
Ghidul complet pentru blocarea (sau permiterea) crawlerelor AI
Află cum să blochezi sau să permiți crawleri AI precum GPTBot și ClaudeBot folosind robots.txt, blocare la nivel de server și metode avansate de protecție. Ghid...
7 min citire
Află cum să implementezi blocarea selectivă a crawlerilor AI pentru a-ți proteja conținutul de roboții de instruire, menținând totodată vizibilitatea în rezultatele căutărilor AI. Strategii tehnice pentru editori.
Editorii de astăzi se confruntă cu o alegere imposibilă: să blocheze toți crawlerii AI și să piardă traficul valoros din motoarele de căutare, sau să îi permită pe toți și să vadă cum conținutul lor alimentează seturile de date pentru instruire fără nicio compensație. Ascensiunea AI generativ a creat un ecosistem de crawlere bifurcat, unde aceleași reguli robots.txt se aplică nediferențiat atât motoarelor de căutare care generează venituri, cât și crawlerelor de instruire care extrag valoare. Acest paradox i-a forțat pe editorii progresiști să dezvolte strategii de control selectiv al crawlerelor, care fac diferența între tipurile de roboți AI în funcție de impactul lor real asupra indicatorilor de afaceri.
Peisajul crawlerelor AI se împarte în două categorii distincte, cu scopuri și implicații de business foarte diferite. Crawlerii de instruire—operați de companii precum OpenAI, Anthropic și Google—sunt concepuți să absoarbă cantități masive de date text pentru a construi și îmbunătăți modelele lingvistice de mari dimensiuni, pe când crawlerii de căutare indexează conținut pentru descoperire și recuperare. Roboții de instruire reprezintă aproximativ 80% din activitatea totală a roboților AI, dar generează venituri directe zero pentru editori, în timp ce crawlerii de căutare precum Googlebot și Bingbot aduc anual milioane de vizite și afișări de reclame. Diferența contează, deoarece un singur crawler de instruire poate consuma lățime de bandă echivalentă cu a mii de utilizatori umani, în timp ce crawlerii de căutare sunt optimizați pentru eficiență și, de regulă, respectă limitele de rată.
| Nume bot | Operator | Scop principal | Potențial trafic |
|---|---|---|---|
| GPTBot | OpenAI | Instruire modele | Niciunul (extragere date) |
| Claude Web Crawler | Anthropic | Instruire modele | Niciunul (extragere date) |
| Googlebot | Indexare căutare | 243,8M vizite (aprilie 2025) | |
| Bingbot | Microsoft | Indexare căutare | 45,2M vizite (aprilie 2025) |
| Perplexity Bot | Perplexity AI | Căutare + instruire | 12,1M vizite (aprilie 2025) |
Datele sunt clare: doar crawlerul ChatGPT a trimis 243,8 milioane de vizite către editori în aprilie 2025, dar aceste vizite au generat zero clickuri, zero afișări de reclame și zero venituri. Între timp, traficul Googlebot s-a convertit în implicare reală a utilizatorilor și oportunități de monetizare. Înțelegerea acestei diferențe este primul pas spre implementarea unei strategii de blocare selectivă care să protejeze conținutul, păstrând totodată vizibilitatea în căutări.
Blocarea generală a tuturor crawlerelor AI este auto-distructivă din punct de vedere economic pentru majoritatea editorilor. În timp ce crawlerii de instruire extrag valoare fără compensație, crawlerii de căutare rămân unele dintre cele mai sigure surse de trafic într-un peisaj digital tot mai fragmentat. Argumentul financiar pentru blocarea selectivă se bazează pe câțiva factori-cheie:
Editorii care implementează strategii de blocare selectivă raportează menținerea sau chiar creșterea traficului din căutări, reducând totodată extragerea neautorizată a conținutului cu până la 85%. Această abordare strategică recunoaște că nu toți crawlerii AI sunt egali, iar o politică nuanțată servește mult mai bine intereselor de business decât o abordare de tip “pământ pârjolit”.
Fișierul robots.txt rămâne principalul mecanism de comunicare a permisiunilor pentru crawlere și este surprinzător de eficient când este configurat corect pentru a diferenția tipurile de roboți. Acest fișier text simplu, plasat în directorul rădăcină al site-ului, folosește directive user-agent pentru a specifica ce crawlere pot accesa ce conținut. Pentru controlul selectiv al crawlerelor AI, poți permite motoarele de căutare și bloca roboții de instruire cu precizie chirurgicală.
