
O que é o MUM e como ele afeta a busca por IA?
Saiba mais sobre o Modelo Unificado Multitarefa (MUM) do Google e seu impacto nos resultados de busca por IA. Entenda como o MUM processa consultas complexas em...
9 min de leitura
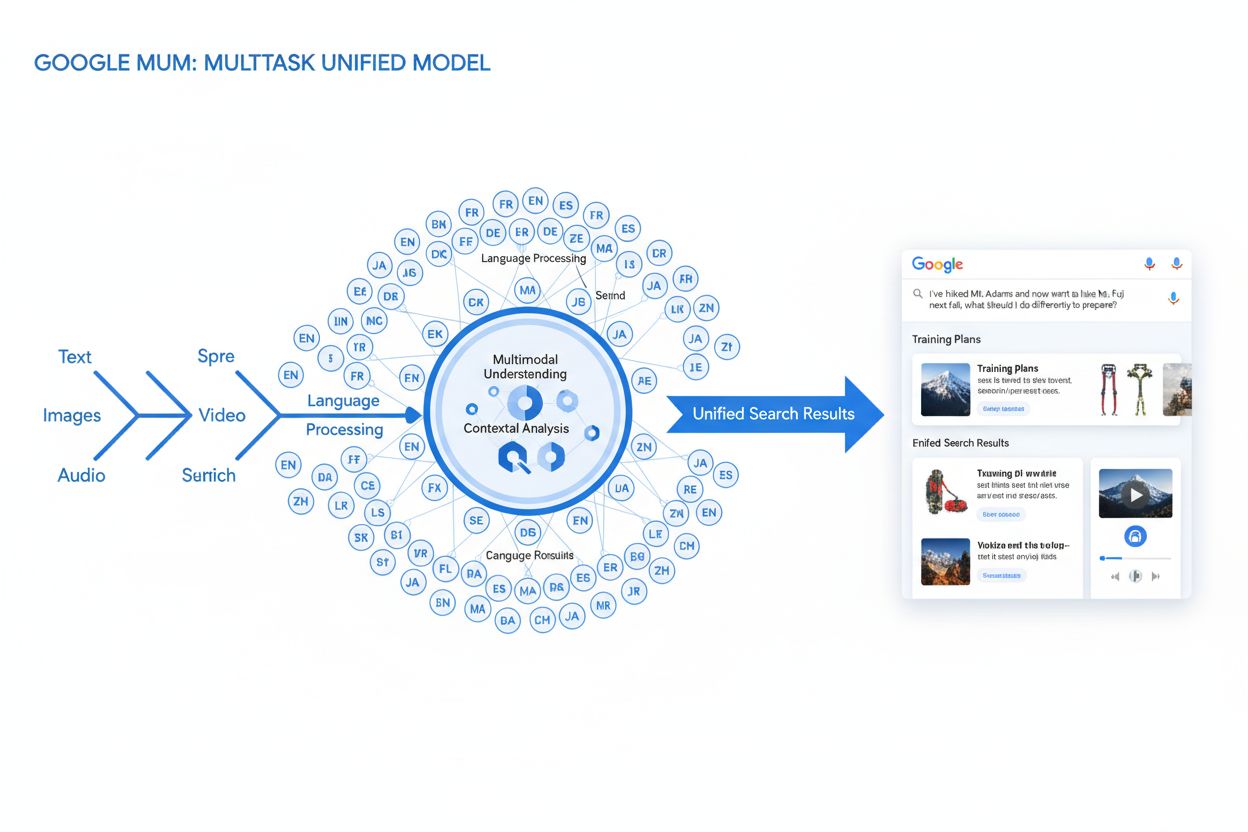
MUM (Multitask Unified Model) é o avançado modelo de IA multimodal do Google que processa texto, imagens, vídeo e áudio simultaneamente em mais de 75 idiomas para fornecer resultados de pesquisa mais abrangentes e contextuais. Lançado em 2021, o MUM é 1.000 vezes mais poderoso que o BERT e representa uma mudança fundamental na forma como os mecanismos de busca entendem e respondem a consultas complexas dos usuários.
MUM (Multitask Unified Model) é o avançado modelo de IA multimodal do Google que processa texto, imagens, vídeo e áudio simultaneamente em mais de 75 idiomas para fornecer resultados de pesquisa mais abrangentes e contextuais. Lançado em 2021, o MUM é 1.000 vezes mais poderoso que o BERT e representa uma mudança fundamental na forma como os mecanismos de busca entendem e respondem a consultas complexas dos usuários.
