
Cobertura de Indexação por IA
Saiba o que é Cobertura de Indexação por IA e por que ela é importante para a visibilidade da sua marca no ChatGPT, Google AI Overviews e Perplexity. Descubra f...
9 min de leitura

Cobertura de indexação refere-se à porcentagem e ao status das páginas de um site que foram descobertas, rastreadas e incluídas no índice de um mecanismo de busca. Mede quais páginas estão elegíveis para aparecer nos resultados de busca e identifica problemas técnicos que impedem a indexação.
Cobertura de indexação refere-se à porcentagem e ao status das páginas de um site que foram descobertas, rastreadas e incluídas no índice de um mecanismo de busca. Mede quais páginas estão elegíveis para aparecer nos resultados de busca e identifica problemas técnicos que impedem a indexação.
Cobertura de indexação é a métrica que indica quantas páginas do seu site foram descobertas, rastreadas e incluídas no índice de um mecanismo de busca. Representa a porcentagem das páginas do seu site que estão aptas a aparecer nos resultados de busca e identifica quais páginas enfrentam problemas técnicos que impedem a indexação. Em essência, a cobertura de indexação responde à pergunta crítica: “Quanto do meu site os mecanismos de busca realmente conseguem encontrar e ranquear?” Essa métrica é fundamental para entender a visibilidade do seu site nos mecanismos de busca e é acompanhada por ferramentas como o Google Search Console, que oferece relatórios detalhados sobre páginas indexadas, excluídas e com erros. Sem uma cobertura de indexação adequada, até mesmo o conteúdo mais otimizado permanece invisível tanto para mecanismos de busca quanto para usuários em busca de suas informações.
A cobertura de indexação não se refere apenas à quantidade—mas sim à garantia de que as páginas certas estão indexadas. Um site pode ter milhares de páginas, mas, se muitas forem duplicadas, de baixo valor ou bloqueadas pelo robots.txt, a cobertura real de indexação pode ser consideravelmente menor do que o esperado. Essa distinção entre o total de páginas e as páginas indexadas é fundamental para desenvolver uma estratégia eficaz de SEO. Organizações que monitoram a cobertura de indexação regularmente conseguem identificar e corrigir problemas técnicos antes que impactem o tráfego orgânico, tornando-a uma das métricas mais acionáveis do SEO técnico.
O conceito de cobertura de indexação surgiu à medida que os mecanismos de busca evoluíram de simples rastreadores para sistemas sofisticados capazes de processar milhões de páginas diariamente. Nos primeiros anos do SEO, os administradores de sites tinham pouca visibilidade sobre como os mecanismos de busca interagiam com seus sites. O Google Search Console, lançado originalmente como Google Webmaster Tools em 2006, revolucionou essa transparência ao fornecer feedback direto sobre o status de rastreamento e indexação. O Relatório de Cobertura do Índice (antigamente chamado de “Relatório de Indexação de Páginas”) tornou-se a principal ferramenta para entender quais páginas o Google havia indexado e por que outras foram excluídas.
À medida que os sites se tornaram mais complexos, com conteúdo dinâmico, parâmetros e páginas duplicadas, os problemas de cobertura de indexação se tornaram cada vez mais comuns. Pesquisas indicam que aproximadamente 40-60% dos sites apresentam problemas significativos de cobertura de indexação, com muitas páginas permanecendo não descobertas ou deliberadamente excluídas do índice. O surgimento de sites baseados em JavaScript e aplicações de página única complicou ainda mais a indexação, pois os mecanismos de busca passaram a precisar renderizar o conteúdo antes de determinar a indexabilidade. Hoje, o monitoramento da cobertura de indexação é considerado essencial para qualquer organização que dependa de tráfego orgânico, com especialistas do setor recomendando auditorias mensais, no mínimo.