Iată un exemplu practic care blochează crawlerii de instruire și permite motoarele de căutare:
# Blochează GPTBot de la OpenAI
User-agent: GPTBot
Disallow: /
# Blochează crawlerul Claude de la Anthropic
User-agent: Claude-Web
Disallow: /
# Blochează alți crawleri de instruire
User-agent: CCBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
# Permite motoarele de căutare
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
User-agent: *
Disallow: /admin/
Disallow: /private/
Această abordare oferă instrucțiuni clare crawlerelor “bine crescute”, menținând totodată descoperibilitatea site-ului în rezultate de căutare. Totuși, robots.txt este fundamental un standard voluntar—se bazează pe faptul că operatorii crawlerelor respectă directivele tale. Pentru editorii preocupați de conformitate, sunt necesare și straturi suplimentare de aplicare.
Robots.txt nu poate garanta conformitatea, deoarece aproximativ 13% dintre crawlerii AI ignoră complet directivele, fie din neglijență, fie intenționat. Aplicarea la nivel de server, folosind serverul web sau aplicația, oferă un “backstop” tehnic ce împiedică accesul neautorizat indiferent de comportamentul crawlerului. Această abordare blochează cererile la nivel HTTP, înainte ca acestea să consume resurse sau lățime de bandă.
Implementarea blocării la nivel de server cu Nginx este simplă și foarte eficientă:
# În blocul server Nginx
location / {
# Blochează crawlerii de instruire la nivel de server
if ($http_user_agent ~* (GPTBot|Claude-Web|CCBot|anthropic-ai|Omgili)) {
return 403;
}
# Blochează după intervale IP dacă este necesar (pentru crawleri care își falsifică user-agent-ul)
if ($remote_addr ~* "^(192\.0\.2\.|198\.51\.100\.)") {
return 403;
}
# Continuă procesarea normală a cererii
proxy_pass http://backend;
}
Această configurație returnează un răspuns 403 Forbidden crawlerilor blocați, consumând resurse minime și comunicând clar că accesul este refuzat. Împreună cu robots.txt, aplicarea la nivel de server creează o apărare în două straturi, capturând atât crawlerii conformi, cât și pe cei neconformi. Rata de ocolire de 13% scade aproape de zero când regulile serverului sunt implementate corect.
Rețelele de livrare a conținutului (CDN) și firewall-urile de aplicație web adaugă un strat suplimentar de protecție, acționând înainte ca cererile să ajungă la serverele tale de origine. Servicii precum Cloudflare, Akamai și AWS WAF permit crearea de reguli care blochează anumiți user-agents sau intervale IP la margine, împiedicând crawlerii rău intenționați sau nedoriți să îți consume resursele. Aceste servicii mențin liste actualizate cu intervale IP și user-agents de crawleri de instruire cunoscuți, blocându-i automat fără configurare manuală.
Controlul la nivel de CDN are mai multe avantaje față de blocarea la nivel de server: reduce sarcina pe serverele de origine, permite blocarea geografică și oferă analize în timp real despre cererile blocate. Mulți furnizori CDN oferă acum reguli specifice pentru blocarea AI ca funcționalitate standard, recunoscând preocuparea largă a editorilor privind extragerea neautorizată de date pentru instruire. Pentru editorii care folosesc Cloudflare, activarea opțiunii “Block AI Crawlers” în setările de securitate oferă protecție cu un singur click împotriva principalilor crawleri de instruire, păstrând accesul motoarelor de căutare.
Blocarea selectivă eficientă necesită o abordare sistematică de clasificare a crawlerelor în funcție de impactul lor de business și gradul de încredere. În loc să tratezi toți crawlerii AI la fel, editorii ar trebui să implementeze un cadru în trei niveluri, care reflectă valoarea și riscul real pe care le prezintă fiecare crawler. Acest cadru permite decizii nuanțate, echilibrând protecția conținutului cu oportunitățile de business.
