
Token
Saiba o que são tokens em modelos de linguagem. Tokens são unidades fundamentais de processamento de texto em sistemas de IA, representando palavras, subpalavra...
12 min de leitura

Explore como os limites de tokens afetam a performance da IA e aprenda estratégias práticas para otimização de conteúdo, incluindo RAG, chunking e técnicas de sumarização.
Tokens são os blocos fundamentais que modelos de IA usam para processar e entender informações. Em vez de trabalhar com palavras ou frases completas, grandes modelos de linguagem dividem o texto em unidades menores chamadas tokens, que podem ser caracteres individuais, subpalavras ou palavras completas dependendo do algoritmo de tokenização. Cada token recebe um identificador numérico único que o modelo utiliza internamente para cálculos. Esse processo de tokenização é essencial porque permite que sistemas de IA lidem com entradas de comprimento variável de maneira eficiente e mantenham um processamento consistente entre diferentes tipos de conteúdo. Entender tokens é crucial para qualquer pessoa que trabalhe com sistemas de IA, pois eles impactam diretamente o desempenho, o custo e a qualidade dos resultados alcançados.
Diferentes modelos de IA possuem limites de tokens bastante distintos, que definem a quantidade máxima de informação que podem processar em uma única solicitação. Esses limites evoluíram drasticamente nos últimos anos, com modelos mais recentes suportando janelas de contexto significativamente maiores. O limite de tokens abrange tanto tokens de entrada (seu prompt e dados) quanto tokens de saída (resposta do modelo), criando um orçamento compartilhado que deve ser cuidadosamente gerenciado. Compreender esses limites é essencial para escolher o modelo certo para seu caso de uso e planejar a arquitetura da aplicação de acordo.
| Modelo | Limite de Tokens | Caso de Uso Principal | Nível de Custo |
|---|---|---|---|
| GPT-3.5 Turbo | 4.096 | Conversas curtas, tarefas rápidas | Baixo |
| GPT-4 | 8.192 | Aplicações padrão, complexidade moderada | Médio |
| GPT-4 Turbo | 128.000 | Documentos longos, análise complexa | Alto |
| Claude 3.5 Sonnet | 200.000 | Documentos extensos, análise abrangente | Alto |
| Gemini 1.5 Pro | 1.000.000 | Grandes volumes de dados, livros inteiros, análise de vídeo | Muito Alto |
Principais considerações ao avaliar limites de tokens:
Os limites de tokens criam restrições significativas que afetam diretamente a precisão, confiabilidade e custo-benefício das aplicações de IA. Ao exceder o limite de tokens de um modelo, a aplicação falha completamente—não há degradação gradual ou processamento parcial. Mesmo dentro dos limites, abordagens ingênuas como truncamento simples podem degradar severamente o desempenho ao remover contextos críticos necessários para gerar respostas precisas. Isso é particularmente problemático em áreas como análise jurídica, pesquisa médica e engenharia de software, nas quais a ausência de um único detalhe importante pode levar a conclusões incorretas. O desafio se torna ainda mais complexo ao considerar que diferentes tipos de conteúdo consomem tokens em taxas diferentes—dados estruturados como código ou JSON exigem significativamente mais tokens do que texto simples em inglês devido a símbolos e formatação.
O truncamento é o método mais simples para lidar com limites de tokens—basta cortar o conteúdo excedente quando ultrapassa a capacidade do modelo. Embora fácil de implementar, essa abordagem traz riscos significativos. Ao truncar o texto, inevitavelmente perde-se informação, e o modelo não tem como saber o que foi removido. Isso pode levar a análises incompletas, contexto ausente e até alucinações, quando o modelo gera informações plausíveis, porém incorretas, para preencher lacunas em sua compreensão.
def truncate_text(text: str, max_tokens: int) -> str:
"""Simple truncation approach - not recommended for production"""
tokens = encode(text)
if len(tokens) > max_tokens:
truncated_tokens = tokens[:max_tokens]
return decode(truncated_tokens)
return text
# Example: Truncating to 4000 tokens
long_document = load_document("legal_contract.pdf")
truncated = truncate_text(long_document, 4000)
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": truncated}]
)
Uma estratégia de truncamento mais sofisticada distingue entre conteúdo essencial e opcional. Você pode priorizar elementos obrigatórios, como a consulta do usuário atual e instruções principais, e então adicionar contexto opcional, como histórico de conversas, apenas se houver espaço disponível. Essa abordagem preserva informações críticas, respeitando ao mesmo tempo os limites de tokens.
