
Alucinações de IA e Segurança de Marca: Protegendo Sua Reputação
Saiba como as alucinações de IA ameaçam a segurança da marca em Google AI Overviews, ChatGPT e Perplexity. Descubra estratégias de monitoramento, técnicas de fo...
11 min de leitura

Descubra como grounding em LLMs e busca na web permitem que sistemas de IA acessem informações em tempo real, reduzam alucinações e forneçam citações precisas. Aprenda sobre RAG, estratégias de implementação e melhores práticas para empresas.
Grandes modelos de linguagem são treinados com enormes quantidades de dados textuais, mas esse processo de treinamento tem uma limitação crítica: captura apenas informações disponíveis até um momento específico no tempo, conhecido como data de corte de conhecimento. Por exemplo, se um LLM foi treinado com dados até dezembro de 2023, ele não tem conhecimento de eventos, descobertas ou desenvolvimentos que ocorreram após essa data. Quando usuários fazem perguntas sobre eventos atuais, lançamentos de produtos recentes ou notícias de última hora, o modelo não pode acessar essas informações em seus dados de treinamento. Em vez de admitir incerteza, LLMs frequentemente geram respostas plausíveis, porém incorretas — um fenômeno conhecido como alucinação. Essa tendência se torna especialmente problemática em aplicações onde a precisão é crítica, como suporte ao cliente, aconselhamento financeiro ou informações médicas, onde informações desatualizadas ou inventadas podem ter consequências graves.
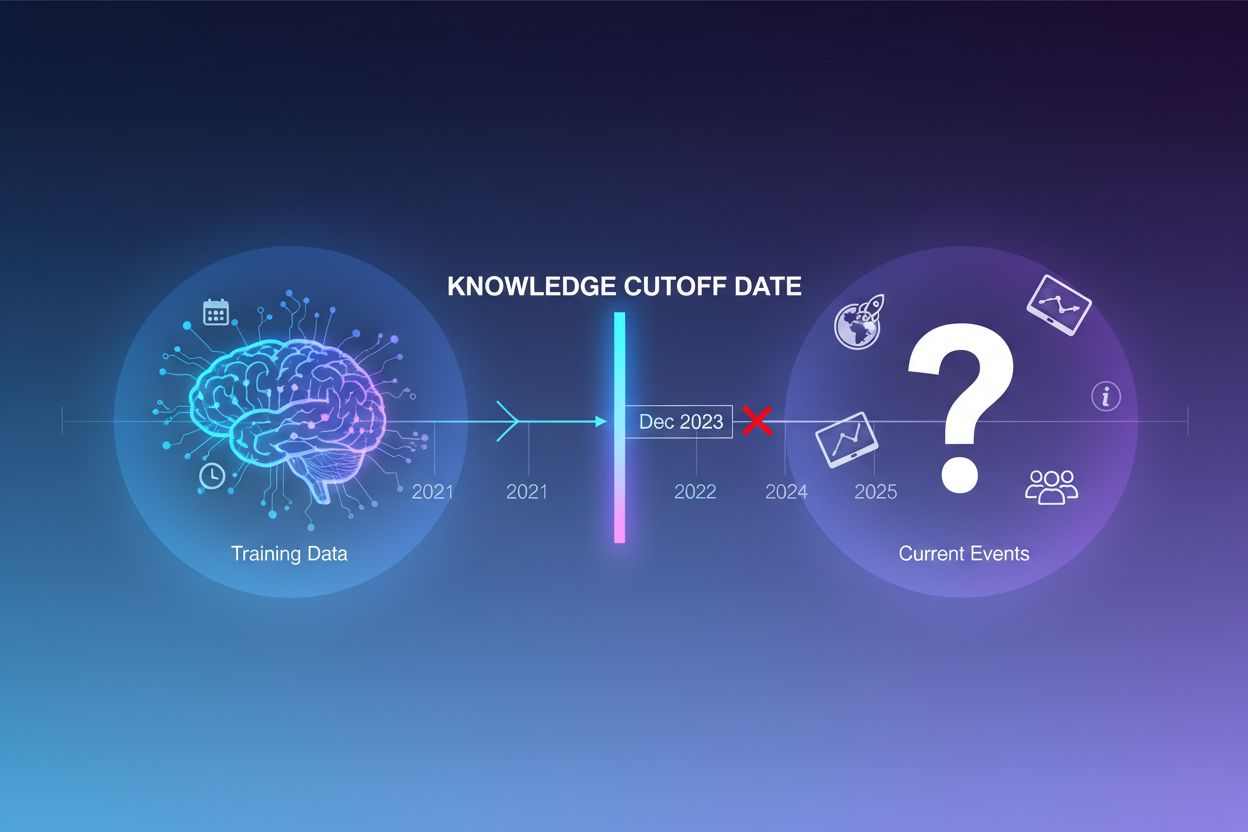
Grounding é o processo de aumentar o conhecimento pré-treinado de um LLM com informações contextuais externas no momento da inferência. Em vez de confiar apenas nos padrões aprendidos durante o treinamento, grounding conecta o modelo a fontes de dados do mundo real — sejam páginas web, documentos internos, bancos de dados ou APIs. Esse conceito vem da psicologia cognitiva, especialmente da teoria da cognição situada, que postula que o conhecimento é mais efetivamente aplicado quando está fundamentado no contexto onde será usado. Na prática, grounding transforma o problema de “gerar uma resposta de memória” para “sintetizar uma resposta a partir de informações fornecidas”. Uma definição rigorosa de pesquisas recentes exige que o LLM utilize todo o conhecimento essencial do contexto fornecido e respeite seu escopo, sem alucinar informações adicionais.
