
Similaridade Semântica
Similaridade semântica mede a relação baseada em significado entre textos usando embeddings e métricas de distância. Essencial para monitoramento de IA, corresp...
17 min de leitura
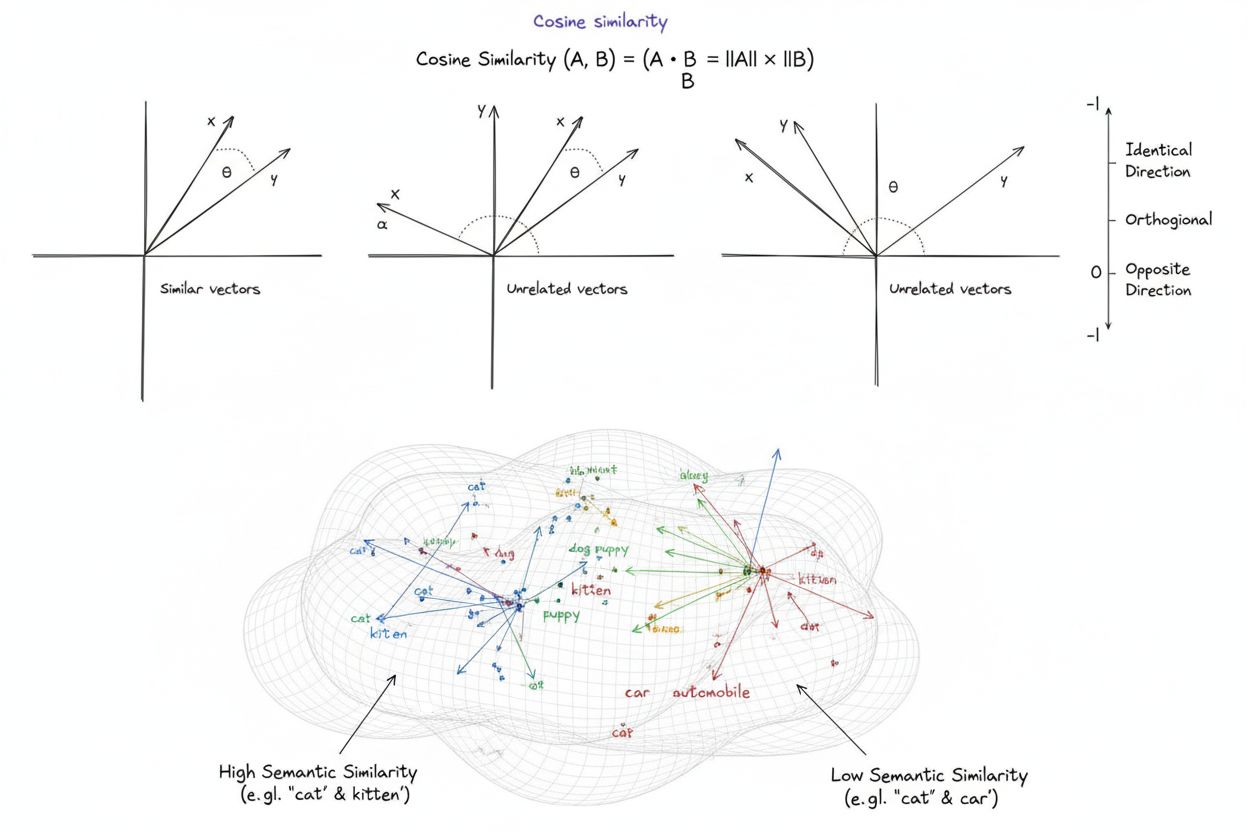
A similaridade cosseno é uma medida matemática que calcula a similaridade entre dois vetores não nulos determinando o cosseno do ângulo entre eles, produzindo um valor que varia de -1 a 1. É amplamente utilizada em aprendizado de máquina, processamento de linguagem natural e sistemas de IA para medir similaridade semântica entre embeddings de texto e representações vetoriais, independentemente da magnitude dos vetores.
