Algoritmo de Seleção de Citação
Aprenda como sistemas de IA selecionam quais fontes citar versus parafrasear. Entenda algoritmos de seleção de citação, padrões de viés e estratégias para melho...
7 min de leitura

Descubra como modelos de IA como ChatGPT, Perplexity e Gemini selecionam fontes para citar. Entenda os mecanismos de citação, fatores de ranqueamento e estratégias de otimização para visibilidade em IA.
Os modelos de IA decidem o que citar por meio da Geração Aumentada por Recuperação (RAG), avaliando fontes com base na autoridade do domínio, atualidade do conteúdo, relevância semântica, estrutura da informação e densidade factual. O processo de decisão ocorre em milissegundos usando correspondência de similaridade vetorial e algoritmos de pontuação multifatorial que avaliam credibilidade, sinais de expertise e qualidade do conteúdo.
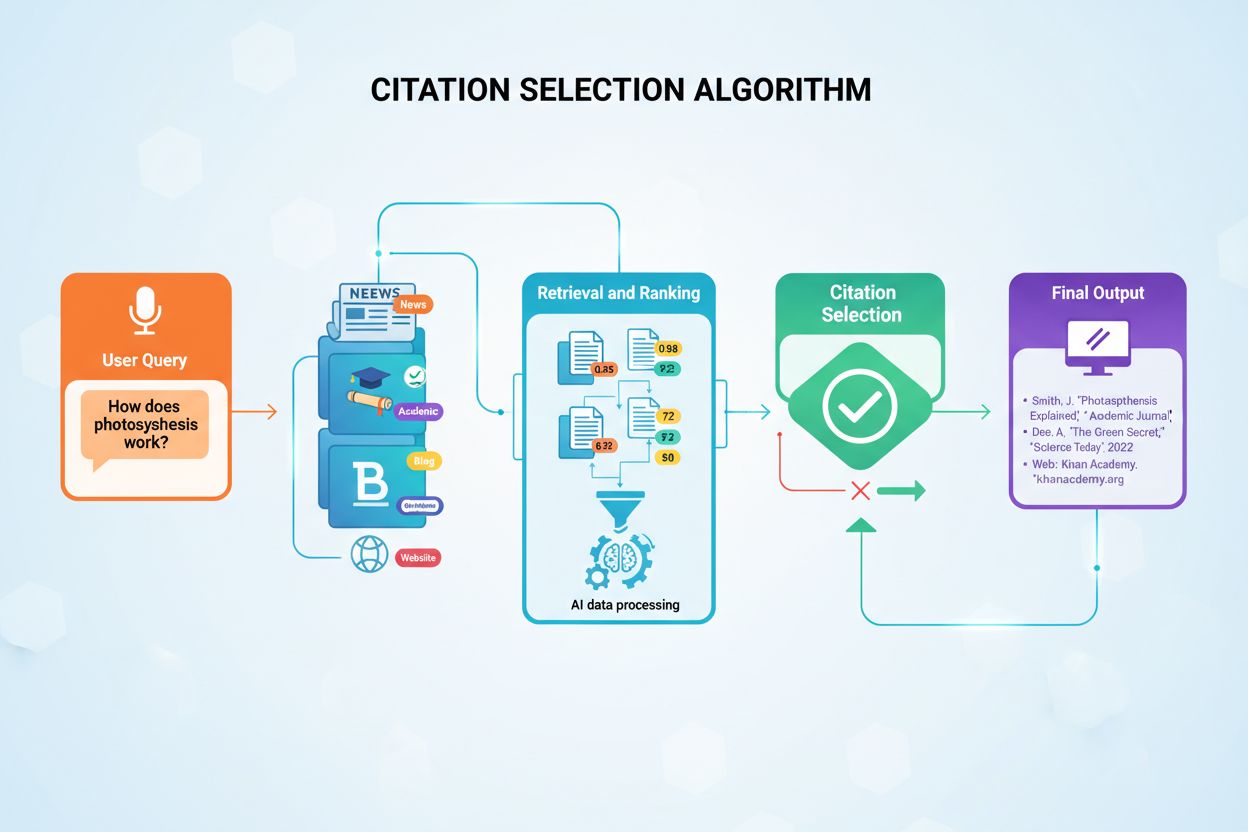
Modelos de IA não selecionam aleatoriamente as fontes que citam em suas respostas. Em vez disso, eles utilizam algoritmos sofisticados que avaliam centenas de sinais em milissegundos para determinar quais fontes merecem atribuição. O processo, conhecido como Geração Aumentada por Recuperação (RAG), difere fundamentalmente de como motores de busca tradicionais ranqueiam conteúdos. Enquanto o algoritmo do Google foca em ranquear páginas para visibilidade nos resultados de busca, algoritmos de citação de IA priorizam fontes que fornecem as informações mais autoritativas, relevantes e confiáveis para responder a consultas específicas dos usuários. Essa distinção significa que alcançar visibilidade em respostas geradas por IA exige compreender um conjunto totalmente diferente de princípios de otimização em relação ao SEO tradicional.