MUM (Multitask Unified Model) é o avançado modelo de inteligência artificial multimodal do Google projetado para revolucionar a forma como mecanismos de busca entendem e respondem a consultas complexas dos usuários. Anunciado em maio de 2021 por Pandu Nayak, Google Fellow e Vice-presidente de Pesquisa, o MUM representa uma mudança fundamental na tecnologia de recuperação de informações. Construído sobre o framework T5 de text-to-text e com aproximadamente 110 bilhões de parâmetros, o MUM é 1.000 vezes mais poderoso que o BERT, o anterior marco do Google em processamento de linguagem natural. Diferente dos algoritmos tradicionais de busca, que processam texto de forma isolada, o MUM processa simultaneamente texto, imagens, vídeo e áudio enquanto compreende informações em mais de 75 idiomas nativamente. Essa capacidade multimodal e multilíngue possibilita ao MUM entender consultas complexas que antes exigiam múltiplas pesquisas dos usuários, transformando a busca de um simples exercício de correspondência de palavras-chave em um sistema inteligente de recuperação de informações com consciência de contexto. O MUM não apenas entende a linguagem, mas também a gera, sendo capaz de sintetizar informações de diversas fontes e formatos para fornecer respostas abrangentes e nuançadas que atendem ao escopo total da intenção do usuário.
A trajetória do Google até o MUM representa anos de inovação incremental em processamento de linguagem natural e aprendizado de máquina. A evolução começou com o Hummingbird (2013), que introduziu o entendimento semântico para interpretar o significado por trás das consultas, em vez de apenas corresponder palavras-chave. Em seguida veio o RankBrain (2015), que utilizou aprendizado de máquina para compreender palavras-chave de cauda longa e padrões de pesquisa inéditos. O Neural Matching (2018) avançou ainda mais ao usar redes neurais para combinar consultas com conteúdo relevante em um nível semântico mais profundo. O BERT (Bidirectional Encoder Representations from Transformers), lançado em 2019, marcou um grande avanço ao entender o contexto dentro de frases e parágrafos, melhorando a capacidade do Google de interpretar linguagem nuançada. Contudo, o BERT apresentava limitações significativas—processava apenas texto, tinha suporte multilíngue limitado e não conseguia lidar com a complexidade de consultas que exigiam síntese de informações em múltiplos formatos. Segundo pesquisas do Google, usuários realizam, em média, oito consultas separadas para responder perguntas complexas, como comparar dois destinos de trilha ou avaliar opções de produtos. Essa estatística evidenciou uma lacuna crítica na tecnologia de busca que o MUM foi especificamente criado para preencher. A Helpful Content Update (2022) e o framework E-E-A-T (2023) refinaram ainda mais a forma como o Google prioriza conteúdo autoritativo e confiável. O MUM se baseia em todas essas inovações, introduzindo capacidades que vão além das limitações anteriores, representando não apenas uma melhoria incremental, mas uma mudança de paradigma em como mecanismos de busca processam e entregam informações.
A base técnica do MUM está na arquitetura Transformer, especificamente no framework T5 (Text-to-Text Transfer Transformer) desenvolvido anteriormente pelo Google. O T5 trata todas as tarefas de processamento de linguagem natural como problemas texto para texto, convertendo entradas e saídas em representações textuais unificadas. O MUM expande essa abordagem ao incorporar capacidades de processamento multimodal, permitindo lidar com texto, imagens, vídeo e áudio simultaneamente em um único modelo. Essa escolha arquitetural é significativa porque permite ao MUM entender relações e contexto entre diferentes tipos de mídia de maneiras que modelos anteriores não conseguiam. Por exemplo, ao processar uma consulta sobre trilha no Monte Fuji combinada com a imagem de botas específicas, o MUM não analisa texto e imagem separadamente—ele processa ambos juntos, entendendo como as características da bota se relacionam com o contexto da consulta. Os 110 bilhões de parâmetros do modelo lhe conferem capacidade para armazenar e processar vastas quantidades de conhecimento sobre linguagem, conceitos visuais e seus relacionamentos. O MUM é treinado em 75 idiomas diferentes e múltiplas tarefas simultaneamente, o que possibilita um entendimento mais abrangente de informações e conhecimento de mundo do que modelos treinados em um único idioma ou tarefa. Essa abordagem multitarefa faz com que o MUM aprenda a reconhecer padrões e relações que se transferem entre idiomas e domínios, tornando-o mais robusto e generalizável que modelos anteriores. O processamento simultâneo de vários idiomas durante o treinamento permite ao MUM realizar transferência de conhecimento entre idiomas, ou seja, entender informações escritas em um idioma e aplicar esse entendimento a consultas em outro, quebrando barreiras linguísticas que antes limitavam os resultados da busca.
