginas. Esse enorme desequilíbrio indica que seu conteúdo é consumido muito mais agressivamente do que é citado, levantando importantes questões sobre compensação justa pelo uso do conteúdo.
A abordagem do Google ao rastreamento de IA é significativamente diferente dos concorrentes, pois a empresa mantém separação estrita entre indexação de busca e treinamento de IA. Google-Extended é o crawler responsável por coletar dados para treinar o Gemini (antigo Bard) e outros produtos de IA do Google, completamente separado do Googlebot tradicional:
O user agent do Google-Extended é: Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Google-Extended/1.0. Essa separação é intencional e benéfica para proprietários de sites, pois permite bloquear o Google-Extended via robots.txt sem afetar sua visibilidade no Google Search. O Google afirma oficialmente que bloquear o Google-Extended não impacta o ranking de busca nem a inclusão em AI Overviews, embora alguns webmasters relatem preocupações que merecem monitoramento. Gemini-Deep-Research é outro crawler do Google que suporta o recurso de pesquisa do Gemini, operando em volumes muito baixos com impacto mínimo nos recursos do servidor. Uma vantagem técnica significativa dos crawlers do Google é a capacidade de executar JavaScript e renderizar conteúdo dinâmico, ao contrário da maioria dos concorrentes. Isso significa que o Google-Extended consegue rastrear aplicações React, Vue e Angular efetivamente, enquanto o GPTBot da OpenAI e o ClaudeBot da Anthropic não conseguem. Para proprietários de aplicações com muito JavaScript, essa distinção é fundamental para visibilidade em IA.
Além dos gigantes da tecnologia, várias outras organizações operam crawlers de IA que merecem atenção. Meta-ExternalAgent, lançado discretamente em julho de 2024, coleta conteúdo da web para treinar modelos de IA da Meta e aprimorar produtos do Facebook, Instagram e WhatsApp. Opera a cerca de 1100 páginas/hora e recebeu menos atenção pública apesar do comportamento agressivo. Bytespider, operado pela ByteDance (controladora do TikTok), tornou-se um dos crawlers mais agressivos da internet desde seu lançamento em abril de 2024. Monitoramento de terceiros indica que o Bytespider rastreia muito mais agressivamente que GPTBot ou ClaudeBot, embora multiplicadores exatos variem. Relatos sugerem que pode não respeitar consistentemente as diretrizes do robots.txt, tornando o bloqueio por IP mais confiável.
Os crawlers da Perplexity incluem o PerplexityBot para indexação de busca e o Perplexity-User para busca em tempo real. A Perplexity tem relatos anedóticos de ignorar as diretivas do robots.txt, embora a empresa afirme estar em conformidade. Amazonbot alimenta as capacidades de perguntas e respostas da Alexa e respeita o protocolo robots.txt, operando a cerca de 1050 páginas/hora. Applebot-Extended, introduzido em junho de 2024, determina como o conteúdo já indexado pelo Applebot será usado para treinamento de IA da Apple, embora não rastreie páginas diretamente. CCBot, operado pela Common Crawl (organização sem fins lucrativos), constrói arquivos abertos da web usados por várias empresas de IA, incluindo OpenAI, Google, Meta e Hugging Face. Crawlers emergentes de empresas como xAI (Grok), Mistral e DeepSeek começam a aparecer nos logs de servidores, sinalizando a contínua expansão do ecossistema de crawlers de IA.
