Lista Completa de Crawlers de IA em 2025: Todos os Bots Que Você Precisa Conhecer
Guia abrangente dos crawlers de IA em 2025. Identifique GPTBot, ClaudeBot, PerplexityBot e mais de 20 outros bots de IA. Aprenda como bloquear, permitir ou monitorar crawlers com robots.txt e técnicas avançadas.
Publicado em Jan 3, 2026.Última modificação em Jan 3, 2026 às 3:24 am
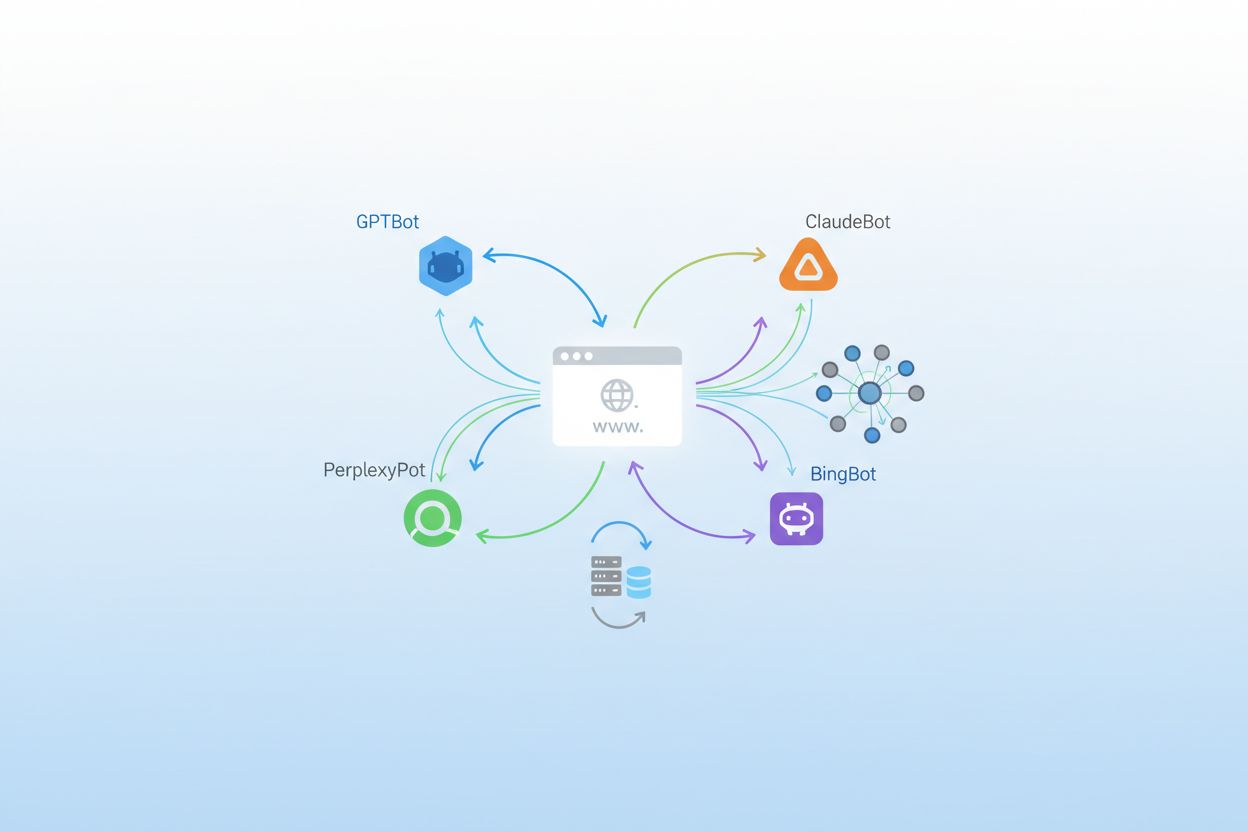
Crawlers de IA são bots automatizados projetados para navegar e coletar dados de sites de forma sistemática, mas seu propósito mudou fundamentalmente nos últimos anos. Enquanto crawlers tradicionais de motores de busca como o Googlebot focam em indexar conteúdo para resultados de busca, os crawlers modernos de IA priorizam a coleta de dados para treinamento de grandes modelos de linguagem e sistemas de IA generativa. Segundo dados recentes da Playwire, os crawlers de IA agora representam aproximadamente 80% de todo o tráfego de bots de IA, indicando um aumento dramático no volume e diversidade de visitantes automatizados nos sites. Essa mudança reflete a transformação mais ampla em como sistemas de inteligência artificial são desenvolvidos e treinados, migrando de conjuntos de dados públicos para coleta de conteúdo em tempo real na web. Compreender esses crawlers tornou-se essencial para proprietários de sites, editores e criadores de conteúdo que precisam tomar decisões informadas sobre sua presença digital.
