
Acesso Diferencial de Crawlers
Saiba como permitir ou bloquear seletivamente crawlers de IA com base em objetivos de negócios. Implemente o acesso diferencial de crawlers para proteger seu co...
10 min de leitura

Aprenda como usar o robots.txt para controlar quais bots de IA acessam seu conteúdo. Guia completo para bloquear GPTBot, ClaudeBot e outros crawlers de IA com exemplos práticos e estratégias de configuração.
O cenário do rastreamento web mudou fundamentalmente nos últimos dois anos, indo além do território familiar da indexação dos mecanismos de busca para o mundo complexo do treinamento de modelos de IA. Enquanto o Googlebot do Google sempre foi um visitante previsível nos sites dos editores, uma nova geração de crawlers agora chega com intenções e padrões de consumo dramaticamente diferentes. O GPTBot da OpenAI apresenta uma razão de rastreamento para referência de aproximadamente 1.700:1, ou seja, rastreia 1.700 páginas para gerar apenas uma referência de volta ao seu site, enquanto o ClaudeBot da Anthropic opera em uma razão ainda mais extrema de 73.000:1 — muito diferente da razão de 14:1 do Google, onde a atividade de rastreamento se traduz em tráfego significativo. Essa diferença fundamental cria uma decisão de negócios urgente para criadores de conteúdo: permitir acesso irrestrito a esses bots significa que seu conteúdo treina modelos de IA que competem com seu tráfego e receitas, enquanto seu site recebe pouca compensação ou tráfego em troca. Os editores agora precisam decidir ativamente se a proposta de valor do acesso de bots de IA está alinhada com seu modelo de negócios, tornando a configuração do robots.txt não apenas uma consideração técnica, mas um imperativo estratégico.
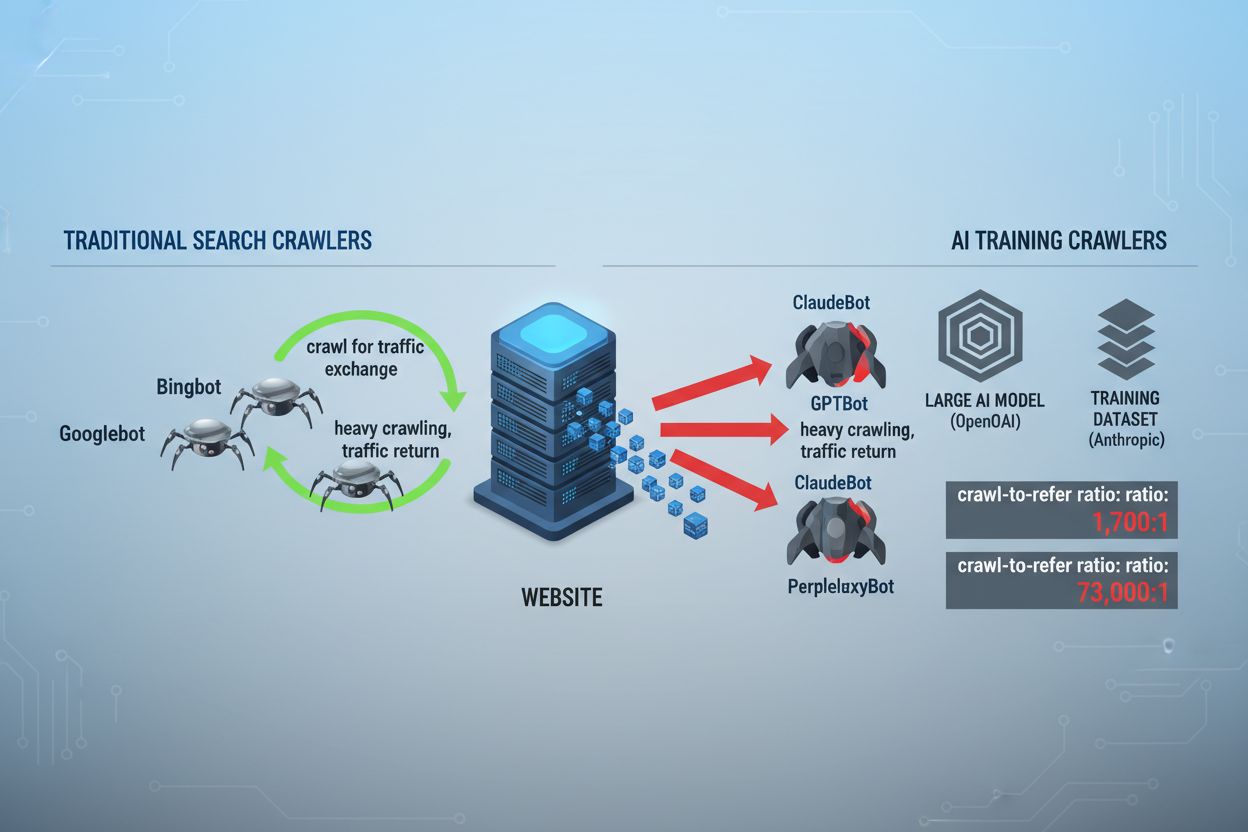
Crawlers de IA operam em três categorias distintas, cada uma servindo a propósitos diferentes e exigindo estratégias de bloqueio específicas. Crawlers de treinamento são projetados para ingerir grandes volumes de conteúdo a fim de treinar modelos fundamentais de IA — incluem GPTBot da OpenAI, ClaudeBot da Anthropic, Google-Extended do Google, PerplexityBot da Perplexity, Meta-ExternalAgent da Meta, Applebot-Extended da Apple e novos players como Amazonbot, Bytespider e cohere-ai. Crawlers de busca, por outro lado, são projetados para alimentar experiências de busca por IA e normalmente retornam tráfego para os editores; incluem OAI-SearchBot da OpenAI, Claude-Web da Anthropic e funcionalidade de busca do Perplexity. Agentes acionados pelo usuário representam uma terceira categoria, onde o conteúdo é acessado sob demanda, quando um usuário solicita informações