A similaridade cosseno é uma medida matemática que calcula a similaridade entre dois vetores não nulos determinando o cosseno do ângulo entre eles, produzindo um valor que varia de -1 a 1. É amplamente utilizada em aprendizado de máquina, processamento de linguagem natural e sistemas de IA para medir similaridade semântica entre embeddings de texto e representações vetoriais, independentemente da magnitude dos vetores.
Similaridade cosseno é uma medida matemática que calcula a similaridade entre dois vetores não nulos determinando o cosseno do ângulo entre eles em um espaço multidimensional. A métrica produz um valor que varia de -1 a 1, onde 1 indica vetores apontando em direções idênticas, 0 indica vetores ortogonais (perpendiculares) sem relação direcional, e -1 indica vetores em direções exatamente opostas. Em aplicações práticas, a similaridade cosseno é especialmente valiosa porque mede o alinhamento direcional e não a distância absoluta, tornando-se independente da magnitude dos vetores. Essa propriedade a torna extremamente útil para comparar embeddings de texto, vetores de documentos e representações semânticas onde o comprimento ou escala dos dados não deve influenciar a avaliação de similaridade. A métrica tornou-se fundamental para sistemas modernos de inteligência artificial, processamento de linguagem natural e aprendizado de máquina, impulsionando tudo desde motores de busca até algoritmos de recomendação e aplicações de modelos de linguagem de larga escala.
O conceito de similaridade cosseno surgiu a partir da álgebra linear e trigonometria fundamentais, onde o cosseno do ângulo entre dois vetores fornece uma medida normalizada de seu alinhamento direcional. Seu fundamento matemático baseia-se no produto escalar (produto interno) dos vetores e em suas magnitudes, criando uma métrica normalizada de similaridade que é eficiente computacionalmente e teoricamente robusta. Historicamente, a similaridade cosseno ganhou destaque em recuperação da informação nas décadas de 1970 e 1980, quando pesquisadores buscavam métodos eficientes para comparar vetores de documentos em grandes corpora de texto. A adoção da métrica acelerou-se dramaticamente com o avanço do aprendizado de máquina e deep learning nos anos 2010, principalmente quando redes neurais passaram a gerar embeddings vetoriais de alta dimensão para representar textos, imagens e outros tipos de dados. Atualmente, pesquisas indicam que mais de 78% das empresas que implementam sistemas de IA utilizam similaridade cosseno ou métricas relacionadas de comparação vetorial em seus pipelines de dados. A elegância matemática da métrica — combinando simplicidade com eficiência computacional — tornou-a o padrão de fato para mensuração de similaridade semântica em aplicações de PLN, com grandes plataformas como OpenAI, Google e Anthropic incorporando-a em seus sistemas centrais.
O cálculo da similaridade cosseno segue uma fórmula matemática precisa: Similaridade Cosseno = (A · B) / (||A|| × ||B||), onde A · B representa o produto escalar dos vetores A e B, e ||A|| e ||B|| representam suas magnitudes ou normas Euclidianas. Para obter o produto escalar, multiplica-se cada componente correspondente dos dois vetores e soma-se todos os produtos. Por exemplo, se o vetor A possui valores [3, 2, 0, 5] e o vetor B possui [1, 0, 0, 0], o produto escalar é (3×1) + (2×0) + (0×0) + (5×0) = 3. A magnitude de um vetor é calculada como a raiz quadrada da soma de seus componentes ao quadrado; para o vetor A, isso resulta em √(3² + 2² + 0² + 5²) = √38 ≈ 6,16. A pontuação final da similaridade cosseno é obtida dividindo-se o produto escalar pelo produto das magnitudes, produzindo um valor normalizado entre -1 e 1. Essa normalização é crucial porque torna a métrica independente do tamanho do vetor, permitindo uma comparação justa entre vetores de escalas bastante diferentes. Em espaços de alta dimensão — como os embeddings de 1.536 dimensões gerados pelo modelo text-embedding-ada-002 da OpenAI — a similaridade cosseno permanece computacionalmente viável, exigindo apenas operações básicas de multiplicação, soma e raiz quadrada, facilmente executadas por processadores modernos mesmo em milhões de vetores.