A decisão de citação ocorre por meio de um processo em múltiplas etapas que se inicia no momento em que o usuário envia uma consulta. O sistema de IA converte a pergunta do usuário em vetores numéricos chamados embeddings, que representam o significado semântico da consulta. Esses embeddings então buscam em bancos de dados de conteúdo indexados contendo milhões de documentos, procurando por trechos de conteúdo semanticamente similares. O sistema não simplesmente recupera o conteúdo mais similar; em vez disso, aplica múltiplos critérios de avaliação simultaneamente para ranquear as potenciais fontes conforme sua adequação à citação. Esse processo de avaliação paralela garante que as fontes mais confiáveis, relevantes e bem estruturadas subam ao topo do ranking.
A Geração Aumentada por Recuperação (RAG) representa a arquitetura fundamental que permite aos modelos de IA citar fontes externas. Diferentemente de modelos de linguagem de grande porte tradicionais, que dependem exclusivamente de dados de treinamento codificados durante seu desenvolvimento, sistemas RAG pesquisam ativamente documentos indexados no momento da consulta, recuperando informações relevantes antes de gerar respostas. Essa diferença arquitetural explica por que certas plataformas como Perplexity e Google AI Overviews fornecem citações de forma consistente, enquanto outras como o ChatGPT base frequentemente geram respostas sem atribuição explícita de fontes. Compreender o RAG ajuda a esclarecer por que alguns conteúdos são citados enquanto outros igualmente qualificados permanecem invisíveis para sistemas de IA.
O processo RAG opera em quatro fases distintas que determinam quais fontes recebem citações. Primeiro, os documentos são divididos em trechos gerenciáveis de 200-500 palavras, garantindo que os sistemas de IA possam extrair informações específicas e relevantes sem processar artigos inteiros. Segundo, esses trechos são convertidos em vetores numéricos chamados embeddings usando modelos de aprendizado de máquina treinados para entender significado semântico. Terceiro, quando o usuário faz uma pergunta, o sistema busca por vetores semanticamente similares usando correspondência de similaridade vetorial, identificando conteúdos que abordam os conceitos centrais da consulta. Quarto, a IA gera uma resposta usando o conteúdo recuperado como contexto, e as fontes que mais contribuíram para a resposta recebem citações. Essa arquitetura explica por que estrutura do conteúdo, clareza e alinhamento semântico com consultas comuns impactam diretamente a probabilidade de citação.
Algoritmos de citação em IA avaliam fontes em cinco dimensões centrais que, em conjunto, determinam o valor da citação. Esses fatores trabalham em conjunto para criar uma avaliação abrangente da qualidade da fonte, com cada dimensão contribuindo para a pontuação final de citação.