| Atributo | MUM (2021) | BERT (2019) | RankBrain (2015) | Framework T5 |
|---|---|---|---|---|
| Função Primária | Compreensão multimodal de consultas e síntese de respostas | Compreensão contextual baseada em texto | Interpretação de palavras-chave de cauda longa | Aprendizado de transferência texto para texto |
| Modalidades de Entrada | Texto, imagens, vídeo, áudio | Apenas texto | Apenas texto | Apenas texto |
| Suporte a Idiomas | Mais de 75 idiomas nativamente | Suporte multilíngue limitado | Principalmente inglês | Principalmente inglês |
| Parâmetros do Modelo | ~110 bilhões | ~340 milhões | Não divulgado | ~220 milhões |
| Comparação de Potência | 1.000x mais poderoso que o BERT | Referência | Predecessor do BERT | Base para o MUM |
| Capacidades | Compreensão + geração | Apenas compreensão | Reconhecimento de padrões | Transformação de texto |
| Impacto na SERP | Resultados enriquecidos e multiformato | Melhores trechos e contexto | Relevância aprimorada | Tecnologia fundacional |
| Tratamento de Consultas Complexas | Consultas complexas e multi-etapas | Contexto de consulta única | Variações de cauda longa | Tarefas de transformação de texto |
| Transferência de Conhecimento | Entre idiomas e modalidades | Apenas dentro do idioma | Transferência limitada | Transferência entre tarefas |
| Aplicação no Mundo Real | Busca Google, AI Overviews | Ranqueamento na Busca Google | Ranqueamento na Busca Google | Base técnica do MUM |
O processamento de consultas pelo MUM envolve múltiplas etapas sofisticadas que trabalham juntas para entregar respostas abrangentes e contextuais. Quando um usuário envia uma consulta, o MUM inicia com um pré-processamento independente de idioma, entendendo a consulta em qualquer um dos mais de 75 idiomas suportados, sem necessidade de tradução. Esse entendimento nativo preserva nuances linguísticas e contexto regional que poderiam se perder na tradução. Em seguida, o MUM utiliza correspondência sequência a sequência, analisando toda a consulta como uma sequência de significados em vez de palavras-chave isoladas. Isso permite ao MUM compreender relações entre conceitos—por exemplo, reconhecer que uma consulta sobre “preparar-se para o Monte Fuji após escalar o Monte Adams” envolve comparação, preparação e adaptação contextual. Simultaneamente, o MUM realiza análise de entrada multimodal, processando quaisquer imagens, vídeos ou outros meios incluídos na consulta. O modelo então executa um processamento simultâneo da consulta, avaliando múltiplas intenções possíveis do usuário em paralelo, ao invés de se limitar a uma única interpretação. Assim, o MUM pode reconhecer que uma consulta sobre trilha no Monte Fuji pode envolver preparação física, escolha de equipamentos, experiências culturais ou logística de viagem—e exibe informações relevantes para todas essas interpretações. O entendimento semântico baseado em vetores converte a consulta e o conteúdo indexado em vetores de alta dimensão que representam o significado semântico, permitindo a recuperação com base na similaridade conceitual, e não em correspondência de palavras-chave. O MUM então aplica filtros de conteúdo via transferência de conhecimento, utilizando aprendizado de máquina treinado em logs de pesquisa, dados de navegação e padrões de comportamento de usuários para priorizar fontes de alta qualidade e autoridade. Por fim, o MUM gera uma composição multimídia enriquecida na SERP, combinando trechos de texto, imagens, vídeos, perguntas relacionadas e elementos interativos em uma experiência de busca visualmente rica. Todo esse processo ocorre em milissegundos, permitindo ao MUM entregar resultados que respondem não apenas à consulta explícita, mas também a perguntas subsequentes e necessidades relacionadas de informação.
