
Ce crawlere AI ar trebui să permit accesul? Ghid complet pentru 2025
Află ce crawlere AI să permiți sau să blochezi în robots.txt. Ghid cuprinzător despre GPTBot, ClaudeBot, PerplexityBot și peste 25 de crawlere AI, cu exemple de...
11 min citire

Află cum să implementezi meta tag-urile noai și noimageai pentru a controla accesul crawlerelor AI la conținutul site-ului tău. Ghid complet pentru headerele de control AI și metode de implementare.
Crawlerele web sunt programe automate care navighează sistematic pe internet, colectând informații de pe site-uri. Istoric, acești boți erau operați în principal de motoare de căutare precum Google, al căror Googlebot scana pagini, indexa conținut și aducea utilizatorii înapoi pe site-uri prin rezultate de căutare—creând o relație reciproc avantajoasă. Totuși, apariția crawlerelor AI a schimbat fundamental această dinamică. Spre deosebire de boții clasici ai motoarelor de căutare care oferă trafic de referință în schimbul accesului la conținut, crawler-ele de antrenare AI consumă cantități uriașe de conținut web pentru a construi seturi de date pentru modele lingvistice mari, oferind adesea trafic minim sau chiar zero publisherilor. Această schimbare a făcut ca meta tag-urile—directive HTML mici care comunică instrucțiuni crawlerelor—să devină tot mai importante pentru creatorii de conținut care doresc să dețină controlul asupra modului în care munca lor este folosită de sistemele de inteligență artificială.
noai și noimageai sunt meta tag-uri create de DeviantArt în 2022 pentru a ajuta creatorii de conținut să prevină folosirea lucrărilor lor la antrenarea generatoarelor AI de imagini. Aceste tag-uri funcționează similar cu directiva bine-cunoscută noindex ce spune motoarelor de căutare să nu indexeze o pagină. Directiva noai semnalează că niciun conținut de pe pagină nu trebuie folosit pentru antrenare AI, în timp ce noimageai previne special folosirea imaginilor pentru antrenare AI. Le poți implementa în secțiunea head a HTML-ului tău folosind următoarea sintaxă:
<!-- Blochează tot conținutul de la antrenarea AI -->
<meta name="robots" content="noai">
<!-- Blochează doar imaginile de la antrenarea AI -->
<meta name="robots" content="noimageai">
<!-- Blochează atât conținutul, cât și imaginile -->
<meta name="robots" content="noai, noimageai">
Iată un tabel comparativ al diferitelor directive meta tag și scopurile lor:
| Directivă | Scop | Sintaxă | Acoperire |
|---|---|---|---|
| noai | Previne tot conținutul de la antrenarea AI | content="noai" | Tot conținutul paginii |
| noimageai | Previne imaginile de la antrenarea AI | content="noimageai" | Doar imaginile |
