
Arquitetura Transformer
A Arquitetura Transformer é um design de rede neural que utiliza mecanismos de autoatenção para processar dados sequenciais em paralelo. Ela impulsiona o ChatGP...
20 min de leitura
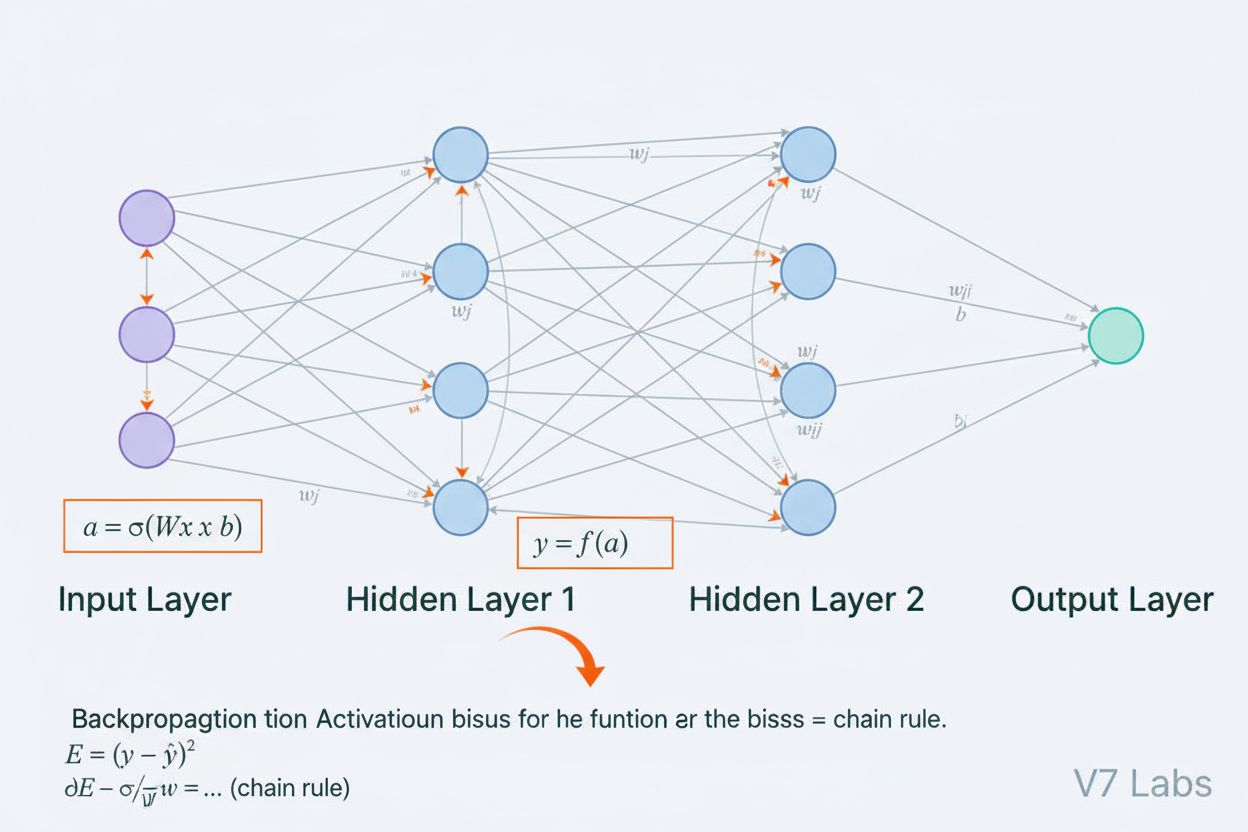
Uma rede neural é um sistema computacional inspirado em redes neurais biológicas, composto por neurônios artificiais interconectados organizados em camadas, capaz de aprender padrões a partir de dados por meio de um processo chamado retropropagação. Esses sistemas formam a base da inteligência artificial e do deep learning modernos, impulsionando aplicações desde o processamento de linguagem natural até a visão computacional.
