
Ar trebui să blocați sau să permiteți crawlerii AI? Cadru decizional
Aflați cum să luați decizii strategice despre blocarea crawlerilor AI. Evaluați tipul de conținut, sursele de trafic, modelele de venituri și poziția competitiv...
12 min citire

Ghid cuprinzător despre crawlerele AI în 2025. Identifică GPTBot, ClaudeBot, PerplexityBot și peste 20 de alți boți AI. Află cum să blochezi, să permiți sau să monitorizezi crawlerele cu robots.txt și tehnici avansate.
Crawlerele AI sunt boți automatizați concepuți să navigheze și să colecteze date sistematic de pe website-uri, însă scopul lor s-a schimbat fundamental în ultimii ani. În timp ce crawlerele tradiționale de motor de căutare precum Googlebot se concentrează pe indexarea conținutului pentru rezultate de căutare, crawlerele AI moderne prioritizează colectarea de date pentru antrenarea modelelor lingvistice de mari dimensiuni și a sistemelor AI generative. Conform celor mai noi date de la Playwire, crawlerele AI reprezintă acum aproximativ 80% din tot traficul boților AI, reflectând o creștere dramatică a volumului și diversității vizitatorilor automatizați pe website-uri. Această schimbare reflectă transformarea modului în care sistemele de inteligență artificială sunt dezvoltate și antrenate, trecând de la seturi de date publice la colectarea în timp real a conținutului web. Înțelegerea acestor crawlere a devenit esențială pentru deținătorii de website-uri, editori și creatori de conținut care trebuie să ia decizii informate cu privire la prezența lor digitală.
Crawlerele AI pot fi clasificate în trei categorii distincte, în funcție de rolul, comportamentul și impactul lor asupra website-ului tău. Crawlerele de antrenament reprezintă segmentul cel mai mare, cu aproximativ 80% din traficul boților AI, fiind proiectate să colecteze conținut pentru antrenarea modelelor de machine learning; aceste crawlere operează de obicei la volum mare și aduc trafic de referință minim, fiind intensive în consum de lățime de bandă, dar puțin probabil să aducă vizitatori pe site. Crawlerele de căutare și citare operează la volume moderate și sunt concepute special pentru a găsi și referenția conținut în rezultate de căutare și aplicații asistate de AI; spre deosebire de crawlerele de antrenament, acești boți pot chiar trimite trafic spre website-ul tău când utilizatorii accesează linkuri din răspunsuri generate de AI. Fetcher-ele declanșate de utilizator reprezintă cea mai mică categorie și operează la cerere, atunci când utilizatorii solicită explicit preluarea conținutului prin aplicații AI precum funcția de browsing a ChatGPT; aceste crawlere au volum mic, dar relevanță mare pentru interogările individuale.
