
LLM Meta Answers
Află ce sunt LLM Meta Answers și cum să îți optimizezi conținutul pentru vizibilitate în răspunsurile generate de AI de către ChatGPT, Perplexity și Google AI O...
11 min citire

Află cum să creezi răspunsuri meta pentru LLM pe care sistemele AI le pot cita. Descoperă tehnici structurale, strategii pentru densitatea răspunsurilor și formate de conținut pregătite pentru citare care cresc vizibilitatea în rezultatele de căutare AI.
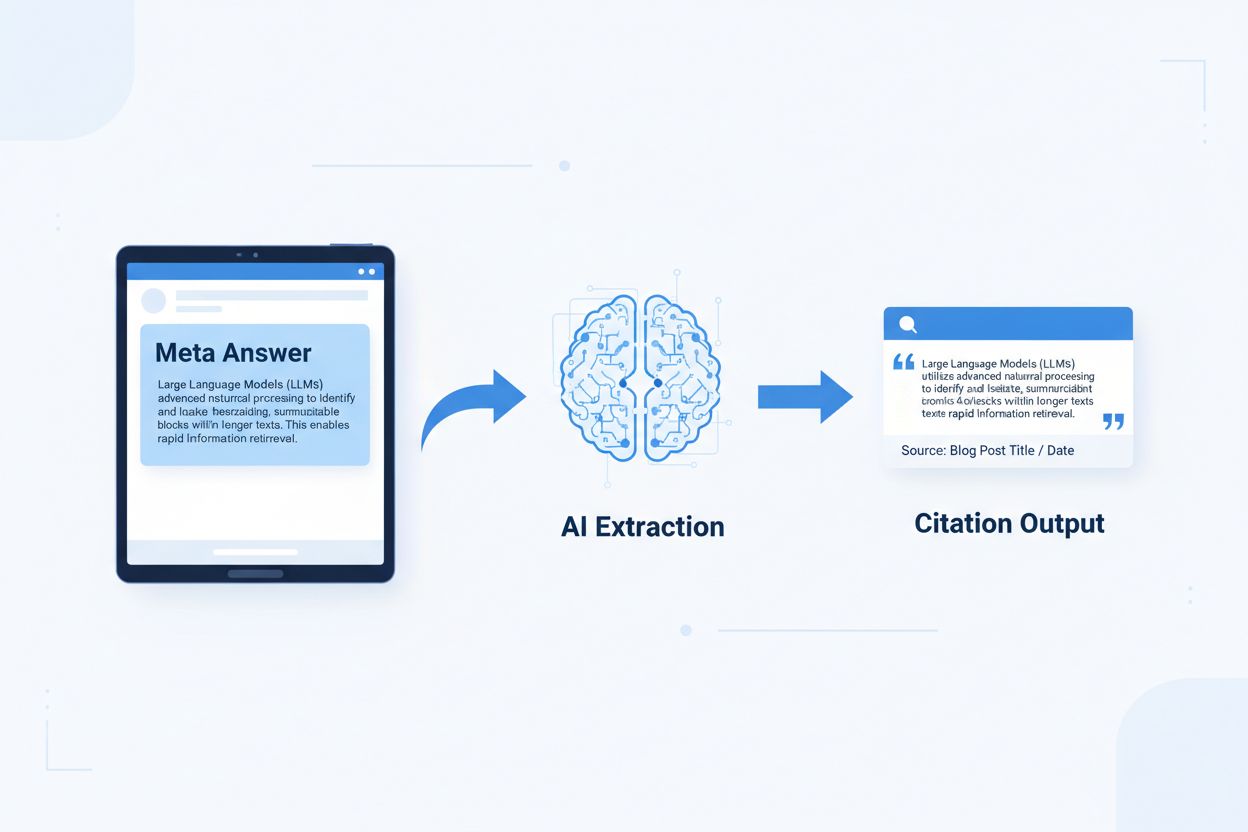
Răspunsurile meta LLM sunt blocuri de conținut independente, optimizate pentru AI, create pentru a fi extrase și citate direct de modelele de limbaj fără a necesita context suplimentar. Spre deosebire de conținutul web tradițional care se bazează pe navigație, titluri și contextul din jur pentru a oferi înțeles, răspunsurile meta funcționează ca informații independente ce își păstrează valoarea semantică completă chiar și izolate. Diferența este esențială deoarece sistemele AI moderne nu „citesc” site-urile ca oamenii—ele împart conținutul în fragmente, evaluează relevanța și extrag pasaje pentru a-și susține răspunsurile. Când AI întâlnește răspunsuri meta bine structurate, le poate cita cu încredere pentru că informația este completă, verificabilă și independentă contextual. Cercetări realizate de Onely arată că conținutul optimizat pentru citarea de către AI primește de 3-5 ori mai multe mențiuni în răspunsurile LLM față de conținutul formatat tradițional, impactând direct vizibilitatea brandului în răspunsurile generate de AI. Această schimbare reprezintă o transformare fundamentală a modului în care performează conținutul: în loc să concureze pentru poziții în căutare, răspunsurile meta concurează pentru a fi incluse în răspunsurile AI. Platforme de monitorizare a citărilor precum AmICited.com urmăresc acum aceste mențiuni AI, considerându-le metrică de performanță critică, și au descoperit că organizațiile cu conținut pregătit pentru citare văd creșteri măsurabile în traficul și autoritatea generate de AI. Legătura este directă—conținutul structurat ca răspunsuri meta este citat mai frecvent, crescând vizibilitatea brandului în peisajul informațional dominat de AI.
