
Como Obtenho Produtos Recomendados por IA?
Saiba como funcionam as recomendações de produtos por IA, os algoritmos por trás delas e como otimizar sua visibilidade em sistemas de recomendação alimentados ...
9 min de leitura
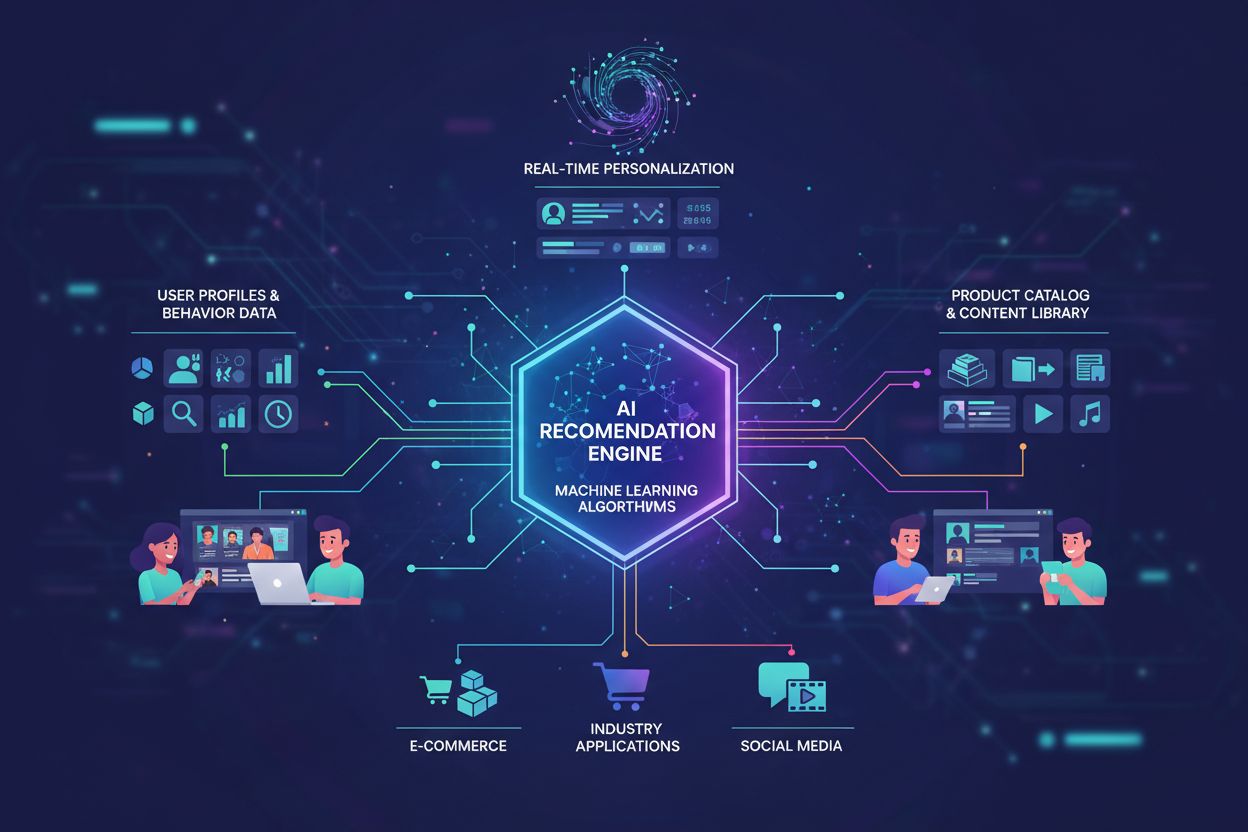
Sistemas de aprendizado de máquina que analisam o comportamento e as preferências dos usuários para fornecer sugestões personalizadas de produtos e conteúdos. Esses sistemas utilizam algoritmos como filtragem colaborativa e filtragem baseada em conteúdo para prever o que os usuários podem ter interesse, permitindo que empresas aumentem o engajamento, as vendas e a satisfação dos clientes por meio de recomendações sob medida.
Sistemas de aprendizado de máquina que analisam o comportamento e as preferências dos usuários para fornecer sugestões personalizadas de produtos e conteúdos. Esses sistemas utilizam algoritmos como filtragem colaborativa e filtragem baseada em conteúdo para prever o que os usuários podem ter interesse, permitindo que empresas aumentem o engajamento, as vendas e a satisfação dos clientes por meio de recomendações sob medida.