| Categorie | Scop | Exemple |
|---|---|---|
| Crawlere de antrenament | Colectează date pentru antrenarea modelelor AI | GPTBot, ClaudeBot, Meta-ExternalAgent, Bytespider |
| Crawlere de căutare/citare | Găsesc și referențiază conținut în răspunsuri AI | OAI-SearchBot, Claude-SearchBot, PerplexityBot, You.com |
| Fetcher-e declanșate de utilizator | Preiau conținut la cerere pentru utilizatori | ChatGPT-User, Claude-Web, Gemini-Deep-Research |
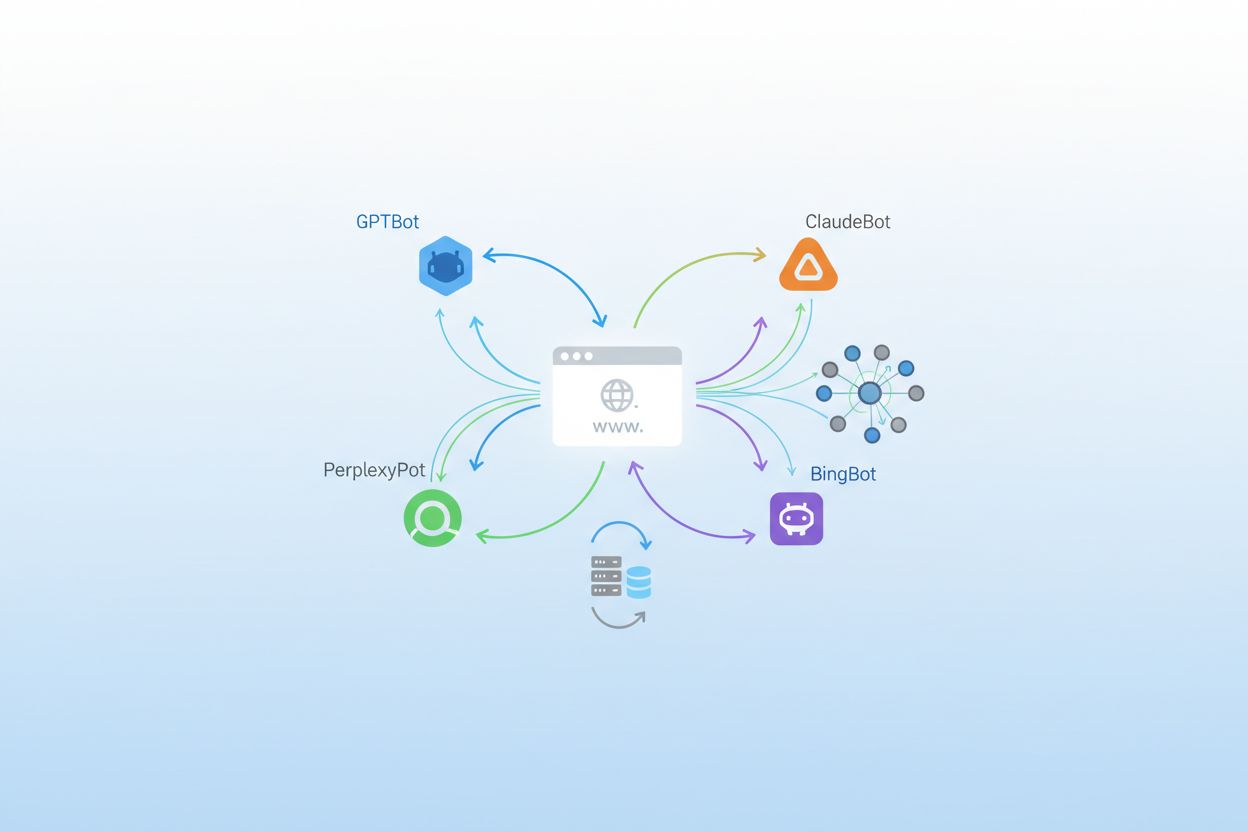
OpenAI operează cel mai divers și agresiv ecosistem de crawlere din peisajul AI, cu mai mulți boți cu scopuri diferite în suita lor de produse. GPTBot este crawlerul principal de antrenament, responsabil cu colectarea de conținut pentru îmbunătățirea GPT-4 și a viitoarelor modele, și a înregistrat o creștere uluitoare de 305% a traficului de crawler conform datelor Cloudflare; acest bot are un raport de crawl la referință de 400:1, adică descarcă conținut de 400 de ori pentru fiecare vizitator trimis înapoi pe site-ul tău. OAI-SearchBot are o funcție complet diferită, concentrându-se pe găsirea și citarea conținutului pentru funcția de căutare a ChatGPT, fără a folosi conținutul pentru antrenarea modelului. ChatGPT-User reprezintă categoria cu cea mai explozivă creștere, cu o creștere remarcabilă de 2.825% a traficului, operând de fiecare dată când utilizatorii activează funcția “Browse with Bing” pentru a prelua conținut în timp real, la cerere. Poți identifica aceste crawlere după șirurile user agent: GPTBot/1.0, OAI-SearchBot/1.0 și ChatGPT-User/1.0, iar OpenAI oferă metode de verificare a IP-ului pentru a confirma traficul legitim din infrastructura lor.