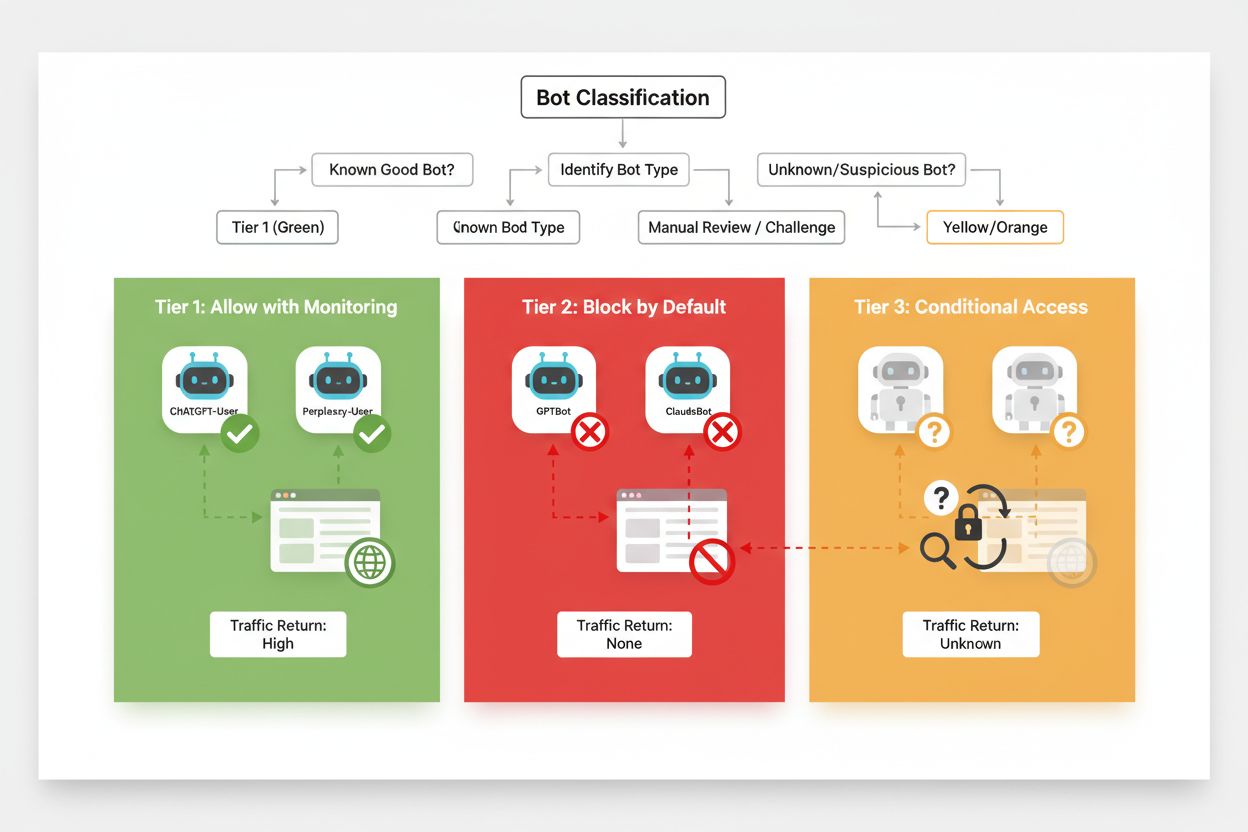
| Nivel | Clasificare | Exemple | Acțiune |
|---|---|---|---|
| Nivelul 1: Generatoare de venit | Motoare de căutare și surse majore de trafic de recomandare | Googlebot, Bingbot, Perplexity Bot | Permite acces complet; optimizează crawlabilitatea |
| Nivelul 2: Neutru/Nedovedit | Crawleri noi sau emergenți cu scopuri neclare | Startup-uri AI mici, roboți de cercetare | Monitorizează atent; permite cu limitare de rată |
| Nivelul 3: Extractoare de valoare | Crawleri de instruire fără beneficii directe | GPTBot, Claude-Web, CCBot | Blochează complet; aplică reguli pe mai multe straturi |
Implementarea acestui cadru presupune cercetare continuă asupra crawlerelor noi și a modelelor lor de business. Editorii ar trebui să auditeze regulat logurile de acces pentru a identifica roboți noi, să cerceteze termenii de utilizare ai operatorilor și politicile de compensație și să ajusteze clasificările în consecință. Un crawler care începe la nivelul 3 poate trece la nivelul 2 dacă operatorul său începe să ofere partajare de venit, iar un crawler anterior de încredere poate ajunge la nivelul 3 dacă depășește limitele sau încalcă directivele robots.txt.