Três Categorias de Crawlers de IA
Os crawlers de IA podem ser classificados em três categorias distintas com base em sua função, comportamento e impacto no seu site. Crawlers de Treinamento representam o maior segmento, respondendo por cerca de 80% do tráfego de bots de IA, e são projetados para coletar conteúdo para treinar modelos de machine learning; esses crawlers normalmente operam em alto volume e com tráfego de referência mínimo, tornando-se intensivos em largura de banda, mas improváveis de trazer visitantes de volta ao seu site. Crawlers de Busca e Citação operam em volumes moderados e são projetados especificamente para encontrar e referenciar conteúdo em resultados de busca e aplicativos com IA; ao contrário dos crawlers de treinamento, esses bots podem realmente enviar tráfego para seu site quando usuários clicam em respostas geradas por IA. Fetchers acionados pelo usuário representam a menor categoria e operam sob demanda quando usuários solicitam explicitamente a recuperação de conteúdo por meio de aplicativos de IA como o recurso de navegação do ChatGPT; esses crawlers têm baixo volume, mas alta relevância para consultas individuais.
Categoria
Propósito
Exemplos
Crawlers de Treinamento
Coletar dados para treinamento de modelos de IA
GPTBot, ClaudeBot, Meta-ExternalAgent, Bytespider
Crawlers de Busca/Citação
Encontrar e referenciar conteúdo em respostas de IA
A OpenAI opera o ecossistema de crawlers mais diverso e agressivo no cenário da IA, com múltiplos bots servindo a diferentes propósitos em sua suíte de produtos. O GPTBot é seu principal crawler de treinamento, responsável por coletar conteúdo para aprimorar o GPT-4 e futuros modelos, e experimentou um impressionante crescimento de 305% no tráfego de crawler segundo dados da Cloudflare; esse bot opera com uma proporção de 400:1 de rastreamento para referência, o que significa que ele baixa conteúdo 400 vezes para cada visitante que retorna ao seu site. O OAI-SearchBot serve uma função totalmente diferente, focando em encontrar e citar conteúdo para o recurso de busca do ChatGPT, sem usar o conteúdo para treinamento de modelos. O ChatGPT-User representa a categoria de crescimento mais explosivo, com um notável aumento de 2.825% no tráfego, operando sempre que usuários ativam o recurso “Navegar com Bing” para buscar conteúdo em tempo real sob demanda. Você pode identificar esses crawlers por suas user agent strings: GPTBot/1.0, OAI-SearchBot/1.0 e ChatGPT-User/1.0, e a OpenAI fornece métodos de verificação de IP para confirmar o tráfego legítimo de crawlers de sua infraestrutura.