Uma rede neural é um sistema computacional inspirado em redes neurais biológicas, composto por neurônios artificiais interconectados organizados em camadas, capaz de aprender padrões a partir de dados por meio de um processo chamado retropropagação. Esses sistemas formam a base da inteligência artificial e do deep learning modernos, impulsionando aplicações desde o processamento de linguagem natural até a visão computacional.
Uma rede neural é um sistema computacional fundamentalmente inspirado na estrutura e funcionamento das redes neurais biológicas encontradas em cérebros de animais. Ela consiste em neurônios artificiais interconectados, organizados em camadas — tipicamente uma camada de entrada, uma ou mais camadas ocultas e uma camada de saída — que trabalham em conjunto para processar dados, reconhecer padrões e fazer previsões. Cada neurônio recebe entradas, aplica transformações matemáticas por meio de pesos e vieses e passa o resultado por uma função de ativação para produzir uma saída. A característica definidora das redes neurais é sua capacidade de aprender a partir de dados por meio de um processo iterativo chamado retropropagação, onde a rede ajusta seus parâmetros internos para minimizar erros de previsão. Essa capacidade de aprendizado, combinada à habilidade de modelar relações complexas e não-lineares, tornou as redes neurais a tecnologia fundamental que impulsiona sistemas modernos de inteligência artificial, desde grandes modelos de linguagem até aplicações de visão computacional.
O conceito de redes neurais artificiais surgiu a partir das primeiras tentativas de modelar matematicamente como neurônios biológicos se comunicam e processam informações. Em 1943, Warren McCulloch e Walter Pitts propuseram o primeiro modelo matemático de um neurônio, demonstrando que unidades computacionais simples poderiam realizar operações lógicas. Essa base teórica foi seguida pela introdução do perceptron por Frank Rosenblatt em 1958, um algoritmo projetado para reconhecimento de padrões que se tornou o ancestral histórico das arquiteturas sofisticadas de redes neurais atuais. O perceptron era essencialmente um modelo linear com saída restrita, capaz de aprender fronteiras de decisão simples. No entanto, o campo enfrentou retrocessos significativos nos anos 1970, quando pesquisadores descobriram que perceptrons de camada única não conseguiam resolver problemas não-lineares como a função XOR, levando ao chamado “inverno da IA”. O avanço veio nos anos 1980 com o redescobrimento e aprimoramento da retropropagação, um algoritmo que permitiu o treinamento de redes com múltiplas camadas. Esse ressurgimento acelerou dramaticamente na década de 2010 com a disponibilidade de grandes volumes de dados, GPUs poderosas e técnicas de treinamento refinadas, levando à revolução do deep learning que transformou a inteligência artificial.
A arquitetura de uma rede neural é composta por diversos componentes essenciais que trabalham em conjunto. A camada de entrada recebe características brutas dos dados provenientes de fontes externas, sendo que cada neurônio dessa camada corresponde a uma característica. As camadas ocultas realizam o processamento computacional intenso, transformando as entradas em representações cada vez mais abstratas por meio de combinações ponderadas e funções de ativação não-lineares. O número e o tamanho das camadas ocultas determinam a capacidade da rede de aprender padrões complexos — redes mais profundas conseguem capturar relações mais sofisticadas, mas exigem mais dados e recursos computacionais. A camada de saída gera as previsões finais, com sua estrutura dependendo da tarefa: um neurônio para regressão, múltiplos neurônios para classificação multiclasse ou arquiteturas especializadas para outras aplicações. Cada conexão entre neurônios carrega um peso que determina o grau de influência, enquanto cada neurônio possui um viés que desloca seu limiar de ativação. Esses pesos e vieses são os parâmetros aprendíveis que a rede ajusta durante o treinamento. A função de ativação aplicada em cada neurônio introduz a não-linearidade crucial, permitindo que a rede aprenda fronteiras de decisão e padrões que modelos lineares não conseguem capturar.