Segue uma tabela de referência abrangente dos crawlers de IA verificados, seus propósitos, user agents e sintaxe de bloqueio no robots.txt. Esta tabela é atualizada regularmente com base em análise de logs e documentação oficial. Cada entrada foi verificada em listas de IP oficiais quando disponíveis:
| Nome do Crawler | Empresa | Propósito | User Agent | Taxa de Rastreamento | Verificação de IP | Sintaxe robots.txt |
|---|---|---|---|---|---|---|
| GPTBot | OpenAI | Coleta de dados para treinamento | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.3; +https://openai.com/gptbot) | 100/h | ✓ Oficial | User-agent: GPTBot Disallow: / |
| ChatGPT-User | OpenAI | Requisições de usuário em tempo real | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; ChatGPT-User/1.0 | 2400/h | ✓ Oficial | User-agent: ChatGPT-User Disallow: / |
| OAI-SearchBot | OpenAI | Indexação de busca | Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36; compatible; OAI-SearchBot/1.3 | 150/h | ✓ Oficial | User-agent: OAI-SearchBot Disallow: / |
| ClaudeBot | Anthropic | Coleta de dados para treinamento | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com) | 500/h | ✓ Oficial | User-agent: ClaudeBot Disallow: / |
| Claude-User | Anthropic | Acesso web em tempo real | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Claude-User/1.0) | <10/h | ✗ Não disponível | User-agent: Claude-User Disallow: / |
| Claude-SearchBot | Anthropic | Indexação de busca | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Claude-SearchBot/1.0) | <10/h | ✗ Não disponível | User-agent: Claude-SearchBot Disallow: / |
| Google-Extended | Treinamento Gemini AI | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Google-Extended/1.0) | Variável | ✓ Oficial | User-agent: Google-Extended Disallow: / | |
| Gemini-Deep-Research | Recurso de pesquisa | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Gemini-Deep-Research) | <10/h | ✓ Oficial | User-agent: Gemini-Deep-Research Disallow: / | |
| Bingbot | Microsoft | Busca Bing & Copilot | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; bingbot/2.0) | 1300/h | ✓ Oficial | User-agent: Bingbot Disallow: / |
| Meta-ExternalAgent | Meta | Treinamento de modelo IA | meta-externalagent/1.1 (+https://developers.facebook.com/docs/sharing/webmasters/crawler) | 1100/h | ✗ Não disponível | User-agent: Meta-ExternalAgent Disallow: / |
| Amazonbot | Amazon | Melhoria de serviço | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Amazonbot/0.1) | 1050/h | ✓ Oficial | User-agent: Amazonbot Disallow: / |
| Applebot-Extended | Apple | Treinamento de IA | Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15; compatible; Applebot-Extended | <10/h | ✓ Oficial | User-agent: Applebot-Extended Disallow: / |
| PerplexityBot | Perplexity | Indexação de busca | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; PerplexityBot/1.0) | 150/h | ✓ Oficial | User-agent: PerplexityBot Disallow: / |
| Perplexity-User | Perplexity | Busca em tempo real | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Perplexity-User/1.0) | <10/h | ✓ Oficial | User-agent: Perplexity-User Disallow: / |
| Bytespider | ByteDance | Treinamento de IA | Mozilla/5.0 (Linux; Android 5.0) AppleWebKit/537.36; compatible; Bytespider | <10/h | ✗ Não disponível | User-agent: Bytespider Disallow: / |
| CCBot | Common Crawl | Dataset aberto | CCBot/2.0 (https://commoncrawl.org/faq/ ) | <10/h | ✓ Oficial | User-agent: CCBot Disallow: / |
| DuckAssistBot | DuckDuckGo | Busca por IA | DuckAssistBot/1.2; (+http://duckduckgo.com/duckassistbot.html) | 20/h | ✓ Oficial | User-agent: DuckAssistBot Disallow: / |
| Diffbot | Diffbot | Extração de dados | Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.9.1.2) Gecko/20090729 Firefox/3.5.2 Diffbot/0.1 | <10/h | ✗ Não disponível | User-agent: Diffbot Disallow: / |
| MistralAI-User | Mistral | Busca em tempo real | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; MistralAI-User/1.0) | <10/h | ✗ Não disponível | User-agent: MistralAI-User Disallow: / |
| ICC-Crawler | NICT | Treinamento IA/ML | ICC-Crawler/3.0 (Mozilla-compatible; https://ucri.nict.go.jp/en/icccrawler.html ) | <10/h | ✗ Não disponível | User-agent: ICC-Crawler Disallow: / |
Nem todo crawler de IA serve ao mesmo propósito, e entender essas distinções é fundamental para decisões de bloqueio informadas. Crawlers de treinamento representam cerca de 80% de todo o tráfego de bots de IA e coletam conteúdo especificamente para compor datasets de desenvolvimento de grandes modelos de linguagem. Uma vez que seu conteúdo entra em um dataset de treinamento, ele passa a compor o conhecimento permanente do modelo, potencialmente reduzindo a necessidade dos usuários de visitar seu site. Crawlers de treinamento como GPTBot, ClaudeBot e Meta-ExternalAgent operam em alto volume e com padrões sistemáticos de rastreamento, retornando pouco ou nenhum tráfego de referência aos editores.