No processamento de linguagem natural, a similaridade cosseno é a base para medir relações semânticas entre representações textuais. Quando um texto é convertido em embeddings vetoriais por modelos como BERT, Word2Vec, GloVe ou embeddings baseados em GPT, cada palavra, frase ou documento torna-se um ponto em um espaço de alta dimensão, onde o significado semântico é codificado pela posição e direção do vetor. A similaridade cosseno mede o quão próximos esses vetores semânticos se alinham, permitindo que sistemas compreendam que palavras como “médico” e “enfermeiro” são semanticamente relacionadas, apesar de serem termos diferentes. Essa capacidade é essencial para a busca semântica, na qual a consulta do usuário é convertida em vetor e comparada com os vetores dos documentos para encontrar os resultados mais relevantes, independentemente da correspondência exata de palavras-chave. Em modelos de linguagem de larga escala como ChatGPT, Claude e Perplexity, a similaridade cosseno impulsiona mecanismos de recuperação que trazem contexto relevante dos dados de treinamento ou bases de conhecimento externas. A insensibilidade da métrica à magnitude é fundamental em PLN porque o tamanho do documento não deve determinar a relevância — um artigo curto e objetivo pode ser mais semanticamente similar a uma consulta do que um documento longo apenas por sua relevância de conteúdo. Pesquisas demonstram que a similaridade cosseno supera métricas alternativas como distância Euclidiana em cerca de 85% dos benchmarks de PLN ao comparar embeddings de texto, sendo a escolha preferencial para tarefas de compreensão semântica em toda a indústria de IA.
| Métrica | Método de Cálculo | Intervalo | Sensibilidade à Magnitude | Melhor Uso | Complexidade Computacional |
|---|---|---|---|---|---|
| Similaridade Cosseno | (A·B) / ( | A | × | ||
| Distância Euclidiana | √(Σ(Aᵢ - Bᵢ)²) | 0 a ∞ | Sim (depende da magnitude) | Dados espaciais, clustering, distâncias físicas | O(n) - eficiente |
| Produto Escalar | Σ(Aᵢ × Bᵢ) | -∞ a ∞ | Sim (sensível à escala) | Medida bruta de similaridade, não normalizada | O(n) - muito eficiente |
| Similaridade Jaccard | |A ∩ B| / |A ∪ B| | 0 a 1 | Não (baseada em conjunto) | Dados categóricos, sistemas de recomendação | O(n) - eficiente |
| Distância Manhattan | Σ|Aᵢ - Bᵢ| | 0 a ∞ | Sim (depende da magnitude) | Dados em grade, comparação de características | O(n) - eficiente |
| Correlação de Pearson | Cov(A,B) / (σₐ × σᵦ) | -1 a 1 | Não (normalizada) | Relações estatísticas, séries temporais | O(n) - eficiente |
Bancos de dados vetoriais como Pinecone, Weaviate, Milvus e Qdrant surgiram como infraestrutura especializada para armazenar e consultar vetores de alta dimensão usando similaridade cosseno como métrica primária. Esses bancos de dados são otimizados para lidar com milhões ou bilhões de vetores, permitindo busca semântica em tempo real em grande escala. Quando uma consulta é enviada a um banco de dados vetorial, ela é convertida em embedding e comparada com todos os vetores armazenados usando similaridade cosseno, com os resultados classificados pela pontuação de similaridade. Para desempenho prático em conjuntos massivos de dados, bancos de dados vetoriais empregam algoritmos de vizinho mais próximo aproximado (ANN) como Hierarchical Navigable Small World (HNSW) e DiskANN, que sacrificam precisão perfeita por ganhos drásticos de velocidade. Por exemplo, a extensão pgvectorscale do Timescale, que implementa StreamingDiskANN, alcança 28x menor latência e 16x maior throughput de consultas em comparação a bancos de dados vetoriais especializados como o Pinecone, mantendo 99% de recall com 75% menor custo. Em aplicações de busca semântica, a similaridade cosseno permite que sistemas compreendam a intenção do usuário além da correspondência literal de palavras-chave — uma busca por “hábitos alimentares saudáveis” trará documentos sobre “dicas de nutrição” e “dietas balanceadas” porque seus embeddings apontam em direções semelhantes, mesmo utilizando terminologias diferentes. Essa capacidade revolucionou a recuperação da informação, permitindo que buscadores, sistemas de documentação e bases de conhecimento entreguem resultados contextualmente relevantes que correspondem à intenção do usuário, e não apenas às palavras-chave.