Blocarea selectivă nu este o configurație “set-and-forget”—necesită monitorizare și ajustare continuă pe măsură ce ecosistemul crawlerelor evoluează. Editorii ar trebui să implementeze logare și analiză cuprinzătoare pentru a urmări ce crawlere accesează conținutul, câtă lățime de bandă consumă și dacă respectă restricțiile configurate. Aceste date stau la baza deciziilor strategice privind ce crawlere să permiți, să blochezi sau să limitezi.
Analiza logurilor de acces dezvăluie modele de comportament ale crawlerelor care fundamentează ajustări de politică:
# Identifică toți crawlerii AI care accesează site-ul tău
grep -i "bot\|crawler" /var/log/nginx/access.log | \
awk '{print $12}' | sort | uniq -c | sort -rn | head -20
# Calculează lățimea de bandă consumată de anumiți crawlere
grep "GPTBot" /var/log/nginx/access.log | \
awk '{sum+=$10} END {print "GPTBot bandwidth: " sum/1024/1024 " MB"}'
# Monitorizează răspunsurile 403 către crawlerii blocați
grep " 403 " /var/log/nginx/access.log | grep -i "bot" | wc -l
Analiza regulată a acestor date—ideal săptămânal sau lunar—îți arată dacă strategia de blocare funcționează, dacă au apărut crawleri noi și dacă vreun crawler anterior blocat și-a schimbat comportamentul. Aceste informații revin în cadrul de clasificare, asigurând că politicile tale rămân aliniate la obiectivele de afaceri și realitatea tehnică.
Editorii care implementează blocarea selectivă a crawlerelor fac adesea greșeli care le subminează strategia sau creează consecințe neintenționate. Înțelegerea acestor capcane te ajută să eviți erorile costisitoare și să implementezi o politică mai eficientă de la bun început.
Blocarea tuturor crawlerelor fără discriminare: Cea mai frecventă greșeală este folosirea unor reguli prea largi, care blochează și motoarele de căutare împreună cu crawlerii de instruire, distrugând vizibilitatea în căutări în încercarea de a proteja conținutul.
A te baza doar pe robots.txt: Presupunerea că robots.txt singur va preveni accesul neautorizat ignoră faptul că 13% dintre crawlere îl ignoră complet, lăsând conținutul vulnerabil la extragerea de date.
Nemonitorizarea și neajustarea: Implementarea unei politici statice de blocare și lipsa revizuirii ulterioare înseamnă să ratezi crawleri noi, să nu te adaptezi la modele de business în schimbare și să blochezi eventual crawlere benefice care și-au îmbunătățit practicile.
Blocarea doar după user-agent: Crawlerii sofisticați își falsifică user-agent-ul sau îl rotesc frecvent, deci blocarea doar pe user-agent este ineficientă fără reguli suplimentare pe IP și limitare de rată.
Ignorarea limitării de rată: Chiar și crawlerii permiși pot consuma excesiv lățime de bandă dacă nu sunt limitați, afectând performanța pentru utilizatorii umani și consumând resurse nejustificat.
Viitorul relației editorilor cu crawlerii AI va implica probabil negocieri și modele de compensație mai sofisticate, nu doar blocare simplă. Totuși, până la apariția unor standarde de industrie, controlul selectiv al crawlerelor rămâne cea mai practică abordare pentru protejarea conținutului și menținerea vizibilității în căutări. Editorii ar trebui să își vadă strategia de blocare ca pe o politică dinamică, care evoluează odată cu ecosistemul crawlerelor și reevaluează constant ce crawlere merită acces în funcție de impactul și gradul lor de încredere.
Cei mai de succes editori vor fi cei care implementează apărări stratificate—combinând directive robots.txt, aplicare la nivel de server, controale CDN și monitorizare continuă într-o strategie cuprinzătoare. Această abordare protejează împotriva crawlerelor conforme și neconforme și, totodată, păstrează traficul din motoarele de căutare care generează venituri și implicare. Pe măsură ce companiile AI vor recunoaște tot mai mult valoarea conținutului editorial și vor începe să ofere compensații sau acorduri de licențiere, cadrul pe care îl construiești astăzi se va adapta ușor la noi modele de business, păstrând totodată controlul asupra activelor tale digitale.