Crawlers de busca e citação indexam conteúdo para experiências de busca baseadas em IA e podem de fato enviar algum tráfego de volta por meio de citações. Quando usuários fazem perguntas no ChatGPT ou Perplexity, esses crawlers ajudam a destacar fontes relevantes. Ao contrário dos crawlers de treinamento, crawlers de busca como OAI-SearchBot e PerplexityBot operam em volume moderado e comportamento de recuperação, podendo incluir atribuição e links. Fetchers acionados por usuários ativam-se somente quando usuários solicitam conteúdo via assistentes de IA. Quando alguém cola uma URL no ChatGPT ou pede que o Perplexity analise uma página específica, esses fetchers buscam o conteúdo sob demanda. Operam em volume muito baixo, com requisições pontuais, e a maioria das empresas de IA confirma que não são usados para treinamento de modelos. Entender essas categorias ajuda a tomar decisões estratégicas sobre quais crawlers permitir ou bloquear conforme suas prioridades de negócio.
O primeiro passo para gerenciar crawlers de IA é entender quais realmente visitam seu site. Seus logs de acesso do servidor contêm registros detalhados de todas as requisições, incluindo o user agent que identifica o crawler. A maioria dos painéis de hospedagem oferece ferramentas de análise de logs, mas também é possível acessar os logs brutos diretamente. Em servidores Apache, normalmente estão em /var/log/apache2/access.log, enquanto no Nginx em /var/log/nginx/access.log. Você pode filtrar esses logs com grep para encontrar atividade de crawler:
grep -i "gptbot\|claudebot\|google-extended\|bytespider" /var/log/apache2/access.log | head -20
Esse comando mostra as 20 requisições mais recentes dos principais crawlers de IA. Google Search Console fornece estatísticas de rastreamento para os bots do Google, embora só mostre crawlers do próprio Google. Cloudflare Radar oferece insights globais sobre padrões de tráfego de bots de IA e pode ajudar a identificar quais crawlers estão mais ativos. Para verificar se um crawler é legítimo ou falsificado, cheque o IP da requisição nas listas oficiais publicadas pelas empresas. A OpenAI publica IPs verificados em https://openai.com/gptbot.json, a Amazon em https://developer.amazon.com/amazonbot/ip-addresses/, entre outros. Um crawler falso, que simula um user agent legítimo a partir de um IP não verificado, deve ser bloqueado imediatamente, pois provavelmente trata-se de scraping malicioso.
O robots.txt é sua principal ferramenta para controlar o acesso de crawlers. Esse arquivo de texto simples, na raiz do site, informa aos crawlers quais partes do site podem ser acessadas. Para bloquear crawlers de IA específicos, adicione entradas como:
# Bloquear o GPTBot da OpenAI
User-agent: GPTBot
Disallow: /
# Bloquear o ClaudeBot da Anthropic
User-agent: ClaudeBot
Disallow: /
# Bloquear treinamento de IA do Google (não busca)
User-agent: Google-Extended
Disallow: /
# Bloquear o Common Crawl
User-agent: CCBot
Disallow: /
Você também pode permitir crawlers e definir limites de taxa para evitar sobrecarga:
User-agent: GPTBot
Crawl-delay: 10
Disallow: /private/
Isso instrui o GPTBot a esperar 10 segundos entre requisições e não acessar o diretório /private/. Para uma abordagem equilibrada que permita crawlers de busca e bloqueie os de treinamento:
# Permitir mecanismos de busca tradicionais
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
# Bloquear todos os crawlers de IA de treinamento
User-agent: GPTBot
User-agent: ClaudeBot
User-agent: CCBot
User-agent: Google-Extended
User-agent: Bytespider
User-agent: Meta-ExternalAgent
Disallow: /
# Permitir crawlers de busca de IA
User-agent: OAI-SearchBot
Allow: /
User-agent: PerplexityBot
Allow: /
A maioria dos crawlers de IA respeitáveis segue as diretrizes do robots.txt, embora alguns crawlers agressivos as ignorem completamente. Por isso, o robots.txt sozinho não garante proteção total.