| Aspecto | Resposta Não-Groundeada | Resposta Groundeada |
|---|---|---|
| Fonte de Informação | Apenas conhecimento pré-treinado | Conhecimento pré-treinado + dados externos |
| Precisão para Eventos Recentes | Baixa (limites do cutoff de conhecimento) | Alta (acesso a informações atuais) |
| Risco de Alucinação | Alto (modelo “chuta”) | Baixo (limitado pelo contexto fornecido) |
| Capacidade de Citação | Limitada ou impossível | Total rastreabilidade às fontes |
| Escalabilidade | Fixa (tamanho do modelo) | Flexível (pode adicionar novas fontes de dados) |
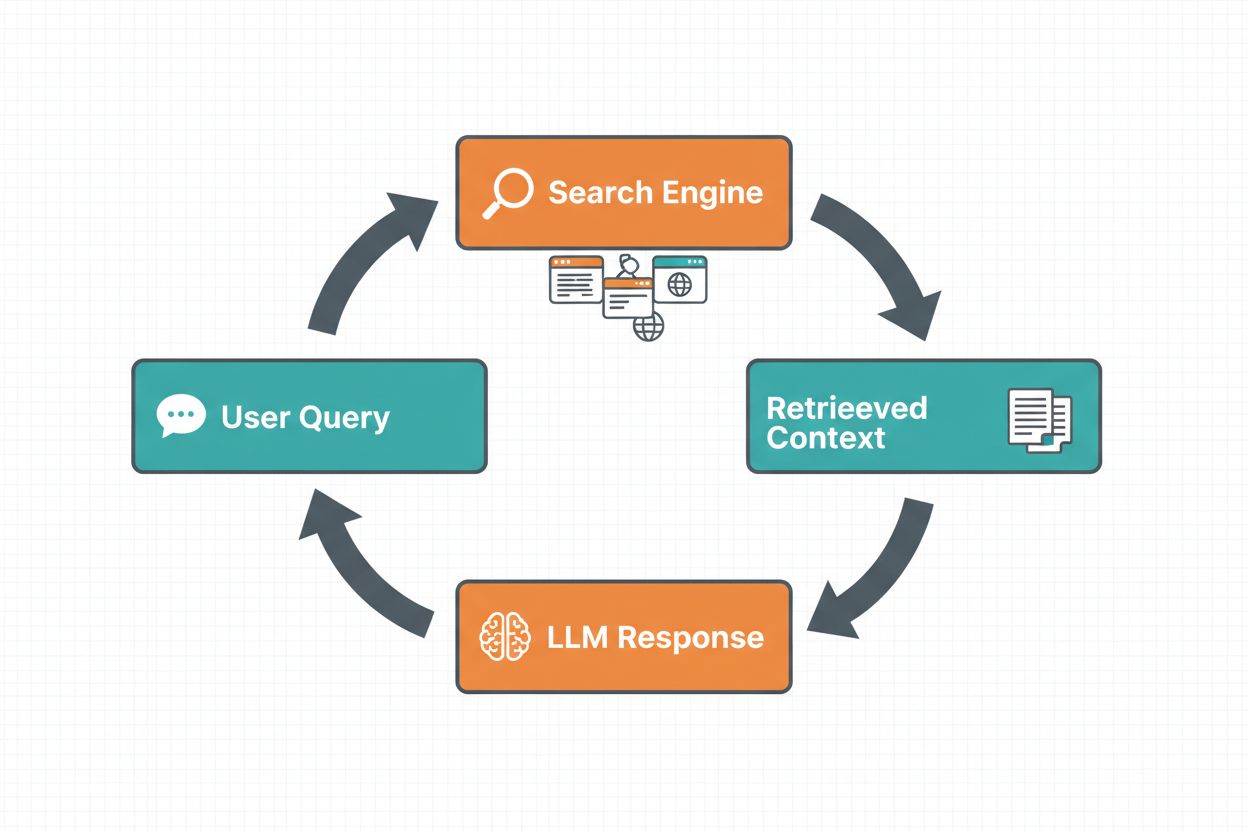
O grounding via busca na web permite que LLMs acessem informações em tempo real ao pesquisar automaticamente na web e incorporar os resultados no processo de geração das respostas do modelo. O fluxo de trabalho segue uma sequência estruturada: primeiro, o sistema analisa o prompt do usuário para determinar se uma busca na web melhoraria a resposta; depois, gera uma ou mais consultas otimizadas para recuperar informações relevantes; em seguida, executa essas consultas em um mecanismo de busca (como Google Search ou DuckDuckGo); depois, processa os resultados e extrai conteúdos relevantes; e, por fim, fornece esse contexto ao LLM como parte do prompt, permitindo que o modelo gere uma resposta fundamentada. O sistema também retorna metadados de grounding — informações estruturadas sobre quais buscas foram executadas, quais fontes foram recuperadas e como partes específicas da resposta são sustentadas por essas fontes. Esses metadados são essenciais para criar confiança e permitir que usuários verifiquem as afirmações.
Fluxo de Trabalho do Grounding via Busca na Web:
Retrieval Augmented Generation (RAG) tornou-se a principal técnica de grounding, combinando décadas de pesquisa em recuperação de informação com as capacidades modernas de LLMs. O RAG funciona recuperando primeiro documentos ou trechos relevantes de uma fonte externa de conhecimento (tipicamente indexada em um banco de dados vetorial) e, em seguida, fornecendo esses itens recuperados como contexto