A relação entre a cobertura de indexação e o orçamento de rastreamento tornou-se cada vez mais importante à medida que os sites escalam. Orçamento de rastreamento refere-se ao número de páginas que o Googlebot irá rastrear em seu site em determinado período. Grandes sites com arquitetura ruim ou excesso de conteúdo duplicado podem desperdiçar o orçamento de rastreamento em páginas de baixo valor, deixando conteúdos importantes sem serem descobertos. Estudos mostram que mais de 78% das empresas utilizam algum tipo de ferramenta de monitoramento de conteúdo para acompanhar sua visibilidade nos motores de busca e plataformas de IA, reconhecendo que a cobertura de indexação é fundamental para qualquer estratégia de visibilidade.
| Conceito | Definição | Controle Principal | Ferramentas Utilizadas | Impacto nos Rankings |
|---|---|---|---|---|
| Cobertura de Indexação | Porcentagem de páginas indexadas pelos motores de busca | Meta tags, robots.txt, qualidade do conteúdo | Google Search Console, Bing Webmaster Tools | Direto—apenas páginas indexadas podem ranquear |
| Rastreabilidade | Capacidade dos bots acessarem e navegarem nas páginas | robots.txt, estrutura do site, links internos | Screaming Frog, ZentroAudit, logs do servidor | Indireto—páginas precisam ser rastreáveis para indexação |
| Indexabilidade | Capacidade das páginas rastreadas serem adicionadas ao índice | Diretivas noindex, tags canônicas, conteúdo | Google Search Console, Ferramenta de Inspeção de URL | Direto—determina se as páginas aparecem nos resultados |
| Orçamento de Rastreamento | Número de páginas rastreadas pelo Googlebot em determinado período | Autoridade do site, qualidade das páginas, erros de rastreamento | Google Search Console, logs do servidor | Indireto—afeta quais páginas serão rastreadas |
| Conteúdo Duplicado | Múltiplas páginas com conteúdo idêntico ou semelhante | Tags canônicas, redirecionamentos 301, noindex | Ferramentas de auditoria SEO, análise manual | Negativo—dilui o potencial de ranqueamento |
A cobertura de indexação opera em três etapas: descoberta, rastreamento e indexação. Na fase de descoberta, os mecanismos de busca encontram URLs por diversos meios, incluindo sitemaps XML, links internos, backlinks externos e envio direto via Google Search Console. Uma vez descoberta, a URL é colocada na fila de rastreamento, onde o Googlebot solicita a página e analisa seu conteúdo. Finalmente, durante a indexação, o Google processa o conteúdo da página, determina sua relevância e qualidade e decide se ela será incluída no índice pesquisável.
O Relatório de Cobertura do Índice no Google Search Console categoriza as páginas em quatro status principais: Válidas (páginas indexadas), Válidas com avisos (indexadas, mas com problemas), Excluídas (intencionalmente não indexadas) e Erro (páginas que não puderam ser indexadas). Dentro de cada status, existem tipos específicos de problemas que fornecem insights detalhados sobre o motivo pelo qual as páginas estão ou não indexadas. Por exemplo, páginas podem ser excluídas por conterem uma meta tag noindex, serem bloqueadas pelo robots.txt, serem duplicadas sem tags canônicas adequadas ou retornarem códigos de status HTTP 4xx ou 5xx.
Compreender os mecanismos técnicos por trás da cobertura de indexação exige conhecimento de alguns componentes-chave. O arquivo robots.txt é um arquivo de texto no diretório raiz do site que instrui os rastreadores dos motores de busca sobre quais diretórios e arquivos podem ou não ser acessados. Uma configuração incorreta do robots.txt é uma das causas mais comuns de problemas de indexação—bloquear acidentalmente diretórios importantes impede que o Google descubra essas páginas. A meta tag robots, colocada no head HTML da página, fornece instruções em nível de página usando diretivas como index, noindex, follow e nofollow. A tag canônica (rel=“canonical”) informa aos mecanismos de busca qual é a versão preferida de uma página quando existem duplicatas, evitando inchaço do índice e consolidando sinais de ranqueamento.