Anthropic, compania din spatele Claude, operează una dintre cele mai selective, dar intensive, operațiuni de crawlere din industrie. ClaudeBot este crawlerul lor principal de antrenament și funcționează cu un raport extraordinar de 38.000:1 crawl la referință, adică descarcă conținut mult mai agresiv decât boții OpenAI raportat la traficul trimis înapoi; acest raport extrem reflectă accentul Anthropic pe colectarea exhaustivă de date pentru antrenarea modelelor. Claude-Web și Claude-SearchBot au scopuri diferite, primul gestionând preluarea de conținut declanșată de utilizator, iar al doilea fiind axat pe funcționalitate de căutare și citare. Google și-a adaptat strategia de crawlere pentru epoca AI prin introducerea Google-Extended, un token special care permite website-urilor să opteze pentru antrenarea AI, blocând totodată indexarea tradițională de către Googlebot, și Gemini-Deep-Research, care realizează interogări de cercetare aprofundate pentru utilizatorii produselor AI ale Google. Mulți deținători de website-uri dezbat dacă să blocheze Google-Extended deoarece provine de la aceeași companie care controlează traficul de căutare, ceea ce face decizia mai complexă decât în cazul crawlerelor AI ale unor terți.
Meta a devenit un jucător important în spațiul crawlerelor AI cu Meta-ExternalAgent, care reprezintă aproximativ 19% din traficul crawlerelor AI și este folosit pentru antrenarea modelelor AI și alimentarea funcționalităților din Facebook, Instagram și WhatsApp. Meta-WebIndexer are un rol complementar, concentrându-se pe indexarea web pentru funcții și recomandări AI. Apple a introdus Applebot-Extended pentru a susține Apple Intelligence, funcțiile AI on-device, iar acest crawler a crescut constant pe măsură ce compania extinde capabilitățile AI pe dispozitivele iPhone, iPad și Mac. Amazon operează Amazonbot pentru a alimenta Alexa și Rufus, asistentul AI pentru cumpărături, făcându-l relevant pentru site-urile de e-commerce și conținut axat pe produse. PerplexityBot reprezintă una dintre cele mai spectaculoase creșteri din peisajul crawlerelor, cu o creștere uimitoare de 157.490% a traficului, reflectând creșterea explozivă a Perplexity AI ca alternativă de căutare; în ciuda acestei creșteri uriașe, Perplexity are încă un volum absolut mai mic comparativ cu OpenAI și Google, dar traiectoria indică o importanță tot mai mare.
Dincolo de jucătorii mari, numeroase crawlere AI emergente și specializate colectează activ date de pe website-uri din întreaga lume. Bytespider, operat de ByteDance (compania-mamă a TikTok), a avut o scădere dramatică de 85% a traficului de crawler, sugerând fie o schimbare de strategie, fie o nevoie redusă de colectare de date pentru antrenament. Cohere, Diffbot și CCBot de la Common Crawl reprezintă crawlere specializate axate pe cazuri de utilizare specifice, de la antrenarea modelelor lingvistice la extragerea de date structurate. You.com, Mistral și DuckDuckGo operează fiecare propriile crawlere pentru a susține funcțiile de căutare și asistent AI, adăugând la complexitatea tot mai mare a peisajului crawlerelor. Apariția regulată a unor crawlere noi, atât din partea startupurilor cât și a companiilor consacrate, face ca informarea despre acestea să fie esențială, deoarece blocarea sau permiterea lor poate avea un impact semnificativ asupra vizibilității tale pe platforme și aplicații AI de descoperire.