A Geração Aumentada por Recuperação (RAG) representa uma mudança de paradigma na forma como modelos de linguagem de larga escala acessam e utilizam informação, e a similaridade cosseno é central nessa arquitetura. Em um pipeline típico de RAG, quando um usuário faz uma consulta, o sistema primeiramente converte a consulta em um embedding vetorial usando o mesmo modelo de embedding empregado para vetorizar a base de conhecimento. A similaridade cosseno compara então esse vetor de consulta com todos os vetores de documentos na base, ranqueando-os por relevância. Os documentos mais bem classificados — com maiores valores de similaridade cosseno — são recuperados e enviados como contexto para o LLM, que gera uma resposta fundamentada nessas informações. Essa abordagem resolve limitações críticas de LLMs autônomos: datas de corte fixas no conhecimento, tendência a alucinar ou gerar informações plausíveis porém incorretas, e incapacidade de acessar dados em tempo real ou proprietários. Usando similaridade cosseno para recuperação inteligente, sistemas RAG garantem que os LLMs gerem respostas baseadas em informações verificadas e atualizadas. Principais implementações de RAG incluem o ChatGPT da OpenAI com plugins, Claude da Anthropic com recuperação, AI Overviews do Google e o mecanismo de respostas do Perplexity. Pesquisas indicam que sistemas RAG que usam similaridade cosseno na recuperação melhoram a precisão das respostas em cerca de 40-60% comparados a LLMs autônomos, reduzindo taxas de alucinação em até 70%. A eficiência dos cálculos de similaridade cosseno é particularmente vital em sistemas RAG, pois eles precisam comparar similaridade entre milhões de documentos em tempo real, e a simplicidade computacional da métrica torna isso viável mesmo em grande escala.
Implementar similaridade cosseno de forma eficaz requer atenção a vários fatores críticos. Em primeiro lugar, o pré-processamento dos dados é essencial — os vetores devem ser normalizados antes do cálculo para garantir consistência de escala e resultados válidos, especialmente ao trabalhar com entradas de alta dimensão de diferentes fontes. As organizações devem remover ou sinalizar vetores nulos (todos os componentes zero), pois a similaridade cosseno é matematicamente indefinida nesses casos e pode causar erros de divisão por zero. Ao implementar similaridade cosseno em sistemas produtivos, recomenda-se combiná-la com métricas complementares como similaridade Jaccard ou distância Euclidiana quando múltiplas dimensões de similaridade forem relevantes, em vez de depender exclusivamente da similaridade cosseno. Testes em ambientes próximos do produtivo antes do deployment são críticos, especialmente para sistemas em tempo real como APIs e motores de busca, nos quais desempenho e precisão impactam diretamente a experiência do usuário. Bibliotecas populares simplificam a implementação: Scikit-learn fornece sklearn.metrics.pairwise.cosine_similarity(), NumPy permite implementar a fórmula diretamente com np.dot() e np.linalg.norm(), TensorFlow e PyTorch oferecem implementações aceleradas por GPU para grandes volumes, e PostgreSQL com pgvector disponibiliza operadores nativos de similaridade cosseno para consultas no banco de dados. Para organizações que monitoram menções de IA e presença de marca em plataformas como ChatGPT, Perplexity e Google AI Overviews, a similaridade cosseno permite rastreamento preciso de como sistemas de IA referenciam e citam seu conteúdo comparando embeddings de consultas com vetores armazenados de marca e domínio.