para o LLM. O processo de recuperação normalmente envolve duas etapas: um recuperador utiliza algoritmos eficientes (como BM25 ou busca semântica com embeddings) para identificar documentos candidatos, e um ranqueador usa modelos neurais mais sofisticados para reordenar esses candidatos por relevância. O contexto recuperado é então incorporado ao prompt, permitindo que o LLM sintetize respostas fundamentadas em informações autoritativas. O RAG oferece vantagens significativas em relação ao fine-tuning: é mais econômico (não há necessidade de retreinar o modelo), mais escalável (basta adicionar novos documentos à base de conhecimento) e mais fácil de manter (atualizações sem retreinar). Por exemplo, um prompt RAG pode ser assim:
Use os documentos a seguir para responder à pergunta.
[Pergunta]
Qual é a capital do Canadá?
[Documento 1]
Ottawa é a capital do Canadá, localizada em Ontário...
[Documento 2]
O Canadá é um país na América do Norte com dez províncias...
Um dos benefícios mais atraentes do grounding via busca na web é a capacidade de acessar e incorporar informações em tempo real nas respostas dos LLMs. Isso é especialmente valioso para aplicações que requerem dados atuais — análise de notícias, pesquisa de mercado, informações sobre eventos ou disponibilidade de produtos. Além do simples acesso a informações novas, o grounding fornece citações e atribuição de fontes, o que é crucial para criar confiança e permitir a verificação. Quando um LLM gera uma resposta fundamentada, ele retorna metadados estruturados que mapeiam afirmações específicas aos documentos-fonte, permitindo citações inline como “[1] source.com” diretamente no texto da resposta. Essa capacidade está alinhada diretamente com a missão de plataformas como o AmICited.com, que monitora como sistemas de IA referenciam e citam fontes em diferentes plataformas. A possibilidade de rastrear quais fontes um sistema de IA consultou e como atribuiu informações está se tornando cada vez mais importante para monitoramento de marca, atribuição de conteúdo e garantia de uso responsável da IA.