Crawlers de IA da Anthropic e do Google
A Anthropic, empresa por trás do Claude, opera uma das operações de crawlers mais seletivas, porém intensivas, da indústria. O ClaudeBot é seu principal crawler de treinamento e opera com uma extraordinária proporção de 38.000:1 de rastreamento para referência, o que significa que ele baixa conteúdo de forma muito mais agressiva do que os bots da OpenAI em relação ao tráfego enviado de volta; essa proporção extrema reflete o foco da Anthropic na coleta abrangente de dados para treinamento de modelos. Claude-Web e Claude-SearchBot têm propósitos diferentes, sendo o primeiro responsável pela busca de conteúdo sob demanda feita pelo usuário e o segundo focado em funcionalidades de busca e citação. O Google adaptou sua estratégia de crawlers para a era da IA ao introduzir o Google-Extended, um token especial que permite aos sites optarem pelo treinamento de IA enquanto bloqueiam a indexação tradicional do Googlebot, e o Gemini-Deep-Research, que realiza consultas de pesquisa aprofundadas para usuários dos produtos de IA do Google. Muitos proprietários de sites debatem se devem bloquear o Google-Extended, já que ele vem da mesma empresa que controla o tráfego de busca, tornando a decisão mais complexa do que com crawlers de IA de terceiros.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Meta, Apple, Amazon e Perplexity
A Meta tornou-se um player significativo no espaço de crawlers de IA com o Meta-ExternalAgent, que responde por cerca de 19% do tráfego de crawlers de IA e é usado para treinar seus modelos de IA e alimentar recursos do Facebook, Instagram e WhatsApp. O Meta-WebIndexer exerce função complementar, focando na indexação web para recursos e recomendações alimentadas por IA. A Apple introduziu o Applebot-Extended para dar suporte ao Apple Intelligence, seus recursos de IA on-device, e esse crawler tem crescido de forma constante à medida que a empresa expande suas capacidades de IA em iPhone, iPad e dispositivos Mac. A Amazon opera o Amazonbot para alimentar a Alexa e o Rufus, seu assistente de compras com IA, tornando-o relevante para sites de e-commerce e conteúdo de produtos. O PerplexityBot representa uma das histórias de crescimento mais dramáticas no cenário de crawlers, com um impressionante aumento de 157.490% no tráfego, refletindo o crescimento explosivo do Perplexity AI como alternativa de busca; apesar desse crescimento massivo, o Perplexity ainda representa um volume absoluto menor em comparação com a OpenAI e o Google, mas a trajetória indica importância rapidamente crescente.
Crawlers Emergentes e Especializados
Além dos grandes players, vários crawlers de IA emergentes e especializados estão ativamente coletando dados de sites por toda a internet. O Bytespider, operado pela ByteDance (empresa-mãe do TikTok), experimentou uma queda dramática de 85% no tráfego de crawler, sugerindo uma mudança de estratégia ou menor necessidade de coleta de dados para treinamento. Cohere, Diffbot e o CCBot do Common Crawl representam crawlers especializados focados em casos de uso específicos, desde treinamento de modelos de linguagem até extração de dados estruturados. You.com, Mistral e DuckDuckGo operam seus próprios crawlers para dar suporte a recursos de busca e assistentes alimentados por IA, aumentando a complexidade do cenário de crawlers. O surgimento de novos crawlers ocorre regularmente, com startups e empresas estabelecidas lançando continuamente produtos de IA que exigem coleta de dados web. Manter-se informado sobre esses crawlers emergentes é crucial, pois bloqueá-los ou permiti-los pode impactar significativamente sua visibilidade em novas plataformas e aplicativos de descoberta baseados em IA.