Crawlerii de instruire, precum GPTBot și ClaudeBot, colectează date pentru a construi modele AI fără a aduce trafic pe site-ul tău. Crawlerii de căutare, precum OAI-SearchBot și PerplexityBot, indexează conținut pentru motoarele de căutare AI și pot genera trafic semnificativ de recomandare către site-ul tău. Înțelegerea acestei distincții este esențială pentru implementarea unei strategii eficiente de blocare selectivă.
Da, aceasta este strategia de bază a controlului selectiv al crawlerelor. Poți folosi robots.txt pentru a interzice roboții de instruire și în același timp să permiți roboții de căutare, apoi să aplici restricții la nivel de server pentru cei care ignoră robots.txt. Această abordare îți protejează conținutul de instruirea neautorizată, menținând vizibilitatea în rezultatele căutărilor AI.
Majoritatea companiilor AI importante susțin că respectă robots.txt, însă conformarea este voluntară. Cercetările arată că aproximativ 13% dintre roboții AI ocolesc complet directivele din robots.txt. De aceea, aplicarea la nivel de server este esențială pentru editorii care iau în serios protejarea conținutului de crawlerii neconformi.
Semnificativ și în creștere. ChatGPT a trimis 243,8 milioane de vizite către 250 de site-uri de știri și media în aprilie 2025, cu 98% mai mult față de ianuarie. Blocarea acestor crawleri înseamnă pierderea acestei surse emergente de trafic. Pentru mulți editori, traficul din căutările AI reprezintă acum 5-15% din totalul traficului de recomandare.
Analizează periodic logurile serverului folosind comenzi grep pentru a identifica user agent-urile roboților, a urmări frecvența crawl-ului și a verifica respectarea regulilor din robots.txt. Verifică logurile cel puțin lunar pentru a identifica roboți noi, modele de comportament neobișnuite și dacă roboții blocați rămân într-adevăr blocați. Aceste date te ajută să iei decizii strategice privind politica ta față de crawlere.
Îți protejezi conținutul de instruirea neautorizată, dar pierzi vizibilitatea în rezultatele căutărilor AI, ratezi surse noi de trafic și poți reduce mențiunile brandului tău în răspunsurile generate de AI. Editorii care implementează blocaje totale văd adesea scăderi de 40-60% ale vizibilității în căutări și ratează oportunitățile de descoperire prin platformele AI.
Cel puțin lunar, deoarece apar constant roboți noi și cei existenți își modifică comportamentul. Ecosistemul crawlerelor AI se schimbă rapid, cu operatori noi care lansează roboți și jucători existenți care își modifică sau redenumesc crawlerii. Revizuirea regulată te asigură că politica ta rămâne aliniată la obiectivele de business și realitatea tehnică.
Este raportul dintre numărul de pagini crawl-uite și vizitatorii trimiși înapoi pe site-ul tău. Anthropic crawl-uiește 38.000 de pagini pentru fiecare vizitator trimis înapoi, OpenAI are un raport de 1.091:1, iar Perplexity de 194:1. Rapoartele mai mici indică o valoare mai bună pentru permiterea crawlerului. Acest indicator te ajută să decizi ce crawleri merită acces în funcție de impactul lor real asupra afacerii.
AmICited urmărește ce platforme AI citează brandul și conținutul tău. Obține informații despre vizibilitatea ta în AI și asigură-ți atribuirea corectă în ChatGPT, Perplexity, Google AI Overviews și multe altele.
Află cum să blochezi sau să permiți crawleri AI precum GPTBot și ClaudeBot folosind robots.txt, blocare la nivel de server și metode avansate de protecție. Ghid...

Află cum firewall-urile pentru aplicații web oferă control avansat asupra crawlerelor AI, dincolo de robots.txt. Implementează reguli WAF pentru a-ți proteja co...

Discuție în comunitate despre dacă să permiteți GPTBot și alte crawlere AI. Proprietarii de site-uri împărtășesc experiențe, impactul asupra vizibilității și co...