Alucinações ocorrem porque LLMs são fundamentalmente projetados para prever o próximo token com base nos anteriores e em padrões aprendidos, sem qualquer compreensão inerente dos limites de seu conhecimento. Quando confrontados com perguntas fora de seus dados de treinamento, eles continuam gerando textos plausíveis em vez de admitir incerteza. O grounding resolve isso ao mudar fundamentalmente a tarefa do modelo: em vez de gerar por memória, o modelo agora sintetiza a partir de informações fornecidas. Sob a perspectiva técnica, quando um contexto externo relevante é incluído no prompt, isso desloca a distribuição de probabilidade dos tokens para respostas fundamentadas nesse contexto, tornando as alucinações menos prováveis. Pesquisas demonstram que grounding pode reduzir taxas de alucinação em 30-50%, dependendo da tarefa e implementação. Por exemplo, ao ser perguntado “Quem ganhou a Euro 2024?”, sem grounding, um modelo antigo pode dar uma resposta incorreta; com grounding usando resultados de busca na web, ele identifica corretamente a Espanha como campeã e traz detalhes específicos do jogo. Esse mecanismo funciona porque os mecanismos de atenção do modelo agora podem focar no contexto fornecido em vez de depender de padrões incompletos ou conflitantes do treinamento.
Implementar grounding via busca na web exige a integração de vários componentes: uma API de busca (como Google Search, DuckDuckGo via Serp API ou Bing Search), lógica para determinar quando grounding é necessário e engenharia de prompts para incorporar efetivamente os resultados da busca. Uma implementação prática normalmente começa avaliando se a consulta do usuário exige informação atual — isso pode ser feito perguntando ao próprio LLM se o prompt precisa de algo mais recente que seu cutoff de conhecimento. Se o grounding for necessário, o sistema executa uma busca na web, processa os resultados para extrair trechos relevantes e constrói um prompt que inclui tanto a pergunta original quanto o contexto da busca. Considerações de custo são importantes: cada busca na web gera custos de API, então implementar grounding dinâmico (buscar só quando necessário) pode reduzir drasticamente as despesas. Por exemplo, uma pergunta como “Por que o céu é azul?” provavelmente não exige busca, enquanto “Quem é o presidente atual?” certamente exige. Implementações avançadas usam modelos menores e mais rápidos para tomar a decisão de grounding, reduzindo latência e custos, reservando modelos maiores para a geração da resposta final.
Apesar de poderoso, o grounding introduz vários desafios que precisam ser gerenciados cuidadosamente. Relevância dos dados é crítico — se as informações recuperadas não abordam realmente a pergunta do usuário, o grounding não ajudará e pode até introduzir contexto irrelevante. Quantidade de dados apresenta um paradoxo: embora mais informação pareça benéfica, pesquisas mostram que o desempenho dos LLMs frequentemente piora com excesso de input, um fenômeno chamado viés “perdido no meio”, onde os modelos têm dificuldade em encontrar e usar informações posicionadas no meio de contextos longos. Eficiência de tokens também é questão, já que cada pedaço de contexto recuperado consome tokens, aumentando latência e custo. O princípio do “menos é mais” se aplica: recupere apenas os k resultados mais relevantes (tipicamente 3-5), trabalhe com trechos menores em vez de documentos inteiros e considere extrair frases-chave de passagens longas.
| Desafio | Impacto | Solução |
|---|---|---|
| Relevância dos Dados | Contexto irrelevante confunde o modelo | Use busca semântica + ranqueadores; teste a qualidade da recuperação |
| Viés Perdido no Meio | Modelo ignora info importante no meio | Minimize o tamanho do input; coloque info crítica no início/fim |
| Eficiência de Tokens | Alta latência e custo | Recupere menos resultados; use trechos menores |
| Informação Desatualizada | Contexto desatualizado na base de conhecimento | Implemente políticas de atualização; controle de versões |
| Latência | Respostas lentas devido à busca + inferência | Use operações assíncronas; cache de consultas comuns |
Implantar sistemas de grounding em ambientes de produção requer atenção especial à governança, segurança e operações. Garantia de qualidade dos dados é básica — a informação utilizada no grounding precisa ser precisa, atual e relevante para seus casos de uso. Controle de acesso torna-se fundamental quando o grounding utiliza documentos proprietários ou sensíveis; deve-se garantir que o LLM só acesse informações apropriadas para cada usuário, conforme suas permissões. Gestão de atualização e drift exige políticas para frequência de atualização das bases de conhecimento e para lidar com informações conflitantes entre fontes. Auditoria é essencial para compliance e troubleshooting — registre quais documentos foram recuperados, como foram ranqueados e qual contexto foi fornecido ao modelo. Outras considerações incluem:
O campo do grounding em LLMs está evoluindo rapidamente além da simples recuperação textual. Grounding multimodal está surgindo, permitindo que sistemas fundamentem respostas em imagens, vídeos e dados estruturados além do texto — especialmente importante para áreas como análise de documentos jurídicos, imagens médicas e documentação técnica. Raciocínio automatizado está sendo incorporado ao RAG, permitindo que agentes não apenas recuperem informações, mas também sintetizem a partir de múltiplas fontes, tirem conclusões lógicas e expliquem seu raciocínio. Guardrails estão sendo integrados ao grounding para garantir que, mesmo com acesso a informações externas, os modelos mantenham restrições de segurança e conformidade. Atualizações in-place de modelos representam outra fronteira — em vez de confiar totalmente em recuperação externa, pesquisadores estão explorando maneiras de atualizar os pesos dos modelos diretamente com novas informações, potencialmente reduzindo a necessidade de grandes bases externas de conhecimento. Esses avanços sugerem que os sistemas de grounding do futuro serão mais inteligentes, eficientes e capazes de lidar com tarefas complexas de raciocínio em múltiplas etapas, mantendo precisão factual e rastreabilidade.