As redes neurais aprendem por meio de um processo iterativo em duas fases. Durante a propagação direta, os dados de entrada fluem pela rede, da camada de entrada até a camada de saída. Em cada neurônio, calcula-se a soma ponderada das entradas mais o viés (z = w₁x₁ + w₂x₂ + … + wₙxₙ + b), que é então passada por uma função de ativação para produzir a saída do neurônio. Esse processo se repete em cada camada oculta até chegar à camada de saída, que gera a previsão da rede. A rede então calcula o erro entre sua previsão e o rótulo verdadeiro usando uma função de perda, que quantifica o quanto a previsão está distante da resposta correta. Na retropropagação, esse erro é propagado de volta pela rede utilizando a regra da cadeia do cálculo. Em cada neurônio, o algoritmo calcula o gradiente da perda em relação a cada peso e viés, determinando quanto cada parâmetro contribuiu para o erro geral. Esses gradientes guiam as atualizações dos parâmetros: pesos e vieses são ajustados na direção oposta ao gradiente, escalados por uma taxa de aprendizado que controla o tamanho dos passos. Esse processo se repete por muitas iterações sobre o conjunto de treinamento, reduzindo gradualmente a perda e melhorando as previsões da rede. A combinação de propagação direta, cálculo de perda, retropropagação e atualização de parâmetros forma o ciclo completo de treinamento que permite às redes neurais aprenderem a partir de dados.
| Tipo de Arquitetura | Principal Caso de Uso | Característica-Chave | Forças | Limitações |
|---|---|---|---|---|
| Redes Feedforward | Classificação, regressão em dados estruturados | Informação flui apenas em uma direção | Treinamento simples e rápido, interpretável | Não lida bem com dados sequenciais ou espaciais |
| Redes Neurais Convolucionais (CNNs) | Reconhecimento de imagens, visão computacional | Camadas convolucionais detectam padrões espaciais | Excelente para capturar padrões locais, eficiente em parâmetros | Requer grandes conjuntos de imagens rotuladas |
| Redes Neurais Recorrentes (RNNs) | Dados sequenciais, séries temporais, PLN | Estado oculto mantém memória entre etapas | Pode processar sequências de tamanho variável | Sofre com gradientes que somem ou explodem |
| Long Short-Term Memory (LSTM) | Dependências de longo prazo em sequências | Células de memória com portas de entrada/esquecimento/saída | Lida bem com dependências de longo prazo | Mais complexa, treinamento mais lento que RNN |
| Redes Transformer | Processamento de linguagem natural, grandes modelos de linguagem | Mecanismo de atenção multi-cabeças, processamento paralelo | Altamente paralelizável, captura dependências longas | Requer recursos computacionais massivos |
| Generative Adversarial Networks (GANs) | Geração de imagens, criação de dados sintéticos | Redes geradora e discriminadora competem | Pode gerar dados sintéticos realistas | Difícil de treinar, problemas de colapso de modo |
A introdução de funções de ativação representa uma das inovações mais importantes no design de redes neurais. Sem funções de ativação, uma rede neural seria matematicamente equivalente a uma única transformação linear, independentemente do número de camadas. Isso ocorre porque a composição de funções lineares é ela própria linear, limitando severamente a capacidade da rede de aprender padrões complexos. As funções de ativação resolvem esse problema ao introduzir não-linearidade em cada neurônio. A função ReLU (Unidade Linear Retificada), definida como f(x) = max(0, x), tornou-se a escolha mais popular no deep learning moderno devido à sua eficiência computacional e eficácia no treinamento de redes profundas. A função sigmoid, f(x) = 1/(1 + e^(-x)), comprime as saídas para um intervalo entre 0 e 1, sendo útil para tarefas de classificação binária. A função tanh, f(x) = (e^x - e^(-x))/(e^x + e^(-x)), produz saídas entre -1 e 1 e frequentemente apresenta melhor desempenho que a sigmoid em camadas ocultas. A escolha da função de ativação impacta significativamente a dinâmica de aprendizado da rede, a velocidade de convergência e o desempenho final. Arquiteturas modernas normalmente usam ReLU nas camadas ocultas pela eficiência e sigmoid ou softmax nas camadas de saída para estimativa de probabilidades. A não-linearidade introduzida pelas funções de ativação permite que as redes neurais aproximem qualquer função contínua, uma propriedade conhecida como teorema da aproximação universal, o que explica sua notável versatilidade em diversas aplicações.