Robots.txt é um conselho e não obrigatório, ou seja, crawlers podem ignorar suas diretrizes se quiserem. Para proteção mais forte contra crawlers que ignoram o robots.txt, implemente bloqueio por IP no nível do servidor. Essa abordagem é mais confiável, pois é mais difícil falsificar um IP do que um user agent. Você pode liberar IPs oficiais enquanto bloqueia todas as outras requisições que alegam ser crawlers de IA.
Para servidores Apache, use regras .htaccess para bloquear crawlers no nível do servidor:
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} (GPTBot|ClaudeBot|anthropic-ai|Bytespider|CCBot) [NC]
RewriteRule .* - [F,L]
</IfModule>
Isso retorna um 403 Forbidden para user agents correspondentes, independentemente do robots.txt. Regras de firewall adicionam outra camada de proteção, liberando apenas faixas de IP verificadas. A maioria dos firewalls e provedores de hospedagem permite criar regras para permitir requisições de IPs oficiais e bloquear as demais que alegam ser crawlers de IA. Meta tags HTML oferecem controle em nível de página. A Amazon e alguns outros crawlers respeitam a diretiva noarchive:
<meta name="robots" content="noarchive">
Isso instrui crawlers a não usar a página para treinamento de modelo, permitindo outros tipos de indexação. Escolha o método de bloqueio conforme sua capacidade técnica e os crawlers que deseja atingir. Bloqueio por IP é o mais confiável, mas exige configuração técnica, enquanto robots.txt é mais fácil, porém menos efetivo contra crawlers não conformes.
Implementar bloqueios é apenas metade do processo; é preciso verificar se estão funcionando. Monitoramento regular ajuda a detectar problemas e identificar novos crawlers. Verifique semanalmente os logs do servidor para atividade suspeita, procurando user agents com “bot”, “crawler”, “spider” ou nomes como “GPT”, “Claude” ou “Perplexity”. Configure alertas para picos de tráfego de bots, o que pode indicar novos crawlers ou comportamento agressivo. Google Search Console mostra estatísticas para os bots do Google, ajudando a monitorar Googlebot e Google-Extended. Cloudflare Radar traz insights globais sobre padrões de tráfego de crawlers de IA e identifica crawlers emergentes.
Para verificar se o robots.txt está funcionando, acesse diretamente seudominio.com/robots.txt e confirme se todos os user agents e diretrizes estão corretos. Para bloqueios no servidor, monitore os logs para requisições vindas de crawlers bloqueados. Se observar requisições de crawlers bloqueados, eles estão ignorando suas diretrizes ou falsificando user agents. Teste as implementações checando o acesso dos crawlers em suas análises e logs. Revisões trimestrais são essenciais, pois o cenário de crawlers de IA evolui rapidamente. Novos crawlers surgem, user agents são atualizados e empresas introduzem bots sem aviso. Programe revisões regulares da lista de bloqueio para garantir atualidade e eficácia.
Além de gerenciar o acesso de crawlers, é fundamental entender como sistemas de IA realmente citam e referenciam seu conteúdo. AmICited.com oferece monitoramento abrangente de como sua marca e conteúdo aparecem em respostas geradas por IA no ChatGPT, Perplexity, Google Gemini e outras plataformas. Em vez de simplesmente bloquear crawlers, o AmICited.com ajuda a entender o impacto real dos crawlers de IA na sua visibilidade e autoridade. A plataforma acompanha quais sistemas de IA citam seu conteúdo, com que frequência sua marca aparece em respostas de IA e como essa visibilidade se traduz em tráfego e autoridade. Ao monitorar suas citações em IA, você toma decisões informadas sobre quais crawlers permitir com base em dados reais de visibilidade. O AmICited.com integra-se à sua estratégia de conteúdo, mostrando quais temas e tipos de conteúdo geram mais citações em IA. Essa abordagem orientada por dados otimiza seu conteúdo para descobribilidade por IA ao mesmo tempo em que protege sua propriedade intelectual mais valiosa. Entender suas métricas de citação em IA permite decisões estratégicas para acesso de crawlers alinhadas aos objetivos do seu negócio.