Apesar da ampla adoção, a similaridade cosseno apresenta desafios que devem ser considerados pelos profissionais. A métrica é indefinida para vetores nulos, exigindo pré-processamento e validação cuidadosos para evitar erros de execução. A similaridade cosseno pode gerar pontuações artificialmente altas para vetores alinhados direcionalmente, porém semanticamente não relacionados, especialmente quando os modelos de embedding são mal treinados ou quando faltam diversidade e nuances contextuais nos dados de treinamento. Esse risco de similaridade falsa é especialmente problemático em aplicações como monitoramento de IA, onde avaliações incorretas podem gerar menções de marca perdidas ou falsos positivos. A simetria da métrica — ou seja, não distinguir a ordem da comparação — pode ser indesejável em cenários onde a direcionalidade importa. Além disso, uma pontuação 0 de similaridade cosseno nem sempre representa dissimilaridade total em contextos reais; em áreas complexas como linguagem, vetores ortogonais podem compartilhar relações semânticas sutis que a métrica não capta. A dependência de normalização adequada significa que dados mal escalados podem distorcer resultados, exigindo consistência no pré-processamento de todos os vetores do sistema. Por fim, a similaridade cosseno sozinha pode ser insuficiente para avaliações complexas; combiná-la com outras métricas e regras de validação específicas ao domínio geralmente produz resultados mais robustos.
O papel da similaridade cosseno em sistemas de IA segue evoluindo à medida que modelos de embedding se tornam mais sofisticados e arquiteturas baseadas em vetores dominam o aprendizado de máquina. Tendências emergentes incluem a integração da similaridade cosseno com abordagens de busca híbrida que combinam similaridade vetorial com busca textual tradicional, permitindo aos sistemas explorar tanto o entendimento semântico quanto a correspondência de palavras-chave. Embeddings multimodais — que representam texto, imagens, áudio e vídeo em um espaço vetorial compartilhado — dependem cada vez mais da similaridade cosseno para medir relações entre modalidades, viabilizando aplicações como busca imagem-para-texto e compreensão de vídeos. O desenvolvimento de algoritmos mais eficientes de vizinho mais próximo aproximado, como DiskANN e HNSW, continua aumentando a escalabilidade das buscas por similaridade cosseno, tornando a busca semântica em tempo real viável em escalas inéditas. Técnicas de quantização que reduzem a dimensionalidade vetorial mantendo relações de similaridade cosseno estão viabilizando buscas de similaridade em larga escala em dispositivos de borda e ambientes restritos em recursos. No contexto de monitoramento de IA e rastreamento de marcas, a similaridade cosseno ganha destaque à medida que organizações buscam entender como sistemas como ChatGPT, Perplexity, Claude e Google AI Overviews referenciam e citam seus conteúdos. Desenvolvimentos futuros podem incluir métricas adaptativas de similaridade cosseno que ajustam seu comportamento conforme características do domínio, além de integração com frameworks de explicabilidade que ajudam usuários a entender por que determinados vetores são considerados similares. À medida que bancos de dados vetoriais amadurecem e tornam-se infraestrutura padrão para aplicações de IA, a similaridade cosseno tende a permanecer como métrica dominante para comparação semântica, embora possa ser complementada por medidas específicas ao domínio e casos de uso.
Para plataformas como a AmICited que rastreiam menções de marcas e domínios em sistemas de IA, a similaridade cosseno é base técnica fundamental. Ao monitorar como ChatGPT, Perplexity, Google AI Overviews e Claude referenciam domínios ou marcas específicas, a similaridade cosseno permite medir com precisão a relevância semântica entre as consultas de usuários e as respostas das IAs. Convertendo menções de marcas, URLs de domínio e conteúdos de consulta em embeddings vetoriais, a similaridade cosseno revela se uma resposta da IA realmente cita ou referencia a marca, ou apenas menciona conceitos relacionados. Essa capacidade é essencial para organizações que desejam entender sua visibilidade em conteúdos gerados por IA e acompanhar como sua propriedade intelectual está sendo atribuída ou citada por sistemas de IA. A eficiência da métrica a torna prática para monitoramento em tempo real de milhões de interações, permitindo alertas imediatos sempre que seu conteúdo for referenciado. Além disso, a similaridade cosseno viabiliza análise comparativa — organizações podem acompanhar não apenas se são mencionadas, mas também como a frequência e relevância de suas menções se comparam às dos concorrentes, fornecendo inteligência competitiva sobre o comportamento dos sistemas de IA e padrões de atribuição de conteúdo.