explicitamente, como ChatGPT-User ou interações Claude-Web iniciadas diretamente por usuários finais. Entender essa taxonomia é essencial porque sua estratégia de bloqueio deve refletir suas prioridades de negócio — você pode receber crawlers de busca que geram tráfego de referência enquanto bloqueia crawlers de treinamento que consomem conteúdo sem compensação. Cada empresa de IA mantém sua própria frota de crawlers especializados, e a distinção entre eles geralmente se resume ao user agent string empregado, tornando a identificação precisa e o bloqueio direcionado essenciais para uma configuração eficaz do robots.txt.
| Empresa | Crawler de Treinamento | Crawler de Busca | Agente Acionado por Usuário |
|---|---|---|---|
| OpenAI | GPTBot | OAI-SearchBot | ChatGPT-User |
| Anthropic | ClaudeBot, anthropic-ai | Claude-Web | claude-web |
| Google-Extended | — | (Usa Googlebot padrão) | |
| Perplexity | PerplexityBot | PerplexityBot | Perplexity-User |
| Meta | Meta-ExternalAgent | — | Meta-ExternalFetcher |
| Apple | Applebot-Extended | — | Applebot |
Manter uma lista precisa e atualizada de user agents de bots de IA é essencial para configurar o robots.txt de forma eficaz, mas esse cenário evolui rapidamente à medida que novos modelos são lançados e empresas ajustam suas estratégias de rastreamento. Os principais crawlers de treinamento que você deve conhecer incluem GPTBot (crawler principal de treinamento da OpenAI), ClaudeBot (Anthropic), anthropic-ai (identificador alternativo da Anthropic), Google-Extended (token de IA do Google), PerplexityBot (Perplexity), Meta-ExternalAgent (Meta), Applebot-Extended (Apple), CCBot (Common Crawl), Amazonbot (Amazon), Bytespider (ByteDance), cohere-ai (Cohere), DuckAssistBot (assistente da DuckDuckGo) e YouBot (You.com). Crawlers focados em busca que normalmente retornam tráfego incluem OAI-SearchBot, Claude-Web e PerplexityBot quando operando em modo de busca. O desafio é que essa lista não é estática — novas empresas de IA surgem regularmente, empresas existentes lançam novos crawlers para novos produtos, e os user agents podem mudar ou expandir. Os editores devem tratar a configuração do robots.txt como um documento vivo, revisando e atualizando trimestralmente, potencialmente assinando recursos de monitoramento do setor ou acompanhando logs do servidor para identificar novos user agents que possam indicar a chegada de novos crawlers de IA ao seu site. Não manter sua lista atualizada pode significar permitir acidentalmente novos crawlers de treinamento que você pretendia bloquear ou bloquear desnecessariamente crawlers legítimos de busca que podem gerar tráfego valioso.