O mercado de redes neurais experimentou um crescimento explosivo, refletindo o papel central da tecnologia na inteligência artificial moderna. Segundo pesquisas recentes, o mercado global de softwares de redes neurais foi avaliado em cerca de US$ 34,76 bilhões em 2025 e projeta-se que atinja US$ 139,86 bilhões até 2030, representando uma taxa composta de crescimento anual (CAGR) de 32,10%. O mercado mais amplo de redes neurais mostra expansão ainda mais dramática, com estimativas sugerindo crescimento de US$ 34,05 bilhões em 2024 para US$ 385,29 bilhões até 2033, a um CAGR de 31,4%. Esse crescimento explosivo é impulsionado por diversos fatores: a crescente disponibilidade de grandes volumes de dados, o desenvolvimento de algoritmos de treinamento mais eficientes, a proliferação de GPUs e hardwares especializados em IA, além da adoção generalizada de redes neurais em diversos setores. Segundo o Relatório Stanford AI Index de 2025, 78% das organizações relataram o uso de IA em 2024, frente a 55% no ano anterior, sendo as redes neurais a espinha dorsal da maioria das implementações corporativas de IA. A adoção abrange saúde, finanças, manufatura, varejo e praticamente todos os setores, à medida que as organizações reconhecem a vantagem competitiva proporcionada por sistemas baseados em redes neurais para reconhecimento de padrões, predição e tomada de decisão.
As redes neurais impulsionam os sistemas de IA mais avançados atualmente, incluindo ChatGPT, Perplexity, Google AI Overviews e Claude. Esses grandes modelos de linguagem são construídos sobre arquiteturas de redes neurais baseadas em transformers, que utilizam mecanismos de atenção para processar e gerar linguagem humana com notável sofisticação. A arquitetura transformer, introduzida em 2017, revolucionou o processamento de linguagem natural ao permitir o processamento paralelo de sequências inteiras, em vez do processamento sequencial, melhorando dramaticamente a eficiência de treinamento e o desempenho dos modelos. No contexto do monitoramento de marca e rastreamento de citações em IA, compreender redes neurais é crucial porque esses sistemas usam redes neurais para entender contexto, recuperar informações relevantes e gerar respostas que podem referenciar ou citar sua marca, domínio ou conteúdo. O AmICited utiliza o conhecimento de como redes neurais processam e recuperam informações para monitorar onde sua marca aparece em respostas geradas por IA em múltiplas plataformas. À medida que as redes neurais continuam a aprimorar sua capacidade de compreender significado semântico e recuperar informações relevantes, a importância de monitorar a presença da sua marca em respostas de IA torna-se cada vez mais crítica para manter a visibilidade e gerenciar a reputação online na era da busca e geração de conteúdo impulsionadas por IA.
Treinar redes neurais de forma eficaz apresenta diversos desafios importantes que pesquisadores e profissionais precisam enfrentar. O overfitting ocorre quando a rede aprende excessivamente bem os dados de treinamento, incluindo ruídos e peculiaridades, resultando em baixo desempenho em dados novos e não vistos. Isso é especialmente problemático em redes profundas com muitos parâmetros em relação ao tamanho dos dados de treinamento. O underfitting representa o problema oposto, quando a rede não possui capacidade ou treinamento suficiente para captar os padrões subjacentes dos dados. O problema do gradiente que some ocorre em redes muito profundas, quando os gradientes tornam-se exponencialmente pequenos ao serem propagados para trás, fazendo com que os pesos das camadas iniciais sejam ajustados muito lentamente ou nem sejam ajustados. O problema do gradiente explosivo é o oposto, com gradientes que se tornam muito grandes, causando instabilidade no treinamento. Soluções modernas incluem a normalização em lote (batch normalization), que normaliza as entradas das camadas para manter o fluxo estável dos gradientes; conexões residuais (skip connections), que permitem o fluxo direto dos gradientes por várias camadas; e clipping de gradientes, que limita a magnitude dos gradientes. Técnicas de regularização como L1 e L2 adicionam penalidades para grandes pesos, incentivando modelos mais simples e com melhor generalização. Dropout desativa aleatoriamente neurônios durante o treinamento, prevenindo coadaptações e melhorando a generalização. A escolha do otimizador (como Adam, SGD ou RMSprop) e da taxa de aprendizado impacta significativamente a eficiência do treinamento e o desempenho final do modelo. Profissionais devem equilibrar cuidadosamente a complexidade do modelo, o tamanho do conjunto de dados, a força da regularização e os parâmetros de otimização para obter redes que aprendam de forma eficaz sem overfitting.