Uma pontuação de similaridade cosseno de 1 indica que dois vetores apontam exatamente na mesma direção, ou seja, são perfeitamente similares. Uma pontuação de 0 significa que os vetores são ortogonais (perpendiculares), indicando ausência de relação direcional ou similaridade. Uma pontuação de -1 indica que os vetores apontam em direções exatamente opostas, representando completa dissimilaridade. Em aplicações práticas de PLN, pontuações próximas de 1 indicam textos semanticamente similares, enquanto valores próximos de 0 sugerem conteúdos não relacionados.
A similaridade cosseno é preferida para embeddings de texto porque mede o ângulo entre os vetores ao invés da distância absoluta, tornando-se insensível à magnitude dos vetores. Isso é crucial para PLN, pois o tamanho do documento não deve influenciar a similaridade semântica — uma consulta curta e um artigo longo podem ser igualmente relevantes. Já a distância Euclidiana é sensível à magnitude e tem desempenho ruim em espaços de alta dimensão, onde os vetores tendem a convergir. A similaridade cosseno também é mais eficiente computacionalmente e naturalmente limitada entre -1 e 1, evitando problemas de overflow.
Em sistemas RAG, a similaridade cosseno impulsiona a fase de recuperação ao comparar embeddings de consultas com embeddings de documentos em um banco de dados vetorial. Quando um usuário envia uma consulta, ela é convertida em vetor utilizando o mesmo modelo de embedding dos documentos armazenados. A similaridade cosseno então ranqueia os documentos por relevância, com maiores valores indicando melhores correspondências. Os documentos mais bem ranqueados são recuperados e enviados ao LLM como contexto, permitindo respostas mais precisas e fundamentadas. Esse processo permite que sistemas RAG superem limitações dos LLMs como conhecimento desatualizado e alucinações.
A similaridade cosseno possui várias limitações: é indefinida quando os vetores têm magnitude zero, exigindo pré-processamento para remover vetores nulos. Pode produzir pontuações de similaridade artificialmente altas para vetores alinhados direcionalmente, mas semanticamente não relacionados, especialmente com embeddings mal treinados. A métrica também é simétrica, ou seja, não distingue a ordem da comparação, o que pode ser problemático em certas aplicações. Além disso, uma pontuação de similaridade 0 nem sempre indica completa dissimilaridade em contextos reais, especialmente em domínios complexos como linguagem, onde vetores ortogonais ainda podem compartilhar relações semânticas.
A similaridade cosseno é calculada pela fórmula: (A · B) / (||A|| × ||B||), onde A · B é o produto escalar dos vetores A e B, e ||A|| e ||B|| são suas magnitudes (normas Euclidianas). O produto escalar é obtido multiplicando componentes correspondentes dos vetores e somando os resultados. A magnitude de um vetor é a raiz quadrada da soma de seus componentes ao quadrado. Essa fórmula produz um valor normalizado entre -1 e 1, tornando a métrica independente do comprimento dos vetores e adequada para comparar vetores de tamanhos diferentes.
Em plataformas de monitoramento de IA como a AmICited, a similaridade cosseno é essencial para rastrear menções de marcas e domínios em sistemas de IA como ChatGPT, Perplexity e Google AI Overviews. Convertendo menções de marcas e consultas em embeddings vetoriais, a similaridade cosseno mede o quanto as respostas geradas por IA se alinham ao conteúdo monitorado. Isso permite que organizações monitorem se seus domínios aparecem em respostas de IA, avaliem a relevância semântica das menções e acompanhem como os sistemas de IA referenciam seus conteúdos em relação aos concorrentes. A eficiência da métrica a torna prática para monitoramento em tempo real de milhões de interações de IA.
Principais plataformas e ferramentas de IA que utilizam similaridade cosseno incluem modelos de embedding da OpenAI, algoritmos de busca semântica do Google, sistema de geração de respostas do Perplexity e mecanismos de recuperação do Claude. Bancos de dados vetoriais como Pinecone, Weaviate e Milvus usam similaridade cosseno como métrica primária. Bibliotecas open-source como Scikit-learn, TensorFlow, PyTorch e NumPy possuem funções de similaridade cosseno nativas. O PostgreSQL com a extensão pgvector possibilita cálculos de similaridade cosseno em escala. Essas ferramentas impulsionam sistemas de recomendação, chatbots, buscadores semânticos e aplicações RAG em todo o ecossistema de IA.