Conținutul pregătit pentru citare necesită elemente structurale specifice care semnalează sistemelor AI: „Acesta este un răspuns complet, ce poate fi citat.” Cele mai eficiente răspunsuri meta combină o propoziție topică clară, dovezi suport și concluzii independente, toate într-o unitate logică singulară. Aceste elemente lucrează împreună pentru a crea ceea ce sistemele AI recunosc drept cunoaștere extractibilă—informație care poate exista de sine stătătoare fără ca cititorul să fie nevoit să viziteze pagina sursă. Această abordare structurală diferă fundamental de conținutul web tradițional, care deseori fragmentează informația pe mai multe pagini și se bazează pe linkuri interne pentru a crea context.
| Element Pregătit pentru Citare | De ce îl Preferă Sistemele AI |
|---|---|
| Propoziție topică cu afirmație | Semnalează imediat valoarea de bază a răspunsului; AI poate evalua relevanța în primele 20 de tokeni |
| Dovezi suport (date/exemple) | Oferă susținere verificabilă; crește siguranța în acuratețea citării |
| Metrici sau statistici specifice | Afirmațiile cuantificabile sunt mai des citate; reduc ambiguitatea |
| Definiție sau explicație | Asigură înțelegerea independentă; AI nu are nevoie de context extern |
| Concluzie aplicabilă | Semnalează completitudinea; indică AI-ului că răspunsul s-a încheiat |
| Atribuire sursă | Construiește încredere; AI preferă să citeze conținut cu proveniență clară |
Sfaturi de implementare pentru extractibilitate AI maximă:
Dimensiunea optimă a unui fragment pentru extragerea AI se situează între 256-512 tokeni, echivalentul a 2-4 paragrafe bine structurate. Această plajă reprezintă punctul ideal în care AI poate extrage informații relevante fără a pierde contextul sau a include detalii irelevante. Fragmente mai mici de 256 tokeni nu oferă context suficient pentru citare încrezătoare, iar cele care depășesc 512 tokeni obligă AI să rezume sau să trunchieze, reducând citabilitatea directă. Fragmentarea pe bază de paragrafe—unde fiecare paragraf reprezintă o idee completă—este superioară fragmentării arbitrare pe bază de tokeni, deoarece păstrează coerența semantică și fluxul logic pe care AI-ul îl folosește pentru a evalua relevanța.