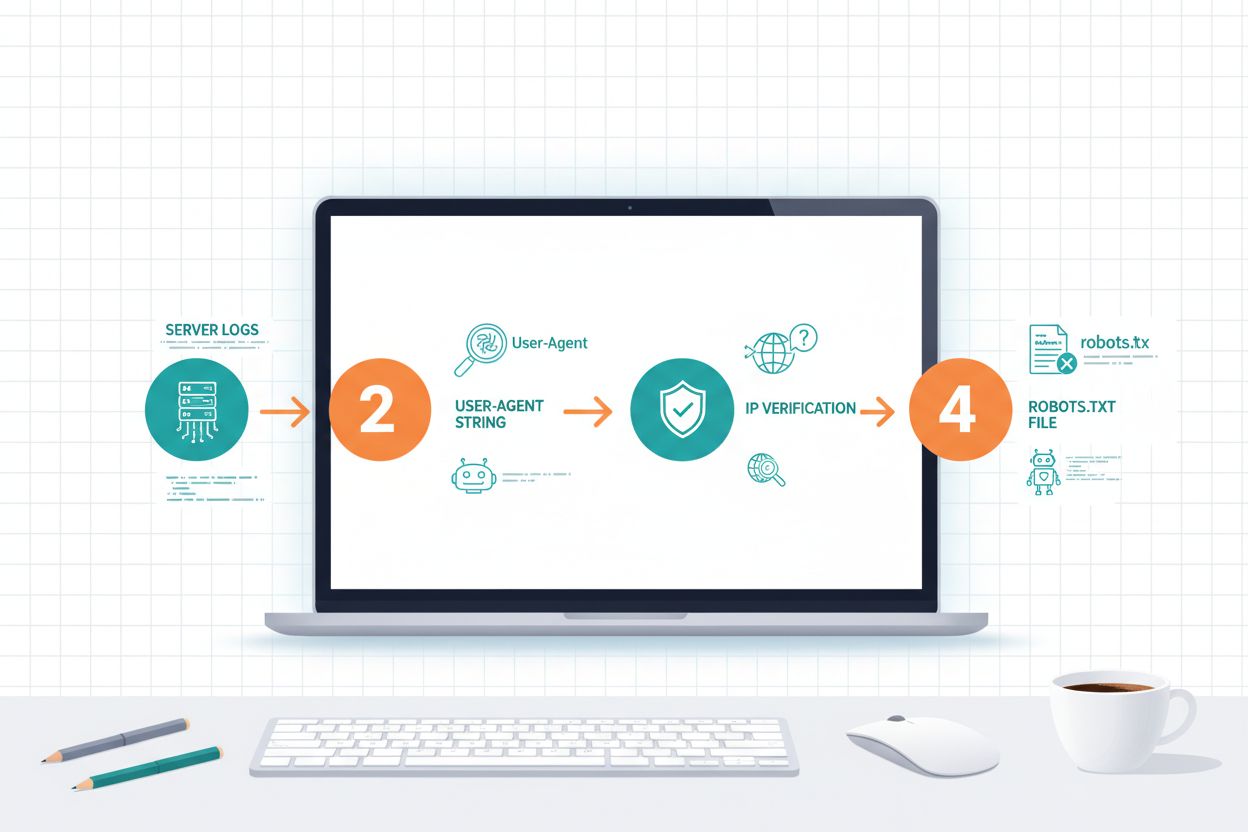
Identificarea crawlerelor AI presupune înțelegerea modului în care acestea se identifică și analiza tiparelor de trafic pe serverul tău. Șirurile user-agent sunt metoda principală de identificare, fiecare crawler anunțându-se cu un identificator specific în cererile HTTP; de exemplu, GPTBot folosește GPTBot/1.0, ClaudeBot folosește Claude-Web/1.0, iar PerplexityBot folosește PerplexityBot/1.0. Analiza logurilor serverului (de obicei în /var/log/apache2/access.log pe servere Linux sau IIS logs pe Windows) îți permite să vezi ce crawlere îți accesează site-ul și cât de des. Verificarea IP-ului este o tehnică critică suplimentară, unde poți verifica dacă un crawler care pretinde că este de la OpenAI sau Anthropic provine efectiv din intervalele lor legitime de IP, pe care aceste companii le publică pentru siguranță. Examinarea fișierului robots.txt îți arată ce crawlere ai permis sau blocat explicit, iar compararea cu traficul real arată dacă crawlerele îți respectă directivele. Instrumente precum Cloudflare Radar oferă vizibilitate în timp real asupra tiparelor de trafic ale crawlerelor și te pot ajuta să identifici care boți sunt cei mai activi pe site-ul tău. Pași practici de identificare includ: verificarea platformei de analiză pentru trafic de boți, revizuirea logurilor brute pentru tipare de user-agent, compararea adreselor IP cu intervalele de IP publicate de crawlere și folosirea instrumentelor online de verificare a crawlerelor pentru a confirma sursele suspecte de trafic.