| Fator de Citação | Nível de Impacto | Indicadores-Chave |
|---|---|---|
| Autoridade do Domínio | Muito Alta (25-30%) | Perfil de backlinks, idade do domínio, presença em knowledge graph, menções na Wikipedia |
| Atualidade do Conteúdo | Alta (20-25%) | Data de publicação, frequência de atualização, atualidade de estatísticas e dados |
| Relevância Semântica | Alta (20-25%) | Alinhamento entre consulta e conteúdo, especificidade do tópico, presença de resposta direta |
| Estrutura da Informação | Média-Alta (15-20%) | Hierarquia de títulos, formato escaneável, implementação de schema markup |
| Densidade Factual | Média (10-15%) | Pontos de dados específicos, estatísticas, citações de especialistas, cadeias de citação |
Autoridade representa o fator mais fortemente ponderado nas decisões de citação em IA. Pesquisas que analisam 150.000 citações de IA revelam que Reddit e Wikipedia respondem por 40,1% e 26,3% de todas as citações de LLM, respectivamente, demonstrando como a autoridade estabelecida influencia dramaticamente a seleção. Sistemas de IA avaliam autoridade por meio de múltiplos sinais de confiança, incluindo idade do domínio, qualidade do perfil de backlinks, presença em knowledge graphs e validação por terceiros. Sites com pontuação de autoridade do domínio acima de 60 apresentam taxas de citação consistentemente mais altas no ChatGPT, Perplexity e Gemini. No entanto, autoridade não diz respeito apenas a métricas de nível de domínio; também abrange credibilidade do autor, com conteúdos assinados por especialistas nomeados e com credenciais verificáveis recebendo tratamento preferencial sobre contribuições anônimas.
Atualidade funciona como um filtro temporal crítico que determina se o conteúdo permanece elegível para citação. Conteúdos publicados ou atualizados em até 48-72 horas recebem ranqueamento preferencial, enquanto a decadência do conteúdo começa imediatamente, com a visibilidade caindo perceptivelmente em 2-3 dias sem atualizações. Esse viés de atualidade reflete o compromisso das plataformas de IA em fornecer informações atuais, especialmente para temas em rápida evolução onde informações desatualizadas podem confundir usuários. No entanto, conteúdo perene com atualizações recentes pode superar conteúdos mais novos, mas superficiais, sugerindo que a combinação de qualidade fundamental e atualização temporal importa mais do que qualquer fator isolado. Organizações que mantêm ciclos de atualização trimestrais ou anuais sustentam taxas de citação mais altas do que aquelas que publicam uma vez e abandonam o conteúdo.
Relevância mede o alinhamento semântico entre as consultas dos usuários e o conteúdo do documento. Fontes que abordam diretamente a questão central, com pouca informação tangencial, pontuam mais alto do que recursos abrangentes, porém dispersos. Sistemas de IA avaliam relevância por similaridade de embeddings, comparando a representação numérica da consulta com a dos trechos de documentos. Isso significa que conteúdos escritos em linguagem conversacional, compatível com consultas naturais, performam melhor do que textos otimizados por palavras-chave para motores de busca tradicionais. Conteúdos em formato de FAQ e pares de pergunta-resposta alinham-se naturalmente com o modo como sistemas de IA processam consultas, tornando esse formato particularmente digno de citação.
Estrutura abrange tanto a arquitetura da informação quanto a implementação técnica. Organização hierárquica clara com títulos descritivos, fluxo lógico e formato escaneável ajuda sistemas de IA a entender limites do conteúdo e extrair informações relevantes. Marcação de dados estruturados utilizando schemas como FAQ, Article e Organization pode aumentar a probabilidade de citação em até 10%. Conteúdos organizados como resumos concisos, listas com marcadores, tabelas comparativas e pares de pergunta-resposta recebem tratamento preferencial em relação a parágrafos densos com informações ocultas. Essa preferência estrutural reflete como sistemas de IA são treinados para reconhecer informações bem organizadas que fornecem respostas completas e contextuais.
Densidade Factual refere-se à concentração de informações específicas e verificáveis dentro do conteúdo. Fontes que contêm pontos de dados, estatísticas, datas e exemplos concretos superam conteúdos puramente conceituais. Mais importante, fontes que citam referências autoritativas criam cascatas de confiança, onde sistemas de IA herdam confiança das fontes citadas. Conteúdo que inclui evidências e links para fontes primárias apresenta taxas de citação mais altas do que alegações sem suporte. Esse requisito de densidade factual significa que toda afirmação significativa deve incluir atribuição a fontes confiáveis com datas de publicação e credenciais de especialistas.
Diferentes plataformas de IA implementam estratégias de citação distintas, refletindo suas diferenças arquiteturais e filosofias de design. Compreender essas preferências específicas de cada plataforma ajuda criadores de conteúdo a otimizar para múltiplos sistemas de IA simultaneamente.