Para empresas que dependem de tráfego orgânico, a cobertura de indexação impacta diretamente receita e visibilidade. Quando páginas importantes não são indexadas, elas não podem aparecer nos resultados de busca, o que significa que potenciais clientes não as encontrarão pelo Google. Lojas virtuais com baixa cobertura de indexação podem ter páginas de produtos presas no status “Descoberto – atualmente não indexado”, resultando em perda de vendas. Plataformas de marketing de conteúdo com milhares de artigos precisam de uma cobertura robusta para garantir que seu conteúdo chegue ao público. Empresas SaaS dependem de documentação e posts de blog indexados para gerar leads orgânicos.
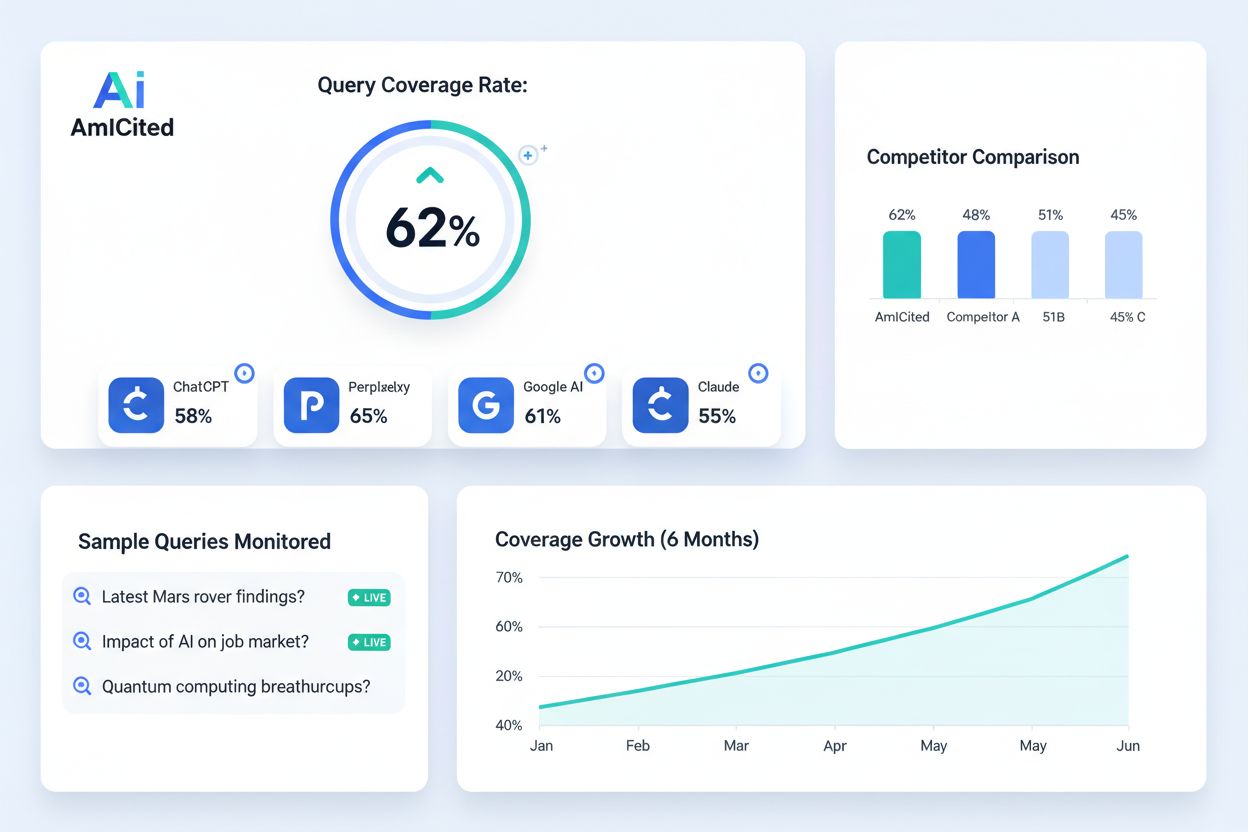
As implicações práticas vão além da busca tradicional. Com o crescimento de plataformas de IA generativa como ChatGPT, Perplexity e Google AI Overviews, a cobertura de indexação passou a ser relevante também para a visibilidade em IA. Esses sistemas frequentemente utilizam conteúdo indexado na web como fonte de dados de treinamento e de citações. Se suas páginas não estiverem devidamente indexadas pelo Google, é menos provável que sejam incluídas em datasets de IA ou citadas em respostas geradas por IA. Isso gera um problema de visibilidade composto: baixa cobertura de indexação afeta tanto os rankings de busca tradicionais quanto a visibilidade em conteúdos gerados por IA.