Fragmentarea bună păstrează limitele semantice:
✓ BINE: "Conținutul pregătit pentru citare necesită elemente structurale specifice.
Cele mai eficiente răspunsuri meta combină propoziții topică clare,
dovezi suport și concluzii de sine stătătoare într-o singură
unitate logică. Aceste elemente lucrează împreună pentru a crea ceea ce
sistemele AI recunosc drept cunoaștere extractibilă."
✗ RĂU: "Conținutul pregătit pentru citare necesită elemente structurale
care semnalează sistemelor AI: 'Acesta este un răspuns complet, ce poate fi citat.' Cele
mai eficiente răspunsuri meta combină propoziții topică clare, dovezi
suport și concluzii de sine stătătoare într-o singură unitate logică.
Aceste elemente lucrează împreună pentru a crea ceea ce sistemele AI
recunosc drept cunoaștere extractibilă—informație care poate exista de sine stătătoare fără ca
cititorul să fie nevoit să viziteze pagina sursă. Abordarea structurală diferă
fundamental de conținutul web tradițional, care fragmentează adesea
informația pe mai multe pagini și se bazează pe linkuri interne pentru
a crea context."
Exemplul bun păstrează coerența semantică și se oprește la o concluzie naturală. Exemplul rău combină mai multe idei, forțând AI-ul să trunchieze la mijlocul unui raționament sau să includă context irelevant. Strategiile de suprapunere—unde ultima propoziție dintr-un fragment prefigurează următorul—ajută AI-ul să înțeleagă relațiile dintre conținut fără a pierde extractibilitatea. Listă de verificare practică pentru optimizarea fragmentării: Răspunde fiecare fragment la o singură întrebare? Poate fi înțeles fără a citi paragrafele din jur? Are între 256-512 tokeni? Se termină la o limită semantică naturală?
Densitatea răspunsului măsoară raportul dintre informația aplicabilă și numărul total de cuvinte, iar conținutul cu densitate mare primește de 2-3 ori mai multe citări AI decât alternativele cu densitate redusă. Un paragraf cu densitate de 80% conține preponderent afirmații, dovezi și recomandări aplicabile, în timp ce unul cu 40% densitate include mult conținut balast, repetiții sau context care nu susține direct răspunsul de bază. Sistemele AI evaluează densitatea implicit—vor extrage și cita mai des pasaje unde fiecare propoziție contribuie la răspunsul întrebării utilizatorului. Elementele de densitate înaltă includ statistici specifice, instrucțiuni pas-cu-pas, date comparative, definiții și recomandări aplicabile. Modelele de densitate scăzută includ introduceri lungi, concepte repetate, întrebări retorice și povestiri narative care nu avansează argumentul de bază.
Metodă de măsurare: Numără propozițiile care răspund direct la întrebare versus cele ce oferă context sau tranziție. Un paragraf de densitate mare ar suna astfel: „Conținutul pregătit pentru citare primește de 3-5 ori mai multe mențiuni AI (statistică). Acest lucru se întâmplă deoarece AI-ul extrage răspunsuri complete și independente (explicație). Aplică structura răspuns-în-prima-linie și fragmentarea semantică pentru a maximiza densitatea (acțiune).” O versiune de densitate mică ar adăuga: „Multe organizații se confruntă cu provocări de vizibilitate în AI. Peisajul digital se schimbă rapid. Strategia de conținut a evoluat semnificativ. Conținutul pregătit pentru citare devine tot mai important…” A doua versiune diluează mesajul central cu context care nu susține direct răspunsul.