Em vez de truncar, o chunking divide o conteúdo em partes menores e gerenciáveis que podem ser processadas de forma independente ou seletiva. O chunking de tamanho fixo divide o texto em segmentos uniformes, enquanto o chunking semântico utiliza embeddings para identificar pontos de divisão naturais baseados em significado, e não em contagem arbitrária de tokens. Janelas deslizantes com sobreposição preservam o contexto entre os chunks, garantindo que informações importantes que atravessam as fronteiras dos segmentos não sejam perdidas.
O chunking hierárquico cria múltiplos níveis de abstração—parágrafos individuais no nível mais detalhado, seções no próximo nível e capítulos no nível mais alto. Essa abordagem permite estratégias sofisticadas de recuperação, possibilitando identificar rapidamente seções relevantes sem processar o documento inteiro. Quando combinado com bancos de dados vetoriais e busca semântica, o chunking se torna uma ferramenta poderosa para gerenciar grandes bases de conhecimento, mantendo relevância e precisão.
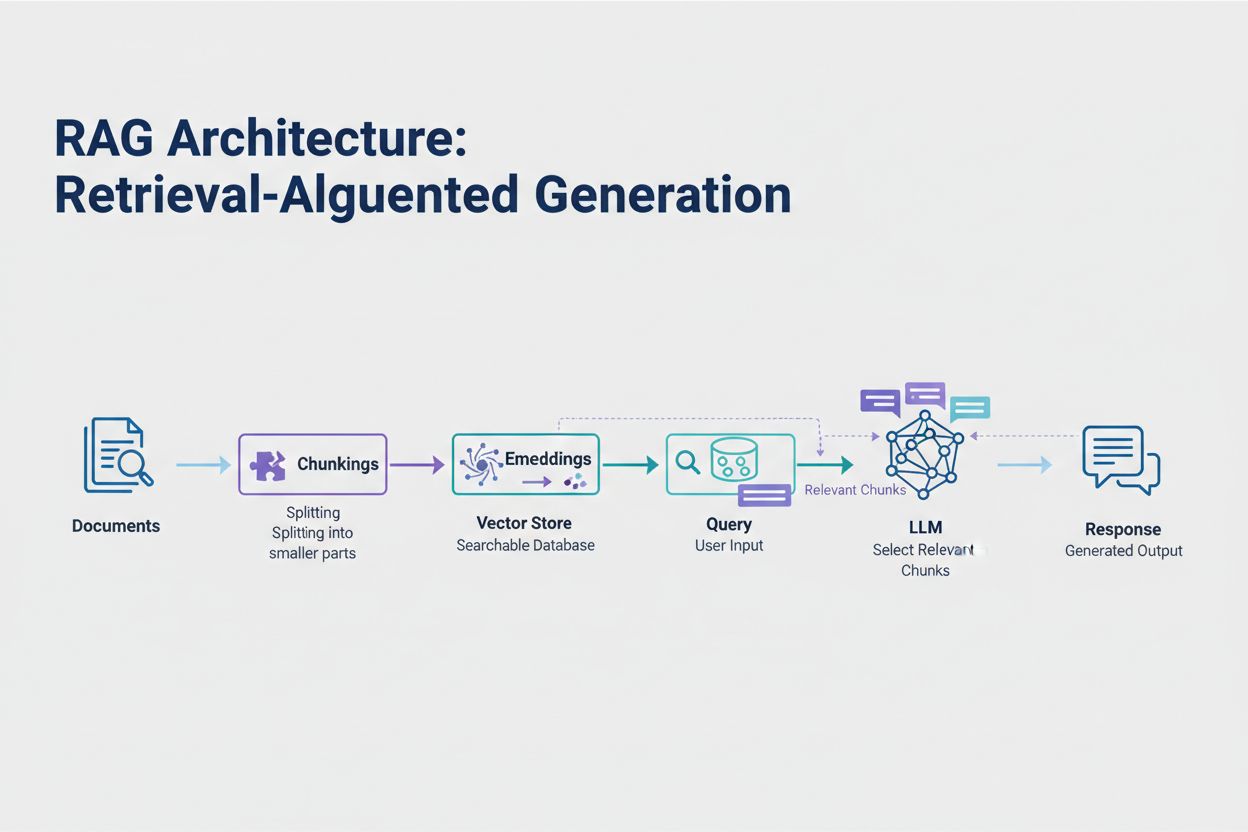
A Geração Aumentada por Recuperação (RAG) representa a abordagem moderna mais eficaz para lidar com limites de tokens. Em vez de tentar encaixar todos os dados na janela de contexto do modelo, o RAG recupera apenas as informações mais relevantes no momento da consulta. O processo começa convertendo seus documentos em embeddings—representações numéricas que capturam o significado semântico. Esses embeddings são armazenados em um banco de dados vetorial, permitindo buscas por similaridade rápidas.