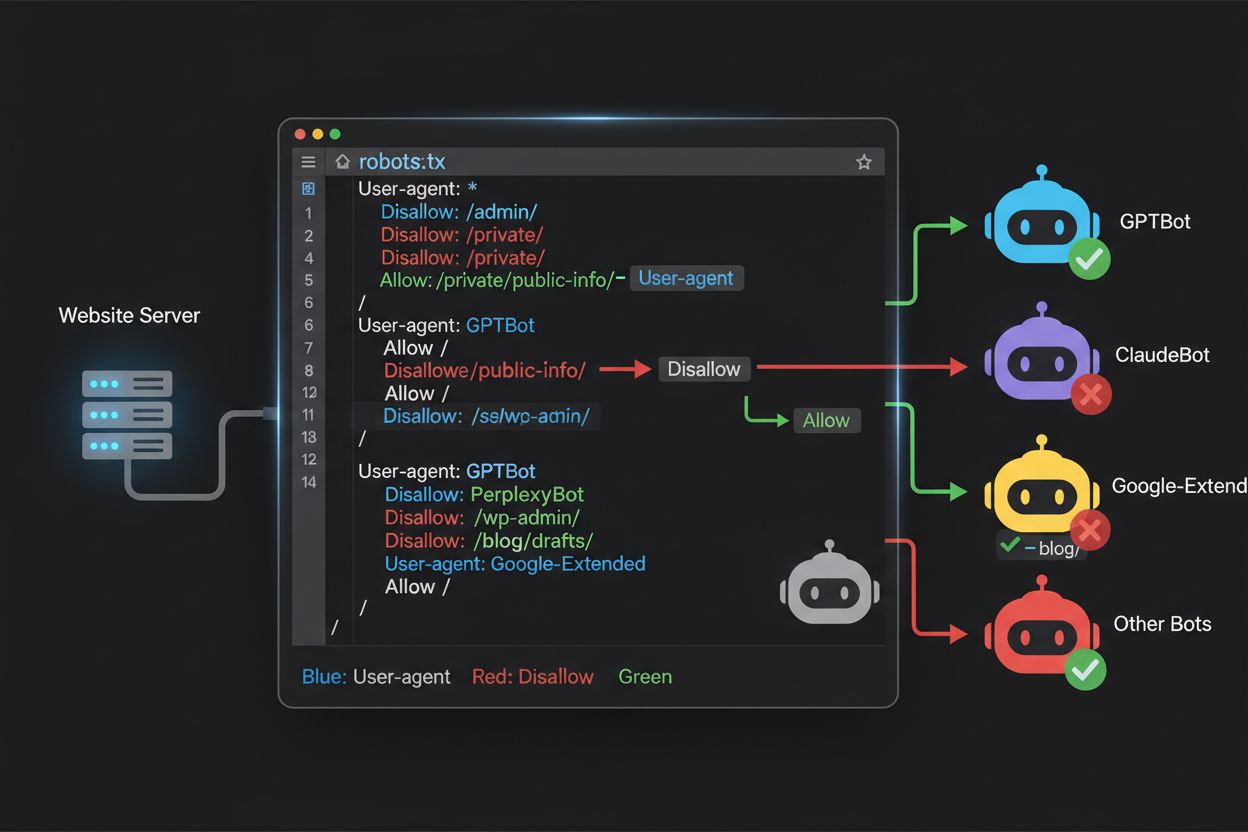
O arquivo robots.txt, localizado na raiz do seu domínio (seudominio.com/robots.txt), usa uma sintaxe direta para comunicar preferências de rastreamento a bots que respeitam o protocolo. Cada regra começa com uma diretiva User-Agent especificando para qual bot a regra se aplica, seguida de uma ou mais diretivas Disallow indicando quais caminhos o bot não pode acessar. Para bloquear todos os principais crawlers de treinamento de IA enquanto preserva o acesso para mecanismos de busca tradicionais, você deve criar blocos User-Agent separados para cada crawler de treinamento que deseja excluir: GPTBot, ClaudeBot, anthropic-ai, Google-Extended, PerplexityBot, Meta-ExternalAgent, Applebot-Extended e outros, cada um com um “Disallow: /” impedindo-os de rastrear qualquer conteúdo do seu site. Ao mesmo tempo, garanta que crawlers legítimos como Googlebot, Bingbot e variantes de busca como OAI-SearchBot permaneçam desbloqueados, permitindo que continuem indexando seu conteúdo e gerando tráfego. Um robots.txt devidamente configurado também deve incluir uma referência ao Sitemap apontando para seu sitemap XML, que ajuda mecanismos de busca a descobrir e indexar seu conteúdo de forma eficiente. A importância de uma configuração correta não pode ser subestimada — um único erro de sintaxe, caractere fora do lugar ou user agent incorreto pode tornar toda sua estratégia de bloqueio ineficaz, permitindo que crawlers indesejados acessem seu conteúdo e, potencialmente, bloqueando fontes legítimas de tráfego. Testar sua configuração antes da implantação não é opcional, mas essencial para garantir que seu robots.txt tenha o efeito desejado.
# Bloquear Crawlers de Treinamento de IA
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: PerplexityBot
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
User-agent: Applebot-Extended
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: Amazonbot