Decidir permitir ou bloquear crawlers de IA depende totalmente da sua situação e prioridades de negócio. Permita crawlers de IA se: você tem um site de notícias ou blog em que visibilidade em respostas de IA gera tráfego significativo, seu negócio se beneficia de citações como fonte em respostas geradas por IA, você quer participar de treinamentos de IA para influenciar como modelos entendem seu setor, ou está confortável com o uso do seu conteúdo para desenvolvimento de IA. Editores de notícias, produtores de conteúdo educacional e líderes de opinião geralmente se beneficiam da visibilidade em IA, pois citações geram tráfego e autoridade.
Bloqueie crawlers de IA se: você possui conteúdo proprietário ou segredos comerciais a proteger, seus recursos de servidor são limitados e não suportam rastreamento agressivo, há preocupação com uso não remunerado do conteúdo, deseja controlar o uso da sua propriedade intelectual, ou já teve problemas de desempenho por tráfego de bots. E-commerces com informações de produtos, empresas SaaS com documentação proprietária e editores com conteúdo restrito frequentemente optam por bloquear crawlers de treinamento. A principal troca é entre proteção de conteúdo e visibilidade em plataformas de descoberta baseadas em IA. Bloquear crawlers de treinamento protege seu conteúdo, mas pode reduzir visibilidade em respostas de IA. Bloquear crawlers de busca pode reduzir visibilidade em resultados de busca baseados em IA. Muitos editores adotam uma abordagem de bloqueio seletivo: permitem crawlers de busca e citação como OAI-SearchBot e PerplexityBot, bloqueando crawlers de treinamento agressivos como GPTBot e ClaudeBot. Essa estratégia equilibra visibilidade em buscas por IA com proteção contra coleta ilimitada de dados para treinamento. Sua decisão deve estar alinhada ao modelo de negócio, estratégia de conteúdo e limitações de recursos.
O ecossistema de crawlers de IA segue se expandindo rapidamente com novas empresas entrando no mercado e players existentes lançando bots adicionais. O crawler Grok da xAI já aparece em logs de servidores à medida que a empresa escala sua plataforma. MistralAI-User da Mistral suporta busca em tempo real para o assistente Mistral AI. DeepSeekBot da DeepSeek representa competição emergente de empresas chinesas de IA. Agentes de IA baseados em navegador como Operator da OpenAI e produtos similares apresentam novo desafio: não usam user agents distintos e aparecem como tráfego comum do Chrome, tornando impossível bloqueá-los pelos métodos tradicionais. Esses browsers agentes são a fronteira da evolução dos crawlers de IA, pois interagem com sites como usuários humanos, executando JavaScript e navegando interfaces complexas.
O futuro dos crawlers de IA provavelmente envolverá sofisticação crescente, mecanismos de controle mais granulares e possivelmente novos padrões para gerenciar o acesso de IA ao conteúdo. Manter-se informado sobre crawlers emergentes é essencial, pois novos bots aparecem regularmente e crawlers existentes evoluem seu comportamento. Monitore recursos como o projeto ai.robots.txt no GitHub , que mantém uma lista comunitária de crawlers de IA conhecidos. Verifique regularmente os logs do servidor para user agents desconhecidos. Assine atualizações das principais empresas de IA sobre comportamento de crawlers e faixas de IP. O cenário de crawlers de IA seguirá evoluindo, e sua estratégia de gestão deve acompanhar. Monitoramento constante, revisões trimestrais e atualização sobre tendências do setor garantem que você mantenha o controle sobre como sistemas de IA acessam e usam seu conteúdo.