Comece a rastrear como os chatbots de IA mencionam a sua marca no ChatGPT, Perplexity e outras plataformas. Obtenha insights acionáveis para melhorar a sua presença de IA.
Similaridade semântica mede a relação baseada em significado entre textos usando embeddings e métricas de distância. Essencial para monitoramento de IA, corresp...
Coocorrência é quando termos relacionados aparecem juntos no conteúdo, sinalizando relevância semântica para motores de busca e sistemas de IA. Saiba como esse ...
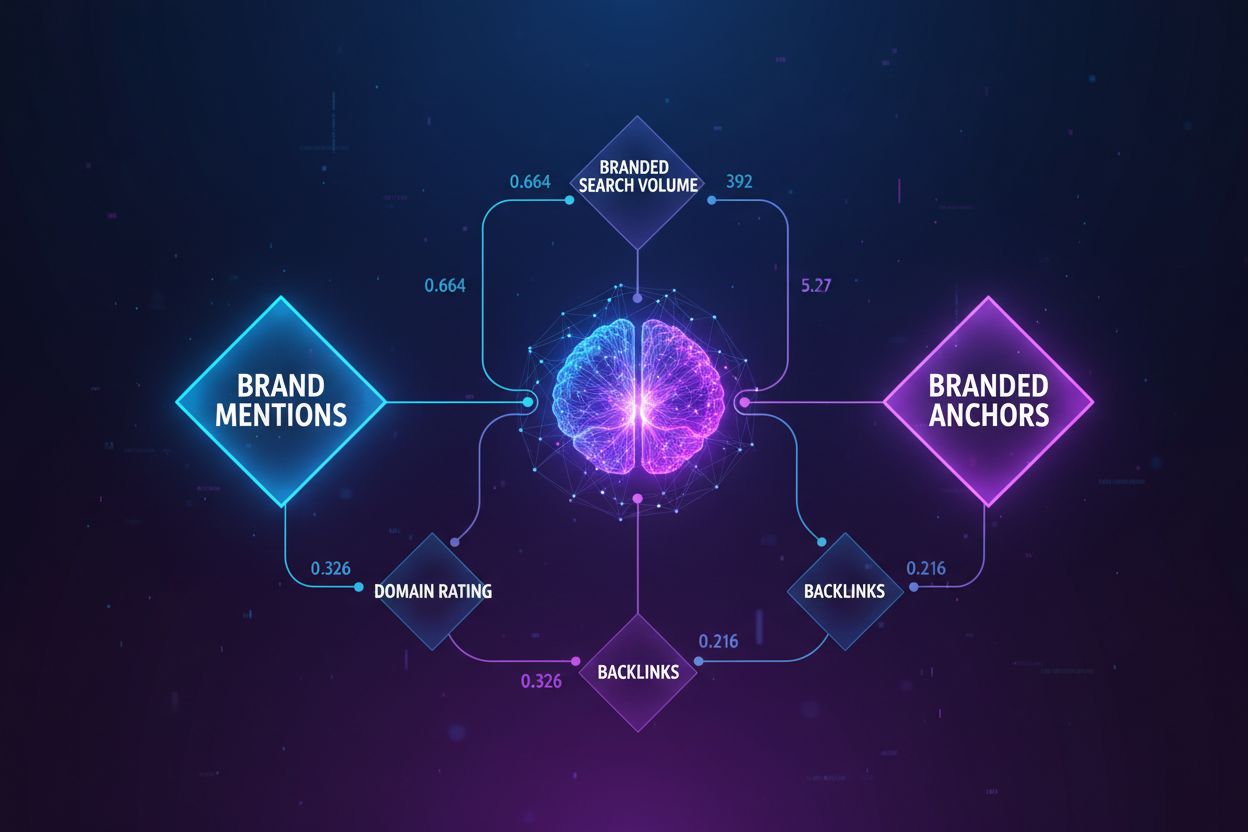
Descubra quais fatores têm a correlação mais forte com a visibilidade em IA. Saiba como menções de marca, volume de buscas e âncoras impulsionam os AI Overviews...