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: cohere-ai
Disallow: /
User-agent: DuckAssistBot
Disallow: /
User-agent: YouBot
Disallow: /
# Permitir mecanismos de busca tradicionais
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
# Referência ao Sitemap
Sitemap: https://yoursite.com/sitemap.xml
Muitos editores enfrentam uma decisão complexa: desejam manter visibilidade em resultados de busca por IA e receber o tráfego de referência que essas plataformas geram, mas querem evitar que seu conteúdo seja usado para treinar modelos fundamentais de IA que competem com seu negócio. Essa estratégia de bloqueio seletivo exige diferenciar crawlers de busca e crawlers de treinamento da mesma empresa — por exemplo, permitindo o OAI-SearchBot da OpenAI (que alimenta a busca do ChatGPT e retorna tráfego) enquanto bloqueia o GPTBot (que treina o modelo subjacente). Da mesma forma, você pode permitir o crawler de busca do Perplexity enquanto bloqueia operações de treinamento, ou permitir o Claude-Web para buscas acionadas por usuários e bloquear as atividades de treinamento do ClaudeBot. O motivo de negócio é claro: crawlers de busca normalmente operam em razões de rastreamento para referência muito menores porque são projetados para gerar tráfego para seu site, enquanto crawlers de treinamento consomem conteúdo em grande escala com mínimo benefício recíproco. Essa abordagem exige configuração cuidadosa e monitoramento contínuo, pois as empresas podem alterar estratégias de crawlers ou introduzir novos user agents que confundem a linha entre busca e treinamento. Editores que adotam essa estratégia devem auditar regularmente seus logs do servidor para verificar se os crawlers pretendidos estão acessando seu conteúdo enquanto os bloqueados estão realmente excluídos, ajustando o robots.txt à medida que o cenário de IA evolui e novos players entram no mercado.