As capacidades multimodais do MUM representam uma ruptura fundamental com os sistemas de busca apenas baseados em texto. O modelo pode processar e compreender informações de texto, imagens, vídeo e áudio simultaneamente, extraindo significado de cada modalidade e sintetizando em respostas coesas. Essa capacidade é especialmente poderosa para consultas que se beneficiam de contexto visual. Por exemplo, se um usuário perguntar “Posso usar estas botas de caminhada para o Monte Fuji?” mostrando uma imagem das próprias botas, o MUM entende as características da bota a partir da imagem—material, padrão do solado, altura, cor—e conecta esse entendimento visual ao conhecimento sobre o terreno, clima e exigências de trilha do Monte Fuji para fornecer uma resposta contextualizada. A dimensão multilíngue do MUM é igualmente transformadora. Com suporte nativo para mais de 75 idiomas, o MUM pode realizar transferência de conhecimento entre idiomas, ou seja, aprende com fontes em um idioma e aplica esse conhecimento a consultas em outro. Isso elimina uma barreira significativa que antes limitava os resultados de busca ao idioma do usuário. Se informações detalhadas sobre o Monte Fuji existirem principalmente em fontes japonesas—including guias locais de trilha, padrões sazonais de clima e insights culturais—o MUM pode compreender esse conteúdo em japonês e apresentar informações relevantes a usuários que falam inglês. Segundo testes do Google, o MUM conseguiu listar 800 variações de vacinas contra a COVID-19 em mais de 50 idiomas em poucos segundos, demonstrando a escala e velocidade de seu processamento multilíngue. Esse entendimento multilíngue é particularmente valioso para usuários em mercados não anglófonos e para consultas sobre temas com informações ricas em vários idiomas. A combinação de processamento multimodal e multilíngue permite ao MUM destacar as informações mais relevantes, independentemente do formato apresentado ou do idioma original, criando uma experiência de busca verdadeiramente global.
O MUM transforma fundamentalmente como os resultados de busca são exibidos e experimentados pelos usuários. Em vez da tradicional lista de links azuis que dominou a busca por décadas, o MUM cria SERPs enriquecidas e interativas que combinam múltiplos formatos de conteúdo em uma única página. Os usuários podem ver trechos de texto, imagens em alta resolução, carrosséis de vídeo, perguntas relacionadas e elementos interativos sem sair da página de resultados. Essa mudança tem profundas implicações para a interação do usuário com a busca. Em vez de realizar múltimas buscas para reunir informações sobre um tema complexo, o usuário pode explorar diferentes ângulos e subtemas diretamente na SERP. Por exemplo, uma consulta sobre “preparar-se para o Monte Fuji no outono” pode mostrar comparações de elevação, previsões do tempo, recomendações de equipamentos, guias em vídeo e avaliações de usuários—tudo organizado contextualmente em uma página. A integração com o Google Lens alimentada pelo MUM permite pesquisas usando imagens em vez de palavras-chave, transformando elementos visuais em ferramentas interativas de descoberta. Os painéis “Coisas para Saber” dividem consultas complexas em subtemas digeríveis, guiando o usuário por diferentes aspectos de um tema com trechos relevantes para cada um. Imagens ampliáveis em alta resolução aparecem diretamente nos resultados, permitindo comparação visual e reduzindo a fricção nas etapas iniciais de decisão. A funcionalidade “Refinar e Ampliar” sugere conceitos relacionados para ajudar o usuário a se aprofundar ou explorar tópicos adjacentes. Essas mudanças representam uma transição da busca como mecanismo de recuperação simples para uma experiência interativa e exploratória que antecipa as necessidades do usuário e fornece informações completas dentro da própria interface de pesquisa. Pesquisas indicam que essa experiência mais rica reduz o número médio de buscas necessárias para responder perguntas complexas, mas também significa que os usuários podem consumir informações diretamente nos resultados sem clicar em sites.