As recomendações impulsionadas por IA representam uma tecnologia sofisticada que utiliza algoritmos de aprendizado de máquina para analisar o comportamento e as preferências dos usuários, fornecendo sugestões personalizadas adaptadas às necessidades e interesses individuais. Um mecanismo de recomendação é o componente central desse sistema, funcionando como um intermediário inteligente entre vastos catálogos de produtos e usuários individuais, possibilitando níveis inéditos de personalização em escala. O mercado global de mecanismos de recomendação experimentou um crescimento explosivo, avaliado em aproximadamente US$ 2,8 bilhões em 2023 e com projeção de atingir US$ 8,5 bilhões até 2030, refletindo a importância crítica dessa tecnologia na economia digital. Essas recomendações impulsionadas por IA tornaram-se indispensáveis em diversos setores, com aplicações de destaque em plataformas de e-commerce como Amazon e eBay, serviços de streaming como Netflix e Spotify, redes sociais e plataformas de conteúdo. O princípio fundamental por trás desses sistemas é que algoritmos de aprendizado de máquina conseguem identificar padrões no comportamento dos usuários que os humanos não percebem facilmente, permitindo que empresas antecipem necessidades de clientes antes mesmo que eles próprios as reconheçam. Ao aproveitar grandes conjuntos de dados e poder computacional, os sistemas de recomendação transformaram a forma como consumidores descobrem produtos, conteúdos e serviços, remodelando fundamentalmente as estratégias de engajamento de clientes em diferentes indústrias.

Os sistemas de recomendação impulsionados por IA operam por meio de um sofisticado processo de cinco fases que transforma dados brutos dos usuários em sugestões personalizadas acionáveis. A primeira fase envolve a coleta abrangente de dados, em que os sistemas reúnem informações de múltiplos pontos de contato, incluindo interações do usuário, histórico de navegação, registros de compras e mecanismos de feedback explícito. Durante a fase de análise, o sistema processa esses dados coletados para identificar padrões e relações significativas, utilizando algoritmos de aprendizado de máquina como filtragem colaborativa, filtragem baseada em conteúdo e redes neurais para extrair insights de conjuntos de dados complexos. A fase de reconhecimento de padrões representa o núcleo computacional do sistema, onde algoritmos identificam semelhanças entre usuários, itens, ou ambos, criando representações matemáticas de preferências e características dos itens. A fase de predição utiliza esses padrões identificados para prever com quais itens o usuário tem mais probabilidade de interagir, atribuindo pontuações de confiança às recomendações em potencial. Por fim, a fase de entrega apresenta essas previsões aos usuários por meio de interfaces personalizadas, garantindo que as recomendações apareçam nos momentos ideais da jornada do usuário. A capacidade de processamento em tempo real tornou-se cada vez mais crítica, com sistemas modernos atualizando recomendações instantaneamente à medida que novos dados de comportamento chegam, permitindo personalização dinâmica que se adapta às preferências em mudança. Sistemas avançados de recomendação empregam métodos de ensemble que combinam múltiplos algoritmos simultaneamente, com cada algoritmo contribuindo com suas previsões para gerar recomendações finais mais robustas e precisas do que qualquer abordagem isolada.
Sistemas de recomendação dependem de duas categorias distintas de dados de usuários, cada uma fornecendo insights únicos sobre preferências e padrões de comportamento:
Dados Explícitos:
Dados Implícitos:
Dados explícitos fornecem sinais diretos e inequívocos das preferências dos usuários, mas sofrem de escassez, já que a maioria avalia apenas uma pequena fração dos itens disponíveis. Já os dados implícitos são abundantes e continuamente gerados por interações normais, embora exijam interpretação sofisticada, pois ações como visualizar um produto não necessariamente indicam preferência. Os sistemas de recomendação mais eficazes integram ambos os tipos de dados, usando feedback explícito para validar e calibrar sinais implícitos, criando perfis de usuário abrangentes que capturam tanto preferências declaradas quanto reveladas.