Quando um usuário faz uma consulta, o sistema transforma a consulta em embedding e recupera os chunks de documento mais relevantes do banco vetorial. Somente esses trechos relevantes são injetados no prompt junto com a pergunta do usuário, reduzindo drasticamente o consumo de tokens enquanto melhora a precisão. Por exemplo, analisar um contrato jurídico de 100 páginas com RAG pode exigir apenas 3-5 cláusulas-chave no prompt, em comparação a milhares de tokens necessários para incluir o documento completo.
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
# Step 1: Load and chunk documents
documents = load_documents("knowledge_base/")
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = splitter.split_documents(documents)
# Step 2: Create embeddings and vector store
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(chunks, embeddings)
# Step 3: Set up RAG chain
retriever = vectorstore.as_retriever(search_kwargs={"k": 5})
llm = ChatOpenAI(model="gpt-4", temperature=0)
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=retriever,
return_source_documents=True
)
# Step 4: Query the system
result = qa_chain.run("What are the key terms of this contract?")
A sumarização condensa conteúdos extensos enquanto preserva informações essenciais, reduzindo de forma eficaz o consumo de tokens. A sumarização extrativa seleciona frases-chave do texto original, enquanto a sumarização abstrativa gera novo texto conciso que captura as ideias principais. A sumarização hierárquica cria múltiplos níveis de resumos—primeiro resumindo seções individuais, depois combinando esses resumos em visões gerais de nível superior. Essa abordagem funciona especialmente bem para documentos estruturados como artigos científicos ou relatórios técnicos.
A compressão de contexto adota uma abordagem diferente ao remover redundâncias e conteúdo irrelevante, mantendo a redação original. Técnicas de grafo de conhecimento extraem entidades e relações do texto, reconstruindo o contexto apenas com os fatos mais relevantes. Essas técnicas podem alcançar uma redução de 40-60% nos tokens mantendo a precisão semântica, tornando-se valiosas para otimização de custos em sistemas de produção.
O gerenciamento de tokens impacta diretamente os custos da sua aplicação de IA. Cada token consumido durante a inferência gera um custo, e os valores escalam linearmente conforme o uso de tokens. Monitorar o consumo de tokens é essencial para entender a estrutura de custos e identificar oportunidades de otimização. Muitas plataformas de IA agora oferecem utilitários de contagem de tokens e painéis em tempo real que acompanham padrões de uso, ajudando a identificar quais consultas ou funcionalidades consomem mais tokens.
Um monitoramento eficaz revela oportunidades de otimização—talvez certos tipos de consultas excedam consistentemente os limites de tokens, ou funcionalidades específicas consumam recursos desproporcionais. Ao acompanhar esses padrões, você pode tomar decisões informadas sobre qual estratégia de otimização implementar. Algumas aplicações se beneficiam do direcionamento de solicitações grandes para modelos mais capazes (porém mais caros), enquanto outras ganham mais ao implementar RAG ou sumarização. O fundamental é medir a performance e os custos reais para validar as escolhas de otimização.
A escolha da estratégia de gerenciamento de tokens ideal depende do seu caso de uso, requisitos de desempenho e restrições de custo. Aplicações que exigem alta precisão com respostas fundamentadas se beneficiam mais do RAG, que preserva a fidelidade da informação enquanto gerencia o consumo de tokens. Aplicações conversacionais de longa duração se beneficiam de técnicas de buffer de memória que resumem o histórico da conversa, preservando decisões e contextos importantes. Aplicações com muitos documentos, como análise jurídica ou ferramentas de pesquisa, geralmente se beneficiam de sumarização hierárquica combinada com chunking semântico.