Para organizações que acompanham sua presença em sistemas de IA, o MUM representa uma evolução crítica na forma como a informação é descoberta e exibida. À medida que o MUM se integra cada vez mais à Busca Google e influencia outros sistemas de IA, entender como marcas e domínios aparecem nos resultados movidos pelo MUM torna-se essencial para manter a visibilidade. O processamento multimodal do MUM significa que as marcas precisam otimizar em múltiplos formatos de conteúdo, não apenas em texto. Uma marca que antes dependia de ranquear para palavras-chave específicas agora precisa garantir que seu conteúdo seja descoberto por meio de imagens, vídeos e dados estruturados. A capacidade do modelo de sintetizar informações de diversas fontes faz com que a visibilidade dependa não apenas do próprio site da marca, mas de como suas informações aparecem em todo o ecossistema web. As capacidades multilíngues do MUM criam novas oportunidades e desafios para marcas globais. Conteúdos publicados em um idioma agora podem ser descobertos por usuários pesquisando em outros idiomas, ampliando o alcance potencial. Contudo, isso também significa que as marcas devem garantir que suas informações estejam corretas e consistentes entre idiomas, já que o MUM pode exibir dados de múltiplas fontes linguísticas em uma única consulta. Para plataformas de monitoramento de IA como o AmICited, rastrear o impacto do MUM é crucial porque ele representa como sistemas modernos de IA recuperam e apresentam informações. Ao monitorar onde uma marca aparece em respostas de IA—seja no Google AI Overviews, Perplexity, ChatGPT ou Claude—entender a tecnologia subjacente ao MUM ajuda a explicar por que certos conteúdos são exibidos e como otimizar para visibilidade. A transição para buscas multimodais e multilíngues exige que as marcas façam monitoramento abrangente de sua presença em diferentes formatos e idiomas, e não apenas rankings tradicionais de palavras-chave. Organizações que compreendem as capacidades do MUM podem otimizar melhor sua estratégia de conteúdo para garantir visibilidade neste novo cenário de busca.
Apesar de o MUM representar um grande avanço, ele também traz novos desafios e limitações que as organizações precisam gerenciar. Taxas de clique menores são uma preocupação importante para editores e criadores de conteúdo, já que os usuários podem consumir informações completas diretamente nos resultados, sem acessar os sites. Isso torna métricas tradicionais de tráfego menos confiáveis como indicadores de sucesso de conteúdo. Exigências técnicas de SEO aumentadas significam que, para serem devidamente entendidos pelo MUM, os conteúdos precisam ser bem estruturados com marcação de schema, HTML semântico e relações claras entre entidades. Conteúdo sem essa base técnica pode não ser corretamente indexado ou compreendido pelo processamento multimodal do MUM. Saturação da SERP cria desafios para a visibilidade, já que mais formatos de conteúdo competem por atenção em uma única página. Mesmo conteúdos fortes podem receber poucos ou nenhum clique se os usuários encontrarem informações suficientes na própria SERP. Potencial para resultados enganosos existe quando o MUM exibe informações de múltiplas fontes que podem se contradizer ou quando o contexto se perde na síntese. Dependência de dados estruturados significa que conteúdos não estruturados ou mal formatados podem não ser corretamente entendidos ou exibidos pelo MUM. Desafios de nuances linguísticas e culturais podem surgir quando o MUM transfere conhecimento entre idiomas, potencialmente perdendo contexto cultural ou variações regionais de significado. Exigências computacionais para operar o MUM em escala são elevadas, embora o Google invista em melhorias de eficiência para reduzir a pegada de carbono. Preocupações com viés e justiça exigem atenção contínua para garantir que o MUM não perpetue vieses presentes nos dados de treinamento ou prejudique certas perspectivas ou comunidades.