| noindex | Previne indexarea de către motoarele de căutare | content="noindex" | Rezultate de căutare |
| nofollow | Previne urmărirea link-urilor | content="nofollow" | Link-uri externe |
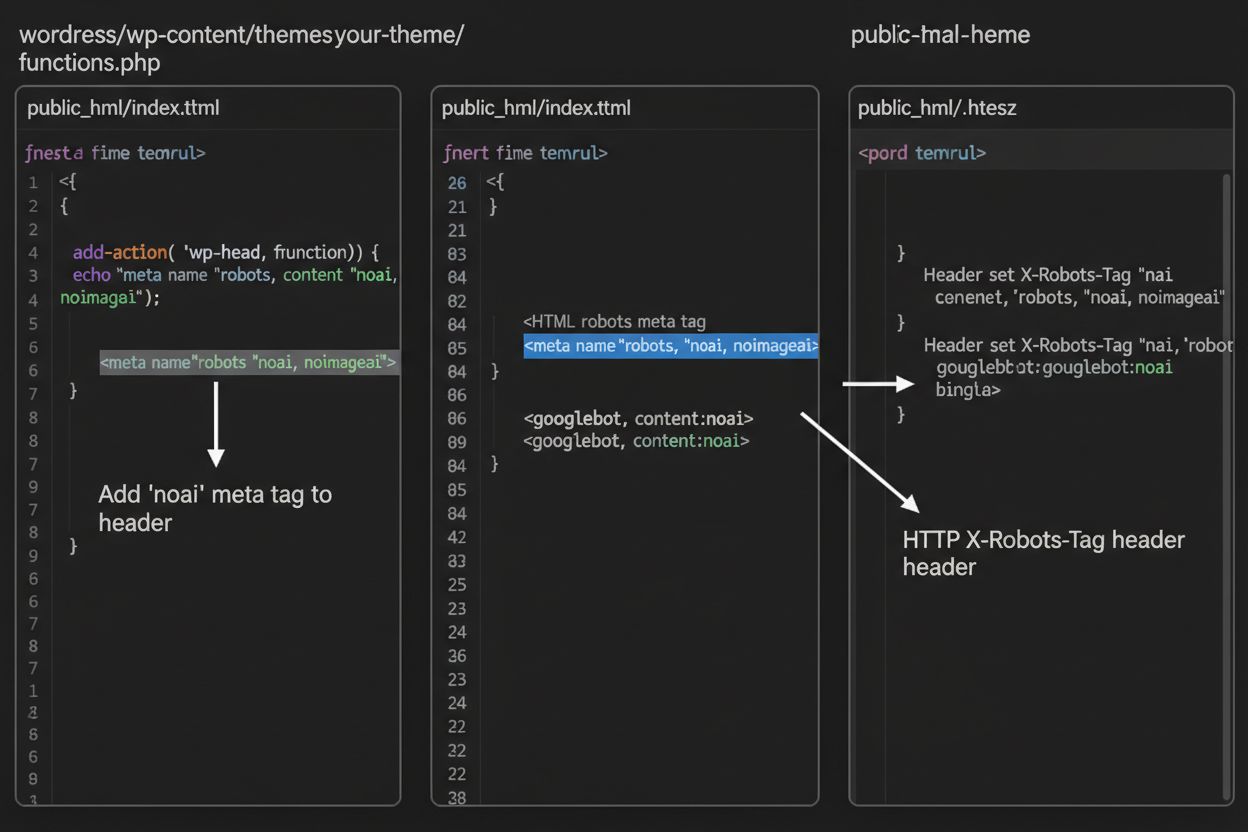
Deși meta tag-urile sunt plasate direct în HTML-ul tău, headerele HTTP oferă o metodă alternativă pentru a comunica directive către crawlere la nivel de server. Headerul X-Robots-Tag poate include aceleași directive ca meta tag-urile, dar funcționează diferit—este trimis în răspunsul HTTP înainte de livrarea conținutului paginii. Această abordare este deosebit de valoroasă pentru controlul accesului la fișiere non-HTML precum PDF-uri, imagini și videoclipuri, unde nu poți încorpora meta tag-uri HTML.
Pentru servere Apache, poți seta headere X-Robots-Tag în fișierul .htaccess:
<IfModule mod_headers.c>
Header set X-Robots-Tag "noai, noimageai"
</IfModule>
Pentru servere NGINX, adaugă headerul în configurația serverului:
location / {
add_header X-Robots-Tag "noai, noimageai";
}
Headerele oferă protecție globală pe întregul site sau pe directoare specifice, făcându-le ideale pentru strategii de control AI la scară largă.
Eficiența tag-urilor noai și noimageai depinde în totalitate de faptul dacă crawlerele aleg sau nu să le respecte. Crawlerele respectuoase de la companii AI mari, în general, onorează aceste directive:
Totuși, boți comportați necorespunzător și crawlere malițioase pot ignora deliberat aceste directive pentru că nu există niciun mecanism de impunere. Spre deosebire de robots.txt, pe care motoarele de căutare au agreat să-l respecte ca standard al industriei, noai nu este un standard web oficial, ceea ce înseamnă că crawlerele nu au nicio obligație să se conformeze. De aceea, experții în securitate recomandă o abordare în straturi care combină mai multe metode de protecție, nu doar meta tag-uri.
Implementarea tag-urilor noai și noimageai diferă în funcție de platforma site-ului tău. Iată instrucțiuni pas cu pas pentru cele mai comune platforme:
1. WordPress (prin functions.php) Adaugă acest cod în fișierul functions.php al temei copil:
function add_noai_meta_tag() {
echo '<meta name="robots" content="noai, noimageai">' . "\n";
}
add_action('wp_head', 'add_noai_meta_tag');
2. Site-uri Statice HTML
Adaugă direct în secțiunea <head> a HTML-ului:
<head>
<meta name="robots" content="noai, noimageai">
</head>
3. Squarespace Navighează la Settings > Advanced > Code Injection, apoi adaugă în secțiunea Header:
<meta name="robots" content="noai, noimageai">
4. Wix Mergi la Settings > Custom Code, fă clic pe “Add Custom Code”, inserează meta tag-ul, selectează “Head” și aplică pe toate paginile.