# Permitir Crawlers de Busca de IA
User-agent: OAI-SearchBot
Allow: /
User-agent: Perplexity-User
Allow: /
User-agent: ChatGPT-User
Allow: /
# Bloquear Crawlers de Treinamento
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
Mesmo webmasters experientes cometem erros de configuração que minam completamente sua estratégia de robots.txt, deixando o conteúdo vulnerável aos crawlers que pretendiam bloquear. O primeiro erro comum é criar linhas User-Agent isoladas sem diretivas Disallow correspondentes — por exemplo, escrever “User-Agent: GPTBot” em uma linha e já começar uma nova regra sem especificar o que o GPTBot deve ser impedido de acessar, deixando o bot completamente desbloqueado. O segundo erro envolve localização incorreta do arquivo, nomeação ou sensibilidade a maiúsculas e minúsculas; o arquivo deve ser nomeado exatamente “robots.txt” (minúsculo), localizado na raiz do domínio e servido com código HTTP 200 — colocá-lo em subdiretório ou nomeá-lo “Robots.txt” ou “robots.TXT” o torna invisível para crawlers. O terceiro erro é inserir linhas em branco dentro de um bloco de regras, que muitos parsers de robots.txt interpretam como fim daquela regra, fazendo com que diretivas posteriores sejam ignoradas ou mal aplicadas. O quarto erro envolve sensibilidade a maiúsculas em caminhos de URL; nomes de user agent não diferenciam maiúsculas, mas os caminhos em Disallow são sensíveis, então “Disallow: /Admin” não bloqueará “/admin” ou “/ADMIN”. O quinto erro é uso incorreto de curingas — o asterisco (*) corresponde a qualquer sequência de caracteres, mas muitos editores usam erroneamente padrões como “Disallow: .pdf” quando deveriam usar “Disallow: /.pdf” ou “Disallow: /*pdf” para corresponder corretamente a extensões. Além disso, alguns criam regras excessivamente complexas com múltiplas diretivas Disallow que se contradizem, ou não consideram parâmetros de URL e query strings, o que pode fazer com que conteúdo legítimo seja bloqueado ou conteúdo indesejado permaneça acessível. Testar sua configuração com validadores dedicados de robots.txt antes da implantação pode detectar esses erros antes de impactar a rastreabilidade do seu site.
Erros Comuns para Evitar:
Google-Extended representa um caso único na configuração do robots.txt porque funciona como um token de controle e não como um crawler tradicional, e entender essa distinção é fundamental para tomar decisões informadas de bloqueio. Diferente do Googlebot, que rastreia seu site para indexar conteúdo para o Google Search, o Google-Extended é um sinal que controla se seu conteúdo pode ser usado para treinar os modelos Gemini do Google e alimentar a funcionalidade de AI Overviews nos resultados de busca. Bloquear o Google-Extended impede que seu conteúdo seja usado no treinamento do Gemini e na geração de AI Overviews, mas não afeta sua visibilidade nos resultados tradicionais do Google Search — o Googlebot continuará indexando normalmente. O impacto é significativo: bloquear o Google-Extended significa que seu conteúdo não aparecerá em AI Overviews, que estão cada vez mais presentes nos resultados de busca do Google e podem gerar tráfego importante, mas protege seu conteúdo de ser usado para treinar um modelo concorrente. Por outro lado, permitir o Google-Extended faz com que seu conteúdo possa aparecer nos AI Overviews (potencialmente gerando tráfego), mas também contribui para os dados de treinamento do Gemini, o que pode eventualmente competir com seu próprio conteúdo ou modelo de negócios. Editores devem considerar cuidadosamente sua situação específica — organizações de notícias e criadores de conteúdo cujo negócio depende de tráfego direto podem se beneficiar de bloquear o Google-Extended, enquanto outros podem buscar a visibilidade e o potencial de tráfego dos AI Overviews. Essa decisão deve ser tomada de forma intencional e não por padrão, pois tem implicações significativas para sua visibilidade e padrões de tráfego a longo prazo no ecossistema do Google.