Como Identificar Crawlers de IA
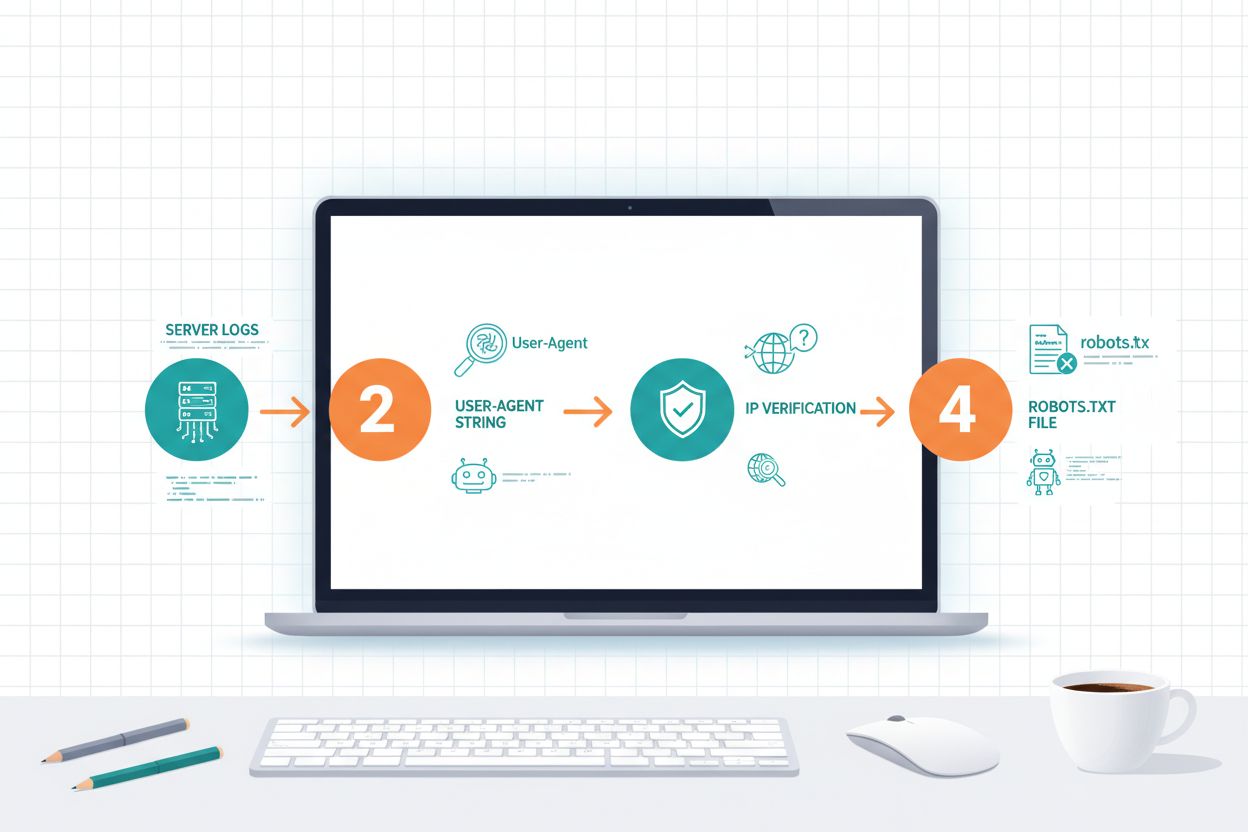
Identificar crawlers de IA exige compreender como eles se identificam e analisar os padrões de tráfego do seu servidor. User-agent strings são o principal método de identificação, pois cada crawler se anuncia com um identificador específico nas requisições HTTP; por exemplo, o GPTBot usa GPTBot/1.0, o ClaudeBot usa Claude-Web/1.0 e o PerplexityBot usa PerplexityBot/1.0. Analisar seus logs do servidor (normalmente encontrados em /var/log/apache2/access.log nos servidores Linux ou logs do IIS no Windows) permite ver quais crawlers estão acessando seu site e com que frequência. A verificação de IP é outra técnica crítica, na qual você pode checar se um crawler que afirma ser da OpenAI ou Anthropic está realmente vindo de suas faixas de IP legítimas, que essas empresas publicam por motivos de segurança. Examinar seu arquivo robots.txt revela quais crawlers você permitiu ou bloqueou explicitamente, e comparar isso com o tráfego real mostra se os crawlers estão respeitando suas diretrizes. Ferramentas como o Cloudflare Radar oferecem visibilidade em tempo real dos padrões de tráfego de crawlers e podem ajudar a identificar quais bots estão mais ativos em seu site. Passos práticos de identificação incluem: checar sua plataforma de análise para tráfego de bots, revisar logs brutos do servidor em busca de padrões de user-agent, cruzar endereços IP com as faixas de IP publicadas dos crawlers e usar ferramentas online de verificação de crawlers para confirmar fontes suspeitas de tráfego.