Decizia de a permite sau bloca crawlerele AI implică evaluarea a mai multor considerații de afaceri care nu au o soluție universală. Compromisurile principale includ:
Deoarece 80% din traficul boților AI provine de la crawlerele de antrenament cu potențial minim de referință, mulți editori aleg să blocheze crawlerele de antrenament și să permită cele de căutare și citare. Această decizie depinde în cele din urmă de modelul tău de afaceri, tipul de conținut și prioritățile strategice privind vizibilitatea AI versus consumul de resurse.
Fișierul robots.txt este principalul tău instrument pentru comunicarea politicilor către boții AI, însă e important de înțeles că respectarea lui este voluntară și nu poate fi impusă tehnic. Robots.txt folosește potrivirea user-agent pentru a viza crawlere specifice, permițând crearea de reguli diferite pentru boți diferiți; de exemplu, poți bloca GPTBot permițând în același timp OAI-SearchBot, sau poți bloca toate crawlerele de antrenament, permițând cele de căutare. Conform cercetărilor recente, doar 14% dintre primele 10.000 de domenii au implementat reguli robots.txt specifice AI, ceea ce indică faptul că majoritatea website-urilor nu și-au optimizat încă politicile de crawlere pentru era AI. Fișierul folosește o sintaxă simplă, unde specifici un nume user-agent urmat de directive de disallow sau allow, și poți folosi wildcard-uri pentru a potrivi mai multe crawlere cu denumiri similare.
Iată trei scenarii practice de configurare a robots.txt:
# Scenariul 1: Blochează toate crawlerele AI de antrenament, permite cele de căutare
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
User-agent: Amazonbot
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: OAI-SearchBot
Allow: /
User-agent: PerplexityBot
Allow: /
# Scenariul 2: Blochează complet toate crawlerele AI
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
User-agent: Amazonbot
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: OAI-SearchBot
Disallow: /
User-agent: PerplexityBot
Disallow: /
User-agent: Applebot-Extended
Disallow: /
# Scenariul 3: Blocare selectivă pe directoare
User-agent: GPTBot
Disallow: /private/
Disallow: /admin/
Allow: /public/
User-agent: ClaudeBot
Disallow: /
User-agent: OAI-SearchBot
Allow: /
Reține că robots.txt este doar consultativ, iar crawlerele rău intenționate sau neconforme pot ignora complet directivele tale. Potrivirea user-agent nu ține cont de majuscule/minuscule, astfel încât gptbot, GPTBot și GPTBOT se referă la același crawler, iar cu User-agent: * poți crea reguli care se aplică tuturor crawlerelor.