A filtragem colaborativa representa uma das abordagens fundamentais em sistemas de recomendação, operando sob o princípio de que usuários com preferências semelhantes no passado provavelmente gostarão de itens semelhantes no futuro. Essa metodologia analisa padrões em toda a população de usuários para identificar similaridades, diferenciando-se de abordagens que examinam características individuais dos itens. A filtragem colaborativa baseada em usuários identifica usuários com históricos de preferência semelhantes ao usuário alvo e recomenda itens que esses usuários semelhantes gostaram, mas que o usuário alvo ainda não conheceu, aproveitando, assim, a sabedoria de usuários comparáveis. A filtragem colaborativa baseada em itens, por sua vez, foca nas similaridades entre itens, recomendando produtos semelhantes àqueles que o usuário avaliou positivamente, com base em como outros usuários avaliaram esses itens em relação uns aos outros. Ambas as abordagens utilizam métricas sofisticadas de similaridade, como similaridade cosseno, correlação de Pearson ou distância euclidiana para quantificar o quanto usuários ou itens se assemelham no espaço de preferências. A filtragem colaborativa oferece vantagens significativas, incluindo a capacidade de recomendar itens sem metadados de conteúdo e de descobrir recomendações inesperadas que os usuários talvez não antecipassem. No entanto, a abordagem enfrenta limitações notáveis, especialmente o “problema do início a frio”, em que novos usuários ou itens carecem de dados históricos suficientes para cálculos precisos de similaridade, além de questões de escassez de dados em domínios com milhões de itens onde a maioria das interações usuário-item permanece não observada.
A filtragem baseada em conteúdo recomenda analisando as características intrínsecas e atributos dos próprios itens, indicando produtos semelhantes àqueles que o usuário já preferiu com base em seus atributos mensuráveis. Em vez de depender de padrões de comportamento coletivo, sistemas baseados em conteúdo constroem perfis detalhados dos itens, englobando características relevantes como gênero, diretor e elenco para filmes; autor, tema e data de publicação para livros; ou categoria, marca e especificações para itens de e-commerce. O sistema calcula similaridade entre itens comparando seus vetores de características com técnicas matemáticas como similaridade cosseno ou distância euclidiana, criando uma medida quantitativa de proximidade no espaço de atributos. Quando um usuário avalia ou interage com um item, o sistema identifica outros com perfis de características semelhantes e os recomenda, personalizando sugestões com base em preferências demonstradas por atributos específicos. A filtragem baseada em conteúdo é