Statistici de impact real: Conținutul cu densitate peste 70% are în medie 4,2 citări pe lună în răspunsurile AI, comparativ cu 1,1 citări pentru conținutul sub 40%. Organizațiile care au restructurat conținutul pentru a crește densitatea au observat creșteri medii de 156% ale citărilor în 60 de zile. Exemplu de conținut de densitate mare: „Folosește fragmente de 256-512 tokeni pentru extragere AI optimă (afirmație). Această plajă păstrează contextul și previne trunchierea (dovadă). Aplică fragmentare pe paragrafe pentru a menține coerența semantică (acțiune).” Versiune de densitate mică: „Fragmentarea este importantă pentru AI. Există abordări diferite pentru organizarea conținutului. Unii preferă fragmente mici, alții mai mari. Abordarea potrivită depinde de nevoile fiecăruia.” Versiunea de densitate mare oferă îndrumări aplicabile; cea cu densitate mică enunță fapte evidente fără specificitate.

Structurile de conținut specifice semnalează AI-ului că informația este organizată pentru extragere, crescând dramatic probabilitatea de citare. Secțiunile FAQ sunt deosebit de eficiente deoarece asociază explicit întrebări cu răspunsuri, făcând ușoară identificarea și extragerea pasajelor relevante de către AI. Tabelele comparative permit AI-ului să evalueze rapid mai multe opțiuni și să citeze rânduri specifice care răspund întrebărilor utilizatorului. Instrucțiunile pas-cu-pas oferă limite semantice clare și sunt frecvent citate la întrebările de tip „cum fac…”. Listele de definiții asociază termeni cu explicații, creând puncte naturale de extragere. Casetele rezumat evidențiază idei-cheie, iar listiculele fragmentează subiectele complexe în elemente distincte și citabile.
Elemente structurale care maximizează regăsirea AI:
Exemple practice: O secțiune FAQ care întreabă „Ce este densitatea răspunsului?” urmată de o definiție și explicație completă devine sursă directă de citare. Un tabel comparativ cu „Element Pregătit pentru Citare | De ce îl Preferă Sistemele AI” (precum cel din secțiunea 2) va fi citat la întrebări comparative. Un ghid pas-cu-pas intitulat „Cum se implementează fragmentarea semantică” cu pași numerotați devine conținut instrucțional citabil. Aceste structuri funcționează pentru că se aliniază cu modul în care AI-ul procesează și extrage informația—căutând perechi clare întrebare-răspuns, comparații structurate și pași distincți.
Marcajul semantic HTML5 semnalează structura conținutului către AI, îmbunătățind acuratețea extragerii și creșterea probabilității de citare cu 40-60%. Utilizarea ierarhiei corecte a titlurilor (H1 pentru subiecte principale, H2 pentru subteme, H3 pentru puncte suport) ajută AI-ul să înțeleagă relațiile din conținut și să identifice limitele de extragere. Elemente semantice precum <article>, <section>, și <aside> oferă context suplimentar asupra scopului conținutului. Datele structurate schema.org—în special formatul JSON-LD—spun explicit AI-ului ce informații sunt prezente, permițând citări mai încrezătoare.
Exemplu JSON-LD pentru conținut FAQ:
{
"@context": "https://schema.org",
"@type": "FAQPage",
"mainEntity": [{
"@type": "Question",
"name": "Ce este densitatea răspunsului?",
"acceptedAnswer": {
"@type": "Answer",
"text": "Densitatea răspunsului măsoară raportul dintre informația aplicabilă și numărul total de cuvinte. Conținutul cu densitate mare primește de 2-3 ori mai multe citări AI decât alternativele cu densitate redusă."
}
}]
}
Exemplu JSON-LD pentru metadate articol:
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "Crearea de Răspunsuri Meta pentru LLM",
"author": {"@type": "Organization", "name": "AmICited"},
"datePublished": "2024-01-15",
"articleBody": "..."
}
Meta-conținutul—inclusiv meta descrierile și tag-urile Open Graph—ajută AI-ul să înțeleagă scopul conținutului înainte de a-l parcurge. Optimizările de performanță și accesibilitate (încărcare rapidă, optimizare mobilă, text alternativ corect) susțin indirect regăsirea AI, asigurând că tot conținutul este indexabil și accesibil. Listă de verificare tehnică: Este HTML-ul tău semantic și bine structurat? Ai implementat marcajul schema.org pentru tipul tău de conținut? Meta descrierile rezumă corect conținutul? Site-ul este optimizat pentru mobil și rapid? Imaginile au text alternativ adecvat?