Dincolo de robots.txt, există mai multe metode avansate care oferă protecție mai puternică împotriva crawlerelor AI nedorite, fiecare având niveluri diferite de eficiență și complexitate de implementare. Verificarea IP și regulile de firewall îți permit să blochezi traficul din intervale IP asociate crawlerelor AI; poți obține aceste intervale din documentația operatorilor de crawlere și configura firewall-ul sau Web Application Firewall (WAF) pentru a respinge cereri din acele IP-uri, însă acest lucru necesită mentenanță continuă pe măsură ce intervalele se modifică. Blocarea la nivel de server prin .htaccess oferă protecție pentru serverele Apache, verificând șirurile user-agent și adresele IP înainte de servirea conținutului, fiind mai fiabil decât robots.txt deoarece funcționează la nivel de server, nu pe baza bunei-credințe a crawlerului.
Iată un exemplu practic de .htaccess pentru blocarea avansată a crawlerelor:
# Blochează crawlerele AI de antrenament la nivel de server
<IfModule mod_rewrite.c>
RewriteEngine On
# Blochează după user-agent
RewriteCond %{HTTP_USER_AGENT} (GPTBot|ClaudeBot|Meta-ExternalAgent|Amazonbot|Bytespider) [NC]
RewriteRule ^.*$ - [F,L]
# Blochează după adresă IP (exemple IP-uri - înlocuiește cu IP-urile reale ale crawlerelor)
RewriteCond %{REMOTE_ADDR} ^192\.0\.2\.0$ [OR]
RewriteCond %{REMOTE_ADDR} ^198\.51\.100\.0$
RewriteRule ^.*$ - [F,L]
# Permite anumiți crawlere, blocând altele
RewriteCond %{HTTP_USER_AGENT} !OAI-SearchBot [NC]
RewriteCond %{HTTP_USER_AGENT} (GPTBot|ClaudeBot) [NC]
RewriteRule ^.*$ - [F,L]
</IfModule>
# Variante cu meta tag HTML (de adăugat în head-ul paginilor)
# <meta name="robots" content="noarchive, noimageindex">
# <meta name="googlebot" content="noindex, nofollow">
Meta tag-urile HTML precum <meta name="robots" content="noarchive"> și <meta name="googlebot" content="noindex"> oferă control la nivel de pagină, deși sunt mai puțin de încredere decât blocarea la nivel de server, deoarece crawlerele trebuie să parcurgă HTML-ul ca să le vadă. Este important de notat că IP spoofing-ul este tehnic posibil, ceea ce înseamnă că actori sofisticați pot imita IP-urile crawlerelor legitime, așa că folosirea mai multor metode combinat oferă protecție mai bună decât bazarea pe o singură abordare. Fiecare metodă are avantaje diferite: robots.txt e ușor de implementat, dar nu e impus, blocarea IP este fiabilă, dar necesită mentenanță, .htaccess oferă impunere la nivel de server, iar meta tag-urile oferă granularitate la nivel de pagină.
Implementarea politicilor privind crawlerele reprezintă doar jumătate din efort; trebuie să monitorizezi activ dacă acestea îți respectă directivele și să-ți ajustezi strategia în funcție de tiparele reale de trafic. Logurile serverului sunt sursa ta principală de date, localizate de obicei la /var/log/apache2/access.log pe servere Linux sau în directorul IIS logs pe Windows, unde poți căuta user-agent-uri specifice pentru a vedea ce crawlere îți accesează site-ul și cât de des. Platformele de analiză precum Google Analytics, Matomo sau Plausible pot fi configurate pentru a urmări traficul boților separat de vizitatorii umani, permițându-ți să vezi volumul și comportamentul diverselor crawlere în timp. Cloudflare Radar oferă vizibilitate în timp real asupra tiparelor de trafic ale crawlerelor la nivel global și îți poate arăta cum se compară traficul de crawlere de pe site-ul tău cu media industriei. Pentru a verifica dacă crawlerele îți respectă blocajele, poți folosi instrumente online pentru a verifica fișierul robots.txt, să revizuiești logurile serverului pentru user-agent-uri blocate și să compari adresele IP cu intervalele de IP publicate pentru a confirma că traficul provine din surse legitime. Pași practici de monitorizare includ: setarea unei analize săptămânale a logurilor pentru a urmări volumul de crawlere, configurarea de alerte pentru activitate neobișnuită a crawlerelor, verificarea lunar a dashboard-ului de analiză pentru tendințe de trafic boți și efectuarea de revizuiri trimestriale ale politicilor privind crawlerele pentru a te asigura că acestea corespund obiectivelor tale de business. Monitorizarea regulată te ajută să identifici crawlere noi, să detectezi încălcări ale politicilor și să iei decizii bazate pe date privind ce crawlere să permiți sau să blochezi.