especialmente eficaz em cenários onde o metadado dos itens é rico e bem estruturado, além de solucionar naturalmente o problema do início a frio para novos itens, já que as recomendações dependem das características dos itens e não de interações históricas. Contudo, essa abordagem apresenta limitações em termos de descoberta e surpresa, pois tende a recomendar itens muito similares às preferências passadas, podendo criar bolhas de filtro que restringem os usuários a categorias estreitas. Comparada à filtragem colaborativa, sistemas baseados em conteúdo exigem engenharia explícita de atributos e têm dificuldades com itens sem fronteiras categóricas claras, mas oferecem transparência superior, pois as recomendações podem ser explicadas por meio de atributos específicos do item.
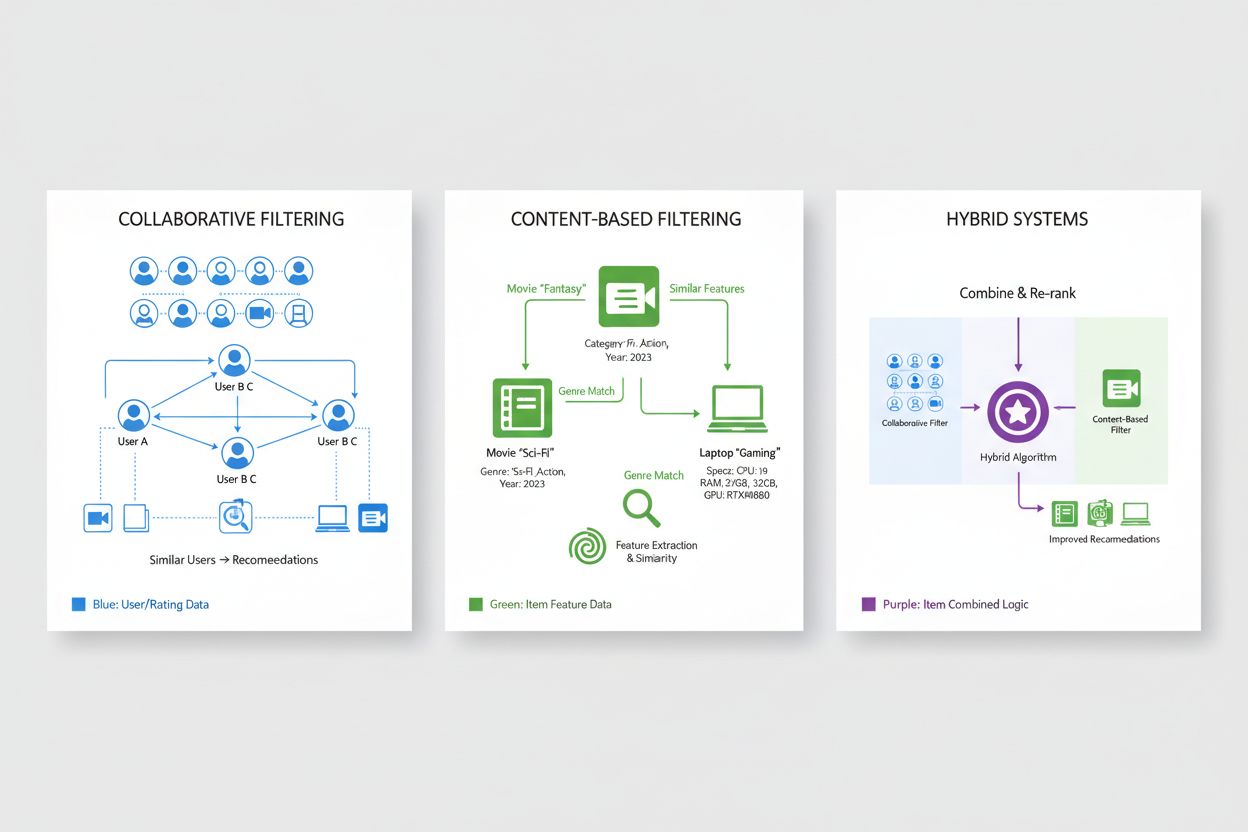
Sistemas de recomendação híbridos combinam estrategicamente abordagens de filtragem colaborativa e baseada em conteúdo, aproveitando as forças complementares de cada metodologia para superar limitações individuais e oferecer recomendações com precisão superior. Esses sistemas utilizam várias estratégias de integração, incluindo combinações ponderadas, onde previsões de múltiplos algoritmos são mescladas usando pesos pré-definidos ou aprendidos, mecanismos de alternância que escolhem o algoritmo mais adequado conforme fatores contextuais, ou abordagens em cascata nas quais a saída de um algoritmo alimenta o outro. Ao integrar a capacidade da filtragem colaborativa de identificar recomendações inesperadas e captar padrões complexos de preferência com a aptidão da filtragem baseada em conteúdo de lidar com novos itens e fornecer recomendações explicáveis, sistemas híbridos alcançam desempenho mais robusto em cenários diversos. Grandes empresas de tecnologia adotaram abordagens híbridas como prática padrão do setor; a Netflix combina filtragem colaborativa com métodos baseados em conteúdo e informações contextuais para entregar recomendações que equilibram popularidade, personalização e novidade. O mecanismo de recomendação do Spotify também emprega técnicas híbridas, integrando filtragem colaborativa baseada em padrões de escuta com análise de características de áudio e metadados, além de processamento de linguagem natural em playlists e resenhas geradas por usuários. As vantagens dos sistemas híbridos vão além da precisão, abrangendo maior cobertura do catálogo, melhor manejo de cenários com dados esparsos e maior resiliência diante de desafios comuns em recomendação. Esses sistemas representam o estado da arte em tecnologia de personalização, com a maioria das plataformas de recomendação em escala corporativa empregando arquiteturas híbridas que evoluem continuamente à medida que surgem novas inovações algorítmicas.