Testes e validações são críticos antes de implantar qualquer estratégia de gerenciamento de tokens em produção. Crie casos de teste que excedam os limites de tokens do seu modelo e avalie como diferentes estratégias afetam precisão, latência e custo. Meça métricas como relevância da resposta, precisão factual e eficiência de tokens para garantir que a abordagem escolhida atenda aos seus requisitos. Armadilhas comuns incluem sumarização excessivamente agressiva que perde detalhes críticos, sistemas de recuperação que deixam de captar informações relevantes e estratégias de chunking que dividem o conteúdo em pontos semanticamente inadequados.
Os limites de tokens continuam a se expandir à medida que os modelos se tornam mais sofisticados e eficientes. Técnicas emergentes como mecanismos de atenção esparsa e transformers eficientes prometem reduzir o custo computacional do processamento de grandes janelas de contexto. Modelos multimodais que processam texto, imagens, áudio e vídeo simultaneamente introduzem novos desafios e oportunidades de tokenização. Tokens de raciocínio—tokens especiais usados por modelos para “pensar” sobre problemas complexos—representam uma nova categoria de consumo de tokens que permite uma solução de problemas mais sofisticada, mas exige gerenciamento cuidadoso.
A trajetória é clara: à medida que as janelas de contexto se expandem e o processamento de tokens se torna mais eficiente, o gargalo se desloca da capacidade bruta para a seleção inteligente de conteúdo. O futuro pertence a sistemas capazes de identificar e recuperar com eficácia as informações mais relevantes de grandes bases de conhecimento, em vez de sistemas que apenas processam volumes maiores de dados. Isso torna técnicas como RAG e busca semântica cada vez mais importantes para construir aplicações de IA escaláveis e econômicas.
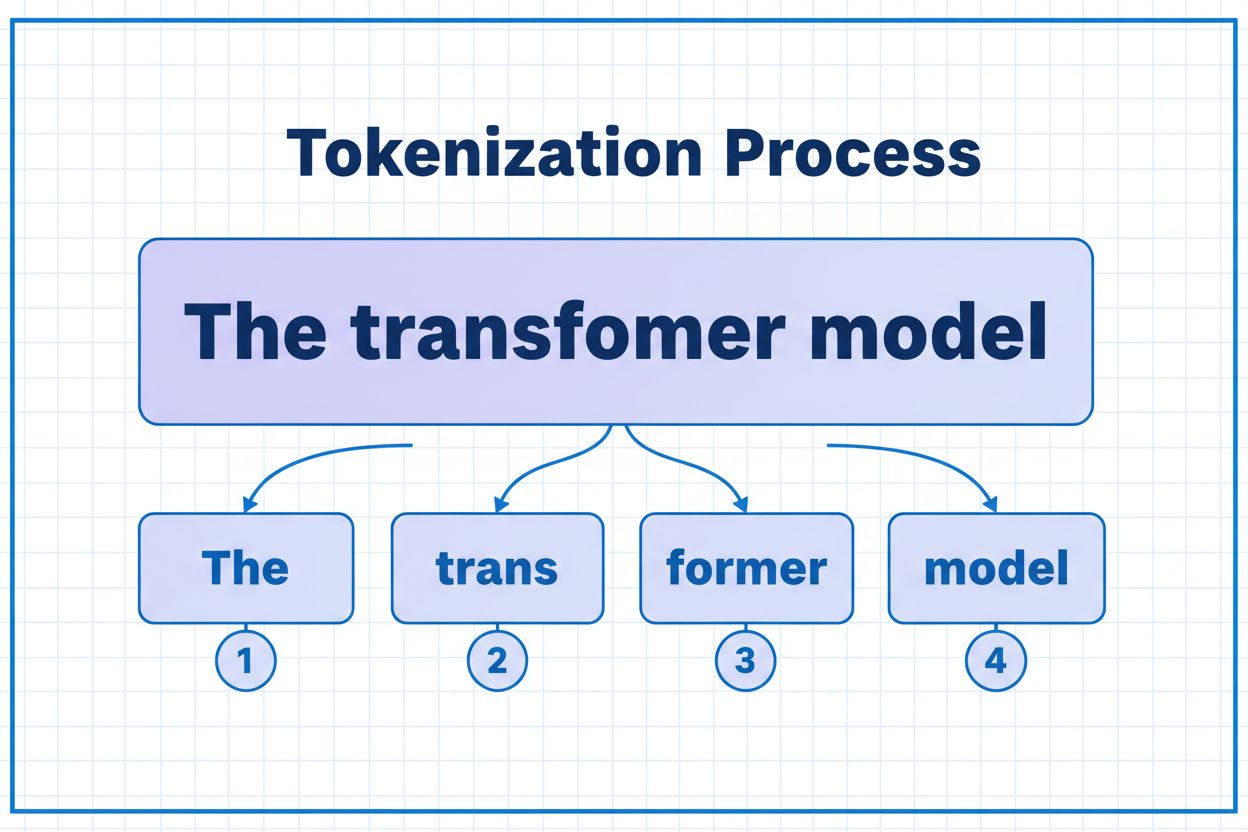
Um token é a menor unidade de dados que um modelo de IA processa. Tokens podem ser caracteres individuais, subpalavras ou palavras completas, dependendo do algoritmo de tokenização. Por exemplo, a palavra 'transformer' pode ser dividida em 'trans' e 'former' como dois tokens separados. Cada token recebe um identificador numérico único que o modelo usa internamente para cálculo.