Crawlers de IA como GPTBot e ClaudeBot coletam conteúdo especificamente para treinar grandes modelos de linguagem, enquanto crawlers de mecanismos de busca como o Googlebot indexam conteúdo para que as pessoas possam encontrá-lo nos resultados de busca. Os crawlers de IA alimentam as bases de conhecimento de sistemas de IA, enquanto os crawlers de busca ajudam os usuários a descobrir seu conteúdo. A diferença principal é o objetivo: treinamento versus recuperação.
Não, bloquear crawlers de IA não prejudica seu ranking tradicional de busca. Crawlers de IA como GPTBot e ClaudeBot são completamente separados dos crawlers de mecanismos de busca como o Googlebot. Você pode bloquear o Google-Extended (para treinamento de IA) e ainda permitir o Googlebot (para busca). Cada crawler serve a um propósito diferente e bloquear um não afeta o outro.
Verifique os logs de acesso do seu servidor para ver quais user agents estão visitando seu site. Procure por nomes de bot como GPTBot, ClaudeBot, CCBot e Bytespider nas cadeias de user agent. A maioria dos painéis de controle de hospedagem oferece ferramentas de análise de logs. Você também pode usar o Google Search Console para monitorar a atividade de rastreamento, embora ele mostre apenas os crawlers do Google.
Nem todos os crawlers de IA respeitam o robots.txt igualmente. O GPTBot da OpenAI, o ClaudeBot da Anthropic e o Google-Extended geralmente seguem as regras do robots.txt. Bytespider e PerplexityBot têm relatos sugerindo que podem não respeitar consistentemente as diretivas do robots.txt. Para crawlers que não respeitam o robots.txt, será necessário implementar bloqueio por IP no nível do servidor via firewall ou arquivo .htaccess.
A decisão depende de seus objetivos. Bloqueie crawlers de treinamento se você possui conteúdo proprietário ou recursos limitados de servidor. Permita crawlers de busca se quiser visibilidade em resultados de busca e chatbots baseados em IA, que podem gerar tráfego e estabelecer autoridade. Muitas empresas adotam uma abordagem seletiva, permitindo crawlers específicos e bloqueando os mais agressivos como o Bytespider.
Novos crawlers de IA surgem regularmente, então revise e atualize sua lista de bloqueio ao menos trimestralmente. Acompanhe recursos como o projeto ai.robots.txt no GitHub para listas mantidas pela comunidade. Verifique os logs do servidor mensalmente para identificar novos crawlers acessando seu site que não estão em sua configuração atual. O cenário de crawlers de IA evolui rapidamente e sua estratégia deve evoluir junto.
Sim, verifique o endereço IP da requisição com as listas oficiais de IPs publicadas pelas grandes empresas. A OpenAI publica IPs verificados em https://openai.com/gptbot.json, a Amazon em https://developer.amazon.com/amazonbot/ip-addresses/ e outros mantêm listas semelhantes. Um crawler que falsifica um user agent legítimo a partir de um IP não verificado deve ser bloqueado imediatamente, pois provavelmente se trata de scraping malicioso.
Crawlers de IA podem consumir largura de banda e recursos significativos do servidor. Bytespider e Meta-ExternalAgent estão entre os crawlers mais agressivos. Alguns editores relatam redução no consumo de banda de 800GB para 200GB por dia ao bloquear crawlers de IA, economizando cerca de US$1.500 por mês. Monitore os recursos do seu servidor durante os picos de rastreamento e implemente limitação de taxa para bots agressivos, se necessário.
Acompanhe quais crawlers de IA estão citando seu conteúdo e otimize sua visibilidade no ChatGPT, Perplexity, Google Gemini e muito mais.
Aprenda como otimizar sitemaps XML para crawlers de IA como GPTBot e ClaudeBot. Domine as melhores práticas de sitemap para aumentar a visibilidade em respostas...

Saiba quais crawlers de IA permitir ou bloquear no seu robots.txt. Guia abrangente cobrindo GPTBot, ClaudeBot, PerplexityBot e mais de 25 crawlers de IA com exe...
Descubra os fatores técnicos críticos de SEO que afetam sua visibilidade em mecanismos de busca por IA como ChatGPT, Perplexity e Google AI Mode. Saiba como vel...