Monitorizarea citărilor a devenit esențială pentru măsurarea performanței conținutului, însă majoritatea organizațiilor nu au vizibilitate asupra frecvenței apariției în răspunsurile AI. Testarea regăsirii presupune trimiterea întrebărilor țintă către principalele LLM-uri (ChatGPT, Claude, Gemini) și documentarea surselor citate în răspunsuri. Auditul conținutului presupune revizuirea sistematică a conținutului existent raportat la standardele de citare, identificând lacune și oportunități de optimizare. Metricile de performanță ar trebui să urmărească frecvența citării, contextul citării (modul în care este folosit conținutul) și creșterea citărilor în timp. Optimizarea iterativă presupune testarea modificărilor structurale, măsurarea impactului asupra frecvenței citărilor și scalarea celor mai eficiente tactici.
| Unealtă de Monitorizare | Funcție Principală | Recomandată Pentru |
|---|---|---|
| AmICited.com | Monitorizare completă a citărilor AI pe toate LLM-urile majore | Vizibilitate totală asupra citărilor și analiză competitivă |
| Otterly.AI | Detectare de conținut AI și monitorizare a citărilor | Identificarea apariției conținutului tău în răspunsuri AI |
| Peec AI | Performanța conținutului în sisteme AI | Măsurarea frecvenței și tendințelor de citare |
| ZipTie | Monitorizare conținut generat de AI | Urmărirea mențiunilor brandului în răspunsuri AI |
| PromptMonitor | Analiza ieșirilor LLM | Înțelegerea modului în care AI folosește conținutul tău |
AmICited.com se remarcă drept soluția principală deoarece oferă monitorizare în timp real pe ChatGPT, Claude, Gemini și alte LLM-uri majore, cu analize comparative și context detaliat al citărilor. Platforma arată nu doar dacă ai fost citat, ci și modul în care a fost folosit conținutul—dacă este citat direct, parafrazat sau utilizat ca dovadă. Metodă de măsurare: Stabilește frecvența de bază a citărilor pentru cele mai bune 20 articole ale tale. Implementează optimizări pentru citare pe 5-10 piese. Măsoară schimbările de citare timp de 30-60 de zile. Scalează tacticile eficiente pe restul conținutului. Urmărește metrici precum frecvență, rată de creștere, context și cotă de citare competitivă.
Greșeala 1: Îngroparea răspunsului în context. Mulți creatori de conținut încep cu informații de fundal, context istoric sau descrierea problemei înainte de a oferi răspunsul propriu-zis. AI-ul evaluează relevanța în primele 50-100 de tokeni; dacă răspunsul nu apare rapid, trece la următoarea sursă. Problemă: Utilizatorii care întreabă „Ce este densitatea răspunsului?” găsesc un paragraf ce începe cu „Strategia de conținut a evoluat semnificativ…” în loc de definiție. Soluție: Folosește structura răspuns-în-prima-linie—începe cu ideea principală, apoi adaugă contextul suport.
Greșeala 2: Crearea de răspunsuri ce necesită context extern. Conținutul care face referire la „secțiunea anterioară” sau „cum am menționat mai devreme” nu poate fi extras independent. Problemă: Un paragraf care spune „Urmând abordarea discutată, implementează acești pași…” eșuează deoarece abordarea nu este inclusă în fragmentul extras. Soluție: Fă fiecare răspuns independent; include contextul necesar chiar dacă presupune repetiții minore.
Greșeala 3: Amestecarea mai multor răspunsuri într-un singur fragment. Paragrafele ce răspund la mai multe întrebări forțează AI-ul să trunchieze sau să includă informații irelevante. Problemă: Un paragraf de 600 de cuvinte care acoperă „Ce este densitatea răspunsului?”, „Cum se măsoară?” și „De ce contează?” devine prea mare pentru extragere sigură. Soluție: Creează fragmente separate, concentrate pe fiecare întrebare sau concept distinct.