O surgimento do MUM exige mudanças fundamentais na abordagem de SEO e estratégia de conteúdo das organizações. Otimização tradicional focada em palavras-chave torna-se menos eficaz quando o MUM entende intenção e contexto além da correspondência exata. Estratégia de conteúdo baseada em tópicos ganha mais importância que a baseada em palavras-chave, exigindo que as organizações criem clusters de conteúdo abrangentes que abordem tópicos sob múltiplos ângulos. Criação de conteúdo multimídia deixa de ser opcional—é preciso investir em imagens, vídeos e conteúdo interativo de alta qualidade que complemente o conteúdo textual. Implementação de dados estruturados torna-se crítica, pois a marcação schema ajuda o MUM a entender estrutura e relações do conteúdo. Construção de entidades e otimização semântica auxiliam na autoridade temática e melhoram o entendimento das relações pelo MUM. Estratégia de conteúdo multilíngue ganha importância com as capacidades de transferência entre idiomas do MUM, permitindo descoberta em vários mercados linguísticos. Mapeamento de intenção do usuário torna-se mais sofisticado, exigindo compreensão não só da intenção principal, mas também de perguntas relacionadas e subtemas que o usuário pode explorar. Atualidade e precisão do conteúdo aumentam de importância já que o MUM sintetiza informações de múltiplas fontes—conteúdo desatualizado ou impreciso pode ser despriorizado. Otimização multiplataforma vai além da Busca Google para incluir como o conteúdo aparece em sistemas de IA como Google AI Overviews, Perplexity e outras interfaces de busca com IA. Sinais E-E-A-T (Experiência, Especialização, Autoridade, Confiabilidade) tornam-se ainda mais relevantes, pois o MUM prioriza conteúdos de fontes autoritativas. Organizações que alinham suas estratégias às capacidades do MUM—focando em conteúdo abrangente, multimodal, bem estruturado e que demonstre expertise e autoridade—manterão visibilidade neste cenário de busca em evolução.
O MUM não é um destino final, mas um marco na evolução da busca movida por IA. O Google já indicou que o MUM continuará expandindo suas capacidades, com processamento de vídeo e áudio cada vez mais sofisticados. A empresa pesquisa ativamente formas de reduzir a pegada computacional do MUM mantendo ou melhorando seu desempenho, abordando preocupações de sustentabilidade em modelos de IA em larga escala. A integração do MUM com outras tecnologias do Google sugere desenvolvimentos futuros em que o entendimento do MUM alimenta não apenas a busca, mas também o Google Assistente, Google Lens e outros produtos. Pressões competitivas de outros sistemas de IA como o ChatGPT da OpenAI, Claude da Anthropic e o mecanismo de busca de IA Perplexity provavelmente impulsionarão a evolução contínua do MUM para manter a vantagem competitiva do Google. Escrutínio regulatório sobre sistemas de IA pode influenciar o desenvolvimento do MUM, especialmente em relação a viés, justiça e transparência. A adaptação do comportamento do usuário moldará a evolução do MUM—a medida que os usuários se acostumam com experiências de busca mais ricas e interativas, as expectativas por qualidade e abrangência aumentam. A ascensão da IA generativa pode tornar mais proeminente a capacidade do MUM de sintetizar e gerar informação, potencialmente criando conteúdo original além de apenas recuperar e organizar o já existente. A IA multimodal tornando-se padrão sugere que a abordagem do MUM de processar múltiplos formatos simultaneamente será regra em sistemas de IA. Privacidade e considerações sobre dados influenciarão como o MUM usa dados do usuário e sinais comportamentais para personalizar e aprimorar resultados. As organizações devem se preparar para essa evolução contínua adotando estratégias de conteúdo flexíveis e adaptáveis, priorizando qualidade, abrangência e excelência técnica, em vez de táticas específicas que podem se tornar obsoletas à medida que o MUM evolui. O princípio fundamental—criar conteúdo que realmente atenda à intenção do usuário em múltiplos formatos e idiomas—permanece relevante independentemente de como as capacidades específicas do MUM se desenvolvam.
Enquanto o BERT (2019) focava em entender a linguagem natural em consultas baseadas em texto, o MUM representa uma evolução significativa. O MUM é construído sobre o framework T5 de text-to-text e é 1.000 vezes mais poderoso que o BERT. Diferente do processamento exclusivo de texto do BERT, o MUM é multimodal—processa texto, imagens, vídeo e áudio simultaneamente. Além disso, o MUM oferece suporte nativo a mais de 75 idiomas, enquanto o BERT tinha suporte multilíngue limitado em seu lançamento. O MUM pode tanto compreender quanto gerar linguagem, tornando-o capaz de lidar com consultas complexas e de múltiplas etapas que o BERT não conseguia abordar de forma eficaz.
Multimodal refere-se à capacidade do MUM de processar e compreender informações provenientes de múltiplos tipos de formatos de entrada simultaneamente. Em vez de analisar texto separadamente de imagens ou vídeos, o MUM processa todos esses formatos juntos de forma unificada. Isso significa que ao pesquisar algo como 'botas de caminhada para o Monte Fuji', o MUM pode entender sua consulta textual, analisar imagens das botas, assistir a avaliações em vídeo e extrair descrições em áudio—tudo ao mesmo tempo. Essa abordagem integrada permite que o MUM forneça respostas mais ricas e contextuais, considerando informações de todos esses diferentes tipos de mídia.
