
Card de Referință AI Crawler: Toți Boții dintr-o Privire
Ghid complet de referință pentru crawlerele și boții AI. Identifică GPTBot, ClaudeBot, Google-Extended și peste 20 de alte crawlere AI cu user agent, rate de cr...
14 min citire

Află cum să blochezi sau să permiți crawleri AI precum GPTBot și ClaudeBot folosind robots.txt, blocare la nivel de server și metode avansate de protecție. Ghid tehnic complet cu exemple.
Peisajul digital s-a schimbat fundamental, trecând de la optimizarea clasică pentru motoare de căutare la gestionarea unei categorii noi de vizitatori automați: crawlerii AI. Spre deosebire de bot-urile de căutare tradiționale care aduc trafic către site-ul tău prin rezultate, crawlerii de antrenament AI consumă conținutul tău pentru a construi modele lingvistice, fără a trimite neapărat trafic de referință înapoi. Această diferență are implicații profunde pentru editori, creatori de conținut și afaceri care depind de trafic pentru venituri. Miza este mare—controlul asupra sistemelor AI care îți accesează conținutul are impact direct asupra avantajului competitiv, confidențialității datelor și profitabilității.
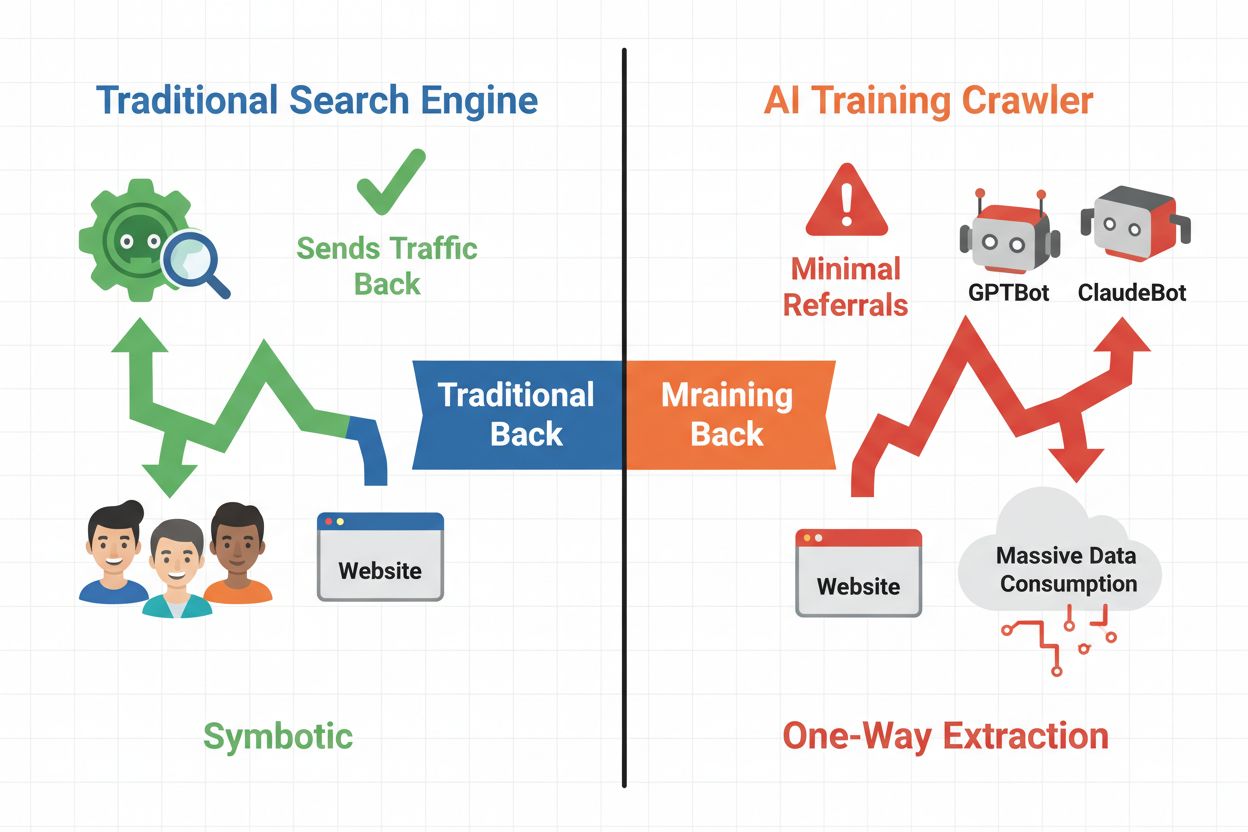
Crawlerii AI se împart în trei categorii distincte, fiecare cu scopuri și impacturi diferite asupra traficului. Crawlerii de antrenament sunt folosiți de companiile AI pentru a-și construi și îmbunătăți modelele lingvistice, operând de regulă la scară mare cu trafic de retur minim. Crawlerii de căutare și citare indexează conținut pentru motoare AI de căutare și sisteme de citare, aducând adesea ceva trafic de referință editorilor. Crawlerii declanșați de utilizatori preiau conținut la cerere când utilizatorii interacționează cu aplicații AI, reprezentând un segment mai mic, dar în creștere. Înțelegerea acestor categorii te ajută să decizi informat ce crawleri să permiți sau să blochezi în funcție de modelul tău de afaceri.
| Tip crawler | Scop | Impact trafic | Exemple |
|---|---|---|---|
| Antrenament | Construire/îmbunătățire LLM | Minim sau deloc | GPTBot, ClaudeBot, Bytespider |