Organizações que monitoram proativamente a cobertura de indexação observam melhorias mensuráveis no tráfego orgânico. Um cenário típico envolve descobrir que 30-40% das URLs enviadas estão excluídas por tags noindex, conteúdo duplicado ou erros de rastreamento. Após a remediação—removendo tags noindex desnecessárias, implementando canonização adequada e corrigindo erros de rastreamento—o número de páginas indexadas costuma aumentar entre 20-50%, o que se correlaciona diretamente com maior visibilidade orgânica. O custo da inação é significativo: cada mês em que uma página permanece não indexada é um mês de tráfego e conversões potenciais perdidos.
O Google Search Console continua sendo a principal ferramenta para monitorar a cobertura de indexação, fornecendo os dados mais confiáveis sobre as decisões de indexação do Google. O Relatório de Cobertura do Índice mostra páginas indexadas, com avisos, excluídas e com erro, além de detalhar os tipos específicos de problemas. O Google também disponibiliza a Ferramenta de Inspeção de URL, que permite verificar o status de indexação de páginas individuais e solicitar indexação para conteúdo novo ou atualizado. Essa ferramenta é fundamental para solucionar problemas específicos e entender por que o Google não indexou determinada página.
O Bing Webmaster Tools oferece funcionalidades semelhantes por meio do Index Explorer e do Envio de URL. Embora o Bing tenha uma fatia de mercado menor que o Google, ainda é importante para alcançar usuários que preferem esse buscador. Os dados de cobertura de indexação do Bing às vezes diferem dos do Google, revelando problemas específicos nos algoritmos de rastreamento ou indexação do Bing. Organizações que gerenciam grandes sites devem monitorar ambas as plataformas para garantir cobertura abrangente.
Para monitoramento de IA e visibilidade de marca, plataformas como a AmICited acompanham como sua marca e domínio aparecem no ChatGPT, Perplexity, Google AI Overviews e Claude. Essas plataformas correlacionam a cobertura tradicional de indexação com a visibilidade em IA, ajudando as organizações a entender como seu conteúdo indexado é mencionado em respostas geradas por IA. Essa integração é fundamental para uma estratégia moderna de SEO, já que a visibilidade em sistemas de IA influencia cada vez mais o reconhecimento da marca e o tráfego.
Ferramentas de auditoria SEO de terceiros como Ahrefs, SEMrush e Screaming Frog oferecem insights adicionais sobre cobertura de indexação ao rastrear seu site independentemente e comparar os resultados com os relatórios do Google. Diferenças entre o rastreamento da ferramenta e o reportado pelo Google podem indicar problemas como renderização de JavaScript, falhas no servidor ou restrições de orçamento de rastreamento. Essas ferramentas também identificam páginas órfãs (sem links internos), que frequentemente enfrentam dificuldades de indexação.
Melhorar a cobertura de indexação exige uma abordagem sistemática que aborde questões técnicas e estratégicas. Primeiro, faça uma auditoria do estado atual utilizando o Relatório de Cobertura do Google Search Console. Identifique os principais tipos de problemas que afetam seu site—sejam tags noindex, bloqueios em robots.txt, conteúdo duplicado ou erros de rastreamento. Priorize os problemas por impacto: páginas que deveriam ser indexadas, mas não são, têm prioridade maior que páginas corretamente excluídas.
Segundo, corrija configurações incorretas no robots.txt revisando o arquivo e garantindo que não está bloqueando acidentalmente diretórios importantes. Um erro comum é bloquear /admin/, /staging/ ou /temp/ (que devem ser bloqueados), mas também bloquear sem querer /blog/, /produtos/ ou outros conteúdos públicos. Use o testador de robots.txt do Google Search Console para verificar se páginas importantes não estão bloqueadas.