Testar sua configuração do robots.txt antes de implantá-la em produção é absolutamente fundamental, pois erros podem ter consequências sérias tanto para sua visibilidade em buscas quanto para sua estratégia de proteção do conteúdo. O Google Search Console oferece um tester integrado de robots.txt que permite verificar se user agents específicos podem acessar URLs do seu site — você pode inserir uma string de user agent como “GPTBot” e um caminho de URL, e o Google informará se o bot seria permitido ou bloqueado de acordo com sua configuração atual. O Merkle Robots.txt Tester oferece funcionalidade semelhante com interface amigável e explicações detalhadas de como suas regras estão sendo interpretadas. O TechnicalSEO.com fornece outra ferramenta gratuita que valida a sintaxe do seu robots.txt e mostra exatamente como diferentes bots seriam tratados. Para monitoramento mais abrangente, o Knowatoa AI Search Console oferece ferramentas especializadas para rastrear atividade de crawlers de IA e validar sua configuração contra os bots que você deseja bloquear. Seu fluxo de validação deve incluir o upload do robots.txt em um ambiente de staging primeiro, depois a verificação de que páginas críticas que você quer manter acessíveis não estão bloqueadas por engano, confirmação de que os bots que você pretende bloquear estão de fato sendo excluídos e monitoramento dos logs do servidor para qualquer atividade inesperada de crawlers. Essa fase de testes também deve checar se a referência ao Sitemap está correta e se mecanismos de busca ainda podem acessar seu conteúdo normalmente — o objetivo é bloquear crawlers de treinamento de IA sem bloquear acidentalmente tráfego legítimo de busca. Só após testes rigorosos você deve implantar a configuração em produção, e mesmo assim, continue monitorando os logs durante a primeira semana para identificar possíveis problemas.
Ferramentas de Teste:
Embora o robots.txt seja uma boa primeira linha de defesa, é importante entender que ele funciona sob um sistema de honra — bots que respeitam o protocolo seguirão suas diretivas, mas crawlers maliciosos ou mal projetados podem ignorar completamente o robots.txt e acessar seu conteúdo mesmo assim. Dados do setor sugerem que o robots.txt bloqueia com sucesso cerca de 40-60% do tráfego de crawlers indesejados, ou seja, 40-60% dos bots ignoram o protocolo ou são projetados para contorná-lo. Para editores que precisam de proteção mais robusta, camadas adicionais de defesa tornam-se necessárias. O Web Application Firewall (WAF) do Cloudflare permite criar regras para bloquear tráfego com base em user agents, endereços IP ou padrões de comportamento, proporcionando proteção contra bots que ignoram o robots.txt. Ferramentas no nível do servidor, como .htaccess (em servidores Apache) ou configuração equivalente no Nginx, podem bloquear user agents ou faixas de IPs específicos antes mesmo que os pedidos cheguem à sua aplicação. O bloqueio de IP pode ser eficaz se você identificar as faixas de IP usadas por crawlers específicos, embora isso exija manutenção contínua, já que a infraestrutura dos crawlers muda. Ferramentas como Fail2ban podem bloquear automaticamente IPs que apresentam padrões suspeitos, como requisições em velocidade anormal ou acesso a caminhos sensíveis. Porém, a implantação dessas proteções adicionais exige cuidado — bloqueios excessivamente agressivos podem excluir tráfego legítimo, incluindo usuários reais acessando seu site por VPNs ou proxies empresariais compartilhados com crawlers conhecidos. A abordagem mais eficaz combina o robots.txt como pedido educado, bloqueio de user agents no servidor para bots que ignoram o robots.txt e monitoramento comportamental para capturar crawlers sofisticados que falsificam user agents ou usam IPs distribuídos. Edite e implemente essas camadas gradualmente, testando cada uma para garantir que não bloqueiem tráfego legítimo enquanto atingem os objetivos de proteção do conteúdo.