Grounding aumenta um LLM com informações externas no momento da inferência sem modificar o próprio modelo, enquanto o fine-tuning retreina o modelo com novos dados. Grounding é mais econômico, rápido de implementar e fácil de atualizar com novas informações. Fine-tuning é melhor quando é necessário mudar fundamentalmente o comportamento do modelo ou quando há padrões específicos de domínio para aprender.
O grounding reduz alucinações ao fornecer ao LLM um contexto factual para se basear, em vez de depender apenas de seus dados de treinamento. Quando informações externas relevantes são incluídas no prompt, a distribuição de probabilidade dos tokens do modelo se desloca para respostas fundamentadas nesse contexto, tornando informações inventadas menos prováveis. Pesquisas mostram que grounding pode reduzir taxas de alucinação em 30-50%.
Retrieval Augmented Generation (RAG) é uma técnica de grounding que recupera documentos relevantes de uma fonte externa de conhecimento e os fornece como contexto para o LLM. RAG é importante porque é escalável, econômico e permite atualizar informações sem retreinar o modelo. Tornou-se o padrão do setor para construir aplicações de IA fundamentadas.
Implemente grounding via busca na web quando sua aplicação precisar de acesso a informações atuais (notícias, eventos, dados recentes), quando precisão e citações forem críticas, ou quando o cutoff de conhecimento do seu LLM for uma limitação. Use grounding dinâmico para buscar apenas quando necessário, reduzindo custos e latência para perguntas que não exigem informações atualizadas.
Os principais desafios incluem garantir a relevância dos dados (as informações recuperadas realmente precisam responder à pergunta), gerenciar a quantidade de dados (mais nem sempre é melhor), lidar com o viés 'perdido no meio', onde modelos perdem informações em contextos longos, e otimizar a eficiência do uso de tokens. As soluções incluem usar busca semântica com ranqueadores, recuperar resultados menos numerosos porém de maior qualidade e posicionar informações críticas no início ou fim do contexto.
Grounding é diretamente relevante para o monitoramento de respostas de IA porque permite que sistemas forneçam citações e atribuição de fontes. Plataformas como o AmICited monitoram como sistemas de IA referenciam fontes, o que só é possível quando o grounding é implementado corretamente. Isso ajuda a garantir o uso responsável da IA e a atribuição de marca em diferentes plataformas de IA.
O viés 'perdido no meio' é um fenômeno em que LLMs têm desempenho pior quando informações relevantes estão no meio de contextos longos, em comparação com informações no início ou fim. Isso ocorre porque os modelos tendem a 'passar os olhos' ao processar grandes quantidades de texto. As soluções incluem minimizar o tamanho do input, posicionar informações críticas em locais preferenciais e usar trechos menores de texto.
Para implantação em produção, foque em garantia de qualidade dos dados, implemente controles de acesso para informações sensíveis, estabeleça políticas de atualização e renovação, habilite logs de auditoria para compliance e crie ciclos de feedback do usuário para identificar falhas. Monitore o uso de tokens para otimizar custos, implemente controle de versões para bases de conhecimento e acompanhe o comportamento do modelo para detecção de drift.
O AmICited monitora como GPTs, Perplexity e Google AI Overviews citam e referenciam seu conteúdo. Obtenha insights em tempo real sobre monitoramento de respostas de IA e atribuição de marca.
Saiba como as alucinações de IA ameaçam a segurança da marca em Google AI Overviews, ChatGPT e Perplexity. Descubra estratégias de monitoramento, técnicas de fo...

Descubra como a Geração Aumentada por Recuperação transforma as citações em IA, permitindo atribuição precisa de fontes e respostas fundamentadas em ChatGPT, Pe...

Saiba o que é alucinação de IA, por que ela acontece no ChatGPT, Claude e Perplexity, e como detectar informações falsas geradas por IA nos resultados de busca....