Padrões de Citação do ChatGPT revelam forte preferência por fontes enciclopédicas e autoritativas. A Wikipedia aparece em aproximadamente 35% das citações do ChatGPT, demonstrando a dependência do modelo em informações estabelecidas e verificadas pela comunidade. A plataforma evita conteúdos de fóruns gerados por usuários, a menos que a consulta solicite especificamente opiniões da comunidade, preferindo fontes com cadeias claras de atribuição e fatos verificáveis em vez de conteúdo opinativo. Essa abordagem conservadora reflete o treinamento do ChatGPT em fontes de alta qualidade e sua filosofia de priorizar precisão em vez de abrangência. Organizações que buscam citações do ChatGPT se beneficiam ao estabelecer presença em knowledge graphs, criar entradas na Wikipedia e produzir conteúdos com profundidade e neutralidade enciclopédica.
Sistemas de IA do Google, incluindo Gemini e AI Overviews, incorporam tipos de fontes mais diversos, refletindo a filosofia de indexação mais ampla do Google. Publicações do Reddit respondem por aproximadamente 5% das citações do AI Overviews, enquanto a plataforma favorece conteúdo que aparece nos principais resultados orgânicos, criando sinergia entre SEO tradicional e taxas de citação em IA. Os sistemas de IA do Google demonstram maior disposição em citar fontes novas e conteúdos gerados por usuários em comparação ao ChatGPT, desde que essas fontes demonstrem relevância e autoridade. Essa preferência de plataforma significa que forte desempenho em SEO tradicional se correlaciona com sucesso de citação em IA nas plataformas do Google, embora a correlação não seja perfeita.
Preferências do Perplexity AI enfatizam transparência e atribuição direta de fontes. A plataforma normalmente fornece de 3 a 5 fontes por resposta com links diretos, preferindo sites de avaliação do setor, publicações de especialistas e conteúdos orientados por dados. A autoridade do domínio pesa bastante, com publicações estabelecidas recebendo tratamento preferencial, enquanto conteúdo comunitário aparece em cerca de 1% das citações, principalmente para recomendações de produtos. A filosofia de design do Perplexity prioriza ajudar usuários a verificar informações fornecendo atribuição clara de fontes, tornando-o particularmente valioso para rastrear a visibilidade de marcas. Organizações otimizando para o Perplexity se beneficiam ao criar conteúdos ricos em dados, recursos específicos do setor e artigos assinados por especialistas que demonstrem autoridade clara.
Autoridade do domínio funciona como um proxy de confiabilidade em algoritmos de IA, sinalizando que a fonte demonstrou credibilidade ao longo do tempo. Sistemas avaliam autoridade por meio de múltiplos sinais de confiança que representam cerca de 5% da probabilidade total de citação, embora essa porcentagem aumente significativamente para tópicos YMYL (Your Money, Your Life) que afetam saúde, finanças ou segurança. Indicadores-chave de autoridade incluem idade do domínio, certificados SSL, políticas de privacidade e selos de conformidade como SOC 2 ou certificação GDPR. Esses sinais técnicos se potencializam quando combinados com métricas de qualidade de conteúdo, criando um efeito multiplicador onde sites tecnicamente sólidos, com conteúdo excelente, superam sites tecnicamente fracos, independentemente da qualidade do conteúdo.
Perfis de backlinks influenciam significativamente a percepção da fonte em algoritmos de IA. Modelos de IA avaliam a autoridade dos domínios de origem, a relevância do contexto do link e a diversidade do portfólio de backlinks. Pesquisas mostram que dez backlinks de grandes publicações superam cem backlinks de sites de baixa autoridade, demonstrando que a qualidade do link importa muito mais do que a quantidade. Atribuição de especialistas aumenta substancialmente a probabilidade de citação, com conteúdos assinados por autores nomeados e com credenciais verificáveis performando significativamente melhor do que conteúdos anônimos. Schema markup de autor e bios detalhadas ajudam sistemas de IA a validar expertise, enquanto validação por terceiros por meio de menções em publicações do setor reforça a credibilidade. Organizações que buscam autoridade devem focar em conquistar backlinks de fontes de alta autoridade, estabelecer credenciais de autores e garantir menções em publicações do setor.