Peisajul crawlerelor AI continuă să evolueze rapid, cu noi jucători care intră pe piață și crawlerele existente care își extind capabilitățile în direcții neașteptate. Crawlerele emergente de la companii precum xAI (Grok), Mistral și DeepSeek au început să colecteze date web la scară largă, iar fiecare nou startup AI lansat va introduce probabil și propriul crawler pentru a susține antrenarea modelului și funcțiile de produs. Browserele agentice reprezintă o nouă frontieră în tehnologia crawlerelor, cu sisteme precum ChatGPT Operator și Comet care pot interacționa cu website-urile ca utilizatorii umani, apăsând butoane, completând formulare și navigând interfețe complexe; acești agenți bazate pe browser sunt dificil de identificat și blocat prin metode tradiționale. Provocarea cu agenții bazate pe browser este că s-ar putea să nu se identifice clar în user-agent și pot chiar ocoli blocarea IP folosind proxy-uri rezidențiale sau infrastructuri distribuite. Crawlerele noi apar frecvent, adesea cu puțin preaviz, ceea ce face esențială informarea constantă privind evoluțiile din spațiul AI și ajustarea politicilor în consecință. Traiectoria indică o creștere continuă a traficului de crawlere, Cloudflare raportând o creștere generală de 18% a traficului de crawlere între mai 2024 și mai 2025, iar această creștere probabil se va accelera pe măsură ce tot mai multe aplicații AI devin mainstream. Deținătorii de website-uri și editorii trebuie să rămână vigilenți și adaptabili, revizuindu-și regulat politicile privind crawlerele și monitorizând noutățile pentru a se asigura că strategiile lor rămân eficiente într-un mediu în rapidă schimbare.
Deși gestionarea accesului crawlerelor la website-ul tău este importantă, la fel de critic este să înțelegi modul în care conținutul tău este folosit și citat în răspunsurile generate de AI. AmICited.com este o platformă specializată creată pentru a rezolva această problemă, urmărind modul în care crawlerele AI colectează conținutul tău și monitorizând dacă brandul și conținutul tău sunt corect citate în aplicațiile asistate de AI. Platforma te ajută să înțelegi ce sisteme AI folosesc conținutul tău, cât de frecvent apare informația ta în răspunsuri AI și dacă se oferă atribuire corectă surselor originale. Pentru editori și creatori de conținut, AmICited.com furnizează informații valoroase despre vizibilitatea ta în ecosistemul AI, ajutându-te să măsori impactul deciziei de a permite sau bloca crawlerele și să înțelegi valoarea reală pe care o primești din descoperirea asistată de AI. Monitorizând citările tale pe mai multe platforme AI, poți lua decizii mai informate privind politicile de crawlere, poți identifica oportunități pentru a-ți crește vizibilitatea în răspunsurile AI și poți asigura că proprietatea ta intelectuală este atribuită corect. Dacă ești interesat să înțelegi prezența brandului tău în web-ul alimentat de AI, AmICited.com oferă transparența și capabilitățile de monitorizare de care ai nevoie pentru a rămâne informat și a-ți proteja valoarea conținutului în această nouă eră a descoperirii conduse de AI.