Greșeala 4: Folosirea unui limbaj vag în locul metricilor specifice. Expresii precum „mulți”, „unele”, „adesea” și „de obicei” reduc încrederea citării deoarece sunt imprecise. Problemă: „Multe organizații văd îmbunătățiri” e mai puțin citabil decât „Organizațiile care au restructurat conținutul au avut creșteri de 156% la citări.” Soluție: Înlocuiește calificativele cu date specifice; dacă nu ai cifre exacte, folosește intervale („40-60%”) în locul termenilor vagi.
Greșeala 5: Neglijarea marcajului structural. Conținutul fără structură HTML corectă, titluri sau marcaj schema.org este mai greu de procesat și extras de AI. Problemă: Un paragraf fără titlu, fără HTML semantic și fără schema markup este tratat ca text generic, nu ca răspuns distinct. Soluție: Folosește HTML5 semantic, implementează ierarhia titlurilor și adaugă marcaj schema.org pentru tipul tău de conținut.
Greșeala 6: Crearea de răspunsuri prea scurte sau prea lungi. Fragmentele sub 150 tokeni nu au context suficient; cele peste 700 tokeni sunt trunchiate. Problemă: Un răspuns de 100 de cuvinte nu are dovezi suport; unul de 1000 de cuvinte e împărțit în mai multe extrageri. Soluție: Țintește la 256-512 tokeni (2-4 paragrafe); include afirmație, dovadă și concluzie în acest interval.
Consistența entităților—folosirea terminologiei identice pentru același concept în tot conținutul—crește probabilitatea citării AI semnalând cunoaștere autoritară. Dacă definești „densitatea răspunsului” într-o secțiune, folosește exact acest termen peste tot, nu alterna cu „densitate informațională” sau „densitatea conținutului”. AI-ul recunoaște consistența entității ca semnal de expertiză și va cita mai ușor conținutul cu terminologie precisă și consistentă. Acest principiu se aplică numelor de produse, metodologiilor și termenilor tehnici—consistența crește încrederea în acuratețea citării.
Mențiunile terțe și cercetarea originală cresc dramatic frecvența citării. Conținutul care citează alte surse autoritare (cu atribuire corectă) semnalează credibilitate, iar cercetarea originală sau datele proprii fac conținutul unic citabil. Când incluzi statistici din propria cercetare sau studii de caz cu clienții tăi, AI-ul recunoaște aceste informații drept perspective originale care nu pot fi găsite altundeva. Organizațiile care publică cercetare originală văd rate de citare de 3-4 ori mai mari decât cele care se bazează doar pe informații sintetizate. Strategie: Realizează cercetare originală în industrie, publică rezultatele cu metodologie detaliată și fă referire la aceste descoperiri în răspunsurile tale meta.
Semnalele de prospețime—date de publicare, date de actualizare și referințe la evenimente recente—ajută AI-ul să înțeleagă actualitatea conținutului. Conținutul actualizat în ultimele 30 de zile primește prioritate mai mare la citare decât cel depășit, mai ales pe teme cu informații ce se schimbă frecvent. Include date de publicare în marcajul schema.org și timpi de actualizare la revizii. Strategie: Stabilește un calendar de reîmprospătare a conținutului; actualizează cele mai performante materiale la fiecare 30-60 de zile cu statistici noi, exemple recente sau explicații extinse.
Semnalele E-E-A-T (Experiență, Expertiză, Autoritate, Încredere) influențează deciziile AI privind citarea. Conținutul scris de experți recunoscuți, publicat pe domenii autoritare și susținut de acreditări primește prioritate la citare. Include biografii de autor cu acreditări relevante, publică pe domenii cu autoritate și obține backlink-uri de la surse recunoscute în industrie. Strategie: Evidențiază autori experți, include informații despre acreditări în biografiile autorilor și urmărește backlink-uri din publicații de prestigiu.