Entender o que realmente está acessando seu site é essencial para validar se a configuração do robots.txt está funcionando como esperado e para identificar novos crawlers que podem precisar ser bloqueados. A análise de logs do servidor é o método principal para esse monitoramento — os logs do seu servidor web (logs de acesso do Apache, logs do Nginx ou equivalentes) contêm registros detalhados de cada requisição ao seu site, incluindo user agent, IP, horário e recurso solicitado. Você pode usar ferramentas de linha de comando como grep para buscar user agents específicos; por exemplo, “grep ‘GPTBot’ /var/log/apache2/access.log” mostrará todas as requisições do GPTBot, permitindo verificar se suas regras de bloqueio estão funcionando. Análises mais sofisticadas podem envolver o processamento dos logs para identificar a taxa de rastreamento de diferentes bots, páginas acessadas e se estão respeitando as diretivas do robots.txt. Soluções de monitoramento automatizado podem analisar seus logs continuamente e alertá-lo quando aparecem crawlers novos ou inesperados, especialmente útil diante da evolução rápida do cenário de crawlers de IA. Alguns editores usam plataformas de agregação de logs como ELK Stack, Splunk ou soluções em nuvem para centralizar e analisar atividade de crawlers em múltiplos servidores. O cenário em rápida mudança dos crawlers de IA significa que o monitoramento não é uma tarefa pontual, mas uma responsabilidade contínua — novos bots surgem regularmente, bots existentes mudam suas strings de user agent e o comportamento dos crawlers evolui conforme as empresas ajustam suas estratégias. Estabeleça uma rotina regular de monitoramento (revisões semanais ou mensais dos logs) para se antecipar às mudanças e ajustar o robots.txt proativamente, em vez de descobrir problemas de forma reativa após impactarem seu site.
Sua configuração do robots.txt para crawlers de IA é, fundamentalmente, uma decisão de receita e merece a mesma consideração estratégica aplicada a qualquer escolha de negócio com impacto financeiro significativo. Permitir acesso irrestrito de crawlers de treinamento ao seu conteúdo significa que modelos de IA treinados com seus dados podem eventualmente competir com seu tráfego e receitas — se seu modelo de negócio depende de tráfego direto, visibilidade em buscas ou receita de anúncios, você estará fornecendo gratuitamente dados de treinamento para empresas que constroem produtos concorrentes. Por outro lado, bloquear todos os crawlers de IA significa perder potencial visibilidade em resultados de busca por IA e tráfego de referência de assistentes de IA, que representam uma fatia crescente da descoberta de conteúdo. A estratégia ideal depende do seu modelo de negócio: editores sustentados por anúncios podem se beneficiar ao permitir crawlers de busca (que geram tráfego e impressões) e bloquear crawlers de treinamento (que não geram tráfego). Editores por assinatura podem adotar postura mais agressiva, bloqueando a maioria dos crawlers de IA para proteger seu conteúdo de ser resumido ou replicado por sistemas de IA. Editores focados em visibilidade de marca e liderança de pensamento podem buscar a visibilidade em buscas de IA como forma de distribuição. O importante é tomar essa decisão de forma intencional e não por padrão — muitos editores nunca configuraram o robots.txt para crawlers de IA, permitindo todos os bots por padrão, ou seja, tomaram uma decisão passiva de contribuir com conteúdo para treinamento de IA sem optar ativamente por isso. Considere também implementar schema markup para garantir atribuição adequada quando seu conteúdo for usado por sistemas de IA, ajudando a garantir que tráfego e crédito retornem ao seu site mesmo quando o conteúdo é referenciado por assistentes de IA. Sua configuração do robots.txt deve refletir uma estratégia de negócio deliberada, revisada e atualizada regularmente à medida que o cenário de IA evolui e suas próprias prioridades mudam.
O cenário de crawlers de IA evolui em ritmo sem precedentes, com novas empresas lançando produtos de IA, empresas estabelecidas introduzindo novos crawlers e user agents mudando ou expandindo regularmente. Sua configuração do robots.txt não deve ser um arquivo “configure e esqueça”, mas um documento vivo que você revisa e atualiza pelo menos trimestralmente. Estabeleça um processo para monitorar anúncios do setor sobre novos crawlers de IA, assine newsletters ou blogs relevantes que acompanham esses desenvolvimentos e audite regularmente seus logs para identificar user agents desconhecidos que possam indicar a chegada de novos crawlers ao seu site. Ao descobrir novos crawlers, pesquise seu propósito e modelo de negócio para decidir se eles se alinham à sua estratégia de proteção de conteúdo e atualize seu robots.txt conforme necessário. Além disso, monitore a eficácia da configuração acompanhando métricas como volume de tráfego de crawlers, razão de requisições de crawlers para tráfego de usuários e quaisquer mudanças em sua visibilidade orgânica ou tráfego de referência de resultados de busca de IA. Alguns editores percebem que sua estratégia inicial precisa de ajustes após alguns meses de dados reais — talvez descubram que bloquear determinado crawler teve consequências inesperadas, ou que permitir certos crawlers gera tráfego mais valioso do que o esperado. Esteja preparado para iterar sua estratégia com base em resultados reais e não em suposições. Por fim, comunique sua estratégia de robots.txt para os stakeholders relevantes da organização — sua equipe de SEO, conteúdo e liderança empresarial devem entender por que certos crawlers são bloqueados ou permitidos, para que as decisões permaneçam consistentes e intencionais à medida que a organização evolui. Essa atenção contínua à gestão de crawlers garante que sua estratégia de proteção de conteúdo continue eficaz e alinhada aos objetivos de negócio enquanto o cenário de IA continua a se transformar.