Crawlerele de antrenament precum GPTBot și ClaudeBot colectează conținut pentru a construi seturi de date destinate dezvoltării modelelor lingvistice de mari dimensiuni, devenind parte din baza de cunoștințe a AI-ului. Crawlerele de căutare precum OAI-SearchBot și PerplexityBot indexează conținutul pentru experiențe de căutare asistate de AI și pot trimite trafic de referință înapoi către editori prin citări.
Acest lucru depinde de prioritățile afacerii tale. Blocarea crawlerelor de antrenament îți protejează conținutul de a fi încorporat în modele AI. Blocarea crawlerelor de căutare poate reduce vizibilitatea ta în platforme de descoperire asistate de AI precum ChatGPT search sau Perplexity. Mulți editori optează pentru blocarea selectivă, vizând crawlerele de antrenament, permițând totodată crawlerele de căutare și citare.
Cea mai fiabilă metodă de verificare este verificarea IP-ului cererii față de intervalele de IP-uri publicate oficial de operatorii de crawlere. Companii mari precum OpenAI, Anthropic și Amazon publică adresele IP ale crawlerelor lor. Poți folosi și reguli de firewall pentru a include pe lista albă IP-urile verificate și a bloca cererile din surse neverificate care pretind că sunt crawlere AI.
Google afirmă oficial că blocarea Google-Extended nu influențează poziționarea în căutări sau includerea în AI Overviews. Totuși, unii administratori de site au raportat îngrijorări, așa că monitorizează performanța căutării după implementarea blocării. AI Overviews din Google Search respectă regulile standard ale Googlebot, nu Google-Extended.
Apar în mod regulat noi crawlere AI, așa că revizuiește și actualizează lista de blocare cel puțin trimestrial. Urmărește resurse precum proiectul ai.robots.txt de pe GitHub pentru liste menținute de comunitate. Verifică lunar logurile serverului pentru a identifica crawlere noi care accesează site-ul și care nu sunt incluse în configurația actuală.
Da, robots.txt este consultativ, nu obligatoriu. Crawlerele disciplinate de la companiile mari respectă de obicei directivele robots.txt, însă unele crawlere le pot ignora. Pentru protecție mai puternică, implementează blocare la nivel de server prin .htaccess sau reguli de firewall și verifică crawlerele legitime folosind intervalele de IP publicate.
Crawlerele AI pot genera o încărcare semnificativă asupra serverului și consum de lățime de bandă. Unele proiecte de infrastructură au raportat că blocarea crawlerelor AI a redus consumul de lățime de bandă de la 800GB la 200GB zilnic, economisind aproximativ 1.500$ pe lună. Editorii cu trafic mare pot vedea reduceri semnificative de costuri prin blocare selectivă.
Verifică logurile serverului (de obicei la /var/log/apache2/access.log pe Linux) pentru șiruri user-agent care corespund crawlerelor cunoscute. Folosește platforme de analiză precum Google Analytics sau Cloudflare Radar pentru a urmări separat traficul boților. Setează alerte pentru activitate neobișnuită a crawlerelor și efectuează revizuiri trimestriale ale politicilor privind crawlerele.
Urmărește modul în care platformele AI precum ChatGPT, Perplexity și Google AI Overviews fac referire la conținutul tău. Primește alerte în timp real când brandul tău este menționat în răspunsuri generate de AI.
Aflați cum să luați decizii strategice despre blocarea crawlerilor AI. Evaluați tipul de conținut, sursele de trafic, modelele de venituri și poziția competitiv...

Învață să identifici și să monitorizezi crawlerii AI precum GPTBot, ClaudeBot și PerplexityBot în jurnalele serverului tău. Ghid complet cu șiruri user-agent, v...

Află cum să identifici și să monitorizezi crawlerele AI precum GPTBot, PerplexityBot și ClaudeBot în jurnalele serverului tău. Descoperă șiruri user-agent, meto...