Os limites de tokens definem a quantidade máxima de informação que seu modelo de IA pode processar em uma única solicitação. Quando você excede esse limite, sua aplicação falha completamente. Mesmo permanecendo dentro dos limites, abordagens ingênuas como truncamento podem degradar a precisão ao remover contextos críticos. Os limites de tokens também afetam diretamente os custos, pois normalmente você paga por cada token consumido.
Tokens de entrada são os tokens em seu prompt e dados que você envia ao modelo, enquanto tokens de saída são os tokens que o modelo gera em sua resposta. Eles compartilham um orçamento combinado definido pela janela de contexto do modelo. Se sua entrada usa 90% de uma janela de 128K tokens, você tem apenas 10% restante para a saída do modelo.
O truncamento é simples de implementar, mas arriscado. Ele remove informações sem que o modelo saiba o que foi perdido, levando a análises incompletas e possíveis alucinações. Embora útil como último recurso, abordagens melhores como RAG, chunking ou sumarização preservam a fidelidade da informação enquanto gerenciam o consumo de tokens de forma mais eficaz.
A Geração Aumentada por Recuperação (RAG) recupera apenas as informações mais relevantes no momento da consulta, em vez de incluir documentos inteiros. Seus documentos são convertidos em embeddings e armazenados em um banco de dados vetorial. Quando um usuário faz uma consulta, o sistema recupera apenas os trechos relevantes e os injeta no prompt, reduzindo drasticamente o consumo de tokens enquanto melhora a precisão.
A maioria das plataformas de IA oferece utilitários de contagem de tokens e painéis em tempo real para acompanhar padrões de uso. Monitore quais consultas ou funcionalidades consomem mais tokens e implemente estratégias de otimização como RAG para aplicações com muitos documentos, sumarização para conversas longas ou encaminhamento para modelos maiores em tarefas complexas. Meça a performance e os custos reais para validar suas escolhas.
Os serviços de IA normalmente cobram por token consumido. Os custos escalam linearmente com o uso de tokens, fazendo com que a otimização dos tokens impacte diretamente suas despesas. Uma redução de 20% no consumo de tokens resulta em uma redução de 20% no custo. Entender a eficiência dos tokens ajuda você a escolher a estratégia de otimização certa para suas restrições orçamentárias.
Os limites de tokens continuam a se expandir à medida que os modelos se tornam mais sofisticados. Técnicas emergentes como mecanismos de atenção esparsa prometem reduzir os custos computacionais do processamento de grandes contextos. O futuro foca na seleção e recuperação inteligente de conteúdo ao invés da capacidade bruta de processamento, tornando técnicas como RAG cada vez mais importantes para aplicações de IA escaláveis.
Entenda a eficiência dos tokens e acompanhe como modelos de IA citam sua marca com a plataforma abrangente de monitoramento de citações de IA da AmICited.
Saiba o que são tokens em modelos de linguagem. Tokens são unidades fundamentais de processamento de texto em sistemas de IA, representando palavras, subpalavra...

Saiba como modelos de IA processam texto por meio de tokenização, embeddings, blocos transformadores e redes neurais. Entenda o pipeline completo do input ao ou...

Guia fundamentado em pesquisa sobre o comprimento ideal de trechos para citações de IA. Saiba por que 75-150 palavras é o ideal, como os tokens afetam a recuper...