Não. Bloquear crawlers de treinamento de IA como GPTBot, ClaudeBot e CCBot não afeta seu ranking no Google ou Bing. Os mecanismos de busca tradicionais usam crawlers diferentes (Googlebot, Bingbot) que operam de forma independente. Só bloqueie esses se quiser desaparecer completamente dos resultados de busca.
Principais crawlers da OpenAI (GPTBot), Anthropic (ClaudeBot), Google (Google-Extended) e Perplexity (PerplexityBot) afirmam oficialmente que respeitam as diretivas do robots.txt. No entanto, bots menores ou menos transparentes podem ignorar sua configuração, por isso existem estratégias de proteção em camadas.
Depende da sua estratégia. Bloquear apenas crawlers de treinamento (GPTBot, ClaudeBot, CCBot) protege seu conteúdo do treinamento de modelos, permitindo que crawlers focados em busca ajudem você a aparecer em resultados de busca por IA. Bloqueio completo remove você dos ecossistemas de IA totalmente.
Revise sua configuração pelo menos trimestralmente. Empresas de IA introduzem novos crawlers regularmente. A Anthropic fundiu seus bots 'anthropic-ai' e 'Claude-Web' no 'ClaudeBot', dando ao novo bot acesso irrestrito temporário a sites que não atualizaram suas regras.
O robots.txt é um arquivo na raiz do seu domínio que se aplica a todas as páginas, enquanto as meta tags robots são diretivas HTML em páginas individuais. O robots.txt é verificado primeiro e pode impedir crawlers de acessar páginas, enquanto as meta tags só são lidas se a página for acessada. Use ambos para controle abrangente.
Sim. Você pode usar regras Disallow específicas por caminho no robots.txt (ex.: 'Disallow: /premium/' para bloquear apenas conteúdo premium) ou usar meta tags robots em páginas individuais. Isso permite proteger conteúdo sensível enquanto libera outras áreas para crawlers.
Se um bot ignorar o robots.txt, você precisará de métodos adicionais de proteção como bloqueio no nível do servidor (.htaccess), bloqueio de IP ou regras de WAF. O robots.txt bloqueia cerca de 40-60% dos crawlers indesejados, então proteção em camadas é importante para defesa completa.
Use ferramentas de teste como o tester do robots.txt do Google Search Console, Merkle Robots.txt Tester ou TechnicalSEO.com para validar sua configuração. Monitore os logs do servidor para atividade de crawlers e verifique se bots bloqueados estão sendo excluídos e bots permitidos estão acessando seu conteúdo.
O robots.txt é apenas o primeiro passo. Use o AmICited para acompanhar quais sistemas de IA estão citando seu conteúdo, com que frequência fazem referência a você, e garanta a atribuição adequada entre GPTs, Perplexity, Google AI Overviews e mais.
Saiba como permitir ou bloquear seletivamente crawlers de IA com base em objetivos de negócios. Implemente o acesso diferencial de crawlers para proteger seu co...

Saiba o que significa orçamento de rastreamento para IA, como ele difere do orçamento de rastreamento tradicional dos mecanismos de busca e por que isso importa...
Frequência de rastreamento é a periodicidade com que mecanismos de busca e rastreadores de IA visitam seu site. Saiba o que afeta as taxas de rastreamento, por ...