Os Dilemas: Bloquear vs. Permitir
Decidir se deve permitir ou bloquear crawlers de IA envolve pesar várias considerações e não existe uma resposta única para todos os casos. Os principais dilemas incluem:
Visibilidade em Aplicativos de IA: Permitir crawlers garante que seu conteúdo apareça em resultados de busca, plataformas de descoberta e respostas de assistentes com IA, potencialmente gerando tráfego de novas fontes
Largura de Banda e Carga no Servidor: Crawlers de treinamento consomem largura de banda significativa e recursos do servidor, com alguns sites relatando aumento de 10-30% no tráfego apenas de bots de IA, podendo elevar os custos de hospedagem
Proteção de Conteúdo vs. Tráfego: Bloquear crawlers protege seu conteúdo de ser usado em treinamento de IA, mas elimina a possibilidade de receber tráfego de referência de plataformas de descoberta alimentadas por IA
Potencial de Tráfego de Referência: Crawlers de busca e citação como o PerplexityBot e o OAI-SearchBot podem enviar tráfego de volta ao seu site, enquanto crawlers de treinamento como o GPTBot e o ClaudeBot normalmente não enviam
Posicionamento Competitivo: Concorrentes que permitem crawlers podem ganhar visibilidade em aplicativos de IA enquanto você permanece invisível, afetando sua posição no mercado de descoberta por IA
Como 80% do tráfego de bots de IA vem de crawlers de treinamento com mínimo potencial de referência, muitos editores optam por bloquear crawlers de treinamento enquanto permitem crawlers de busca e citação. Essa decisão depende do seu modelo de negócio, tipo de conteúdo e prioridades estratégicas quanto à visibilidade em IA versus consumo de recursos.
Configurando Robots.txt para Crawlers de IA
O arquivo robots.txt é sua principal ferramenta para comunicar políticas de crawlers para bots de IA, embora seja importante entender que o cumprimento é voluntário e não tecnicamente obrigatório. O robots.txt usa correspondência de user-agent para direcionar crawlers específicos, permitindo criar regras diferentes para cada bot; por exemplo, você pode bloquear o GPTBot enquanto permite o OAI-SearchBot, ou bloquear todos os crawlers de treinamento e permitir os de busca. Segundo pesquisas recentes, apenas 14% dos 10.000 principais domínios implementaram regras específicas para IA no robots.txt, indicando que a maioria dos sites ainda não otimizou suas políticas de crawlers para a era da IA. O arquivo utiliza uma sintaxe simples onde você especifica o nome do user-agent seguido de diretivas de disallow ou allow, podendo usar curingas para abranger múltiplos crawlers com padrões de nomes similares.
Aqui estão três cenários práticos de configuração do robots.txt:
# Cenário 1: Bloquear todos os crawlers de IA de treinamento, permitir crawlers de busca
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
User-agent: Amazonbot
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: OAI-SearchBot
Allow: /
User-agent: PerplexityBot
Allow: /
# Cenário 2: Bloquear completamente todos os crawlers de IA
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
User-agent: Amazonbot
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: OAI-SearchBot
Disallow: /
User-agent: PerplexityBot
Disallow: /
User-agent: Applebot-Extended
Disallow: /
# Cenário 3: Bloqueio seletivo por diretório
User-agent: GPTBot
Disallow: /private/
Disallow: /admin/
Allow: /public/
User-agent: ClaudeBot
Disallow: /
User-agent: OAI-SearchBot
Allow: /
Lembre-se de que o robots.txt é apenas uma recomendação, e crawlers mal-intencionados ou não conformes podem ignorar completamente suas diretrizes. A correspondência de user-agent não diferencia maiúsculas de minúsculas, portanto gptbot, GPTBot e GPTBOT referem-se ao mesmo crawler, e você pode usar User-agent: * para criar regras que se aplicam a todos os crawlers.