Presença na Wikipedia e em knowledge graph melhora dramaticamente as taxas de citação independentemente de outros fatores. Fontes referenciadas na Wikipedia desfrutam de vantagens significativas porque knowledge graphs servem como fontes autoritativas que modelos de IA consultam repetidamente em diversas consultas. Informações do Google Knowledge Panel alimentam diretamente a forma como modelos de IA compreendem relações de entidades e autoridade. Organizações sem presença na Wikipedia têm dificuldade em obter citações consistentes mesmo com conteúdo de alta qualidade, sugerindo que o desenvolvimento de knowledge graph deve ser prioridade para estratégias sérias de visibilidade em IA. Isso cria uma camada fundamental de confiança que modelos de linguagem consultam durante a recuperação, fazendo com que entradas em knowledge graph sirvam como fontes autoritativas a serem referenciadas repetidamente.
Alinhamento com Consultas Conversacionais representa uma mudança fundamental em relação à otimização de SEO tradicional. Conteúdo estruturado em pares de pergunta-resposta tem desempenho superior nos algoritmos de recuperação em relação a conteúdos otimizados por palavras-chave. Páginas de FAQ e conteúdos que espelham consultas em linguagem natural recebem tratamento preferencial porque sistemas de IA são treinados em dados conversacionais e entendem melhor padrões de linguagem natural do que cadeias de palavras-chave. Isso significa que conteúdos escritos como se estivessem respondendo à pergunta de um amigo superam conteúdos escritos para algoritmos de motores de busca. Organizações devem auditar seus conteúdos para tom conversacional, respostas diretas a perguntas comuns e alinhamento com a linguagem natural conforme usuários realmente perguntam.
Qualidade das Citações no Conteúdo cria cascatas de confiança que se estendem além das fontes individuais. Sistemas de IA avaliam se as afirmações incluem dados de apoio e evidências. Conteúdos que citam referências autoritativas herdam confiança dessas fontes citadas, criando um efeito multiplicador de credibilidade. Fontes que incluem evidências e links para fontes primárias apresentam taxas de citação mais altas do que afirmações não fundamentadas. Isso significa que toda afirmação significativa deve incluir atribuição a fontes confiáveis com datas de publicação e credenciais de especialistas. Organizações que desejam criar conteúdos dignos de citação devem pesquisar e citar no mínimo de 5 a 8 fontes confiáveis, incluir de 2 a 3 citações de especialistas com credenciais completas e adicionar de 3 a 5 estatísticas recentes com datas de publicação.
Consistência Entre Plataformas influencia como sistemas de IA avaliam a credibilidade das fontes. Quando a IA encontra informações consistentes em várias fontes, a confiança aumenta para citar qualquer fonte individual desse grupo. Fontes que contradizem o consenso geral recebem prioridade menor, a menos que apresentem evidências contrárias convincentes. Esse viés de consistência significa que estabelecer narrativas coerentes em canais próprios, conquistados e compartilhados reforça a citabilidade de fontes individuais. Organizações que desenvolvem estratégias de reputação em IA devem manter mensagens consistentes em todas as propriedades digitais, garantindo que as informações apresentadas em sites corporativos, redes sociais, publicações do setor e plataformas de terceiros sejam alinhadas e reforcem as mensagens centrais.
Estratégia de Frequência de Atualização importa mais na era da IA do que no SEO tradicional. A frequência de publicação impacta diretamente as taxas de citação, com plataformas de IA mostrando forte preferência por conteúdos recentemente atualizados. Organizações devem atualizar conteúdos existentes a cada 48-72 horas para manter sinais de atualidade, embora isso não exija reescritas completas. Adicionar novos dados, atualizar estatísticas ou expandir seções com desenvolvimentos recentes mantém a elegibilidade para citação. Sistemas de gerenciamento de conteúdo que acompanham frequência de atualização e frescor do conteúdo ajudam a manter taxas de citação competitivas à medida que plataformas de IA valorizam cada vez mais sinais de atualidade. Essa abordagem contínua de atualização difere fundamentalmente do SEO tradicional, onde um conteúdo poderia ranquear indefinidamente sem modificação.