As recomendações impulsionadas por IA tornaram-se centrais nos modelos de negócios de grandes empresas de tecnologia e varejo, transformando fundamentalmente como os clientes descobrem e compram produtos. A Amazon, pioneira do e-commerce, gera cerca de 35% de sua receita total por meio de compras guiadas por recomendações, com seu sistema sofisticado analisando histórico de navegação, padrões de compra, avaliações de produtos e comportamentos de clientes semelhantes para sugerir itens em pontos críticos da jornada de compra. A Netflix processa histórico de visualização, avaliações, buscas e padrões temporais para sugerir conteúdos, relatando que recomendações personalizadas respondem por cerca de 80% das horas assistidas na plataforma, demonstrando o impacto profundo da personalização no engajamento e retenção dos usuários. O Spotify utiliza recomendações impulsionadas por IA em múltiplas superfícies, incluindo o recurso “Descobertas da Semana”, que combina filtragem colaborativa com análise de características de áudio e informações contextuais, gerando recomendações musicais altamente personalizadas que se tornaram centrais para engajamento e retenção de assinantes. O Temu, plataforma de e-commerce em rápido crescimento, emprega sistemas avançados de recomendação que analisam padrões comportamentais, buscas e histórico de compras para destacar produtos alinhados ao perfil individual, contribuindo significativamente para seu crescimento explosivo e métricas de engajamento. Essas implementações demonstram que sistemas de recomendação impactam diretamente métricas-chave de negócios como valor do ciclo de vida do cliente, taxas de recompra e tempo de engajamento, com empresas investindo fortemente em tecnologia de recomendação como diferencial competitivo em mercados digitais cada vez mais concorridos.
As recomendações impulsionadas por IA oferecem valor substancial tanto para empresas quanto para usuários, criando um ecossistema mutuamente benéfico que impulsiona engajamento e satisfação:
Benefícios para Empresas:
Benefícios para Usuários:
O impacto cumulativo desses benefícios tornou os sistemas de recomendação infraestrutura essencial no comércio e conteúdo digitais, com usuários cada vez mais esperando experiências personalizadas como recurso padrão, e não como diferencial premium.
Apesar do sucesso generalizado, sistemas de recomendação impulsionados por IA enfrentam desafios significativos que continuam sendo alvo de pesquisadores e profissionais. Preocupações com privacidade de dados se intensificaram à medida que regulamentações como GDPR e CCPA impõem exigências rigorosas sobre coleta e uso de dados, obrigando empresas a equilibrar a eficácia da personalização com direitos de privacidade e obrigações de proteção de dados. O problema do início a frio permanece especialmente crítico para novos usuários e itens, quando a falta de histórico impede recomendações precisas, exigindo abordagens híbridas ou estratégias alternativas para iniciar a personalização. O viés algorítmico é outro desafio central, já que sistemas de recomendação podem perpetuar e amplificar vieses existentes nos dados de treinamento, potencialmente discriminando certos grupos de usuários ou criando bolhas de filtro que limitam o acesso a diferentes perspectivas e conteúdos.
Tendências emergentes estão remodelando o cenário de recomendações, com a personalização em tempo real tornando-se cada vez mais sofisticada graças ao edge computing e ao processamento de dados em fluxo, permitindo adaptação instantânea ao comportamento do usuário. A integração de dados multimodais está indo além dos sinais comportamentais tradicionais para incorporar recursos visuais, características sonoras, conteúdo textual e informações contextuais, permitindo compreensão mais rica e detalhada das preferências do usuário. Recomendações baseadas em emoções representam uma nova fronteira, com sistemas começando a incorporar contexto emocional e análise de sentimento para sugerir recomendações alinhadas não só ao histórico de preferências, mas também ao estado emocional e necessidades do momento. Os próximos avanços devem enfatizar explicabilidade e transparência, permitindo que usuários compreendam o motivo das recomendações e fornecendo mecanismos de controle para que possam moldar seus próprios perfis de recomendação. A convergência dessas tendências indica que a próxima geração de sistemas de recomendação será mais consciente da privacidade, transparente, emocionalmente inteligente e capaz de proporcionar experiências de personalização verdadeiramente transformadoras, respeitando autonomia e direitos dos usuários.
As recomendações impulsionadas por IA sugerem itens de forma proativa com base no comportamento e nas preferências do usuário sem exigir buscas explícitas, enquanto a busca tradicional exige que os usuários pesquisem ativamente por produtos. As recomendações usam aprendizado de máquina para prever interesses, enquanto a busca depende da correspondência de palavras-chave. As recomendações são personalizadas para cada usuário, enquanto os resultados de busca geralmente são mais genéricos. Sistemas modernos frequentemente combinam ambas as abordagens para uma experiência ideal do usuário.
Novos usuários enfrentam o 'problema do início a frio', em que os sistemas não possuem dados históricos para recomendações precisas. As soluções incluem o uso de informações demográficas, exibição de itens populares, aplicação de filtragem baseada em conteúdo de acordo com características dos itens ou solicitação direta de preferências. Sistemas híbridos combinam múltiplas abordagens para acelerar recomendações para novos usuários. Algumas plataformas utilizam filtragem colaborativa com perfis de usuários semelhantes ou informações contextuais como tipo de dispositivo e localização para sugerir inicialmente.