Densitatea de brand generativă—raportul dintre ideile brandului și informațiile generice—determină dacă AI-ul te citează pe tine sau concurența. Conținutul care include cadre proprii, metodologii unice sau abordări marcate devine mai citabil pentru că este diferențiat. Conținutul generic despre „cele mai bune practici” este citat mai rar decât unul despre „Cadrul de Optimizare a Citărilor de la AmICited” deoarece varianta de brand este unică și ușor de urmărit. Organizațiile cu densitate mare de brand generativ văd de 2-3 ori mai multe citări decât cele cu conținut generic. Strategie: Dezvoltă cadre, metodologii sau termeni proprii; folosește-le constant în tot conținutul; fă-le fundația răspunsurilor tale meta.

Răspunsurile meta LLM sunt concepute special pentru extragerea și citarea de către AI, în timp ce fragmentele evidențiate sunt optimizate pentru afișarea rezultatelor în Google. Răspunsurile meta prioritizează completitudinea de sine stătătoare și coerența semantică, pe când fragmentele evidențiate se concentrează pe concizie și potrivirea cuvintelor cheie. Ambele pot coexista în conținutul tău, dar răspunsurile meta necesită optimizare structurală diferită.
Lungimea optimă este de 256-512 tokeni, echivalentul a aproximativ 2-4 paragrafe bine structurate sau 200-400 de cuvinte. Această plajă păstrează suficient context pentru extragerea AI cu încredere și previne trunchierea. Răspunsurile mai scurte nu oferă context; cele mai lungi obligă sistemele AI să rezume sau să împartă răspunsul în mai multe extrageri.
Da, dar necesită restructurare. Evaluează conținutul existent pentru structură de tip răspuns-la-întrebare, coerență semantică și completitudine de sine stătătoare. Majoritatea conținutului poate fi adaptat mutând ideile principale la început, eliminând referințele încrucișate și asigurând ca fiecare secțiune să răspundă complet la o întrebare fără context extern.
Actualizează conținutul cu cele mai bune performanțe la fiecare 30-60 de zile cu statistici noi, exemple recente sau explicații extinse. Sistemele AI prioritizează conținutul actualizat în ultimele 30 de zile, în special pentru subiecte cu informații în continuă schimbare. Include date de publicare și timpi de actualizare în marcajul schema.org.
Densitatea răspunsului se corelează direct cu frecvența citării. Conținutul cu densitate de răspuns peste 70% are în medie 4,2 citări pe lună în ieșirile AI, comparativ cu 1,1 citări pentru conținutul sub 40% densitate. Conținutul de densitate mare oferă informații aplicabile fără balast, devenind astfel mai valoros pentru a fi citat de AI.
Folosește platforme de monitorizare a citărilor precum AmICited.com, care urmărește citările pe ChatGPT, Claude, Gemini și alte LLM-uri majore. Efectuează teste manuale trimițând întrebările tale țintă către sisteme AI și documentează sursele citate. Măsoară frecvența de bază a citărilor, implementează optimizări și urmărește schimbările timp de 30-60 de zile.
Structura de bază a răspunsului meta rămâne constantă pe platforme, dar poți optimiza pentru preferințe specifice. ChatGPT preferă conținut complet și bine sursat. Perplexity pune accent pe informații recente și citări clare. Google AI Overviews prioritizează date structurate și semnale E-E-A-T. Testează variante și monitorizează performanța citărilor pe fiecare platformă.
AmICited oferă monitorizare în timp real a citărilor conținutului tău pe toate platformele AI majore, arătând exact unde apar răspunsurile tale meta, cum sunt utilizate și cât de multă cotă de citare ai față de concurență. Platforma arată contextul citărilor—dacă conținutul este citat direct, parafrazat sau folosit ca suport—permițând decizii de optimizare bazate pe date.
Vezi exact unde conținutul tău este citat de ChatGPT, Perplexity, Google AI Overviews și alte sisteme AI. Urmărește tendințele de citare, monitorizează concurența și optimizează-ți strategia de conținut cu AmICited.