O MUM é treinado em mais de 75 idiomas, o que representa um grande avanço na acessibilidade global da pesquisa. Essa capacidade multilíngue permite ao MUM transferir conhecimento entre idiomas—se informações úteis sobre um tópico existirem em japonês, o MUM pode compreendê-las e apresentar resultados relevantes para usuários que falam inglês. Isso quebra barreiras linguísticas que anteriormente limitavam os resultados de pesquisa ao idioma nativo do usuário. Para marcas e criadores de conteúdo, isso significa que seu conteúdo pode ter visibilidade em vários mercados linguísticos, e usuários de todo o mundo podem acessar informações independentemente do idioma original da publicação.
T5 (Text-to-Text Transfer Transformer) é o modelo baseado em transformadores do Google que serve de base para o MUM. O framework T5 trata todas as tarefas de PLN como problemas de texto para texto, o que significa que converte entradas e saídas em formato de texto para processamento unificado. O MUM amplia as capacidades do T5 ao incorporar processamento multimodal (lidando com imagens, vídeo e áudio) e escalando para aproximadamente 110 bilhões de parâmetros. Essa base permite ao MUM tanto compreender quanto gerar linguagem, mantendo a eficiência e flexibilidade que tornaram o T5 bem-sucedido.
O MUM muda fundamentalmente como o conteúdo é descoberto e exibido nos resultados de pesquisa. Em vez das tradicionais listas de links azuis, o MUM cria SERPs enriquecidas com múltiplos formatos de conteúdo—imagens, vídeos, trechos de texto e elementos interativos—tudo em uma só página. Isso significa que as marcas precisam otimizar em vários formatos, não apenas texto. Conteúdo que antes exigia que os usuários navegassem por várias páginas agora pode ser mostrado diretamente nos resultados de pesquisa. No entanto, isso também pode resultar em taxas de cliques menores para alguns conteúdos, já que os usuários podem consumir informações dentro da própria SERP. As marcas devem, portanto, focar na visibilidade dentro dos resultados de pesquisa e garantir que seus conteúdos estejam estruturados com marcação de schema para serem devidamente entendidos pelo MUM.
O MUM é fundamental para plataformas de monitoramento de IA porque representa como os sistemas modernos de IA entendem e recuperam informações. À medida que o MUM se torna mais presente na Busca Google e influencia outros sistemas de IA, monitorar onde marcas e domínios aparecem em resultados movidos pelo MUM torna-se essencial. O AmICited rastreia como as marcas são citadas e aparecem em sistemas de IA, incluindo a busca aprimorada pelo MUM do Google. Compreender as capacidades multimodais e multilíngues do MUM ajuda as organizações a otimizarem sua presença em diferentes formatos de conteúdo e idiomas, garantindo visibilidade quando sistemas de IA como o MUM recuperam e exibem suas informações para os usuários.
Sim, o MUM pode processar imagens e vídeos com um entendimento sofisticado. Quando você faz upload de uma imagem ou inclui um vídeo em uma consulta, o MUM não apenas reconhece objetos—ele extrai contexto, significado e relações. Por exemplo, se você mostrar ao MUM uma foto de botas de caminhada e perguntar 'posso usar estas para o Monte Fuji?', o MUM entende as características da bota a partir da imagem e conecta esse entendimento à sua pergunta, fornecendo uma resposta contextualizada. Essa compreensão multimodal é um dos recursos mais poderosos do MUM, permitindo responder questões que exigem entendimento visual combinado com conhecimento textual.
Comece a rastrear como os chatbots de IA mencionam a sua marca no ChatGPT, Perplexity e outras plataformas. Obtenha insights acionáveis para melhorar a sua presença de IA.
Saiba mais sobre o Modelo Unificado Multitarefa (MUM) do Google e seu impacto nos resultados de busca por IA. Entenda como o MUM processa consultas complexas em...
Discussão comunitária explicando o Google MUM e seu impacto na busca por IA. Especialistas compartilham como esse modelo de IA multimodal afeta a otimização de ...

Saiba como sistemas de busca de IA multimodal processam texto, imagens, áudio e vídeo juntos para entregar resultados mais precisos e relevantes do que abordage...