Posicionamento Estratégico em Sites Agregadores cria múltiplos caminhos de descoberta para sistemas de IA. Ser destacado em compilações do setor, listas de especialistas ou sites de avaliação gera oportunidades além do que fontes originais alcançam sozinhas. Uma única menção em uma publicação frequentemente citada cria múltiplos caminhos de descoberta e gera oportunidades para sistemas de IA encontrarem seu conteúdo por rotas diversas. Relações com a mídia e parcerias de conteúdo ganham valor para visibilidade em IA, assim como o posicionamento estratégico em bancos de dados e diretórios específicos do setor. Organizações devem buscar destaque em compilações do setor, listas de especialistas e sites de avaliação como parte de sua estratégia de visibilidade em IA.
Implementação de Dados Estruturados melhora a probabilidade de citação ao tornar o conteúdo legível por máquinas. Schema markup em formatos compatíveis com IA ajuda plataformas de IA a entender e extrair fatos específicos sem precisar analisar textos não estruturados. O schema FAQ, Article com informações de autor e Organization criam sinais legíveis por máquinas que algoritmos de recuperação priorizam. Dados estruturados em JSON-LD permitem que a IA extraia fatos específicos de forma eficiente, melhorando tanto a probabilidade de citação quanto a precisão das informações citadas. Organizações que implementam schema markup abrangente observam melhorias mensuráveis nas taxas de citação em múltiplas plataformas de IA.
Desenvolvimento na Wikipedia e Knowledge Graph gera retornos cumulativos apesar de exigir esforço contínuo. Construir presença na Wikipedia exige contribuições neutras e bem referenciadas que atendam aos padrões editoriais da enciclopédia. Simultaneamente, otimizar perfis na Wikidata, Google Knowledge Panel e bancos de dados específicos do setor cria a camada fundamental de confiança que sistemas de IA consultam repetidamente. Essas entradas em knowledge graph servem como fontes autoritativas que modelos consultam em diversas consultas, tornando o desenvolvimento de knowledge graph uma prioridade estratégica para organizações que buscam visibilidade sustentável em IA.
Organizações devem acompanhar a frequência de citações testando manualmente consultas relevantes no ChatGPT, Google AI Overviews, Perplexity e outras plataformas. Testes regulares de prompts revelam quais conteúdos conseguem citações e quais lacunas existem na representação em IA. Essa metodologia de teste fornece visibilidade direta sobre o desempenho das citações e ajuda a identificar oportunidades de otimização. Algoritmos de citação em IA mudam continuamente à medida que os dados de treinamento expandem e estratégias de recuperação evoluem, exigindo que as estratégias de conteúdo se adaptem com base no desempenho. Quando um conteúdo para de receber citações, apesar de sucesso histórico, atualize com informações recentes ou reestruture para melhor alinhamento semântico.
Múltiplas fontes podem receber citações para uma única consulta, criando oportunidades de co-citação em vez de competição de soma zero. Organizações se beneficiam ao criar conteúdos abrangentes que complementam, em vez de duplicar, fontes já altamente citadas. Análises do cenário competitivo revelam quais marcas dominam a visibilidade em IA em categorias específicas, ajudando organizações a identificar lacunas e oportunidades. O acompanhamento do desempenho de citações ao longo do tempo revela tendências e quais URLs impulsionam o sucesso, permitindo replicar estratégias vencedoras e ampliar abordagens bem-sucedidas.
Acompanhe onde seu conteúdo aparece em respostas geradas por IA no ChatGPT, Perplexity, Google AI Overviews e outras plataformas de IA. Obtenha insights em tempo real sobre sua visibilidade em IA e desempenho de citações.
Aprenda como sistemas de IA selecionam quais fontes citar versus parafrasear. Entenda algoritmos de seleção de citação, padrões de viés e estratégias para melho...

Saiba como o conteúdo gerado por IA se comporta em mecanismos de busca como ChatGPT, Perplexity e Google AI Overviews. Descubra fatores de ranqueamento, estraté...

Saiba o que são citações de IA, como funcionam no ChatGPT, Perplexity e Google IA, e por que elas são importantes para a visibilidade da sua marca em mecanismos...