Terceiro, implemente canonização adequada para conteúdo duplicado. Se você possui múltiplas URLs servindo conteúdo semelhante (ex: páginas de produtos acessíveis por diferentes caminhos de categoria), implemente tags canônicas autorreferenciadas em cada página ou use redirecionamentos 301 para consolidar para uma única versão. Isso evita inchaço no índice e consolida os sinais de ranqueamento na versão preferida.
Quarto, remova tags noindex desnecessárias de páginas que você deseja indexar. Faça uma auditoria no site em busca de diretivas noindex, especialmente em ambientes de teste que podem ter sido publicados por engano em produção. Use a Ferramenta de Inspeção de URL para verificar se páginas importantes não possuem tags noindex.
Quinto, envie um sitemap XML ao Google Search Console contendo apenas URLs indexáveis. Mantenha o sitemap limpo, excluindo páginas com tags noindex, redirecionamentos ou erros 404. Para sites grandes, considere dividir os sitemaps por tipo de conteúdo ou seção para melhor organização e relatórios de erro mais detalhados.
Sexto, corrija erros de rastreamento como links quebrados (404), erros de servidor (5xx) e cadeias de redirecionamento. Use o Google Search Console para identificar páginas afetadas e resolva cada problema de forma sistemática. Para erros 404 em páginas importantes, restaure o conteúdo ou implemente redirecionamentos 301 para alternativas relevantes.
O futuro da cobertura de indexação está evoluindo junto com as mudanças na tecnologia de busca e o surgimento de sistemas de IA generativa. À medida que o Google continua refinando os requisitos dos Core Web Vitals e os padrões de E-E-A-T (Experiência, Expertise, Autoridade e Confiabilidade), a cobertura de indexação dependerá cada vez mais da qualidade e da experiência do usuário. Páginas com Core Web Vitals ruins ou conteúdo raso podem enfrentar desafios de indexação mesmo que sejam tecnicamente rastreáveis.
O crescimento de resultados de busca gerados por IA e motores de resposta está mudando como a cobertura de indexação importa. Os rankings tradicionais dependem de páginas indexadas, mas os sistemas de IA podem citar conteúdo indexado de forma diferente ou priorizar certas fontes em relação a outras. As organizações precisarão monitorar não apenas se as páginas estão indexadas pelo Google, mas também se estão sendo citadas e referenciadas por plataformas de IA. Essa dupla exigência de visibilidade faz com que o monitoramento da cobertura de indexação precise ir além do Google Search Console, incluindo plataformas de monitoramento de IA que rastreiam menções de marca no ChatGPT, Perplexity e outros sistemas de IA generativa.
A renderização de JavaScript e o conteúdo dinâmico continuarão complicando a cobertura de indexação. Com mais sites adotando frameworks JavaScript e aplicações de página única, os mecanismos de busca devem renderizar o JavaScript para entender o conteúdo da página. O Google aprimorou sua capacidade de renderização de JavaScript, mas ainda existem desafios. As melhores práticas futuras provavelmente enfatizarão a renderização no servidor ou renderização dinâmica para garantir que o conteúdo esteja imediatamente acessível aos rastreadores sem exigir execução de JavaScript.
A integração de dados estruturados e schema markup se tornará cada vez mais importante para a cobertura de indexação. Os mecanismos de busca usam dados estruturados para compreender melhor o conteúdo e o contexto das páginas, o que pode melhorar as decisões de indexação. Organizações que implementam schema markup abrangente para seus tipos de conteúdo—artigos, produtos, eventos, FAQs—podem observar melhor cobertura de indexação e maior exposição em resultados enriquecidos.
Por fim, o conceito de cobertura de indexação vai além das páginas para incluir entidades e tópicos. Em vez de apenas acompanhar se páginas estão indexadas, o monitoramento futuro focará se sua marca, produtos e tópicos estão devidamente representados nos knowledge graphs dos motores de busca e nos dados de treinamento de IA. Isso representa uma mudança fundamental do monitoramento no nível de páginas para o monitoramento no nível de entidades, exigindo novas abordagens e estratégias.