| Căutare/Citare | Indexare pentru căutare/citări AI | Trafic de referință moderat | Googlebot-Extended, Perplexity |
| Declanșat de utilizator | Preluare la cerere pentru utilizatori | Mic dar constant | Pluginuri ChatGPT, browsing Claude |
Ecosistemul crawlerilor AI include roboti ai celor mai mari companii tehnologice, fiecare cu user agent-uri și scopuri distincte. GPTBot de la OpenAI (user agent: GPTBot/1.0) crawl-ează pentru a antrena ChatGPT și alte modele, în timp ce ClaudeBot de la Anthropic (user agent: Claude-Web/1.0) are un rol similar pentru Claude. Googlebot-Extended de la Google (user agent: Mozilla/5.0 ... Googlebot-Extended) indexează conținut pentru AI Overviews și Bard, în timp ce Meta-ExternalFetcher crawl-ează pentru inițiativele AI ale Meta. Alte exemple majore:
Fiecare crawler operează la scară diferită și respectă directivele de blocare în grade diferite.
Fișierul robots.txt este prima linie de apărare pentru controlul accesului crawlerilor AI, însă trebuie înțeles că are rol consultativ, nu legal. Localizat la rădăcina domeniului tău (ex: siteultau.com/robots.txt), acest fișier folosește o sintaxă simplă pentru a instrui crawlerii ce zone să evite. Pentru a bloca toți crawlerii AI, adaugă următoarele reguli:
User-agent: GPTBot
Disallow: /
User-agent: Claude-Web
Disallow: /
User-agent: Googlebot-Extended
Disallow: /
User-agent: Meta-ExternalFetcher
Disallow: /
User-agent: Amazonbot
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: Applebot-Extended
Disallow: /
User-agent: CCBot
Disallow: /
Dacă preferi blocarea selectivă—permitând crawlerii de căutare, dar blocând pe cei de antrenament—folosește această abordare:
User-agent: GPTBot
Disallow: /
User-agent: Claude-Web
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: Googlebot-Extended
Disallow: /news/
Allow: /
O greșeală frecventă este utilizarea regulilor prea generale ca Disallow: *, care pot deruta parser-ele, sau omisiunea specificării crawlerilor individuali când vrei să blochezi doar anumite bot-uri. Companii mari precum OpenAI, Anthropic și Google respectă de obicei directivele robots.txt, însă unii crawleri precum Perplexity au fost documentați că le ignoră complet.