A evolução das arquiteturas de redes neurais seguiu uma trajetória clara em direção a mecanismos cada vez mais sofisticados de processamento de informação. Redes feedforward iniciais eram limitadas a entradas de tamanho fixo e não conseguiam capturar dependências temporais ou sequenciais. Redes neurais recorrentes (RNNs) introduziram laços de realimentação que permitiram a persistência de informações ao longo do tempo, possibilitando o processamento de sequências de tamanho variável. No entanto, as RNNs sofriam com problemas no fluxo do gradiente e eram inerentemente sequenciais, dificultando a paralelização em hardwares modernos. Redes LSTM resolveram parte desses problemas com células de memória e mecanismos de portas, mas continuavam fundamentalmente sequenciais. O avanço veio com as redes transformer, que substituíram completamente a recorrência por mecanismos de atenção. O mecanismo de atenção permite que a rede foque dinamicamente em diferentes partes da entrada, computando combinações ponderadas de todos os elementos em paralelo. Isso permite que transformers capturem dependências de longo alcance de forma eficiente e totalmente paralelizável em clusters de GPU. A arquitetura transformer, aliada à escala massiva (modelos de linguagem modernos possuem bilhões a trilhões de parâmetros), mostrou-se extremamente eficaz para PLN, visão computacional e tarefas multimodais. O sucesso dos transformers levou à sua adoção como arquitetura padrão para sistemas de IA de ponta, incluindo todos os grandes modelos de linguagem. Essa evolução demonstra como inovações arquiteturais, combinadas a recursos computacionais crescentes e conjuntos de dados maiores, continuam a expandir as fronteiras do que redes neurais podem alcançar.
O campo das redes neurais continua evoluindo rapidamente, com várias direções promissoras em destaque. Computação neuromórfica busca criar hardwares que imitem mais de perto as redes neurais biológicas, potencialmente alcançando maior eficiência energética e poder computacional. Pesquisas em few-shot e zero-shot learning se concentram em permitir que redes neurais aprendam a partir de poucos exemplos, aproximando-se mais da capacidade humana de aprendizado. Explicabilidade e interpretabilidade tornaram-se cada vez mais importantes, com pesquisadores desenvolvendo técnicas para entender e visualizar o que as redes neurais aprendem, fundamental para aplicações críticas em saúde, finanças e justiça criminal. Aprendizado federado permite o treinamento de redes neurais em dados distribuídos, sem centralizar informações sensíveis, atendendo a preocupações de privacidade. Redes neurais quânticas representam uma fronteira onde princípios da computação quântica são combinados a arquiteturas de redes neurais, oferecendo potencial para ganhos exponenciais em certos problemas. Redes neurais multimodais, que integram texto, imagens, áudio e vídeo de forma unificada, estão cada vez mais sofisticadas, permitindo sistemas de IA mais abrangentes. Redes neurais energeticamente eficientes estão sendo desenvolvidas para reduzir o custo computacional e ambiental do treinamento e implantação de grandes modelos. À medida que as redes neurais continuam avançando, sua integração em sistemas de monitoramento de IA como o AmICited torna-se cada vez mais importante para organizações que desejam entender e gerenciar a presença de suas marcas em conteúdos e respostas gerados por IA em plataformas como ChatGPT, Perplexity, Google AI Overviews e Claude.