+++
Rastreabilidade refere-se à capacidade dos bots dos motores de busca acessarem e navegarem pelas páginas do seu site, sendo controlada por fatores como o robots.txt e a estrutura do site. Já a indexabilidade determina se as páginas rastreadas realmente serão adicionadas ao índice do motor de busca, sendo controlada por meta tags robots, tags canônicas e qualidade do conteúdo. Uma página precisa ser rastreável para ser indexável, mas ser rastreável não garante sua indexação.
Para a maioria dos sites, verificar a cobertura de indexação mensalmente é suficiente para identificar grandes problemas. No entanto, se você faz mudanças significativas na estrutura do site, publica novos conteúdos regularmente ou realiza migrações, monitore o relatório semanalmente ou quinzenalmente. O Google envia notificações por e-mail sobre problemas críticos, mas elas costumam atrasar, então o monitoramento proativo é essencial para manter a visibilidade ideal.
Esse status indica que o Google encontrou uma URL (normalmente via sitemaps ou links internos), mas ainda não a rastreou. Isso pode ocorrer devido a limitações do orçamento de rastreamento, quando o Google prioriza outras páginas do seu site. Se páginas importantes permanecerem nesse status por longos períodos, pode ser sinal de problemas com o orçamento de rastreamento ou baixa autoridade do site que precisam ser corrigidos.
Sim, enviar um sitemap XML ao Google Search Console ajuda os motores de busca a descobrir e priorizar suas páginas para rastreamento e indexação. Um sitemap bem mantido, contendo apenas URLs indexáveis, pode melhorar significativamente a cobertura de indexação ao direcionar o orçamento de rastreamento do Google para o conteúdo mais importante e reduzir o tempo necessário para a descoberta.
Problemas comuns incluem páginas bloqueadas por robots.txt, meta tags noindex em páginas importantes, conteúdo duplicado sem canonização adequada, erros de servidor (5xx), cadeias de redirecionamento e conteúdo raso. Além disso, erros 404, soft 404s e páginas com exigência de autenticação (erros 401/403) aparecem frequentemente nos relatórios de cobertura de indexação e precisam ser corrigidos para melhorar a visibilidade.
A cobertura de indexação impacta diretamente se o seu conteúdo aparece em respostas geradas por IA em plataformas como ChatGPT, Perplexity e Google AI Overviews. Se suas páginas não estiverem devidamente indexadas pelo Google, é menos provável que sejam incluídas em dados de treinamento ou citadas por sistemas de IA. Monitorar a cobertura de indexação garante que o conteúdo da sua marca seja descoberto e citado tanto na busca tradicional quanto nas plataformas de IA generativa.
O orçamento de rastreamento é o número de páginas que o Googlebot irá rastrear em seu site em determinado período. Sites com baixa eficiência de orçamento de rastreamento podem ter muitas páginas presas no status 'Descoberto – atualmente não indexado'. Otimizar o orçamento de rastreamento, corrigindo erros, removendo URLs duplicadas e usando o robots.txt de forma estratégica, garante que o Google foque na indexação do seu conteúdo mais valioso.
Não, nem todas as páginas devem ser indexadas. Páginas como ambientes de testes, variações duplicadas de produtos, resultados internos de busca e arquivos de políticas de privacidade normalmente devem ser excluídas do índice usando tags noindex ou robots.txt. O objetivo é indexar apenas conteúdo de alto valor, único e que atenda à intenção do usuário, contribuindo para o desempenho geral de SEO do seu site.
Comece a rastrear como os chatbots de IA mencionam a sua marca no ChatGPT, Perplexity e outras plataformas. Obtenha insights acionáveis para melhorar a sua presença de IA.
Saiba o que é Cobertura de Indexação por IA e por que ela é importante para a visibilidade da sua marca no ChatGPT, Google AI Overviews e Perplexity. Descubra f...

Indexabilidade é a capacidade dos mecanismos de busca incluírem páginas em seu índice. Saiba como rastreabilidade, fatores técnicos e qualidade de conteúdo afet...
Aprenda o que é Taxa de Cobertura de Consultas, como medi-la e por que ela é fundamental para a visibilidade da marca em buscas alimentadas por IA. Descubra ben...