Află ce sunt LLM Meta Answers și cum să îți optimizezi conținutul pentru vizibilitate în răspunsurile generate de AI de către ChatGPT, Perplexity și Google AI O...

Află cum să identifici și să țintești site-urile sursă LLM pentru backlink-uri strategice. Descoperă care platforme AI citează cel mai mult sursele și optimizea...
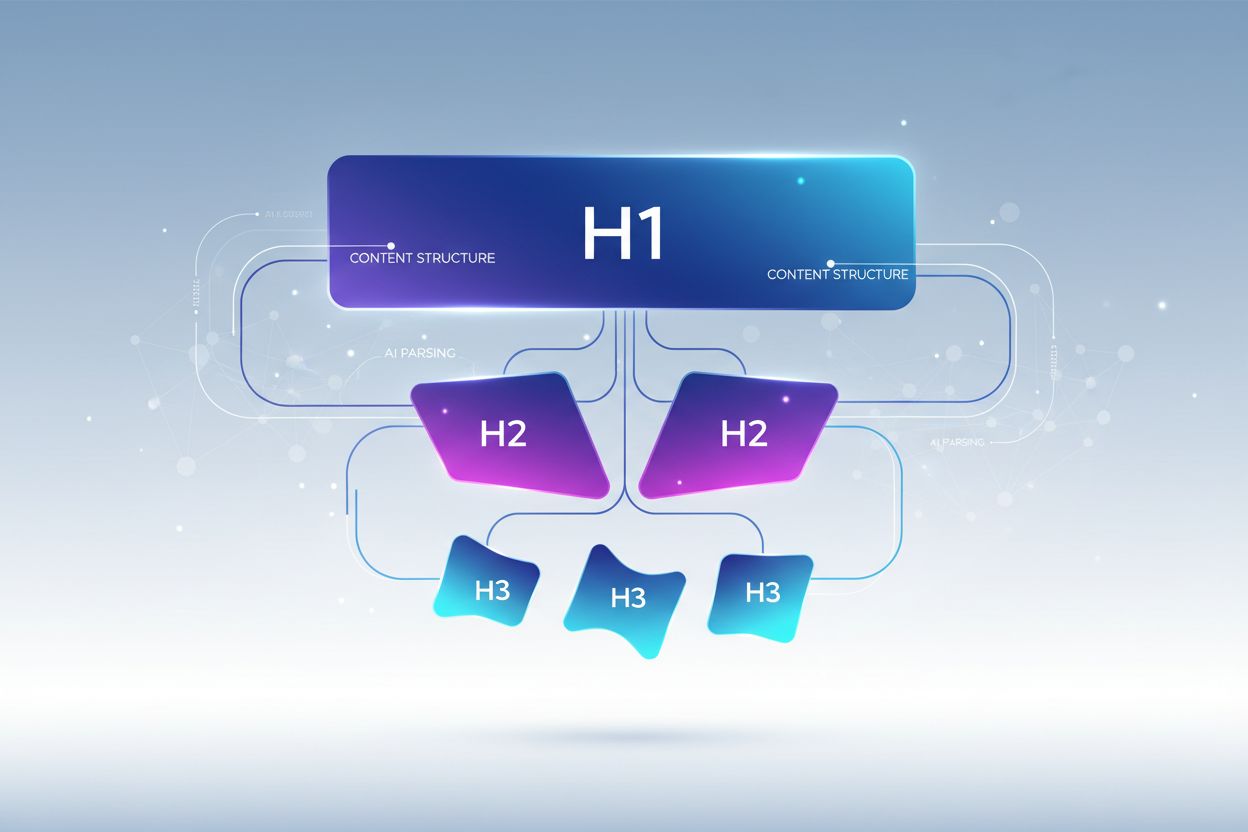
Află cum să optimizezi ierarhia titlurilor pentru parcurgerea de către LLM-uri. Stăpânește structura H1, H2, H3 pentru a crește vizibilitatea în AI, citările și...