As redes neurais são inspiradas na estrutura e função dos neurônios biológicos do cérebro humano. No cérebro, os neurônios se comunicam por meio de sinais elétricos através das sinapses, que podem ser fortalecidas ou enfraquecidas com base na experiência. Redes neurais artificiais imitam esse comportamento usando modelos matemáticos de neurônios conectados por ligações com pesos, permitindo que o sistema aprenda e se adapte aos dados de maneira análoga ao modo como cérebros biológicos processam informações e formam memórias.
A retropropagação é o principal algoritmo que permite o aprendizado das redes neurais. Durante a propagação direta, os dados fluem pelas camadas da rede gerando previsões. A rede então calcula o erro entre as saídas previstas e reais usando uma função de perda. Na passagem inversa, esse erro é propagado de volta pela rede utilizando a regra da cadeia do cálculo, calculando quanto cada peso e viés contribuiu para o erro. Os pesos são então ajustados na direção que minimiza o erro, normalmente utilizando otimização por descida do gradiente.
As principais arquiteturas de redes neurais incluem redes feedforward (dados fluem em uma única direção), redes neurais convolucionais ou CNNs (otimizadas para processamento de imagens), redes neurais recorrentes ou RNNs (projetadas para dados sequenciais), redes LSTM (RNNs aprimoradas com células de memória) e redes transformer (usam mecanismos de atenção para processamento paralelo). Cada arquitetura é especializada para diferentes tipos de dados e tarefas, desde reconhecimento de imagens até processamento de linguagem natural.
Sistemas modernos de IA como ChatGPT, Perplexity e Claude são construídos sobre redes neurais baseadas em transformers, que usam mecanismos de atenção para processar linguagem de forma eficiente. Essas redes neurais permitem que esses sistemas compreendam contexto, gerem textos coerentes e realizem tarefas complexas de raciocínio. A capacidade das redes neurais de aprender a partir de grandes volumes de dados e capturar padrões intrincados na linguagem as torna essenciais para construir IAs conversacionais capazes de compreender e responder a consultas humanas com notável precisão.
Os pesos em redes neurais controlam a força das conexões entre os neurônios, determinando quanto cada entrada influencia a saída. Os vieses são parâmetros adicionais que deslocam o limiar de ativação dos neurônios, permitindo que eles sejam ativados mesmo quando as entradas são fracas. Juntos, pesos e vieses formam os parâmetros ajustáveis da rede que são modificados durante o treinamento para minimizar erros de previsão e permitir que a rede aprenda padrões complexos a partir dos dados.
As funções de ativação introduzem não-linearidade nas redes neurais, permitindo que elas aprendam relações complexas e não-lineares nos dados. Sem funções de ativação, empilhar várias camadas ainda resultaria em transformações lineares, limitando severamente a capacidade de aprendizado da rede. Funções de ativação comuns incluem ReLU (Unidade Linear Retificada), sigmoid e tanh, cada uma introduzindo diferentes tipos de não-linearidade que ajudam a rede a capturar padrões intricados e fazer previsões mais sofisticadas.
As camadas ocultas são camadas intermediárias entre as camadas de entrada e saída, onde a rede realiza a maior parte do processamento computacional. Elas extraem e transformam características dos dados brutos em representações cada vez mais abstratas. A profundidade e a largura das camadas ocultas determinam a capacidade da rede de aprender padrões complexos. Redes mais profundas, com mais camadas ocultas, conseguem capturar relações mais sofisticadas nos dados, mas exigem mais recursos computacionais e treinamento cuidadoso para evitar overfitting.
Comece a rastrear como os chatbots de IA mencionam a sua marca no ChatGPT, Perplexity e outras plataformas. Obtenha insights acionáveis para melhorar a sua presença de IA.
A Arquitetura Transformer é um design de rede neural que utiliza mecanismos de autoatenção para processar dados sequenciais em paralelo. Ela impulsiona o ChatGP...

Descubra o que são as Redes de Sindicação de Conteúdo com IA, como funcionam e por que são essenciais para a distribuição moderna de conteúdo. Veja como a otimi...

Saiba o que são embeddings, como funcionam e por que são essenciais para sistemas de IA. Descubra como o texto se transforma em vetores numéricos que capturam s...