Când robots.txt nu este suficient, există metode mai solide de a controla accesul crawlerilor AI. Blocarea pe bază de IP implică identificarea intervalelor de IP ale crawlerilor AI și blocarea acestora la nivel de firewall sau server—eficient, dar necesită mentenanță continuă pe măsură ce IP-urile se schimbă. Blocarea la nivel de server prin fișiere .htaccess (Apache) sau configurări Nginx oferă un control mai granular și este mai greu de ocolit decât robots.txt. Pentru servere Apache, implementează această regulă:
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} (GPTBot|Claude-Web|Bytespider|Amazonbot) [NC]
RewriteRule ^.*$ - [F,L]
</IfModule>
Blocarea prin meta tag folosind <meta name="robots" content="noindex, noimageindex, nofollowbydefault"> previne indexarea, dar nu oprește crawlerii de antrenament. Verificarea header-ului cererii implică verificarea dacă crawlerii provin cu adevărat din sursa declarată (prin reverse DNS și certificate SSL). Folosește blocarea la nivel de server când ai nevoie de certitudine absolută că bot-ii nu-ți accesează conținutul și combină mai multe metode pentru protecție maximă.
Să blochezi sau nu crawlerii AI presupune cântărirea mai multor interese. Blocarea crawlerilor de antrenament (GPTBot, ClaudeBot, Bytespider) împiedică folosirea conținutului tău pentru antrenarea modelelor, protejând proprietatea intelectuală și avantajul competitiv. Totuși, permiterea crawlerilor de căutare (Googlebot-Extended, Perplexity) poate aduce trafic de referință și crește vizibilitatea în rezultatele AI—un canal de descoperire în creștere. Compania Anthropic, spre exemplu, are un raport de circa 38.000 de crawl-uri pentru fiecare referință, iar raportul OpenAI e de aproximativ 400:1. Încărcarea serverului și lățimea de bandă sunt un alt aspect—crawlerii AI consumă resurse semnificative, iar blocarea lor poate reduce costurile de infrastructură. Decizia ta trebuie să fie aliniată modelului tău de afaceri: publicațiile și organizațiile media pot beneficia de trafic de referință, în timp ce companiile SaaS sau creatorii de conținut proprietar preferă de regulă blocarea.
Implementarea blocării crawlerilor e doar jumătate din bătălie—trebuie să verifici dacă bot-ii respectă cu adevărat directivele tale. Analiza log-urilor serverului este instrumentul principal de verificare; analizează log-urile pentru user agent și IP-uri ale crawlerilor ce încearcă acces după blocare. Folosește grep pentru a căuta în log-uri:
grep -i "gptbot\|claude-web\|bytespider" /var/log/apache2/access.log | wc -l
Această comandă numără de câte ori acești crawleri au accesat site-ul tău. Unelte de testare precum curl pot simula cereri de crawleri pentru a verifica dacă regulile de blocare funcționează corect:
curl -A "GPTBot/1.0" https://siteultau.com/robots.txt
Monitorizează log-urile săptămânal în prima lună după implementarea blocărilor, apoi trimestrial. Dacă detectezi crawleri ce ignoră robots.txt, treci la blocare la nivel de server sau contactează echipa de abuz a operatorului crawlerului.
Peisajul crawlerilor AI evoluează rapid pe măsură ce apar companii noi și se schimbă string-urile user agent sau intervalele IP. Revizuiri trimestriale ale listei de blocare asigură că nu ratezi crawleri noi sau nu blochezi trafic legitim din greșeală. Ecosistemul este fragmentat și descentralizat, deci nu există o listă permanentă universal valabilă. Monitorizează aceste resurse pentru noutăți:
Setează-ți remindere să verifici robots.txt și regulile de blocare la server la fiecare 90 de zile și abonează-te la newslettere de securitate pentru alerte despre noi crawleri.