Métodos Avançados de Proteção
Além do robots.txt, vários métodos avançados oferecem proteção mais forte contra crawlers de IA indesejados, embora cada um tenha diferentes níveis de eficácia e complexidade de implementação. Verificação de IP e regras de firewall permitem bloquear tráfego de faixas de IP específicas associadas a crawlers de IA; você pode obter essas faixas na documentação dos operadores dos crawlers e configurar seu firewall ou Web Application Firewall (WAF) para rejeitar requisições desses IPs, embora isso exija manutenção contínua à medida que as faixas mudam. O bloqueio em nível de servidor via .htaccess oferece proteção no Apache, checando user-agent strings e endereços IP antes de servir o conteúdo, proporcionando aplicação mais confiável do que o robots.txt, já que opera no servidor e não depende do cumprimento do crawler.
Aqui está um exemplo prático de .htaccess para bloqueio avançado de crawlers:
# Bloquear crawlers de treinamento de IA em nível de servidor<IfModulemod_rewrite.c> RewriteEngine On# Bloquear por user-agent string RewriteCond %{HTTP_USER_AGENT} (GPTBot|ClaudeBot|Meta-ExternalAgent|Amazonbot|Bytespider) [NC]
RewriteRule ^.*$ - [F,L]
# Bloquear por endereço IP (IPs de exemplo - substitua pelos IPs reais dos crawlers) RewriteCond %{REMOTE_ADDR} ^192\.0\.2\.0$ [OR]
RewriteCond %{REMOTE_ADDR} ^198\.51\.100\.0$
RewriteRule ^.*$ - [F,L]
# Permitir crawlers específicos enquanto bloqueia outros RewriteCond %{HTTP_USER_AGENT} !OAI-SearchBot [NC]
RewriteCond %{HTTP_USER_AGENT} (GPTBot|ClaudeBot) [NC]
RewriteRule ^.*$ - [F,L]
</IfModule># Abordagem via meta tag HTML (adicionar nos headers das páginas)# <meta name="robots" content="noarchive, noimageindex"># <meta name="googlebot" content="noindex, nofollow">
Meta tags HTML como <meta name="robots" content="noarchive"> e <meta name="googlebot" content="noindex"> oferecem controle em nível de página, embora sejam menos confiáveis do que o bloqueio em nível de servidor, pois os crawlers precisam analisar o HTML para vê-las. É importante notar que falsificação de IP é tecnicamente possível, o que significa que agentes sofisticados podem se passar por IPs legítimos de crawlers, então combinar múltiplos métodos proporciona proteção melhor do que depender de apenas um. Cada método tem suas vantagens: robots.txt é fácil de implementar, mas não é imposto; bloqueio por IP é confiável, mas exige manutenção; .htaccess oferece aplicação em nível de servidor; e meta tags permitem granularidade em nível de página.
Monitoramento e Verificação
Implementar políticas de crawlers é só metade do trabalho; é preciso monitorar ativamente se os crawlers estão respeitando suas diretrizes e ajustar sua estratégia com base nos padrões reais de tráfego. Logs do servidor são sua principal fonte de dados, normalmente localizados em /var/log/apache2/access.log em servidores Linux ou na pasta de logs do IIS em servidores Windows, onde você pode buscar por user-agent strings específicas para ver quais crawlers estão acessando seu site e com que frequência. Plataformas de análise como Google Analytics, Matomo ou Plausible podem ser configuradas para rastrear o tráfego de bots separadamente dos visitantes humanos, permitindo ver o volume e o comportamento de diferentes crawlers ao longo do tempo. O Cloudflare Radar oferece visibilidade em tempo real dos padrões de tráfego de crawlers na internet e pode mostrar como o tráfego de crawlers no seu site se compara às médias do setor. Para verificar se os crawlers estão respeitando seus bloqueios, você pode usar ferramentas online para checar seu arquivo robots.txt, revisar os logs do servidor em busca de user-agents bloqueados e cruzar endereços IP com as faixas publicadas dos crawlers para confirmar que o tráfego vem de fontes legítimas. Passos práticos de monitoramento incluem: configurar análise semanal de logs para acompanhar o volume de crawlers, configurar alertas para atividade incomum de crawlers, revisar mensalmente seu painel de análise para tendências de tráfego de bots e conduzir revisões trimestrais das políticas de crawlers para garantir que ainda estejam alinhadas com seus objetivos de negócio. O monitoramento regular ajuda a identificar novos crawlers, detectar violações de políticas e tomar decisões baseadas em dados sobre quais crawlers permitir ou bloquear.