Sistemas de recomendação coletam dados explícitos como avaliações, resenhas e feedback dos usuários, além de dados implícitos como histórico de navegação, registros de compras, tempo gasto em itens, buscas e padrões de cliques. Podem ainda coletar informações contextuais como tipo de dispositivo, localização, horário e fatores sazonais. Sistemas avançados integram dados demográficos, conexões sociais e sinais comportamentais. Toda coleta de dados deve cumprir regulamentos de privacidade como GDPR e CCPA, exigindo consentimento do usuário e uso transparente dos dados.
Sim, sistemas de recomendação podem perpetuar e amplificar vieses presentes nos dados de treinamento, podendo discriminar certos grupos de usuários ou limitar a exposição a conteúdos diversos. O viés algorítmico pode resultar de dados históricos distorcidos, sub-representação de minorias ou ciclos de retroalimentação que reforçam padrões existentes. Combater o viés exige dados de treinamento diversos, auditorias regulares, métricas de equidade e design algorítmico transparente. As empresas devem monitorar ativamente e aplicar estratégias de mitigação para garantir recomendações equitativas para todos os segmentos de usuários.
Sistemas híbridos combinam a capacidade da filtragem colaborativa de identificar recomendações inesperadas com a aptidão da filtragem baseada em conteúdo de lidar com novos itens e fornecer sugestões explicáveis. Essa combinação supera limitações individuais: filtragem colaborativa tem dificuldade com novos itens enquanto a baseada em conteúdo carece de surpresa. Abordagens híbridas usam combinações ponderadas, mecanismos de alternância ou métodos em cascata para aproveitar as forças de cada algoritmo. O resultado é maior precisão, melhor cobertura do catálogo, manejo aprimorado de dados esparsos e desempenho mais robusto em cenários diversos.
As preocupações de privacidade incluem a coleta extensiva de dados necessária para recomendações precisas, possível uso não autorizado dos dados, riscos de vazamentos e desafios de conformidade com GDPR, CCPA e legislações similares. Usuários podem sentir desconforto com o nível de acompanhamento comportamental exigido para personalização. Empresas devem implementar forte segurança de dados, obter consentimento explícito, ser transparentes sobre o uso dos dados e permitir que usuários controlem suas informações. Equilibrar a eficácia da personalização com proteção à privacidade é um desafio contínuo no setor.
Recomendações em tempo real processam dados comportamentais instantaneamente à medida que ocorrem, atualizando sugestões de acordo com interações correntes. Sistemas usam processamento de dados em fluxo e edge computing para analisar ações como cliques, visualizações ou compras em milissegundos. Isso permite personalização dinâmica que se adapta a preferências que mudam durante uma sessão. Sistemas em tempo real exigem infraestrutura robusta, algoritmos eficientes e pipelines de dados de baixa latência. Exemplos incluem a Netflix atualizando recomendações conforme você navega ou a Amazon sugerindo novos itens ao adicionar produtos ao carrinho.
Tendências futuras incluem recomendações baseadas em emoções que levam em conta o estado emocional dos usuários, integração de dados multimodais combinando informações visuais, de áudio e texto, técnicas avançadas de preservação de privacidade, maior explicabilidade e transparência, e personalização em tempo real em larga escala. Tecnologias emergentes como aprendizado federado permitem recomendações sem centralizar os dados do usuário. Os sistemas se tornarão mais contextuais, incorporando fatores temporais e situacionais. A convergência dessas tendências trará personalização mais sofisticada, transparente e consciente da privacidade, respeitando autonomia e direitos dos usuários.
O AmICited rastreia como sistemas de IA como ChatGPT, Perplexity e Google AI Overviews mencionam sua marca em recomendações personalizadas e conteúdos gerados por IA. Fique informado sobre a visibilidade da sua marca em sistemas alimentados por IA.
Saiba como funcionam as recomendações de produtos por IA, os algoritmos por trás delas e como otimizar sua visibilidade em sistemas de recomendação alimentados ...
Saiba o que são sugestões de pesquisa e recomendações de preenchimento automático, como funcionam usando IA e aprendizado de máquina, e seu impacto na visibilid...
Aprenda a rastrear conversões vindas de motores de busca baseados em IA e geradores de respostas como ChatGPT, Perplexity e Gemini usando GA4, canais personaliz...