Fiecare platformă oferă niveluri diferite de control—WordPress permite implementare la nivel de pagină prin pluginuri, în timp ce Squarespace și Wix oferă opțiuni globale pentru tot site-ul. Alege metoda cea mai potrivită nivelului tău tehnic și nevoilor specifice.
Chiar dacă tag-urile noai și noimageai reprezintă un pas important pentru protecția creatorilor de conținut, ele au limitări semnificative. În primul rând, nu sunt standarde web oficiale—DeviantArt le-a creat ca inițiativă comunitară, deci nu există niciun standard formal sau mecanism de impunere. În al doilea rând, respectarea lor este complet voluntară. Crawlerele respectuoase de la companii mari se conformează acestor directive, însă boții mai puțin corecți și scraperii le pot ignora fără consecințe. În al treilea rând, lipsa standardizării duce la o adopție variabilă. Unele companii AI mici și organizații de cercetare posibil nici nu cunosc aceste directive, cu atât mai puțin să le implementeze. În final, meta tag-urile singure nu pot opri actorii rău intenționați să îți scrapeze conținutul. Un crawler malițios poate ignora complet directivele tale, ceea ce face ca straturile suplimentare de protecție să fie esențiale pentru securitatea completă a conținutului.
Cea mai eficientă strategie de control AI folosește mai multe straturi de protecție în loc să se bazeze pe o singură metodă. Iată o comparație a diferitelor abordări de protecție:
| Metodă | Acoperire | Eficiență | Dificultate |
|---|---|---|---|
| Meta Tag-uri (noai) | La nivel de pagină | Medie (conformare voluntară) | Ușor |
| robots.txt | La nivel de site | Medie (doar consultativ) | Ușor |
| Headere X-Robots-Tag | La nivel de server | Mediu-Ridicat (acoperă toate tipurile de fișiere) | Mediu |
| Reguli Firewall | La nivel de rețea | Ridicată (blochează la nivel infrastructură) | Greu |
| Allowlisting IP | La nivel de rețea | Foarte ridicată (doar surse verificate) | Greu |
O strategie completă poate include: (1) implementarea meta tag-urilor noai pe toate paginile, (2) adăugarea de reguli robots.txt pentru blocarea crawlerelor AI cunoscute, (3) setarea headerelor X-Robots-Tag la nivel de server pentru fișiere non-HTML și (4) monitorizarea log-urilor serverului pentru a identifica crawlerele care îți ignoră directivele. Această abordare stratificată crește semnificativ dificultatea pentru actorii rău intenționați și păstrează compatibilitatea cu crawlerele care respectă preferințele tale.
După implementarea tag-urilor noai și a altor directive, ar trebui să verifici dacă crawlerele chiar respectă regulile tale. Cea mai directă metodă este verificarea log-urilor de acces ale serverului pentru activitate crawler. Pe serverele Apache, poți căuta crawlere specifice astfel:
grep "GPTBot\|ClaudeBot\|PerplexityBot" /var/log/apache2/access.log
Dacă observi cereri de la crawlere pe care le-ai blocat, acestea îți ignoră directivele. Pentru serverele NGINX, verifică /var/log/nginx/access.log folosind aceeași comandă grep. De asemenea, instrumente precum Cloudflare Radar oferă vizibilitate asupra modelelor de trafic ale crawlerelor AI pe site-ul tău, arătând care boți sunt cei mai activi și cum le variază comportamentul în timp. Monitorizarea periodică a log-urilor—cel puțin lunar—te ajută să identifici crawlere noi și să verifici dacă măsurile de protecție funcționează conform așteptărilor.