Deși blocarea crawlerilor AI îi oprește să îți acceseze conținutul, AmICited răspunde provocării complementare: monitorizarea dacă sistemele AI citează sau fac referire la brandul și conținutul tău în rezultatele lor. AmICited urmărește mențiunile organizației tale în răspunsurile generate de AI, oferind vizibilitate asupra modului în care conținutul tău influențează output-urile modelelor AI și unde apare brandul tău în rezultatele AI. Astfel, creezi o strategie completă: controlezi accesul crawlerilor prin robots.txt și blocare la nivel de server, iar AmICited îți arată impactul real asupra ecosistemului AI. Împreună, aceste instrumente îți oferă vizibilitate și control total asupra prezenței tale în AI—de la prevenirea utilizării nedorite a datelor pentru antrenare până la măsurarea citărilor și referințelor generate de conținutul tău pe platformele AI.
Nu. Blocarea crawlerelor de antrenament AI precum GPTBot, ClaudeBot și Bytespider nu îți afectează pozițiile în Google sau Bing. Motoarele de căutare tradiționale folosesc alți crawleri (Googlebot, Bingbot) care operează independent. Blochează-i pe aceștia doar dacă dorești să dispari complet din rezultatele căutărilor.
Crawleri majori de la OpenAI (GPTBot), Anthropic (ClaudeBot), Google (Google-Extended) și Perplexity (PerplexityBot) declară oficial că respectă directivele robots.txt. Totuși, bot-urile mai mici sau mai puțin transparente pot ignora configurația ta, motiv pentru care există strategii de protecție pe mai multe niveluri.
Depinde de strategia ta. Blocarea doar a crawlerelor de antrenament (GPTBot, ClaudeBot, Bytespider) îți protejează conținutul de la a fi folosit pentru antrenarea modelelor, permițând totodată crawlerilor orientați spre căutare să îți aducă vizibilitate în rezultatele AI. Blocarea completă te elimină din ecosistemele AI.
Revizuiește configurația cel puțin trimestrial. Companiile AI introduc periodic noi crawleri. Anthropic a fuzionat bot-urile 'anthropic-ai' și 'Claude-Web' în 'ClaudeBot', oferind temporar acces nerestricționat noului bot pe site-urile care nu și-au actualizat regulile.
Blocarea împiedică accesul crawlerilor la conținutul tău, protejându-l de colectarea pentru antrenare sau indexare. Permiterea crawlerilor le oferă acces, dar poate duce la utilizarea conținutului tău pentru antrenarea modelelor sau afișarea în rezultatele AI cu trafic de referință minim.
Da, robots.txt are rol consultativ, nu este obligatoriu legal. Crawleri serioși de la companii mari respectă de obicei directivele robots.txt, dar unii crawleri le pot ignora. Pentru o protecție mai puternică, implementează blocare la nivel de server prin .htaccess sau reguli de firewall.
Verifică log-urile serverului pentru string-urile user agent ale crawlerilor blocați. Dacă vezi cereri de la crawleri pe care i-ai blocat, probabil nu respectă robots.txt. Folosește unelte de testare precum testerul robots.txt din Google Search Console sau comenzi curl pentru a verifica configurația.
Blocarea crawlerilor de antrenament are de obicei un impact direct minim asupra traficului, deoarece aceștia nu generează trafic de referință semnificativ. Totuși, blocarea crawlerilor de căutare poate reduce vizibilitatea în platforme AI de descoperire. Monitorizează-ți analizele timp de 30 de zile după implementare pentru a măsura impactul real.
Deși controlezi accesul crawlerelor prin robots.txt, AmICited te ajută să urmărești cum sistemele AI citează și menționează conținutul tău în rezultatele lor. Obține vizibilitate completă asupra prezenței tale în AI.
Ghid complet de referință pentru crawlerele și boții AI. Identifică GPTBot, ClaudeBot, Google-Extended și peste 20 de alte crawlere AI cu user agent, rate de cr...

Aflați cum să luați decizii strategice despre blocarea crawlerilor AI. Evaluați tipul de conținut, sursele de trafic, modelele de venituri și poziția competitiv...

Află cum să permiți boturilor AI precum GPTBot, PerplexityBot și ClaudeBot să acceseze site-ul tău. Configurează robots.txt, setează llms.txt și optimizează pen...