O Futuro dos Crawlers de IA
O cenário dos crawlers de IA continua a evoluir rapidamente, com novos players entrando no mercado e crawlers existentes expandindo seus recursos em direções inesperadas. Crawlers emergentes de empresas como xAI (Grok), Mistral e DeepSeek estão começando a coletar dados web em escala, e cada nova startup de IA que surge provavelmente introduzirá seu próprio crawler para dar suporte ao treinamento de modelos e recursos de produtos. Browsers agente representam uma nova fronteira na tecnologia de crawlers, com sistemas como ChatGPT Operator e Comet que conseguem interagir com sites como usuários humanos, clicando em botões, preenchendo formulários e navegando por interfaces complexas; esses agentes baseados em navegador apresentam desafios únicos porque são mais difíceis de identificar e bloquear usando métodos tradicionais. O desafio com agentes baseados em navegador é que eles podem não se identificar claramente nas user-agent strings e podem potencialmente contornar bloqueios baseados em IP usando proxies residenciais ou infraestrutura distribuída. Novos crawlers surgem regularmente, às vezes sem aviso prévio, tornando essencial manter-se informado sobre as novidades do espaço de IA e ajustar suas políticas conforme necessário. A trajetória indica que o tráfego de crawlers continuará a crescer, com a Cloudflare relatando um aumento geral de 18% no tráfego de crawlers de maio de 2024 a maio de 2025, e esse crescimento provavelmente vai acelerar à medida que mais aplicativos de IA se tornarem populares. Proprietários de sites e editores devem permanecer vigilantes e adaptáveis, revisando regularmente suas políticas de crawlers e monitorando novos desenvolvimentos para garantir que suas estratégias permaneçam eficazes nesse cenário em rápida evolução.
Monitorando Sua Marca em Respostas de IA
Embora gerenciar o acesso de crawlers ao seu site seja importante, é igualmente fundamental entender como seu conteúdo está sendo usado e citado em respostas geradas por IA. O AmICited.com é uma plataforma especializada criada para resolver esse problema, acompanhando como crawlers de IA coletam seu conteúdo e monitorando se sua marca e conteúdo estão sendo devidamente citados em aplicativos alimentados por IA. A plataforma ajuda você a entender quais sistemas de IA estão usando seu conteúdo, com que frequência suas informações aparecem em respostas de IA e se está sendo fornecida a atribuição adequada às suas fontes originais. Para editores e criadores de conteúdo, o AmICited.com oferece insights valiosos sobre sua visibilidade dentro do ecossistema de IA, ajudando a medir o impacto da sua decisão de permitir ou bloquear crawlers e entender o valor real que você recebe da descoberta por IA. Ao monitorar suas citações em múltiplas plataformas de IA, você pode tomar decisões mais informadas sobre suas políticas de crawlers, identificar oportunidades para aumentar a visibilidade do seu conteúdo em respostas de IA e garantir que sua propriedade intelectual esteja sendo devidamente atribuída. Se você leva a sério entender a presença da sua marca na web alimentada por IA, o AmICited.com oferece a transparência e as capacidades de monitoramento que você precisa para se manter informado e proteger o valor do seu conteúdo nesta nova era de descoberta impulsionada por IA.
Perguntas frequentes
Qual é a diferença entre crawlers de treinamento e crawlers de busca?
Crawlers de treinamento como GPTBot e ClaudeBot coletam conteúdo para construir conjuntos de dados para o desenvolvimento de grandes modelos de linguagem, tornando-se parte da base de conhecimento da IA. Crawlers de busca como OAI-SearchBot e PerplexityBot indexam conteúdo para experiências de busca com IA e podem enviar tráfego de referência de volta para os editores por meio de citações.
Devo bloquear todos os crawlers de IA ou apenas os de treinamento?
Isso depende das prioridades do seu negócio. Bloquear crawlers de treinamento protege seu conteúdo de ser incorporado em modelos de IA. Bloquear crawlers de busca pode reduzir sua visibilidade em plataformas de descoberta com IA como a busca do ChatGPT ou Perplexity. Muitos editores optam pelo bloqueio seletivo que visa crawlers de treinamento enquanto permite crawlers de busca e citação.