În prezent, noai și noimageai există într-o zonă gri: sunt recunoscute și respectate de marile companii AI, însă rămân neoficiale și nestandardizate. Totuși, există o tendință în creștere spre standardizare formală. W3C (World Wide Web Consortium) și diverse grupuri din industrie discută cum să creeze standarde oficiale pentru controlul AI care ar da acestor directive aceeași greutate ca standardelor existente precum robots.txt. Dacă noai devine un standard web oficial, conformarea va deveni o așteptare a industriei, nu doar un act voluntar, crescând semnificativ eficacitatea sa. Această inițiativă de standardizare reflectă o schimbare mai largă în modul în care industria tech privește drepturile creatorilor de conținut și echilibrul între dezvoltarea AI și protecția publisherilor. Pe măsură ce tot mai mulți publisheri adoptă aceste tag-uri și cer protecții mai puternice, crește probabilitatea unei standardizări oficiale, ceea ce ar putea transforma controlul AI într-un element fundamental al guvernanței web, la fel de important ca regulile de indexare pentru motoarele de căutare.
Meta tag-ul noai este o directivă plasată în secțiunea head a HTML-ului site-ului tău care semnalează crawlerelor AI că acest conținut nu ar trebui folosit pentru antrenarea modelelor de inteligență artificială. Funcționează prin comunicarea preferințelor tale către boți AI respectuoși, deși nu este un standard web oficial și unele crawlere pot să-l ignore.
Nu, noai și noimageai nu sunt standarde web oficiale. Ele au fost create de DeviantArt ca o inițiativă comunitară pentru a ajuta creatorii de conținut să-și protejeze lucrările de antrenarea AI. Totuși, companii AI mari precum OpenAI, Anthropic și altele au început să respecte aceste directive în crawlerele lor.
Marile crawlere AI, inclusiv GPTBot (OpenAI), ClaudeBot (Anthropic), PerplexityBot (Perplexity), Amazonbot (Amazon) și altele, respectă directiva noai. Totuși, unele crawlere mai mici sau mai puțin respectuoase pot să o ignore, motiv pentru care se recomandă o abordare de protecție în straturi.
Meta tag-urile sunt plasate în secțiunea head a HTML-ului și se aplică la nivel de pagină, în timp ce headerele HTTP (X-Robots-Tag) sunt setate la nivel de server și se pot aplica global sau pe tipuri specifice de fișiere. Headerele funcționează și pentru fișiere non-HTML precum PDF-uri și imagini, fiind mai versatile pentru o protecție completă.
Da, poți implementa tag-uri noai pe WordPress prin mai multe metode: adăugând cod în fișierul functions.php al temei, folosind un plugin precum WPCode sau prin instrumente de tip page builder ca Divi și Elementor. Metoda cu functions.php este cea mai comună și presupune adăugarea unui hook simplu pentru a introduce meta tag-ul în header-ul site-ului.
Depinde de obiectivele tale de business. Blocarea crawlerelor de antrenare protejează conținutul tău de a fi folosit la dezvoltarea modelelor AI. Totuși, blocarea crawlerelor de căutare precum OAI-SearchBot poate reduce vizibilitatea ta în rezultatele de căutare AI și în platforme de descoperire. Mulți publisheri folosesc o abordare selectivă, blocând crawlerii de antrenare și permițându-i pe cei de căutare.
Poți verifica log-urile serverului pentru activitatea crawlerelor folosind comenzi ca grep pentru a căuta user agent-uri specifice boților. Instrumente precum Cloudflare Radar oferă vizibilitate asupra traficului crawlerelor AI. Monitorizează periodic log-urile pentru a vedea dacă crawlerele blocate accesează totuși conținutul tău, ceea ce ar indica faptul că îți ignoră directivele.
Dacă crawlerele ignoră meta tag-urile, implementează straturi suplimentare de protecție, inclusiv reguli robots.txt, headere HTTP X-Robots-Tag și blocare la nivel de server prin .htaccess sau reguli de firewall. Pentru verificare mai strictă, folosește allowlisting IP pentru a permite doar cererile din adrese IP verificate publicate de marile companii AI.
Folosește AmICited pentru a urmări modul în care sisteme AI precum ChatGPT, Perplexity și Google AI Overviews citează și referențiază conținutul tău pe diverse platforme AI.
Află ce crawlere AI să permiți sau să blochezi în robots.txt. Ghid cuprinzător despre GPTBot, ClaudeBot, PerplexityBot și peste 25 de crawlere AI, cu exemple de...
Află cum să identifici și să monitorizezi crawlerele AI precum GPTBot, PerplexityBot și ClaudeBot în jurnalele serverului tău. Descoperă șiruri user-agent, meto...

Aflați cum să luați decizii strategice despre blocarea crawlerilor AI. Evaluați tipul de conținut, sursele de trafic, modelele de venituri și poziția competitiv...