Como posso verificar se um crawler é legítimo ou falsificado?
O método de verificação mais confiável é checar o IP do pedido em relação às faixas de IP oficialmente publicadas pelos operadores de crawlers. Grandes empresas como OpenAI, Anthropic e Amazon publicam os endereços IP de seus crawlers. Você também pode usar regras de firewall para colocar na lista de permissões os IPs verificados e bloquear solicitações de fontes não verificadas que alegam ser crawlers de IA.
Bloquear o Google-Extended afetará meu posicionamento nas buscas?
O Google afirma oficialmente que bloquear o Google-Extended não afeta o posicionamento nas buscas nem a inclusão nos AI Overviews. No entanto, alguns webmasters relataram preocupações, então monitore seu desempenho nas buscas após implementar bloqueios. Os AI Overviews na Busca do Google seguem as regras padrão do Googlebot, não do Google-Extended.
Com que frequência devo atualizar minha lista de bloqueio de crawlers de IA?
Novos crawlers de IA surgem regularmente, portanto revise e atualize sua lista de bloqueios, no mínimo, trimestralmente. Acompanhe recursos como o projeto ai.robots.txt no GitHub para listas mantidas pela comunidade. Verifique os logs do servidor mensalmente para identificar novos crawlers acessando seu site que não estão em sua configuração atual.
Crawlers de IA podem ignorar as diretivas do robots.txt?
Sim, o robots.txt é apenas uma recomendação, não uma imposição. Crawlers bem-comportados de grandes empresas geralmente respeitam as diretivas do robots.txt, mas alguns crawlers as ignoram. Para proteção mais forte, implemente bloqueio em nível de servidor via .htaccess ou regras de firewall e verifique crawlers legítimos usando as faixas de endereços IP publicadas.
Qual é o impacto dos crawlers de IA na largura de banda do meu site?
Crawlers de IA podem gerar carga significativa no servidor e consumo de largura de banda. Alguns projetos de infraestrutura relataram que bloquear crawlers de IA reduziu o consumo de banda de 800GB para 200GB diários, economizando aproximadamente US$ 1.500 por mês. Publicadores de alto tráfego podem ver reduções de custo significativas com bloqueio seletivo.
Como posso monitorar quais crawlers de IA estão acessando meu site?
Verifique os logs do seu servidor (normalmente em /var/log/apache2/access.log no Linux) para identificar user-agent strings que correspondam a crawlers conhecidos. Utilize plataformas de análise como Google Analytics ou Cloudflare Radar para acompanhar o tráfego de bots separadamente. Configure alertas para atividade incomum de crawlers e realize revisões trimestrais das suas políticas de crawlers.
Monitore Sua Marca em Respostas de IA
Acompanhe como plataformas de IA como ChatGPT, Perplexity e Google AI Overviews referenciam seu conteúdo. Receba alertas em tempo real quando sua marca for mencionada em respostas geradas por IA.
Você Deve Bloquear ou Permitir Crawlers de IA? Estrutura para Tomada de Decisão
Aprenda como tomar decisões estratégicas sobre o bloqueio de crawlers de IA. Avalie tipo de conteúdo, fontes de tráfego, modelos de receita e posição competitiv...
Como Identificar Crawlers de IA em Logs de Servidor: Guia Completo de Detecção
Aprenda como identificar e monitorar crawlers de IA como GPTBot, PerplexityBot e ClaudeBot em seus logs de servidor. Descubra strings de user-agent, métodos de ...
Cartão de Referência de Crawlers de IA: Todos os Bots em um Relance
Guia completo de referência sobre crawlers e bots de IA. Identifique GPTBot, ClaudeBot, Google-Extended e mais de 20 outros crawlers de IA com user agents, taxa...
18 min de leitura
Consentimento de Cookies Usamos cookies para melhorar sua experiência de navegação e analisar nosso tráfego. See our privacy policy.